Zarządzaj jakością danych dzięki oczekiwaniom dotyczącym potoków danych
Użyj oczekiwań, aby zastosować ograniczenia jakości, które weryfikują dane w przepływach ETL. Oczekiwania zapewniają lepszy wgląd w metryki jakości danych i pozwalają na niepowodzenie aktualizacji lub porzucanie rekordów, gdy wykrywane są nieprawidłowe rekordy.
Ten artykuł zawiera omówienie oczekiwań, w tym przykłady składni i opcje zachowania. Aby uzyskać bardziej zaawansowane przypadki użycia i zalecane najlepsze rozwiązania, zobacz Zalecenia dotyczące oczekiwań i zaawansowane wzorce.
Jakie są oczekiwania?
Oczekiwania dotyczące są opcjonalnymi klauzulami w zmaterializowanym widoku potoku, tabeli przesyłania strumieniowego lub instrukcjach tworzenia widoku, które dotyczą kontroli jakości danych dla każdego rekordu przechodzącego przez zapytanie. Oczekiwania używają standardowych instrukcji logicznych SQL do określania ograniczeń. Można połączyć wiele oczekiwań dla pojedynczego zestawu danych i ustawić oczekiwania w deklaracjach wszystkich zestawów danych przez cały czasoprzebieg.
W poniższych sekcjach przedstawiono trzy składniki oczekiwań i podano przykłady składni.
Nazwa oczekiwania
Każde oczekiwanie musi mieć nazwę, która jest używana jako identyfikator do śledzenia i monitorowania oczekiwań. Wybierz nazwę, która komunikuje weryfikowane metryki. W poniższym przykładzie zdefiniowano oczekiwania valid_customer_age, aby potwierdzić, że wiek wynosi od 0 do 120 lat:
Ważny
Nazwa oczekiwania musi być unikatowa dla danego zestawu danych. Możesz ponownie wykorzystać oczekiwania w wielu zestawach danych w strumieniu przetwarzania. Zobacz Oczekiwania dotyczące przenośnego i wielokrotnego użytku.
Pyton
@dlt.table
@dlt.expect("valid_customer_age", "age BETWEEN 0 AND 120")
def customers():
return spark.readStream.table("datasets.samples.raw_customers")
SQL
CREATE OR REFRESH STREAMING TABLE customers(
CONSTRAINT valid_customer_age EXPECT (age BETWEEN 0 AND 120)
) AS SELECT * FROM STREAM(datasets.samples.raw_customers);
Ograniczenie do oceny
Klauzula ograniczenia jest instrukcją warunkową SQL, która musi mieć wartość true lub false dla każdego rekordu. Ograniczenie zawiera rzeczywistą logikę sprawdzania poprawności. Gdy rekord nie spełni tego warunku, uruchomi się oczekiwanie.
Ograniczenia muszą używać prawidłowej składni SQL i nie mogą zawierać następujących elementów:
- Niestandardowe funkcje języka Python
- Wywołania usług zewnętrznych
- Podzapytania odwołujące się do innych tabel
Poniżej przedstawiono przykłady ograniczeń, które można dodać do instrukcji tworzenia zestawu danych:
Pyton
# Simple constraint
@dlt.expect("non_negative_price", "price >= 0")
# SQL functions
@dlt.expect("valid_date", "year(transaction_date) >= 2020")
# CASE statements
@dlt.expect("valid_order_status", """
CASE
WHEN type = 'ORDER' THEN status IN ('PENDING', 'COMPLETED', 'CANCELLED')
WHEN type = 'REFUND' THEN status IN ('PENDING', 'APPROVED', 'REJECTED')
ELSE false
END
""")
# Multiple constraints
@dlt.expect("non_negative_price", "price >= 0")
@dlt.expect("valid_purchase_date", "date <= current_date()")
# Complex business logic
@dlt.expect(
"valid_subscription_dates",
"""start_date <= end_date
AND end_date <= current_date()
