Korzystanie z rozwiązania Tidyverse
Tidyverse to zbiór pakietów języka R, które analitycy danych często używają w codziennych analizach danych. Obejmuje ona pakiety do importowania danych (), wizualizacji danych (readrggplot2), manipulowania danymi (dplyr, tidyr), programowania funkcjonalnego (purrr) i tworzenia modeli (tidymodels) itp. Pakiety w programie tidyverse zostały zaprojektowane tak, aby bezproblemowo współdziałały i były zgodne ze spójnym zestawem zasad projektowania.
Usługa Microsoft Fabric dystrybuuje najnowszą stabilną wersję tidyverse programu z każdą wersją środowiska uruchomieniowego. Zaimportuj i rozpocznij korzystanie ze znanych pakietów języka R.
Wymagania wstępne
Uzyskaj subskrypcję usługi Microsoft Fabric. Możesz też utworzyć konto bezpłatnej wersji próbnej usługi Microsoft Fabric.
Zaloguj się do usługi Microsoft Fabric.
Użyj przełącznika środowiska w lewym dolnym rogu strony głównej, aby przełączyć się na Fabric.

Otwórz lub utwórz notes. Aby dowiedzieć się, jak używać notesów usługi Microsoft Fabric, zobacz Jak używać notesów usługi Microsoft Fabric.
Ustaw opcję języka na SparkR (R), aby zmienić język podstawowy.
Dołącz notes do magazynu lakehouse. Po lewej stronie wybierz pozycję Dodaj , aby dodać istniejący obiekt lakehouse lub utworzyć jezioro.
Ładunek tidyverse
# load tidyverse
library(tidyverse)
Import danych
readr to pakiet języka R, który udostępnia narzędzia do odczytywania prostokątnych plików danych, takich jak CSV, TSV i pliki o stałej szerokości.
readr Zapewnia szybki i przyjazny sposób odczytywania prostokątnych plików danych, takich jak dostarczanie funkcji read_csv() i read_tsv() odczytywanie plików CSV i TSV odpowiednio.
Najpierw utwórzmy ramkę data.frame języka R, zapiszmy ją w usłudze Lakehouse przy użyciu polecenia i odczytać z powrotem za pomocą readr::write_csv() polecenia readr::read_csv().
Uwaga
Aby uzyskać dostęp do plików usługi Lakehouse przy użyciu metody readr, musisz użyć ścieżki interfejsu API plików. W Eksploratorze usługi Lakehouse kliknij prawym przyciskiem myszy plik lub folder, do którego chcesz uzyskać dostęp, i skopiuj ścieżkę interfejsu API plików z menu kontekstowego.
# create an R data frame
set.seed(1)
stocks <- data.frame(
time = as.Date('2009-01-01') + 0:9,
X = rnorm(10, 20, 1),
Y = rnorm(10, 20, 2),
Z = rnorm(10, 20, 4)
)
stocks
Następnie zapiszemy dane w usłudze Lakehouse przy użyciu ścieżki interfejsu API plików.
# write data to lakehouse using the File API path
temp_csv_api <- "/lakehouse/default/Files/stocks.csv"
readr::write_csv(stocks,temp_csv_api)
Odczytywanie danych z usługi Lakehouse.
# read data from lakehouse using the File API path
stocks_readr <- readr::read_csv(temp_csv_api)
# show the content of the R date.frame
head(stocks_readr)
Czyszczenie danych
tidyr to pakiet języka R, który udostępnia narzędzia do pracy z niechlujnymi danymi. Główne funkcje w programie tidyr zostały zaprojektowane tak, aby ułatwić przekształcanie danych w uporządkowany format. Dane tidy mają określoną strukturę, w której każda zmienna jest kolumną, a każda obserwacja jest wierszem, co ułatwia pracę z danymi w języku R i innymi narzędziami.
