styczeń 2019
Te funkcje i ulepszenia platformy Azure Databricks zostały wydane w styczniu 2019 r.
Uwaga
Wydania są etapowe. Twoje konto usługi Azure Databricks może nie zostać zaktualizowane do tygodnia po początkowej dacie wydania.
Zbliżająca się zmiana: język Python 3 staje się domyślnym ustawieniem podczas tworzenia klastrów
29 stycznia 2019 r.
W przypadku wydania platformy Databricks w wersji 2.91 w połowie lutego domyślna wersja języka Python dla nowych klastrów zmieni się z języka Python 2 na Python 3. Istniejące klastry nie zmienią oczywiście swoich wersji języka Python. Jeśli jednak używasz domyślnego ustawienia języka Python 2 podczas tworzenia nowych klastrów, musisz zacząć zwracać uwagę na wybór wersji języka Python.
Databricks Runtime 5.2 na potrzeby uczenia maszynowego (wersja beta)
24 stycznia 2019 r.
Środowisko Databricks Runtime 5.2 ML jest oparte na środowisku Databricks Runtime 5.2 (EoS). Zawiera wiele popularnych bibliotek uczenia maszynowego, w tym TensorFlow, PyTorch, Keras i XGBoost oraz zapewnia rozproszone trenowanie Biblioteki TensorFlow przy użyciu struktury Horovod. Oprócz aktualizacji biblioteki od czasu uczenia maszynowego Databricks Runtime ML 5.1 usługa Databricks Runtime 5.2 ML obejmuje następujące nowe funkcje:
- Elementy GraphFrames obsługują teraz interfejs API pregel (Python) z optymalizacjami wydajności usługi Databricks.
-
HorovodRunner dodaje:
- W klastrze gpu procesy trenowania są mapowane na procesory GPU zamiast węzłów roboczych, aby uprościć obsługę typów wystąpień z wieloma procesorami GPU. Ta wbudowana obsługa umożliwia dystrybucję do wszystkich procesorów GPU na maszynie z wieloma procesorami GPU bez kodu niestandardowego.
-
HorovodRunner.run()teraz zwraca wartość zwracaną z pierwszego procesu trenowania.
Zobacz pełne informacje o wersji dla środowiska Databricks Runtime 5.2 ML. d
Databricks Runtime 5.2
24 stycznia 2019 r.
Środowisko Databricks Runtime 5.2 jest teraz dostępne. Środowisko Databricks Runtime 5.2 obejmuje platformę Apache Spark 2.4.0, nowe funkcje usługi Delta Lake i strukturalnych przesyłania strumieniowego oraz uaktualnienia oraz uaktualnione biblioteki Python, R, Java i Scala. Aby uzyskać szczegółowe informacje, zobacz Databricks Runtime 5.2 (EoS).
Widok JSON konfiguracji klastra
15-22 stycznia 2019 r.
Strona konfiguracji klastra obsługuje teraz widok JSON:
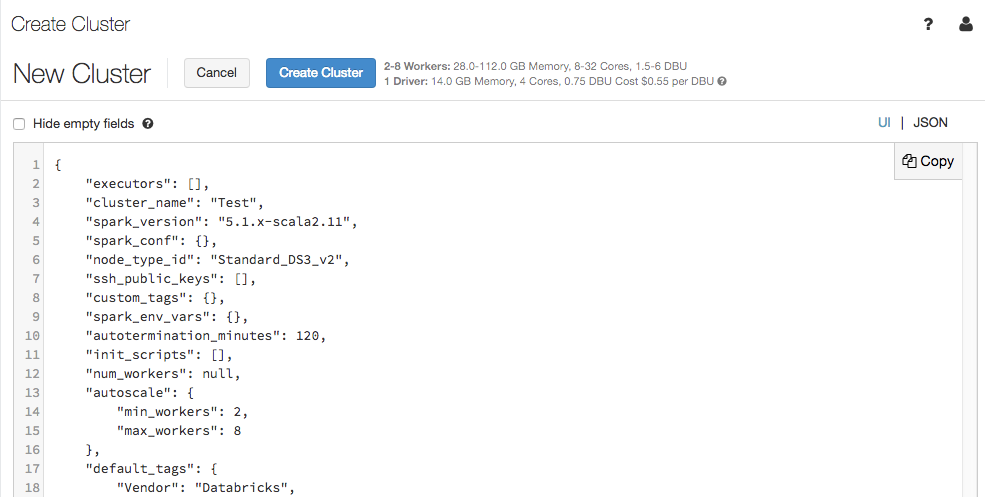
Widok JSON jest tylko do odczytu. Można jednak skopiować kod JSON i użyć go do tworzenia i aktualizowania klastrów przy użyciu interfejsu API klastrów .
