Konfigurowanie ustawień platformy Apache Spark
Klaster SPARK usługi HDInsight obejmuje instalację biblioteki platformy Apache Spark. Każdy klaster usługi HDInsight zawiera domyślne parametry konfiguracji dla wszystkich zainstalowanych usług, w tym spark. Kluczowym aspektem zarządzania klastrem apache Hadoop w usłudze HDInsight jest monitorowanie obciążenia, w tym zadań platformy Spark. Aby najlepiej uruchomić zadania platformy Spark, należy wziąć pod uwagę konfigurację klastra fizycznego podczas określania konfiguracji logicznej klastra.
Domyślny klaster apache Spark usługi HDInsight obejmuje następujące węzły: trzy węzły usługi Apache ZooKeeper, dwa węzły główne i jeden lub więcej węzłów roboczych:
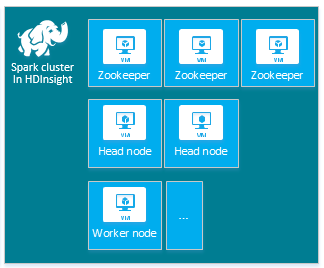
Liczba maszyn wirtualnych i rozmiarów maszyn wirtualnych dla węzłów w klastrze usługi HDInsight może mieć wpływ na konfigurację platformy Spark. Wartości konfiguracji usługi HDInsight inne niż domyślne często wymagają wartości konfiguracji platformy Spark innych niż domyślne. Podczas tworzenia klastra SPARK usługi HDInsight są wyświetlane sugerowane rozmiary maszyn wirtualnych dla każdego ze składników. Obecnie rozmiary maszyn wirtualnych z systemem Linux zoptymalizowane pod kątem pamięci dla platformy Azure to D12 w wersji 2 lub nowszej.
Wersje platformy Apache Spark
Użyj najlepszej wersji platformy Spark dla klastra. Usługa HDInsight obejmuje kilka wersji platformy Spark i samej usługi HDInsight. Każda wersja platformy Spark zawiera zestaw domyślnych ustawień klastra.
Podczas tworzenia nowego klastra istnieje wiele wersji platformy Spark do wyboru. Aby wyświetlić pełną listę, składniki i wersje usługi HDInsight.
Uwaga
Domyślna wersja platformy Apache Spark w usłudze HDInsight może ulec zmianie bez powiadomienia. Jeśli masz zależność wersji, firma Microsoft zaleca określenie tej konkretnej wersji podczas tworzenia klastrów przy użyciu zestawu .NET SDK, programu Azure PowerShell i klasycznego interfejsu wiersza polecenia platformy Azure.
Platforma Apache Spark ma trzy lokalizacje konfiguracji systemu:
- Właściwości platformy Spark kontrolują większość parametrów aplikacji i mogą być ustawiane przy użyciu
SparkConfobiektu lub właściwości systemu Java. - Zmienne środowiskowe mogą służyć do ustawiania ustawień poszczególnych maszyn, takich jak adres IP, za pomocą skryptu
conf/spark-env.shw każdym węźle. - Rejestrowanie można skonfigurować za pomocą usługi
log4j.properties.
Po wybraniu konkretnej wersji platformy Spark klaster zawiera domyślne ustawienia konfiguracji. Domyślne wartości konfiguracji platformy Spark można zmienić przy użyciu niestandardowego pliku konfiguracji platformy Spark. Przykład przedstawiono poniżej.
spark.hadoop.io.compression.codecs org.apache.hadoop.io.compress.GzipCodec
spark.hadoop.mapreduce.input.fileinputformat.split.minsize 1099511627776
spark.hadoop.parquet.block.size 1099511627776
spark.sql.files.maxPartitionBytes 1099511627776
spark.sql.files.openCostInBytes 1099511627776
Powyższy przykład zastępuje kilka wartości domyślnych pięciu parametrów konfiguracji platformy Spark. Te wartości to koder kompresji, apache Hadoop MapReduce podzielone minimalne rozmiary i rozmiary bloków parquet. Ponadto partycja Spark SQL i otwarte rozmiary plików są wartościami domyślnymi. Te zmiany konfiguracji są wybierane, ponieważ skojarzone dane i zadania (w tym przykładzie dane genomiczne) mają określone cechy. Te cechy będą lepiej korzystać z tych niestandardowych ustawień konfiguracji.
