Samouczek: tworzenie, ocenianie i przydzielanie ocen w systemie rekomendacji
Ten samouczek przedstawia pełny przykład przepływu pracy analizy danych usługi Synapse w usłudze Microsoft Fabric. Scenariusz tworzy model rekomendacji dotyczących książek online.
W tym przewodniku omówiono następujące kroki:
- Przekaż dane do magazynu Lakehouse
- Przeprowadzanie eksploracyjnej analizy danych
- Trenowanie modelu i rejestrowanie go za pomocą biblioteki MLflow
- Ładowanie modelu i przewidywanie
Dostępnych jest wiele typów algorytmów rekomendacji. Ten samouczek używa algorytmu faktoryzacji macierzy ALS (Alternating Least Squares). ALS to oparty na modelu algorytm wspólnego filtrowania.

ALS próbuje oszacować macierz ocen R jako produkt dwóch macierzy niższej rangi, U i V. Tutaj R = U * Vt. Zazwyczaj te przybliżenia nazywane są macierzami czynnikowymi .
Algorytm ALS jest iteracyjny. Każda iteracja przechowuje jedną z macierzy współczynników stałą, podczas gdy rozwiązuje drugą przy użyciu metody najmniejszych kwadratów. Następnie utrzymuje nowo rozwiązana macierz współczynników jako stałą podczas rozwiązywania innej macierzy czynników.

Warunki wstępne
Pobierz subskrypcję usługi Microsoft Fabric . Możesz też utworzyć bezpłatne konto wersji próbnej usługi Microsoft Fabric.
Zaloguj się do usługi Microsoft Fabric.
Użyj przełącznika środowiska w lewej dolnej części strony głównej, aby przełączyć się na Fabric.

- W razie potrzeby utwórz lakehouse w usłudze Microsoft Fabric zgodnie z opisem w Tworzenie lakehouse w usłudze Microsoft Fabric.
Śledź w zeszycie
Możesz wybrać jedną z tych opcji, aby śledzić w notesie.
- Otwórz i uruchom wbudowany notes.
- Prześlij swój notatnik z usługi GitHub.
Otwieranie wbudowanego notesu
Przykładowy notes Rekomendacja książki towarzyszy temu samouczkowi.
Aby otworzyć przykładowy notes na potrzeby tego samouczka, postępuj zgodnie z instrukcjami w sekcji Przygotowanie systemu do samouczków z dziedziny nauki o danych.
Przed rozpoczęciem uruchamiania kodu upewnij się, że dołączyć magazyn lakehouse do notesu.
Importuj notatnik z GitHub
Notatnik AIsample - Book Recommendation.ipynb towarzyszy temu samouczkowi.
Aby otworzyć towarzyszący notes na potrzeby tego samouczka, postępuj zgodnie z instrukcjami w Prepare your system for data science tutorials (Przygotowywanie systemu do nauki o danych), aby zaimportować notes do obszaru roboczego.
Jeśli wolisz skopiować i wkleić kod z tej strony, możesz utworzyć nowy notes.
Przed rozpoczęciem uruchamiania kodu pamiętaj, aby powiązać lakehouse z notesem.
Krok 1. Ładowanie danych
Zestaw danych rekomendacji książki w tym scenariuszu składa się z trzech oddzielnych zestawów danych:
Books.csv: Numer międzynarodowej standardowej książki (ISBN) identyfikuje każdą książkę, z nieprawidłowymi datami już usuniętymi. Zestaw danych zawiera również tytuł, autor i wydawcę. W przypadku książki z wieloma autorami plik Books.csv zawiera tylko pierwszego autora. Adresy URL wskazują zasoby witryny internetowej firmy Amazon na potrzeby obrazów okładkowych, w trzech rozmiarach.
ISBN Book-Title Book-Author Rok —Of-Publication Wydawca Obraz:URL-S Obraz —URL-M Image-URL-l 0195153448 Klasyczna mitologia Mark P. O. Morford 2002 Oxford University Press http://images.amazon.com/images/P/0195153448.01.THUMBZZZ.jpg http://images.amazon.com/images/P/0195153448.01.MZZZZZZZ.jpg http://images.amazon.com/images/P/0195153448.01.LZZZZZZZ.jpg 0002005018 Clara Callan Richard Bruce Wright 2001 HarperFlamingo Canada http://images.amazon.com/images/P/0002005018.01.THUMBZZZ.jpg http://images.amazon.com/images/P/0002005018.01.MZZZZZZZ.jpg http://images.amazon.com/images/P/0002005018.01.LZZZZZZZ.jpg Ratings.csv: Oceny dla każdej książki są jawne (udostępniane przez użytkowników w skali od 1 do 10) lub niejawne (obserwowane bez danych wejściowych użytkownika i wskazywane przez 0).
