Migrowanie metadanych magazynu metadanych Hive z usługi Azure Synapse Analytics do sieci szkieletowej
Początkowy krok migracji magazynu metadanych Hive (HMS) obejmuje określenie baz danych, tabel i partycji, które chcesz przenieść. Nie trzeba migrować wszystkiego; Możesz wybrać określone bazy danych. Podczas identyfikowania baz danych na potrzeby migracji upewnij się, czy istnieją zarządzane lub zewnętrzne tabele platformy Spark.
Aby zapoznać się z zagadnieniami dotyczącymi hmS, zapoznaj się z różnicami między usługą Azure Synapse Spark i usługą Fabric.
Uwaga
Alternatywnie, jeśli usługa ADLS Gen2 zawiera tabele delty, możesz utworzyć skrót OneLake do tabeli delty w usłudze ADLS Gen2.
Wymagania wstępne
- Jeśli jeszcze go nie masz, utwórz obszar roboczy sieć szkieletowa w dzierżawie.
- Jeśli jeszcze go nie masz, utwórz usługę Fabric lakehouse w obszarze roboczym.
Opcja 1. Eksportowanie i importowanie hms do magazynu metadanych lakehouse
Wykonaj następujące kluczowe kroki migracji:
- Krok 1. Eksportowanie metadanych ze źródła HMS
- Krok 2. Importowanie metadanych do usługi Fabric Lakehouse
- Kroki po migracji: Weryfikowanie zawartości
Uwaga
Skrypty kopiują tylko obiekty wykazu platformy Spark do usługi Fabric lakehouse. Założeniem jest to, że dane są już kopiowane (na przykład z lokalizacji magazynu do usługi ADLS Gen2) lub dostępne dla zarządzanych i zewnętrznych tabel (na przykład za pomocą skrótów — preferowanych) do usługi Fabric Lakehouse.
Krok 1. Eksportowanie metadanych ze źródła HMS
Celem kroku 1 jest eksportowanie metadanych ze źródłowego systemu HMS do sekcji Pliki w lakehouse usługi Fabric. Ten proces jest następujący:
1.1) Zaimportuj notes eksportu metadanych HMS do obszaru roboczego usługi Azure Synapse. Ten notes wysyła zapytania i eksportuje metadane HMS baz danych, tabel i partycji do katalogu pośredniego w usłudze OneLake (funkcje nie zostały jeszcze uwzględnione). Interfejs API wykazu wewnętrznego platformy Spark jest używany w tym skryscie do odczytywania obiektów wykazu.
1.2) Skonfiguruj parametry w pierwszym poleceniu, aby wyeksportować informacje o metadanych do magazynu pośredniego (OneLake). Poniższy fragment kodu służy do konfigurowania parametrów źródłowych i docelowych. Pamiętaj, aby zastąpić je własnymi wartościami.
// Azure Synapse workspace config var SynapseWorkspaceName = "<synapse_workspace_name>" var DatabaseNames = "<db1_name>;<db2_name>" var SkipExportTablesWithUnrecognizedType:Boolean = false // Fabric config var WorkspaceId = "<workspace_id>" var LakehouseId = "<lakehouse_id>" var ExportFolderName = f"export/${SynapseWorkspaceName}/sparkCatalogMetadata" var OutputFolder = f"abfss://${WorkspaceId}@onelake.dfs.fabric.microsoft.com/${LakehouseId}/Files/${ExportFolderName}/"1.3) Uruchom wszystkie polecenia notesu , aby wyeksportować obiekty wykazu do usługi OneLake. Po zakończeniu tworzenia komórek ta struktura folderów w pośrednim katalogu wyjściowym.
