Wzorce danych natywnych w chmurze
Napiwek
Ta zawartość jest fragmentem książki eBook, Architekting Cloud Native .NET Applications for Azure, dostępnej na platformie .NET Docs lub jako bezpłatny plik PDF do pobrania, który można odczytać w trybie offline.

Jak widzieliśmy w tej książce, podejście natywne dla chmury zmienia sposób projektowania, wdrażania i zarządzania aplikacjami. Zmienia również sposób zarządzania danymi i ich przechowywania.
Rysunek 5–1 kontrastuje z różnicami.
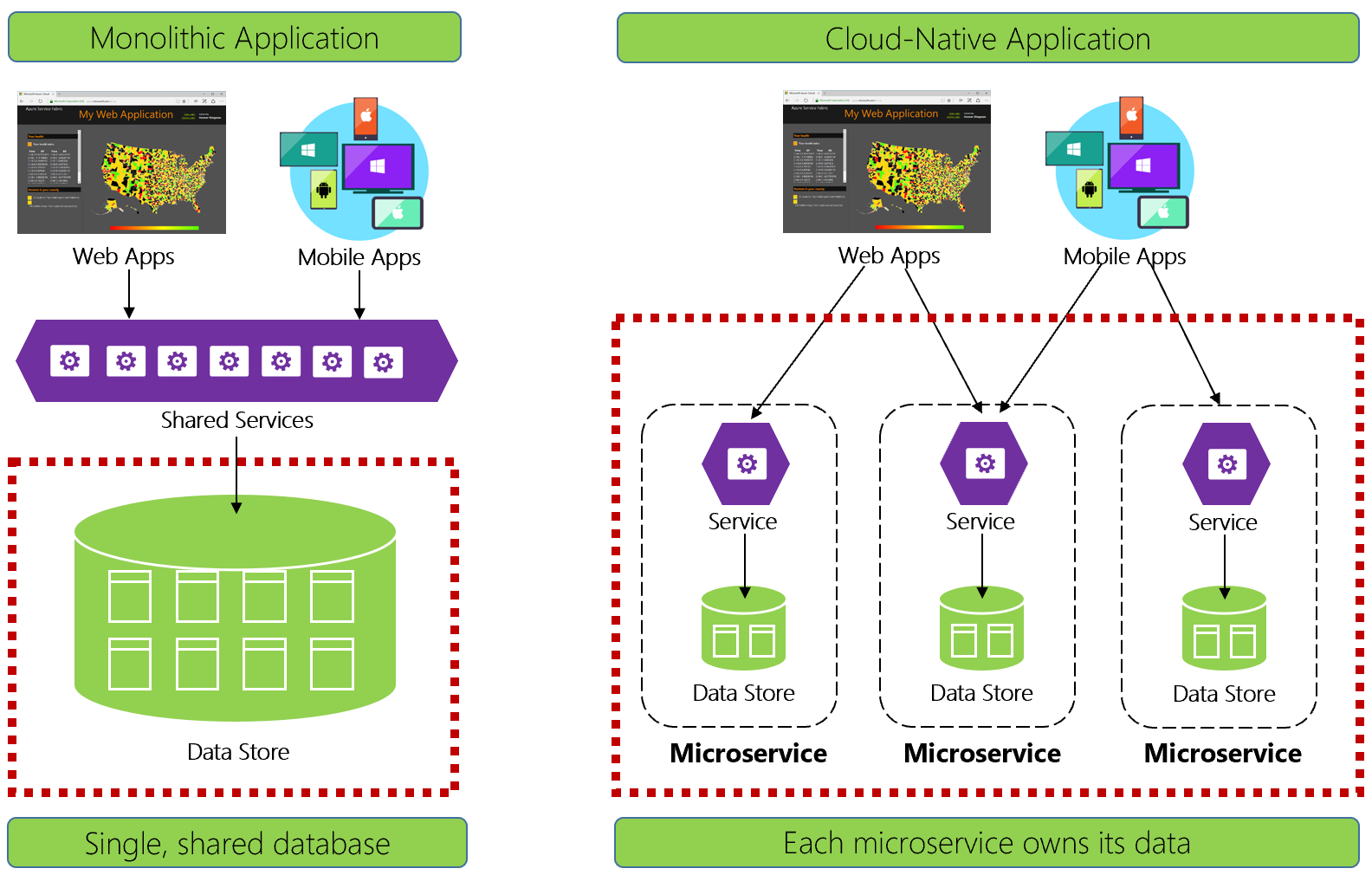
Rysunek 5–1. Zarządzanie danymi w aplikacjach natywnych dla chmury
Doświadczeni deweloperzy łatwo rozpoznają architekturę po lewej stronie rysunku 5-1. W tej monolitycznej aplikacji składniki usług biznesowych łączą się w warstwie usług udostępnionych, udostępniając dane z pojedynczej relacyjnej bazy danych.
