Generowanie wstępnie wypełnionych widoków dla danych w co najmniej jednym magazynie danych, gdy dane nie są idealnie sformatowane dla wymaganych operacji zapytania. Może to pomóc w obsłudze wydajnych zapytań i wyodrębnianiu danych, a także zwiększyć wydajność aplikacji.
Kontekst i problem
W przypadku przechowywania danych priorytetem dla deweloperów i administratorów danych jest często sposób przechowywania danych, w przeciwieństwie do sposobu ich odczytywania. Wybrany format magazynu jest zwykle blisko związany z formatem danych, wymaganiami dotyczącymi zarządzania rozmiarem i integralnością danych oraz typem używanego magazynu. Na przykład w przypadku używania magazynu dokumentów NoSQL dane są często reprezentowane jako seria agregacji, z których każda zawiera wszystkie informacje dla danej jednostki.
Może mieć to jednak negatywny wpływ na zapytania. Gdy zapytanie wymaga tylko podzbioru danych z niektórych jednostek, takich jak podsumowanie zamówień dla wielu klientów bez wszystkich szczegółów zamówień, musi wyodrębnić wszystkie dane odpowiednich jednostek w celu uzyskania wymaganych informacji.
Rozwiązanie
Aby obsługa zapytań była wydajna, typowym rozwiązaniem jest generowanie z wyprzedzeniem widoku, który materializuje dane w formacie pasującym do wymaganego zestawu wyników. Wzorzec zmaterializowanego widoku opisuje generowanie wstępnie wypełnionych widoków danych w środowiskach, gdzie źródło danych nie ma formatu odpowiedniego do wykonywania zapytań, gdzie generowanie odpowiednich zapytań jest trudne lub gdzie wydajność zapytań jest niska z powodu rodzaju danych lub magazynu danych.
Te zmaterializowane widoki, które zawierają tylko dane wymagane przez zapytanie, zezwalają aplikacjom na szybkie uzyskiwanie potrzebnych informacji. Oprócz dołączania tabel lub łączenia jednostek danych, zmaterializowane widoki mogą obejmować bieżące wartości kolumn obliczeniowych lub elementów danych, wyniki łączenia wartości lub wykonania przekształceń elementów danych oraz wartości określone jako część zapytania. Zmaterializowany widok można nawet zoptymalizować pod kątem pojedynczego zapytania.
Kluczowy punkt to fakt, że zmaterializowany widok i zawarte w nim dane są jednorazowe, ponieważ można je całkowicie odbudować z poziomu źródłowych magazynów danych. Zmaterializowany widok nigdy nie jest aktualizowany bezpośrednio przez aplikację i dlatego jest to wyspecjalizowana pamięć podręczna.
Po zmianie źródła danych dla widoku trzeba zaktualizować ten widok, aby uwzględnić nowe informacje. Można zaplanować tę akcję do wykonania automatycznego lub gdy system wykryje zmianę oryginalnych danych. W niektórych przypadkach może być konieczne ponowne ręczne wygenerowanie widoku. Na rysunku przedstawiono przykład sposobu użycia wzorca zmaterializowanego widoku.
