Samouczek: tworzenie, ocena i walidacja modelu przewidywania odejścia klientów
Ten samouczek przedstawia pełny przykład przepływu pracy analizy danych usługi Synapse w usłudze Microsoft Fabric. Scenariusz tworzy model, aby przewidzieć, czy klienci bankowi rezygnują, czy nie. Wskaźnik churn lub wskaźnik odpływu dotyczy tempa, w jakim klienci bankowi rezygnują z usług banku.
Samouczek obejmuje następujące kroki:
- Instalowanie bibliotek niestandardowych
- Ładowanie danych
- Zrozumienie i przetwarzanie danych poprzez eksploracyjną analizę danych oraz pokazanie użycia funkcji Fabric Data Wrangler
- Użyj bibliotek scikit-learn i LightGBM do trenowania modeli uczenia maszynowego oraz śledzenia eksperymentów za pomocą funkcji autologowania MLflow i Fabric.
- Ocenianie i zapisywanie końcowego modelu uczenia maszynowego
- Wyświetlanie wydajności modelu za pomocą wizualizacji usługi Power BI
Warunki wstępne
Pobierz subskrypcję usługi Microsoft Fabric . Możesz też utworzyć bezpłatne konto wersji próbnej usługi Microsoft Fabric.
Zaloguj się do usługi Microsoft Fabric.
Użyj przełącznika doświadczenia w lewej dolnej części strony głównej, aby przełączyć się na Fabric.

- W razie potrzeby utwórz magazyn lakehouse usługi Microsoft Fabric zgodnie z opisem w Tworzenie magazynu lakehouse w usłudze Microsoft Fabric.
Śledź w zeszycie
Możesz wybrać jedną z tych opcji, aby śledzić w notesie:
- Otwórz i uruchom wbudowany notes.
- Prześlij swój notatnik z usługi GitHub.
Otwieranie wbudowanego notesu
W tym samouczku towarzyszy przykładowy notatnik odpływu klientów.
Aby otworzyć przykładowy notatnik na potrzeby tego samouczka, postępuj zgodnie z instrukcjami w Przygotuj system do samouczków dotyczących nauki o danych.
Przed rozpoczęciem uruchamiania kodu upewnij się, że dołącz magazyn typu lakehouse do notesu.
Importowanie notesu z usługi GitHub
Notes AIsample — Bank Customer Churn.ipynb towarzyszy temu samouczkowi.
Aby otworzyć towarzyszący notatnik na potrzeby tego samouczka, postępuj zgodnie z instrukcjami w sekcji Przygotowanie systemu do samouczków z nauki o danych, aby zaimportować notatnik do swojego obszaru roboczego.
Jeśli wolisz skopiować i wkleić kod z tej strony, możesz utworzyć nowy notes.
Przed rozpoczęciem uruchamiania kodu pamiętaj, aby dołączyć magazyn lakehouse do notesu.
Krok 1. Instalowanie bibliotek niestandardowych
W przypadku tworzenia modeli uczenia maszynowego lub analizy danych ad hoc może być konieczne szybkie zainstalowanie biblioteki niestandardowej na potrzeby sesji platformy Apache Spark. Dostępne są dwie opcje instalowania bibliotek.
- Użyj funkcji instalacji wbudowanej w notatnik (
%piplub%conda), aby zainstalować bibliotekę wyłącznie w bieżącym notatniku. - Alternatywnie możesz utworzyć środowisko Fabric, zainstalować biblioteki ze źródeł publicznych lub przekazać do niego biblioteki niestandardowe, a następnie administrator obszaru roboczego może ustawić środowisko jako domyślne dla obszaru roboczego. Wszystkie biblioteki w środowisku staną się następnie dostępne do użycia w dowolnych notesach i definicjach zadań platformy Spark w obszarze roboczym. Aby uzyskać więcej informacji na temat środowisk, zobacz jak tworzyć, konfigurować i używać środowiska w usłudze Microsoft Fabric.
Na potrzeby tego samouczka użyj %pip install, aby zainstalować bibliotekę imblearn w notesie.
Notatka
Jądro PySpark jest uruchamiane ponownie po uruchomieniu %pip install. Zainstaluj wymagane biblioteki przed uruchomieniem innych komórek.
# Use pip to install libraries
%pip install imblearn
Krok 2. Ładowanie danych
Zestaw danych w churn.csv zawiera status odejścia 10 000 klientów oraz 14 atrybutów, które obejmują:
- Ocena kredytowa
- Lokalizacja geograficzna (Niemcy, Francja, Hiszpania)
- Płeć (mężczyzna, kobieta)
- Wiek
- Kadencja (liczba lat, w których dana osoba była klientem w tym banku)
- Saldo konta
- Szacowane wynagrodzenie
- Liczba produktów zakupionych przez klienta za pośrednictwem banku
- Stan karty kredytowej (niezależnie od tego, czy klient ma kartę kredytową)
- Stan aktywnego członka (niezależnie od tego, czy dana osoba jest aktywnym klientem banku)
Zestaw danych zawiera również kolumny: numer wiersza, identyfikator klienta i nazwisko klienta. Wartości w tych kolumnach nie powinny mieć wpływu na decyzję klienta o opuszczeniu banku.
