Zamiast przechowywać wyłącznie bieżący stan danych w domenie, można użyć magazynu tylko do dołączania w celu rejestrowania pełnych szeregów działań wykonywanych na tych danych. Magazyn działa jak system rejestrowania i może służyć do zmaterializowania obiektów domeny. Pozwala to na uproszczenie zadań w złożonych domenach przez uniknięcie konieczności synchronizowania modelu danych i domeny biznesowej, jednocześnie poprawiając wydajność, skalowalność i elastyczność. Ponadto może zapewnić spójność danych transakcyjnych przy zachowaniu pełnego dziennika inspekcji i historii umożliwiającej akcje kompensacyjne.
Kontekst i problem
Większość aplikacji pracuje z danymi; typowym podejściem jest utrzymanie przez aplikację bieżącego stanu danych przez ich aktualizację, gdy użytkownik pracuje z nimi. Na przykład w tradycyjnym modelu tworzenia, odczytu, aktualizowania i usuwania (CRUD) typowy proces danych polega na odczytywaniu danych z magazynu, dokonywaniu pewnych modyfikacji i aktualizowaniu bieżącego stanu danych przy użyciu nowych wartości — często przy użyciu transakcji, które blokują dane.
Podejście CRUD ma następujące ograniczenia:
Systemy CRUD wykonują operacje aktualizacji bezpośrednio w magazynie danych. Te operacje mogą spowalniać wydajność i czas odpowiedzi oraz ograniczać skalowalność ze względu na wymagane obciążenie przetwarzania.
W domenie współpracy z wieloma równoczesnymi użytkownikami konflikty aktualizacji danych są bardziej prawdopodobne, ponieważ operacje aktualizacji odbywają się na pojedynczym elemencie danych.
Jeśli nie istnieje inny mechanizm inspekcji, który rejestruje szczegóły każdej operacji w osobnym dzienniku, historia zostanie utracona.
Rozwiązanie
Wzorzec określania źródła zdarzeń definiuje podejście do obsługi operacji na danych, które są sterowane przez sekwencję zdarzeń, z których każde jest rejestrowane w magazynie tylko do dołączania. Kod aplikacji wysyła szereg zdarzeń, które obowiązkowo opisują każde działanie, które nastąpiło względem danych w magazynie zdarzeń, gdzie zostaje utrwalone. Każde zdarzenie reprezentuje zestaw zmian danych (na przykład AddedItemToOrder).
Zdarzenia są utrwalane w magazynie zdarzeń, który działa jak system rejestrowania (autorytatywne źródło danych) wobec bieżącego stanu danych. Magazyn zdarzeń zwykle publikuje te zdarzenia, tak aby odbiorca mógł zostać powiadomiony i w razie potrzeby mógł je obsłużyć. Odbiorca mógłby na przykład zainicjować zadania, które stosują operacje w zdarzeniach do innych systemów, lub wykonać inną powiązaną akcję, która jest wymagana do ukończenia operacji. Należy zauważyć, że kod aplikacji, który generuje zdarzenia, jest całkowicie niezależny od systemów, które subskrybują zdarzenia.
Zadaniem typowych zastosowań zdarzeń publikowanych przez magazyn zdarzeń jest zachowanie zmaterializowanych widoków jednostek podczas wprowadzania do nich zmian przez akcje w aplikacji oraz integracja z systemami zewnętrznymi. Na przykład system może zachować zmaterializowany widok wszystkich zamówień klienta używanych do wypełniania elementów interfejsu użytkownika. Aplikacja dodaje nowe zamówienia, dodaje lub usuwa elementy w zamówieniu i dodaje informacje o wysyłki. Zdarzenia opisujące te zmiany mogą być obsługiwane i używane do aktualizowania zmaterializowanego widoku.
W dowolnym momencie aplikacje mogą odczytywać historię zdarzeń. Następnie można go użyć do zmaterializowania bieżącego stanu jednostki, odtwarzając i zużywając wszystkie zdarzenia powiązane z jednostką. Ten proces może wystąpić na żądanie, aby zmaterializować obiekt domeny podczas obsługi żądania. Lub proces odbywa się za pomocą zaplanowanego zadania, aby stan jednostki można było przechowywać jako zmaterializowany widok w celu obsługi warstwy prezentacji.
Na schemacie przedstawiono omówienie wzorca, w tym niektóre opcje korzystania ze strumienia zdarzeń, takie jak tworzenie zmaterializowanego widoku, integrowanie zdarzeń z systemami i aplikacjami zewnętrznymi oraz odtwarzanie zdarzeń w celu utworzenia projekcji bieżącego stanu określonej jednostki.