Na wiele sposobów pojedyncza baza danych zapewnia proste zarządzanie danymi. Wykonywanie zapytań dotyczących danych w wielu tabelach jest proste. Zmiany w aktualizacji danych lub wszystkie one wycofywania. Transakcje ACID gwarantują silną i natychmiastową spójność.
Projektowanie pod kątem rozwiązań natywnych dla chmury podejmujemy inne podejście. Po prawej stronie rysunku 5-1 zwróć uwagę na to, jak funkcje biznesowe oddzielają się od małych, niezależnych mikrousług. Każda mikrousługa hermetyzuje określoną funkcję biznesową i własne dane. Monolityczna baza danych rozkłada się na rozproszony model danych z wieloma mniejszymi bazami danych, z których każda jest zgodna z mikrousługą. Po wyczyszceniu dymu pojawia się projekt, który uwidacznia bazę danych na mikrousługę.
Dlaczego baza danych na mikrousługę?
Ta baza danych na mikrousługę zapewnia wiele korzyści, szczególnie w przypadku systemów, które muszą szybko ewoluować i obsługiwać ogromną skalę. Z tym modelem...
- Dane domeny są hermetyzowane w usłudze
- Schemat danych może ewoluować bez bezpośredniego wpływu na inne usługi
- Każdy magazyn danych może niezależnie skalować
- Awaria magazynu danych w jednej usłudze nie wpłynie bezpośrednio na inne usługi
Segregowanie danych umożliwia również każdej mikrousłudze zaimplementowanie typu magazynu danych, który jest najlepiej zoptymalizowany pod kątem obciążenia, potrzeb magazynu i wzorców odczytu/zapisu. Opcje wyboru obejmują magazyny danych relacyjne, dokumentowe, klucz-wartość, a nawet magazyny danych oparte na grafach.