Zdarzenie zamknięcia konta bankowego klienta definiuje utratę klienta. Kolumna Exited zestawu danych odnosi się do odejścia klienta. Ponieważ mamy niewielki kontekst dotyczący tych atrybutów, nie potrzebujemy podstawowych informacji o zestawie danych. Chcemy zrozumieć, jak te atrybuty przyczyniają się do stanu Exited.
Spośród tych 10 000 klientów tylko 2037 klientów (około 20%) opuściło bank. Ze względu na współczynnik dysproporcji klas zaleca się generowanie danych syntetycznych. Dokładność macierzy pomyłek może nie mieć znaczenia dla niezrównoważonych klasyfikacji. Możemy chcieć zmierzyć dokładność przy użyciu obszaru pod krzywą Precision-Recall (AUPRC).
- W tej tabeli przedstawiono podgląd danych
churn.csv:
| Identyfikator klienta | Nazwisko | KredytScore | Geografia | Płeć | Wiek | Stanowisko | Saldo | NumOfProducts | HasCrCard | CzyAktywnyCzłonek | Szacowana pensja | Opuszczony |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 15634602 | Hargrave | 619 | Francja | Kobieta | 42 | 2 | 0.00 | 1 | 1 | 1 | 101348.88 | 1 |
| 15647311 | Wzgórze | 608 | Hiszpania | Kobieta | 41 | 1 | 83807.86 | 1 | 0 | 1 | 112542.58 | 0 |
Pobierz zestaw danych i prześlij do Lakehouse.
Zdefiniuj te parametry, aby można było używać tego notesu z różnymi zestawami danych:
IS_CUSTOM_DATA = False # If TRUE, the dataset has to be uploaded manually
IS_SAMPLE = False # If TRUE, use only SAMPLE_ROWS of data for training; otherwise, use all data
SAMPLE_ROWS = 5000 # If IS_SAMPLE is True, use only this number of rows for training
DATA_ROOT = "/lakehouse/default"
DATA_FOLDER = "Files/churn" # Folder with data files
DATA_FILE = "churn.csv" # Data file name
Ten kod pobiera publicznie dostępną wersję zestawu danych, a następnie przechowuje ten zestaw danych w usłudze Fabric Lakehouse:
Ważny
Dodaj lakehouse do zeszytu przed jego uruchomieniem. Niepowodzenie w tym celu spowoduje wystąpienie błędu.
import os, requests
if not IS_CUSTOM_DATA:
# With an Azure Synapse Analytics blob, this can be done in one line
# Download demo data files into the lakehouse if they don't exist
remote_url = "https://synapseaisolutionsa.blob.core.windows.net/public/bankcustomerchurn"
file_list = ["churn.csv"]
download_path = "/lakehouse/default/Files/churn/raw"
if not os.path.exists("/lakehouse/default"):
raise FileNotFoundError(
"Default lakehouse not found, please add a lakehouse and restart the session."
)
os.makedirs(download_path, exist_ok=True)
for fname in file_list:
if not os.path.exists(f"{download_path}/{fname}"):
r = requests.get(f"{remote_url}/{fname}", timeout=30)
with open(f"{download_path}/{fname}", "wb") as f:
f.write(r.content)
print("Downloaded demo data files into lakehouse.")
Rozpocznij rejestrowanie czasu potrzebnego do uruchomienia notesu:
# Record the notebook running time
import time
ts = time.time()
Odczyt danych surowych z lakehouse
Ten kod odczytuje nieprzetworzone dane z sekcji Files w Lakehouse i dodaje więcej kolumn dla różnych części daty. Tworzenie partycjonowanej tabeli Delta używa tych informacji.
df = (
spark.read.option("header", True)
.option("inferSchema", True)
.csv("Files/churn/raw/churn.csv")
.cache()
)
Tworzenie ramki danych pandas na podstawie zestawu danych
Ten kod konwertuje ramkę danych platformy Spark na ramkę danych biblioteki pandas, aby ułatwić przetwarzanie i wizualizację:
df = df.toPandas()
Krok 3. Wykonywanie eksploracyjnej analizy danych
Wyświetlanie danych pierwotnych
Eksploruj dane pierwotne za pomocą display, oblicz kilka podstawowych statystyk i wyświetl widoki wykresów. Najpierw należy zaimportować wymagane biblioteki do wizualizacji danych — na przykład seaborn. Seaborn to biblioteka wizualizacji danych języka Python, która udostępnia interfejs wysokiego poziomu umożliwiający tworzenie wizualizacji na ramkach danych i tablicach.
import seaborn as sns
sns.set_theme(style="whitegrid", palette="tab10", rc = {'figure.figsize':(9,6)})
import matplotlib.pyplot as plt
import matplotlib.ticker as mticker
from matplotlib import rc, rcParams
import numpy as np
import pandas as pd
import itertools
display(df, summary=True)
Wykonywanie początkowego czyszczenia danych przy użyciu narzędzia Data Wrangler
Uruchom narzędzie Data Wrangler bezpośrednio z notesu, aby eksplorować i przekształcać ramki danych biblioteki pandas. Wybierz listę rozwijaną Data Wrangler z poziomego paska narzędzi, aby przejrzeć aktywowane ramki danych pandas dostępne do edycji. Wybierz ramkę danych, którą chcesz otworzyć w narzędziu Data Wrangler.
