Samouczek: tworzenie, ocenianie i ocenianie modelu wykrywania błędów maszyny
Ten samouczek przedstawia pełny przykład przepływu pracy usługi Synapse Nauka o danych w usłudze Microsoft Fabric. Scenariusz używa uczenia maszynowego do bardziej systematycznego podejścia do diagnozowania błędów, aby aktywnie identyfikować problemy i podejmować działania przed rzeczywistą awarią maszyny. Celem jest przewidywanie, czy maszyna doświadczy awarii w oparciu o temperaturę procesu, prędkość rotacji itp.
W tym samouczku opisano następujące kroki:
- Instalowanie bibliotek niestandardowych
- Ładowanie i przetwarzanie danych
- Omówienie danych za pomocą eksploracyjnej analizy danych
- Używanie biblioteki scikit-learn, LightGBM i MLflow do trenowania modeli uczenia maszynowego oraz używania funkcji automatycznego rejestrowania sieci szkieletowej do śledzenia eksperymentów
- Ocenianie wytrenowanych modeli za pomocą funkcji Sieć szkieletowa
PREDICT, zapisywanie najlepszego modelu i ładowanie tego modelu pod kątem przewidywań - Wyświetlanie załadowanej wydajności modelu za pomocą wizualizacji usługi Power BI
Wymagania wstępne
Uzyskaj subskrypcję usługi Microsoft Fabric. Możesz też utworzyć konto bezpłatnej wersji próbnej usługi Microsoft Fabric.
Zaloguj się do usługi Microsoft Fabric.
Użyj przełącznika środowiska po lewej stronie głównej, aby przełączyć się na środowisko usługi Synapse Nauka o danych.

- W razie potrzeby utwórz magazyn lakehouse usługi Microsoft Fabric zgodnie z opisem w temacie Tworzenie magazynu lakehouse w usłudze Microsoft Fabric.
Postępuj zgodnie z instrukcjami w notesie
Możesz wybrać jedną z tych opcji, które należy wykonać w notesie:
- Otwieranie i uruchamianie wbudowanego notesu w środowisku Nauka o danych
- Przekazywanie notesu z usługi GitHub do środowiska Nauka o danych
Otwieranie wbudowanego notesu
W tym samouczku dołączymy przykładowy notes awarii maszyny.
Aby otworzyć wbudowany notes przykładowy samouczka w środowisku usługi Synapse Nauka o danych:
Przejdź do strony głównej usługi Synapse Nauka o danych.
Wybierz pozycję Użyj przykładu.
Wybierz odpowiedni przykład:
- Na domyślnej karcie Kompleksowe przepływy pracy (Python), jeśli przykład dotyczy samouczka dotyczącego języka Python.
- Na karcie Kompleksowe przepływy pracy (R), jeśli przykład dotyczy samouczka języka R.
- Jeśli przykład jest przeznaczony do szybkiego samouczka, na karcie Szybkie samouczki .
Przed rozpoczęciem uruchamiania kodu dołącz usługę Lakehouse do notesu .
Importowanie notesu z usługi GitHub
Notes AISample — konserwacja predykcyjna jest dołączony do tego samouczka.
Aby otworzyć towarzyszący notes na potrzeby tego samouczka, postępuj zgodnie z instrukcjami w temacie Przygotowywanie systemu do celów nauki o danych, aby zaimportować notes do obszaru roboczego.
Jeśli wolisz skopiować i wkleić kod z tej strony, możesz utworzyć nowy notes.
Przed rozpoczęciem uruchamiania kodu pamiętaj, aby dołączyć usługę Lakehouse do notesu .
Krok 1. Instalowanie bibliotek niestandardowych
W przypadku tworzenia modeli uczenia maszynowego lub analizy danych ad hoc może być konieczne szybkie zainstalowanie biblioteki niestandardowej na potrzeby sesji platformy Apache Spark. Dostępne są dwie opcje instalowania bibliotek.
- Użyj wbudowanych funkcji instalacji (
%piplub%conda) notesu, aby zainstalować bibliotekę tylko w bieżącym notesie. - Alternatywnie możesz utworzyć środowisko sieci szkieletowej, zainstalować biblioteki ze źródeł publicznych lub przekazać do niego biblioteki niestandardowe, a następnie administrator obszaru roboczego może dołączyć środowisko jako domyślne dla obszaru roboczego. Wszystkie biblioteki w środowisku staną się następnie dostępne do użycia w dowolnych notesach i definicjach zadań platformy Spark w obszarze roboczym. Aby uzyskać więcej informacji na temat środowisk, zobacz tworzenie, konfigurowanie i używanie środowiska w usłudze Microsoft Fabric.
Na potrzeby tego samouczka użyj polecenia %pip install , aby zainstalować bibliotekę imblearn w notesie.
Uwaga
Jądro PySpark jest uruchamiane ponownie po %pip install uruchomieniu. Zainstaluj wymagane biblioteki przed uruchomieniem innych komórek.