Rysunek 5–2 przedstawia zasadę trwałości wielolotowej w systemie natywnym dla chmury.
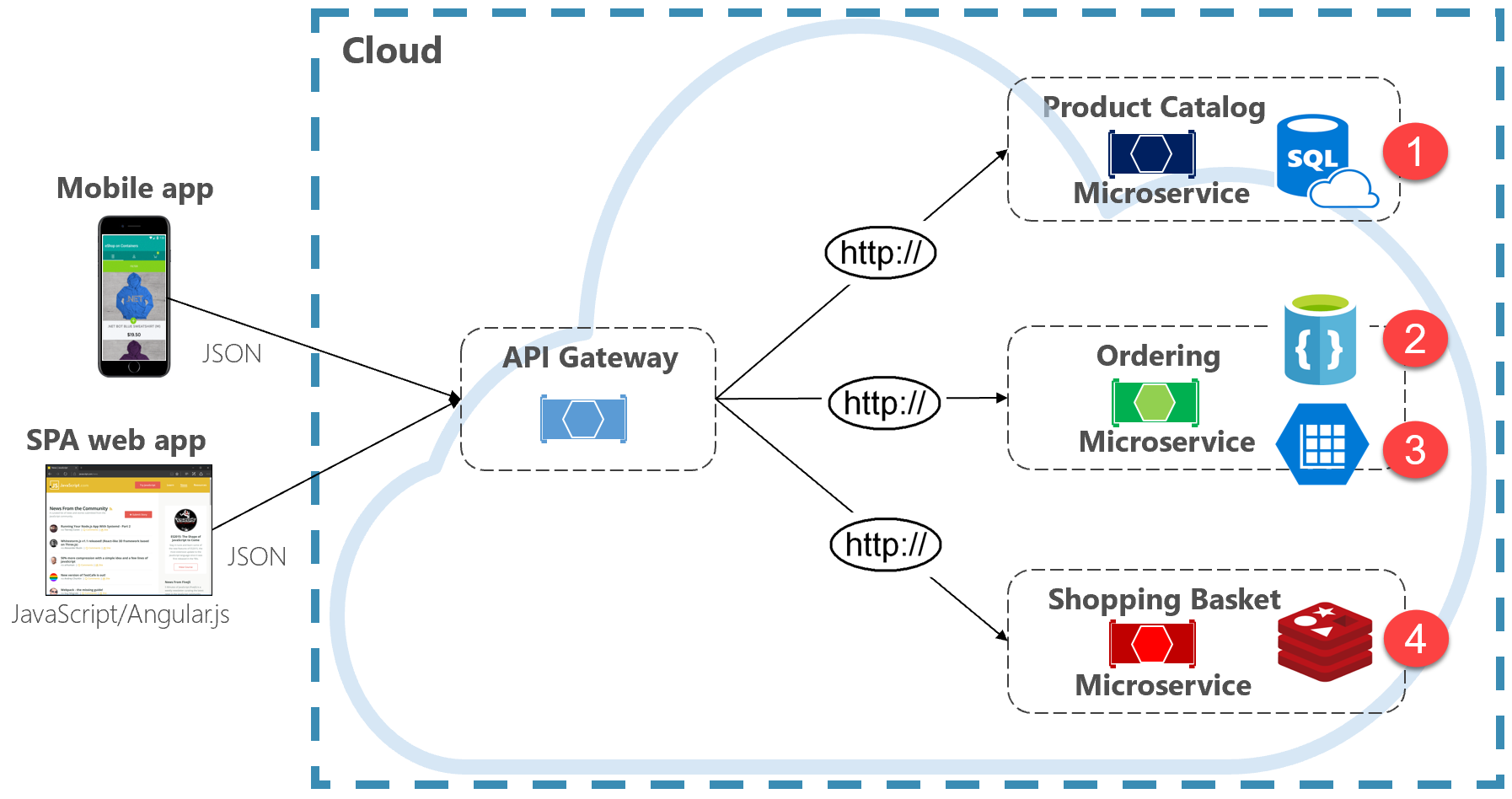
Rysunek 5–2. Trwałość danych wielolotowych
Zwróć uwagę na to, jak każda mikrousługa obsługuje inny typ magazynu danych.
- Mikrousługa wykazu produktów korzysta z relacyjnej bazy danych, aby pomieścić bogatą relacyjną strukturę swoich danych bazowych.
- Mikrousługa koszyka zakupów korzysta z rozproszonej pamięci podręcznej, która obsługuje prosty magazyn danych typu klucz-wartość.
- Mikrousługa porządkowania używa zarówno bazy danych dokumentów NoSql do operacji zapisu, jak i wysoce zdenormalizowanego magazynu kluczy/wartości w celu obsługi dużych ilości operacji odczytu.
Chociaż relacyjne bazy danych pozostają istotne dla mikrousług ze złożonymi danymi, bazy danych NoSQL zyskały znaczną popularność. Zapewniają one ogromną skalę i wysoką dostępność. Ich bez schematu charakter pozwala deweloperom odejść od architektury typowych klas danych i ORM, które zmieniają się kosztownie i czasochłonnie. W dalszej części tego rozdziału omówiono bazy danych NoSQL.
Chociaż hermetyzowanie danych w oddzielnych mikrousług może zwiększyć elastyczność, wydajność i skalowalność, stanowi również wiele wyzwań. W następnej sekcji omówimy te wyzwania wraz z wzorcami i rozwiązaniami, które pomogą je przezwyciężyć.