Na przykład funkcja w programie gather() może służyć do konwertowania tidyr szerokich danych na długie dane. Oto przykład:
# convert the stock data into longer data
library(tidyr)
stocksL <- gather(data = stocks, key = stock, value = price, X, Y, Z)
stocksL
Programowanie funkcjonalne
purrr to pakiet języka R, który rozszerza funkcjonalny zestaw narzędzi programowania języka R, zapewniając kompletny i spójny zestaw narzędzi do pracy z funkcjami i wektorami. Najlepszym miejscem na początek purrr jest rodzina map() funkcji, które pozwalają zastąpić wiele pętli dla pętli kodem, który jest zarówno bardziej zwięzły, jak i łatwiejszy do odczytania. Oto przykład użycia funkcji map() do zastosowania funkcji do każdego elementu listy:
# double the stock values using purrr
library(purrr)
stocks_double = map(stocks %>% select_if(is.numeric), ~.x*2)
stocks_double
Manipulowanie danymi
dplyr to pakiet języka R, który udostępnia spójny zestaw zleceń, które ułatwiają rozwiązywanie typowych problemów z manipulowaniem danymi, takich jak wybieranie zmiennych na podstawie nazw, wybieranie przypadków na podstawie wartości, zmniejszenie wielu wartości w dół do pojedynczego podsumowania i zmiana kolejności wierszy itp. Oto kilka przykładów:
# pick variables based on their names using select()
stocks_value <- stocks %>% select(X:Z)
stocks_value
# pick cases based on their values using filter()
filter(stocks_value, X >20)
# add new variables that are functions of existing variables using mutate()
library(lubridate)
stocks_wday <- stocks %>%
select(time:Z) %>%
mutate(
weekday = wday(time)
)
stocks_wday
# change the ordering of the rows using arrange()
arrange(stocks_wday, weekday)
# reduce multiple values down to a single summary using summarise()
stocks_wday %>%
group_by(weekday) %>%
summarize(meanX = mean(X), n= n())
Wizualizacja danych
ggplot2 to pakiet języka R do deklaratywnego tworzenia grafiki na podstawie gramatyki grafiki. Podajesz dane, informujesz ggplot2 , jak mapować zmienne na estetykę, jakie graficzne pierwotne elementy mają być używane, i dbają o szczegóły. Oto kilka przykładów:
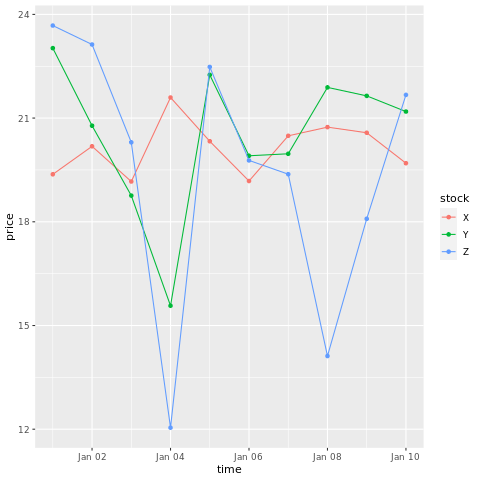
# draw a chart with points and lines all in one
ggplot(stocksL, aes(x=time, y=price, colour = stock)) +