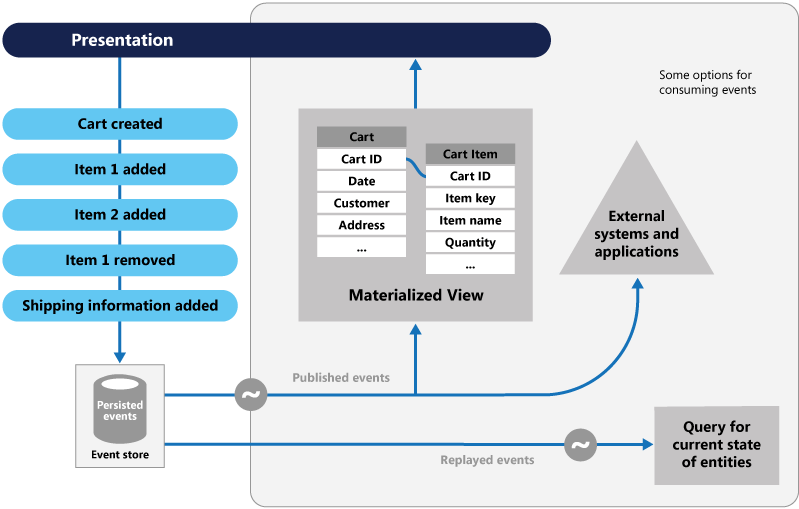
Wzorzec określania źródła zdarzeń zapewnia następujące korzyści:
Zdarzenia są niezmienne i mogą być przechowywane przy użyciu operacji tylko do dołączania. Interfejs użytkownika, przepływ pracy lub proces, który zainicjował zdarzenie, może kontynuować działanie, a zadania, które obsługują zdarzenia, mogą działać w tle. Ten proces, w połączeniu z faktem, że nie ma rywalizacji podczas przetwarzania transakcji, może znacznie poprawić wydajność i skalowalność aplikacji, zwłaszcza na poziomie prezentacji lub interfejsie użytkownika.
Zdarzenia to proste obiekty, które opisują jakąś akcję, która wystąpiła, wraz z skojarzonymi danymi wymaganymi do opisania akcji reprezentowanej przez zdarzenie. Zdarzenia nie aktualizują bezpośrednio magazynu danych. Są one po prostu rejestrowane w celu obsługi w odpowiednim czasie. Użycie zdarzeń może uprościć implementację i zarządzanie.
Zdarzenia zwykle mają znaczenie dla eksperta domeny, podczas gdy niezgodność obiektów relacyjnych impedancji może sprawić, że złożone tabele bazy danych staną się trudne do zrozumienia. Tabele są sztucznymi konstrukcjami, które reprezentują bieżący stan systemu, a nie zdarzenia, które wystąpiły.
Określanie źródła zdarzenia może zapobiec sytuacji, w której równoczesne aktualizacje będą powodować konflikty, ponieważ eliminuje wymóg bezpośredniej aktualizacji obiektów w magazynie danych. Jednak model domeny nadal musi być projektowany tak, aby zabezpieczać przed żądaniami, które mogłyby prowadzić do niespójnego stanu.
Magazyn zdarzeń tylko do dołączania zawiera dziennik inspekcji, który może służyć do monitorowania akcji wykonywanych w magazynie danych. Może on ponownie wygenerować bieżący stan jako zmaterializowane widoki lub projekcje przez ponowne odtworzenie zdarzeń w dowolnym momencie i może pomóc w testowaniu i debugowaniu systemu. Ponadto wymóg użycia zdarzeń wyrównywujących w celu anulowania zmian może zapewnić historię zmian, które zostały odwrócone. Ta funkcja nie byłaby taka, gdyby model przechowywał bieżący stan. Lista zdarzeń może również służyć do analizowania wydajności aplikacji i wykrywania trendów zachowań użytkowników. Może też służyć do uzyskiwania innych przydatnych informacji biznesowych.
Magazyn zdarzeń wywołuje zdarzenia, a zadania w odpowiedzi na te zdarzenia wykonują operacje. To oddzielenie zadań od zdarzeń zapewnia elastyczność i rozszerzalność. Zadania mają informacje na temat typu zdarzenia i danych dotyczących zdarzenia, ale nie na temat operacji, która wyzwoliła zdarzenie. Ponadto wiele zadań może obsługiwać każde zdarzenie. Dzięki temu jest możliwa łatwa integracja z innymi usługami i systemami, które nasłuchują jedynie nowych zdarzeń wywołanych przez magazyn zdarzeń. Jednak zdarzenia określania źródła zdarzeń mogą być na bardzo niskim poziomie i zamiast tego może być konieczne wygenerowanie poszczególnych zdarzeń integracji.