# Use pip to install imblearn
%pip install imblearn
Krok 2. Ładowanie danych
Zestaw danych symuluje rejestrowanie parametrów maszyny produkcyjnej jako funkcję czasu, która jest powszechna w ustawieniach przemysłowych. Składa się z 10 000 punktów danych przechowywanych jako wiersze z funkcjami jako kolumnami. Dostępne funkcje to:
Unikatowy identyfikator (UID) z zakresu od 1 do 10000
Identyfikator produktu, składający się z litery L (dla niskiej), M (dla średniej) lub H (dla wysokiej), aby wskazać wariant jakości produktu i numer seryjny specyficzny dla wariantu. Warianty niskiej, średniej i wysokiej jakości stanowią odpowiednio 60%, 30% i 10% wszystkich produktów
Temperatura powietrza, w stopniach Kelvin (K)
Temperatura procesu, w stopniach Kelvin
Prędkość rotacji, w rewolucjach na minutę (RPM)
Moment obrotowy, w miernikach Newton (Nm)
Zużycie narzędzia w ciągu kilku minut. Warianty jakości H, M i L dodają odpowiednio 5, 3 i 2 minuty zużycia narzędzia do narzędzia używanego w procesie
Etykieta błędu maszyny wskazująca, czy maszyna nie powiodła się w określonym punkcie danych. Ten konkretny punkt danych może mieć dowolny z następujących pięciu niezależnych trybów awarii:
- Awaria zużycia narzędzia (TWF): narzędzie jest zastępowane lub kończy się niepowodzeniem w losowo wybranym czasie noszenia narzędzia w okresie od 200 do 240 minut
- Awaria rozpraszania ciepła (HDF): rozpraszanie ciepła powoduje awarię procesu, jeśli różnica między temperaturą powietrza a temperaturą procesu jest mniejsza niż 8,6 K, a prędkość obracania narzędzia jest mniejsza niż 1380 obr./min
- Awaria zasilania (PWF): produkt momentu obrotowego i prędkości obrotowej (w rad/s) jest równy mocy wymaganej do procesu. Proces kończy się niepowodzeniem, jeśli ta moc spadnie poniżej 3500 W lub przekroczy 9000 W
- Awaria nadmiernego wytrenowania (OSF): jeśli produkt zużycia i momentu obrotowego narzędzia przekracza 11 000 minimalnych nm dla wariantu produktu L (12 000 dla M, 13 000 dla H), proces kończy się niepowodzeniem z powodu nadmiernego wytrenowania
- Losowe błędy (RNF): każdy proces ma szansę awarii na 0,1%, niezależnie od parametrów procesu
Uwaga
Jeśli co najmniej jeden z powyższych trybów awarii ma wartość true, proces zakończy się niepowodzeniem, a etykieta "awaria maszyny" jest ustawiona na 1. Metoda uczenia maszynowego nie może określić, który tryb awarii spowodował awarię procesu.
Pobieranie zestawu danych i przekazywanie do usługi Lakehouse
Połączenie do kontenera Azure Open Datasets i załaduj zestaw danych konserwacji predykcyjnej. Ten kod pobiera publicznie dostępną wersję zestawu danych, a następnie przechowuje go w usłudze Fabric Lakehouse:
Ważne
Dodaj magazyn lakehouse do notesu przed jego uruchomieniem. W przeciwnym razie zostanie wyświetlony błąd. Aby uzyskać informacje na temat dodawania magazynu lakehouse, zobacz Połączenie lakehouses and notebooks (Magazyny i notesy).
# Download demo data files into the lakehouse if they don't exist
import os, requests
DATA_FOLDER = "Files/predictive_maintenance/" # Folder that contains the dataset
DATA_FILE = "predictive_maintenance.csv" # Data file name
remote_url = "https://synapseaisolutionsa.blob.core.windows.net/public/MachineFaultDetection"
file_list = ["predictive_maintenance.csv"]
download_path = f"/lakehouse/default/{DATA_FOLDER}/raw"
if not os.path.exists("/lakehouse/default"):
raise FileNotFoundError(
"Default lakehouse not found, please add a lakehouse and restart the session."
)
os.makedirs(download_path, exist_ok=True)
for fname in file_list:
if not os.path.exists(f"{download_path}/{fname}"):
r = requests.get(f"{remote_url}/{fname}", timeout=30)
with open(f"{download_path}/{fname}", "wb") as f:
f.write(r.content)
print("Downloaded demo data files into lakehouse.")
Po pobraniu zestawu danych do usługi Lakehouse możesz załadować go jako ramkę danych platformy Spark:
df = (
spark.read.option("header", True)
.option("inferSchema", True)
.csv(f"{DATA_FOLDER}raw/{DATA_FILE}")
.cache()
)
df.show(5)
W tej tabeli przedstawiono podgląd danych:
| UDI | Identyfikator produktu | Typ | Temperatura powietrza [K] | Temperatura procesu [K] | Prędkość rotacji [rpm] | Moment obrotowy [Nm] | Zużycie narzędzia [min] | Obiekt docelowy | Typ błędu |
|---|---|---|---|---|---|---|---|---|---|
| 1 | M14860 | M | 298.1 | 308.6 | 1551 | 42.8 | 0 | 0 | Brak błędu |
| 2 | L47181 | L | 298.2 | 308.7 | 1408 | 46.3 | 3 | 0 | Brak błędu |
| 3 | L47182 | L | 298.1 | 308.5 | 1498 | 49.4 | 5 | 0 | Brak błędu |
| 100 | L47183 | L | 298.2 | 308.6 | 1433 | 39.5 | 7 | 0 | Brak błędu |
| 5 | L47184 | L | 298.2 | 308.7 | 1408 | 40,0 | 9 | 0 | Brak błędu |
Zapisywanie ramki danych platformy Spark w tabeli delty usługi Lakehouse
Sformatuj dane (na przykład zastąp spacje podkreśleniami), aby ułatwić wykonywanie operacji platformy Spark w kolejnych krokach:
# Replace the space in the column name with an underscore to avoid an invalid character while saving
df = df.toDF(*(c.replace(' ', '_') for c in df.columns))
table_name = "predictive_maintenance_data"
df.show(5)
W tej tabeli przedstawiono podgląd danych z sformatowanymi nazwami kolumn:
| UDI | Product_ID | Typ | Air_temperature_[K] | Process_temperature_[K] | Rotational_speed_[rpm] | Torque_[Nm] | Tool_wear_[min] | Obiekt docelowy | Failure_Type |
|---|---|---|---|---|---|---|---|---|---|
| 1 | M14860 | M | 298.1 | 308.6 | 1551 | 42.8 | 0 | 0 | Brak błędu |
| 2 | L47181 | L | 298.2 | 308.7 | 1408 | 46.3 | 3 | 0 | Brak błędu |
| 3 | L47182 | L | 298.1 | 308.5 | 1498 | 49.4 | 5 | 0 | Brak błędu |
| 100 | L47183 | L | 298.2 | 308.6 | 1433 | 39.5 | 7 | 0 | Brak błędu |
| 5 | L47184 | L | 298.2 | 308.7 | 1408 | 40,0 | 9 | 0 | Brak błędu |
# Save data with processed columns to the lakehouse
df.write.mode("overwrite").format("delta").save(f"Tables/{table_name}")
print(f"Spark DataFrame saved to delta table: {table_name}")
Krok 3. Wstępne przetwarzanie danych i wykonywanie eksploracyjnej analizy danych
Przekonwertuj ramkę danych platformy Spark na ramkę danych biblioteki pandas, aby użyć popularnych bibliotek kreślenia bibliotek pandas.