Wyświetlanie ustawień konfiguracji klastra
Przed rozpoczęciem optymalizacji wydajności klastra w klastrze sprawdź bieżące ustawienia konfiguracji klastra usługi HDInsight. Uruchom pulpit nawigacyjny usługi HDInsight w witrynie Azure Portal, klikając link Pulpit nawigacyjny w okienku klastra Spark. Zaloguj się przy użyciu nazwy użytkownika i hasła administratora klastra.
Zostanie wyświetlony internetowy interfejs użytkownika systemu Apache Ambari z pulpitem nawigacyjnym kluczowych metryk użycia zasobów klastra. Na pulpicie nawigacyjnym systemu Ambari jest wyświetlana konfiguracja platformy Apache Spark i inne zainstalowane usługi. Pulpit nawigacyjny zawiera kartę Historia konfiguracji, na której są wyświetlane informacje dotyczące zainstalowanych usług, w tym Spark.
Aby wyświetlić wartości konfiguracji platformy Apache Spark, wybierz pozycję Historia konfiguracji, a następnie wybierz pozycję Spark2. Wybierz kartę Configs (Konfiguracje ), a następnie wybierz Spark link (lub Spark2, w zależności od używanej wersji) na liście usług. Zostanie wyświetlona lista wartości konfiguracji klastra:
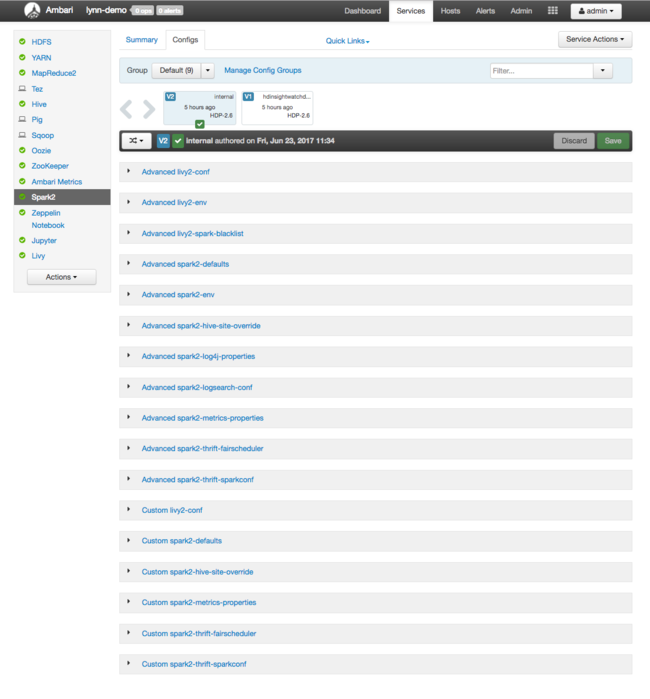
Aby wyświetlić i zmienić poszczególne wartości konfiguracji platformy Spark, wybierz dowolny link z napisem "spark" w tytule. Konfiguracje platformy Spark obejmują zarówno niestandardowe, jak i zaawansowane wartości konfiguracji w następujących kategoriach:
- Niestandardowe wartości domyślne platformy Spark2
- Niestandardowe właściwości metryki platformy Spark2
- Zaawansowane ustawienia domyślne platformy Spark2
- Zaawansowane środowisko Spark2-env
- Zaawansowane przesłonięcia spark2-hive-site-override
Jeśli tworzysz inny niż domyślny zestaw wartości konfiguracji, historia aktualizacji będzie widoczna. Ta historia konfiguracji może być przydatna, aby sprawdzić, która konfiguracja innej niż domyślna ma optymalną wydajność.
Uwaga
Aby zobaczyć, ale nie zmienić, typowe ustawienia konfiguracji klastra Spark, wybierz kartę Środowisko na interfejsie interfejsu użytkownika zadania platformy Spark najwyższego poziomu.
Konfigurowanie funkcji wykonawczych platformy Spark
Na poniższym diagramie przedstawiono kluczowe obiekty platformy Spark: program sterownika i skojarzony z nim kontekst platformy Spark oraz menedżer klastra i jego n węzłów roboczych. Każdy węzeł procesu roboczego obejmuje funkcję wykonawcza, pamięć podręczną i n wystąpień zadań.
