Samouczek: implementowanie wzorca przechwytywania usługi Data Lake w celu zaktualizowania tabeli delty usługi Databricks
W tym samouczku pokazano, jak obsługiwać zdarzenia na koncie magazynu, które ma hierarchiczną przestrzeń nazw.
Utworzysz małe rozwiązanie, które umożliwia użytkownikowi wypełnienie tabeli delty usługi Databricks przez przekazanie pliku wartości rozdzielanych przecinkami (csv), który opisuje zamówienie sprzedaży. To rozwiązanie utworzysz, łącząc ze sobą subskrypcję usługi Event Grid, funkcję platformy Azure i zadanie w usłudze Azure Databricks.
Ten samouczek obejmuje następujące kroki:
- Utwórz subskrypcję usługi Event Grid, która wywołuje funkcję platformy Azure.
- Utwórz funkcję platformy Azure, która odbiera powiadomienie z zdarzenia, a następnie uruchamia zadanie w usłudze Azure Databricks.
- Utwórz zadanie usługi Databricks, które wstawia zamówienie klienta do tabeli delty usługi Databricks znajdującej się na koncie magazynu.
Utworzymy to rozwiązanie w odwrotnej kolejności, zaczynając od obszaru roboczego usługi Azure Databricks.
Wymagania wstępne
Utwórz konto magazynu, które ma hierarchiczną przestrzeń nazw (Azure Data Lake Storage). W tym samouczku jest używane konto magazynu o nazwie
contosoorders.Zobacz Tworzenie konta magazynu do użycia z usługą Azure Data Lake Storage.
Upewnij się, że Twoje konto użytkownika ma przypisaną rolę Współautor danych obiektu blob magazynu.
Utwórz jednostkę usługi, utwórz klucz tajny klienta, a następnie przyznaj jednostce usługi dostęp do konta magazynu.
Zobacz Samouczek: nawiązywanie połączenia z usługą Azure Data Lake Storage (kroki od 1 do 3). Po wykonaniu tych kroków wklej wartości identyfikatora dzierżawy, identyfikatora aplikacji i klucza tajnego klienta do pliku tekstowego. Wkrótce będą potrzebne.
Jeśli nie masz subskrypcji platformy Azure, przed rozpoczęciem utwórz bezpłatne konto.
Utwórz zamówienie sprzedaży
Najpierw utwórz plik CSV, który opisuje zamówienie sprzedaży, a następnie przekaż ten plik do konta magazynu. Później użyjesz danych z tego pliku, aby wypełnić pierwszy wiersz w tabeli delta usługi Databricks.
W witrynie Azure Portal przejdź do swojego nowego konta magazynu.
Wybierz pozycję Storage browser-Blob containers-Add container (Kontenery obiektów> blob usługi Storage)> i utwórz nowy kontener o nazwie data (dane).
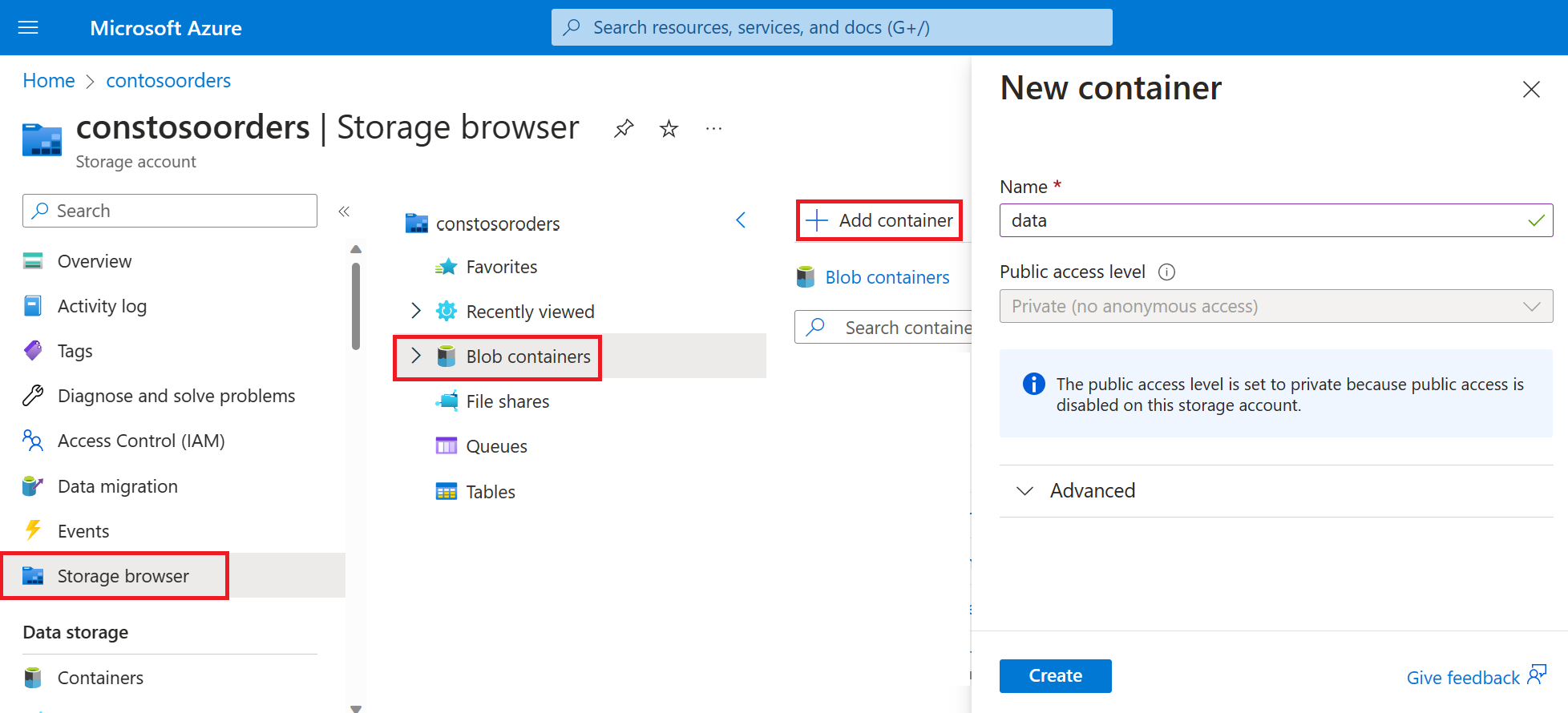
W kontenerze danych utwórz katalog o nazwie input.
