Przekształcanie danych za pomocą tabel delta live
W tym artykule opisano, jak można używać Delta Live Tables do deklarowania przekształceń w zestawach danych oraz jak określać przetwarzanie rekordów w logice zapytań. Zawiera również przykłady typowych wzorców transformacji do tworzenia potoków Delta Live Tables.
Zestaw danych można zdefiniować względem dowolnego zapytania, które zwraca ramkę danych. Możesz użyć wbudowanych operacji Apache Spark, funkcji zdefiniowanych przez użytkownika, niestandardowej logiki i modeli MLflow jako przekształceń w potoku Delta Live Tables. Gdy dane zostaną załadowane do potoku Delta Live Tables, można zdefiniować nowe zestawy danych na podstawie źródeł nadrzędnych w celu utworzenia nowych tabel strumieniowych, zmaterializowanych widoków i widoków.
Aby dowiedzieć się, jak skutecznie wykonywać przetwarzanie stanowe przy użyciu Delta Live Tables, zobacz Optymalizowanie przetwarzania stanowego w Delta Live Tables przy użyciu watermarks.
Kiedy używać widoków, zmaterializowanych widoków i tabel przesyłania strumieniowego
Podczas implementowania zapytań potoku wybierz najlepszy typ zestawu danych, aby upewnić się, że są wydajne i możliwe do utrzymania.
Rozważ użycie widoku, aby wykonać następujące czynności:
- Podziel duże lub złożone zapytanie, które chcesz łatwiej zarządzać zapytaniami.
- Zweryfikuj wyniki pośrednie przy użyciu oczekiwań.
- Zmniejsz koszty magazynowania i zasobów obliczeniowych, aby uzyskać wyniki, których nie trzeba utrwalać. Ponieważ tabele są zmaterializowane, wymagają dodatkowych zasobów obliczeniowych i magazynu.
Rozważ użycie zmaterializowanego widoku, gdy:
- Wiele zapytań podrzędnych korzysta z tabeli. Ponieważ widoki są obliczane na żądanie, widok jest obliczany ponownie za każdym razem, gdy jest wykonywane zapytanie dotyczące widoku.
- Inne potoki, zadania lub zapytania używają tabeli. Ponieważ widoki nie są zmaterializowane, można z nich korzystać tylko w tej samej ścieżce przetwarzania.
- Chcesz wyświetlić wyniki zapytania podczas opracowywania. Ponieważ tabele są zmaterializowane i mogą być wyświetlane i odpytywane poza potokiem, użycie tabel podczas programowania może pomóc zweryfikować poprawność obliczeń. Po zweryfikowaniu przekonwertuj zapytania, które nie wymagają materializacji w widoki.
Rozważ użycie tabeli przesyłania strumieniowego, gdy:
- Zapytanie jest definiowane względem źródła danych, które stale lub przyrostowo rośnie.
- Wyniki zapytania powinny być obliczane przyrostowo.
- Potok wymaga wysokiej przepływności i małych opóźnień.
Uwaga
Tabele przesyłania strumieniowego są zawsze definiowane względem źródeł przesyłania strumieniowego. Możesz również użyć źródeł przesyłania strumieniowego za APPLY CHANGES INTO pomocą polecenia , aby zastosować aktualizacje z kanałów informacyjnych CDC. Zobacz Interfejsy API ZASTOSUJ ZMIANY: Upraszczanie przechwytywania danych zmian za pomocą tabel delta Live Tables.
Wykluczanie tabel ze schematu docelowego
Jeśli musisz obliczyć tabele pośrednie, które nie są przeznaczone do użycia zewnętrznego, możesz uniemożliwić ich publikowanie w schemacie przy użyciu słowa kluczowego TEMPORARY. Tabele tymczasowe nadal przechowują i przetwarzają dane zgodnie z semantyką Delta Live Tables, ale nie powinny być osiągalne poza bieżącym potokiem. Tabela tymczasowa jest przechowywana przez cały czas trwania potoku, który ją tworzy. Użyj następującej składni, aby zadeklarować tabele tymczasowe:
SQL
CREATE TEMPORARY STREAMING TABLE temp_table
AS SELECT ... ;
Python
@dlt.table(
temporary=True)
def temp_table():
return ("...")
