Eksperymenty uczenia maszynowego w usłudze Microsoft Fabric
eksperymentu
Eksperymenty uczenia maszynowego umożliwiają analitykom danych rejestrowanie parametrów, wersji kodu, metryk i plików wyjściowych podczas uruchamiania kodu uczenia maszynowego. Eksperymenty umożliwiają również wizualizowanie, wyszukiwanie i porównywanie przebiegów, a także pobieranie plików run i metadanych do analizy w innych narzędziach.
W tym artykule dowiesz się więcej o tym, jak analitycy danych mogą wchodzić w interakcje z eksperymentami uczenia maszynowego i używać ich do organizowania procesu programowania oraz śledzenia wielu przebiegów.
Warunki wstępne
- Subskrypcja usługi Power BI Premium. Jeśli go nie masz, zobacz Jak kupić usługę Power BI Premium.
- Obszar roboczy usługi Power BI z przypisaną pojemnością Premium.
Tworzenie eksperymentu
Eksperyment uczenia maszynowego można utworzyć bezpośrednio z poziomu interfejsu użytkownika (UI) sieci szkieletowej lub pisząc kod korzystający z interfejsu API platformy MLflow.
Tworzenie eksperymentu przy użyciu interfejsu użytkownika
Aby utworzyć eksperyment uczenia maszynowego z poziomu interfejsu użytkownika:
- Utwórz nowy obszar roboczy lub wybierz istniejący.
- Możesz utworzyć nowy element za pomocą obszaru roboczego lub za pomocą polecenia Utwórz.
- Obszar roboczy:
- Wybierz swój obszar roboczy.
- Wybierz pozycję Nowy element.
- Wybierz pozycję Experiment w obszarze Analizuj i trenuj dane.
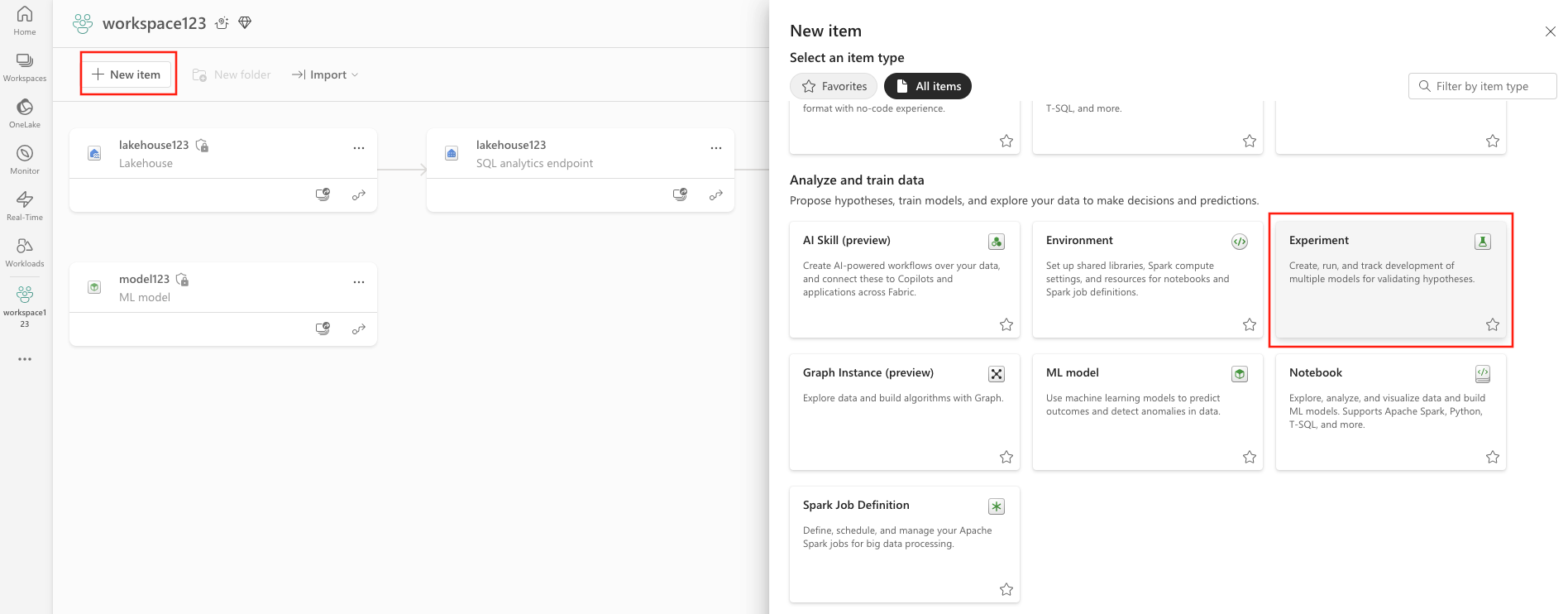
- Przycisk Utwórz:
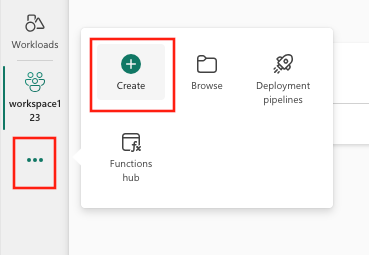
- Wybierz pozycję Utwórz, którą można znaleźć w ... w menu pionowym.
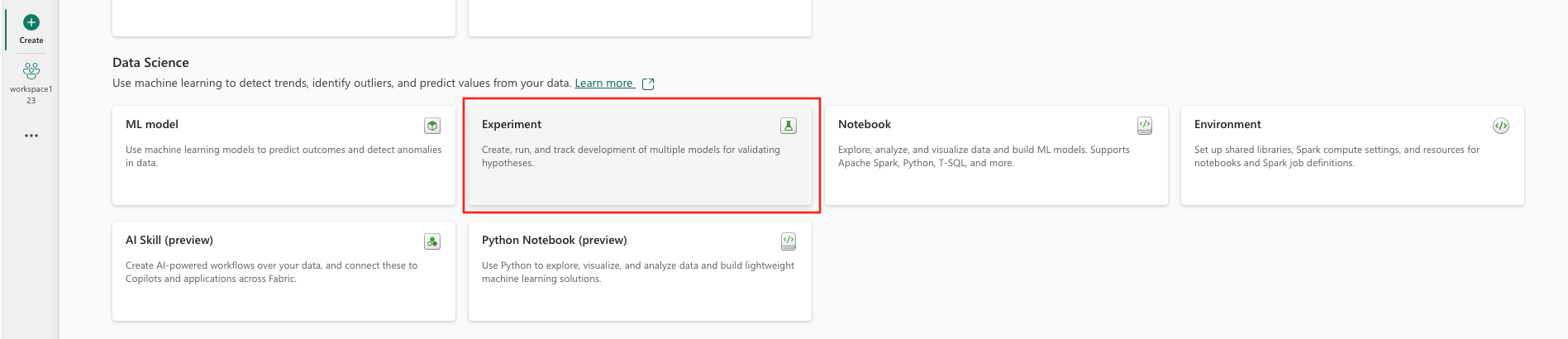
- Wybierz Experiment w sekcji Data Science.
- Wybierz pozycję Utwórz, którą można znaleźć w ... w menu pionowym.
- Obszar roboczy:
- Podaj nazwę eksperymentu i wybierz pozycję Utwórz. Ta akcja powoduje utworzenie pustego eksperymentu w obszarze roboczym.