Krok 2. Importowanie metadanych do usługi Fabric Lakehouse
Krok 2 polega na tym, że rzeczywiste metadane są importowane z magazynu pośredniego do magazynu lakehouse usługi Fabric. W tym kroku mają być migrowane wszystkie metadane HMS (bazy danych, tabele i partycje). Ten proces jest następujący:
2.1) Utwórz skrót w sekcji "Pliki" nad jeziorem. Ten skrót musi wskazywać źródłowy katalog magazynu Spark i jest używany później do zastąpienia tabel zarządzanych przez platformę Spark. Zobacz przykłady skrótów wskazujące katalog magazynu Spark:
- Ścieżka skrótu do katalogu magazynu usługi Azure Synapse Spark:
abfss://<container>@<storage_name>.dfs.core.windows.net/synapse/workspaces/<workspace_name>/warehouse - Ścieżka skrótu do katalogu magazynu usługi Azure Databricks:
dbfs:/mnt/<warehouse_dir> - Ścieżka skrótu do katalogu magazynu HDInsight Spark:
abfss://<container>@<storage_name>.dfs.core.windows.net/apps/spark/warehouse
- Ścieżka skrótu do katalogu magazynu usługi Azure Synapse Spark:
2.2) Zaimportuj notes importu metadanych HMS do obszaru roboczego usługi Fabric. Zaimportuj ten notes , aby zaimportować obiekty bazy danych, tabeli i partycji z magazynu pośredniego. Interfejs API wykazu wewnętrznego platformy Spark jest używany w tym skrygcie do tworzenia obiektów wykazu w sieci szkieletowej.
2.3) Skonfiguruj parametry w pierwszym poleceniu. Na platformie Apache Spark podczas tworzenia tabeli zarządzanej dane dla tej tabeli są przechowywane w lokalizacji zarządzanej przez platformę Spark, zazwyczaj w katalogu magazynu platformy Spark. Dokładna lokalizacja jest określana przez platformę Spark. Kontrastuje to z tabelami zewnętrznymi, w których określasz lokalizację i zarządzasz bazowymi danymi. Podczas migracji metadanych zarządzanej tabeli (bez przenoszenia rzeczywistych danych) metadane nadal zawierają oryginalne informacje o lokalizacji wskazujące stary katalog magazynu Spark. W związku z tym w przypadku tabel zarządzanych
WarehouseMappingssłuży do zastępowania za pomocą skrótu utworzonego w kroku 2.1. Wszystkie źródłowe tabele zarządzane są konwertowane jako tabele zewnętrzne przy użyciu tego skryptu.LakehouseIdodwołuje się do lakehouse utworzonego w kroku 2.1 zawierającego skróty.// Azure Synapse workspace config var ContainerName = "<container_name>" var StorageName = "<storage_name>" var SynapseWorkspaceName = "<synapse_workspace_name>" // Fabric config var WorkspaceId = "<workspace_id>" var LakehouseId = "<lakehouse_id>" var ExportFolderName = f"export/${SynapseWorkspaceName}/sparkCatalogMetadata" var ShortcutName = "<warehouse_dir_shortcut_name>" var WarehouseMappings:Map[String, String] = Map( f"abfss://${ContainerName}@${StorageName}.dfs.core.windows.net/synapse/workspaces/${SynapseWorkspaceName}/warehouse"-> f"abfss://${WorkspaceId}@onelake.dfs.fabric.microsoft.com/${LakehouseId}/Files/${ShortcutName}" ) var OutputFolder = f"abfss://${WorkspaceId}@onelake.dfs.fabric.microsoft.com/${LakehouseId}/Files/${ExportFolderName}/" var DatabasePrefix = "" var TablePrefix = "" var IgnoreIfExists = true2.4) Uruchom wszystkie polecenia notesu , aby zaimportować obiekty wykazu ze ścieżki pośredniej.
Uwaga
Podczas importowania wielu baz danych można (i) utworzyć jedną bazę danych typu lakehouse na bazę danych (podejście użyte tutaj) lub (ii) przenieść wszystkie tabele z różnych baz danych do pojedynczego magazynu typu lakehouse. W przypadku tych ostatnich wszystkie zmigrowane tabele mogą mieć <lakehouse>.<db_name>_<table_name>wartość i należy odpowiednio dostosować notes importu.
Krok 3. Weryfikowanie zawartości
Krok 3 polega na sprawdzeniu, czy metadane zostały pomyślnie zmigrowane. Zobacz różne przykłady.