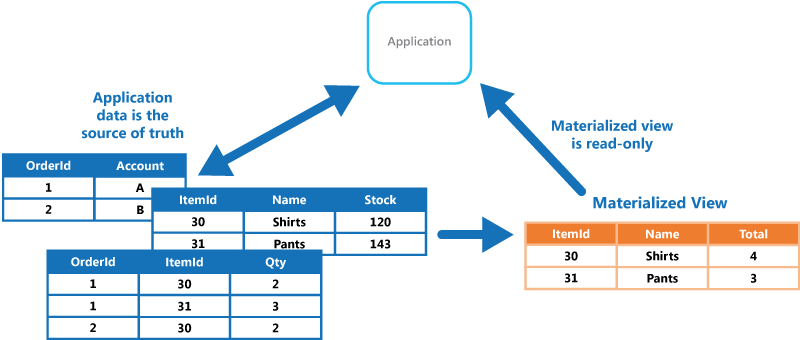
Problemy i kwestie do rozważenia
Podczas podejmowania decyzji o sposobie wdrożenia tego wzorca należy rozważyć następujące punkty:
Sposób i moment aktualizowania widoku. W idealnej sytuacji zostanie on ponownie wygenerowany w odpowiedzi na zdarzenie wskazujące zmianę danych źródłowych, chociaż może to prowadzić do nadmiernego obciążenia, jeśli dane źródłowe zmienią się szybko. W celu ponownego wygenerowania widoku można również rozważyć użycie zaplanowanego zadania, wyzwalacza zewnętrznego lub akcji ręcznej.
W niektórych systemach, na przykład w których wzorzec pozyskiwania danych zdarzenia jest używany do obsługi magazynu zawierającego tylko zdarzenia modyfikujące dane, zmaterializowane widoki są niezbędne. Wstępne wypełnianie widoków przez sprawdzenie wszystkich zdarzeń w celu określenia bieżącego stanu może być jedynym sposobem uzyskania informacji z magazynu zdarzeń. Jeśli nie używasz opcji pozyskiwania danych zdarzeń, musisz zastanowić się, czy zmaterializowany widok faktycznie jest pomocny. Zmaterializowane widoki można zazwyczaj dopasować specjalnie do jednego zapytania lub ich niewielkiej liczby. W przypadku użycia wielu zapytań zmaterializowane widoki mogą spowodować powstanie niemożliwych do zaakceptowania wymagań dotyczących pojemności magazynu oraz kosztów magazynowania.
Podczas generowania widoku i jego aktualizowania, jeśli odbywa się ono zgodnie z harmonogramem, należy wziąć uwagę wpływ na dane. Jeśli źródło danych zmienia się podczas generowania widoku, kopia danych w widoku nie będzie w pełni spójna z oryginalnymi danymi.
Weź pod uwagę lokalizację przechowywania widoku. Widok nie musi znajdować się w tym samym magazynie lub partycji co oryginalne dane. Może być to podzbiór z kilku różnych połączonych partycji.
Utracony widok można ponownie skompilować. Z tego powodu, jeśli widok jest przejściowy i służy tylko do zwiększenia wydajności zapytań przez odzwierciedlenie aktualnego stanu danych lub do poprawienia skalowalności, można go przechowywać w pamięci podręcznej lub w mniej niezawodnej lokalizacji.
W przypadku definiowania zmaterializowanego widoku zmaksymalizuj jego wartość, dodając kolumny lub elementy danych w oparciu o obliczenia lub przekształcenia istniejących elementów danych, o wartości przekazane w zapytaniu lub o kombinacje tych wartości (jeśli ma to zastosowanie).
Jeśli mechanizm magazynu obsługuje indeksowanie zmaterializowanego widoku, zastanów się nad jej użyciem w celu dalszego zwiększenia wydajności. Większość relacyjnych baz danych obsługuje indeksowanie widoków, tak jak rozwiązania danych big data oparte na usłudze Apache Hadoop.
Kiedy używać tego wzorca
Ten wzorzec jest przydatny w przypadku:
- Tworzenia zmaterializowanych widoków danych, dla których trudno jest wykonać zapytanie bezpośrednie lub gdy zapytania muszą być bardzo złożone, aby wyodrębnić dane przechowywane w sposób znormalizowany, ze strukturą częściową i bez struktury.
- Tworzenia widoków tymczasowe, które mogą znacznie zwiększyć wydajność zapytań lub mogą działać bezpośrednio jako widoki źródłowe lub obiektów transferu danych dla interfejsu użytkownika lub na potrzeby raportowania albo wyświetlania.