Po utworzeniu eksperymentu możesz rozpocząć dodawanie przebiegów w celu śledzenia metryk i parametrów przebiegu.
Tworzenie eksperymentu przy użyciu interfejsu API platformy MLflow
Możesz również utworzyć eksperyment uczenia maszynowego bezpośrednio ze środowiska tworzenia przy użyciu interfejsów API mlflow.create_experiment() lub mlflow.set_experiment(). W poniższym kodzie zastąp <EXPERIMENT_NAME> nazwą eksperymentu.
import mlflow
# This will create a new experiment with the provided name.
mlflow.create_experiment("<EXPERIMENT_NAME>")
# This will set the given experiment as the active experiment.
# If an experiment with this name does not exist, a new experiment with this name is created.
mlflow.set_experiment("<EXPERIMENT_NAME>")
Zarządzanie przebiegami w ramach eksperymentu
Eksperyment uczenia maszynowego zawiera kolekcję przebiegów na potrzeby uproszczonego śledzenia i porównywania. W ramach eksperymentu analityk danych może przechodzić między różnymi przebiegami i eksplorować podstawowe parametry i metryki. Analitycy danych mogą również porównać przebiegi w eksperymencie uczenia maszynowego, aby określić, który podzbiór parametrów daje żądaną wydajność modelu.
Śledzenie przebiegów
Przebieg uczenia maszynowego odpowiada pojedynczemu wykonaniu kodu modelu.