Zapytania między usługami
Chociaż mikrousługi są niezależne i koncentrują się na określonych funkcjach, takich jak zapasy, wysyłka lub zamawianie, często wymagają integracji z innymi mikrousługami. Często integracja obejmuje jedną mikrousługę odpytując inną dla danych. Rysunek 5–3 przedstawia scenariusz.
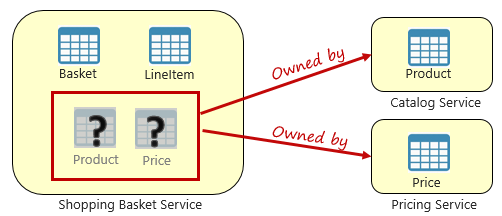
Rysunek 5–3. Wykonywanie zapytań dotyczących mikrousług
Na powyższej ilustracji widzimy mikrousługę koszyka zakupów, która dodaje element do koszyka zakupów użytkownika. Magazyn danych dla tej mikrousługi zawiera dane koszyka i elementu wiersza, ale nie przechowuje danych o produktach ani cenach. Zamiast tego te elementy danych są własnością katalogu i mikrousług cenowych. Ten aspekt stanowi problem. Jak mikrousługa koszyka zakupów może dodać produkt do koszyka zakupów użytkownika, gdy nie ma danych o produkcie ani cenach w bazie danych?
Jedną z opcji omówionych w rozdziale 4 jest bezpośrednie wywołanie HTTP z koszyka zakupów do katalogu i mikrousług cenowych. Jednak w rozdziale 4 powiedzieliśmy, że synchroniczne wywołania HTTP łączą ze sobą kilka mikrousług, zmniejszając ich autonomię i zmniejszając swoje korzyści architektoniczne.
Możemy również zaimplementować wzorzec odpowiedzi żądania z oddzielnymi kolejkami przychodzącymi i wychodzącymi dla każdej usługi. Ten wzorzec jest jednak skomplikowany i wymaga korelowania komunikatów żądań i odpowiedzi. Chociaż usługa wywołująca nadal rozdziela wywołania mikrousługi zaplecza, musi ona nadal synchronicznie czekać na zakończenie wywołania. Przeciążenie sieci, błędy przejściowe lub przeciążona mikrousługa może spowodować długotrwałe, a nawet nieudane operacje.
Zamiast tego powszechnie akceptowany wzorzec usuwania zależności między usługami to zmaterializowany wzorzec widoku pokazany na rysunku 5-4.
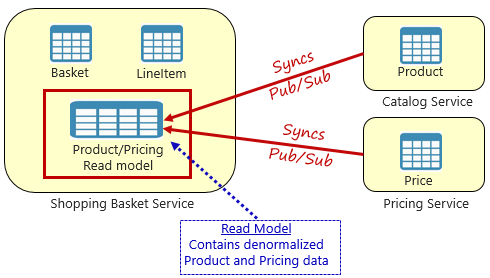
Rysunek 5–4. Materialized View pattern (Wzorzec zmaterializowanego widoku)
Za pomocą tego wzorca umieszczasz lokalną tabelę danych (znaną jako model odczytu) w usłudze koszyka zakupów. Ta tabela zawiera zdenormalizowaną kopię danych potrzebnych z mikrousług produktu i cen. Kopiowanie danych bezpośrednio do mikrousługi koszyka zakupów eliminuje potrzebę kosztownych wywołań między usługami. Dzięki lokalnym danym w usłudze można poprawić czas odpowiedzi i niezawodność usługi. Ponadto posiadanie własnej kopii danych sprawia, że usługa koszyka zakupów jest bardziej odporna. Jeśli usługa wykazu powinna stać się niedostępna, nie wpłynie to bezpośrednio na usługę koszyka zakupów. Koszyk zakupów może nadal działać z danymi z własnego sklepu.
