HorovodRunner: rozproszone uczenie głębokie za pomocą struktury Horovod
Ważne
Horovod i HorovodRunner są teraz przestarzałe. Wersje po wersji 15.4 LTS ML nie będą miały wstępnie zainstalowanego pakietu. W przypadku rozproszonego uczenia głębokiego usługa Databricks zaleca używanie narzędzia TorchDistributor do trenowania rozproszonego za pomocą biblioteki PyTorch lub interfejsu tf.distribute.Strategy API na potrzeby trenowania rozproszonego za pomocą biblioteki TensorFlow.
Dowiedz się, jak wykonywać rozproszone szkolenie modeli uczenia maszynowego przy użyciu narzędzia HorovodRunner w celu uruchomienia zadań szkoleniowych Horovod jako zadań platformy Spark w usłudze Azure Databricks.
Co to jest HorovodRunner?
HorovodRunner to ogólny interfejs API do uruchamiania rozproszonych obciążeń uczenia głębokiego w usłudze Azure Databricks przy użyciu platformy Horovod . Dzięki integracji platformy Horovod z trybem barierowym platformy Spark usługa Azure Databricks może zapewnić większą stabilność dla długotrwałych zadań uczenia głębokiego na platformie Spark. HorovodRunner przyjmuje metodę języka Python, która zawiera kod trenowania uczenia głębokiego za pomocą haków Horovod. Narzędzie HorovodRunner wybiera metodę w sterowniku i dystrybuuje ją do procesów roboczych platformy Spark. Zadanie interfejsu MPI horovod jest osadzone jako zadanie platformy Spark przy użyciu trybu wykonywania bariery. Pierwszy wykonawca zbiera adresy IP wszystkich funkcji wykonawczych zadań przy użyciu polecenia BarrierTaskContext i wyzwala zadanie Horovod przy użyciu polecenia mpirun. Każdy proces MPI języka Python ładuje program użytkownika pickled, deserializuje go i uruchamia.
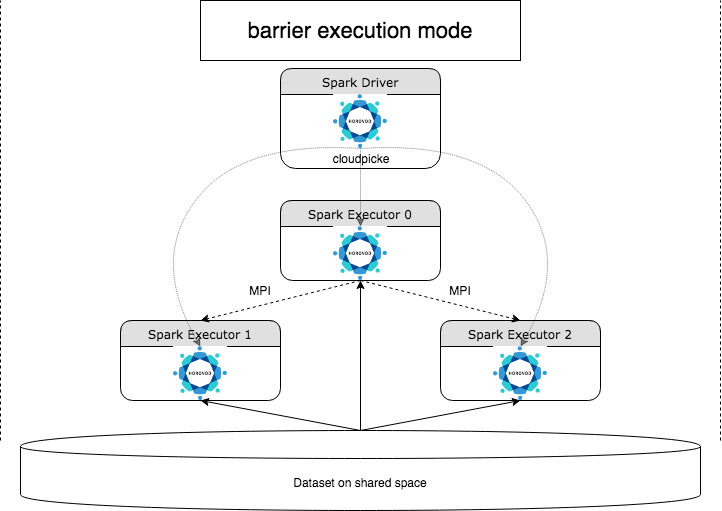
Trenowanie rozproszone za pomocą narzędzia HorovodRunner
Narzędzie HorovodRunner umożliwia uruchamianie zadań szkoleniowych Horovod jako zadań platformy Spark. Interfejs API HorovodRunner obsługuje metody pokazane w tabeli. Aby uzyskać szczegółowe informacje, zobacz dokumentację interfejsu API HorovodRunner.
| Metoda i podpis | opis |
|---|---|
init(self, np) |
Utwórz wystąpienie modułu HorovodRunner. |
run(self, main, **kwargs) |
Uruchom zadanie trenowania Horovod wywołujące main(**kwargs)polecenie . Funkcja główna i argumenty słowa kluczowego są serializowane przy użyciu biblioteki cloudpickle i dystrybuowane do procesów roboczych klastra. |
Ogólne podejście do opracowywania rozproszonego programu szkoleniowego przy użyciu narzędzia HorovodRunner jest następujące:
-
HorovodRunnerUtwórz wystąpienie zainicjowane przy użyciu liczby węzłów. - Zdefiniuj metodę trenowania Horovod zgodnie z metodami opisanymi w metodzie Horovod, dodając instrukcje importu wewnątrz metody .