Zaimportowane bazy danych można zobaczyć, uruchamiając polecenie:
%%sql
SHOW DATABASES
Możesz sprawdzić wszystkie tabele w bazie danych lakehouse, uruchamiając polecenie:
%%sql
SHOW TABLES IN <lakehouse_name>
Szczegóły określonej tabeli można wyświetlić, uruchamiając polecenie:
%%sql
DESCRIBE EXTENDED <lakehouse_name>.<table_name>
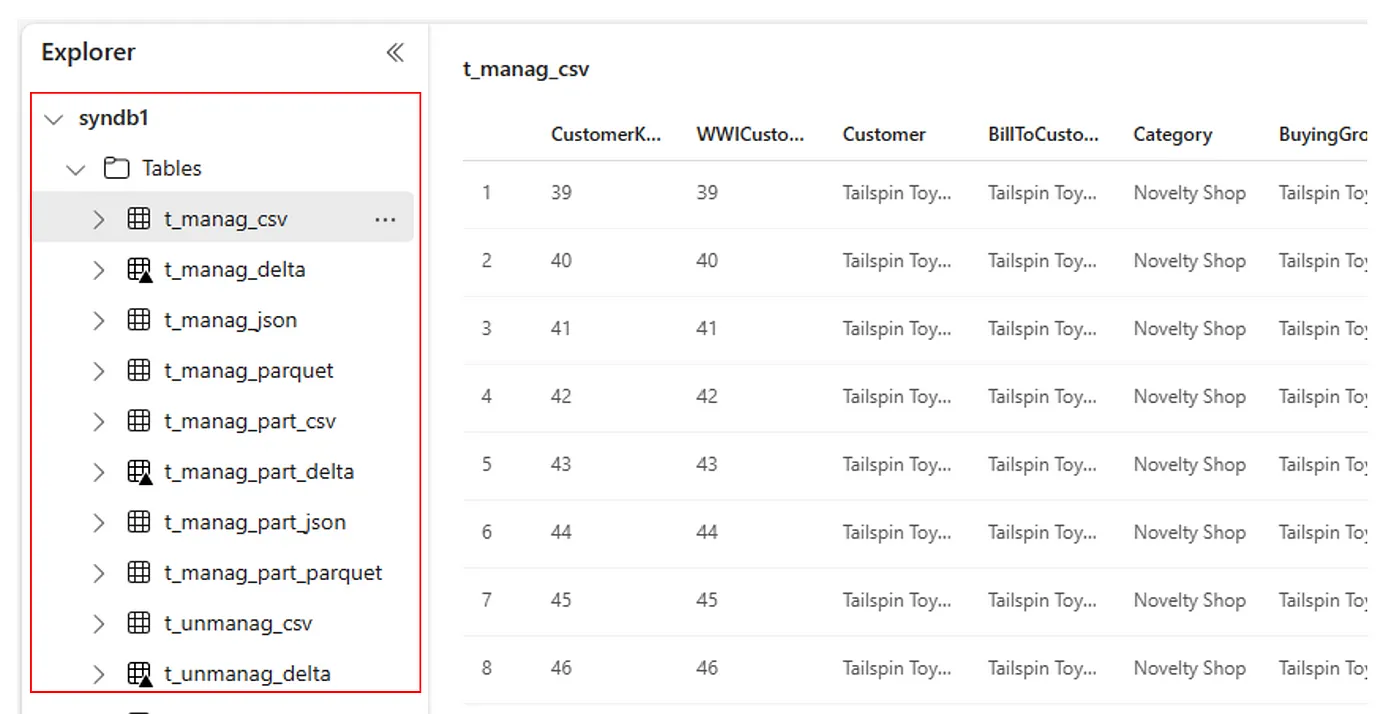
Alternatywnie wszystkie zaimportowane tabele są widoczne w sekcji Tabele interfejsu użytkownika eksploratora usługi Lakehouse dla każdego magazynu lakehouse.
Inne uwagi
- Skalowalność: w tym przypadku rozwiązanie korzysta z wewnętrznego interfejsu API wykazu spark do importowania/eksportowania, ale nie łączy się bezpośrednio z hmS w celu pobrania obiektów wykazu, więc rozwiązanie nie może być skalowane dobrze, jeśli wykaz jest duży. Należy zmienić logikę eksportu przy użyciu bazy danych HMS.
- Dokładność danych: nie ma gwarancji izolacji, co oznacza, że jeśli aparat obliczeniowy Spark wykonuje współbieżne modyfikacje magazynu metadanych podczas działania notesu migracji, niespójne dane można wprowadzić w usłudze Fabric Lakehouse.
Powiązana zawartość
- Sieć szkieletowa a platforma Azure Synapse Spark
- Dowiedz się więcej o opcjach migracji dla pul, konfiguracji, bibliotek, notesów i definicji zadań platformy Spark