Przekształcanie danych przy użyciu dbt
Uwaga
Zadanie apache Airflow jest obsługiwane przez platformę Apache Airflow.
dbt(Data Build Tool) to interfejs wiersza polecenia typu open source, który upraszcza przekształcanie i modelowanie danych w magazynach danych, zarządzając złożonym kodem SQL w ustrukturyzowany, konserwowalny sposób. Umożliwia zespołom danych tworzenie niezawodnych, testowalnych przekształceń w rdzeniu potoków analitycznych.
W połączeniu z platformą Apache Airflow funkcje przekształcania dbt są ulepszane przez funkcje planowania, orkiestracji i zarządzania zadaniami firmy Airflow. To połączone podejście, wykorzystując wiedzę na temat transformacji dbt wraz z zarządzaniem przepływem pracy firmy Airflow, zapewnia wydajne i niezawodne potoki danych, co ostatecznie prowadzi do szybszych i bardziej szczegółowych decyzji opartych na danych.
W tym samouczku pokazano, jak utworzyć grupę DAG platformy Apache Airflow, która używa bazy danych do przekształcania danych przechowywanych w magazynie danych usługi Microsoft Fabric.
Wymagania wstępne
Aby rozpocząć pracę, należy spełnić następujące wymagania wstępne:
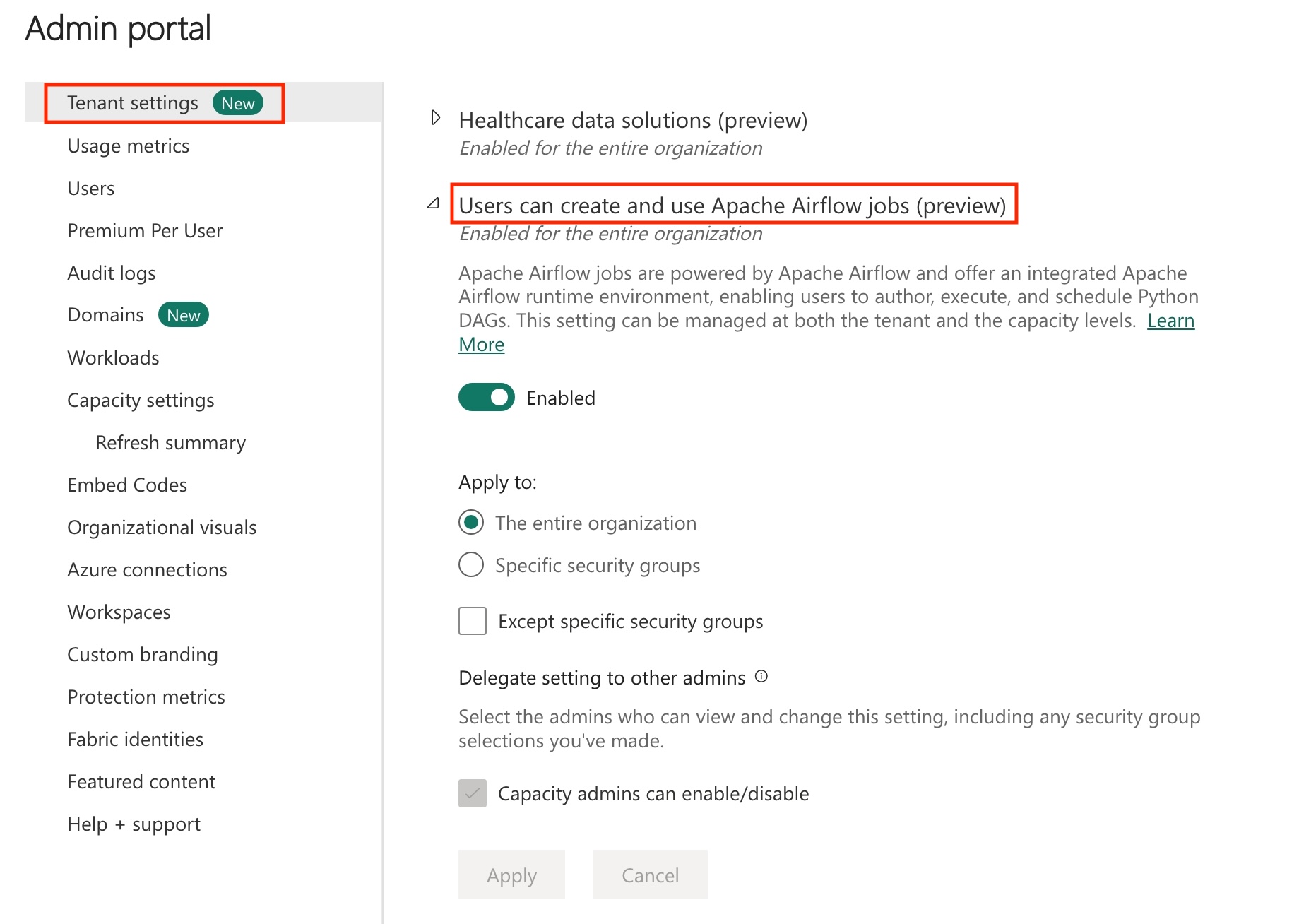
Włącz zadanie platformy Apache Airflow w dzierżawie.