- Sporadycznej obsługi połączonych lub rozłączonych scenariuszy, w których połączenie z magazynem danych nie jest zawsze dostępne. W takim przypadku widok może być buforowany lokalnie.
- Upraszczania zapytań i uwidaczniania danych na potrzeby eksperymentowania w sposób, który nie wymaga znajomości formatu danych źródłowych. Na przykład przez dołączenie różnych tabel do co najmniej jednej bazy danych lub co najmniej jednej domeny w magazynach NoSQL, a następnie sformatowanie danych na potrzeby ewentualnego użycia.
- Zapewniania dostępu do określonych podzbiorów danych źródłowych, które ze względów bezpieczeństwa lub prywatności nie powinny być ogólnodostępne, otwarte na modyfikacje ani w pełni uwidaczniane dla użytkowników.
- Łączenia różnych magazynów danych w celu skorzystania z ich indywidualnych możliwości. Na przykład użycie do przechowywania zmaterializowanych widoków magazynu w chmurze, który oferuje efektywne zapisywania jako magazyn danych referencyjnych, oraz relacyjnego bazy danych z wysoką wydajnością odczytywania i wykonywania zapytań.
- W przypadku korzystania z mikrousług zaleca się ich luźne łączenie, w tym ich przechowywanie danych. W związku z tym zmaterializowane widoki mogą pomóc w konsolidacji danych z usług. Jeśli zmaterializowane widoki nie są odpowiednie w architekturze mikrousług lub konkretnym scenariuszu, rozważ użycie dobrze zdefiniowanych granic, które są zgodne z projektem opartym na domenie (DDD) i agregują dane po żądaniu.
Te wzorzec nie jest użyteczny w następujących sytuacjach:
- Wykonywanie zapytań dotyczących źródła danych jest proste i łatwe.
- Źródło danych zmienia się bardzo szybko lub można uzyskać dostęp do niego bez korzystania z widoku. W takich sytuacjach należy unikać obciążenia przetwarzania podczas tworzenia widoków.
- Spójność ma wysoki priorytet. Widoki nie zawsze mogą być w pełni spójne z oryginalnymi danymi.
Projekt obciążenia
Architekt powinien ocenić, w jaki sposób wzorzec zmaterializowanego widoku może być używany w projekcie obciążenia, aby sprostać celom i zasadom opisanym w filarach platformy Azure Well-Architected Framework. Na przykład:
| Filar | Jak ten wzorzec obsługuje cele filaru |
|---|---|
| Wydajność pomaga wydajnie sprostać zapotrzebowaniu dzięki optymalizacjom skalowania, danych, kodu. | Zmaterializowane widoki przechowują wyniki złożonych obliczeń lub zapytań bez konieczności ponownego obliczania aparatu bazy danych lub klienta dla każdego żądania. Ten projekt zmniejsza ogólne zużycie zasobów. - PE:08 Wydajność danych |
Podobnie jak w przypadku każdej decyzji projektowej, należy rozważyć wszelkie kompromisy w stosunku do celów innych filarów, które mogą zostać wprowadzone przy użyciu tego wzorca.
Przykład
Na poniższej ilustracji przedstawiono przykład użycia wzorca zmaterializowanego widoku do wygenerowania podsumowania sprzedaży. Dane w tabelach Order (Zamówienie), OrderItem (Element zamówienia) i Customer (Klient) w oddzielnych partycjach konta magazynu platformy Azure są łączone w celu wygenerowania widoku zawierającego łączną wartość sprzedaży każdego produktu z kategorii Electronics (Elektronika) i liczbę klientów, którzy kupili poszczególne elementy.
