Migracja: dedykowane pule SQL usługi Azure Synapse Analytics do sieci szkieletowej
Dotyczy:✅ Magazyn w usłudze Microsoft Fabric
W tym artykule szczegółowo opisano strategię, zagadnienia i metody migracji magazynowania danych w dedykowanych pulach SQL usługi Azure Synapse Analytics do usługi Microsoft Fabric Warehouse.
Wprowadzenie do migracji
W miarę jak firma Microsoft wprowadziła usługę Microsoft Fabric, kompleksowe rozwiązanie do analizy SaaS dla przedsiębiorstw, które oferuje kompleksowy pakiet usług, w tym usług Data Factory, inżynierowie danych, Magazyn danych, Nauka o danych, analizy w czasie rzeczywistym i usługi Power BI.
Ten artykuł koncentruje się na opcjach migracji schematu (DDL), migracji kodu bazy danych (DML) i migracji danych. Firma Microsoft oferuje kilka opcji. W tym miejscu szczegółowo omawiamy każdą opcję i udostępniamy wskazówki dotyczące tych opcji, które należy wziąć pod uwagę w danym scenariuszu. W tym artykule użyto testu porównawczego dla branży TPC-DS do celów ilustracyjnych i testów wydajnościowych. Rzeczywisty wynik może się różnić w zależności od wielu czynników, takich jak typ danych, typy danych, szerokość tabel, opóźnienie źródła danych itp.
Przygotowanie do migracji
Starannie zaplanuj projekt migracji przed rozpoczęciem pracy i upewnij się, że schemat, kod i dane są zgodne z usługą Fabric Warehouse. Istnieją pewne ograniczenia , które należy wziąć pod uwagę. Kwantyfikują pracę refaktoryzacji niezgodnych elementów, a także wszelkie inne zasoby potrzebne przed dostarczeniem migracji.
Innym kluczowym celem planowania jest dostosowanie projektu w celu zapewnienia, że rozwiązanie w pełni korzysta z wysokiej wydajności zapytań, którą ma zapewnić magazyn sieci szkieletowej. Projektowanie magazynów danych na potrzeby skalowania wprowadza unikatowe wzorce projektowe, więc tradycyjne podejścia nie zawsze są najlepsze. Zapoznaj się z wytycznymi dotyczącymi wydajności magazynu sieci szkieletowej, ponieważ mimo że niektóre korekty projektu można wprowadzić po migracji, wprowadzanie zmian we wcześniejszej części procesu pozwoli zaoszczędzić czas i nakład pracy. Migracja z jednej technologii/środowiska do innego jest zawsze dużym nakładem pracy.
Poniższy diagram przedstawia listę głównych filarów cyklu życia migracji składających się z filarów Ocena i ocena, Planowanie i projektowanie, Migrowanie, Monitorowanie, Monitorowanie i zarządzanie, Optymalizowanie i modernizacja ze skojarzonymi zadaniami w każdym filarze w celu zaplanowania i przygotowania do bezproblemowej migracji.

Element Runbook na potrzeby migracji
Rozważ następujące działania jako element runbook planowania migracji z dedykowanych pul SQL usługi Synapse do usługi Fabric Warehouse.
-
Ocena i ocena
- Identyfikowanie celów i motywacji. Ustanów jasne żądane wyniki.
- Odnajdywanie, ocenianie i punkt odniesienia istniejącej architektury.
- Identyfikowanie kluczowych uczestników projektu i sponsorów.
- Zdefiniuj zakres migrowanych elementów.
- Rozpocznij od małych i prostych, przygotuj się do wielu małych migracji.
- Rozpocznij monitorowanie i dokumentowanie wszystkich etapów procesu.
- Tworzenie spisu danych i procesów migracji.
- Zdefiniuj zmiany modelu danych (jeśli istnieją).
- Skonfiguruj obszar roboczy sieci szkieletowej.
- Jaki jest twój zestaw umiejętności/preferencje?
- Automatyzuj wszędzie tam, gdzie to możliwe.
- Użyj wbudowanych narzędzi i funkcji platformy Azure, aby zmniejszyć nakład pracy nad migracją.
- Szkolenie pracowników na początku nowej platformy.
- Zidentyfikuj potrzeby i zasoby szkoleniowe, w tym microsoft Learn.
-
Planowanie i projektowanie
- Zdefiniuj żądaną architekturę.
- Wybierz metodę /narzędzia migracji , aby wykonać następujące zadania:
- Wyodrębnianie danych ze źródła.
- Konwersja schematu (DDL), w tym metadane dla tabel i widoków
- Pozyskiwanie danych, w tym dane historyczne.
- W razie potrzeby ponownie zaprojektuj model danych przy użyciu nowej wydajności i skalowalności platformy.
- Migracja kodu bazy danych (DML).
- Migrowanie lub refaktoryzacja procedur składowanych i procesów biznesowych.
