Szczegółowa kontrola dostępu do dedykowanych obliczeń (dawniej obliczenia pojedynczego użytkownika)
W tym artykule przedstawiono funkcjonalność filtrowania danych, która umożliwia precyzyjną kontrolę dostępu do zapytań uruchamianych na dedykowanych zasobach obliczeniowych (komputery ogólnego przeznaczenia lub do zadań skonfigurowane z użyciem trybu dostępu Dedicated). Zobacz Tryby dostępu.
To filtrowanie danych odbywa się w tle przy użyciu obliczeń bezserwerowych.
Dlaczego niektóre zapytania dotyczące dedykowanych obliczeń wymagają filtrowania danych?
Unity Catalog umożliwia kontrolowanie dostępu do danych tabelarycznych na poziomie kolumn i wierszy (zwanej również szczegółową kontrolą dostępu) przy użyciu następujących funkcji:
Gdy użytkownicy wysyłają zapytania dotyczące widoków wykluczających dane z przywołynych tabel lub tabel zapytań, które stosują filtry i maski, mogą używać dowolnego z następujących zasobów obliczeniowych bez ograniczeń:
- Magazyny SQL
- Standardowe zasoby obliczeniowe (poprzednio znane jako współużytkowane obliczenia)
Jeśli jednak używasz dedykowanego środowiska obliczeniowego do uruchamiania takich zapytań, obliczenia i obszar roboczy muszą spełniać określone wymagania:
Dedykowany zasób obliczeniowy musi znajdować się w środowisku Databricks Runtime 15.4 LTS lub nowszym.
Obszar roboczy musi być włączony dla bezserwerowych zasobów obliczeniowych dla zadań, notesów i bibliotek DLLT.
Aby potwierdzić, że region obszaru roboczego obsługuje obliczenia bezserwerowe, zobacz Funkcje z ograniczoną dostępnością regionalną.
Jeśli dedykowany zasób obliczeniowy i obszar roboczy spełniają te wymagania, filtrowanie danych jest uruchamiane automatycznie za każdym razem, gdy wykonujesz zapytanie dotyczące widoku lub tabeli korzystającej z szczegółowej kontroli dostępu.
Obsługa zmaterializowanych widoków, tabel przesyłania strumieniowego i widoków standardowych
Oprócz widoków dynamicznych, filtrów wierszy i masek kolumn filtrowanie danych umożliwia również wykonywanie zapytań dotyczących następujących widoków i tabel, które nie są obsługiwane w dedykowanych obliczeniach z uruchomionym środowiskiem Databricks Runtime 15.3 i poniżej:
W przypadku dedykowanych obliczeń z uruchomionym środowiskiem Databricks Runtime 15.3 lub nowszym użytkownik, który uruchamia zapytanie w widoku, musi mieć SELECT w tabelach i widokach, do których odwołuje się widok, co oznacza, że nie można używać widoków w celu zapewnienia szczegółowej kontroli dostępu. W środowisku Databricks Runtime 15.4 z filtrowaniem danych użytkownik, który wysyła zapytanie do widoku, nie potrzebuje dostępu do przywoływalnych tabel i widoków.
Jak działa filtrowanie danych na dedykowanych obliczeniach?
Za każdym razem, gdy zapytanie uzyskuje dostęp do następujących obiektów bazy danych, dedykowany zasób obliczeniowy przekazuje zapytanie do przetwarzania bezserwerowego w celu przeprowadzenia filtrowania danych:
- Widoki utworzone na podstawie tabel, do których użytkownik nie ma uprawnień
SELECT - Widoki dynamiczne
- Tabele z zdefiniowanymi filtrami wierszy lub maskami kolumn
- Zmaterializowane widoki i tabele przesyłania strumieniowego
Na poniższym diagramie użytkownik ma SELECT w systemach table_1, view_2i table_w_rls, które mają zastosowane filtry wierszy. Użytkownik nie ma SELECT na table_2, do którego odwołuje się view_2.

Zapytanie dotyczące table_1 jest obsługiwane w całości przez dedykowany zasób obliczeniowy, ponieważ nie jest wymagane filtrowanie. Zapytania dotyczące view_2 i table_w_rls wymagają filtrowania danych w celu zwrócenia danych, do których użytkownik ma dostęp. Te zapytania są obsługiwane przez funkcję filtrowania danych w obliczeniach bezserwerowych.
Jakie koszty są naliczane?
Klienci są obciążani opłatami za zasoby obliczeniowe bezserwerowe, które są używane do wykonywania operacji filtrowania danych. Aby uzyskać informacje o cenach, zobacz Warstwy platformy i dodatki.
