Przygotowywanie danych do dostrajania modelu foundation
Ważne
Ta funkcja jest dostępna w publicznej wersji zapoznawczej w następujących regionach: centralus, , eastuseastus2, northcentralusi westus.
W tym artykule opisano akceptowane formaty plików danych szkoleniowych i ewaluacyjnych dla dostrajania modelu fundamentowego (obecnie część szkolenia modelu Mosaic AI).
Notatnik: walidacja danych dla przebiegów treningowych
W poniższym notesie pokazano, jak zweryfikować dane. Jest przeznaczony do uruchamiania niezależnie przed rozpoczęciem trenowania. Sprawdza, czy dane są w poprawnym formacie dostrajania modelu foundation i zawierają kod, który ułatwia szacowanie kosztów podczas przebiegu trenowania przez tokenizowanie nieprzetworzonego zestawu danych.
Weryfikowanie danych na potrzeby notesu przebiegów szkoleniowych
Przygotowywanie danych do ukończenia czatu
W przypadku zadań ukończenia czatu dane sformatowane za pomocą czatu muszą znajdować się w pliku jsonl, gdzie każdy wiersz jest oddzielnym obiektem JSON reprezentującym jedną sesję czatu. Każda sesja czatu jest reprezentowana jako obiekt JSON z pojedynczym kluczem, messagesktóry jest mapowy na tablicę obiektów komunikatów. Aby wytrenować dane czatu, podaj task_type = 'CHAT_COMPLETION', gdy tworzysz swoją sesję treningową.
Wiadomości w formacie czatu są automatycznie formatowane zgodnie z szablonem czatu modelu, więc nie ma potrzeby dodawania specjalnych tokenów czatu, aby ręcznie sygnalizować początek lub koniec obrotu czatu. Przykładem modelu korzystającego z niestandardowego szablonu czatu jest Meta Llama 3.1 8B Instruct.
Każdy obiekt komunikatu w tablicy reprezentuje pojedynczy komunikat w konwersacji i ma następującą strukturę:
-
role: ciąg wskazujący autora wiadomości. Możliwe wartości tosystem,useriassistant. Jeśli rola tosystem, musi to być pierwszy czat na liście wiadomości. Musi istnieć co najmniej jeden komunikat z roląassistant, a wszystkie komunikaty po wyświetleniu (opcjonalnego) monitu systemowego muszą być alternatywne role między użytkownikiem/asystentem. Nie może istnieć dwa sąsiadujące komunikaty z tą samą rolą. Ostatni komunikat w tablicymessagesmusi mieć rolęassistant. -
content: ciąg zawierający tekst wiadomości.
Uwaga
Modele mistralne nie akceptują system ról w swoich formatach danych.
Poniżej przedstawiono przykład danych sformatowanych na czacie:
{"messages": [
{"role": "system", "content": "A conversation between a user and a helpful assistant."},
{"role": "user", "content": "Hi there. What's the capital of the moon?"},
{"role": "assistant", "content": "This question doesn't make sense as nobody currently lives on the moon, meaning it would have no government or political institutions. Furthermore, international treaties prohibit any nation from asserting sovereignty over the moon and other celestial bodies."},
]
}
Przygotowywanie danych do dalszego wstępnego szkolenia
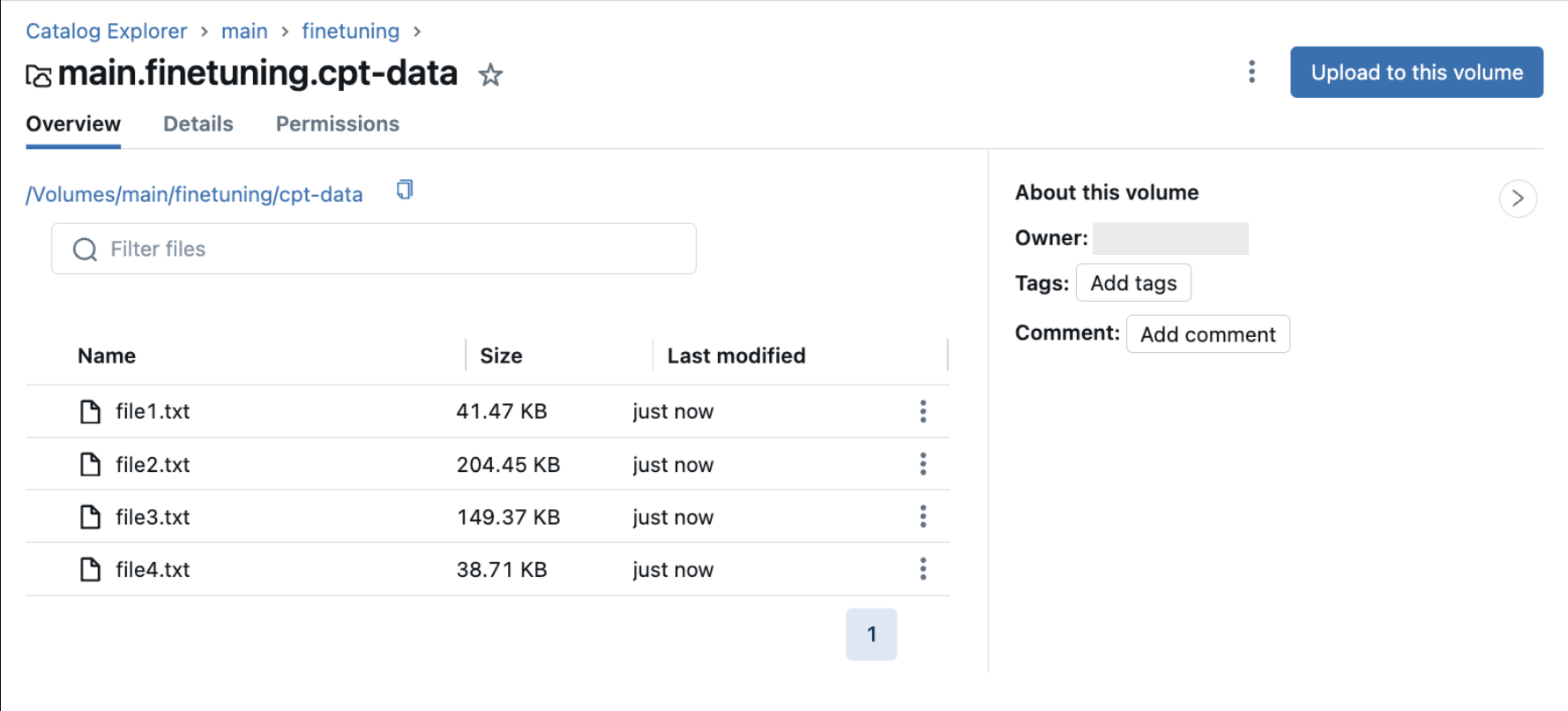
W przypadku dalszych zadań wstępnych dane szkoleniowe to dane tekstowe bez struktury. Dane szkoleniowe muszą znajdować się w woluminie Unity Catalog zawierającym pliki .txt. Każdy plik .txt jest traktowany jako pojedyncza próbka. Jeśli pliki .txt znajdują się w folderze woluminu katalogu Unity, te pliki są również pobierane jako dane szkoleniowe. Wszystkie pliki inne niż txt w woluminie są ignorowane. Zobacz Przekazywanie plików do woluminu wykazu aparatu Unity.
