What is DLT?
Note
DLT requires the Premium plan. Contact your Databricks account team for more information.
DLT is a declarative framework designed to simplify the creation of reliable and maintainable extract, transform, and load (ETL) pipelines. You specify what data to ingest and how to transform it, and DLT automates key aspects of managing your data pipeline, including orchestration, compute management, monitoring, data quality enforcement, and error handling.
DLT is built on Apache Spark, but instead of defining your data pipelines using a series of separate Apache Spark tasks, you define streaming tables and materialized views that the system should create and the queries required to populate and update those streaming tables and materialized views.
To learn more about the benefits of building and running your ETL pipelines with DLT, see the DLT product page.
Benefits of DLT compared to Apache Spark
Apache Spark is a versatile open-source unified analytics engine, including ETL. DLT builds on Spark to address specific and common ETL processing tasks. DLT can significantly accelerate your path to production when your requirements include these processing tasks, including:
- Ingesting data from typical sources.
- Transforming data incrementally.
- Performing change data capture (CDC).
However, DLT is unsuitable for implementing some types of procedural logic. For example, processing requirements such as writing to an external table or including a conditional that operates on external file storage or database tables cannot be performed inside the code defining a DLT dataset. To implement processing not supported by DLT, Databricks recommends using Apache Spark or including the pipeline in a Databricks Job that performs the processing in a separate job task. See DLT pipeline task for jobs.
The following table compares DLT with Apache Spark:
| Capability | DLT | Apache Spark |
|---|---|---|
| Data transformations | You can transform data using SQL or Python. | You can transform data using SQL, Python, Scala, or R. |
| Incremental data processing | Many data transformations are automatically processed incrementally. | You must determine what data is new so you can incrementally process it. |
| Orchestration | Transformations are automatically orchestrated in the right order. | You must make sure that different transformations run in the correct order. |
| Parallelism | All transformations are run with the correct level of parallelism. | You must use threads or an outside orchestrator to run unrelated transformations in parallel. |
| Error handling | Failures are automatically retried. | You must decide how to handle errors and retries. |
| Monitoring | Metrics and events are logged automatically. | You must write code to collect metrics about execution or data quality. |
Key Concepts of DLT
The following illustration shows the important components of a DLT pipeline, followed by an explanation of each.
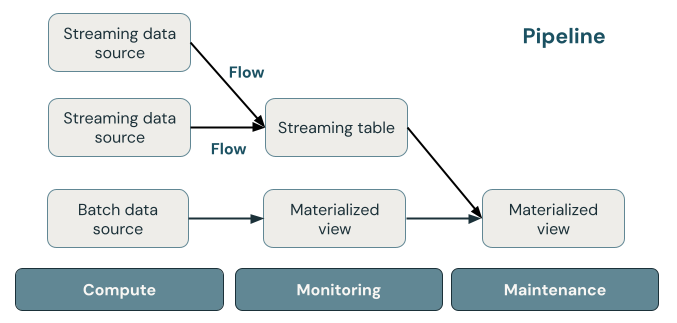
Streaming table
A streaming table is a Delta table that has one or more streams writing to it. Streaming tables are commonly used for ingestion because they process input data exactly once and can process large volumes of append-only data. Streaming tables are also useful for low-latency transformation of high-volume data streams.
Materialized view
A materialized view is a view that contains precomputed records based on the query that defines the materialized view. The records in the materialized view are automatically kept up to date by DLT based on the update schedule or triggers of the pipeline. Each time a materialized view is updated, it is guaranteed to have the same results as running the defining query over the latest data available. However, this is often done without recomputing the full result from scratch, using incremental refresh. Materialized views are commonly used for transformations.
Views
All views in Azure Databricks compute results from source datasets as they are queried, leveraging caching optimizations when available. DLT does not publish views to the catalog, so views can be referenced only in the pipeline in which they are defined. Views are useful as intermediate queries that should not be exposed to end users or systems. Databricks recommends using views to enforce data quality constraints or transform and enrich datasets that drive multiple downstream queries.
Pipeline
A pipeline is a collection of streaming tables and materialized views that are updated together. These streaming tables and materialized views are declared in Python or SQL source files. A pipeline also includes a configuration that defines the compute used to update the streaming tables and materialized views when the pipeline runs. Similar to how a Terraform template defines the infrastructure in your cloud account, a DLT pipeline defines the datasets and transformations for your data processing.
How do DLT datasets process data?
