Tworzenie przebiegu trenowania przy użyciu interfejsu API dostosowywania modelu podstawowego
Ważne
Ta funkcja jest dostępna w publicznej wersji zapoznawczej w następujących regionach: centralus, , eastuseastus2, northcentralusi westus.
W tym artykule opisano sposób tworzenia i konfigurowania przebiegu trenowania przy użyciu dostrajania modelu podstawowego (obecnie część interfejsu API trenowania modelu mozaiki sztucznej inteligencji) oraz opisano wszystkie parametry używane w wywołaniu interfejsu API. Możesz również utworzyć przebieg przy użyciu interfejsu użytkownika. Aby uzyskać instrukcje, zobacz Create a training run using the Foundation Model Fine-tuning UI (Tworzenie przebiegu trenowania przy użyciu interfejsu użytkownika dostrajania modelu podstawowego).
Wymagania
Zobacz Wymagania.
Tworzenie przebiegu trenowania
Aby programowo utworzyć przebiegi trenowania, użyj create() funkcji . Ta funkcja szkoli model w podanym zestawie danych i konwertuje końcowy punkt kontrolny Composer na punkt kontrolny w formacie Hugging Face w celu wnioskowania.
Wymagane dane wejściowe to model, który chcesz wytrenować, lokalizację zestawu danych treningowych i miejsce rejestrowania modelu. Istnieją również opcjonalne parametry, które umożliwiają przeprowadzenie oceny i zmianę hiperparametrów przebiegu.
Po zakończeniu przebiegu ukończono ukończony przebieg i końcowy punkt kontrolny są zapisywane, model jest klonowany, a klon jest zarejestrowany w wykazie aparatu Unity jako wersja modelu na potrzeby wnioskowania.
Model z ukończonego przebiegu, a nie sklonowana wersja modelu w katalogu aparatu Unity, a jego punkty kontrolne Composer i Hugging Face są zapisywane w narzędziu MLflow. Punkty kontrolne Composer mogą służyć do dalszego dostrajania zadań.
Zobacz Konfigurowanie przebiegu trenowania, aby uzyskać szczegółowe informacje o argumentach funkcji create() .
from databricks.model_training import foundation_model as fm
run = fm.create(
model='meta-llama/Llama-2-7b-chat-hf',
train_data_path='dbfs:/Volumes/main/mydirectory/ift/train.jsonl', # UC Volume with JSONL formatted data
# Public HF dataset is also supported
# train_data_path='mosaicml/dolly_hhrlhf/train'
register_to='main.mydirectory', # UC catalog and schema to register the model to
)
Konfigurowanie przebiegu trenowania
Poniższa tabela zawiera podsumowanie parametrów foundation_model.create() funkcji.
| Parametr | Wymagania | Type | opis |
|---|---|---|---|
model |
x | Str | Nazwa modelu do użycia. Zobacz Obsługiwane modele. |
train_data_path |
x | Str | Lokalizacja danych treningowych. Może to być lokalizacja w katalogu aparatu Unity (<catalog>.<schema>.<table> lub dbfs:/Volumes/<catalog>/<schema>/<volume>/<dataset>.jsonl) lub zestawie danych HuggingFace.W przypadku INSTRUCTION_FINETUNEelementu dane powinny być sformatowane przy użyciu każdego wiersza zawierającego prompt pole i response .W przypadku CONTINUED_PRETRAINprogramu jest to folder .txt plików. Zobacz Przygotowywanie danych pod kątem dostrajania modelu foundation pod kątem akceptowanych formatów danych i Zalecany rozmiar danych na potrzeby trenowania modelu na potrzeby zaleceń dotyczących rozmiaru danych. |
register_to |
x | Str | Wykaz i schemat aparatu Unity (<catalog>.<schema> lub <catalog>.<schema>.<custom-name>), w którym model jest zarejestrowany po trenowaniu w celu łatwego wdrożenia. Jeśli custom-name nie zostanie podana wartość domyślna, zostanie ustawiona nazwa uruchomienia. |
data_prep_cluster_id |
Str | Identyfikator klastra klastra do użycia na potrzeby przetwarzania danych platformy Spark. Jest to wymagane w przypadku nadzorowanych zadań szkoleniowych, w których dane szkoleniowe są w tabeli delty. Aby uzyskać informacje na temat znajdowania identyfikatora klastra, zobacz Pobieranie identyfikatora klastra. | |
experiment_path |
Str | Ścieżka do eksperymentu MLflow, w którym są zapisywane dane wyjściowe przebiegu trenowania (metryki i punkty kontrolne). Domyślnie nazwa przebiegu w osobistym obszarze roboczym użytkownika (tj. /Users/<username>/<run_name>). |
|
task_type |
Str | Typ zadania do uruchomienia. Może to być CHAT_COMPLETION (wartość domyślna), CONTINUED_PRETRAINlub INSTRUCTION_FINETUNE. |
|
eval_data_path |
Str | Zdalna lokalizacja danych oceny (jeśli istnieje). Musi być zgodny z tym samym formatem co train_data_path. |
|