Każdy przebieg zawiera następujące informacje:
- Źródło: Nazwa notesu, który utworzył uruchomienie.
- Zarejestrowana Wersja: wskazuje, czy przebieg został zapisany jako model uczenia maszynowego.
- Data rozpoczęcia: Godzina rozpoczęcia uruchomienia.
- stan: postęp przebiegu.
- Hiperparametry: Hiperparametry zapisane jako pary klucz-wartość. Zarówno klucze, jak i wartości są ciągami.
- Metrics: Uruchom metryki zapisane jako pary klucz-wartość. Wartość jest liczbowa.
- pliki wyjściowe: pliki wyjściowe w dowolnym formacie. Można na przykład rejestrować obrazy, środowisko, modele i pliki danych.
- Tagi: metadane jako pary klucz-wartość dla uruchomień.
Wyświetlanie ostatnich przebiegów
Możesz również wyświetlić ostatnie przebiegi dla eksperymentu, wybierając pozycję Lista uruchomień. Ten widok umożliwia śledzenie ostatnich działań, szybkie przechodzenie do powiązanej aplikacji Spark i stosowanie filtrów na podstawie stanu uruchomienia.

Porównywanie i filtrowanie przebiegów
Aby porównać i ocenić jakość przebiegów uczenia maszynowego, możesz porównać parametry, metryki i metadane między wybranymi przebiegami w ramach eksperymentu.
Oznaczanie przebiegów tagami
Tagowanie MLflow dla przebiegów eksperymentów umożliwia użytkownikom dodawanie niestandardowych metadanych w postaci par klucz-wartość do ich przebiegów. Te tagi ułatwiają kategoryzowanie, filtrowanie i wyszukiwanie przebiegów na podstawie określonych atrybutów, co ułatwia zarządzanie eksperymentami i analizowanie ich na platformie MLflow. Użytkownicy mogą używać tagów do etykietowania przebiegów z informacjami, takimi jak typy modeli, parametry lub wszelkie odpowiednie identyfikatory, zwiększając ogólną organizację i możliwość śledzenia eksperymentów.
Ten fragment kodu uruchamia przebieg MLflow, rejestruje niektóre parametry i metryki oraz dodaje tagi do kategoryzowania i zapewnienia dodatkowego kontekstu dla przebiegu.
import mlflow
import mlflow.sklearn
from sklearn.model_selection import train_test_split
from sklearn.linear_model import LinearRegression
from sklearn.metrics import mean_squared_error
from sklearn.datasets import fetch_california_housing
# Autologging
mlflow.autolog()
# Load the California housing dataset
data = fetch_california_housing(as_frame=True)
X = data.data
y = data.target
# Split the data
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
# Start an MLflow run
with mlflow.start_run() as run:
# Train the model
model = LinearRegression()
model.fit(X_train, y_train)
# Predict and evaluate
y_pred = model.predict(X_test)
# Add tags
mlflow.set_tag("model_type", "Linear Regression")
mlflow.set_tag("dataset", "California Housing")
mlflow.set_tag("developer", "Bob")
Po zastosowaniu tagów można wyświetlić wyniki bezpośrednio za pomocą wbudowanego widżetu MLflow lub ze strony szczegółów przebiegu.

Ostrzeżenie
Ostrzeżenie : ograniczenia dotyczące stosowania tagów do przebiegów eksperymentów MLflow w Fabric
- Tagi niepuste: Nazwy lub wartości tagów nie mogą być puste. Jeśli spróbujesz zastosować tag z pustą nazwą lub wartością, operacja zakończy się niepowodzeniem.
- nazwy tagów: Nazwy tagów mogą mieć długość maksymalnie 250 znaków.
- wartości tagów: wartości tagów mogą mieć długość do 5000 znaków.
-
nazwy tagów z ograniczeniami: nazwy tagów rozpoczynające się od niektórych prefiksów nie są obsługiwane. W szczególności nazwy tagów rozpoczynające się od
synapseml,mlflowlubtridentsą ograniczone i nie zostaną zaakceptowane.
Wizualne porównywanie przebiegów
Możesz wizualnie porównać i filtrować przebiegi w istniejącym eksperymencie. Porównanie wizualne umożliwia łatwe nawigowanie między wieloma przebiegami i sortowanie pośród nich.