User-ID ISBN Book-Rating 276725 034545104X 0 276726 0155061224 5 Users.csv: Identyfikatory użytkowników są anonimizowane i mapowane na liczby całkowite. Dane demograficzne — na przykład lokalizacja i wiek — są udostępniane, jeśli są dostępne. Jeśli te dane są niedostępne, te wartości są
null.User-ID Lokalizacja Wiek 1 nyc new york usa 2 "stockton california usa" 18.0
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Zdefiniuj te parametry, abyś mógł używać tego notebooka z różnymi zestawami danych.
IS_CUSTOM_DATA = False # If True, the dataset has to be uploaded manually
USER_ID_COL = "User-ID" # Must not be '_user_id' for this notebook to run successfully
ITEM_ID_COL = "ISBN" # Must not be '_item_id' for this notebook to run successfully
ITEM_INFO_COL = (
"Book-Title" # Must not be '_item_info' for this notebook to run successfully
)
RATING_COL = (
"Book-Rating" # Must not be '_rating' for this notebook to run successfully
)
IS_SAMPLE = True # If True, use only <SAMPLE_ROWS> rows of data for training; otherwise, use all data
SAMPLE_ROWS = 5000 # If IS_SAMPLE is True, use only this number of rows for training
DATA_FOLDER = "Files/book-recommendation/" # Folder that contains the datasets
ITEMS_FILE = "Books.csv" # File that contains the item information
USERS_FILE = "Users.csv" # File that contains the user information
RATINGS_FILE = "Ratings.csv" # File that contains the rating information
EXPERIMENT_NAME = "aisample-recommendation" # MLflow experiment name
Pobieranie i przechowywanie danych w lakehouse
Ten kod pobiera zestaw danych, a następnie przechowuje go w lakehouse (magazynie danych).
Ważny
Przed uruchomieniem należy dodać lakehouse do notesu. W przeciwnym razie zostanie wyświetlony błąd.
if not IS_CUSTOM_DATA:
# Download data files into a lakehouse if they don't exist
import os, requests
remote_url = "https://synapseaisolutionsa.blob.core.windows.net/public/Book-Recommendation-Dataset"
file_list = ["Books.csv", "Ratings.csv", "Users.csv"]
download_path = f"/lakehouse/default/{DATA_FOLDER}/raw"
if not os.path.exists("/lakehouse/default"):
raise FileNotFoundError(
"Default lakehouse not found, please add a lakehouse and restart the session."
)
os.makedirs(download_path, exist_ok=True)
for fname in file_list:
if not os.path.exists(f"{download_path}/{fname}"):
r = requests.get(f"{remote_url}/{fname}", timeout=30)
with open(f"{download_path}/{fname}", "wb") as f:
f.write(r.content)
print("Downloaded demo data files into lakehouse.")
Konfigurowanie śledzenia eksperymentów MLflow
Użyj tego kodu, aby skonfigurować śledzenie eksperymentów MLflow. W tym przykładzie wyłączono automatyczne rejestrowanie. Aby uzyskać więcej informacji, zobacz artykuł Automatyczne rejestrowanie w usłudze Microsoft Fabric.
# Set up MLflow for experiment tracking
import mlflow
mlflow.set_experiment(EXPERIMENT_NAME)
mlflow.autolog(disable=True) # Disable MLflow autologging
Odczytywanie danych z jeziora
Po umieszczeniu prawidłowych danych w lakehouse przeczytaj trzy zestawy danych w oddzielnych ramkach danych platformy Spark w notesie. Ścieżki plików w tym kodzie używają zdefiniowanych wcześniej parametrów.