Napiwek
W przypadku dużego zestawu danych może być konieczne załadowanie części tego zestawu danych.
data = spark.read.format("delta").load("Tables/predictive_maintenance_data")
SEED = 1234
df = data.toPandas()
df.drop(['UDI', 'Product_ID'],axis=1,inplace=True)
# Rename the Target column to IsFail
df = df.rename(columns = {'Target': "IsFail"})
df.info()
Przekonwertuj określone kolumny zestawu danych na liczby zmiennoprzecinkowe lub typy całkowite zgodnie z potrzebami, a ciągi mapy (, , ) na wartości liczbowe ('L'0, 1, 2): 'H''M'
# Convert temperature, rotational speed, torque, and tool wear columns to float
df['Air_temperature_[K]'] = df['Air_temperature_[K]'].astype(float)
df['Process_temperature_[K]'] = df['Process_temperature_[K]'].astype(float)
df['Rotational_speed_[rpm]'] = df['Rotational_speed_[rpm]'].astype(float)
df['Torque_[Nm]'] = df['Torque_[Nm]'].astype(float)
df['Tool_wear_[min]'] = df['Tool_wear_[min]'].astype(float)
# Convert the 'Target' column to an integer
df['IsFail'] = df['IsFail'].astype(int)
# Map 'L', 'M', 'H' to numerical values
df['Type'] = df['Type'].map({'L': 0, 'M': 1, 'H': 2})
Eksplorowanie danych za pomocą wizualizacji
# Import packages and set plotting style
import seaborn as sns
import matplotlib.pyplot as plt
import pandas as pd
sns.set_style('darkgrid')
# Create the correlation matrix
corr_matrix = df.corr(numeric_only=True)
# Plot a heatmap
plt.figure(figsize=(10, 8))
sns.heatmap(corr_matrix, annot=True)
plt.show()
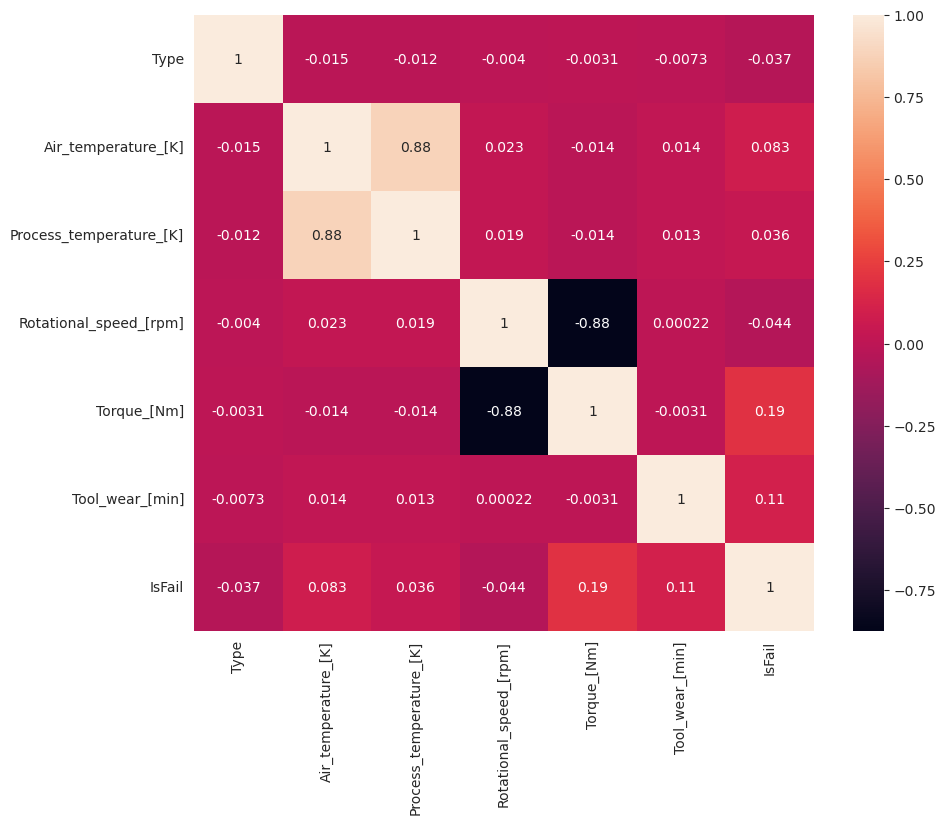
Zgodnie z oczekiwaniami błąd (IsFail) jest skorelowany z wybranymi funkcjami (kolumnami). Macierz korelacji pokazuje, że Air_temperaturewartości , Process_temperature, Rotational_speed, Torquei Tool_wear mają najwyższą korelację ze zmienną IsFail .