- Spis i wyodrębnij funkcje zabezpieczeń i uprawnienia obiektu ze źródła.
- Zaprojektuj i zaplanuj zastąpienie/zmodyfikowanie istniejących procesów ETL/ELT na potrzeby obciążenia przyrostowego.
- Tworzenie równoległych procesów ETL/ELT w nowym środowisku.
- Przygotuj szczegółowy plan migracji.
- Zamapuj bieżący stan na nowy żądany stan.
-
Migrate (Migracja)
- Wykonaj schemat, dane, migrację kodu.
- Wyodrębnianie danych ze źródła.
- Konwersja schematu (DDL)
- Pozyskiwanie danych
- Migracja kodu bazy danych (DML).
- W razie potrzeby przeprowadź tymczasowe skalowanie dedykowanych zasobów puli SQL w górę, aby przyspieszyć migrację.
- Stosowanie zabezpieczeń i uprawnień.
- Migrowanie istniejących procesów ETL/ELT na potrzeby obciążenia przyrostowego.
- Migrowanie lub refaktoryzacja procesów ładowania przyrostowego ETL/ELT.
- Testowanie i porównywanie równoległych procesów ładowania przyrostowego.
- Dostosuj szczegółowy plan migracji zgodnie z potrzebami.
- Wykonaj schemat, dane, migrację kodu.
-
Monitorowanie i zarządzanie
- Uruchom równolegle porównanie ze środowiskiem źródłowym.
- Testowanie aplikacji, platform analizy biznesowej i narzędzi do wykonywania zapytań.
- Testowanie porównawcze i optymalizowanie wydajności zapytań.
- Monitorowanie kosztów, zabezpieczeń i wydajności oraz zarządzanie nimi.
- Test porównawczy i ocena ładu.
- Uruchom równolegle porównanie ze środowiskiem źródłowym.
-
Optymalizowanie i modernizowanie
- Gdy firma jest wygodna, przenoszenie aplikacji i podstawowych platform raportowania do sieci szkieletowej.
- Skalowanie zasobów w górę/w dół w miarę przenoszenia obciążeń z usługi Azure Synapse Analytics do usługi Microsoft Fabric.
- Utwórz powtarzalny szablon na podstawie doświadczenia zdobytego na potrzeby przyszłych migracji. Iteracji.
- Identyfikowanie możliwości optymalizacji kosztów, zabezpieczeń, skalowalności i doskonałości operacyjnej
- Identyfikowanie możliwości modernizacji majątku danych przy użyciu najnowszych funkcji sieci Szkieletowej.
- Gdy firma jest wygodna, przenoszenie aplikacji i podstawowych platform raportowania do sieci szkieletowej.
"Lift and shift" lub modernizacja?
Ogólnie rzecz biorąc, istnieją dwa typy scenariuszy migracji, niezależnie od celu i zakresu planowanej migracji: lift and shift as-is lub podejścia etapowego, które obejmuje zmiany architektury i kodu.
Migrowanie metodą „lift-and-shift”
Podczas migracji metodą "lift and shift" istniejący model danych jest migrowany z niewielkimi zmianami w nowym magazynie sieci szkieletowej. Takie podejście minimalizuje ryzyko i czas migracji, zmniejszając nowe prace potrzebne do realizacji korzyści związanych z migracją.
Migracja metodą "lift and shift" jest dobrym rozwiązaniem w następujących scenariuszach:
- Masz istniejące środowisko z małą liczbą składnic danych do migracji.
- Masz istniejące środowisko z danymi, które są już w dobrze zaprojektowanym schemacie gwiazdy lub płatka śniegu.
- Czas i presja kosztów jest niewystarczająca, aby przejść do magazynu sieci szkieletowej.
Podsumowując, to podejście dobrze sprawdza się w przypadku obciążeń zoptymalizowanych pod kątem bieżącego środowiska dedykowanych pul SQL usługi Synapse i dlatego nie wymaga istotnych zmian w usłudze Fabric.
Modernizuj w podejściu etapowym ze zmianami architektury
Jeśli starszy magazyn danych ewoluował przez długi czas, może być konieczne ponowne zaprojektowanie go w celu zachowania wymaganych poziomów wydajności.
Możesz również przeprojektować architekturę, aby skorzystać z nowych aparatów i funkcji dostępnych w obszarze roboczym sieci szkieletowej.
Różnice projektowe: dedykowane pule SQL usługi Synapse i magazyn sieci szkieletowej
Rozważ następujące różnice w magazynowaniu danych usługi Azure Synapse i Microsoft Fabric, porównując dedykowane pule SQL z magazynem sieci szkieletowej.
Zagadnienia dotyczące tabeli
Podczas migrowania tabel między różnymi środowiskami zazwyczaj tylko nieprzetworzone dane i metadane są migrowane fizycznie. Inne elementy bazy danych z systemu źródłowego, takie jak indeksy, zwykle nie są migrowane, ponieważ mogą być niepotrzebne lub zaimplementowane inaczej w nowym środowisku.