Określanie źródła zdarzeń jest często łączone ze wzorcem CQRS przez wykonywanie zadań zarządzania danymi w odpowiedzi na zdarzenia i przez materializowanie widoków z przechowywanych zdarzeń.
Problemy i kwestie do rozważenia
Podczas podejmowania decyzji o sposobie wdrożenia tego wzorca należy rozważyć następujące punkty:
System będzie ostatecznie spójny tylko podczas tworzenia zmaterializowanych widoków lub generowania projekcji danych przez odtwarzanie zdarzeń. Istnieje pewne opóźnienie między dodawaniem zdarzeń przez aplikację do magazynu zdarzeń w wyniku obsługi żądania, publikowania zdarzeń i odbiorców zdarzeń, które je obsługują. W tym okresie do magazynu zdarzeń mogły przybyć nowe zdarzenia opisujące dalsze zmiany jednostek. System powinien być zaprojektowany tak, aby uwzględniał spójność ostateczną w tych scenariuszach.
Uwaga
Aby uzyskać więcej informacji na temat spójności ostatecznej, zobacz temat Data Consistency Primer (Podstawy spójności danych).
Magazyn zdarzeń jest stałym źródłem informacji, więc dane zdarzenia nigdy nie powinny być aktualizowane. Jedynym sposobem na zaktualizowanie jednostki w celu wycofania zmiany jest dodanie zdarzenia kompensacyjnego do magazynu zdarzeń. Jeśli format (a nie dane) utrwalonych zdarzeń wymaga wprowadzenia zmian, na przykład podczas migracji, połączenie istniejących zdarzeń w magazynie z nową wersją może okazać się trudne. Konieczna może być iteracja wszystkich zdarzeń wprowadzających zmiany, dzięki czemu będą zgodne z nowym formatem, lub dodanie nowych zdarzeń używających nowego formatu. Należy rozważyć użycie sygnatury wersji w każdej wersji schematu zdarzeń w celu zachowania zarówno starego, jak i nowego formatu zdarzeń.
Aplikacje wielowątkowe i wiele wystąpień aplikacji mogą przechowywać zdarzenia w magazynie zdarzeń. Spójność zdarzeń znajdujących się w magazynie zdarzeń jest istotna, podobnie jak kolejność zdarzeń, która ma wpływ na poszczególne jednostki (kolejność, w jakiej występują zmiany jednostki, ma wpływ na jej bieżący stan). Dodanie sygnatury czasowej do każdego zdarzenia może pomóc uniknąć problemów. Inną powszechną praktyką jest adnotowanie identyfikatorem przyrostowym każdego zdarzenia wynikającego z żądania. Jeśli dwie akcje podejmują próbę dodania zdarzeń dla tej samej jednostki w tym samym czasie, magazyn zdarzeń może odrzucić zdarzenie pasujące do istniejącego identyfikatora jednostki i identyfikatora zdarzenia.
Nie ma standardowego podejścia ani istniejących mechanizmów, takich jak zapytania SQL, do odczytywania zdarzeń w celu uzyskania informacji. Jedyne dane, które można wyodrębnić, to strumień zdarzeń wykorzystujący identyfikator zdarzenia jako kryterium. Identyfikator zdarzenia przeważnie wykonuje mapowanie na poszczególne jednostki. Bieżący stan jednostki można określić tylko przez odtworzenie wszystkich zdarzeń, które odnoszą się do niej, względem oryginalnego stanu tej jednostki.
Długość każdego strumienia zdarzeń ma wpływ na zarządzanie i aktualizowanie systemu. W przypadku dużych strumieni należy rozważyć utworzenie migawek w określonych odstępach czasu, takich jak określona liczba zdarzeń. Bieżący stan jednostki można uzyskać z migawki i przez odtworzenie dowolnych zdarzeń, które wystąpiły po tym punkcie w czasie. Aby uzyskać więcej informacji na temat tworzenia migawek danych, zobacz Podstawowo-podrzędna replikacja migawek.