# Plot histograms of select features
fig, axes = plt.subplots(2, 3, figsize=(18,10))
columns = ['Air_temperature_[K]', 'Process_temperature_[K]', 'Rotational_speed_[rpm]', 'Torque_[Nm]', 'Tool_wear_[min]']
data=df.copy()
for ind, item in enumerate (columns):
column = columns[ind]
df_column = data[column]
df_column.hist(ax = axes[ind%2][ind//2], bins=32).set_title(item)
fig.supylabel('count')
fig.subplots_adjust(hspace=0.2)
fig.delaxes(axes[1,2])
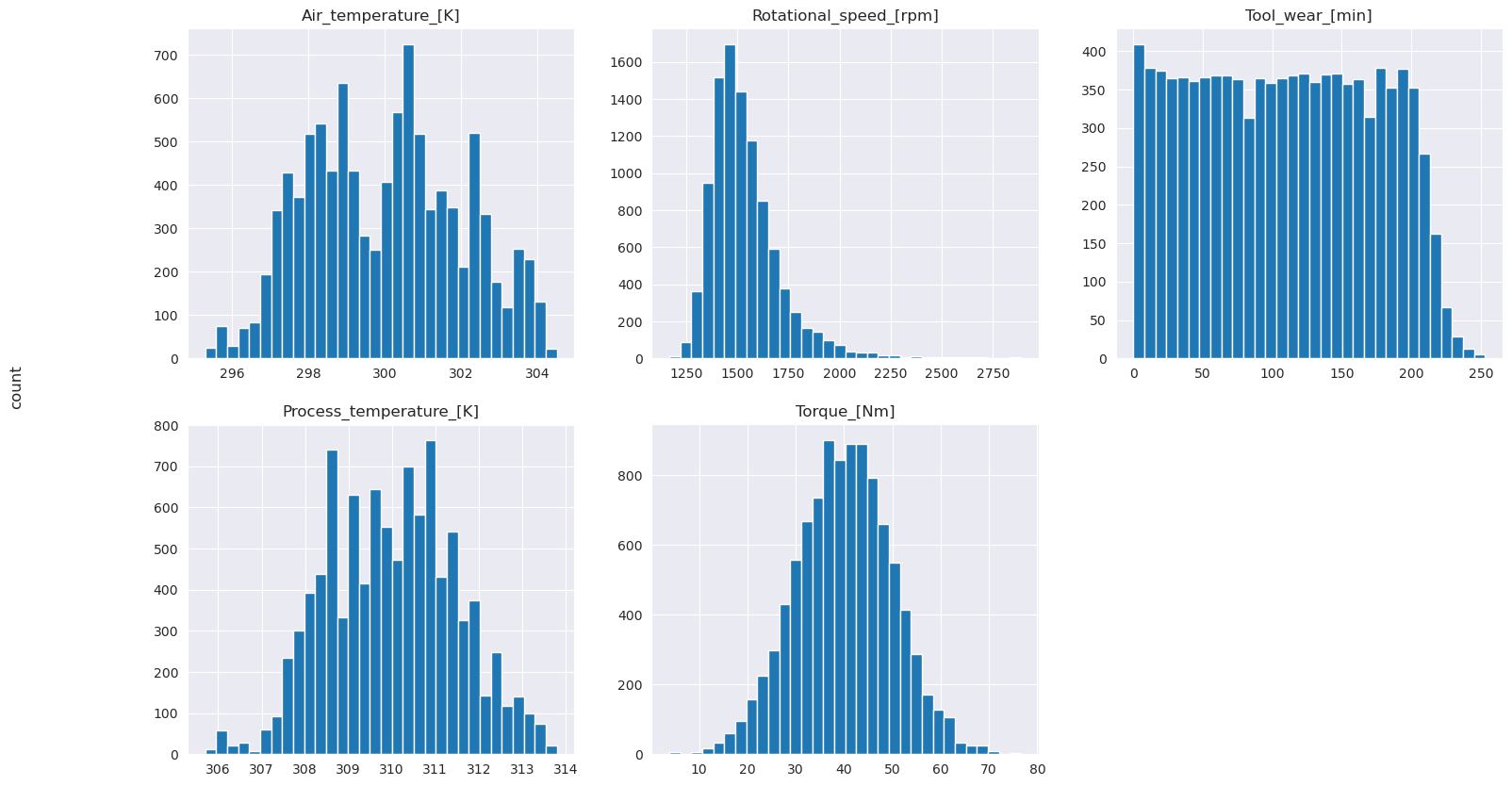
Jak pokazują wykresy wykresów, Air_temperaturezmienne , Process_temperature, Rotational_speed, Torquei Tool_wear nie są rozrzedzone. Wydają się mieć dobrą ciągłość w przestrzeni funkcji. Te wykresy potwierdzają, że trenowanie modelu uczenia maszynowego na tym zestawie danych prawdopodobnie daje wiarygodne wyniki, które mogą uogólnić nowy zestaw danych.