Wychwytywanie przy użyciu tego podejścia polega na tym, że masz teraz zduplikowane dane w systemie. Jednak strategicznie duplikowanie danych w systemach natywnych dla chmury jest ustaloną praktyką i nie jest uważane za anty-wzorzec lub złe rozwiązanie. Należy pamiętać, że jedna i tylko jedna usługa może posiadać zestaw danych i mieć nad nim uprawnienia. Po zaktualizowaniu systemu rekordów należy zsynchronizować modele odczytu. Synchronizacja jest zwykle implementowana za pośrednictwem asynchronicznej obsługi komunikatów ze wzorcem publikowania/subskrybowania, jak pokazano na rysunku 5.4.
Transakcje rozproszone
Chociaż wykonywanie zapytań dotyczących danych między mikrousługami jest trudne, implementacja transakcji w kilku mikrousługach jest jeszcze bardziej złożona. Nieodłączne wyzwanie związane z utrzymaniem spójności danych w niezależnych źródłach danych w różnych mikrousługach nie może być zaniżone. Brak transakcji rozproszonych w aplikacjach natywnych dla chmury oznacza, że należy programowo zarządzać transakcjami rozproszonymi. Przechodzisz od świata natychmiastowej spójności do spójności ostatecznej.
Rysunek 5–5 przedstawia problem.
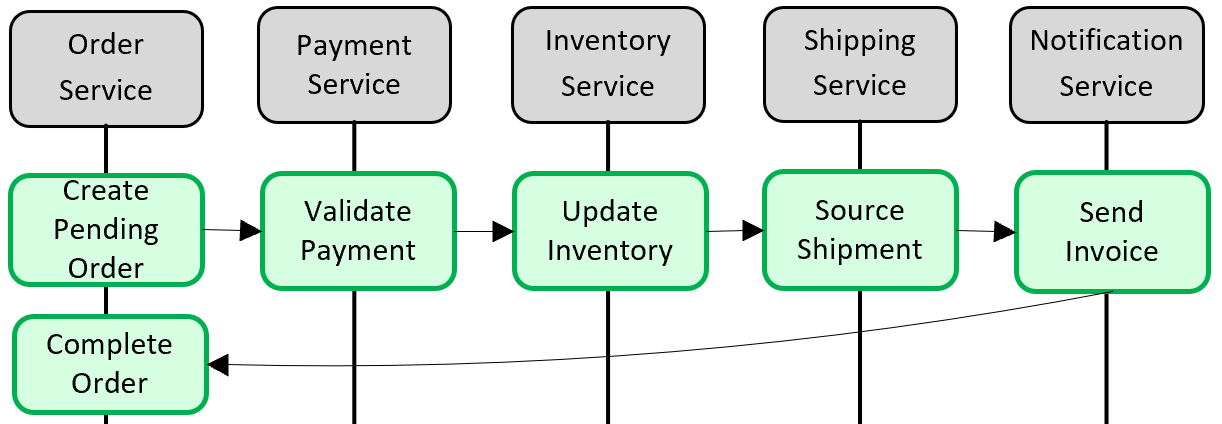
Rysunek 5–5. Implementowanie transakcji między mikrousługami
Na powyższej ilustracji pięć niezależnych mikrousług uczestniczy w transakcji rozproszonej, która tworzy zamówienie. Każda mikrousługa przechowuje własny magazyn danych i implementuje lokalną transakcję dla swojego magazynu. Aby utworzyć zamówienie, transakcja lokalna dla każdej pojedynczej mikrousługi musi zakończyć się powodzeniem lub wszystkie muszą przerwać i wycofać operację. Chociaż wbudowana obsługa transakcyjna jest dostępna wewnątrz każdej mikrousługi, nie ma obsługi transakcji rozproszonej, która obejmowałaby wszystkie pięć usług, aby zapewnić spójność danych.
Zamiast tego należy programowo skonstruować tę transakcję rozproszoną.