Interfejs użytkownika klastra
15-22 stycznia 2019 r.: Wersja 2.89
Strona tworzenia klastra została wyczyszczona i zreorganizowana w celu ułatwienia użycia, w tym nowego przełącznika Opcje zaawansowane.
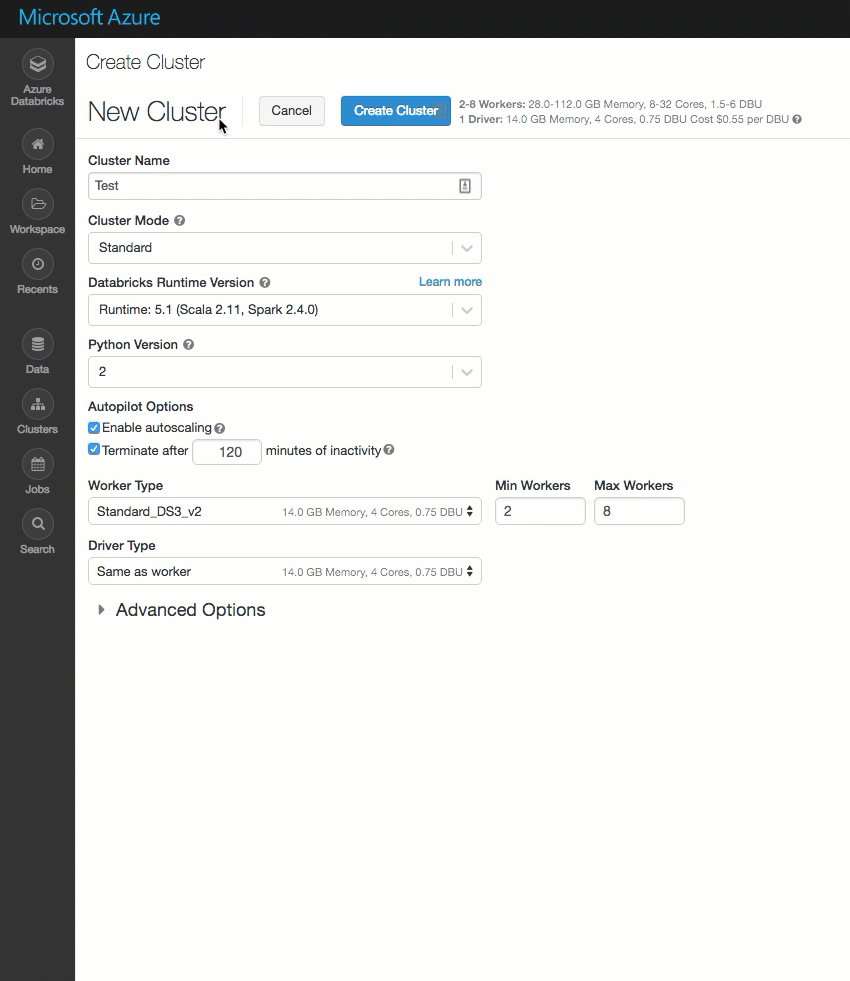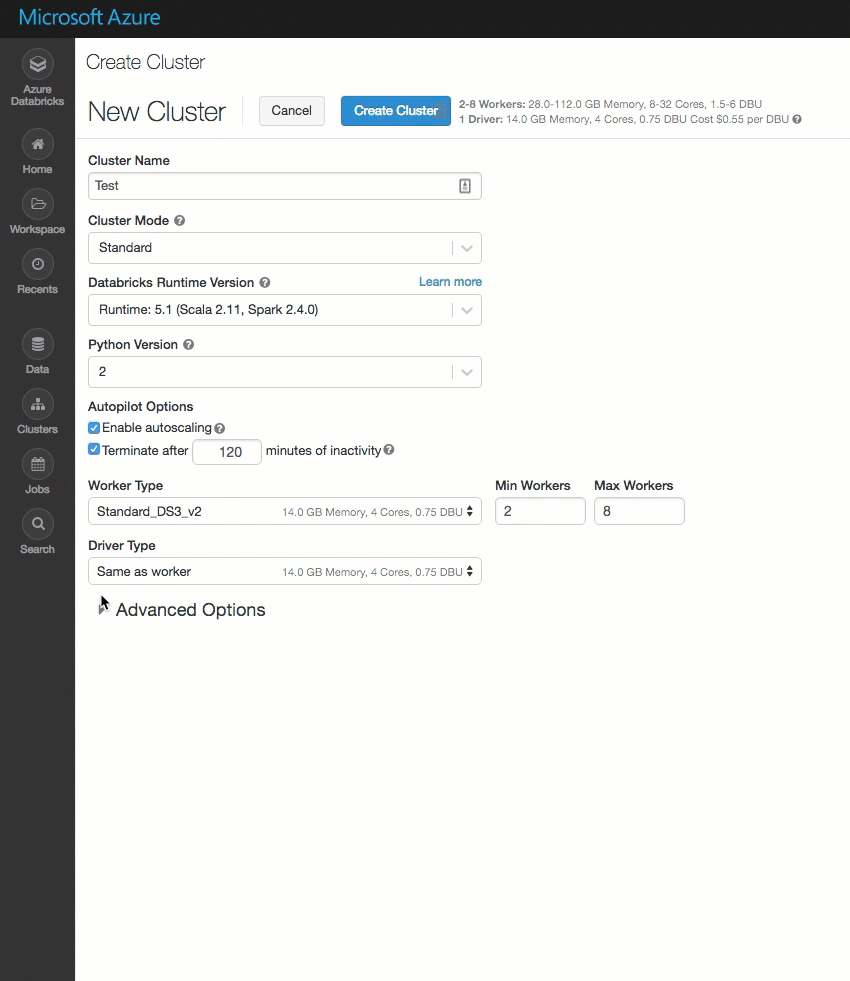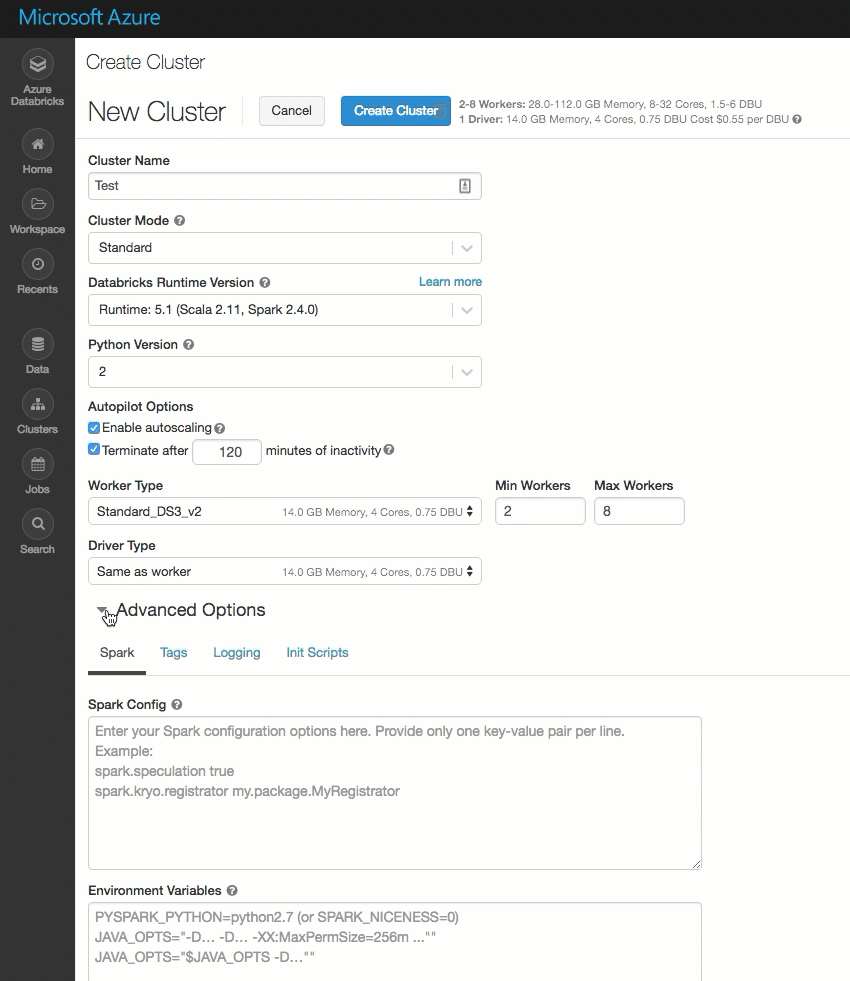