df_items = (
spark.read.option("header", True)
.option("inferSchema", True)
.csv(f"{DATA_FOLDER}/raw/{ITEMS_FILE}")
.cache()
)
df_ratings = (
spark.read.option("header", True)
.option("inferSchema", True)
.csv(f"{DATA_FOLDER}/raw/{RATINGS_FILE}")
.cache()
)
df_users = (
spark.read.option("header", True)
.option("inferSchema", True)
.csv(f"{DATA_FOLDER}/raw/{USERS_FILE}")
.cache()
)
Krok 2. Wykonywanie eksploracyjnej analizy danych
Wyświetlanie danych pierwotnych
Zapoznaj się z ramkami danych za pomocą polecenia display. Za pomocą tego polecenia można wyświetlić ogólne statystyki ramki danych i zrozumieć, jak różne kolumny zestawu danych odnoszą się do siebie nawzajem. Przed rozpoczęciem eksplorowania zestawów danych użyj tego kodu, aby zaimportować wymagane biblioteki:
import pyspark.sql.functions as F
from pyspark.ml.feature import StringIndexer
import matplotlib.pyplot as plt
import seaborn as sns
color = sns.color_palette() # Adjusting plotting style
import pandas as pd # DataFrames
Użyj tego kodu, aby przyjrzeć się ramce danych zawierającej dane książki:
display(df_items, summary=True)
Dodaj kolumnę _item_id do późniejszego użycia. Wartość _item_id musi być liczbą całkowitą dla modeli rekomendacji. Ten kod używa StringIndexer do przekształcania ITEM_ID_COL do indeksów:
df_items = (
StringIndexer(inputCol=ITEM_ID_COL, outputCol="_item_id")
.setHandleInvalid("skip")
.fit(df_items)
.transform(df_items)
.withColumn("_item_id", F.col("_item_id").cast("int"))
)
Wyświetl ramkę danych i sprawdź, czy wartość _item_id zwiększa się monotonicznie i kolejno, zgodnie z oczekiwaniami:
display(df_items.sort(F.col("_item_id").desc()))
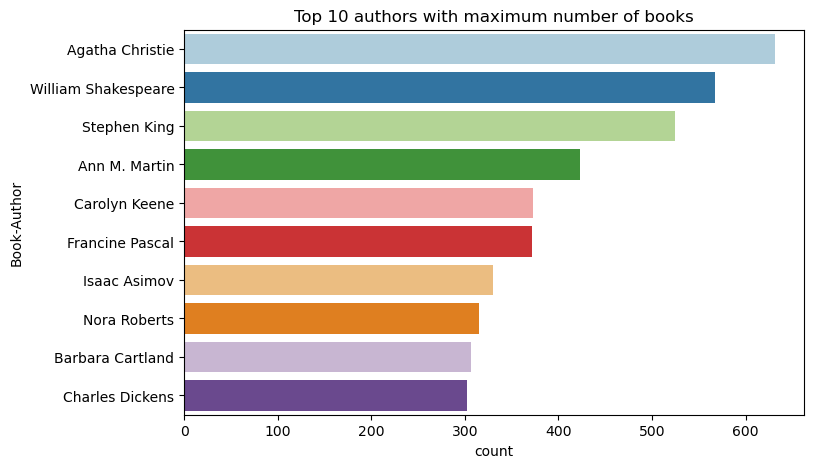
Użyj tego kodu, aby wykreślić 10 najlepszych autorów, według liczby książek napisanych w kolejności malejącej. Agatha Christie jest wiodącą autorką z dorobkiem ponad 600 książek, a tuż za nią plasuje się William Shakespeare.
df_books = df_items.toPandas() # Create a pandas DataFrame from the Spark DataFrame for visualization
plt.figure(figsize=(8,5))
sns.countplot(y="Book-Author",palette = 'Paired', data=df_books,order=df_books['Book-Author'].value_counts().index[0:10])
plt.title("Top 10 authors with maximum number of books")
Następnie wyświetl ramkę danych zawierającą dane użytkownika:
display(df_users, summary=True)
Jeśli w wierszu brakuje wartości User-ID, upuść ten wiersz. Brakujące wartości w dostosowanym zestawie danych nie powodują problemów.
df_users = df_users.dropna(subset=(USER_ID_COL))
display(df_users, summary=True)
Dodaj kolumnę _user_id do późniejszego użycia. W przypadku modeli rekomendacji wartość _user_id musi być liczbą całkowitą. Poniższy przykład kodu używa StringIndexer do przekształcenia USER_ID_COL na indeksy.
