Migrowanie definicji zadania platformy Spark z usługi Azure Synapse do sieci szkieletowej
Aby przenieść definicje zadań platformy Spark (SJD) z usługi Azure Synapse do sieci szkieletowej, dostępne są dwie różne opcje:
- Opcja 1. Ręczne tworzenie definicji zadania platformy Spark w sieci szkieletowej.
- Opcja 2. Za pomocą skryptu można wyeksportować definicje zadań platformy Spark z usługi Azure Synapse i zaimportować je w sieci szkieletowej przy użyciu interfejsu API.
W przypadku zagadnień dotyczących definicji zadań platformy Spark zapoznaj się z różnicami między usługą Azure Synapse Spark i usługą Fabric.
Wymagania wstępne
Jeśli jeszcze go nie masz, utwórz obszar roboczy sieć szkieletowa w dzierżawie.
Opcja 1. Ręczne tworzenie definicji zadania platformy Spark
Aby wyeksportować definicję zadania platformy Spark z usługi Azure Synapse:
- Otwórz program Synapse Studio: zaloguj się na platformie Azure. Przejdź do obszaru roboczego usługi Azure Synapse i otwórz program Synapse Studio.
- Znajdź zadanie Python/Scala/R Spark: znajdź i zidentyfikuj definicję zadania python/Scala/R Spark, którą chcesz przeprowadzić migrację.
-
Wyeksportuj konfigurację definicji zadania:
- W programie Synapse Studio otwórz definicję zadania platformy Spark.
- Wyeksportuj lub zanotuj ustawienia konfiguracji, w tym lokalizację pliku skryptu, zależności, parametry i wszelkie inne istotne szczegóły.
Aby utworzyć nową definicję zadania platformy Spark (SJD) na podstawie wyeksportowanych informacji SJD w usłudze Fabric:
- Obszar roboczy usługi Access Fabric: zaloguj się do sieci szkieletowej i uzyskaj dostęp do obszaru roboczego.
-
Utwórz nową definicję zadania platformy Spark w usłudze Fabric:
- W obszarze Sieć szkieletowa przejdź do strony głównej inżynierowie danych.
- Wybierz pozycję Definicja zadania platformy Spark.
- Skonfiguruj zadanie przy użyciu informacji wyeksportowanych z usługi Synapse, w tym lokalizacji skryptu, zależności, parametrów i ustawień klastra.
- Dostosuj i przetestuj: dokonaj niezbędnej adaptacji do skryptu lub konfiguracji, aby dopasować je do środowiska sieci szkieletowej. Przetestuj zadanie w usłudze Fabric, aby upewnić się, że działa poprawnie.
Po utworzeniu definicji zadania platformy Spark zweryfikuj zależności:
- Upewnij się, że używasz tej samej wersji platformy Spark.
- Zweryfikuj istnienie głównego pliku definicji.
- Zweryfikuj istnienie odwołanych plików, zależności i zasobów.
- Połączone usługi, połączenia ze źródłem danych i punkty instalacji.
Dowiedz się więcej o tworzeniu definicji zadania platformy Apache Spark w usłudze Fabric.
Opcja 2. Korzystanie z interfejsu API sieci szkieletowej
Wykonaj następujące kluczowe kroki migracji:
- Wymagania wstępne.
- Krok 1. Eksportowanie definicji zadania platformy Spark z usługi Azure Synapse do usługi OneLake (.json).
- Krok 2. Automatyczne importowanie definicji zadania platformy Spark do sieci szkieletowej przy użyciu interfejsu API sieci szkieletowej.
Wymagania wstępne
Wymagania wstępne obejmują akcje, które należy wziąć pod uwagę przed rozpoczęciem migracji definicji zadań platformy Spark do sieci szkieletowej.
- Obszar roboczy sieć szkieletowa.
- Jeśli jeszcze go nie masz, utwórz usługę Fabric lakehouse w obszarze roboczym.