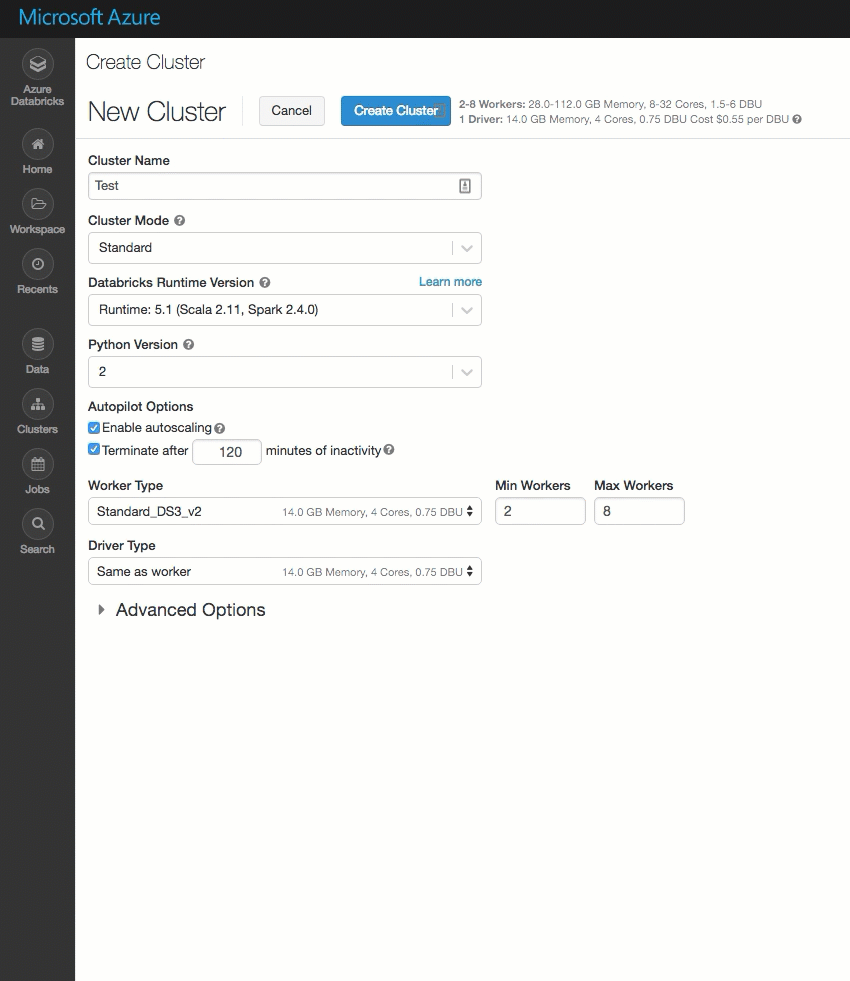
Wdrażanie usługi Azure Databricks we własnej sieci wirtualnej na platformie Azure (iniekcja sieci wirtualnej)
10 stycznia 2019 r.