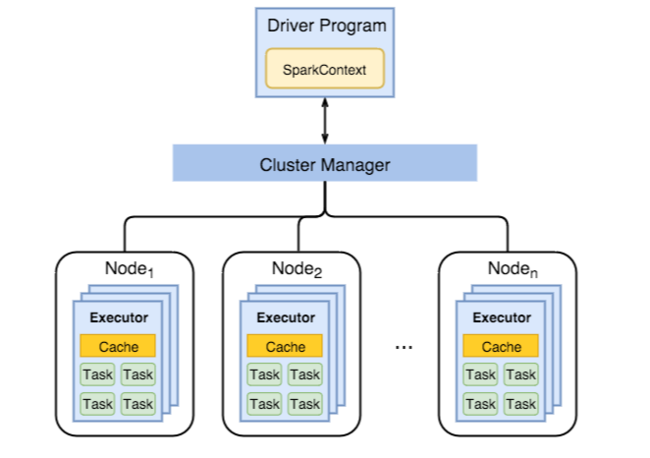
Zadania platformy Spark używają zasobów procesów roboczych, szczególnie pamięci, dlatego często dostosowuje się wartości konfiguracji platformy Spark dla funkcji wykonawczych węzła roboczego.
Trzy kluczowe parametry, które są często dostosowywane w celu dostosowania konfiguracji platformy Spark w celu poprawy wymagań aplikacji, to spark.executor.instances, spark.executor.coresi spark.executor.memory. Funkcja wykonawcza to proces uruchamiany dla aplikacji Spark. Funkcja wykonawcza jest uruchamiana w węźle roboczym i odpowiada za zadania aplikacji. Liczba węzłów procesu roboczego i rozmiar węzła procesu roboczego określa liczbę funkcji wykonawczych i rozmiarów funkcji wykonawczych. Te wartości są przechowywane w spark-defaults.conf węzłach głównych klastra. Te wartości można edytować w uruchomionym klastrze, wybierając pozycję Niestandardowe wartości domyślne platformy Spark w internetowym interfejsie użytkownika systemu Ambari. Po wprowadzeniu zmian zostanie wyświetlony monit interfejsu użytkownika o ponowne uruchomienie wszystkich usług, których dotyczy problem.
Uwaga
Te trzy parametry konfiguracji można skonfigurować na poziomie klastra (dla wszystkich aplikacji uruchamianych w klastrze), a także określonych dla każdej aplikacji.
Innym źródłem informacji o zasobach używanych przez funkcje wykonawcze platformy Spark jest interfejs użytkownika aplikacji platformy Spark. W interfejsie użytkownika funkcje wykonawcze wyświetlają widoki Podsumowanie i Szczegóły konfiguracji i wykorzystanych zasobów. Określ, czy zmienić wartości funkcji wykonawczej dla całego klastra, czy określony zestaw wykonań zadań.
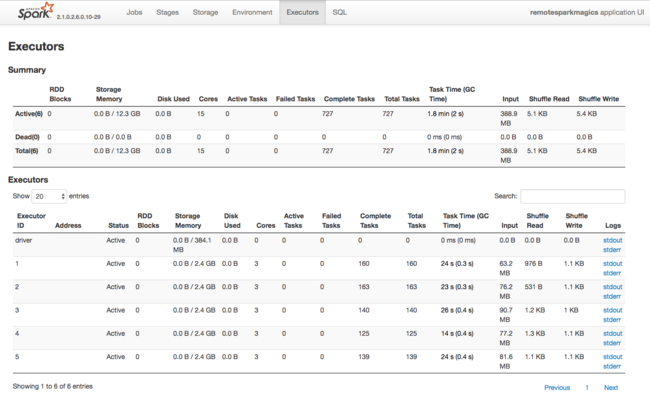
Możesz też użyć interfejsu API REST systemu Ambari do programowego weryfikowania ustawień konfiguracji klastra HDInsight i Spark. Więcej informacji można znaleźć w dokumentacji interfejsu API systemu Apache Ambari w witrynie GitHub.
W zależności od obciążenia platformy Spark może się okazać, że bardziej zoptymalizowane wykonania zadań platformy Spark zapewnia niedomyślna konfiguracja platformy Spark. Przetestuj testy porównawcze z przykładowymi obciążeniami, aby zweryfikować wszystkie konfiguracje klastra inne niż domyślne. Poniżej wymieniono niektóre typowe parametry, których dostosowanie warto rozważyć:
| Parametr | Opis |
|---|---|
| --num-executors | Ustawia liczbę funkcji wykonawczych. |
| --executor-cores | Ustawia liczbę rdzeni dla każdego wykonawcy. Zalecamy używanie funkcji wykonawczych średniej wielkości, ponieważ inne procesy również zużywają część dostępnej pamięci. |
| --executor-memory | Steruje rozmiarem pamięci (rozmiarem sterty) poszczególnych funkcji wykonawczych w usłudze Apache Hadoop YARN i należy pozostawić trochę pamięci na potrzeby obciążenia związanego z wykonywaniem. |
Oto przykład dwóch węzłów procesu roboczego z różnymi wartościami konfiguracji:

Na poniższej liście przedstawiono kluczowe parametry pamięci funkcji wykonawczej platformy Spark.