Sprawdzanie zmiennej docelowej pod kątem dysproporcji klas
Zlicz liczbę próbek dla maszyn zakończonych niepowodzeniem i niezafałszowanych oraz sprawdź saldo danych dla każdej klasy (IsFail=0, IsFail=1):
# Plot the counts for no failure and each failure type
plt.figure(figsize=(12, 2))
ax = sns.countplot(x='Failure_Type', data=df)
for p in ax.patches:
ax.annotate(f'{p.get_height()}', (p.get_x()+0.4, p.get_height()+50))
plt.show()
# Plot the counts for no failure versus the sum of all failure types
plt.figure(figsize=(4, 2))
ax = sns.countplot(x='IsFail', data=df)
for p in ax.patches:
ax.annotate(f'{p.get_height()}', (p.get_x()+0.4, p.get_height()+50))
plt.show()
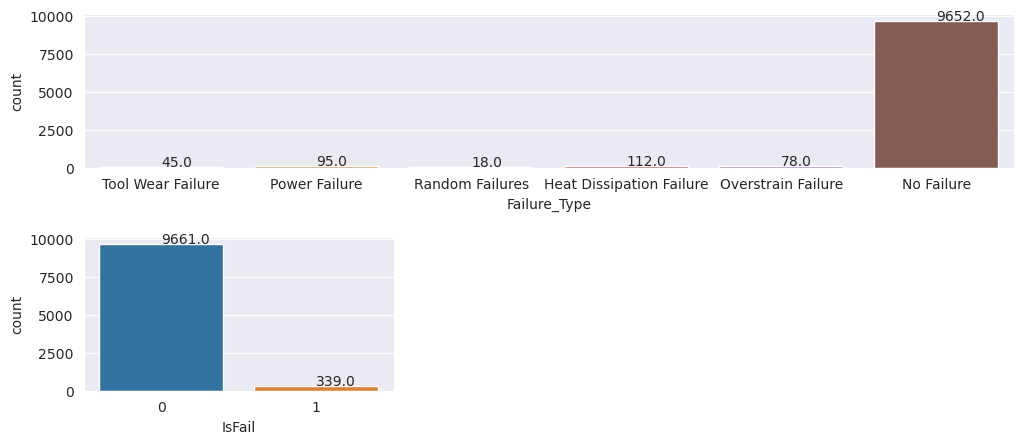
Wykresy wskazują, że klasa no-failure (pokazana na IsFail=0 drugim wykresie) stanowi większość próbek. Użyj techniki oversampling, aby utworzyć bardziej zrównoważony zestaw danych trenowania:
# Separate features and target
features = df[['Type', 'Air_temperature_[K]', 'Process_temperature_[K]', 'Rotational_speed_[rpm]', 'Torque_[Nm]', 'Tool_wear_[min]']]
labels = df['IsFail']
# Split the dataset into the training and testing sets
from sklearn.model_selection import train_test_split
X_train, X_test, y_train, y_test = train_test_split(features, labels, test_size=0.2, random_state=42)
# Ignore warnings
import warnings
warnings.filterwarnings('ignore')
# Save test data to the lakehouse for use in future sections
table_name = "predictive_maintenance_test_data"
df_test_X = spark.createDataFrame(X_test)
df_test_X.write.mode("overwrite").format("delta").save(f"Tables/{table_name}")
print(f"Spark DataFrame saved to delta table: {table_name}")
Oversample to balance classes in the training dataset (Przeładowanie klas w zestawie danych trenowania)
Poprzednia analiza wykazała, że zestaw danych jest wysoce niezrównoważony. Nierównowaga ta staje się problemem, ponieważ klasa mniejszości ma zbyt mało przykładów dla modelu, aby skutecznie nauczyć się granicy decyzyjnej.
SMOTE może rozwiązać problem. SMOTE to powszechnie używana technika oversampling, która generuje syntetyczne przykłady. Generuje przykłady dla klasy mniejszości na podstawie odległości euklidianu między punktami danych. Ta metoda różni się od losowego przewróbkowania, ponieważ tworzy nowe przykłady, które nie tylko duplikują klasę mniejszości. Metoda staje się bardziej efektywną techniką obsługi niezrównoważonych zestawów danych.
# Disable MLflow autologging because you don't want to track SMOTE fitting
import mlflow
mlflow.autolog(disable=True)
from imblearn.combine import SMOTETomek
smt = SMOTETomek(random_state=SEED)
X_train_res, y_train_res = smt.fit_resample(X_train, y_train)
# Plot the counts for both classes
plt.figure(figsize=(4, 2))
ax = sns.countplot(x='IsFail', data=pd.DataFrame({'IsFail': y_train_res.values}))
for p in ax.patches:
ax.annotate(f'{p.get_height()}', (p.get_x()+0.4, p.get_height()+50))
plt.show()
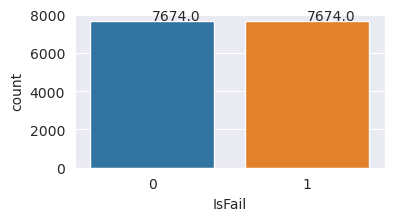
Pomyślnie zrównoważyliśmy zestaw danych. Teraz możesz przejść do trenowania modelu.
Krok 4. Trenowanie i ocenianie modeli
MLflow rejestruje modele, trenuje i porównuje różne modele oraz wybiera najlepszy model do celów przewidywania. Do trenowania modeli można użyć następujących trzech modeli:
- Klasyfikator lasu losowego
- Klasyfikator regresji logistycznej
- Klasyfikator XGBoost
Trenowanie klasyfikatora lasu losowego
import numpy as np
from sklearn.ensemble import RandomForestClassifier
from mlflow.models.signature import infer_signature
from sklearn.metrics import f1_score, accuracy_score, recall_score
mlflow.set_experiment("Machine_Failure_Classification")
mlflow.autolog(exclusive=False) # This is needed to override the preconfigured autologging behavior
with mlflow.start_run() as run:
rfc_id = run.info.run_id
print(f"run_id {rfc_id}, status: {run.info.status}")
rfc = RandomForestClassifier(max_depth=5, n_estimators=50)
rfc.fit(X_train_res, y_train_res)
signature = infer_signature(X_train_res, y_train_res)
mlflow.sklearn.log_model(
rfc,
"machine_failure_model_rf",
signature=signature,
registered_model_name="machine_failure_model_rf"
)
y_pred_train = rfc.predict(X_train)
# Calculate the classification metrics for test data
f1_train = f1_score(y_train, y_pred_train, average='weighted')
accuracy_train = accuracy_score(y_train, y_pred_train)
recall_train = recall_score(y_train, y_pred_train, average='weighted')
# Log the classification metrics to MLflow
mlflow.log_metric("f1_score_train", f1_train)
mlflow.log_metric("accuracy_train", accuracy_train)
mlflow.log_metric("recall_train", recall_train)
# Print the run ID and the classification metrics
print("F1 score_train:", f1_train)
print("Accuracy_train:", accuracy_train)
print("Recall_train:", recall_train)
y_pred_test = rfc.predict(X_test)
# Calculate the classification metrics for test data
f1_test = f1_score(y_test, y_pred_test, average='weighted')
accuracy_test = accuracy_score(y_test, y_pred_test)
recall_test = recall_score(y_test, y_pred_test, average='weighted')
# Log the classification metrics to MLflow
mlflow.log_metric("f1_score_test", f1_test)
mlflow.log_metric("accuracy_test", accuracy_test)
mlflow.log_metric("recall_test", recall_test)
# Print the classification metrics
print("F1 score_test:", f1_test)
print("Accuracy_test:", accuracy_test)
print("Recall_test:", recall_test)
Z danych wyjściowych zarówno zestawy danych treningowych, jak i testowych dają wynik F1, dokładność i kompletność około 0,9 podczas korzystania z klasyfikatora lasu losowego.