Ważne
Ta funkcja jest dostępna w publicznej wersji zapoznawczej.
Domyślne wdrożenie usługi Azure Databricks to w pełni zarządzana usługa na platformie Azure: wszystkie zasoby płaszczyzny obliczeniowej, w tym sieć wirtualna , z którą będą skojarzone wszystkie klastry, są wdrażane w zablokowanej grupie zasobów. Jeśli jednak potrzebujesz dostosowania sieci, możesz teraz wdrożyć usługę Azure Databricks we własnej sieci wirtualnej (czasami nazywane iniekcją sieci wirtualnej), co umożliwia:
- Połącz usługę Azure Databricks z innymi usługami platformy Azure (takimi jak Azure Storage) w bardziej bezpieczny sposób przy użyciu punktów końcowych usługi.
- Połącz się z lokalnymi źródłami danych do użycia z usługą Azure Databricks, korzystając z tras zdefiniowanych przez użytkownika.
- Połącz usługę Azure Databricks z urządzeniem wirtualnym sieci , aby sprawdzić cały ruch wychodzący i podjąć działania zgodnie z regułami zezwalania i odmowy.
- Skonfiguruj usługę Azure Databricks do używania niestandardowego systemu DNS.
- Skonfiguruj reguły sieciowej grupy zabezpieczeń w celu określenia ograniczeń ruchu wychodzącego.
- Wdróż klastry usługi Azure Databricks w istniejącej sieci wirtualnej.
Wdrażanie usługi Azure Databricks we własnej sieci wirtualnej umożliwia również korzystanie z elastycznych zakresów CIDR (w dowolnym miejscu między /16-/24 dla sieci wirtualnej a między /18-/26 dla podsieci).