Możesz zapytać o tabelę użycia systemu rozliczeń, aby sprawdzić, ile zostało naliczone. Na przykład następujące zapytanie dzieli koszty obliczeń według użytkownika:
SELECT usage_date,
sku_name,
identity_metadata.run_as,
SUM(usage_quantity) AS `DBUs consumed by FGAC`
FROM system.billing.usage
WHERE usage_date BETWEEN '2024-08-01' AND '2024-09-01'
AND billing_origin_product = 'FINE_GRAINED_ACCESS_CONTROL'
GROUP BY 1, 2, 3 ORDER BY 1;
Wyświetlanie wydajności zapytań w przypadku włączenia filtrowania danych
Interfejs użytkownika platformy Spark dla dedykowanych obliczeń wyświetla metryki, których można użyć do zrozumienia wydajności zapytań. Dla każdego zapytania uruchamianego w zasobie obliczeniowym karta SQL/Dataframe wyświetla reprezentację grafu zapytania. Jeśli zapytanie było zaangażowane w filtrowanie danych, interfejs użytkownika wyświetla węzeł operatora RemoteSparkConnectScan w dolnej części grafu. Ten węzeł wyświetla metryki, których można użyć do zbadania wydajności zapytań. Zobacz Wyświetlanie informacji o obliczeniach w interfejsie użytkownika platformy Apache Spark.
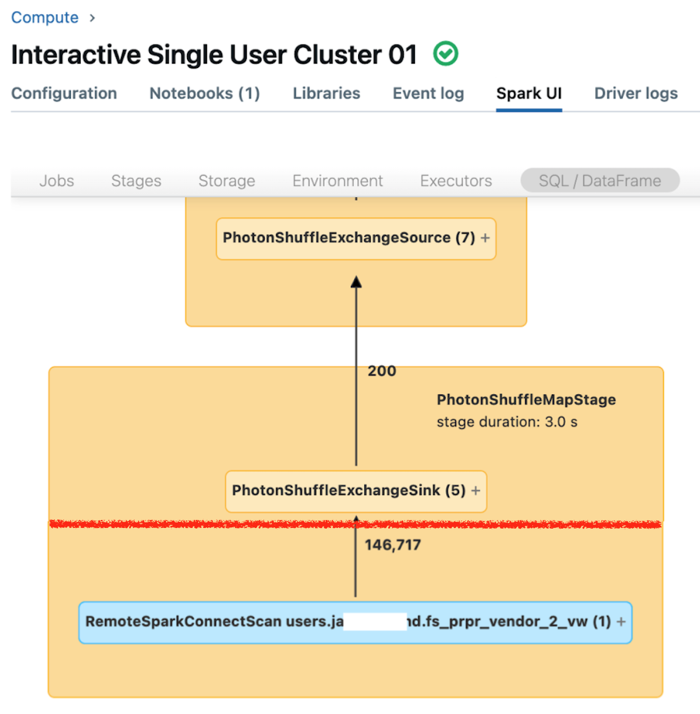
Rozwiń węzeł operatora RemoteSparkConnectScan, aby wyświetlić metryki, które odpowiadają na następujące pytania:
- Ile czasu zajęło filtrowanie danych? Wyświetl łączny czas zdalnego wykonywania.
- Ile wierszy pozostało po filtrowaniu danych? Wyświetl "dane wyjściowe wierszy".
- Ile danych (w bajtach) zostało zwróconych po filtrowaniu danych? Wyświetl "rozmiar wynikowy wierszy".
- Ile plików danych zostało oczyszczonych z partycji i nie trzeba było odczytywać z magazynu? Wyświetl "Pliki oczyszczone" i "Rozmiar plików oczyszczonych".
- Ile plików danych nie można było przyciąć i które musiały zostać odczytane z magazynu? Wyświetl "Pliki odczytane" i "Rozmiar odczytanych plików".
- Ile z plików, które musiały być odczytane, było już w pamięci podręcznej? Wyświetl "Rozmiar trafień pamięci podręcznej" i "Rozmiar błędu pamięci podręcznej".
Ograniczenia
Brak obsługi operacji zapisu lub odświeżania tabeli w tabelach, które mają zastosowane filtry wierszy lub maski kolumn.
W szczególności operacje DML, takie jak
INSERT,DELETE,UPDATE,REFRESH TABLEiMERGE, nie są obsługiwane. Z tych tabel można tylko odczytywać (SELECT).Samosprzężenia są domyślnie blokowane, gdy jest wywoływane filtrowanie danych, ale można je zezwolić, ustawiając
spark.databricks.remoteFiltering.blockSelfJoinswartość false na obliczeniach, na których są uruchamiane te polecenia.Przed włączeniem połączeń samoczynnych na dedykowanym zasobie obliczeniowym, należy pamiętać, że zapytanie połączenia samoczynnego obsługiwane przez funkcjonalność filtrowania danych może zwracać różne migawki tej samej zdalnej tabeli.
- Brak obsługi obrazów w Dockerze.
- Jeśli obszar roboczy został wdrożony z zaporą przed listopadem 2024 r., należy otworzyć porty 8443 i 8444, aby umożliwić szczegółową kontrolę dostępu w dedykowanych obliczeniach. Zobacz Reguły grupy zabezpieczeń sieciowej.