- Przekaż metodę trenowania
HorovodRunnerdo wystąpienia.
Na przykład:
hr = HorovodRunner(np=2)
def train():
import tensorflow as tf
hvd.init()
hr.run(train)
Aby uruchomić narzędzie HorovodRunner na sterowniku tylko w n przypadku podprocesów, użyj polecenia hr = HorovodRunner(np=-n). Jeśli na przykład na węźle sterownika znajduje się 4 procesory GPU, możesz wybrać n maksymalnie 4. Aby uzyskać szczegółowe informacje o parametrze np, zobacz dokumentację interfejsu API HorovodRunner. Aby uzyskać szczegółowe informacje na temat sposobu przypinania jednego procesora GPU na podprocesy, zobacz Przewodnik po użyciu platformy Horovod.
Typowy błąd polega na tym, że nie można odnaleźć ani zebrać obiektów TensorFlow. Dzieje się tak, gdy instrukcje importowania biblioteki nie są dystrybuowane do innych funkcji wykonawczych. Aby uniknąć tego problemu, uwzględnij wszystkie instrukcje importu (na przykład import tensorflow as tf) zarówno w górnej części metody trenowania Horovod, jak i we wszystkich innych funkcjach zdefiniowanych przez użytkownika wywoływanych w metodzie trenowania Horovod.
Rejestrowanie trenowania horovod za pomocą osi czasu Horovod
Horovod ma możliwość rejestrowania osi czasu swojej aktywności o nazwie Horovod Timeline.
Ważne
Oś czasu horovod ma znaczący wpływ na wydajność. Przepływność Inception3 może zmniejszyć się o ok. 40%, gdy jest włączona oś czasu Horovod. Aby przyspieszyć zadania HorovodRunner, nie używaj osi czasu Horovod.
Nie można wyświetlić osi czasu Horovod, gdy szkolenie jest w toku.
Aby zarejestrować oś czasu Horovod, ustaw HOROVOD_TIMELINE zmienną środowiskową na lokalizację, w której chcesz zapisać plik osi czasu. Usługa Databricks zaleca użycie lokalizacji w magazynie udostępnionym, aby plik osi czasu można było łatwo pobrać. Na przykład można użyć interfejsów API plików lokalnych DBFS, jak pokazano poniżej:
timeline_dir = "/dbfs/ml/horovod-timeline/%s" % uuid.uuid4()