Łączenie tabel strumieniowych i zmaterializowanych widoków w jednym potoku
Tabele przesyłania strumieniowego dziedziczą gwarancje przetwarzania przesyłania strumieniowego ze strukturą platformy Apache Spark i są skonfigurowane do przetwarzania zapytań ze źródeł danych tylko do dołączania, gdzie nowe wiersze są zawsze wstawiane do tabeli źródłowej, a nie modyfikowane.
Uwaga
Mimo że domyślnie tabele przesyłania strumieniowego wymagają źródeł danych tylko do dołączania, gdy źródło przesyłania strumieniowego jest inną tabelą przesyłania strumieniowego, która wymaga aktualizacji lub usunięcia, można zastąpić to zachowanie za pomocą flagi skipChangeCommits .
Typowy wzorzec przesyłania strumieniowego obejmuje pozyskiwanie danych źródłowych w celu utworzenia początkowych zestawów danych w potoku. Te początkowe zestawy danych są często nazywane tabelami z brązu i często wykonują proste przekształcenia.
Natomiast ostateczne tabele w potoku, często nazywane złotymi tabelami, często wymagają przeprowadzania skomplikowanych agregacji lub odczytu z celów operacji oznaczonej jako APPLY CHANGES INTO. Ponieważ te operacje z natury tworzą aktualizacje, a nie dołączają, nie są one obsługiwane jako dane wejściowe do tabel przesyłania strumieniowego. Te przekształcenia lepiej pasują do zmaterializowanych widoków.
Łącząc tabele strumieniowe i zmaterializowane widoki w jeden potok, można go uprościć, uniknąć kosztownego ponownego pozyskiwania lub ponownego przetwarzania danych pierwotnych oraz mieć pełne możliwości SQL do wykonywania złożonych agregacji w wydajnie zakodowanym i filtrowanym zestawie danych. W poniższym przykładzie przedstawiono ten typ przetwarzania mieszanego:
Uwaga
W tych przykładach użyto modułu automatycznego ładującego do ładowania plików z magazynu w chmurze. Aby załadować pliki przy użyciu Auto Loader w potoku z włączonym Katalogiem Unity, należy użyć lokalizacji zewnętrznych. Aby dowiedzieć się więcej na temat korzystania z katalogu Unity z tabelami Delta Live Tables, zobacz Korzystanie z katalogu Unity z potokami Delta Live Tables.
Python
@dlt.table
def streaming_bronze():
return (
# Since this is a streaming source, this table is incremental.
spark.readStream.format("cloudFiles")
.option("cloudFiles.format", "json")
.load("abfss://path/to/raw/data")
)
@dlt.table
def streaming_silver():
# Since we read the bronze table as a stream, this silver table is also
# updated incrementally.
return spark.readStream.table("streaming_bronze").where(...)
@dlt.table
def live_gold():
# This table will be recomputed completely by reading the whole silver table
# when it is updated.
return spark.readStream.table("streaming_silver").groupBy("user_id").count()
SQL
CREATE OR REFRESH STREAMING TABLE streaming_bronze
AS SELECT * FROM read_files(
"abfss://path/to/raw/data", "json"
)
CREATE OR REFRESH STREAMING TABLE streaming_silver
AS SELECT * FROM STREAM(streaming_bronze) WHERE...
CREATE OR REFRESH MATERIALIZED VIEW live_gold
AS SELECT count(*) FROM streaming_silver GROUP BY user_id
Dowiedz się więcej na temat używania automatycznego modułu ładującego do przyrostowego pozyskiwania plików JSON z usługi Azure Storage.
Sprzężenia statyczne strumienia
Łączenia strumieniowo-statyczne są dobrym wyborem w przypadku denormalizacji ciągłego strumienia danych, które są tylko dodawane, przy użyciu głównie statycznej tabeli wymiarów.
Z każdą aktualizacją potoku nowe rekordy ze strumienia są łączone z najaktualniejszą migawką tabeli statycznej. Jeśli rekordy są dodawane lub aktualizowane w tabeli statycznej po przetworzeniu odpowiednich danych z tabeli przesyłania strumieniowego, wynikowe rekordy nie zostaną ponownie obliczone, chyba że zostanie wykonane pełne odświeżenie.
