Databricks Runtime na potrzeby uczenia maszynowego
W tym artykule opisano środowisko Databricks Runtime dla uczenia maszynowego i przedstawiono wskazówki dotyczące tworzenia klastra, który go używa.
Co to jest Databricks Runtime dla uczenia maszynowego?
Środowisko Databricks Runtime dla uczenia maszynowego (Databricks Runtime ML) automatyzuje tworzenie klastra przy użyciu wstępnie utworzonej infrastruktury uczenia maszynowego i uczenia głębokiego, w tym najpopularniejszych bibliotek ML i DL.
Biblioteki zawarte w środowisku Databricks Runtime ML
Środowisko Databricks Runtime ML zawiera wiele popularnych bibliotek uczenia maszynowego. Biblioteki są aktualizowane wraz z każdą wersją w celu uwzględnienia nowych funkcji i poprawek.
Usługa Databricks wyznaczyła podzbiór obsługiwanych bibliotek jako bibliotek najwyższego poziomu. W przypadku tych bibliotek usługa Databricks zapewnia szybszy cykl aktualizacji, aktualizując do najnowszych wersji pakietów przy każdej wersji środowiska uruchomieniowego, o ile nie występują konflikty zależności. Databricks zapewnia również zaawansowane wsparcie, testowanie i optymalizacje osadzone dla najwyższej klasy bibliotek. Biblioteki najwyższego poziomu są dodawane lub usuwane tylko w przypadku głównych wydań.
- Aby uzyskać pełną listę najwyższej klasy i innych dostępnych bibliotek, zobacz uwagi do wydania dla środowiska Databricks Runtime ML.
- Aby uzyskać informacje na temat częstotliwości aktualizowania bibliotek i gdy biblioteki są przestarzałe, zobacz Zasady konserwacji uczenia maszynowego środowiska Databricks Runtime.
Możesz zainstalować dodatkowe biblioteki, aby utworzyć własne środowisko dla notebooka lub klastra.
- Aby udostępnić bibliotekę dla wszystkich notesów uruchomionych w klastrze, utwórz bibliotekę klastra. Możesz również użyć skryptu inicjacji, aby zainstalować biblioteki w klastrach podczas tworzenia.
- Aby zainstalować bibliotekę dostępną tylko dla określonej sesji notebooka, użyj bibliotek języka Python o zakresie notebooka.
Konfigurowanie zasobów obliczeniowych dla środowiska Databricks Runtime ML
Proces tworzenia obliczeń opartych na Databricks Runtime ML zależy od tego, czy obszar roboczy jest włączony dla klastra grupy dedykowanej Public Preview, czy nie. Obszary robocze, które są włączone w wersji zapoznawczej, mają nowy uproszczony obliczeniowy interfejs użytkownika.
Tworzenie klastra przy użyciu środowiska Databricks Runtime ML
Podczas tworzenia klastra wybierz wersję środowiska Databricks Runtime ML z menu rozwijanego wersji środowiska uruchomieniowego usługi Databricks. Dostępne są zarówno środowiska uruchomieniowe uczenia maszynowego z obsługą procesora CPU, jak i procesora GPU.
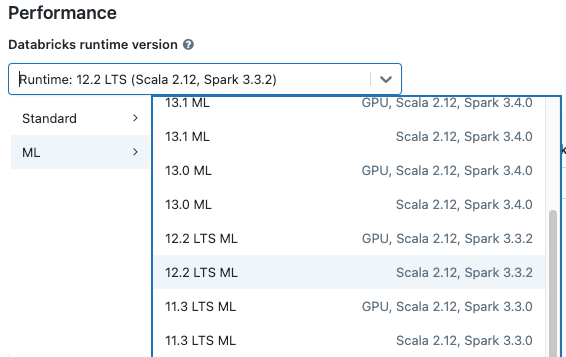
Jeśli wybierzesz klaster z menu rozwijanego w notesie, wersja środowiska Databricks Runtime pojawi się po prawej stronie od nazwy klastra.
W przypadku wybrania środowiska uruchomieniowego uczenia maszynowego z obsługą procesora GPU zostanie wyświetlony monit o wybranie zgodnego typu sterownika i typ procesu roboczego . Niezgodne typy wystąpień są wyłączone w menu rozwijanym. Typy instancji z obsługą GPU są wymienione pod etykietą przyspieszenie GPU. Aby uzyskać informacje na temat tworzenia klastrów GPU usługi Azure Databricks, zobacz Obliczenia z obsługą GPU. Środowisko uruchomieniowe Databricks Runtime ML obejmuje sterowniki sprzętowe procesora GPU i biblioteki firmy NVIDIA, takie jak CUDA.