Konfiguracja przy użyciu interfejsu użytkownika witryny Azure Portal jest szybka i łatwa: podczas tworzenia obszaru roboczego wystarczy wybrać Wdrożyć obszar roboczy usługi Azure Databricks w usłudze Virtual Network, wybrać sieć wirtualną i podać zakresy CIDR dla dwóch podsieci. Usługa Azure Databricks aktualizuje sieć wirtualną za pomocą dwóch nowych podsieci i sieciowych grup zabezpieczeń przy użyciu zakresów CIDR udostępnianych przez Użytkownika, umożliwia dostęp do ruchu przychodzącego i wychodzącego podsieci oraz wdraża obszar roboczy w zaktualizowanej sieci wirtualnej.
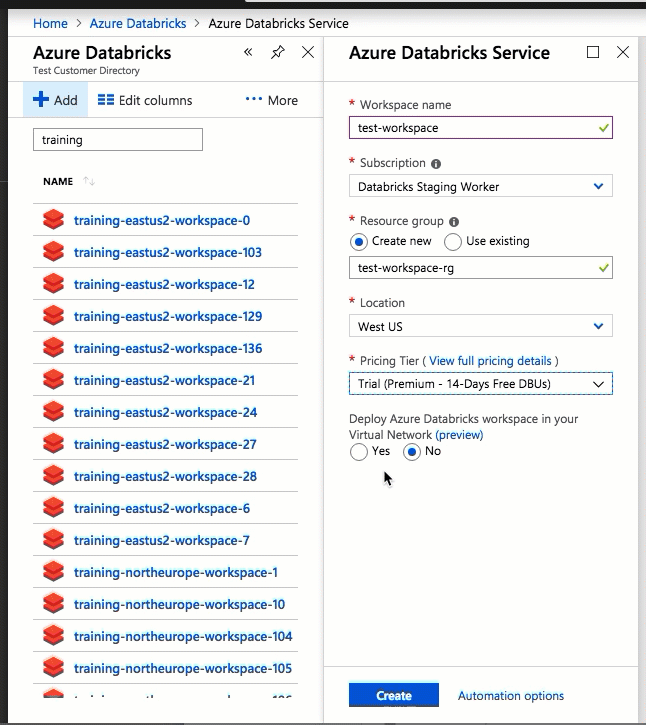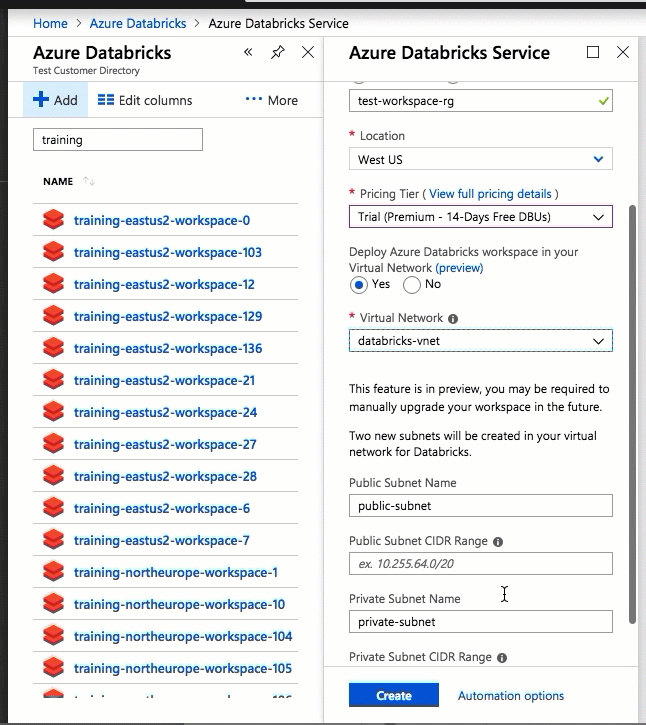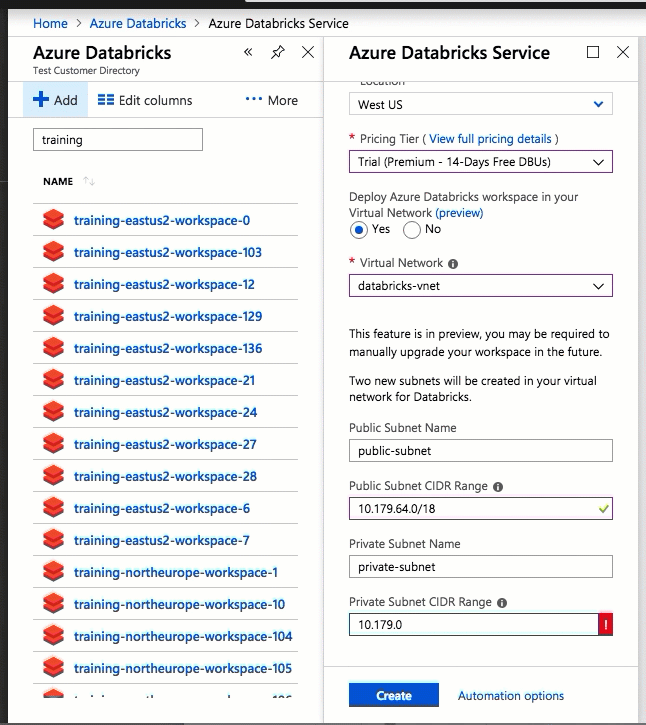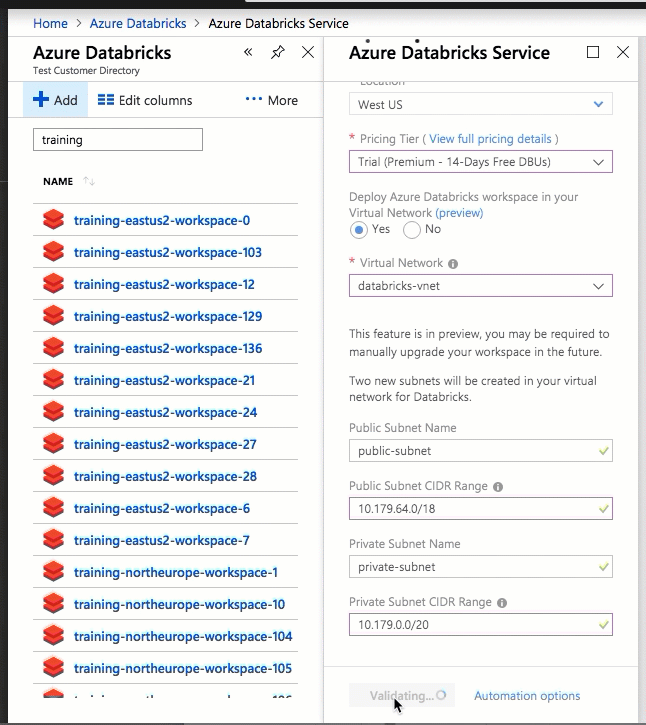
Jeśli wolisz skonfigurować sieć wirtualną na potrzeby samodzielnego wstrzykiwania sieci wirtualnej — na przykład chcesz użyć istniejących podsieci, użyć istniejących sieciowych grup zabezpieczeń lub utworzyć własne reguły zabezpieczeń — możesz użyć szablonów usługi ARM dostarczonych przez usługę Azure-Databricks zamiast interfejsu użytkownika portalu.
Uwaga
Ta funkcja była wcześniej dostępna tylko przez rejestrację. Pozostaje ona w wersji zapoznawczej , ale jest teraz w pełni samoobsługowa.
Aby uzyskać szczegółowe informacje, zobacz Deploy Azure Databricks in your Azure virtual network (VNet injection) (Wdrażanie usługi Azure Databricks w sieci wirtualnej) i Łączenie obszaru roboczego usługi Azure Databricks z siecią lokalną.
Interfejs użytkownika biblioteki
2–9 stycznia 2019 r.: Wersja 2.88
Ulepszenia interfejsu użytkownika biblioteki, które zostały pierwotnie wydane w listopadzie 2018 r. i przywrócone wkrótce potem zostały ponownie wydane. Te aktualizacje ułatwiają przekazywanie, instalowanie i zarządzanie bibliotekami klastrów usługi Azure Databricks oraz zarządzanie nimi.