Notatka
Nie można otworzyć Data Wrangler, gdy jądro notesu jest zajęte. Wykonanie komórki musi zakończyć się przed uruchomieniem narzędzia Data Wrangler. dowiedz się więcej o usłudze Data Wrangler.

Po uruchomieniu narzędzia Data Wrangler zostanie wygenerowane opisowe omówienie panelu danych, jak pokazano na poniższych obrazach. Omówienie zawiera informacje o wymiarze ramki danych, brakujących wartościach itp. Za pomocą narzędzia Data Wrangler można wygenerować skrypt, aby usunąć wiersze z brakującymi wartościami, zduplikowane wiersze i kolumny o określonych nazwach. Następnie możesz skopiować skrypt do komórki. Następna komórka pokazuje skopiowany skrypt.


def clean_data(df):
# Drop rows with missing data across all columns
df.dropna(inplace=True)
# Drop duplicate rows in columns: 'RowNumber', 'CustomerId'
df.drop_duplicates(subset=['RowNumber', 'CustomerId'], inplace=True)
# Drop columns: 'RowNumber', 'CustomerId', 'Surname'
df.drop(columns=['RowNumber', 'CustomerId', 'Surname'], inplace=True)
return df
df_clean = clean_data(df.copy())
Określanie atrybutów
Ten kod określa atrybuty kategorii, liczbowe i docelowe:
# Determine the dependent (target) attribute
dependent_variable_name = "Exited"
print(dependent_variable_name)
# Determine the categorical attributes
categorical_variables = [col for col in df_clean.columns if col in "O"
or df_clean[col].nunique() <=5
and col not in "Exited"]
print(categorical_variables)
# Determine the numerical attributes
numeric_variables = [col for col in df_clean.columns if df_clean[col].dtype != "object"
and df_clean[col].nunique() >5]
print(numeric_variables)
Pokaż podsumowanie z pięcioma liczbami
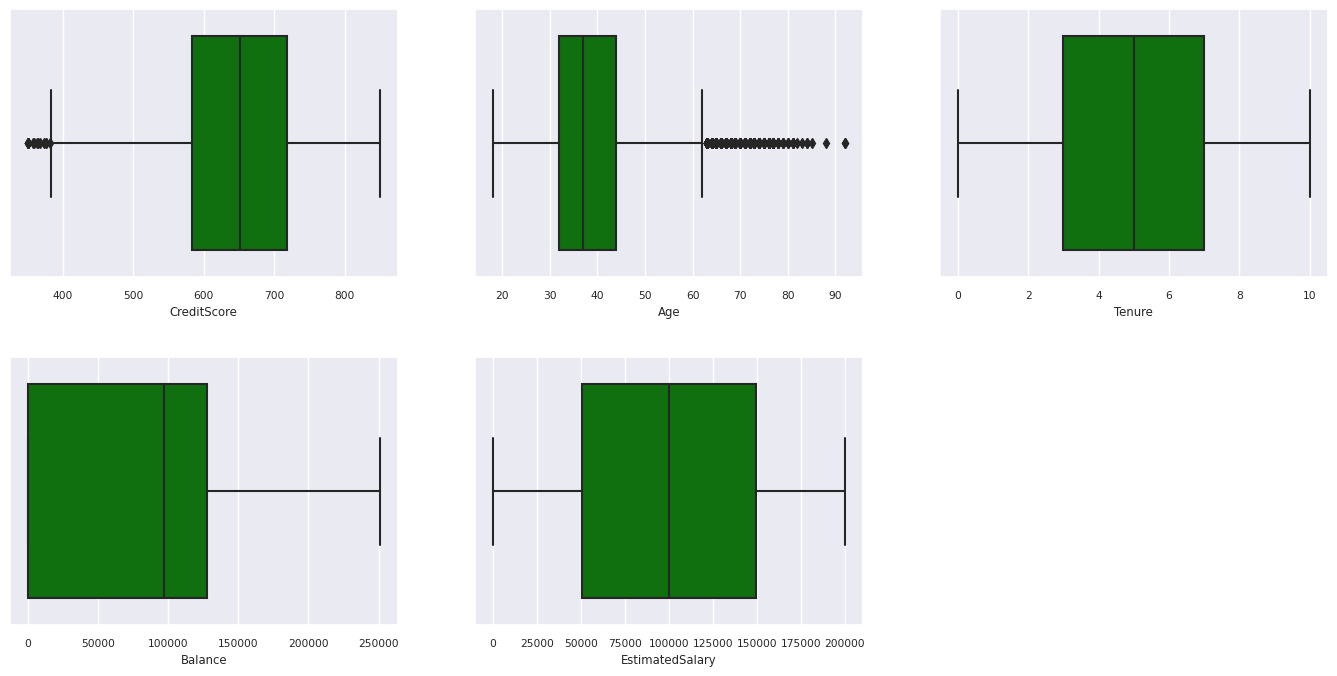
Użyj wykresów pól, aby wyświetlić podsumowanie z pięcioma liczbami
- minimalny wynik
- pierwszy kwartyl
- mediana
- trzeci kwartyl
- maksymalny wynik
dla atrybutów liczbowych.