Trenowanie klasyfikatora regresji logistycznej
from sklearn.linear_model import LogisticRegression
with mlflow.start_run() as run:
lr_id = run.info.run_id
print(f"run_id {lr_id}, status: {run.info.status}")
lr = LogisticRegression(random_state=42)
lr.fit(X_train_res, y_train_res)
signature = infer_signature(X_train_res, y_train_res)
mlflow.sklearn.log_model(
lr,
"machine_failure_model_lr",
signature=signature,
registered_model_name="machine_failure_model_lr"
)
y_pred_train = lr.predict(X_train)
# Calculate the classification metrics for training data
f1_train = f1_score(y_train, y_pred_train, average='weighted')
accuracy_train = accuracy_score(y_train, y_pred_train)
recall_train = recall_score(y_train, y_pred_train, average='weighted')
# Log the classification metrics to MLflow
mlflow.log_metric("f1_score_train", f1_train)
mlflow.log_metric("accuracy_train", accuracy_train)
mlflow.log_metric("recall_train", recall_train)
# Print the run ID and the classification metrics
print("F1 score_train:", f1_train)
print("Accuracy_train:", accuracy_train)
print("Recall_train:", recall_train)
y_pred_test = lr.predict(X_test)
# Calculate the classification metrics for test data
f1_test = f1_score(y_test, y_pred_test, average='weighted')
accuracy_test = accuracy_score(y_test, y_pred_test)
recall_test = recall_score(y_test, y_pred_test, average='weighted')
# Log the classification metrics to MLflow
mlflow.log_metric("f1_score_test", f1_test)
mlflow.log_metric("accuracy_test", accuracy_test)
mlflow.log_metric("recall_test", recall_test)
Trenowanie klasyfikatora XGBoost
from xgboost import XGBClassifier
with mlflow.start_run() as run:
xgb = XGBClassifier()
xgb_id = run.info.run_id
print(f"run_id {xgb_id}, status: {run.info.status}")
xgb.fit(X_train_res.to_numpy(), y_train_res.to_numpy())
signature = infer_signature(X_train_res, y_train_res)
mlflow.xgboost.log_model(
xgb,
"machine_failure_model_xgb",
signature=signature,
registered_model_name="machine_failure_model_xgb"
)
y_pred_train = xgb.predict(X_train)
# Calculate the classification metrics for training data
f1_train = f1_score(y_train, y_pred_train, average='weighted')
accuracy_train = accuracy_score(y_train, y_pred_train)
recall_train = recall_score(y_train, y_pred_train, average='weighted')
# Log the classification metrics to MLflow
mlflow.log_metric("f1_score_train", f1_train)
mlflow.log_metric("accuracy_train", accuracy_train)
mlflow.log_metric("recall_train", recall_train)
# Print the run ID and the classification metrics
print("F1 score_train:", f1_train)
print("Accuracy_train:", accuracy_train)
print("Recall_train:", recall_train)
y_pred_test = xgb.predict(X_test)
# Calculate the classification metrics for test data
f1_test = f1_score(y_test, y_pred_test, average='weighted')
accuracy_test = accuracy_score(y_test, y_pred_test)
recall_test = recall_score(y_test, y_pred_test, average='weighted')
# Log the classification metrics to MLflow
mlflow.log_metric("f1_score_test", f1_test)
mlflow.log_metric("accuracy_test", accuracy_test)
mlflow.log_metric("recall_test", recall_test)
Krok 5. Wybieranie najlepszego modelu i przewidywanie danych wyjściowych
W poprzedniej sekcji wyszkoliliśmy trzy różne klasyfikatory: las losowy, regresję logistyczną i bibliotekę XGBoost. Teraz masz możliwość programowego uzyskiwania dostępu do wyników lub używania interfejsu użytkownika.
W przypadku opcji Ścieżka interfejsu użytkownika przejdź do obszaru roboczego i przefiltruj modele.
Wybierz poszczególne modele, aby uzyskać szczegółowe informacje o wydajności modelu.