Wklej następujący tekst do edytora tekstów.
InvoiceNo,StockCode,Description,Quantity,InvoiceDate,UnitPrice,CustomerID,Country 536365,85123A,WHITE HANGING HEART T-LIGHT HOLDER,6,12/1/2010 8:26,2.55,17850,United KingdomZapisz ten plik na komputerze lokalnym i nadaj mu nazwę data.csv.
W przeglądarce magazynu przekaż ten plik do folderu wejściowego.
Tworzenie zadania w usłudze Azure Databricks
W tej sekcji wykonasz następujące zadania:
- Tworzenie obszaru roboczego usługi Azure Databricks.
- Utwórz notes.
- Utwórz i wypełnij tabelę delty usługi Databricks.
- Dodaj kod, który wstawia wiersze do tabeli delty usługi Databricks.
- Utwórz Zadanie.
Tworzenie obszaru roboczego usługi Azure Databricks
W tej sekcji utworzysz obszar roboczy usługi Azure Databricks przy użyciu witryny Azure Portal.
Tworzenie obszaru roboczego usługi Azure Databricks. Nadaj nazwę obszarowi roboczego
contoso-orders. Zobacz Tworzenie obszaru roboczego usługi Azure Databricks.Tworzenie klastra. Nadaj klastrowi
customer-order-clusternazwę . Zobacz Tworzenie klastra.Utwórz notes. Nadaj notesowi
configure-customer-tablenazwę i wybierz język Python jako domyślny język notesu. Zobacz Tworzenie notesu.
Tworzenie i wypełnianie tabeli delty usługi Databricks
W utworzonym notesie skopiuj i wklej następujący blok kodu do pierwszej komórki, ale nie uruchamiaj jeszcze tego kodu.
Zastąp
appIdwartości zastępcze ,passwordtenantw tym bloku kodu wartościami zebranymi podczas wykonywania wymagań wstępnych tego samouczka.dbutils.widgets.text('source_file', "", "Source File") spark.conf.set("fs.azure.account.auth.type", "OAuth") spark.conf.set("fs.azure.account.oauth.provider.type", "org.apache.hadoop.fs.azurebfs.oauth2.ClientCredsTokenProvider") spark.conf.set("fs.azure.account.oauth2.client.id", "<appId>") spark.conf.set("fs.azure.account.oauth2.client.secret", "<password>") spark.conf.set("fs.azure.account.oauth2.client.endpoint", "https://login.microsoftonline.com/<tenant>/oauth2/token") adlsPath = 'abfss://data@contosoorders.dfs.core.windows.net/' inputPath = adlsPath + dbutils.widgets.get('source_file') customerTablePath = adlsPath + 'delta-tables/customers'Ten kod tworzy widżet o nazwie source_file. Później utworzysz funkcję platformy Azure, która wywołuje ten kod i przekazuje ścieżkę pliku do tego widżetu. Ten kod uwierzytelnia również jednostkę usługi przy użyciu konta magazynu i tworzy pewne zmienne, które będą używane w innych komórkach.