Popularnym wzorcem dodawania rozproszonej obsługi transakcyjnej jest wzorzec Saga. Jest on implementowany przez grupowanie transakcji lokalnych razem programowo i sekwencyjnie wywołując każdy z nich. Jeśli którakolwiek z transakcji lokalnych zakończy się niepowodzeniem, Saga przerywa operację i wywołuje zestaw transakcji wyrównywujących. Transakcje wyrównywujące cofają zmiany wprowadzone przez poprzednie transakcje lokalne i przywracają spójność danych. Rysunek 5–6 przedstawia nieudaną transakcję ze wzorcem Saga.
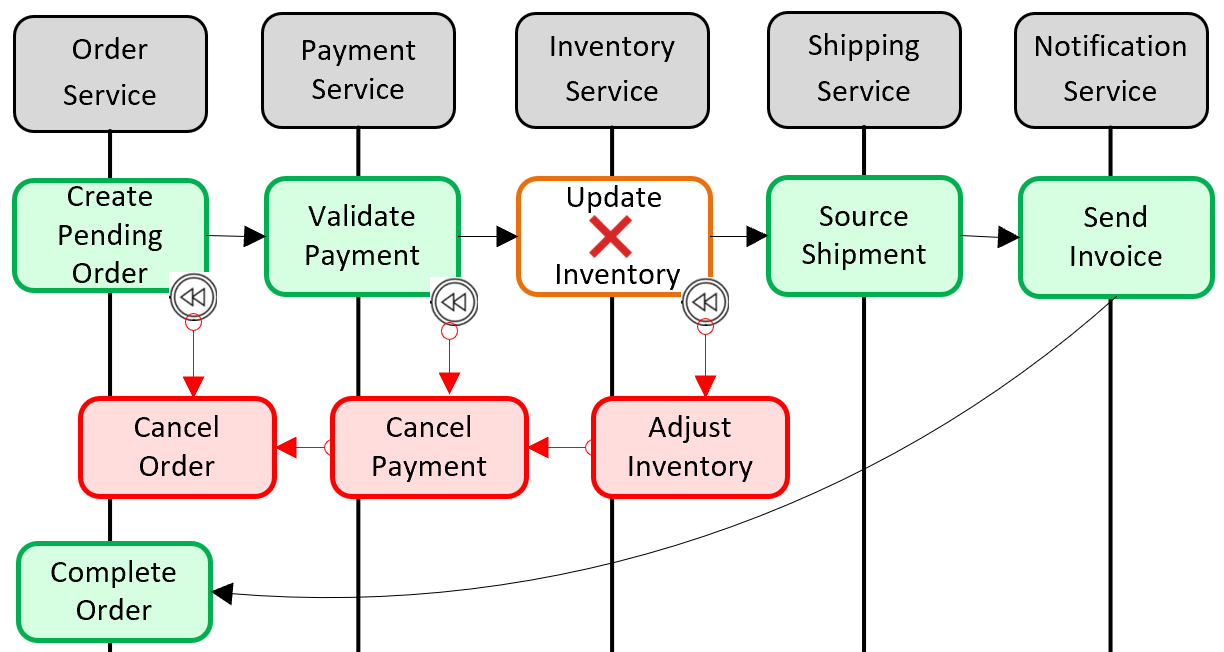
Rysunek 5–6. Wycofywanie transakcji
Na poprzedniej ilustracji operacja Aktualizuj spis nie powiodła się w mikrousłudze Inventory . Saga wywołuje zestaw transakcji kompensacyjnych (na czerwono), aby dostosować liczbę zapasów, anulować płatność i zamówienie oraz zwrócić dane dla każdej mikrousługi z powrotem do spójnego stanu.
Wzorce saga są zwykle choreografią jako seria powiązanych wydarzeń lub orkiestrowane jako zestaw powiązanych poleceń. W rozdziale 4 omówiliśmy wzorzec agregatora usług, który byłby podstawą orkiestrowanej implementacji sagi. Omówiliśmy również zdarzenia wraz z tematami Azure Service Bus i Azure Event Grid , które byłyby podstawą do choreografii implementacji sagi.
Duże ilości danych
Duże aplikacje natywne dla chmury często obsługują wymagania dotyczące dużych ilości danych. W tych scenariuszach tradycyjne techniki przechowywania danych mogą powodować wąskie gardła. W przypadku złożonych systemów, które są wdrażane na dużą skalę, podział odpowiedzialności poleceń i zapytań (CQRS) i określanie źródła zdarzeń może poprawić wydajność aplikacji.