| Parametr | Opis |
|---|---|
| spark.executor.memory | Definiuje łączną ilość pamięci dostępnej dla funkcji wykonawczej. |
| spark.storage.memoryFraction | (ustawienie domyślne ~60%) definiuje ilość pamięci dostępnej do przechowywania utrwalone RDD. |
| spark.shuffle.memoryFraction | (wartość domyślna ~20%) definiuje ilość pamięci zarezerwowanej na potrzeby mieszania. |
| spark.storage.unrollFraction i spark.storage.safetyFraction | (łącznie około 30% całkowitej pamięci) — te wartości są używane wewnętrznie przez platformę Spark i nie powinny być zmieniane. |
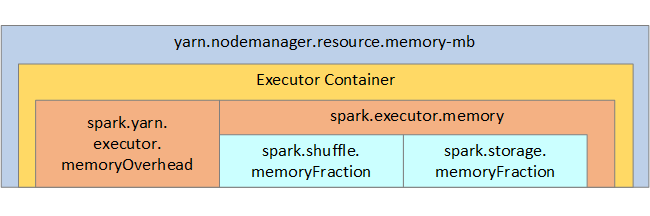
Usługa YARN kontroluje maksymalną sumę pamięci używanej przez kontenery w każdym węźle platformy Spark. Na poniższym diagramie przedstawiono relacje poszczególnych węzłów między obiektami konfiguracji usługi YARN i obiektami platformy Spark.
Zmienianie parametrów aplikacji uruchomionej w notesie Jupyter Notebook
Klastry Spark w usłudze HDInsight domyślnie zawierają wiele składników. Każdy z tych składników zawiera domyślne wartości konfiguracji, które można zastąpić zgodnie z potrzebami.
| Składnik | opis |
|---|---|
| Spark Core | Spark Core, Spark SQL, Interfejsy API przesyłania strumieniowego spark, GraphX i Apache Spark MLlib. |
| Anaconda | Menedżer pakietów języka Python. |
| Apache Livy | Interfejs API REST platformy Apache Spark używany do przesyłania zadań zdalnych do klastra Spark usługi HDInsight. |
| Notesy Jupyter i notesy Apache Zeppelin | Interaktywny interfejs użytkownika oparty na przeglądarce na potrzeby interakcji z klastrem Spark. |
| Sterownik ODBC | Łączy klastry Spark w usłudze HDInsight z narzędziami analizy biznesowej, takimi jak Microsoft Power BI i Tableau. |
W przypadku aplikacji uruchomionych w notesie Jupyter Notebook użyj %%configure polecenia , aby wprowadzić zmiany konfiguracji z poziomu samego notesu. Te zmiany konfiguracji zostaną zastosowane do zadań platformy Spark uruchamianych z wystąpienia notesu. Przed uruchomieniem pierwszej komórki kodu wprowadź takie zmiany na początku aplikacji. Zmieniona konfiguracja jest stosowana do sesji usługi Livy po jej utworzeniu.
Uwaga
Aby zmienić konfigurację na późniejszym etapie w aplikacji, użyj parametru -f (force). Jednak wszystkie postępy w aplikacji zostaną utracone.
Poniższy kod pokazuje, jak zmienić konfigurację aplikacji uruchomionej w notesie Jupyter Notebook.
%%configure
{"executorMemory": "3072M", "executorCores": 4, "numExecutors":10}
Podsumowanie
Monitoruj podstawowe ustawienia konfiguracji, aby upewnić się, że zadania platformy Spark są uruchamiane w przewidywalny i wydajny sposób. Te ustawienia pomagają określić najlepszą konfigurację klastra Spark dla konkretnych obciążeń. Należy również monitorować wykonywanie długotrwałych i zużywających zasoby wykonań zadań platformy Spark. Najczęstsze wyzwania związane z obciążeniem pamięci wynikają z nieprawidłowych konfiguracji, takich jak niepoprawne funkcje wykonawcze. Ponadto długotrwałe operacje i zadania, które powodują operacje kartezjańskie.