geom_point()+
geom_line()
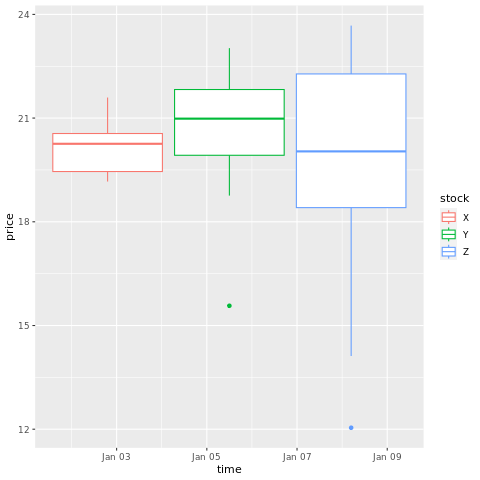
# draw a boxplot
ggplot(stocksL, aes(x=time, y=price, colour = stock)) +
geom_boxplot()
Kompilowanie modelu
Struktura tidymodels jest kolekcją pakietów do modelowania i uczenia maszynowego przy użyciu tidyverse zasad. Obejmuje ona listę pakietów podstawowych dla szerokiej gamy zadań tworzenia modelu, takich jak rsample dzielenie przykładu trenowania/testowania zestawu danych, parsnip specyfikacji modelu, recipes przetwarzania wstępnego danych, workflows modelowania przepływów pracy, tune dostrajania hiperparametrów, yardstick oceny modelu, broom czyszczenia danych wyjściowych modelu i dials zarządzania parametrami dostrajania. Aby dowiedzieć się więcej o pakietach, odwiedź witrynę internetową tidymodels. Oto przykład tworzenia modelu regresji liniowej w celu przewidywania mil na galon (mpg) samochodu na podstawie wagi (wt):
# look at the relationship between the miles per gallon (mpg) of a car and its weight (wt)
ggplot(mtcars, aes(wt,mpg))+
geom_point()
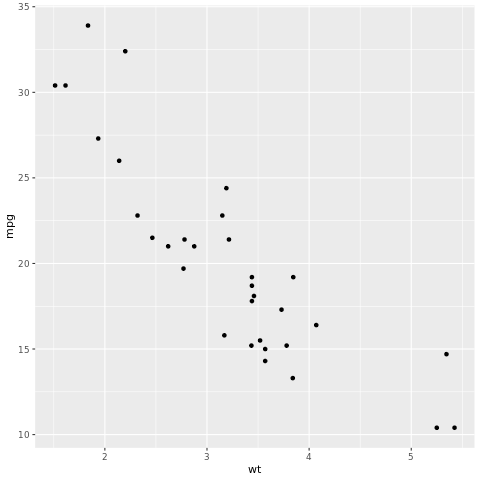
Na wykresie punktowym relacja wygląda w przybliżeniu liniowo, a wariancja wygląda na stałą. Spróbujmy to modelować przy użyciu regresji liniowej.
library(tidymodels)
# split test and training dataset
set.seed(123)
split <- initial_split(mtcars, prop = 0.7, strata = "cyl")
train <- training(split)
test <- testing(split)
# config the linear regression model
lm_spec <- linear_reg() %>%
set_engine("lm") %>%
set_mode("regression")
# build the model
lm_fit <- lm_spec %>%
fit(mpg ~ wt, data = train)
tidy(lm_fit)
Zastosuj model regresji liniowej, aby przewidzieć testowy zestaw danych.
# using the lm model to predict on test dataset
predictions <- predict(lm_fit, test)
predictions
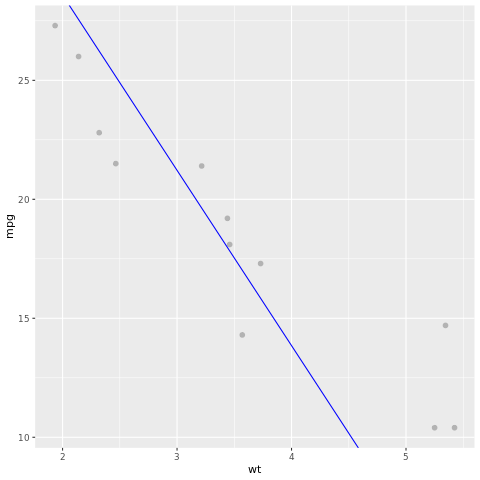
Przyjrzyjmy się wynikowi modelu. Możemy narysować model jako wykres liniowy i dane prawdy podstawy testowej jako punkty na tym samym wykresie. Model wygląda dobrze.
# draw the model as a line chart and the test data groundtruth as points
lm_aug <- augment(lm_fit, test)
ggplot(lm_aug, aes(x = wt, y = mpg)) +
geom_point(size=2,color="grey70") +
geom_abline(intercept = lm_fit$fit$coefficients[1], slope = lm_fit$fit$coefficients[2], color = "blue")