CQRS
CQRS to wzorzec architektury, który może pomóc zmaksymalizować wydajność, skalowalność i bezpieczeństwo. Wzorzec oddziela operacje odczytujące dane od tych operacji, które zapisują dane.
W normalnych scenariuszach ten sam model jednostki i obiekt repozytorium danych są używane zarówno dla operacji odczytu, jak i zapisu.
Jednak scenariusz danych o dużej ilości może korzystać z oddzielnych modeli i tabel danych dla operacji odczytu i zapisu. Aby zwiększyć wydajność, operacja odczytu może wykonywać zapytania względem wysoce zdenormalizowanej reprezentacji danych, aby uniknąć kosztownych powtarzających się sprzężeń tabeli i blokad tabeli. Operacja zapisu, znana jako polecenie, będzie aktualizowana względem w pełni znormalizowanej reprezentacji danych, która gwarantuje spójność. Następnie należy zaimplementować mechanizm, aby zachować synchronizację obu reprezentacji. Zazwyczaj za każdym razem, gdy tabela zapisu jest modyfikowana, publikuje zdarzenie , które replikuje modyfikację do tabeli odczytu.
Rysunek 5–7 przedstawia implementację wzorca CQRS.
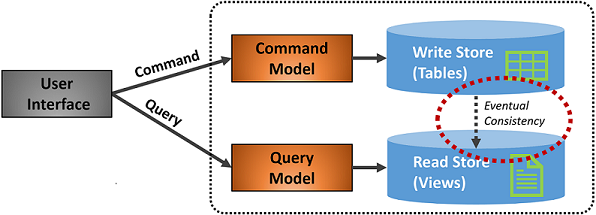
Rysunek 5–7. Implementacja CQRS
Na poprzedniej ilustracji zaimplementowano oddzielne modele poleceń i zapytań. Każda operacja zapisu danych jest zapisywana w magazynie zapisu, a następnie propagowana do magazynu odczytu. Zwróć szczególną uwagę na sposób działania procesu propagacji danych na zasadzie spójności ostatecznej. Model odczytu ostatecznie synchronizuje się z modelem zapisu, ale może wystąpić pewne opóźnienie w procesie. W następnej sekcji omówiono spójność ostateczną.
To rozdzielenie umożliwia niezależne skalowanie operacji odczytu i zapisu. Operacje odczytu używają schematu zoptymalizowanego pod kątem zapytań, podczas gdy zapisy używają schematu zoptymalizowanego pod kątem aktualizacji. Zapytania odczytu są stosowane względem zdenormalizowanych danych, podczas gdy do modelu zapisu można zastosować złożoną logikę biznesową. Ponadto można narzucić ściślejsze zabezpieczenia operacji zapisu niż te, które uwidaczniają operacje odczytu.
Implementowanie CQRS może zwiększyć wydajność aplikacji dla usług natywnych dla chmury. Jednak powoduje to bardziej złożony projekt. Zastosuj tę zasadę ostrożnie i strategicznie do tych sekcji aplikacji natywnej dla chmury, które skorzystają z niej. Aby uzyskać więcej informacji na temat CQRS, zobacz książkę firmy Microsoft .NET Microservices: Architecture for Containerized .NET Applications (Mikrousługi platformy .NET: architektura konteneryzowanych aplikacji .NET).
Określanie źródła zdarzeń
Innym podejściem do optymalizacji scenariuszy danych o dużej ilości danych jest określanie źródła zdarzeń.
System zazwyczaj przechowuje bieżący stan jednostki danych. Jeśli na przykład użytkownik zmieni swój numer telefonu, rekord klienta zostanie zaktualizowany o nowy numer. Zawsze znamy bieżący stan jednostki danych, ale każda aktualizacja zastępuje poprzedni stan.