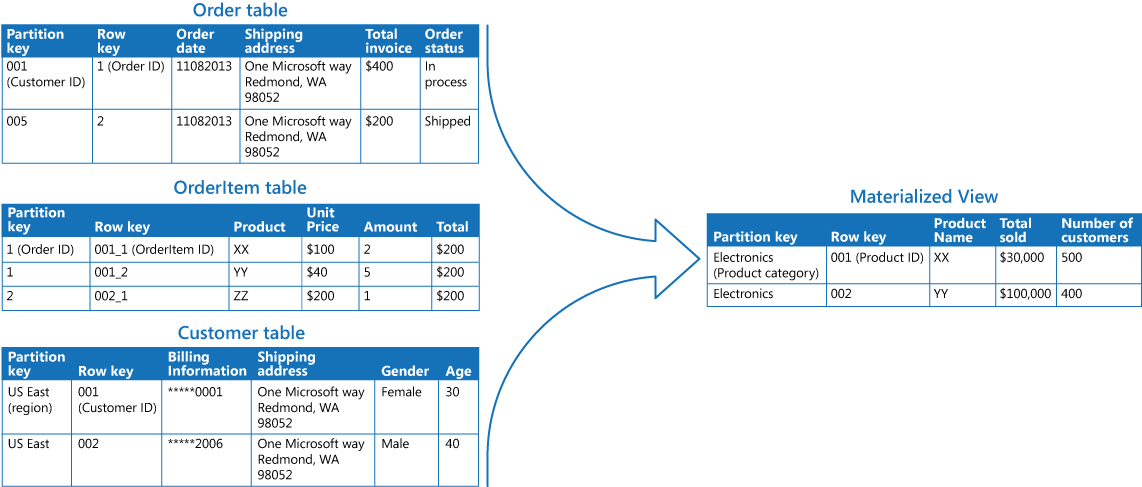
Utworzenie tego zmaterializowanego widoku wymaga złożonych zapytań. Jednak uwidaczniając wynik zapytania w postaci zmaterializowanego widoku, użytkownicy mogą łatwo uzyskać wyniki i używać ich bezpośrednio lub dołączać je do innego zapytania. Widok będzie prawdopodobnie używany w systemie raportowania lub na pulpicie nawigacyjnym i będzie można go aktualizować zgodnie z harmonogramem, na przykład co tydzień.
Chociaż w tym przykładzie użyto usługi Azure Table Storage, wiele systemów zarządzania relacyjnymi bazami danych zapewnia natywną obsługę zmaterializowanych widoków.
Następne kroki
- Podstawy spójności danych. W zmaterializowanym widoku należy obsługiwać informacje zbiorcze, aby odzwierciedlał on odpowiednie wartości danych. Jeśli wartości danych się zmienią, aktualizowanie danych podsumowania w czasie rzeczywistym może być niepraktyczne, a zamiast tego trzeba będzie przyjąć ostatecznie podejście spójne. Podsumowuje zagadnienia związane z utrzymywaniem zgodności danych rozproszonych i opisuje korzyści i kompromisy dla różnych modeli spójności.
Powiązane zasoby
Podczas implementowania tego wzorca mogą być również istotne następujące wzorce:
- Wzorzec podziału odpowiedzialności polecenia i zapytania (CQRS). Służy do aktualizowania informacji w zmaterializowanym widoku przez reagowanie na zdarzenia występujące po zmianie wartości odpowiednich danych.
- Wzorzec określania źródła zdarzeń. Należy używać go w połączeniu z wzorcem CQRS w celu zarządzania danymi w zmaterializowanym widoku. Po zmianie wartości danych, na których opiera się zmaterializowany widok, system może wywoływać zdarzenia, które opisują te zmiany, a następnie zapisywać je w magazynie zdarzeń.
- Wzorzec indeksowania tabeli. Dane w zmaterializowanym widoku są zwykle organizowane według klucza podstawowego, ale zapytania mogą potrzebować informacji pobranych z tego widoku przez zbadanie danych w innych polach. Służy do tworzenia indeksów pomocniczych za pośrednictwem zestawów danych dla magazynów danych, które nie obsługują natywnych indeksów pomocniczych.