Niepowodzenie debugowania zadań platformy Spark za pomocą zestawu narzędzi Azure Toolkit for IntelliJ (wersja zapoznawcza)
Ten artykuł zawiera szczegółowe wskazówki dotyczące używania narzędzi HDInsight Tools w zestawie narzędzi Azure Toolkit for IntelliJ do uruchamiania aplikacji Debugowanie błędów platformy Spark.
Wymagania wstępne
Zestaw Oracle Java Development. W tym samouczku jest używany język Java w wersji 8.0.202.
IntelliJ IDEA. W tym artykule użyto środowiska IntelliJ IDEA Community 2019.1.3.
Azure Toolkit for IntelliJ. Zobacz Installing the Azure Toolkit for IntelliJ (Instalowanie zestawu Azure Toolkit for IntelliJ).
Połącz się z klastrem usługi HDInsight. Zobacz Nawiązywanie połączenia z klastrem usługi HDInsight.
Eksplorator usługi Microsoft Azure Storage. Zobacz Pobieranie Eksplorator usługi Microsoft Azure Storage.
Tworzenie projektu przy użyciu szablonu debugowania
Utwórz projekt spark2.3.2, aby kontynuować debugowanie błędów, wykonaj przykładowy plik debugowania zadania niepowodzenia w tym dokumencie.
Otwórz środowisko IntelliJ IDEA. Otwórz okno Nowy projekt.
a. Wybierz pozycję Azure Spark/HDInsight w okienku po lewej stronie.
b. Wybierz pozycję Projekt Spark z przykładowym debugowaniem zadań niepowodzenia (wersja zapoznawcza)(Scala) w oknie głównym.
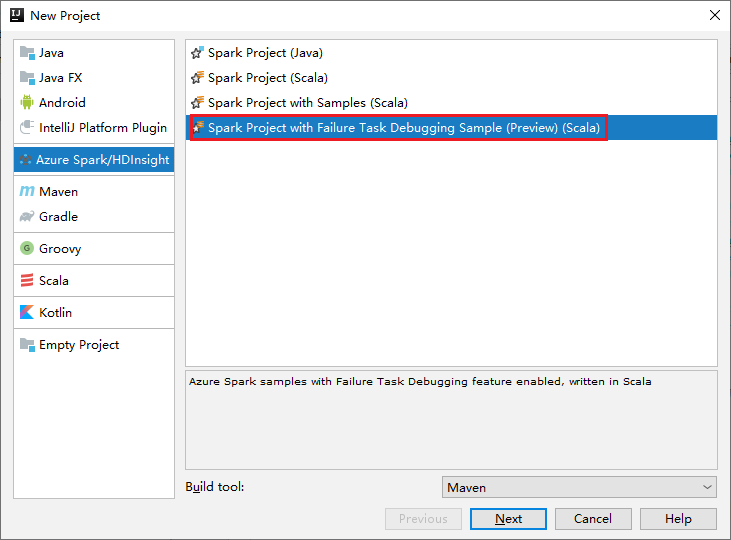
c. Wybierz Dalej.
W oknie Nowy projekt wykonaj następujące czynności:
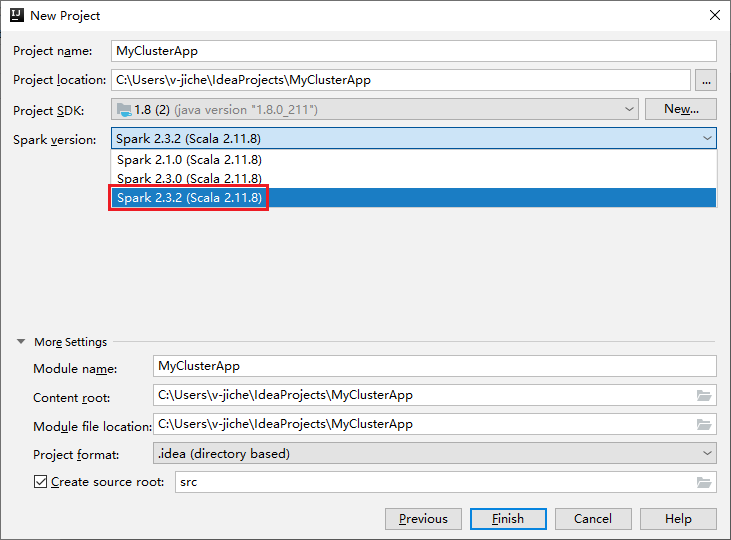
a. Wprowadź nazwę projektu i lokalizację projektu.
b. Z listy rozwijanej Zestaw SDK projektu wybierz pozycję Java 1.8 dla klastra Spark 2.3.2 .
c. Z listy rozwijanej Wersja platformy Spark wybierz pozycję Spark 2.3.2(Scala 2.11.8).
d. Wybierz Zakończ.