Na poniższej ilustracji przedstawiono przykładowe pliki .txt w woluminie Unity Catalog. Aby użyć tych danych w konfiguracji ciągłego działania przedtreningowego, ustaw train_data_path = "dbfs:/Volumes/main/finetuning/cpt-data" i ustaw task_type = 'CONTINUED_PRETRAIN'.
Samodzielne formatowanie danych
Ostrzeżenie
Wskazówki zawarte w tej sekcji nie są zalecane, ale są dostępne w scenariuszach, w których wymagane jest niestandardowe formatowanie danych.
Usługa Databricks zdecydowanie zaleca używanie danych w formacie czatu, aby odpowiednie formatowanie było automatycznie stosowane do danych w zależności od modelu, który jest używany.
Dostrajanie modelu foundation umożliwia samodzielne formatowanie danych. Każde formatowanie danych musi być stosowane podczas trenowania i obsługi modelu. Aby wytrenować model przy użyciu sformatowanych danych, ustaw task_type = 'INSTRUCTION_FINETUNE' podczas tworzenia sesji treningowej.
Dane szkoleniowe i ewaluacyjne muszą znajdować się w jednym z następujących schematów:
Pary monitów i odpowiedzi.
{"prompt": "your-custom-prompt", "response": "your-custom-response"}Pary monitów i uzupełniania.
{"prompt": "your-custom-prompt", "completion": "your-custom-response"}
Ważne
Monitowanie odpowiedzi i uzupełnianie monitów niesą szablonowane, więc wszelkie szablony specyficzne dla modelu, takie jak formatowanie instrukcji Mistral, musi być wykonywane jako krok przetwarzania wstępnego.
Obsługiwane formaty danych
Obsługiwane są następujące formaty danych:
Wolumin wykazu aparatu Unity z plikiem
.jsonl. Dane szkoleniowe muszą być w formacie JSONL, gdzie każdy wiersz jest prawidłowym obiektem JSON. W poniższym przykładzie przedstawiono przykład pary monitów i odpowiedzi:{"prompt": "What is Databricks?","response": "Databricks is a cloud-based data engineering platform that provides a fast, easy, and collaborative way to process large-scale data."}Tabela delty zgodna z jednym z akceptowanych schematów wymienionych powyżej. W przypadku tabel delty należy podać
data_prep_cluster_idparametr do przetwarzania danych. Zobacz Konfigurowanie przebiegu trenowania.Publiczny zestaw danych przytulania twarzy.
Jeśli używasz publicznego zestawu danych funkcji Przytulanie twarzy jako danych treningowych, określ pełną ścieżkę z podziałem, na przykład
mosaicml/instruct-v3/train and mosaicml/instruct-v3/test. To konto dotyczy zestawów danych, które mają różne schematy podzielone. Zagnieżdżone zestawy danych z przytulania twarzy nie są obsługiwane.Aby zapoznać się z bardziej rozbudowanym przykładem, zobacz
mosaicml/dolly_hhrlhfzestaw danych dotyczący funkcji Hugging Face.Następujące przykładowe wiersze danych pochodzą z
mosaicml/dolly_hhrlhfzestawu danych.{"prompt": "Below is an instruction that describes a task. Write a response that appropriately completes the request. ### Instruction: what is Databricks? ### Response: ","response": "Databricks is a cloud-based data engineering platform that provides a fast, easy, and collaborative way to process large-scale data."} {"prompt": "Below is an instruction that describes a task. Write a response that appropriately completes the request. ### Instruction: Van Halen famously banned what color M&Ms in their rider? ### Response: ","response": "Brown."}