Optymalizacje wydajności w środowisku źródłowym, takie jak indeksy, wskazują, gdzie można dodać optymalizację wydajności w nowym środowisku, ale teraz sieć szkieletowa automatycznie zajmuje się tym automatycznie.
Zagadnienia dotyczące języka T-SQL
Istnieje kilka różnic składni języka manipulowania danymi (DML), o których należy pamiętać. Zapoznaj się z obszarem powierzchni języka T-SQL w usłudze Microsoft Fabric. Rozważ również ocenę kodu podczas wybierania metod migracji dla kodu bazy danych (DML).
W zależności od różnic parzystości w czasie migracji może być konieczne ponowne zapisywanie części kodu DML języka T-SQL.
Różnice mapowania typów danych
Istnieje kilka różnic typów danych w magazynie sieci szkieletowej. Aby uzyskać więcej informacji, zobacz Typy danych w usłudze Microsoft Fabric.
Poniższa tabela zawiera mapowanie obsługiwanych typów danych z dedykowanych pul SQL usługi Synapse do usługi Fabric Warehouse.
| Dedykowane pule SQL usługi Synapse | Magazyn sieci szkieletowej |
|---|---|
| pieniędzy | dziesiętne (19,4) |
| smallmoney | dziesiętne (10,4) |
| smalldatetime | datetime2 |
| datetime | datetime2 |
| nchar | char |
| nvarchar | varchar |
| tinyint | smallint |
| dane binarne | varbinary |
| datetimeoffset* | datetime2 |
* Data/godzina2 nie przechowuje dodatkowych informacji o przesunięciach strefy czasowej, w których są przechowywane. Ponieważ typ danych datetimeoffset nie jest obecnie obsługiwany w magazynie sieci szkieletowej, dane przesunięcia strefy czasowej muszą zostać wyodrębnione do oddzielnej kolumny.
Metody migracji schematu, kodu i danych
Przejrzyj i zidentyfikuj, które z tych opcji pasują do twojego scenariusza, zestawów umiejętności personelu i właściwości danych. Wybrane opcje zależą od środowiska, preferencji i korzyści wynikających z każdego z narzędzi. Naszym celem jest kontynuowanie opracowywania narzędzi migracji, które zmniejszają problemy i ręczną interwencję, aby zapewnić bezproblemowe środowisko migracji.
Ta tabela zawiera podsumowanie informacji dotyczących schematu danych (DDL), kodu bazy danych (DML) i metod migracji danych. Rozwijamy dalej każdy scenariusz w dalszej części tego artykułu, połączony w kolumnie Opcja .
| Numer opcji | Opcja | Wyniki działania | Umiejętność/preferencje | Scenariusz |
|---|---|---|---|---|
| 1 | Data Factory | Konwersja schematu (DDL) Wyodrębnianie danych Pozyskiwanie danych |
ADF/Potok | Uproszczone wszystkie w jednym schemacie (DDL) i migracji danych. Zalecane w przypadku tabel wymiarów. |
| 2 | Usługa Data Factory z partycją | Konwersja schematu (DDL) Wyodrębnianie danych Pozyskiwanie danych |
ADF/Potok | Użycie opcji partycjonowania w celu zwiększenia równoległości odczytu/zapisu zapewniającej 10-krotną przepływność a opcję 1 zalecaną dla tabel faktów. |
| 3 | Usługa Data Factory z przyspieszonym kodem | Konwersja schematu (DDL) | ADF/Potok | Najpierw przekonwertuj i zmigruj schemat (DDL), a następnie użyj instrukcji CETAS, aby wyodrębnić i skopiować/fabrykę danych w celu uzyskania optymalnej ogólnej wydajności pozyskiwania. |
| 100 | Procedury składowane — przyspieszony kod | Konwersja schematu (DDL) Wyodrębnianie danych Ocena kodu |
T-SQL | Użytkownik SQL korzystający ze środowiska IDE z bardziej szczegółową kontrolą nad zadaniami, nad którymi chcą pracować. Użyj funkcji COPY/Data Factory do pozyskiwania danych. |
| 5 | Rozszerzenie projektu usługi SQL Database dla programu Azure Data Studio | Konwersja schematu (DDL) Wyodrębnianie danych Ocena kodu |
Projekt SQL | Projekt usługi SQL Database na potrzeby wdrożenia z integracją opcji 4. Pozyskiwanie danych za pomocą funkcji COPY lub Data Factory. |
| 6 | UTWÓRZ TABELĘ ZEWNĘTRZNĄ JAKO WYBIERZ (CETAS) | Wyodrębnianie danych | T-SQL | Ekonomiczne i wysokiej wydajności wyodrębnianie danych do usługi Azure Data Lake Storage (ADLS) Gen2. Użyj funkcji COPY/Data Factory do pozyskiwania danych. |
| 7 | Migrowanie przy użyciu bazy danych dbt | Konwersja schematu (DDL) Konwersja kodu bazy danych (DML) |
dbt | Istniejący użytkownicy dbt mogą użyć karty dbt Fabric do konwersji ich DDL i DML. Następnie należy przeprowadzić migrację danych przy użyciu innych opcji w tej tabeli. |
Wybieranie obciążenia na potrzeby migracji początkowej
Podczas wybierania miejsca rozpoczęcia pracy z dedykowaną pulą SQL usługi Synapse w projekcie migracji usługi Fabric Warehouse wybierz obszar obciążenia, w którym można wykonać następujące działania:
- Udowodnij rentowność migracji do magazynu sieci szkieletowej, szybko zapewniając korzyści wynikające z nowego środowiska. Rozpocznij od małych i prostych, przygotuj się do wielu małych migracji.