df_num_cols = df_clean[numeric_variables]
sns.set(font_scale = 0.7)
fig, axes = plt.subplots(nrows = 2, ncols = 3, gridspec_kw = dict(hspace=0.3), figsize = (17,8))
fig.tight_layout()
for ax,col in zip(axes.flatten(), df_num_cols.columns):
sns.boxplot(x = df_num_cols[col], color='green', ax = ax)
# fig.suptitle('visualize and compare the distribution and central tendency of numerical attributes', color = 'k', fontsize = 12)
fig.delaxes(axes[1,2])
Pokaż rozmieszczenie utraconych i pozostających klientów
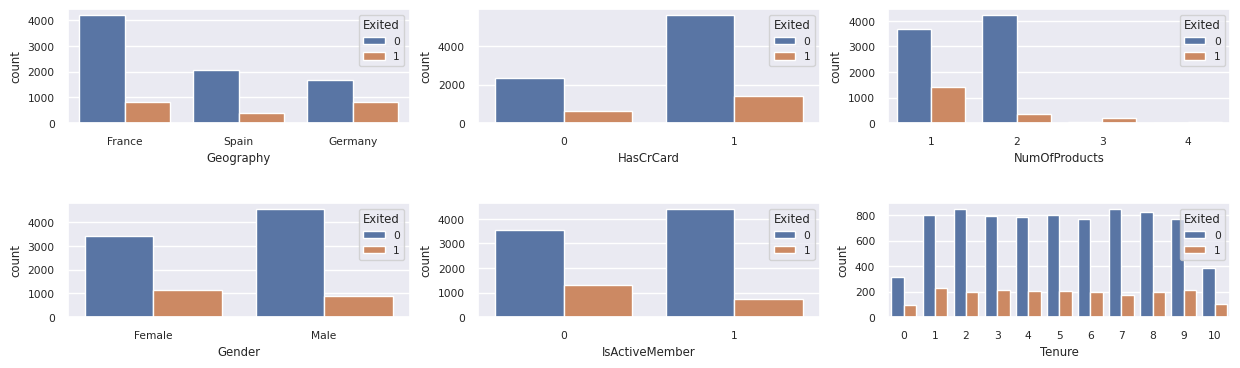
Pokaż dystrybucję klientów, którzy zrezygnowali, w porównaniu z tymi, którzy nie zrezygnowali, w odniesieniu do atrybutów kategorycznych.
attr_list = ['Geography', 'Gender', 'HasCrCard', 'IsActiveMember', 'NumOfProducts', 'Tenure']
fig, axarr = plt.subplots(2, 3, figsize=(15, 4))
for ind, item in enumerate (attr_list):
sns.countplot(x = item, hue = 'Exited', data = df_clean, ax = axarr[ind%2][ind//2])
fig.subplots_adjust(hspace=0.7)
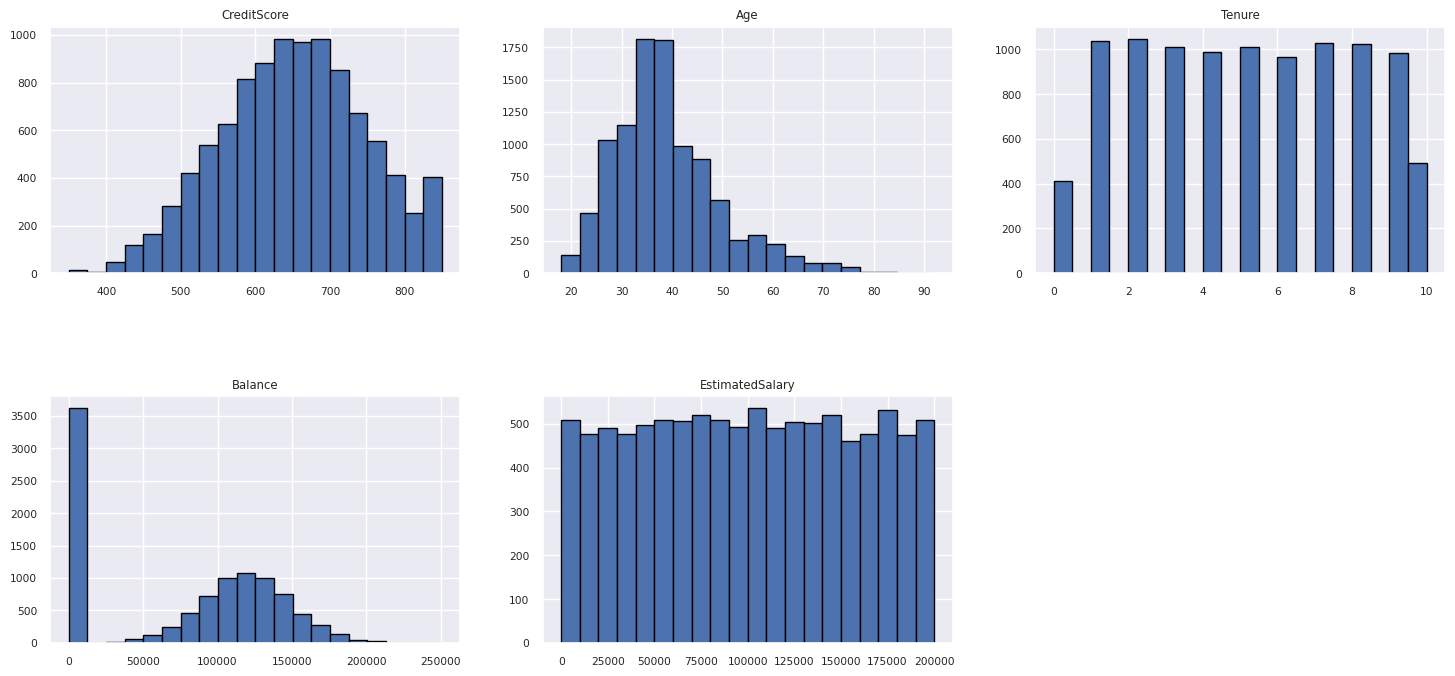
Pokaż rozkład atrybutów liczbowych
Użyj histogramu, aby wyświetlić rozkład częstotliwości atrybutów liczbowych:
columns = df_num_cols.columns[: len(df_num_cols.columns)]
fig = plt.figure()
fig.set_size_inches(18, 8)
length = len(columns)
for i,j in itertools.zip_longest(columns, range(length)):
plt.subplot((length // 2), 3, j+1)
plt.subplots_adjust(wspace = 0.2, hspace = 0.5)
df_num_cols[i].hist(bins = 20, edgecolor = 'black')
plt.title(i)
# fig = fig.suptitle('distribution of numerical attributes', color = 'r' ,fontsize = 14)
plt.show()
Wykonywanie inżynierii cech
Ta inżynieria cech generuje nowe atrybuty na podstawie bieżących atrybutów:
df_clean["NewTenure"] = df_clean["Tenure"]/df_clean["Age"]
df_clean["NewCreditsScore"] = pd.qcut(df_clean['CreditScore'], 6, labels = [1, 2, 3, 4, 5, 6])
df_clean["NewAgeScore"] = pd.qcut(df_clean['Age'], 8, labels = [1, 2, 3, 4, 5, 6, 7, 8])
df_clean["NewBalanceScore"] = pd.qcut(df_clean['Balance'].rank(method="first"), 5, labels = [1, 2, 3, 4, 5])
df_clean["NewEstSalaryScore"] = pd.qcut(df_clean['EstimatedSalary'], 10, labels = [1, 2, 3, 4, 5, 6, 7, 8, 9, 10])
Używanie narzędzia Data Wrangler do wykonywania kodowania jednorazowego
Korzystając z tych samych kroków, które omówiono wcześniej do uruchomienia narzędzia Data Wrangler, wykonaj kodowanie one-hot przy użyciu tego narzędzia. W tej komórce zostanie wyświetlony skopiowany skrypt wygenerowany na potrzeby kodowania jednokrotnego:


df_clean = pd.get_dummies(df_clean, columns=['Geography', 'Gender'])
Utwórz tabelę delta w celu wygenerowania raportu Power BI
table_name = "df_clean"
# Create a PySpark DataFrame from pandas
sparkDF=spark.createDataFrame(df_clean)
sparkDF.write.mode("overwrite").format("delta").save(f"Tables/{table_name}")
print(f"Spark DataFrame saved to delta table: {table_name}")
Podsumowanie obserwacji z eksploracyjnej analizy danych
- Większość klientów pochodzi z Francji. Hiszpania ma najniższy wskaźnik zmian, w porównaniu z Francją i Niemcami.
- Większość klientów ma karty kredytowe
- Niektórzy klienci mają zarówno ponad 60 lat, jak i wyniki kredytowe poniżej 400. Nie można ich jednak traktować jako wartości odstające
- Bardzo niewielu klientów ma więcej niż dwa produkty bankowe
- Nieaktywni klienci mają wyższy współczynnik zmian
- Płeć i czas użytkowania mają niewielki wpływ na decyzję klienta o zamknięciu konta bankowego
Krok 4: Przeprowadzanie trenowania i śledzenia modelu
Dzięki danym można teraz zdefiniować model. Zastosuj modele lasu losowego i LightGBM w tym notatniku.
Użyj bibliotek scikit-learn i LightGBM, aby zaimplementować modele z kilkoma wierszami kodu. Ponadto użyj autologowania MLflow i Fabric do śledzenia eksperymentów.
Ten przykładowy fragment kodu ładuje tabelę delta z lakehouse. Możesz użyć innych tabel różnicowych, które same korzystają z lakehouse jako źródła.
SEED = 12345
df_clean = spark.read.format("delta").load("Tables/df_clean").toPandas()
Generowanie eksperymentu na potrzeby śledzenia i rejestrowania modeli przy użyciu biblioteki MLflow
W tej sekcji przedstawiono sposób generowania eksperymentu oraz określa on parametry modelu i trenowania oraz metryki oceniania. Ponadto pokazuje, jak trenować modele, rejestrować je i zapisywać wytrenowane modele do późniejszego użycia.
import mlflow
# Set up the experiment name
EXPERIMENT_NAME = "sample-bank-churn-experiment" # MLflow experiment name
Automatyczne rejestrowanie automatycznie przechwytuje zarówno wartości parametrów wejściowych, jak i metryki wyjściowe modelu uczenia maszynowego, ponieważ ten model jest trenowany. Te informacje są następnie rejestrowane w obszarze roboczym, gdzie interfejsy API MLflow lub odpowiedni eksperyment w obszarze roboczym mogą uzyskiwać do niego dostęp i wizualizować je.