Zestaw danych książki ma już kolumnę typu całkowitego User-ID. Jednak dodanie kolumny _user_id w celu zapewnienia zgodności z różnymi zestawami danych sprawia, że ten przykład jest bardziej niezawodny. Użyj tego kodu, aby dodać kolumnę _user_id:
df_users = (
StringIndexer(inputCol=USER_ID_COL, outputCol="_user_id")
.setHandleInvalid("skip")
.fit(df_users)
.transform(df_users)
.withColumn("_user_id", F.col("_user_id").cast("int"))
)
display(df_users.sort(F.col("_user_id").desc()))
Użyj tego kodu, aby wyświetlić dane oceny:
display(df_ratings, summary=True)
Uzyskaj odrębne oceny i zapisz je do późniejszego użycia na liście o nazwie ratings:
ratings = [i[0] for i in df_ratings.select(RATING_COL).distinct().collect()]
print(ratings)
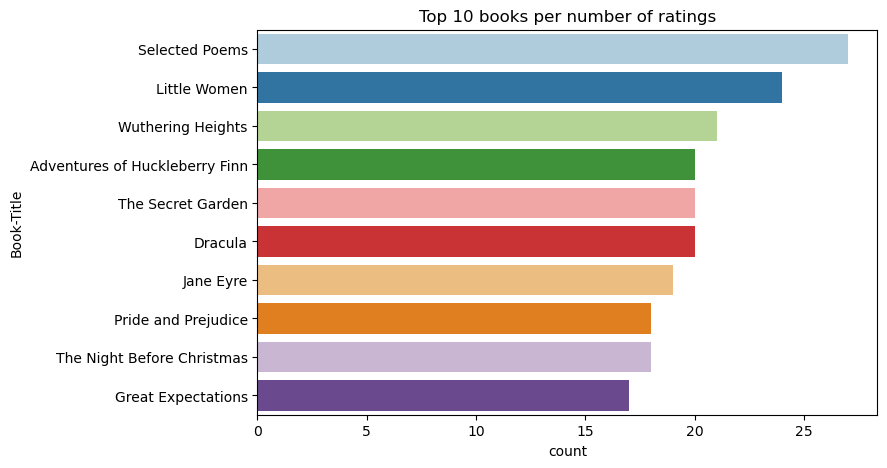
Użyj tego kodu, aby pokazać 10 najlepszych książek o najwyższych ocenach:
plt.figure(figsize=(8,5))
sns.countplot(y="Book-Title",palette = 'Paired',data= df_books, order=df_books['Book-Title'].value_counts().index[0:10])
plt.title("Top 10 books per number of ratings")
Według ocen, Wybrane Wiersze jest najpopularniejszą książką. Adventures of Huckleberry Finn, Secret Gardeni Dracula mają taką samą ocenę.
Scalanie danych
Połącz trzy DataFrames w jeden DataFrame, aby uzyskać bardziej wszechstronną analizę.
df_all = df_ratings.join(df_users, USER_ID_COL, "inner").join(
df_items, ITEM_ID_COL, "inner"
)
df_all_columns = [
c for c in df_all.columns if c not in ["_user_id", "_item_id", RATING_COL]
]
# Reorder the columns to ensure that _user_id, _item_id, and Book-Rating are the first three columns
df_all = (
df_all.select(["_user_id", "_item_id", RATING_COL] + df_all_columns)
.withColumn("id", F.monotonically_increasing_id())
.cache()
)
display(df_all)
Użyj tego kodu, aby wyświetlić liczbę unikatowych użytkowników, książek i interakcji:
print(f"Total Users: {df_users.select('_user_id').distinct().count()}")
print(f"Total Items: {df_items.select('_item_id').distinct().count()}")
print(f"Total User-Item Interactions: {df_all.count()}")
Obliczanie i kreślenie najpopularniejszych elementów
Użyj tego kodu, aby obliczyć i wyświetlić 10 najpopularniejszych książek:
# Compute top popular products
df_top_items = (
df_all.groupby(["_item_id"])
.count()
.join(df_items, "_item_id", "inner")
.sort(["count"], ascending=[0])
)
# Find top <topn> popular items
topn = 10
pd_top_items = df_top_items.limit(topn).toPandas()
pd_top_items.head(10)
Napiwek
Użyj wartości <topn> dla sekcji rekomendacji Popularne lub Najczęściej kupowane.