Uwaga
W środowisku produkcyjnym rozważ przechowywanie klucza uwierzytelniania w usłudze Azure Databricks. Następnie dodaj do bloku kodu klucz wyszukiwania zamiast klucza uwierzytelniania.
Na przykład zamiast używać tego wiersza kodu:spark.conf.set("fs.azure.account.oauth2.client.secret", "<password>"), należy użyć następującego wiersza kodu:spark.conf.set("fs.azure.account.oauth2.client.secret", dbutils.secrets.get(scope = "<scope-name>", key = "<key-name-for-service-credential>")).
Po ukończeniu tego samouczka zobacz artykuł Azure Data Lake Storage w witrynie internetowej usługi Azure Databricks, aby zapoznać się z przykładami tego podejścia.Naciśnij klawisze SHIFT+ENTER, aby uruchomić kod w tym bloku.
Skopiuj i wklej następujący blok kodu do innej komórki, a następnie naciśnij SHIFT + ENTER , aby uruchomić kod w tym bloku.
from pyspark.sql.types import StructType, StructField, DoubleType, IntegerType, StringType inputSchema = StructType([ StructField("InvoiceNo", IntegerType(), True), StructField("StockCode", StringType(), True), StructField("Description", StringType(), True), StructField("Quantity", IntegerType(), True), StructField("InvoiceDate", StringType(), True), StructField("UnitPrice", DoubleType(), True), StructField("CustomerID", IntegerType(), True), StructField("Country", StringType(), True) ]) rawDataDF = (spark.read .option("header", "true") .schema(inputSchema) .csv(adlsPath + 'input') ) (rawDataDF.write .mode("overwrite") .format("delta") .saveAsTable("customer_data", path=customerTablePath))Ten kod tworzy tabelę delta usługi Databricks na koncie magazynu, a następnie ładuje pewne początkowe dane z przekazanego wcześniej pliku CSV.
Po pomyślnym uruchomieniu tego bloku kodu usuń ten blok kodu z notesu.
Dodawanie kodu, który wstawia wiersze do tabeli delty usługi Databricks
Skopiuj i wklej następujący blok kodu do innej komórki, ale nie uruchamiaj tej komórki.
upsertDataDF = (spark .read .option("header", "true") .csv(inputPath) ) upsertDataDF.createOrReplaceTempView("customer_data_to_upsert")Ten kod wstawia dane do tymczasowego widoku tabeli przy użyciu danych z pliku CSV. Ścieżka do tego pliku CSV pochodzi z widżetu wejściowego utworzonego we wcześniejszym kroku.
Skopiuj i wklej następujący blok kodu do innej komórki. Ten kod scala zawartość tymczasowego widoku tabeli z tabelą delty usługi Databricks.
%sql MERGE INTO customer_data cd USING customer_data_to_upsert cu ON cd.CustomerID = cu.CustomerID WHEN MATCHED THEN UPDATE SET cd.StockCode = cu.StockCode, cd.Description = cu.Description, cd.InvoiceNo = cu.InvoiceNo, cd.Quantity = cu.Quantity, cd.InvoiceDate = cu.InvoiceDate, cd.UnitPrice = cu.UnitPrice, cd.Country = cu.Country WHEN NOT MATCHED THEN INSERT (InvoiceNo, StockCode, Description, Quantity, InvoiceDate, UnitPrice, CustomerID, Country) VALUES ( cu.InvoiceNo, cu.StockCode, cu.Description, cu.Quantity, cu.InvoiceDate, cu.UnitPrice, cu.CustomerID, cu.Country)
Tworzenie zadania
Utwórz zadanie uruchamiające utworzony wcześniej notes. Później utworzysz funkcję platformy Azure, która uruchamia to zadanie po wystąpieniu zdarzenia.
Wybierz pozycję Nowe zadanie>.
Nadaj zadaniu nazwę, wybierz utworzony notes i klaster. Następnie wybierz pozycję Utwórz , aby utworzyć zadanie.
Tworzenie funkcji platformy Azure
Utwórz funkcję platformy Azure, która uruchamia zadanie.
W obszarze roboczym usługi Azure Databricks kliknij nazwę użytkownika usługi Azure Databricks na górnym pasku, a następnie z listy rozwijanej wybierz pozycję Ustawienia użytkownika.