Po zakończeniu eksperyment przypomina ten obraz:

Wszystkie eksperymenty z odpowiednimi nazwami są rejestrowane i można śledzić ich parametry i metryki wydajności. Aby dowiedzieć się więcej na temat automatycznego rejestrowania, zobacz automatyczne rejestrowanie w usłudze Microsoft Fabric.
Ustawianie specyfikacji eksperymentu i automatycznego rejestrowania
mlflow.set_experiment(EXPERIMENT_NAME) # Use a date stamp to append to the experiment
mlflow.autolog(exclusive=False)
Importowanie biblioteki scikit-learn i lightGBM
# Import the required libraries for model training
from sklearn.model_selection import train_test_split
from lightgbm import LGBMClassifier
from sklearn.ensemble import RandomForestClassifier
from sklearn.metrics import accuracy_score, f1_score, precision_score, confusion_matrix, recall_score, roc_auc_score, classification_report
Przygotowywanie zestawów danych trenowania i testowania
y = df_clean["Exited"]
X = df_clean.drop("Exited",axis=1)
# Train/test separation
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.20, random_state=SEED)
Stosowanie narzędzia SMOTE do danych treningowych
Niezrównoważona klasyfikacja ma problem, ponieważ ma zbyt mało przykładów klasy mniejszości, aby model mógł skutecznie nauczyć się granicy decyzyjnej. Aby to zrobić, Syntetyczna technika mniejszościowego nadpróbkowania (SMOTE) jest najczęściej stosowaną metodą do syntezowania nowych próbek dla klasy mniejszościowej. Uzyskaj dostęp do narzędzia SMOTE przy użyciu biblioteki imblearn zainstalowanej w kroku 1.
Zastosuj smOTE tylko do zestawu danych szkoleniowych. Aby uzyskać prawidłowe przybliżenie działania modelu na oryginalnych danych, należy pozostawić zestaw danych testowych w jego pierwotnej, niezrównoważonej dystrybucji. Ten eksperyment reprezentuje sytuację w środowisku produkcyjnym.
from collections import Counter
from imblearn.over_sampling import SMOTE
sm = SMOTE(random_state=SEED)
X_res, y_res = sm.fit_resample(X_train, y_train)
new_train = pd.concat([X_res, y_res], axis=1)
Aby uzyskać więcej informacji, zobacz SMOTE i Od losowego nadpróbkowania do SMOTE i ADASYN. Witryna imbalanced-learn hostuje te zasoby.
Trenowanie modelu
Użyj Random Forest do wytrenowania modelu z maksymalną głębokością czterech i czterema cechami:
mlflow.sklearn.autolog(registered_model_name='rfc1_sm') # Register the trained model with autologging
rfc1_sm = RandomForestClassifier(max_depth=4, max_features=4, min_samples_split=3, random_state=1) # Pass hyperparameters
with mlflow.start_run(run_name="rfc1_sm") as run:
rfc1_sm_run_id = run.info.run_id # Capture run_id for model prediction later
print("run_id: {}; status: {}".format(rfc1_sm_run_id, run.info.status))
# rfc1.fit(X_train,y_train) # Imbalanced training data
rfc1_sm.fit(X_res, y_res.ravel()) # Balanced training data
rfc1_sm.score(X_test, y_test)
y_pred = rfc1_sm.predict(X_test)
cr_rfc1_sm = classification_report(y_test, y_pred)
cm_rfc1_sm = confusion_matrix(y_test, y_pred)
roc_auc_rfc1_sm = roc_auc_score(y_res, rfc1_sm.predict_proba(X_res)[:, 1])
Użyj algorytmu Random Forest do wytrenowania modelu z maksymalną głębokością ośmiu i sześcioma cechami.