W większości przypadków ten model działa prawidłowo. Jednak w dużych systemach obciążenia związane z blokowaniem transakcyjnym i częstymi operacjami aktualizacji mogą mieć wpływ na wydajność, czas odpowiedzi i skalowalność bazy danych.
Określanie źródła zdarzeń ma inne podejście do przechwytywania danych. Każda operacja, która ma wpływ na dane, jest utrwalana w magazynie zdarzeń. Zamiast aktualizować stan rekordu danych, dołączamy każdą zmianę do sekwencyjnej listy przeszłych zdarzeń — podobnie jak rejestr księgowy. Magazyn zdarzeń staje się systemem rekordów dla danych. Służy do propagowania różnych zmaterializowanych widoków w powiązanym kontekście mikrousługi. Rysunek 5.8 przedstawia wzorzec.
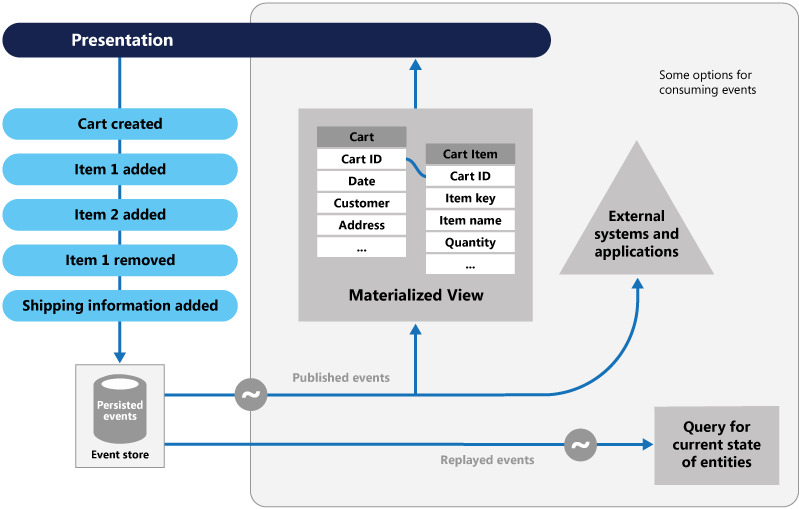
Rysunek 5–8. Określanie źródła zdarzeń
Na poprzedniej ilustracji zwróć uwagę, jak każdy wpis (w kolorze niebieskim) dla koszyka zakupów użytkownika jest dołączany do bazowego magazynu zdarzeń. W sąsiednim widoku zmaterializowanym system projektuje bieżący stan przez odtworzenie wszystkich zdarzeń skojarzonych z każdym koszykiem. Ten widok lub model odczytu jest następnie uwidaczniany z powrotem w interfejsie użytkownika. Zdarzenia można również zintegrować z systemami zewnętrznymi i aplikacjami lub wykonywać zapytania w celu określenia bieżącego stanu jednostki. Dzięki temu podejściu zachowasz historię. Wiesz nie tylko bieżący stan jednostki, ale także sposób osiągnięcia tego stanu.
Mówiąc mechanicznie, określanie źródła zdarzeń upraszcza model zapisu. Brak aktualizacji ani usuwania. Dołączanie każdego wpisu danych jako niezmiennego zdarzenia minimalizuje rywalizację, blokowanie i konflikty współbieżności skojarzone z relacyjnymi bazami danych. Tworzenie modeli odczytu za pomocą zmaterializowanego wzorca widoku umożliwia oddzielenie widoku od modelu zapisu i wybranie najlepszego magazynu danych w celu zoptymalizowania potrzeb interfejsu użytkownika aplikacji.
W tym wzorcu rozważ magazyn danych, który bezpośrednio obsługuje określanie źródła zdarzeń. Usługi Azure Cosmos DB, MongoDB, Cassandra, CouchDB i RavenDB są dobrymi kandydatami.
Podobnie jak we wszystkich wzorcach i technologiach, należy wdrożyć strategicznie i w razie potrzeby. Określanie źródła zdarzeń może zapewnić zwiększoną wydajność i skalowalność, ale kosztem złożoności i krzywej uczenia się.