Tworzenie nowego klastra przy użyciu nowego uproszczonego interfejsu użytkownika obliczeniowego
Wykonaj kroki opisane w tej sekcji tylko, jeśli obszar roboczy jest dostępny w ramach podglądu klastra dedykowanej grupy.
Aby użyć wersji uczenia maszynowego środowiska Databricks Runtime, zaznacz pole wyboru Machine Learning.
wybór MLR interfejsu użytkownika obliczeniowego 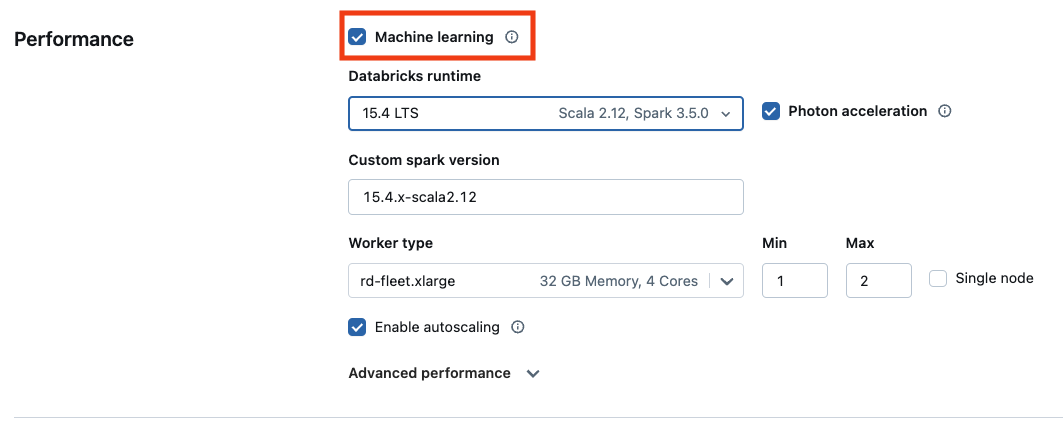
W przypadku obliczeń opartych na procesorze GPU wybierz typ wystąpienia z obsługą procesora GPU. Aby uzyskać pełną listę obsługiwanych typów procesorów GPU, zobacz Obsługiwane typy wystąpień.
Photon i Databricks Runtime ML
Podczas tworzenia klastra procesora CPU z uruchomionym środowiskiem Databricks Runtime 15.2 ML lub nowszym możesz włączyć funkcję Photon. Photon zwiększa wydajność aplikacji przy użyciu Spark SQL, Spark DataFrames, inżynierii cech, GraphFrames i xgboost4j. Nie oczekuje się poprawy wydajności aplikacji przy użyciu rdD platformy Spark, funkcji UDF biblioteki Pandas i języków innych niż JVM, takich jak Python. W związku z tym pakiety języka Python, takie jak XGBoost, PyTorch i TensorFlow, nie będą widzieć poprawy w narzędziu Photon.
Interfejsy API RDD platformy Spark i biblioteki MLlib platformy Spark mają ograniczoną zgodność z aplikacją Photon. Podczas przetwarzania dużych zestawów danych przy użyciu rdD platformy Spark lub biblioteki MLlib platformy Spark mogą wystąpić problemy z pamięcią platformy Spark. Zobacz Problemy z pamięcią platformy Spark.
Tryb dostępu dla klastrów uczenia maszynowego środowiska Databricks Runtime
Aby uzyskać dostęp do danych w katalogu Unity w klastrze z uruchomionym środowiskiem Databricks Runtime ML, tryb dostępu musi być ustawiony na Dedykowane (dawniej tryb dostępu pojedynczego użytkownika).
Gdy zasób obliczeniowy ma dostęp dedykowany , można go przypisać jednemu użytkownikowi lub grupie. Po przypisaniu do grupy (klastra grup) uprawnienia użytkownika automatycznie obniżają zakresy do uprawnień grupy, umożliwiając użytkownikowi bezpieczne udostępnianie zasobu innym członkom grupy.
W przypadku korzystania z trybu dedykowanego dostępu następujące funkcje są dostępne tylko w środowisku Databricks Runtime 15.4 LTS ML i nowszych wersjach:
- Szczegółowa kontrola dostępu.
- tworzenie tabel zapytań przy użyciupotoku DLT, w tym tabel przesyłania strumieniowego i zmaterializowanych widoków.