Uwaga
Ponieważ zadanie platformy Apache Airflow jest w wersji zapoznawczej, należy włączyć je za pośrednictwem administratora dzierżawy. Jeśli widzisz już zadanie platformy Apache Airflow, administrator dzierżawy mógł go już włączyć.
Przejdź do pozycji Portal administracyjny —> Ustawienia dzierżawy —> w obszarze Microsoft Fabric —> rozwiń sekcję "Użytkownicy mogą tworzyć zadania platformy Apache Airflow (wersja zapoznawcza)".
Wybierz Zastosuj.
Utwórz jednostkę usługi. Dodaj jednostkę usługi jako element
Contributorw obszarze roboczym, w którym tworzysz magazyn danych.Jeśli go nie masz, utwórz magazyn sieci szkieletowej. Pozyskiwanie przykładowych danych do magazynu przy użyciu potoku danych. Na potrzeby tego samouczka użyjemy przykładu NYC Taxi-Green .

Przekształcanie danych przechowywanych w magazynie sieci szkieletowej przy użyciu bazy danych dbt
W tej sekcji przedstawiono następujące kroki:
- Określ wymagania.
- Utwórz projekt dbt w magazynie zarządzanym sieci szkieletowej udostępnionym przez zadanie Apache Airflow.
- Tworzenie grupy DAG systemu Apache Airflow w celu organizowania zadań dbt
Określanie wymagań
Utwórz plik requirements.txt w folderze dags . Dodaj następujące pakiety jako wymagania dotyczące platformy Apache Airflow.
astronom-cosmos: Ten pakiet służy do uruchamiania podstawowych projektów dbt jako dags apache Airflow i grup zadań.
dbt-fabric: ten pakiet służy do tworzenia projektu dbt, który następnie można wdrożyć w magazynie danych sieci szkieletowej
astronomer-cosmos==1.0.3 dbt-fabric==1.5.0
Utwórz projekt dbt w magazynie zarządzanym sieci szkieletowej udostępnionym przez zadanie Apache Airflow.
W tej sekcji utworzymy przykładowy projekt dbt w zadaniu platformy Apache Airflow dla zestawu danych