W potokach skonfigurowanych do wyzwalanego wykonywania tabela statyczna zwraca wyniki z momentu rozpoczęcia aktualizacji. W rurach skonfigurowanych do ciągłego działania najnowsza wersja tabeli statycznej jest odpytywana za każdym razem, gdy aktualizacja jest przetwarzana.
Poniżej przedstawiono przykład strumieniowo-statycznego łączenia:
Python
@dlt.table
def customer_sales():
return spark.readStream.table("sales").join(spark.readStream.table("customers"), ["customer_id"], "left")
SQL
CREATE OR REFRESH STREAMING TABLE customer_sales
AS SELECT * FROM STREAM(sales)
INNER JOIN LEFT customers USING (customer_id)
Wydajne obliczanie agregacji
Tabele przesyłania strumieniowego umożliwiają przyrostowe obliczanie prostych agregacji dystrybucyjnych, takich jak liczba, minimalna, maksymalna lub suma oraz agregacje algebraiczne, takie jak średnia lub odchylenie standardowe. Usługa Databricks zaleca agregację przyrostową dla zapytań z ograniczoną liczbą grup, takich jak zapytanie z klauzulą GROUP BY country . Tylko nowe dane wejściowe są odczytywane przy każdej aktualizacji.
Dowiedz się więcej na temat pisania zapytań Delta Live Tables, które wykonują agregacje przyrostowe, zobacz Wykonywanie agregacji okienkowych za pomocą znaczników wodnych.
Używanie modeli MLflow w potoku Delta Live Tables
Uwaga
Aby używać modeli MLflow w potoku obsługującym Unity Catalog, potok musi być skonfigurowany do korzystania z kanału preview. Aby użyć kanału current , należy skonfigurować potok do publikowania w magazynie metadanych Hive.
Modele trenowane przez platformę MLflow można używać w potokach tabel delta live tables. Modele MLflow są traktowane jako przekształcenia w usłudze Azure Databricks, co oznacza, że działają na danych wejściowych ramki danych platformy Spark i zwracają wyniki jako ramkę danych platformy Spark. Ponieważ Delta Live Tables definiuje zestawy danych względem DataFrames, można konwertować obciążenia robocze Apache Spark, które używają MLflow, do Delta Live Tables, używając tylko kilku wierszy kodu. Aby uzyskać więcej informacji na temat platformy MLflow, zobacz MLflow for gen AI agent and ML model lifecycle.
Jeśli masz już notes języka Python wywołujący model MLflow, możesz dostosować ten kod do Delta Live Tables przy użyciu dekoratora @dlt.table i upewnienia się, że funkcje są zdefiniowane tak, aby zwracały wyniki transformacji. Delta Live Tables domyślnie nie instaluje bibliotek MLflow, dlatego upewnij się, że zainstalowano biblioteki MLFlow z %pip install mlflow i zaimportowano mlflow i dlt w górnej części notesu. Aby zapoznać się z wprowadzeniem do składni funkcji Delta Live Tables, zobacz
Aby użyć modeli MLflow w tabelach delta live, wykonaj następujące kroki:
- Uzyskaj identyfikator przebiegu i nazwę modelu MLflow. Identyfikator przebiegu i nazwa modelu są używane do konstruowania identyfikatora URI modelu MLflow.
- Użyj identyfikatora URI, aby zdefiniować funkcję UDF platformy Spark w celu załadowania modelu MLflow.
- Wywołaj funkcję UDF w definicjach tabeli, aby użyć modelu MLflow.
W poniższym przykładzie przedstawiono podstawową składnię dla tego wzorca:
%pip install mlflow
import dlt
import mlflow
run_id= "<mlflow-run-id>"
model_name = "<the-model-name-in-run>"
model_uri = f"runs:/{run_id}/{model_name}"
loaded_model_udf = mlflow.pyfunc.spark_udf(spark, model_uri=model_uri)
@dlt.table
def model_predictions():
return spark.read.table(<input-data>)
.withColumn("prediction", loaded_model_udf(<model-features>))
W kompletnym przykładzie poniższy kod definiuje funkcję UDF platformy Spark o nazwie loaded_model_udf , która ładuje model MLflow wyszkolony na podstawie danych o ryzyku kredytowym. Kolumny danych używane do przewidywania są przekazywane jako argument do funkcji UDF. Tabela loan_risk_predictions oblicza przewidywania dla każdego wiersza w loan_risk_input_data.