Aby porównać przebiegi:
- Wybierz istniejący eksperyment uczenia maszynowego zawierający wiele przebiegów.
- Wybierz kartę Widok, a następnie przejdź do listy Widok Uruchom. Alternatywnie, możesz wybrać opcję Wyświetl listę uruchamiania bezpośrednio z widoku Szczegóły uruchomienia.
- Dostosuj kolumny w tabeli, rozwijając panel Dostosuj kolumny. W tym miejscu możesz wybrać właściwości, metryki, tagi i hiperparametry, które chcesz zobaczyć.
- Rozwiń okienko Filtr, aby zawęzić wyniki na podstawie określonych kryteriów.
- Wybierz wiele przebiegów, aby porównać wyniki w okienku porównania metryk. W tym okienku można dostosować wykresy, zmieniając tytuł wykresu, typ wizualizacji, oś X, oś Y i nie tylko.
Porównaj przebiegi za pomocą interfejsu API MLflow
Analitycy danych mogą również używać biblioteki MLflow do wykonywania zapytań i wyszukiwania między przebiegami w ramach eksperymentu. Więcej interfejsów API platformy MLflow do wyszukiwania, filtrowania i porównywania przebiegów można znaleźć w dokumentacji platformy MLflow .
Pobieranie wszystkich przebiegów
Możesz użyć interfejsu API wyszukiwania MLflow mlflow.search_runs(), aby pobrać wszystkie przebiegi w eksperymencie, zastępując <EXPERIMENT_NAME> nazwą eksperymentu lub <EXPERIMENT_ID> identyfikatorem eksperymentu w następującym kodzie:
import mlflow
# Get runs by experiment name:
mlflow.search_runs(experiment_names=["<EXPERIMENT_NAME>"])
# Get runs by experiment ID:
mlflow.search_runs(experiment_ids=["<EXPERIMENT_ID>"])
Napiwek
Możesz przeszukiwać wiele eksperymentów, podając listę identyfikatorów eksperymentów dla parametru experiment_ids. Podobnie udostępnienie listy nazw eksperymentów do parametru experiment_names umożliwi usłudze MLflow wyszukiwanie w wielu eksperymentach. Może to być przydatne, jeśli chcesz porównać przebiegi w różnych eksperymentach.
Zamówienia i limity uruchomień
Aby ograniczyć liczbę zwracanych przebiegów, użyj parametru max_results z search_runs. Parametr order_by umożliwia wyświetlenie listy kolumn do kolejności i może zawierać opcjonalną wartość DESC lub ASC. Na przykład poniższa funkcja zwraca ostatni przebieg eksperymentu.
mlflow.search_runs(experiment_ids=[ "1234-5678-90AB-CDEFG" ], max_results=1, order_by=["start_time DESC"])
Porównaj wyniki w notesie Fabric
Możesz używać widżetu tworzenia MLFlow w notesach Fabric do śledzenia biegów MLflow generowanych w każdej komórce notesu. Widżet umożliwia śledzenie przebiegów, skojarzonych metryk, parametrów i właściwości aż do poziomu poszczególnych komórek.
Aby uzyskać porównanie wizualne, możesz również przełączyć się na widok Porównaj. Ten widok przedstawia dane graficznie, ułatwiając szybką identyfikację wzorców lub odchyleń w różnych przebiegach.

Zapisz przebieg jako model uczenia maszynowego
Po uzyskaniu żądanego wyniku przebiegu możesz zapisać go jako model uczenia maszynowego, aby usprawnić śledzenie i wdrażanie modelu, wybierając pozycję Zapisz jako model uczenia maszynowego.

Monitorowanie eksperymentów uczenia maszynowego (wersja zapoznawcza)
Eksperymenty uczenia maszynowego są zintegrowane bezpośrednio z monitorem. Ta funkcja została zaprojektowana w celu zapewnienia większego wglądu w aplikacje platformy Spark i generowane przez nie eksperymenty uczenia maszynowego, co ułatwia zarządzanie tymi procesami i ich debugowanie.
Śledzenie danych z monitora
Użytkownicy mogą śledzić przebiegi eksperymentów bezpośrednio z monitora, zapewniając ujednolicony widok wszystkich swoich działań. Ta integracja obejmuje opcje filtrowania, umożliwiając użytkownikom skoncentrowanie się na eksperymentach lub przebiegach utworzonych w ciągu ostatnich 30 dni lub innych określonych okresów.

Śledzenie powiązanych przebiegów eksperymentów uczenia maszynowego z poziomu aplikacji Spark
Eksperyment uczenia maszynowego jest zintegrowany bezpośrednio z monitorem, w którym można wybrać określoną aplikację platformy Spark i uzyskać dostęp do migawek elementów. W tym miejscu znajdziesz listę wszystkich eksperymentów i przebiegów generowanych przez aplikację.