Wybierz pozycję src>main>scala, aby otworzyć kod w projekcie. W tym przykładzie użyto skryptu AgeMean_Div().
Uruchamianie aplikacji Spark Scala/Java w klastrze usługi HDInsight
Utwórz aplikację Spark Scala/Java, a następnie uruchom aplikację w klastrze Spark, wykonując następujące czynności:
Kliknij pozycję Dodaj konfigurację , aby otworzyć okno Uruchom/Debugowanie konfiguracji.

W oknie dialogowym Konfiguracje uruchamiania/debugowania wybierz znak plus (+). Następnie wybierz opcję Apache Spark w usłudze HDInsight .
Przejdź do zdalnego uruchamiania na karcie Klaster . Wprowadź informacje o nazwach, klastrze Spark i nazwie klasy Main. Nasze narzędzia obsługują debugowanie za pomocą funkcji wykonawczej. Wartość domyślna numExecutors to 5 i lepiej nie ustawić wartości wyższej niż 3. Aby skrócić czas wykonywania, możesz dodać element spark.yarn.maxAppAttempts do konfiguracji zadania i ustawić wartość na 1. Kliknij przycisk OK , aby zapisać konfigurację.
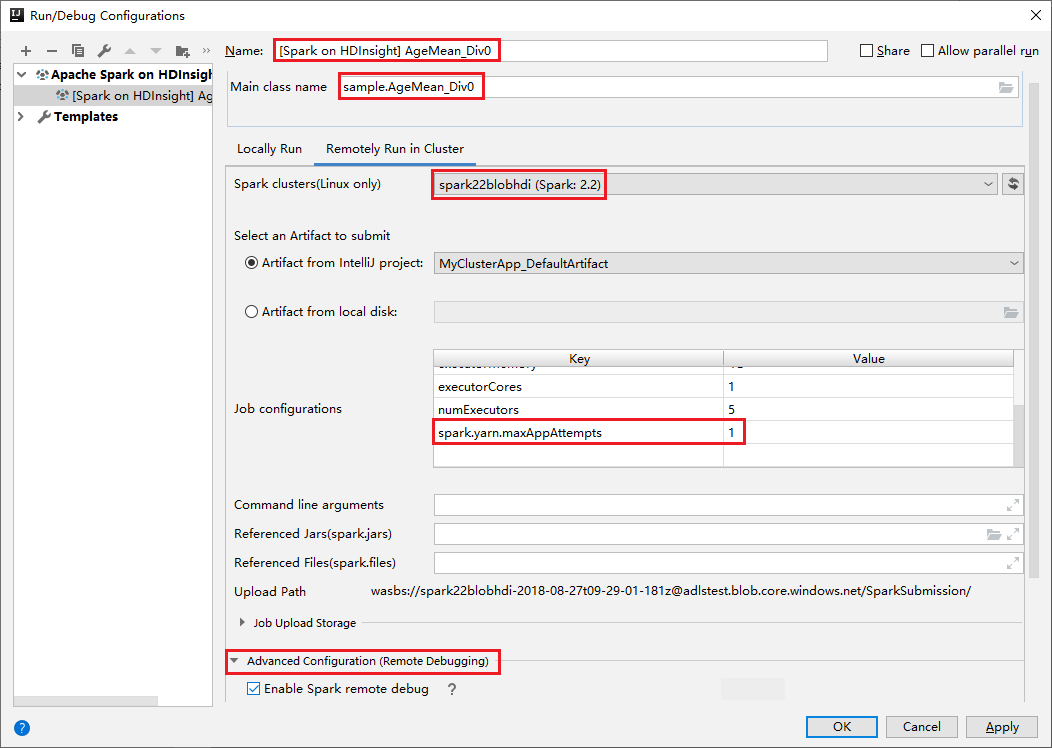
Konfiguracja jest teraz zapisywana przy użyciu podanej nazwy. Aby wyświetlić szczegóły konfiguracji, wybierz nazwę konfiguracji. Aby wprowadzić zmiany, wybierz pozycję Edytuj konfiguracje.