# Plot top <topn> items
f, ax = plt.subplots(figsize=(10, 5))
plt.xticks(rotation="vertical")
sns.barplot(y=ITEM_INFO_COL, x="count", data=pd_top_items)
ax.tick_params(axis='x', rotation=45)
plt.xlabel("Number of Ratings for the Item")
plt.show()

Przygotowywanie zestawów danych trenowania i testowania
Macierz ALS wymaga przygotowania danych przed szkoleniem. Użyj tego przykładowego kodu, aby przygotować dane. Kod wykonuje następujące akcje:
- Rzutowanie kolumny oceny na poprawny typ
- Przykładowe dane szkoleniowe z ocenami użytkowników
- Dzielenie danych na zestawy danych szkoleniowych i testowych
if IS_SAMPLE:
# Must sort by '_user_id' before performing limit to ensure that ALS works normally
# If training and test datasets have no common _user_id, ALS will fail
df_all = df_all.sort("_user_id").limit(SAMPLE_ROWS)
# Cast the column into the correct type
df_all = df_all.withColumn(RATING_COL, F.col(RATING_COL).cast("float"))
# Using a fraction between 0 and 1 returns the approximate size of the dataset; for example, 0.8 means 80% of the dataset
# Rating = 0 means the user didn't rate the item, so it can't be used for training
# We use the 80% of the dataset with rating > 0 as the training dataset
fractions_train = {0: 0}
fractions_test = {0: 0}
for i in ratings:
if i == 0:
continue
fractions_train[i] = 0.8
fractions_test[i] = 1
# Training dataset
train = df_all.sampleBy(RATING_COL, fractions=fractions_train)
# Join with leftanti will select all rows from df_all with rating > 0 and not in the training dataset; for example, the remaining 20% of the dataset
# test dataset
test = df_all.join(train, on="id", how="leftanti").sampleBy(
RATING_COL, fractions=fractions_test
)
Rzadkość odnosi się do rzadkich danych zwrotnych, które nie potrafią identyfikować podobieństw w zainteresowaniach użytkowników. Aby lepiej zrozumieć zarówno dane, jak i bieżący problem, użyj tego kodu, aby obliczyć rozrzedanie zestawu danych:
# Compute the sparsity of the dataset
def get_mat_sparsity(ratings):
# Count the total number of ratings in the dataset - used as numerator
count_nonzero = ratings.select(RATING_COL).count()
print(f"Number of rows: {count_nonzero}")
# Count the total number of distinct user_id and distinct product_id - used as denominator
total_elements = (
ratings.select("_user_id").distinct().count()
* ratings.select("_item_id").distinct().count()
)
# Calculate the sparsity by dividing the numerator by the denominator
sparsity = (1.0 - (count_nonzero * 1.0) / total_elements) * 100
print("The ratings DataFrame is ", "%.4f" % sparsity + "% sparse.")
get_mat_sparsity(df_all)
# Check the ID range
# ALS supports only values in the integer range
print(f"max user_id: {df_all.agg({'_user_id': 'max'}).collect()[0][0]}")
print(f"max user_id: {df_all.agg({'_item_id': 'max'}).collect()[0][0]}")
Krok 3. Opracowywanie i trenowanie modelu
Trenowanie modelu ALS w celu nadania użytkownikom spersonalizowanych zaleceń.
Definiowanie modelu
Platforma Spark ML udostępnia wygodny interfejs API do tworzenia modelu ALS. Jednak model nie obsługuje niezawodnie problemów, takich jak rozrzedzenie danych i zimny start (tworzenie rekomendacji, gdy użytkownicy lub przedmioty są nowe). Aby zwiększyć wydajność modelu, połącz krzyżowe sprawdzanie poprawności i automatyczne dostrajanie hiperparametrów.