nyc_taxi_greenz następującą strukturą katalogu.dags |-- my_cosmos_dag.py |-- nyc_taxi_green | |-- profiles.yml | |-- dbt_project.yml | |-- models | | |-- nyc_trip_count.sql | |-- targetUtwórz folder o nazwie
nyc_taxi_greenw folderzedagsz plikiemprofiles.yml. Ten folder zawiera wszystkie pliki wymagane dla projektu dbt.
Skopiuj następującą zawartość do pliku
profiles.yml. Ten plik konfiguracji zawiera szczegóły połączenia bazy danych i profile używane przez bazę danych dbt. Zaktualizuj wartości symboli zastępczych i zapisz plik.config: partial_parse: true nyc_taxi_green: target: fabric-dev outputs: fabric-dev: type: fabric driver: "ODBC Driver 18 for SQL Server" server: <sql connection string of your data warehouse> port: 1433 database: "<name of the database>" schema: dbo threads: 4 authentication: ServicePrincipal tenant_id: <Tenant ID of your service principal> client_id: <Client ID of your service principal> client_secret: <Client Secret of your service principal>dbt_project.ymlUtwórz plik i skopiuj następującą zawartość. Ten plik określa konfigurację na poziomie projektu.name: "nyc_taxi_green" config-version: 2 version: "0.1" profile: "nyc_taxi_green" model-paths: ["models"] seed-paths: ["seeds"] test-paths: ["tests"] analysis-paths: ["analysis"] macro-paths: ["macros"] target-path: "target" clean-targets: - "target" - "dbt_modules" - "logs" require-dbt-version: [">=1.0.0", "<2.0.0"] models: nyc_taxi_green: materialized: tablemodelsUtwórz folder w folderzenyc_taxi_green. Na potrzeby tego samouczka utworzymy przykładowy model w pliku o nazwienyc_trip_count.sql, który tworzy tabelę zawierającą liczbę podróży dziennie na dostawcę. Skopiuj następującą zawartość w pliku.with new_york_taxis as ( select * from nyctlc ), final as ( SELECT vendorID, CAST(lpepPickupDatetime AS DATE) AS trip_date, COUNT(*) AS trip_count FROM [contoso-data-warehouse].