Po zakończeniu ustawień konfiguracji można uruchomić projekt względem klastra zdalnego.

Identyfikator aplikacji można sprawdzić w oknie danych wyjściowych.

Pobieranie profilu zadania nie powiodło się
Jeśli przesyłanie zadania nie powiedzie się, możesz pobrać profil zadania, który zakończył się niepowodzeniem, na maszynę lokalną w celu dalszego debugowania.
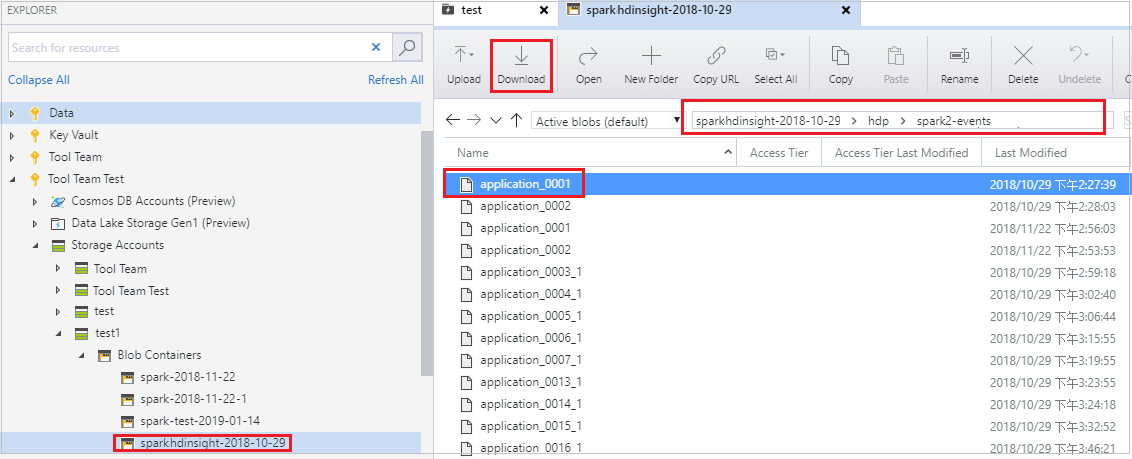
Otwórz Eksplorator usługi Microsoft Azure Storage, znajdź konto usługi HDInsight klastra dla zadania, które zakończyło się niepowodzeniem, pobierz zasoby zadania, które zakończyły się niepowodzeniem, z odpowiedniej lokalizacji: \hdp\spark2-events\.spark-failures\<identyfikator> aplikacji do folderu lokalnego. W oknie działań zostanie wyświetlony postęp pobierania.
Konfigurowanie lokalnego środowiska debugowania i debugowanie po niepowodzeniu
Otwórz oryginalny projekt lub utwórz nowy projekt i skojarz go z oryginalnym kodem źródłowym. Obecnie debugowanie błędów jest obsługiwane tylko w wersji spark2.3.2.