- Zezwól pracownikom technicznym na uzyskanie odpowiedniego doświadczenia z procesami i narzędziami używanymi podczas migracji do innych obszarów.
- Utwórz szablon do dalszych migracji specyficznych dla źródłowego środowiska usługi Synapse oraz narzędzi i procesów, które mają być pomocne.
Napiwek
Utwórz spis obiektów, które muszą zostać zmigrowane, i udokumentować proces migracji od początku do końca, aby można je było powtórzyć dla innych dedykowanych pul SQL lub obciążeń.
Ilość migrowanych danych w początkowej migracji powinna być wystarczająco duża, aby zademonstrować możliwości i zalety środowiska magazynu sieci szkieletowej, ale nie zbyt duże, aby szybko zademonstrować wartość. Typowy jest rozmiar zakresu 1–10 terabajtów.
Migracja za pomocą usługi Fabric Data Factory
W tej sekcji omówiono opcje korzystania z usługi Data Factory dla osoby o niskim kodzie/braku kodu, które znają usługę Azure Data Factory i potok synapse. Ta opcja przeciągania i upuszczania interfejsu użytkownika zapewnia prosty krok konwersji DDL i migracji danych.
Usługa Fabric Data Factory może wykonywać następujące zadania:
- Przekonwertuj schemat (DDL) na składnię magazynu sieci szkieletowej.
- Utwórz schemat (DDL) w magazynie sieci szkieletowej.
- Migrowanie danych do magazynu sieci szkieletowej.
Sposób 1. Schemat/migracja danych — działanie kopiowania kreatora kopiowania i forEach
Ta metoda używa asystenta kopiowania usługi Data Factory do nawiązywania połączenia ze źródłową dedykowaną pulą SQL, konwertowania dedykowanej składni DDL puli SQL na sieć szkieletową i kopiowania danych do magazynu sieci szkieletowej. Możesz wybrać co najmniej 1 tabelę docelową (dla zestawu danych TPC-DS istnieje 22 tabele). Generuje on pętlę ForEach za pośrednictwem listy tabel wybranych w interfejsie użytkownika i zduplikowania 22 równoległych wątków działania kopiowania.
- 22 Zapytania SELECT (po jednym dla każdej wybranej tabeli) zostały wygenerowane i wykonane w dedykowanej puli SQL.
- Upewnij się, że masz odpowiednią klasę DWU i klasę zasobów, aby umożliwić wykonywanie zapytań wygenerowanych. W tym przypadku potrzebujesz co najmniej DWU1000,
staticrc10aby umożliwić maksymalnie 32 zapytania do obsługi 22 przesłanych zapytań. - Usługa Data Factory bezpośrednio kopiuje dane z dedykowanej puli SQL do usługi Fabric Warehouse wymaga przemieszczania. Proces pozyskiwania składał się z dwóch faz.
- Pierwsza faza składa się z wyodrębniania danych z dedykowanej puli SQL do usługi ADLS i jest nazywana przemieszczaniem.
- Druga faza polega na pozyskiwaniu danych z przemieszczania do magazynu sieci szkieletowej. Większość czasu pozyskiwania danych jest w fazie przejściowej. Podsumowując, przemieszczanie ma ogromny wpływ na wydajność pozyskiwania.
Zalecane użycie
Użycie Kreatora kopiowania do wygenerowania elementu ForEach zapewnia prosty interfejs użytkownika do konwertowania języka DDL i pozyskiwania wybranych tabel z dedykowanej puli SQL do usługi Fabric Warehouse w jednym kroku.
Jednak nie jest to optymalne w przypadku ogólnej przepływności. Wymaganie użycia przemieszczania, konieczność równoległego przetwarzania odczytu i zapisu dla kroku "Source to Stage" to główne czynniki opóźnienia wydajności. Zaleca się użycie tej opcji tylko w przypadku tabel wymiarów.
Sposób 2. Migracja danych/DDL — potok danych przy użyciu opcji partycji
Aby rozwiązać problem z zwiększeniem przepływności ładowania większych tabel faktów przy użyciu potoku danych sieci szkieletowej, zaleca się użycie działania kopiowania dla każdej tabeli faktów z opcją partycji. Zapewnia to najlepszą wydajność działanie Kopiuj.