[dbo].[nyctlc] GROUP BY vendorID, CAST(lpepPickupDatetime AS DATE) ORDER BY vendorID, trip_date; ) select * from final


Tworzenie grupy DAG systemu Apache Airflow w celu organizowania zadań dbt
Utwórz plik o nazwie
my_cosmos_dag.pywdagsfolderze i wklej w nim następującą zawartość.import os from pathlib import Path from datetime import datetime from cosmos import DbtDag, ProjectConfig, ProfileConfig, ExecutionConfig DEFAULT_DBT_ROOT_PATH = Path(__file__).parent.parent / "dags" / "nyc_taxi_green" DBT_ROOT_PATH = Path(os.getenv("DBT_ROOT_PATH", DEFAULT_DBT_ROOT_PATH)) profile_config = ProfileConfig( profile_name="nyc_taxi_green", target_name="fabric-dev", profiles_yml_filepath=DBT_ROOT_PATH / "profiles.yml", ) dbt_fabric_dag = DbtDag( project_config=ProjectConfig(DBT_ROOT_PATH,), operator_args={"install_deps": True}, profile_config=profile_config, schedule_interval="@daily", start_date=datetime(2023, 9, 10), catchup=False, dag_id="dbt_fabric_dag", )
Uruchamianie grupy DAG
Uruchom grupę DAG w ramach zadania przepływu powietrza apache.
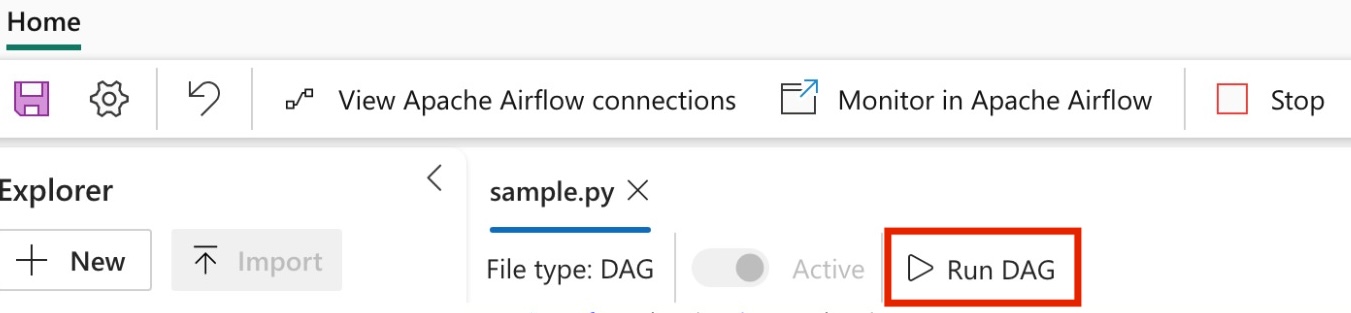
Aby wyświetlić plik dag załadowany w interfejsie użytkownika platformy Apache Airflow, kliknij pozycję
Monitor in Apache Airflow.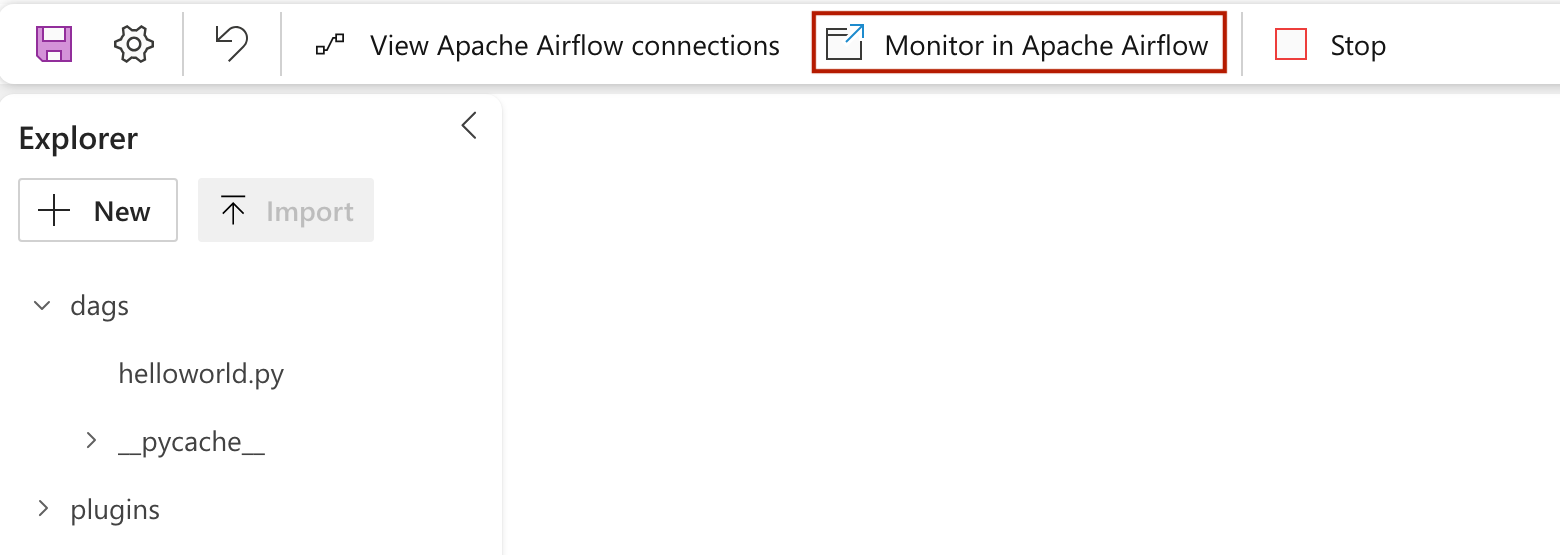



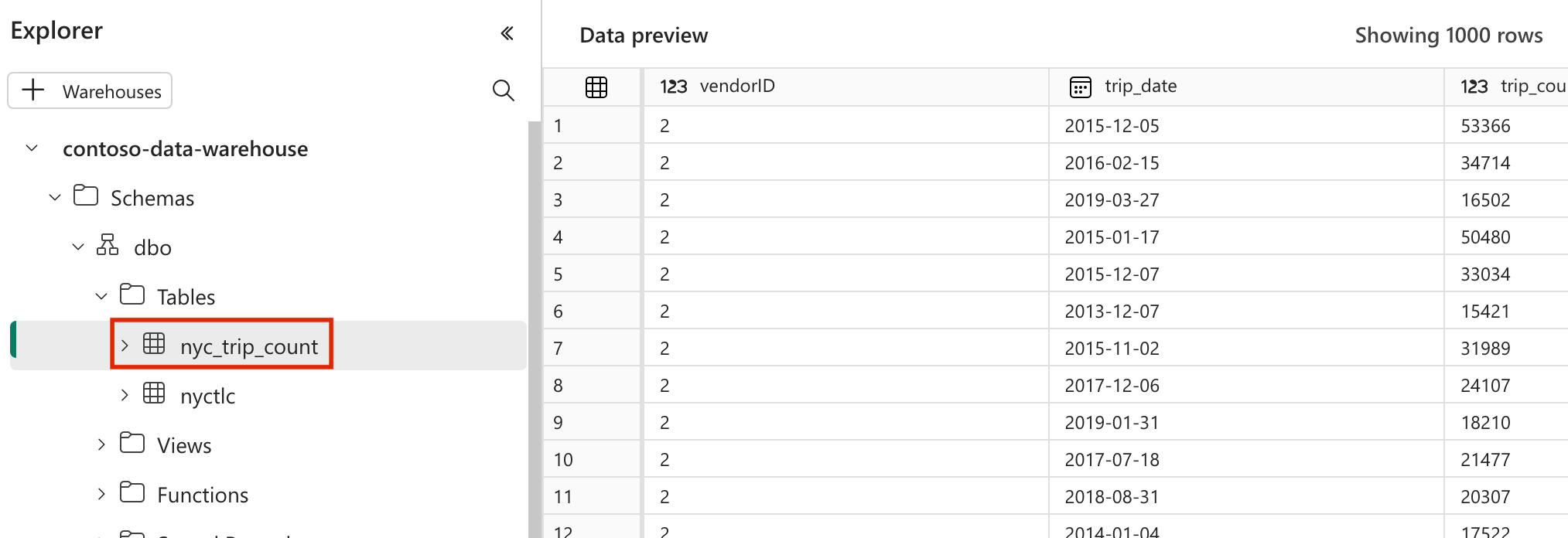
Weryfikowanie danych
- Po pomyślnym uruchomieniu, aby zweryfikować dane, możesz zobaczyć nową tabelę o nazwie "nyc_trip_count.sql" utworzoną w magazynie danych usługi Fabric.