Mimo że określanie źródła zdarzeń minimalizuje szanse na wystąpienie konfliktu aktualizacji z danymi, aplikacja musi nadal mieć możliwość postępowania w przypadku niespójności wynikających ze spójności ostatecznej i braku transakcji. Na przykład zdarzenie wskazujące zmniejszenie zapasów może pojawić się w magazynie danych podczas składania zamówienia dla tego elementu. Taka sytuacja skutkuje wymaganiem uzgodnienia dwóch operacji, doradzając klientowi lub tworząc zamówienie wsteczne.
Publikacja zdarzeń może być co najmniej raz, więc użytkownicy zdarzeń muszą być idempotentni. Nie mogą ponownie stosować aktualizacji opisanej w zdarzeniu, jeśli zdarzenie jest obsługiwane więcej niż raz. Wiele wystąpień konsumenta może obsługiwać i agregować właściwość jednostki, na przykład całkowitą liczbę złożonych zamówień. Tylko jeden z nich musi pomyślnie zwiększać agregację, gdy wystąpi zdarzenie złożone w zamówieniu. Chociaż ten wynik nie jest kluczową cechą określania źródła zdarzeń, jest to zwykła decyzja implementacji.
Wybrany magazyn zdarzeń musi obsługiwać obciążenie zdarzenia wygenerowane przez aplikację.
Należy pamiętać o scenariuszach, w których przetwarzanie jednego zdarzenia obejmuje utworzenie jednego lub kilku nowych zdarzeń, ponieważ może to spowodować nieskończoną pętlę.
Kiedy używać tego wzorca
Tego wzorca należy używać w następujących scenariuszach:
Gdy zachodzi potrzeba przechwycenia zamiaru, celu lub przyczyny w danych. Na przykład zmiany w jednostce klienta można przechwycić jako serię określonych typów zdarzeń, takich jak Przeniesiono do domu, Zamknięte konto lub Zmarły.
Gdy konieczne jest zminimalizowanie lub całkowite wykluczenie wystąpienia konfliktu aktualizacji względem danych.
Jeśli chcesz rejestrować zdarzenia, aby odtworzyć je w celu przywrócenia stanu systemu, wycofać zmiany lub zachować historię i dziennik inspekcji. Na przykład jeśli zadanie obejmuje wiele kroków, może być konieczne wykonanie akcji w celu przywrócenia aktualizacji, a następnie odtworzenie niektórych kroków w celu przywrócenia danych z powrotem do spójnego stanu.
W przypadku korzystania ze zdarzeń. Jest to naturalna funkcja działania aplikacji i wymaga niewielkiego nakładu pracy nad programowaniem lub implementacją.
Jeśli musisz rozdzielić proces wprowadzania danych lub zaktualizować dane z zadań wymaganych do zastosowania tych akcji. Ta zmiana może spowodować zwiększenie wydajności interfejsu użytkownika lub dystrybuowanie zdarzeń do innych odbiorników, które podejmują działania po wystąpieniu zdarzeń. Na przykład można zintegrować system płac z witryną internetową przesyłania wydatków. Zdarzenia zgłaszane przez magazyn zdarzeń w odpowiedzi na aktualizacje danych wprowadzone w witrynie internetowej będą używane zarówno przez witrynę internetową, jak i system płac.
Jeśli chcesz, aby elastyczność była w stanie zmienić format zmaterializowanych modeli i danych jednostki, jeśli wymagania się zmieniają, lub — w przypadku użycia z usługą CQRS — musisz dostosować model odczytu lub widoki, które uwidaczniają dane.
W przypadku użycia z usługą CQRS i spójność ostateczna jest akceptowalna podczas aktualizowania modelu odczytu lub wpływ na wydajność ponownego wypełniania jednostek i danych ze strumienia zdarzeń jest akceptowalny.
Ten wzorzec może nie być użyteczny w następujących sytuacjach:
Małe lub proste domeny, systemy, które mają niewielką logikę biznesową lub nie mają jej wcale, lub systemy bezdomenowe, które naturalnie działają prawidłowo z tradycyjnymi mechanizmami zarządzania danymi CRUD.
Systemy, w których jest wymagana spójność i aktualizacje w czasie rzeczywistym widoków danych.
Systemy, w których dzienniki inspekcji, historia i możliwości wycofywania i powtarzania akcji nie są wymagane.
Systemy, w których występuje tylko małe wystąpienie konfliktowych aktualizacji danych bazowych. Na przykład systemy, które raczej głównie dodają, a nie aktualizują dane.