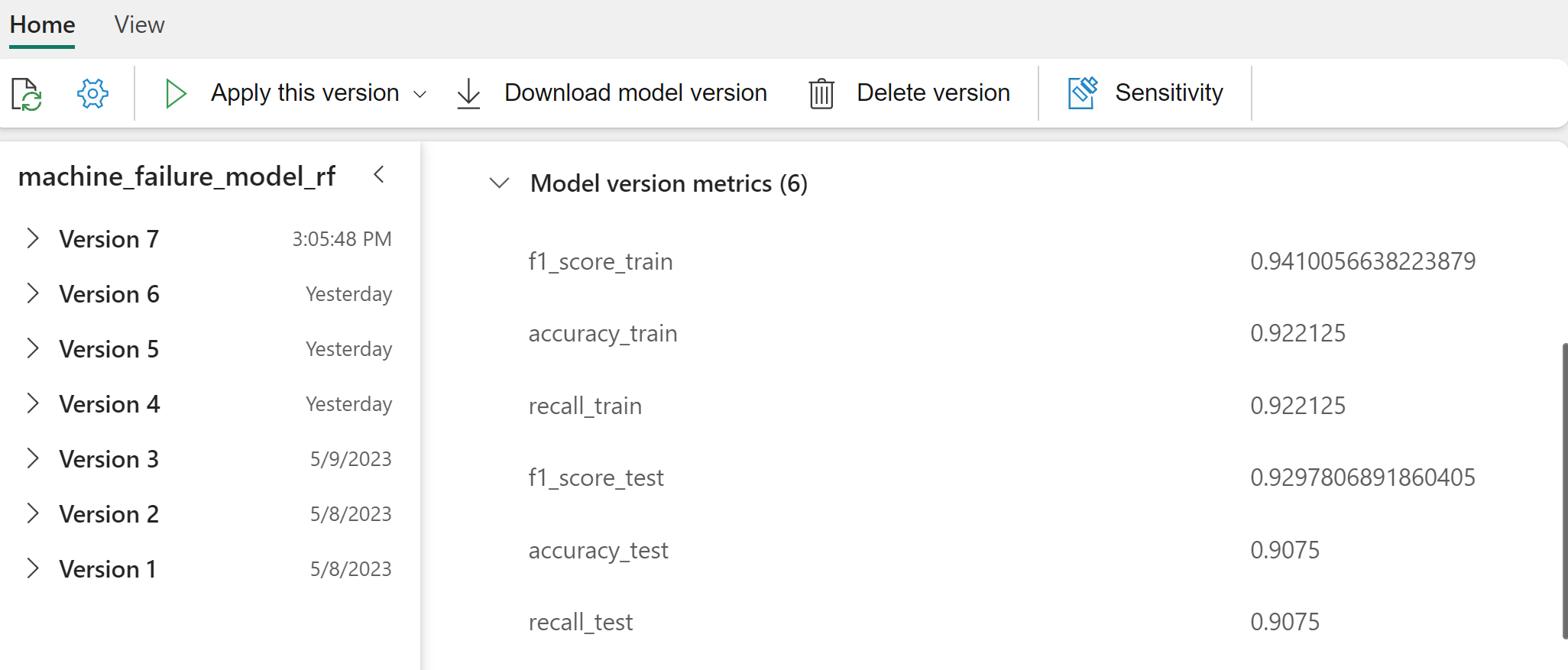
W tym przykładzie pokazano, jak programowo uzyskać dostęp do modeli za pośrednictwem biblioteki MLflow:
runs = {'random forest classifier': rfc_id,
'logistic regression classifier': lr_id,
'xgboost classifier': xgb_id}
# Create an empty DataFrame to hold the metrics
df_metrics = pd.DataFrame()
# Loop through the run IDs and retrieve the metrics for each run
for run_name, run_id in runs.items():
metrics = mlflow.get_run(run_id).data.metrics
metrics["run_name"] = run_name
df_metrics = df_metrics.append(metrics, ignore_index=True)
# Print the DataFrame
print(df_metrics)
Chociaż biblioteka XGBoost daje najlepsze wyniki w zestawie treningowym, działa źle na zestawie danych testowych. Ta niska wydajność wskazuje na nadmierne dopasowanie. Klasyfikator regresji logistycznej działa słabo zarówno na zestawach danych szkoleniowych, jak i testowych. Ogólnie rzecz biorąc, losowy las osiąga dobrą równowagę między wydajnością treningu a unikaniem nadmiernego dopasowania.
W następnej sekcji wybierz zarejestrowany model lasu losowego i wykonaj przewidywanie za pomocą funkcji PREDICT :
from synapse.ml.predict import MLFlowTransformer
model = MLFlowTransformer(
inputCols=list(X_test.columns),
outputCol='predictions',
modelName='machine_failure_model_rf',
modelVersion=1
)
Za pomocą utworzonego MLFlowTransformer obiektu w celu załadowania modelu do wnioskowania użyj interfejsu API przekształcania, aby ocenić model w testowym zestawie danych:
predictions = model.transform(spark.createDataFrame(X_test))
predictions.show()
W tej tabeli przedstawiono dane wyjściowe:
| Typ | Air_temperature_[K] | Process_temperature_[K] | Rotational_speed_[rpm] | Torque_[Nm] | Tool_wear_[min] | Prognoz |
|---|---|---|---|---|---|---|
| 0 | 300.6 | 309.7 | 1639,0 | 30,4 | 121.0 | 0 |
| 0 | 303.9 | 313.0 | 1551.0 | 36,8 | 140.0 | 0 |
| 1 | 299.1 | 308.6 | 1491.0 | 38.5 | 166.0 | 0 |
| 0 | 300.9 | 312.1 | 1359.0 | 51.7 | 146.0 | 1 |
| 0 | 303.7 | 312.6 | 1621.0 | 38,8 | 182.0 | 0 |
| 0 | 299.0 | 310.3 | 1868.0 | 24,0 | 221.0 | 1 |
| 2 | 297.8 | 307.5 | 1631,0 | 31,3 | 124.0 | 0 |
| 0 | 297.5 | 308.2 | 1327.0 | 56.5 | 189.0 | 1 |
| 0 | 301.3 | 310.3 | 1460.0 | 41.5 | 197.0 | 0 |
| 2 | 297.6 | 309.0 | 1413.0 | 40.2 | 51,0 | 0 |
| 1 | 300.9 | 309.4 | 1724.0 | 25,6 | 119.0 | 0 |
| 0 | 303.3 | 311.3 | 1389.0 | 53.9 | 39.0 | 0 |
| 0 | 298.4 | 307.9 | 1981.0 | 23.2 | 16.0 | 0 |
| 0 | 299.3 | 308.8 | 1636.0 | 29,9 | 201.0 | 0 |
| 1 | 298.1 | 309.2 | 1460.0 | 45.8 | 80.0 | 0 |
| 0 | 300.0 | 309.5 | 1728.0 | 26,0 | 37,0 | 0 |
| 2 | 299.0 | 308.7 | 1940.0 | 19.9 | 98.0 | 0 |
| 0 | 302.2 | 310.8 | 1383.0 | 46.9 | 45.0 | 0 |
| 0 | 300.2 | 309.2 | 1431,0 | 51.3 | 57,0 | 0 |
| 0 | 299.6 | 310.2 | 1468,0 | 48,0 | 9.0 | 0 |
Zapisz dane w lakehouse. Następnie dane staną się dostępne do późniejszego użycia — na przykład pulpit nawigacyjny usługi Power BI.