mlflow.sklearn.autolog(registered_model_name='rfc2_sm') # Register the trained model with autologging
rfc2_sm = RandomForestClassifier(max_depth=8, max_features=6, min_samples_split=3, random_state=1) # Pass hyperparameters
with mlflow.start_run(run_name="rfc2_sm") as run:
rfc2_sm_run_id = run.info.run_id # Capture run_id for model prediction later
print("run_id: {}; status: {}".format(rfc2_sm_run_id, run.info.status))
# rfc2.fit(X_train,y_train) # Imbalanced training data
rfc2_sm.fit(X_res, y_res.ravel()) # Balanced training data
rfc2_sm.score(X_test, y_test)
y_pred = rfc2_sm.predict(X_test)
cr_rfc2_sm = classification_report(y_test, y_pred)
cm_rfc2_sm = confusion_matrix(y_test, y_pred)
roc_auc_rfc2_sm = roc_auc_score(y_res, rfc2_sm.predict_proba(X_res)[:, 1])
Trenowanie modelu za pomocą rozwiązania LightGBM:
# lgbm_model
mlflow.lightgbm.autolog(registered_model_name='lgbm_sm') # Register the trained model with autologging
lgbm_sm_model = LGBMClassifier(learning_rate = 0.07,
max_delta_step = 2,
n_estimators = 100,
max_depth = 10,
eval_metric = "logloss",
objective='binary',
random_state=42)
with mlflow.start_run(run_name="lgbm_sm") as run:
lgbm1_sm_run_id = run.info.run_id # Capture run_id for model prediction later
# lgbm_sm_model.fit(X_train,y_train) # Imbalanced training data
lgbm_sm_model.fit(X_res, y_res.ravel()) # Balanced training data
y_pred = lgbm_sm_model.predict(X_test)
accuracy = accuracy_score(y_test, y_pred)
cr_lgbm_sm = classification_report(y_test, y_pred)
cm_lgbm_sm = confusion_matrix(y_test, y_pred)
roc_auc_lgbm_sm = roc_auc_score(y_res, lgbm_sm_model.predict_proba(X_res)[:, 1])
Wyświetlanie artefaktu eksperymentu w celu śledzenia wydajności modelu
Przebiegi eksperymentu są automatycznie zapisywane w dokumentacji eksperymentu. Ten artefakt można znaleźć w obszarze roboczym. Nazwa artefaktu jest oparta na nazwie użytej do ustawienia eksperymentu. Wszystkie wytrenowane modele, ich przebiegi, metryki wydajności i parametry modelu są rejestrowane na stronie eksperymentu.
Aby obejrzeć eksperymenty:
- Na panelu po lewej stronie wybierz swój obszar roboczy.
- Znajdź i wybierz nazwę eksperymentu, w tym przypadku sample-bank-churn-experiment.
Krok 5. Ocena i zapisanie końcowego modelu uczenia maszynowego
Otwórz zapisany eksperyment z obszaru roboczego, aby wybrać i zapisać najlepszy model:
# Define run_uri to fetch the model
# MLflow client: mlflow.model.url, list model
load_model_rfc1_sm = mlflow.sklearn.load_model(f"runs:/{rfc1_sm_run_id}/model")
load_model_rfc2_sm = mlflow.sklearn.load_model(f"runs:/{rfc2_sm_run_id}/model")
load_model_lgbm1_sm = mlflow.lightgbm.load_model(f"runs:/{lgbm1_sm_run_id}/model")
Ocena wydajności zapisanych modeli w zestawie danych testowych
ypred_rfc1_sm = load_model_rfc1_sm.predict(X_test) # Random forest with maximum depth of 4 and 4 features
ypred_rfc2_sm = load_model_rfc2_sm.predict(X_test) # Random forest with maximum depth of 8 and 6 features
ypred_lgbm1_sm = load_model_lgbm1_sm.predict(X_test) # LightGBM
Pokaż prawdziwie/fałszywie dodatnie/ujemne wyniki przy użyciu macierzy pomyłek
Aby ocenić dokładność klasyfikacji, utwórz skrypt, który rysuje macierz pomyłek. Macierz pomyłek można również wykreślić przy użyciu narzędzi SynapseML, jak pokazano w przykładzie wykrywania oszustw .
def plot_confusion_matrix(cm, classes,
normalize=False,
title='Confusion matrix',
cmap=plt.cm.Blues):
print(cm)
plt.figure(figsize=(4,4))
plt.rcParams.update({'font.size': 10})
plt.imshow(cm, interpolation='nearest', cmap=cmap)
plt.title(title)
plt.colorbar()
tick_marks = np.arange(len(classes))
plt.xticks(tick_marks, classes, rotation=45, color="blue")
plt.yticks(tick_marks, classes, color="blue")
fmt = '.2f' if normalize else 'd'
thresh = cm.max() / 2.
for i, j in itertools.product(range(cm.shape[0]), range(cm.shape[1])):
plt.text(j, i, format(cm[i, j], fmt),
horizontalalignment="center",
color="red" if cm[i, j] > thresh else "black")
plt.tight_layout()
plt.ylabel('True label')
plt.xlabel('Predicted label')
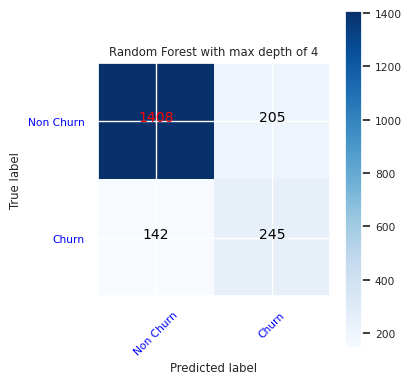
Utwórz macierz pomyłek dla klasyfikatora lasu losowego o maksymalnej głębokości czterech, z czterema cechami.