eval_prompts |
Lista[str] | Lista ciągów monitów do generowania odpowiedzi podczas oceny. Wartość domyślna to None (nie generuj monitów). Wyniki są rejestrowane w eksperymencie za każdym razem, gdy model jest sprawdzany. Generacje są wykonywane w każdym punkcie kontrolnym modelu z następującymi parametrami generowania: max_new_tokens: 100, , temperature: 1top_k: 50, top_p: 0.95, . do_sample: true |
|
custom_weights_path |
Str | Zdalna lokalizacja niestandardowego punktu kontrolnego modelu na potrzeby trenowania. Wartość domyślna to None, co oznacza, że przebieg rozpoczyna się od oryginalnych wstępnie wytrenowanych wag wybranego modelu. Jeśli podano wagi niestandardowe, te wagi są używane zamiast oryginalnych wstępnie wytrenowanych wag modelu. Wagi te muszą być punktem kontrolnym Composer i muszą być zgodne z architekturą określonego model . Zobacz Build on custom model weights (Tworzenie na niestandardowych wagach modelu) |
|
training_duration |
Str | Łączny czas trwania przebiegu. Wartość domyślna to jedna epoka lub 1ep. Można określić w epokach (10ep) lub tokenach (1000000tok). |
|
learning_rate |
Str | Wskaźnik uczenia na potrzeby trenowania modelu. W przypadku wszystkich modeli innych niż Llama 3.1 405B Poinstruuj, domyślnym wskaźnikiem nauki jest 5e-7. W przypadku Llama 3.1 405B Poinstruuj domyślną stawką nauki jest 1.0e-5. Optymalizator to DecoupledLionW z wersjami beta 0,99 i 0,95 i bez rozkładu masy. Harmonogram szybkości nauki to LinearWithWarmupSchedule z rozgrzewką wynoszącą 2% całkowitego czasu trwania szkolenia i ostatnim mnożnikiem szybkości nauki wynoszącym 0. |
|
context_length |
Str | Maksymalna długość sekwencji próbki danych. Służy do obcinania wszelkich danych, które są zbyt długie i spakować krótsze sekwencje razem w celu zapewnienia wydajności. Wartość domyślna to 8192 tokeny lub maksymalna długość kontekstu dla podanego modelu, w zależności od tego, która z nich jest niższa. Tego parametru można użyć do skonfigurowania długości kontekstu, ale konfigurowanie poza maksymalną długością kontekstu każdego modelu nie jest obsługiwane. Zobacz Obsługiwane modele , aby uzyskać maksymalną obsługiwaną długość kontekstu każdego modelu. |
|
validate_inputs |
Wartość logiczna | Czy należy zweryfikować dostęp do ścieżek wejściowych przed przesłaniem zadania trenowania. Wartość domyślna to True. |
Tworzenie niestandardowych wag modelu
Dostosowywanie modelu podstawowego obsługuje dodawanie niestandardowych wag przy użyciu opcjonalnego parametru custom_weights_path do trenowania i dostosowywania modelu.
Aby rozpocząć, ustaw custom_weights_path ścieżkę punktu kontrolnego Composer z poprzedniego przebiegu trenowania. Ścieżki punktów kontrolnych można znaleźć na karcie Artefakty poprzedniego przebiegu platformy MLflow. Nazwa folderu punktu kontrolnego odpowiada partii i epoki określonej migawki, takiej jak ep29-ba30/.

- Aby podać najnowszy punkt kontrolny z poprzedniego przebiegu, ustaw
custom_weights_pathpunkt kontrolny Composer. Na przykładcustom_weights_path=dbfs:/databricks/mlflow-tracking/<experiment_id>/<run_id>/artifacts/<run_name>/checkpoints/latest-sharded-rank0.symlink. - Aby podać wcześniejszy punkt kontrolny, ustaw
custom_weights_pathścieżkę do folderu zawierającego.distcppliki odpowiadające żądanemu punktowi kontrolnemu, takie jakcustom_weights_path=dbfs:/databricks/mlflow-tracking/<experiment_id>/<run_id>/artifacts/<run_name>/checkpoints/ep#-ba#.
Następnie zaktualizuj model parametr tak, aby był zgodny z modelem podstawowym punktu kontrolnego przekazanego do custom_weights_path.
W poniższym przykładzie ift-meta-llama-3-1-70b-instruct-ohugkq jest to poprzedni przebieg, który dostraja meta-llama/Meta-Llama-3.1-70Bprogram . Aby dostosować najnowszy punkt kontrolny z ift-meta-llama-3-1-70b-instruct-ohugkqklasy , ustaw model zmienne i custom_weights_path w następujący sposób:
from databricks.model_training import foundation_model as fm
run = fm.create(
model = 'meta-llama/Meta-Llama-3.1-70B'
custom_weights_path = 'dbfs:/databricks/mlflow-tracking/2948323364469837/d4cd1fcac71b4fb4ae42878cb81d8def/artifacts/ift-meta-llama-3-1-70b-instruct-ohugkq/checkpoints/latest-sharded-rank0.symlink'
... ## other parameters for your fine-tuning run
)
Zobacz Konfigurowanie przebiegu trenowania w celu skonfigurowania innych parametrów w przebiegu dostrajania.