The following table describes how materialized views, streaming tables, and views process data:
| Dataset type | How are records processed through defined queries? |
|---|---|
| Streaming table | Each record is processed exactly once. This assumes an append-only source. |
| Materialized view | Records are processed as required to return accurate results for the current data state. Materialized views should be used for data processing tasks such as transformations, aggregations, or pre-computing slow queries and frequently used computations. |
| View | Records are processed each time the view is queried. Use views for intermediate transformations and data quality checks that should not be published to public datasets. |
Declare your first datasets in DLT
DLT introduces new syntax for Python and SQL. To learn the basics of pipeline syntax, see Develop pipeline code with Python and Develop pipeline code with SQL.
Note
DLT separates dataset definitions from update processing, and DLT notebooks are not intended for interactive execution.
How do you configure DLT pipelines?
The settings for DLT pipelines fall into two broad categories:
- Configurations that define a collection of notebooks or files (known as source code) that use DLT syntax to declare datasets.
- Configurations that control pipeline infrastructure, dependency management, how updates are processed, and how tables are saved in the workspace.
Most configurations are optional, but some require careful attention, especially when configuring production pipelines. These include the following:
- To make data available outside the pipeline, you must declare a target schema to publish to the Hive metastore or a target catalog and target schema to publish to Unity Catalog.
- Data access permissions are configured through the cluster used for execution. Ensure your cluster has appropriate permissions configured for data sources and the target storage location, if specified.
For details on using Python and SQL to write source code for pipelines, see DLT SQL language reference and DLT Python language reference.
For more on pipeline settings and configurations, see Configure a DLT pipeline.
Deploy your first pipeline and trigger updates
Before processing data with DLT, you must configure a pipeline. After a pipeline is configured, you can trigger an update to calculate results for each dataset in your pipeline. To get started using DLT pipelines, see Tutorial: Run your first DLT pipeline.
What is a pipeline update?
Pipelines deploy infrastructure and recompute data state when you start an update. An update does the following:
- Starts a cluster with the correct configuration.
- Discovers all the tables and views defined and checks for any analysis errors such as invalid column names, missing dependencies, and syntax errors.
- Creates or updates tables and views with the most recent data available.
Pipelines can be run continuously or on a schedule depending on your use case’s cost and latency requirements. See Run an update on a DLT pipeline.
Ingest data with DLT
DLT supports all data sources available in Azure Databricks.
Databricks recommends using streaming tables for most ingestion use cases. For files arriving in cloud object storage, Databricks recommends Auto Loader. You can directly ingest data with DLT from most message buses.
For more information about configuring access to cloud storage, see Cloud storage configuration.
For formats not supported by Auto Loader, you can use Python or SQL to query any format supported by Apache Spark. See Load data with DLT.
Monitor and enforce data quality
You can use expectations to specify data quality controls on the contents of a dataset. Unlike a CHECK constraint in a traditional database which prevents adding any records that fail the constraint, expectations provide flexibility when processing data that fails data quality requirements. This flexibility allows you to process and store data that you expect to be messy and data that must meet strict quality requirements. See Manage data quality with pipeline expectations.
How are DLT and Delta Lake related?
DLT extends the functionality of Delta Lake. Because tables created and managed by DLT are Delta tables, they have the same guarantees and features provided by Delta Lake. See What is Delta Lake?.
DLT adds several table properties in addition to the many table properties that can be set in Delta Lake. See DLT properties reference and Delta table properties reference.
How tables are created and managed by DLT
Azure Databricks automatically manages tables created with DLT, determining how updates need to be processed to correctly compute the current state of a table and performing a number of maintenance and optimization tasks.
For most operations, you should allow DLT to process all updates, inserts, and deletes to a target table. For details and limitations, see Retain manual deletes or updates.
Maintenance tasks performed by DLT
DLT performs maintenance tasks within 24 hours of a table being updated. Maintenance can improve query performance and reduce cost by removing old versions of tables. By default, the system performs a full OPTIMIZE operation followed by VACUUM. You can disable OPTIMIZE for a table by setting pipelines.autoOptimize.managed = false in the table properties for the table. Maintenance tasks are performed only if a pipeline update has run in the 24 hours before the maintenance tasks are scheduled.
Delta Live Tables is now DLT
The product formerly known as Delta Live Tables is now DLT.
Limitations
For a list of limitations, see DLT Limitations.
For a list of requirements and limitations that are specific to using DLT with Unity Catalog, see Use Unity Catalog with your DLT pipelines
Additional resources
- DLT has full support in the Databricks REST API. See DLT API.
- For pipeline and table settings, see DLT properties reference.
- DLT SQL language reference.
- DLT Python language reference.