Użyj tego kodu, aby zaimportować biblioteki wymagane do trenowania i oceny modelu:
# Import Spark required libraries
from pyspark.ml.evaluation import RegressionEvaluator
from pyspark.ml.recommendation import ALS
from pyspark.ml.tuning import ParamGridBuilder, CrossValidator, TrainValidationSplit
# Specify the training parameters
num_epochs = 1 # Number of epochs; here we use 1 to reduce the training time
rank_size_list = [64] # The values of rank in ALS for tuning
reg_param_list = [0.01, 0.1] # The values of regParam in ALS for tuning
model_tuning_method = "TrainValidationSplit" # TrainValidationSplit or CrossValidator
# Build the recommendation model by using ALS on the training data
# We set the cold start strategy to 'drop' to ensure that we don't get NaN evaluation metrics
als = ALS(
maxIter=num_epochs,
userCol="_user_id",
itemCol="_item_id",
ratingCol=RATING_COL,
coldStartStrategy="drop",
implicitPrefs=False,
nonnegative=True,
)
Dostrajanie hiperparametrów modelu
Następny przykładowy kod tworzy siatkę parametrów, aby ułatwić wyszukiwanie hiperparametrów. Kod tworzy również ewaluator regresji, który używa błędu głównego średniokwadratowego (RMSE) jako metryki oceny:
# Construct a grid search to select the best values for the training parameters
param_grid = (
ParamGridBuilder()
.addGrid(als.rank, rank_size_list)
.addGrid(als.regParam, reg_param_list)
.build()
)
print("Number of models to be tested: ", len(param_grid))
# Define the evaluator and set the loss function to the RMSE
evaluator = RegressionEvaluator(
metricName="rmse", labelCol=RATING_COL, predictionCol="prediction"
)
Następny przykładowy kod inicjuje różne metody dostrajania modelu na podstawie wstępnie skonfigurowanych parametrów. Aby uzyskać więcej informacji na temat dostrajania modelu, zobacz Dostrajanie uczenia maszynowego: wybór modelu i dostrajanie hiperparametrów w witrynie internetowej platformy Apache Spark.
# Build cross-validation by using CrossValidator and TrainValidationSplit
if model_tuning_method == "CrossValidator":
tuner = CrossValidator(
estimator=als,
estimatorParamMaps=param_grid,
evaluator=evaluator,
numFolds=5,
collectSubModels=True,
)
elif model_tuning_method == "TrainValidationSplit":
tuner = TrainValidationSplit(
estimator=als,
estimatorParamMaps=param_grid,
evaluator=evaluator,
# 80% of the training data will be used for training; 20% for validation
trainRatio=0.8,
collectSubModels=True,
)
else:
raise ValueError(f"Unknown model_tuning_method: {model_tuning_method}")
Ocena modelu
Należy ocenić moduły względem danych testowych. Dobrze wytrenowany model powinien mieć wysokie metryki w zestawie danych.
Nadmiernie dopasowany model może wymagać zwiększenia rozmiaru danych treningowych lub zmniejszenia niektórych nadmiarowych funkcji. Architektura modelu może wymagać zmiany lub jego parametry mogą wymagać dostrajania.
Notatka
Ujemna wartość wskaźnika R-kwadrat wskazuje, że wytrenowany model działa gorzej niż pozioma linia prosta. To stwierdzenie sugeruje, że wytrenowany model nie wyjaśnia danych.
Aby zdefiniować funkcję oceny, użyj następującego kodu:
def evaluate(model, data, verbose=0):
"""
Evaluate the model by computing rmse, mae, r2, and variance over the data.
"""
predictions = model.transform(data).withColumn(
"prediction", F.col("prediction").cast("double")
)
if verbose > 1:
# Show 10 predictions
predictions.select("_user_id", "_item_id", RATING_COL, "prediction").limit(
10
).show()
# Initialize the regression evaluator
evaluator = RegressionEvaluator(predictionCol="prediction", labelCol=RATING_COL)
_evaluator = lambda metric: evaluator.setMetricName(metric).evaluate(predictions)
rmse = _evaluator("rmse")
mae = _evaluator("mae")
r2 = _evaluator("r2")
var = _evaluator("var")
if verbose > 0:
print(f"RMSE score = {rmse}")
print(f"MAE score = {mae}")
print(f"R2 score = {r2}")
print(f"Explained variance = {var}")
return predictions, (rmse, mae, r2, var)
Śledzenie eksperymentu przy użyciu biblioteki MLflow