Na karcie Tokeny dostępu wybierz pozycję Generuj nowy token.
Skopiuj wyświetlony token, a następnie kliknij przycisk Gotowe.
W górnym rogu obszaru roboczego usługi Databricks wybierz ikonę osoby, a następnie wybierz pozycję Ustawienia użytkownika.

Wybierz przycisk Generuj nowy token, a następnie wybierz przycisk Generuj.
Pamiętaj, aby skopiować token do bezpiecznego miejsca. Funkcja platformy Azure wymaga tego tokenu do uwierzytelniania w usłudze Databricks, aby można było uruchomić zadanie.
W menu witryny Azure Portal lub na stronie głównej wybierz pozycję Utwórz zasób.
Na stronie Nowy wybierz pozycję Aplikacja funkcji obliczeniowej>.
Na karcie Podstawowe na stronie Tworzenie aplikacji funkcji wybierz grupę zasobów, a następnie zmień lub zweryfikuj następujące ustawienia:
Ustawienie Wartość Nazwa aplikacji funkcji contosoorder Stos środowiska uruchomieniowego .NET Publikowanie Kod System operacyjny Windows Typ planu Zużycie (bezserwerowe) Wybierz opcję Przejrzyj i utwórz, a następnie wybierz pozycję Utwórz.
Po zakończeniu wdrażania wybierz pozycję Przejdź do zasobu , aby otworzyć stronę przeglądu aplikacji funkcji.
W grupie Ustawienia wybierz pozycję Konfiguracja.
Na stronie Ustawienia aplikacji wybierz przycisk Nowe ustawienie aplikacji, aby dodać każde ustawienie.

Dodaj następujące ustawienia:
Nazwa ustawienia Wartość DBX_INSTANCE Region obszaru roboczego usługi Databricks. Na przykład: westus2.azuredatabricks.net.DBX_PAT Osobisty token dostępu wygenerowany wcześniej. DBX_JOB_ID Identyfikator uruchomionego zadania. Wybierz pozycję Zapisz , aby zatwierdzić te ustawienia.
W grupie Funkcje wybierz pozycję Funkcje, a następnie wybierz pozycję Utwórz.
Wybierz pozycję Wyzwalacz usługi Azure Event Grid.
Zainstaluj rozszerzenie Microsoft.Azure.WebJobs.Extensions.EventGrid, jeśli zostanie wyświetlony monit o to. Jeśli musisz go zainstalować, musisz ponownie wybrać wyzwalacz usługi Azure Event Grid, aby utworzyć funkcję.
Zostanie wyświetlone okienko Nowa funkcja .
W okienku Nowa funkcja nadaj funkcji nazwę UpsertOrder, a następnie wybierz przycisk Utwórz.
Zastąp zawartość pliku kodu tym kodem, a następnie wybierz przycisk Zapisz :
#r "Azure.Messaging.EventGrid" #r "System.Memory.Data" #r "Newtonsoft.Json" #r "System.Text.Json" using Azure.Messaging.EventGrid; using Azure.Messaging.EventGrid.SystemEvents; using Newtonsoft.Json; using Newtonsoft.Json.Linq; private static HttpClient httpClient = new HttpClient(); public static async Task Run(EventGridEvent eventGridEvent, ILogger log) { log.LogInformation("Event Subject: " + eventGridEvent.Subject); log.LogInformation("Event Topic: " + eventGridEvent.Topic); log.LogInformation("Event Type: " + eventGridEvent.EventType); log.LogInformation(eventGridEvent.Data.ToString()); if (eventGridEvent.EventType == "Microsoft.Storage.BlobCreated" || eventGridEvent.EventType == "Microsoft.Storage.FileRenamed") { StorageBlobCreatedEventData fileData = eventGridEvent.Data.ToObjectFromJson<StorageBlobCreatedEventData>(); if (fileData.Api == "FlushWithClose") { log.LogInformation("Triggering Databricks Job for file: " + fileData.Url); var fileUrl = new Uri(fileData.Url); var httpRequestMessage = new HttpRequestMessage { Method = HttpMethod.Post, RequestUri = new Uri(String.Format("https://{0}/api/2.0/jobs/run-now", System.Environment.GetEnvironmentVariable("DBX_INSTANCE", EnvironmentVariableTarget.Process))), Headers = { { System.Net.HttpRequestHeader.Authorization.ToString(), "Bearer " + System.Environment.GetEnvironmentVariable("DBX_PAT", EnvironmentVariableTarget.Process)}, { System.Net.HttpRequestHeader.ContentType.ToString(), "application/json" } }, Content = new StringContent(JsonConvert.SerializeObject(new { job_id = System.Environment.GetEnvironmentVariable("DBX_JOB_ID", EnvironmentVariableTarget.Process), notebook_params = new { source_file = String.Join("", fileUrl.Segments.Skip(2)) } })) }; var response = await httpClient.SendAsync(httpRequestMessage); response.EnsureSuccessStatusCode(); } } }
Ten kod analizuje informacje o zgłoszonym zdarzeniu magazynu, a następnie tworzy komunikat żądania z adresem URL pliku, który wyzwolił zdarzenie. W ramach komunikatu funkcja przekazuje wartość do utworzonego wcześniej widżetu source_file . Kod funkcji wysyła komunikat do zadania usługi Databricks i używa tokenu uzyskanego wcześniej jako uwierzytelnianie.