%pip install mlflow
import dlt
import mlflow
from pyspark.sql.functions import struct
run_id = "mlflow_run_id"
model_name = "the_model_name_in_run"
model_uri = f"runs:/{run_id}/{model_name}"
loaded_model_udf = mlflow.pyfunc.spark_udf(spark, model_uri=model_uri)
categoricals = ["term", "home_ownership", "purpose",
"addr_state","verification_status","application_type"]
numerics = ["loan_amnt", "emp_length", "annual_inc", "dti", "delinq_2yrs",
"revol_util", "total_acc", "credit_length_in_years"]
features = categoricals + numerics
@dlt.table(
comment="GBT ML predictions of loan risk",
table_properties={
"quality": "gold"
}
)
def loan_risk_predictions():
return spark.read.table("loan_risk_input_data")
.withColumn('predictions', loaded_model_udf(struct(features)))
Zachowywanie ręcznego usuwania lub aktualizacji
Funkcja Delta Live Tables umożliwia ręczne usuwanie lub aktualizowanie rekordów z tabeli i wykonywanie operacji odświeżania w celu ponownego skompilowania tabel podrzędnych.
Domyślnie Delta Live Tables ponownie przelicza wyniki tabel na podstawie danych wejściowych za każdym razem, gdy aktualizuje się pipeline, dlatego należy upewnić się, że usunięty rekord nie zostanie ponownie załadowany z danych źródłowych. Ustawienie właściwości tabeli pipelines.reset.allowed na wartość false uniemożliwia odświeżanie tabeli, ale nie zapobiega przyrostowym zapisom w tabelach lub nowym danych przepływanych do tabeli.
Na poniższym diagramie przedstawiono przykład użycia dwóch tabel przesyłania strumieniowego:
-
raw_user_tablepozyskiwanie nieprzetworzonych danych użytkownika ze źródła. -
bmi_tableprzyrostowo oblicza wyniki BMI przy użyciu wagi i wysokości zraw_user_table.
Chcesz ręcznie usunąć lub zaktualizować rekordy użytkowników z raw_user_table i ponownie skompilować bmi_table.
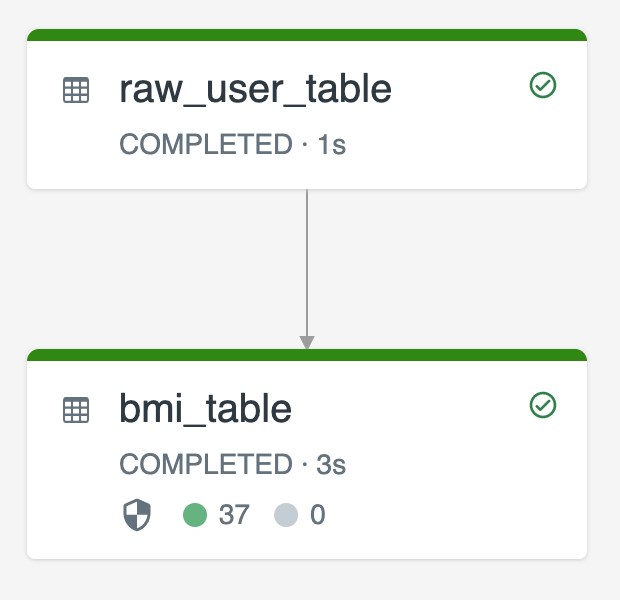
Poniższy kod demonstruje ustawienie właściwości tabeli pipelines.reset.allowed na false, aby wyłączyć pełne odświeżanie dla raw_user_table tak, aby zamierzone zmiany zostały zachowane w czasie, ale tabele podrzędne są ponownie obliczane po uruchomieniu aktualizacji potoku:
CREATE OR REFRESH STREAMING TABLE raw_user_table
TBLPROPERTIES(pipelines.reset.allowed = false)
AS SELECT * FROM read_files("/databricks-datasets/iot-stream/data-user", "csv");
CREATE OR REFRESH STREAMING TABLE bmi_table
AS SELECT userid, (weight/2.2) / pow(height*0.0254,2) AS bmi FROM STREAM(raw_user_table);