Pobieranie identyfikatora klastra
Aby pobrać identyfikator klastra:
Na lewym pasku nawigacyjnym obszaru roboczego usługi Databricks kliknij pozycję Obliczenia.
W tabeli kliknij nazwę klastra.
Kliknij
 w prawym górnym rogu i wybierz pozycję Wyświetl kod JSON z menu rozwijanego.
w prawym górnym rogu i wybierz pozycję Wyświetl kod JSON z menu rozwijanego.Zostanie wyświetlony plik JSON klastra. Skopiuj identyfikator klastra, który jest pierwszym wierszem w pliku.
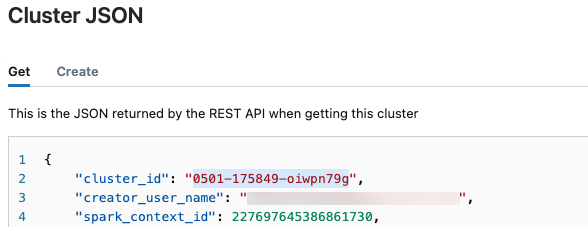
Uzyskiwanie stanu przebiegu
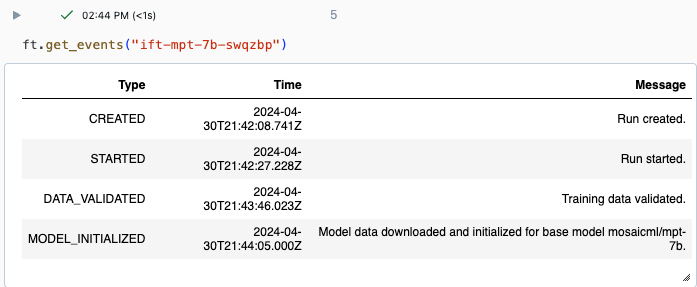
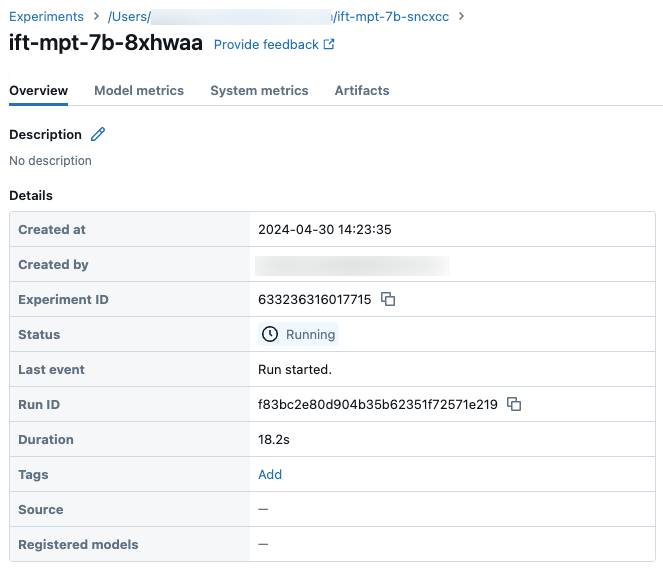
Postęp przebiegu można śledzić przy użyciu strony Eksperyment w interfejsie użytkownika usługi Databricks lub za pomocą polecenia get_events()interfejsu API . Aby uzyskać szczegółowe informacje, zobacz Wyświetlanie przebiegów dostrajania modelu podstawowego, zarządzanie nimi i analizowanie ich.
Przykładowe dane wyjściowe z :get_events()
Przykładowe szczegóły przebiegu na stronie Eksperyment:
Następne kroki
Po zakończeniu przebiegu trenowania możesz przejrzeć metryki w środowisku MLflow i wdrożyć model na potrzeby wnioskowania. Zobacz kroki od 5 do 7 samouczka : tworzenie i wdrażanie przebiegu dostrajania modelu podstawowego.
Zobacz szczegółowe dostrajanie instrukcji: nazwany notes demonstracyjny rozpoznawania jednostek, aby zapoznać się z przykładem dostrajania instrukcji, który przeprowadzi cię przez proces przygotowywania danych, dostrajania przebiegu trenowania i wdrażania.
Przykład notesu
W poniższym notesie przedstawiono przykład generowania danych syntetycznych przy użyciu modelu Meta Llama 3.1 405B Poinstruuj model i użyj tych danych w celu dostosowania modelu:
Generowanie danych syntetycznych przy użyciu notesu Instrukcje llama 3.1 405B
Dodatkowe zasoby
- Dostrajanie modelu podstawowego
- Samouczek: tworzenie i wdrażanie przebiegu dostrajania modelu podstawowego
- Tworzenie przebiegu trenowania przy użyciu interfejsu użytkownika dostrajania modelu podstawowego
- Wyświetlanie przebiegów dostrajania modelu podstawowego, zarządzanie nimi i analizowanie ich
- Przygotowywanie danych do dostrajania modelu foundation