Tworzenie subskrypcji usługi Event Grid
W tej sekcji utworzysz subskrypcję usługi Event Grid, która wywołuje funkcję platformy Azure po przekazaniu plików na konto magazynu.
Wybierz pozycję Integracja, a następnie na stronie Integracja wybierz pozycję Wyzwalacz usługi Event Grid.
W okienku Edytowanie wyzwalacza nadaj zdarzeniu
eventGridEventnazwę , a następnie wybierz pozycję Utwórz subskrypcję zdarzeń.Uwaga
Nazwa
eventGridEventjest zgodna z parametrem o nazwie , który jest przekazywany do funkcji platformy Azure.Na karcie Podstawowe na stronie Tworzenie subskrypcji zdarzeń zmień lub sprawdź następujące ustawienia:
Ustawienie Wartość Nazwisko contoso-order-event-subscription Typ tematu Konto magazynu Zasób źródłowy contosoorders Nazwa tematu systemowego <create any name>Filtruj do typów zdarzeń Utworzony obiekt blob i usunięty obiekt blob Zaznacz przycisk Utwórz.
Testowanie subskrypcji usługi Event Grid
Utwórz plik o nazwie
customer-order.csv, wklej następujące informacje do tego pliku i zapisz go na komputerze lokalnym.InvoiceNo,StockCode,Description,Quantity,InvoiceDate,UnitPrice,CustomerID,Country 536371,99999,EverGlow Single,228,1/1/2018 9:01,33.85,20993,Sierra LeoneW Eksplorator usługi Storage przekaż ten plik do folderu wejściowego konta magazynu.
Przekazanie pliku powoduje zgłoszenie zdarzenia Microsoft.Storage.BlobCreated . Usługa Event Grid powiadamia wszystkich subskrybentów o tym zdarzeniu. W naszym przypadku funkcja platformy Azure jest jedynym subskrybentem. Funkcja platformy Azure analizuje parametry zdarzenia, aby określić, które zdarzenie wystąpiło. Następnie przekazuje adres URL pliku do zadania usługi Databricks. Zadanie usługi Databricks odczytuje plik i dodaje wiersz do tabeli delty usługi Databricks, która znajduje się twoje konto magazynu.
Aby sprawdzić, czy zadanie zakończyło się pomyślnie, wyświetl uruchomienia zadania. Zobaczysz stan ukończenia. Aby uzyskać więcej informacji na temat wyświetlania przebiegów dla zadania, zobacz Wyświetlanie przebiegów zadania
W nowej komórce skoroszytu uruchom to zapytanie w komórce, aby wyświetlić zaktualizowaną tabelę różnicową.
%sql select * from customer_dataZwrócona tabela zawiera najnowszy rekord.

Aby zaktualizować ten rekord, utwórz plik o nazwie
customer-order-update.csv, wklej następujące informacje do tego pliku i zapisz go na komputerze lokalnym.InvoiceNo,StockCode,Description,Quantity,InvoiceDate,UnitPrice,CustomerID,Country 536371,99999,EverGlow Single,22,1/1/2018 9:01,33.85,20993,Sierra LeoneTen plik CSV jest prawie identyczny z poprzednim, z wyjątkiem ilości zamówienia został zmieniony z
228na22.W Eksplorator usługi Storage przekaż ten plik do folderu wejściowego konta magazynu.
Uruchom ponownie zapytanie,
selectaby wyświetlić zaktualizowaną tabelę delty.%sql select * from customer_dataZwrócona tabela zawiera zaktualizowany rekord.

Czyszczenie zasobów
Gdy grupa zasobów i wszystkie pokrewne zasoby nie będą już potrzebne, usuń je. W tym celu zaznacz grupę zasobów konta magazynu i wybierz pozycję Usuń.