Istnieje możliwość użycia partycjonowania fizycznego tabeli źródłowej, jeśli jest dostępna. Jeśli tabela nie ma partycjonowania fizycznego, należy określić kolumnę partycji i podać wartości minimalne/maksymalne, aby używać partycjonowania dynamicznego. Na poniższym zrzucie ekranu opcje źródła potoku ws_sold_date_sk
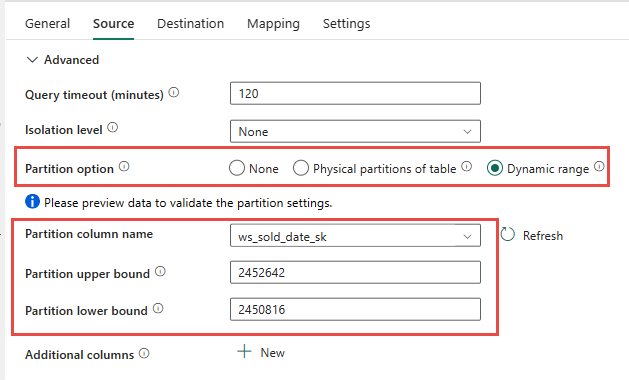
Podczas korzystania z partycji można zwiększyć przepływność w fazie przejściowej, należy wziąć pod uwagę odpowiednie korekty:
- W zależności od zakresu partycji może on potencjalnie używać wszystkich miejsc współbieżności, ponieważ może generować ponad 128 zapytań w dedykowanej puli SQL.
- Wymagane jest skalowanie do minimum DWU6000, aby umożliwić wykonywanie wszystkich zapytań.
- Na przykład w przypadku tabeli TPC-DS
web_salesdo dedykowanej puli SQL przesłano 163 zapytania. W DWU6000 wykonano 128 zapytań, podczas gdy kolejkowano 35 zapytań. - Partycja dynamiczna automatycznie wybiera partycję zakresu. W tym przypadku 11-dniowy zakres dla każdego zapytania SELECT przesłanego do dedykowanej puli SQL. Na przykład: .
WHERE [ws_sold_date_sk] > '2451069' AND [ws_sold_date_sk] <= '2451080') ... WHERE [ws_sold_date_sk] > '2451333' AND [ws_sold_date_sk] <= '2451344')
Zalecane użycie
W przypadku tabel faktów zalecamy użycie usługi Data Factory z opcją partycjonowania w celu zwiększenia przepływności.
Jednak zwiększone operacje odczytu równoległego wymagają dedykowanej puli SQL do skalowania do wyższych jednostek DWU, aby umożliwić wykonywanie zapytań wyodrębniania. Korzystając z partycjonowania, szybkość jest większa niż 10 razy większa niż opcja partycji. Możesz zwiększyć liczbę jednostek DWU, aby uzyskać dodatkową przepływność za pośrednictwem zasobów obliczeniowych, ale dedykowana pula SQL ma maksymalnie 128 aktywnych zapytań dozwolonych.
Uwaga
Aby uzyskać więcej informacji na temat mapowania jednostek DWU usługi Synapse na sieć szkieletową, zobacz Blog: Mapowanie dedykowanych pul SQL usługi Azure Synapse na zasoby obliczeniowe magazynu danych usługi Fabric.
Sposób 3. Migracja DDL — działanie kopiowania kreatora kopiowania forEach
Dwie poprzednie opcje to doskonałe opcje migracji danych dla mniejszych baz danych. Jeśli jednak potrzebujesz wyższej przepływności, zalecamy użycie alternatywnej opcji:
- Wyodrębnij dane z dedykowanej puli SQL do usługi ADLS, co zmniejsza obciążenie związane z wydajnością etapu.
- Użyj usługi Data Factory lub polecenia COPY, aby pozyskać dane do magazynu sieci szkieletowej.
Zalecane użycie
Możesz nadal używać usługi Data Factory do konwertowania schematu (DDL). Za pomocą Kreatora kopiowania możesz wybrać określoną tabelę lub Wszystkie tabele. Zgodnie z projektem program migruje schemat i dane w jednym kroku, wyodrębniając schemat bez żadnych wierszy przy użyciu warunku TOP 0 false w instrukcji zapytania.
Poniższy przykładowy kod obejmuje migrację schematu (DDL) z usługą Data Factory.
Przykład kodu: migracja schematu (DDL) za pomocą usługi Data Factory
Za pomocą potoków danych sieci szkieletowej można łatwo przeprowadzić migrację za pośrednictwem języka DDL (schematów) dla obiektów tabeli z dowolnej źródłowej bazy danych Azure SQL Database lub dedykowanej puli SQL. Ten potok danych migruje schemat (DDL) dla źródłowych tabel dedykowanej puli SQL do usługi Fabric Warehouse.