cfm = confusion_matrix(y_test, y_pred=ypred_rfc1_sm)
plot_confusion_matrix(cfm, classes=['Non Churn','Churn'],
title='Random Forest with max depth of 4')
tn, fp, fn, tp = cfm.ravel()
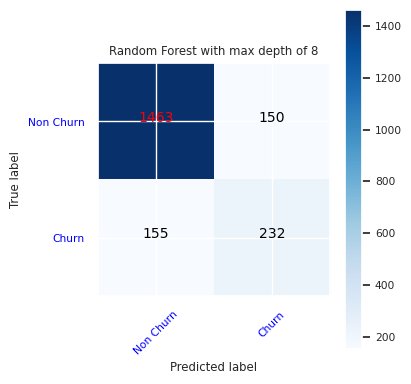
Utwórz macierz pomyłek dla klasyfikatora lasu losowego z maksymalną głębokością ośmiu, z sześcioma funkcjami:
cfm = confusion_matrix(y_test, y_pred=ypred_rfc2_sm)
plot_confusion_matrix(cfm, classes=['Non Churn','Churn'],
title='Random Forest with max depth of 8')
tn, fp, fn, tp = cfm.ravel()
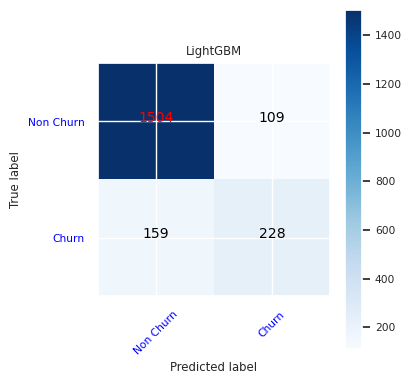
Utwórz macierz błędów dla modelu LightGBM.
cfm = confusion_matrix(y_test, y_pred=ypred_lgbm1_sm)
plot_confusion_matrix(cfm, classes=['Non Churn','Churn'],
title='LightGBM')
tn, fp, fn, tp = cfm.ravel()
Zapisywanie wyników dla usługi Power BI
Zapisz ramkę delta do Lakehouse, aby przenieść wyniki przewidywania modelu do wizualizacji w Power BI.
df_pred = X_test.copy()
df_pred['y_test'] = y_test
df_pred['ypred_rfc1_sm'] = ypred_rfc1_sm
df_pred['ypred_rfc2_sm'] =ypred_rfc2_sm
df_pred['ypred_lgbm1_sm'] = ypred_lgbm1_sm
table_name = "df_pred_results"
sparkDF=spark.createDataFrame(df_pred)
sparkDF.write.mode("overwrite").format("delta").option("overwriteSchema", "true").save(f"Tables/{table_name}")
print(f"Spark DataFrame saved to delta table: {table_name}")
Krok 6. Uzyskiwanie dostępu do wizualizacji w usłudze Power BI
Uzyskaj dostęp do zapisanej tabeli w usłudze Power BI:
- Po lewej stronie wybierz pozycję OneLake.
- Wybierz lakehouse, który dodałeś do tego notesu.
- W sekcji Open this Lakehouse wybierz pozycję Otwórz.
- Na wstążce wybierz pozycję Nowy model semantyczny. Wybierz pozycję
df_pred_results, a następnie wybierz pozycję Potwierdź, aby utworzyć nowy model semantyczny usługi Power BI połączony z przewidywaniami. - Otwórz nowy model semantyczny. Możesz go znaleźć w usłudze OneLake.
- Wybierz pozycję Utwórz nowy raport w menu Plik z narzędzi w górnej części strony modeli semantycznych, aby otworzyć stronę autorstwa raportu Power BI.
Poniższy zrzut ekranu przedstawia przykładowe wizualizacje. Panel danych pokazuje tabele delta i kolumny do wyboru z tabeli. Po wybraniu odpowiedniej kategorii (x) i osi wartości (y) można wybrać filtry i funkcje — na przykład sumę lub średnią kolumny tabeli.
Notatka
Na tym zrzucie ekranu zilustrowany przykład opisuje analizę zapisanych wyników przewidywania w usłudze Power BI:

Jednak w przypadku rzeczywistego przypadku użycia współczynnika zmian klientów użytkownik może potrzebować bardziej szczegółowego zestawu wymagań wizualizacji do utworzenia, na podstawie wiedzy specjalistycznej oraz tego, co firma i zespół ds. analizy biznesowej i firma ustandaryzowały jako metryki.
Raport usługi Power BI pokazuje, że klienci korzystający z więcej niż dwóch produktów bankowych mają wyższy współczynnik zmian. Jednak niewielu klientów miało więcej niż dwa produkty. (Zobacz wykres w lewym dolnym panelu). Bank powinien zbierać więcej danych, ale powinien również zbadać inne funkcje, które są skorelowane z większą liczbą produktów.
Klienci bankowi w Niemczech mają wyższy współczynnik zmian w porównaniu z klientami we Francji i Hiszpanii. (Zobacz wykres w prawym dolnym panelu). Na podstawie wyników raportu badanie czynników, które zachęciły klientów do opuszczenia, może pomóc.
Istnieje więcej klientów w średnim wieku (od 25 do 45). Klienci w wieku od 45 do 60 lat mają tendencję do częstszego odchodzenia.
Na koniec klienci z niższymi ocenami kredytowymi najprawdopodobniej opuściliby bank dla innych instytucji finansowych. Bank powinien zbadać sposoby zachęcania klientów o niższych ocenach kredytowych i saldach kont, aby pozostać w banku.
# Determine the entire runtime
print(f"Full run cost {int(time.time() - ts)} seconds.")