Krok 1. Eksportowanie definicji zadania platformy Spark z obszaru roboczego usługi Azure Synapse
Celem kroku 1 jest eksportowanie definicji zadania platformy Spark z obszaru roboczego usługi Azure Synapse do usługi OneLake w formacie json. Ten proces jest następujący:
- 1.1) Zaimportuj notes migracji SJD do obszaru roboczego usługi Fabric . Ten notes eksportuje wszystkie definicje zadań platformy Spark z danego obszaru roboczego usługi Azure Synapse do katalogu pośredniego w usłudze OneLake. Interfejs API usługi Synapse służy do eksportowania usługi SJD.
- 1.2) Skonfiguruj parametry w pierwszym poleceniu, aby wyeksportować definicję zadania platformy Spark do magazynu pośredniego (OneLake). Spowoduje to wyeksportowanie tylko pliku metadanych JSON. Poniższy fragment kodu służy do konfigurowania parametrów źródłowych i docelowych. Pamiętaj, aby zastąpić je własnymi wartościami.
# Azure config
azure_client_id = "<client_id>"
azure_tenant_id = "<tenant_id>"
azure_client_secret = "<client_secret>"
# Azure Synapse workspace config
synapse_workspace_name = "<synapse_workspace_name>"
# Fabric config
workspace_id = "<workspace_id>"
lakehouse_id = "<lakehouse_id>"
export_folder_name = f"export/{synapse_workspace_name}"
prefix = "" # this prefix is used during import {prefix}{sjd_name}
output_folder = f"abfss://{workspace_id}@onelake.dfs.fabric.microsoft.com/{lakehouse_id}/Files/{export_folder_name}"
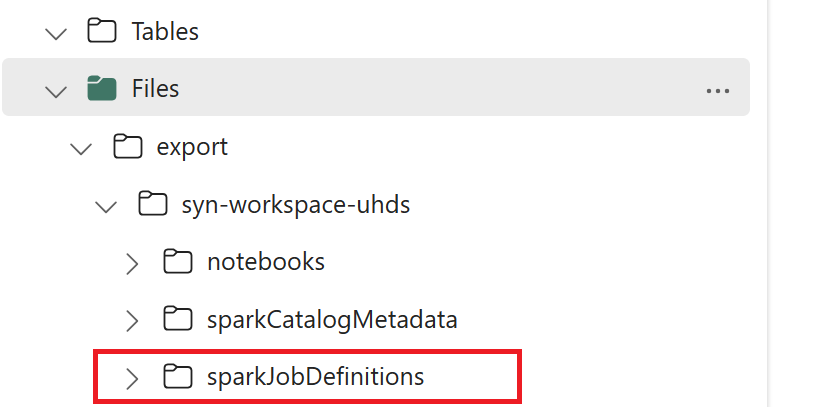
- 1.3) Uruchom dwie pierwsze komórki notesu eksportu/importu, aby wyeksportować metadane definicji zadania platformy Spark do usługi OneLake. Po zakończeniu tworzenia komórek ta struktura folderów w pośrednim katalogu wyjściowym.
Krok 2. Importowanie definicji zadania platformy Spark do sieci szkieletowej
Krok 2 polega na tym, że definicje zadań platformy Spark są importowane z magazynu pośredniego do obszaru roboczego Sieć szkieletowa. Ten proces jest następujący:
- 2.1) Zweryfikuj konfiguracje w wersji 1.2, aby upewnić się, że właściwy obszar roboczy i prefiks są wskazywane na zaimportowanie definicji zadań platformy Spark.
- 2.2) Uruchom trzecią komórkę notesu eksportu/importu, aby zaimportować wszystkie definicje zadań platformy Spark z lokalizacji pośredniej.
Uwaga
Opcja eksportu zwraca plik metadanych JSON. Upewnij się, że pliki wykonywalne definicji zadań platformy Spark, pliki referencyjne i argumenty są dostępne z sieci szkieletowej.