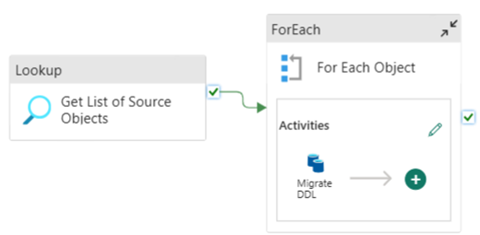
Projekt potoku: parametry
Ten potok danych akceptuje parametr SchemaName, który umożliwia określenie schematów, które mają być migrowane. Schemat dbo jest domyślny.
W polu Wartość domyślna wprowadź rozdzielaną przecinkami listę schematu tabeli wskazującą, które schematy mają być migrowane: w celu udostępnienia dwóch schematów i 'dbo','tpch'dbotpch.
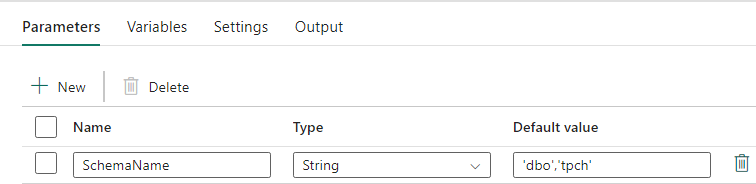
Projekt potoku: działanie lookup
Utwórz działanie odnośnika i ustaw pozycję Połączenie, aby wskazywało źródłową bazę danych.
Na karcie Ustawienia:
Ustaw typ magazynu danych na Wartość Zewnętrzna.
Połączenie to dedykowana pula SQL usługi Azure Synapse. Typ połączenia to Azure Synapse Analytics.
Użyj zapytania jest ustawiona na Zapytanie.
Pole Zapytanie musi zostać skompilowane przy użyciu wyrażenia dynamicznego, co umożliwia użycie parametru SchemaName w zapytaniu zwracającym listę docelowych tabel źródłowych. Wybierz pozycję Zapytanie , a następnie wybierz pozycję Dodaj zawartość dynamiczną.
To wyrażenie w działaniu LookUp generuje instrukcję SQL w celu wykonywania zapytań względem widoków systemowych w celu pobrania listy schematów i tabel. Odwołuje się do parametru SchemaName, aby umożliwić filtrowanie schematów SQL. Dane wyjściowe są tablicą schematu SQL i tabel, które będą używane jako dane wejściowe do działania ForEach.
Użyj poniższego kodu, aby zwrócić listę wszystkich tabel użytkowników z nazwą schematu.
@concat(' SELECT s.name AS SchemaName, t.name AS TableName FROM sys.tables AS t INNER JOIN sys.schemas AS s ON t.type = ''U'' AND s.schema_id = t.schema_id AND s.name in (',coalesce(pipeline().parameters.SchemaName, 'dbo'),') ')
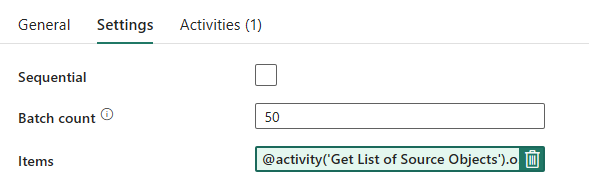
Projekt potoku: Pętla ForEach
W przypadku pętli ForEach skonfiguruj następujące opcje na karcie Ustawienia :
- Wyłącz sekwencyjne zezwalanie na współbieżne uruchamianie wielu iteracji.
- Ustaw wartość Liczba partii na
50, ograniczając maksymalną liczbę współbieżnych iteracji. - Pole Elementy musi używać zawartości dynamicznej, aby odwoływać się do danych wyjściowych działania LookUp. Użyj następującego fragmentu kodu:
@activity('Get List of Source Objects').output.value
Projekt potoku: działanie kopiowania wewnątrz pętli ForEach
Wewnątrz działania ForEach dodaj działanie kopiowania. Ta metoda używa języka wyrażeń dynamicznych w potokach danych, aby skompilować SELECT TOP 0 * FROM <TABLE> obiekt w celu przeprowadzenia migracji tylko schematu bez danych do magazynu sieci szkieletowej.
Na karcie Źródło:
- Ustaw typ magazynu danych na Wartość Zewnętrzna.
- Połączenie to dedykowana pula SQL usługi Azure Synapse. Typ połączenia to Azure Synapse Analytics.
- Ustaw opcję Użyj zapytania na Zapytanie.
-
W polu Zapytanie wklej zapytanie zawartości dynamicznej i użyj tego wyrażenia, które zwróci zero wierszy, tylko schemat tabeli:
@concat('SELECT TOP 0 * FROM ',item().SchemaName,'.',item().TableName)

Na karcie Miejsce docelowe:
- Ustaw typ magazynu danych na Obszar roboczy.
- Typ magazynu danych obszaru roboczego to Data Warehouse, a magazyn danych jest ustawiony na magazyn sieci szkieletowej.