Użyj biblioteki MLflow, aby śledzić wszystkie eksperymenty i rejestrować parametry, metryki i modele. Aby rozpocząć trenowanie i ewaluację modelu, użyj następującego kodu:
from mlflow.models.signature import infer_signature
with mlflow.start_run(run_name="als"):
# Train models
models = tuner.fit(train)
best_metrics = {"RMSE": 10e6, "MAE": 10e6, "R2": 0, "Explained variance": 0}
best_index = 0
# Evaluate models
# Log models, metrics, and parameters
for idx, model in enumerate(models.subModels):
with mlflow.start_run(nested=True, run_name=f"als_{idx}") as run:
print("\nEvaluating on test data:")
print(f"subModel No. {idx + 1}")
predictions, (rmse, mae, r2, var) = evaluate(model, test, verbose=1)
signature = infer_signature(
train.select(["_user_id", "_item_id"]),
predictions.select(["_user_id", "_item_id", "prediction"]),
)
print("log model:")
mlflow.spark.log_model(
model,
f"{EXPERIMENT_NAME}-alsmodel",
signature=signature,
registered_model_name=f"{EXPERIMENT_NAME}-alsmodel",
dfs_tmpdir="Files/spark",
)
print("log metrics:")
current_metric = {
"RMSE": rmse,
"MAE": mae,
"R2": r2,
"Explained variance": var,
}
mlflow.log_metrics(current_metric)
if rmse < best_metrics["RMSE"]:
best_metrics = current_metric
best_index = idx
print("log parameters:")
mlflow.log_params(
{
"subModel_idx": idx,
"num_epochs": num_epochs,
"rank_size_list": rank_size_list,
"reg_param_list": reg_param_list,
"model_tuning_method": model_tuning_method,
"DATA_FOLDER": DATA_FOLDER,
}
)
# Log the best model and related metrics and parameters to the parent run
mlflow.spark.log_model(
models.subModels[best_index],
f"{EXPERIMENT_NAME}-alsmodel",
signature=signature,
registered_model_name=f"{EXPERIMENT_NAME}-alsmodel",
dfs_tmpdir="Files/spark",
)
mlflow.log_metrics(best_metrics)
mlflow.log_params(
{
"subModel_idx": idx,
"num_epochs": num_epochs,
"rank_size_list": rank_size_list,
"reg_param_list": reg_param_list,
"model_tuning_method": model_tuning_method,
"DATA_FOLDER": DATA_FOLDER,
}
)
Wybierz eksperyment o nazwie aisample-recommendation z obszaru roboczego, aby wyświetlić zarejestrowane informacje dotyczące przebiegu trenowania. Jeśli zmieniono nazwę eksperymentu, wybierz eksperyment, który ma nową nazwę. Zarejestrowane informacje przypominają ten obraz:

Krok 4. Ładowanie końcowego modelu do oceniania i tworzenie przewidywań
Po zakończeniu trenowania modelu i wybraniu najlepszego, załaduj go do ewaluacji (czasami nazywanej wnioskowaniem). Ten kod ładuje model i używa przewidywań, aby zalecić 10 pierwszych książek dla każdego użytkownika:
# Load the best model
# MLflow uses PipelineModel to wrap the original model, so we extract the original ALSModel from the stages
model_uri = f"models:/{EXPERIMENT_NAME}-alsmodel/1"
loaded_model = mlflow.spark.load_model(model_uri, dfs_tmpdir="Files/spark").stages[-1]
# Generate top 10 book recommendations for each user
userRecs = loaded_model.recommendForAllUsers(10)
# Represent the recommendations in an interpretable format
userRecs = (
userRecs.withColumn("rec_exp", F.explode("recommendations"))
.select("_user_id", F.col("rec_exp._item_id"), F.col("rec_exp.rating"))
.join(df_items.select(["_item_id", "Book-Title"]), on="_item_id")
)
userRecs.limit(10).show()
Dane wyjściowe przypominają następującą tabelę:
| _item_id | _user_id | ocena | Book-Title |
|---|---|---|---|
| 44865 | 7 | 7.9996786 | Lasher: Życia ... |
| 786 | 7 | 6.2255826 | The Piano Man's D... |
| 45330 | 7 | 4.980466 | Stan umysłu |
| 38960 | 7 | 4.980466 | Wszystko, co kiedykolwiek chciał |
| 125415 | 7 | 4.505084 | Harry Potter i ... |
| 44939 | 7 | 4.3579073 | Taltos: Życie ... |
| 175247 | 7 | 4.3579073 | Bonesetter's ... |
| 170183 | 7 | 4.228735 | Życie proste... |
| 88503 | 7 | 4.221206 | Wyspa Błękitu |
| 32894 | 7 | 3.9031885 | Przesilenie zimowe |
Zapisz przewidywania w lakehouse
Użyj tego kodu, aby wprowadzić z powrotem zalecenia do lakehouse.
# Code to save userRecs into the lakehouse
userRecs.write.format("delta").mode("overwrite").save(
f"{DATA_FOLDER}/predictions/userRecs"
)