Projekt obciążenia
Architekt powinien ocenić, w jaki sposób wzorzec określania źródła zdarzeń może być używany w projekcie obciążenia, aby sprostać celom i zasadom opisanym w filarach platformy Azure Well-Architected Framework. Na przykład:
| Filar | Jak ten wzorzec obsługuje cele filaru |
|---|---|
| Decyzje projektowe dotyczące niezawodności pomagają obciążeniu stać się odporne na awarię i zapewnić, że zostanie przywrócony do w pełni funkcjonalnego stanu po wystąpieniu awarii. | Ze względu na przechwytywanie historii zmian w złożonym procesie biznesowym może ułatwić rekonstrukcję stanu, jeśli trzeba odzyskać magazyny stanów. - PARTYcjonowanie danych RE:06 - RE:09 Odzyskiwanie po awarii |
| Wydajność pomaga wydajnie sprostać zapotrzebowaniu dzięki optymalizacjom skalowania, danych, kodu. | Ten wzorzec, zwykle w połączeniu z usługą CQRS, odpowiedni projekt domeny i strategiczne tworzenie migawek, może poprawić wydajność obciążenia ze względu na niepodzielne operacje tylko do dołączania i unikanie blokowania bazy danych dla zapisów i odczytów. - PE:08 Wydajność danych |
Podobnie jak w przypadku każdej decyzji projektowej, należy rozważyć wszelkie kompromisy w stosunku do celów innych filarów, które mogą zostać wprowadzone przy użyciu tego wzorca.
Przykład
System zarządzania konferencjami musi śledzić liczbę ukończonych rezerwacji na konferencji. W ten sposób może sprawdzić, czy są jeszcze dostępne miejsca, gdy potencjalny uczestnik próbuje dokonać rezerwacji. System może przechowywać łączną liczbę rezerwacji dla danej konferencji na co najmniej dwa sposoby:
System może przechowywać informacje o całkowitej liczbie rezerwacji jako osobne jednostki w bazie danych, która przechowuje informacje o rezerwacji. W momencie dokonywania lub anulowania rezerwacji system może odpowiednio powiększyć lub pomniejszyć tę liczbę. Ta metoda teoretycznie jest prosta, lecz może powodować problemy ze skalowalnością w przypadku dużej liczby uczestników próbujących zarezerwować miejsce w krótkim czasie. Na przykład w ostatni dzień lub przed zamknięciem okresu rezerwacji.
System może przechowywać informacje o dokonanych i anulowanych rezerwacjach jako zdarzenia przechowywane w magazynie zdarzeń. Następnie może obliczyć liczbę dostępnych miejsc przez odtworzenie tych zdarzeń. Ta metoda może być bardziej skalowalna dzięki niezmienności zdarzeń. System musi jedynie mieć możliwość odczytywania danych z magazynu zdarzeń lub dołączania danych do magazynu zdarzeń. Informacje zdarzeń o dokonaniu i anulowaniu rezerwacji nigdy nie są modyfikowane.
Na poniższym diagramie pokazano, w jaki sposób za pomocą określania źródła zdarzeń można zaimplementować podsystem rezerwacji miejsc systemu zarządzania konferencjami.
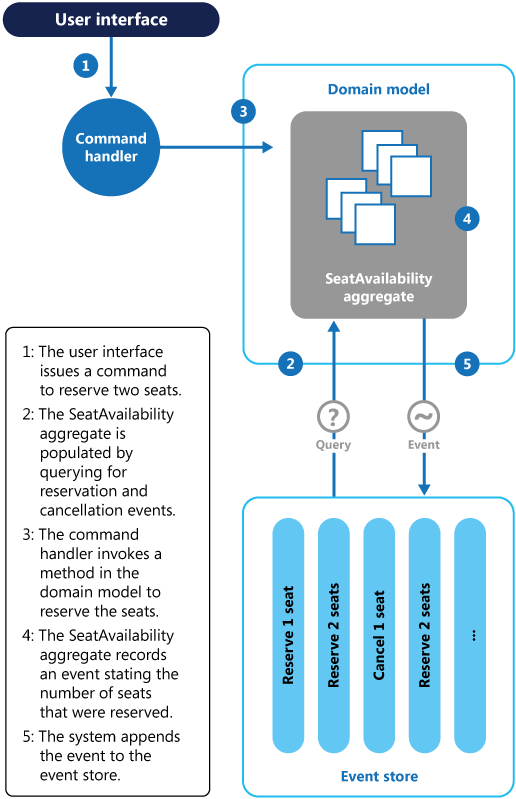
Sekwencja akcji mających na celu zarezerwowanie dwóch miejsc jest następująca:
Interfejs użytkownika wydaje polecenie w celu zarezerwowania miejsc dla dwóch uczestników. Polecenie jest obsługiwane przez oddzielny program obsługi poleceń. Jest to fragment logiki, który jest całkowicie niezależny od interfejsu użytkownika i który jest odpowiedzialny za obsługę żądań publikowanych jako polecenia.