Interfejs użytkownika usługi Azure Databricks obsługuje teraz biblioteki obszarów roboczych i biblioteki zainstalowane w klastrze. Biblioteka obszarów roboczych istnieje w obszarze roboczym i może być zainstalowana w co najmniej jednym klastrze. Biblioteka zainstalowana w klastrze to biblioteka, która istnieje tylko w kontekście klastra, na którym jest zainstalowany. Dodatkowo:
- Teraz możesz utworzyć bibliotekę na podstawie pliku przekazanego do magazynu obiektów.
- Biblioteki można teraz instalować i odinstalować na stronie szczegółów biblioteki oraz na karcie Biblioteki klastra.
- Biblioteki zainstalowane przy użyciu interfejsu API są teraz wyświetlane na karcie Biblioteki klastra.
Aby uzyskać szczegółowe informacje, zobacz Biblioteki.
Zdarzenia klastra
2–9 stycznia 2019 r.: Wersja 2.88
Dodano nowe zdarzenia klastra w celu odzwierciedlenia stanu sterownika platformy Spark. Aby uzyskać szczegółowe informacje, zobacz Interfejs API klastrów.
Kontrola wersji notesu przy użyciu usługi Azure DevOps Services
2–9 stycznia 2019 r.: Wersja 2.88
Usługa Azure Databricks ułatwia teraz używanie usług Azure DevOps Services (dawniej VSTS) do kontrolowania wersji notesów. Uwierzytelnianie jest automatyczne, konfiguracja jest prosta i zarządzasz poprawkami notesu tak samo jak w przypadku integracji z usługą GitHub.
Aby uzyskać szczegółowe informacje, zobacz Kontrola wersji usługi Git dla notesów (starsza wersja).