- Schemat i nazwa tabeli docelowej są definiowane przy użyciu zawartości dynamicznej.
- Schemat odwołuje się do pola bieżącej iteracji, SchemaName z fragmentem kodu:
@item().SchemaName - Tabela odwołuje się do tabeli TableName z fragmentem kodu:
@item().TableName
- Schemat odwołuje się do pola bieżącej iteracji, SchemaName z fragmentem kodu:

Projekt potoku: ujście
W polu Ujście wskaż magazyn i odwołaj się do nazwy schematu źródłowego i tabeli.
Po uruchomieniu tego potoku zobaczysz, że magazyn danych zostanie wypełniony z każdą tabelą w źródle przy użyciu odpowiedniego schematu.
Migracja przy użyciu procedur składowanych w dedykowanej puli SQL usługi Synapse
Ta opcja używa procedur składowanych do przeprowadzenia migracji sieci szkieletowej.
Przykłady kodu można pobrać w witrynie microsoft/fabric-migration on GitHub.com. Ten kod jest udostępniany jako open source, dlatego możesz współtworzyć współpracę i pomóc społeczności.
Jakie procedury składowane migracji mogą wykonywać:
- Przekonwertuj schemat (DDL) na składnię magazynu sieci szkieletowej.
- Utwórz schemat (DDL) w magazynie sieci szkieletowej.
- Wyodrębnianie danych z dedykowanej puli SQL usługi Synapse do usługi ADLS.
- Flagowanie nieobsługiwanej składni sieci szkieletowej dla kodów T-SQL (procedur składowanych, funkcji, widoków).
Zalecane użycie
Jest to świetna opcja dla tych, którzy:
- Znasz język T-SQL.
- Chcesz użyć zintegrowanego środowiska programistycznego, takiego jak SQL Server Management Studio (SSMS).
- Chcesz mieć bardziej szczegółową kontrolę nad zadaniami, nad którymi chcą pracować.
Można wykonać określoną procedurę składowaną dla konwersji schematu (DDL), wyodrębniania danych lub oceny kodu T-SQL.
W przypadku migracji danych należy użyć funkcji COPY INTO lub Data Factory, aby pozyskać dane do magazynu sieci szkieletowej.
Migrowanie przy użyciu projektów bazy danych SQL
Usługa Microsoft Fabric Data Warehouse jest obsługiwana w rozszerzeniu SQL Database Projects dostępnym w usługach Azure Data Studio i Visual Studio Code.
To rozszerzenie jest dostępne w usługach Azure Data Studio i Visual Studio Code. Ta funkcja umożliwia korzystanie z funkcji kontroli źródła, testowania bazy danych i sprawdzania poprawności schematu.
Aby uzyskać więcej informacji na temat kontroli źródła dla magazynów w usłudze Microsoft Fabric, w tym potoków integracji i wdrażania usługi Git, zobacz Kontrola źródła w magazynie.
Zalecane użycie
Jest to świetna opcja dla tych, którzy wolą używać projektu usługi SQL Database do wdrożenia. Ta opcja zasadniczo zintegrowała procedury składowane migracji sieci szkieletowej do projektu usługi SQL Database w celu zapewnienia bezproblemowego środowiska migracji.
Projekt usługi SQL Database może wykonywać następujące czynności:
- Przekonwertuj schemat (DDL) na składnię magazynu sieci szkieletowej.
- Utwórz schemat (DDL) w magazynie sieci szkieletowej.
- Wyodrębnianie danych z dedykowanej puli SQL usługi Synapse do usługi ADLS.
- Flagowanie nieobsługiwanej składni dla kodów T-SQL (procedur składowanych, funkcji, widoków).
W przypadku migracji danych użyjesz polecenia COPY INTO lub Data Factory, aby pozyskać dane do magazynu sieci szkieletowej.
Dodając do możliwości obsługi narzędzia Azure Data Studio dla usługi Microsoft Fabric, zespół CAT usługi Microsoft Fabric udostępnił zestaw skryptów programu PowerShell do obsługi wyodrębniania, tworzenia i wdrażania schematu (DDL) i kodu bazy danych (DML) za pośrednictwem projektu usługi SQL Database. Aby zapoznać się z przewodnikiem po korzystaniu z projektu usługi SQL Database z naszymi przydatnymi skryptami programu PowerShell, zobacz microsoft/fabric-migration on GitHub.com(Microsoft/fabric-migration on GitHub.com).
Aby uzyskać więcej informacji na temat projektów usługi SQL Database, zobacz Getting started with the SQL Database Projects extension (Wprowadzenie do rozszerzenia SQL Database Projects) i Build and Publish a project (Kompilowanie i publikowanie projektu).
Migracja danych za pomocą instrukcji CETAS
Polecenie T-SQL CREATE EXTERNAL TABLE AS SELECT (CETAS) zapewnia najbardziej opłacalną i optymalną metodę wyodrębniania danych z dedykowanych pul SQL usługi Synapse do usługi Azure Data Lake Storage (ADLS) Gen2.