# Save test data to the lakehouse for use in the next section.
table_name = "predictive_maintenance_test_with_predictions"
predictions.write.mode("overwrite").format("delta").save(f"Tables/{table_name}")
print(f"Spark DataFrame saved to delta table: {table_name}")
Krok 6. Wyświetlanie analizy biznesowej za pomocą wizualizacji w usłudze Power BI
Pokaż wyniki w formacie offline z pulpitem nawigacyjnym usługi Power BI.
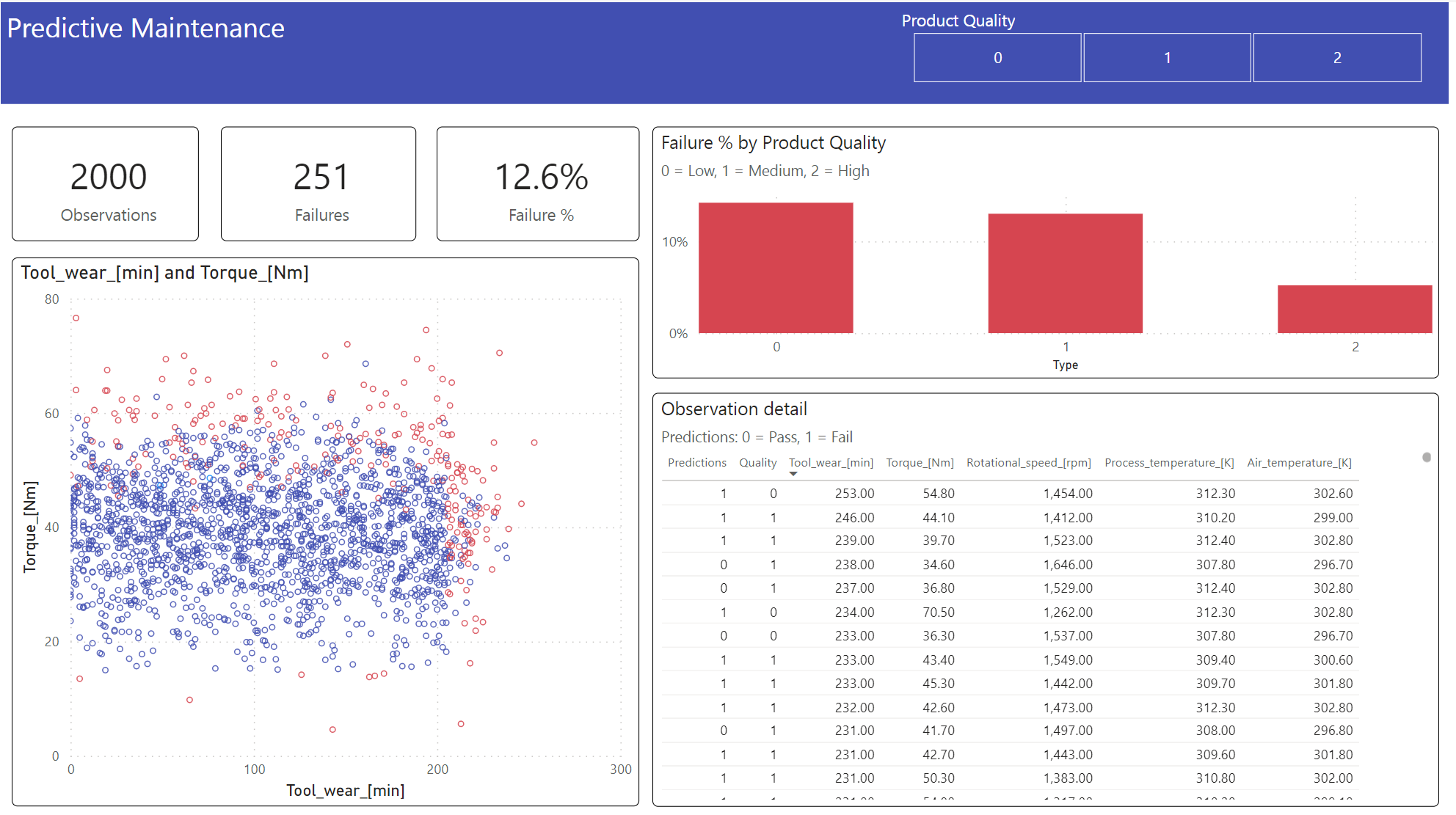
Na pulpicie nawigacyjnym pokazano, że Tool_wear i Torque utworzyć zauważalną granicę między przypadkami, które zakończyły się niepowodzeniem i niezafałszowanym przypadkiem, zgodnie z oczekiwaniami z wcześniejszej analizy korelacji w kroku 2.