os.makedirs(timeline_dir)
os.environ['HOROVOD_TIMELINE'] = timeline_dir + "/horovod_timeline.json"
hr = HorovodRunner(np=4)
hr.run(run_training_horovod, params=params)
Następnie dodaj kod specyficzny dla osi czasu na początku i na końcu funkcji trenowania. Poniższy przykładowy notes zawiera przykładowy kod, którego można użyć jako obejścia, aby wyświetlić postęp trenowania.
Przykładowy notes osi czasu horovod
Aby pobrać plik osi czasu, użyj interfejsu wiersza polecenia usługi Databricks, a następnie użyj funkcji przeglądarki chrome://tracing Chrome, aby go wyświetlić. Na przykład:
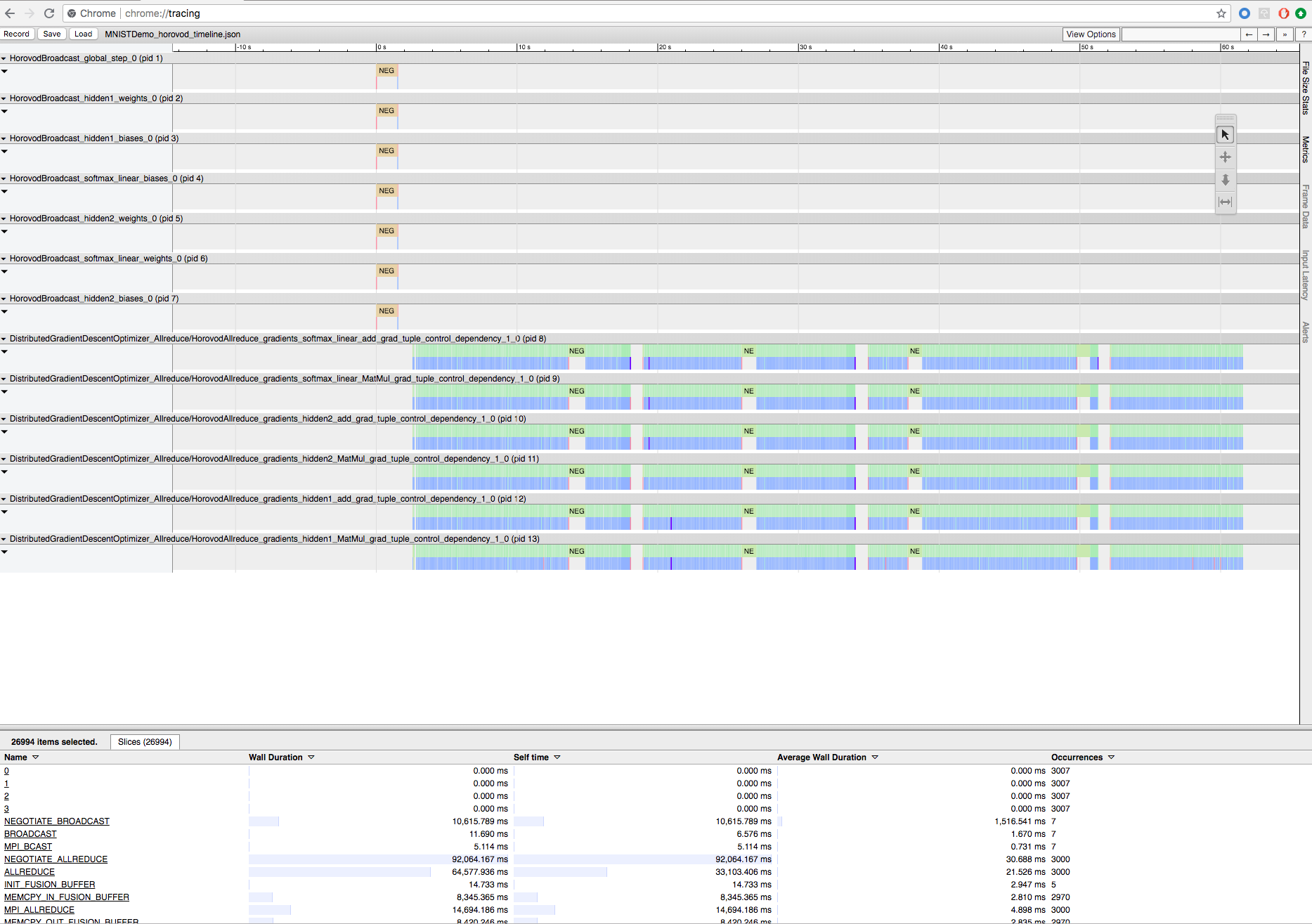
Przepływ pracy programowania
Poniżej przedstawiono ogólne kroki migracji kodu uczenia głębokiego z jednym węzłem do rozproszonego trenowania. Przykłady: Migrowanie do rozproszonego uczenia głębokiego za pomocą narzędzia HorovodRunner w tej sekcji ilustruje te kroki.
- Przygotuj kod pojedynczego węzła: przygotuj i przetestuj kod pojedynczego węzła za pomocą biblioteki TensorFlow, Keras lub PyTorch.
-
Migrowanie do struktury Horovod: postępuj zgodnie z instrukcjami z użycia struktury Horovod, aby przeprowadzić migrację kodu za pomocą struktury Horovod i przetestować go w sterowniku:
- Dodaj
hvd.init()polecenie , aby zainicjować horovod. - Przypnij procesor GPU serwera, który ma być używany przez ten proces przy użyciu polecenia
config.gpu_options.visible_device_list. W przypadku typowej konfiguracji jednego procesora GPU na proces można ustawić tę pozycję na rangę lokalną. W takim przypadku pierwszy proces na serwerze zostanie przydzielony pierwszy procesor GPU, drugi proces zostanie przydzielony drugiego procesora GPU i tak dalej. - Dołącz fragment zestawu danych. Ten operator zestawu danych jest bardzo przydatny podczas uruchamiania trenowania rozproszonego, ponieważ umożliwia każdemu procesowi roboczemu odczytywanie unikatowego podzestawu.