Agregacja zawierająca informacje o wszystkich rezerwacjach dla danej konferencji jest tworzona przez wykonywanie zapytań opisujących dokonane i anulowane rezerwacje. Ta agregacja jest nazywana
SeatAvailabilityi znajduje się w modelu domeny, który udostępnia metody wykonywania zapytań i modyfikowania danych w agregacji.Niektóre optymalizacje do rozważenia korzystają z migawek (dzięki czemu nie trzeba wykonywać zapytań i powtarzać pełnej listy zdarzeń w celu uzyskania bieżącego stanu agregacji) i obsługi buforowanej kopii agregacji w pamięci.
Program obsługi poleceń wywołuje metodę udostępnianą przez model domeny, aby dokonać rezerwacji.
Agregacja
SeatAvailabilityrejestruje zdarzenie zawierające liczbę miejsc, które zostały zarezerwowane. Następnym razem, gdy agregacja zastosuje zdarzenia, wszystkie rezerwacje posłużą do obliczenia liczby pozostałych miejsc.System dołącza nowe zdarzenie do listy zdarzeń w magazynie zdarzeń.
Jeśli użytkownik anuluje rezerwację, system wykonuje podobną procedurę, z tą różnicą, że program obsługi poleceń wydaje polecenie, które generuje zdarzenie anulowania miejsca i dołącza je do magazynu zdarzeń.
Oprócz zapewnienia większego zakresu skalowalności, korzystanie z magazynu zdarzeń zapewnia również pełną historię lub dziennik inspekcji rezerwacji i anulowania na konferencji. Zdarzenia w magazynie zdarzeń są precyzyjnymi rekordami. Nie ma potrzeby utrwalania agregacji w żaden inny sposób, ponieważ system może łatwo odtworzyć zdarzenia i przywrócić stan do dowolnego punktu w czasie.
Więcej informacji na temat tego przykładu znajduje się w temacie Introducing Event Sourcing (Wprowadzenie do określania źródła zdarzeń).
Następne kroki
Podstawy spójności danych. Jeśli używasz określania źródła zdarzeń z oddzielnym magazynem odczytu lub zmaterializowanymi widokami, dane odczytu nie będą natychmiast spójne. Zamiast tego dane będą ostatecznie spójne. W tym artykule przedstawiono podsumowanie problemów związanych z utrzymaniem spójności w przypadku danych rozproszonych.
Data Partitioning Guidance (Wskazówki dotyczące partycjonowania danych). Dane są często partycjonowane w przypadku używania określania źródła zdarzeń w celu zwiększenia skalowalności, zmniejszenia rywalizacji i optymalizacji wydajności. W tym artykule opisano sposób dzielenia danych na odrębne partycje oraz problemy, które mogą wystąpić.
Blog Martina Fowlera:
Powiązane zasoby
Podczas implementowania tego wzorca mogą być istotne następujące wzorce i wskazówki:
Wzorzec podziału odpowiedzialności polecenia i zapytania (CQRS). Magazyn zapisu, który zapewnia stałe źródło informacji dla implementacji CQRS, często opiera się na implementacji wzorca określania źródła zdarzeń. Opisuje sposób segregowania operacji, które odczytują dane w aplikacji, od operacji, które aktualizują dane przy użyciu osobnych interfejsów.
Materialized View pattern (Wzorzec zmaterializowanego widoku). Magazyn danych używany w systemie opartym na określaniu źródła zdarzeń zwykle nie nadaje się do wydajnego wykonywania zapytań. Zamiast tego typowym podejściem jest generowanie wstępnie wypełnionych widoków danych w regularnych odstępach czasu lub po zmianie danych.
Wzorzec transakcji wyrównującej. Istniejące dane w magazynie określania źródła zdarzeń nie są aktualizowane. Zamiast tego dodawane są nowe wpisy, które przechodzą stan jednostek do nowych wartości. Aby odwrócić zmianę, używane są wpisy wyrównywujące, ponieważ nie jest możliwe odwrócenie poprzedniej zmiany. Wzorzec opisuje, w jaki sposób cofnąć działanie wykonane przez poprzednią operację.