Co może zrobić CETAS:
- Wyodrębnianie danych do usługi ADLS.
- Ta opcja wymaga od użytkowników utworzenia schematu (DDL) w magazynie sieci szkieletowej przed pozyskiwaniem danych. Zapoznaj się z opcjami w tym artykule, aby przeprowadzić migrację schematu (DDL).
Zalety tej opcji to:
- Tylko jedno zapytanie na tabelę jest przesyłane względem źródłowej dedykowanej puli SQL usługi Synapse. Nie będzie to używać wszystkich miejsc współbieżności, więc nie zablokuje współbieżnych operacji ETL/zapytań produkcyjnych klientów.
- Skalowanie do DWU6000 nie jest wymagane, ponieważ dla każdej tabeli jest używane tylko jedno miejsce współbieżności, dzięki czemu klienci mogą używać niższych jednostek DWU.
- Wyodrębnianie jest uruchamiane równolegle we wszystkich węzłach obliczeniowych i jest to klucz do poprawy wydajności.
Zalecane użycie
Użyj instrukcji CETAS, aby wyodrębnić dane do usługi ADLS jako pliki Parquet. Pliki Parquet zapewniają korzyść wydajnego przechowywania danych z kompresją kolumnową, która będzie mniejsza przepustowość, aby przenieść się przez sieć. Ponadto, ponieważ sieć szkieletowa przechowuje dane jako format delta parquet, pozyskiwanie danych będzie 2,5 razy szybsze w porównaniu z formatem pliku tekstowego, ponieważ podczas pozyskiwania nie ma konwersji na obciążenie formatu delta.
Aby zwiększyć przepływność CETAS:
- Dodaj równoległe operacje CETAS, zwiększając użycie miejsc współbieżności, ale zapewniając większą przepływność.
- Skalowanie jednostek DWU w dedykowanej puli SQL usługi Synapse.
Migracja za pośrednictwem bazy danych
W tej sekcji omówimy opcję dbt dla tych klientów, którzy już używają bazy danych dbt w bieżącym dedykowanym środowisku puli SQL usługi Synapse.
Co dbt może zrobić:
- Przekonwertuj schemat (DDL) na składnię magazynu sieci szkieletowej.
- Utwórz schemat (DDL) w magazynie sieci szkieletowej.
- Przekonwertuj kod bazy danych (DML) na składnię sieci szkieletowej.
Platforma dbt generuje DDL i DML (skrypty SQL) na bieżąco z każdym wykonaniem. W przypadku plików modelu wyrażonych w instrukcjach SELECT język DDL/DML można przetłumaczyć natychmiast na dowolną platformę docelową, zmieniając profil (parametry połączenia) i typ karty.
Zalecane użycie
Struktura dbt to podejście oparte na kodzie. Dane muszą być migrowane przy użyciu opcji wymienionych w tym dokumencie, takich jak CETAS lub COPY/Data Factory.
Karta dbt dla usługi Microsoft Fabric Data Warehouse umożliwia migrowanie istniejących projektów dbt przeznaczonych dla różnych platform, takich jak dedykowane pule SQL usługi Synapse, Snowflake, Databricks, Google Big Query lub Amazon Redshift do magazynu sieci szkieletowej z prostą zmianą konfiguracji.
Aby rozpocząć pracę z projektem dbt przeznaczonym dla magazynu sieci szkieletowej, zobacz Samouczek: konfigurowanie bazy danych dbt dla magazynu danych sieci szkieletowej. Ten dokument zawiera również listę opcji przenoszenia między różnymi magazynami/platformami.
Pozyskiwanie danych do magazynu sieci szkieletowej
W celu pozyskiwania danych do magazynu sieci szkieletowej użyj polecenia COPY INTO lub Fabric Data Factory, w zależności od preferencji. Obie metody są zalecanymi i najlepiej wydajnymi opcjami, ponieważ mają równoważną przepływność wydajności, biorąc pod uwagę wymagania wstępne, że pliki są już wyodrębnione do usługi Azure Data Lake Storage (ADLS) Gen2.
Należy pamiętać o kilku czynnikach, aby można było zaprojektować proces pod kątem maksymalnej wydajności:
- W przypadku sieci szkieletowej nie ma żadnej rywalizacji o zasoby podczas jednoczesnego ładowania wielu tabel z usługi ADLS do magazynu sieci szkieletowej. W związku z tym podczas ładowania wątków równoległych nie występuje spadek wydajności. Maksymalna przepływność pozyskiwania będzie ograniczona tylko przez moc obliczeniową pojemności sieci szkieletowej.
- Zarządzanie obciążeniami sieci szkieletowej zapewnia rozdzielenie zasobów przydzielonych do ładowania i wykonywania zapytań. Nie ma rywalizacji o zasoby podczas wykonywania zapytań i ładowania danych w tym samym czasie.