- Skaluj szybkość nauki według liczby procesów roboczych. Efektywny rozmiar partii w synchronicznym trenowaniu rozproszonym jest skalowany przez liczbę procesów roboczych. Zwiększenie szybkości nauki rekompensuje zwiększony rozmiar partii.
- Zawijaj optymalizator w programie
hvd.DistributedOptimizer. Rozproszony optymalizator deleguje obliczenia gradientowe do oryginalnego optymalizatora, średnie gradienty przy użyciu allreduce lub allgather, a następnie stosuje uśrednione gradienty. - Dodaj
hvd.BroadcastGlobalVariablesHook(0)do emisji początkowych stanów zmiennych z rangi 0 do wszystkich innych procesów. Jest to konieczne, aby zapewnić spójne inicjowanie wszystkich procesów roboczych podczas trenowania z losowymi wagami lub przywracane z punktu kontrolnego. Alternatywnie, jeśli nie używaszMonitoredTrainingSessionmetody , możesz wykonać operacjęhvd.broadcast_global_variablespo zainicjowaniu zmiennych globalnych. - Zmodyfikuj kod, aby zapisywać punkty kontrolne tylko w przypadku procesu roboczego 0, aby uniemożliwić innym pracownikom ich uszkodzenie.
- Dodaj
- Migrowanie do aplikacji HorovodRunner: Narzędzie HorovodRunner uruchamia zadanie szkoleniowe Horovod, wywołując funkcję języka Python. Należy opakowować główną procedurę trenowania w jedną funkcję języka Python. Następnie można przetestować narzędzie HorovodRunner w trybie lokalnym i trybie rozproszonym.
Aktualizowanie bibliotek uczenia głębokiego
W przypadku uaktualnienia lub obniżenia poziomu biblioteki TensorFlow, Keras lub PyTorch należy ponownie zainstalować bibliotekę Horovod, aby była kompilowana dla nowo zainstalowanej biblioteki. Jeśli na przykład chcesz uaktualnić bibliotekę TensorFlow, usługa Databricks zaleca użycie skryptu inicjowania z instrukcji instalacji biblioteki TensorFlow i dołączenie następującego kodu instalacyjnego Horovod specyficznego dla biblioteki TensorFlow na końcu. Zapoznaj się z instrukcjami instalacji horovod, aby pracować z różnymi kombinacjami, takimi jak uaktualnianie lub obniżanie wersji bibliotek PyTorch i innych bibliotek.
add-apt-repository -y ppa:ubuntu-toolchain-r/test
apt update
# Using the same compiler that TensorFlow was built to compile Horovod
apt install g++-7 -y
update-alternatives --install /usr/bin/gcc gcc /usr/bin/gcc-7 60
HOROVOD_GPU_ALLREDUCE=NCCL HOROVOD_CUDA_HOME=/usr/local/cuda pip install horovod==0.18.1 --force-reinstall --no-deps --no-cache-dir
Przykłady: Migrowanie do rozproszonego uczenia głębokiego za pomocą narzędzia HorovodRunner
W poniższych przykładach opartych na zestawie danych MNIST pokazano, jak przeprowadzić migrację programu uczenia głębokiego z jednym węzłem do rozproszonego uczenia głębokiego za pomocą narzędzia HorovodRunner.
- Uczenie głębokie przy użyciu biblioteki TensorFlow z narzędziem HorovodRunner dla MNIST
- Dostosowywanie pojedynczego węzła PyTorch do rozproszonego uczenia głębokiego
Ograniczenia
- Podczas pracy z plikami obszaru roboczego narzędzie HorovodRunner nie będzie działać, jeśli
npjest ustawiona na wartość większą niż 1, a import notesu z innych plików względnych. Rozważ użycie biblioteki horovod.spark zamiastHorovodRunner. - Jeśli wystąpią błędy takie jak
WARNING: Open MPI accepted a TCP connection from what appears to be a another Open MPI process but cannot find a corresponding process entry for that peer, oznacza to problem z komunikacją sieciową między węzłami w klastrze. Aby rozwiązać ten błąd, dodaj następujący fragment kodu szkoleniowego, aby użyć podstawowego interfejsu sieciowego.
import os
os.environ["OMPI_MCA_btl_tcp_if_include"]="eth0"
os.environ["NCCL_SOCKET_IFNAME"]="eth0"