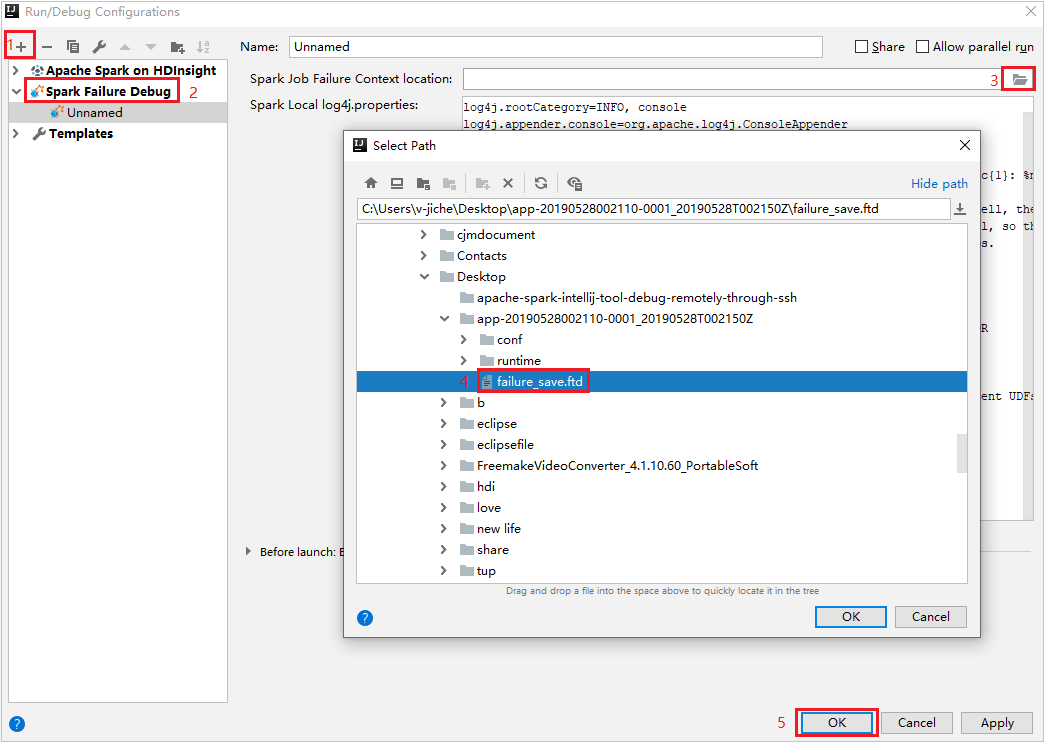
W środowisku IntelliJ IDEA utwórz plik konfiguracji debugowania niepowodzenia platformy Spark, wybierz plik FTD z wcześniej pobranych zasobów zadania, które zakończyły się niepowodzeniem dla pola Lokalizacja kontekstu niepowodzenia zadania platformy Spark.
Kliknij przycisk uruchamiania lokalnego na pasku narzędzi. Błąd zostanie wyświetlony w oknie Uruchom.
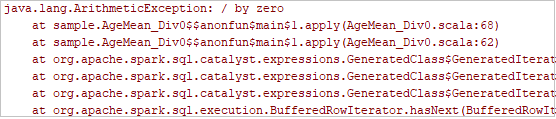
Ustaw punkt przerwania, jak wskazuje dziennik, a następnie kliknij przycisk lokalnego debugowania, aby wykonać debugowanie lokalne tak jak normalne projekty Scala / Java w środowisku IntelliJ.
Po debugowaniu, jeśli projekt zakończy się pomyślnie, można ponownie przesłać zadanie zakończone niepowodzeniem do platformy Spark w klastrze usługi HDInsight.
Następne kroki
Scenariusze
- Platforma Apache Spark z usługą BI: wykonywanie interaktywnej analizy danych przy użyciu platformy Spark w usłudze HDInsight z narzędziami analizy biznesowej
- Platforma Apache Spark z usługą Machine Learning: używanie platformy Spark w usłudze HDInsight do analizowania temperatury budynku przy użyciu danych HVAC
- Platforma Apache Spark z usługą Machine Learning: przewidywanie wyników inspekcji żywności przy użyciu platformy Spark w usłudze HDInsight
- Analiza dzienników witryn internetowych przy użyciu platformy Apache Spark w usłudze HDInsight
Tworzenie i uruchamianie aplikacji
- Tworzenie autonomicznych aplikacji przy użyciu języka Scala
- Zdalne uruchamianie zadań w klastrze Apache Spark przy użyciu programu Apache Livy
Narzędzia i rozszerzenia
- Tworzenie aplikacji Platformy Apache Spark dla klastra usługi HDInsight przy użyciu zestawu narzędzi Azure Toolkit for IntelliJ
- Zdalne debugowanie aplikacji Platformy Apache Spark za pośrednictwem sieci VPN przy użyciu zestawu narzędzi Azure Toolkit for IntelliJ
- Tworzenie aplikacji platformy Apache Spark za pomocą narzędzi HDInsight Tools w zestawie narzędzi Azure Toolkit for Eclipse
- Używanie notesów Apache Zeppelin z klastrem Apache Spark w usłudze HDInsight
- Jądra dostępne dla notesu Jupyter w klastrze Apache Spark dla usługi HDInsight
- Używanie pakietów zewnętrznych z notesami Jupyter Notebook
- Instalacja oprogramowania Jupyter na komputerze i nawiązywanie połączenia z klastrem Spark w usłudze HDInsight