AND start_date >= '2020-01-01'"""
)
# Complex boolean logic
@dlt.expect("valid_order_state", """
(status = 'ACTIVE' AND balance > 0)
OR (status = 'PENDING' AND created_date > current_date() - INTERVAL 7 DAYS)
""")
SQL
-- Simple constraint
CONSTRAINT non_negative_price EXPECT (price >= 0)
-- SQL functions
CONSTRAINT valid_date EXPECT (year(transaction_date) >= 2020)
-- CASE statements
CONSTRAINT valid_order_status EXPECT (
CASE
WHEN type = 'ORDER' THEN status IN ('PENDING', 'COMPLETED', 'CANCELLED')
WHEN type = 'REFUND' THEN status IN ('PENDING', 'APPROVED', 'REJECTED')
ELSE false
END
)
-- Multiple constraints
CONSTRAINT non_negative_price EXPECT (price >= 0)
CONSTRAINT valid_purchase_date EXPECT (date <= current_date())
-- Complex business logic
CONSTRAINT valid_subscription_dates EXPECT (
start_date <= end_date
AND end_date <= current_date()
AND start_date >= '2020-01-01'
)
-- Complex boolean logic
CONSTRAINT valid_order_state EXPECT (
(status = 'ACTIVE' AND balance > 0)
OR (status = 'PENDING' AND created_date > current_date() - INTERVAL 7 DAYS)
)
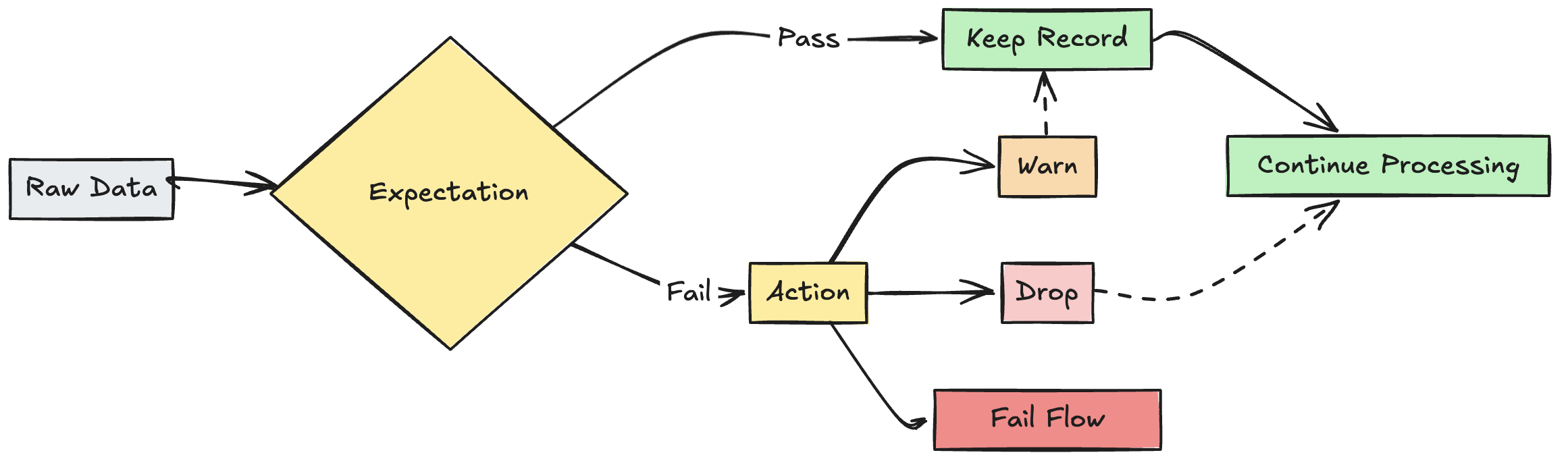
Działanie na rekordzie nieprawidłowym
Należy określić akcję, aby określić, co się stanie, gdy rekord zakończy się niepowodzeniem sprawdzania poprawności. W poniższej tabeli opisano dostępne akcje:
| Akcja | Składnia SQL | Składnia języka Python | Wynik |
|---|---|---|---|
| ostrzeżenie (ustawienie domyślne) | EXPECT |
dlt.expect |
Nieprawidłowe rekordy są zapisywane w obiekcie docelowym. Liczba prawidłowych i nieprawidłowych rekordów jest rejestrowana wraz z innymi metrykami zestawu danych. |
| Upuść | EXPECT ... ON VIOLATION DROP ROW |
dlt.expect_or_drop |
Nieprawidłowe rekordy są odrzucane, zanim dane zostaną zapisane w miejscu docelowym. Liczba porzuconych rekordów jest rejestrowana wraz z innymi metrykami zestawu danych. |
| niepowodzenie | EXPECT ... ON VIOLATION FAIL UPDATE |
dlt.expect_or_fail |
Nieprawidłowe rekordy uniemożliwiają pomyślne zaktualizowanie. Interwencja ręczna jest wymagana przed ponownym przetworzeniem. To oczekiwanie powoduje awarię pojedynczego przepływu i nie prowadzi do awarii innych przepływów w kanale. |
Możesz również zaimplementować zaawansowaną logikę w celu kwarantanny nieprawidłowych rekordów bez niepowodzenia lub porzucania danych. Sprawdź Kwarantanna nieprawidłowych rekordów.
metryki monitorowania oczekiwań
Możesz zobaczyć metryki śledzenia dla akcji warn lub drop w interfejsie użytkownika potoku. Ponieważ fail powoduje niepowodzenie aktualizacji po wykryciu nieprawidłowego rekordu, metryki nie są rejestrowane.
Aby wyświetlić metryki oczekiwań, wykonaj następujące kroki:
- Kliknij DLT na pasku bocznym.
- Kliknij nazwę swojego potoku.
- Kliknij zestaw danych ze zdefiniowanym oczekiwaniem.
- Wybierz kartę Jakość danych na prawym pasku bocznym.
Metryki jakości danych można wyświetlić, wysyłając zapytanie do dziennika zdarzeń DLT. Zobacz Jakość danych zapytań z dziennika zdarzeń.
Zachowaj nieprawidłowe rekordy
Zachowywanie nieprawidłowych rekordów jest domyślnym zachowaniem oczekiwań. Użyj operatora expect, jeśli chcesz przechowywać rekordy naruszające oczekiwania i jednocześnie zbierać metryki dotyczące liczby rekordów, które przechodzą lub nie spełniają ograniczenia. Rekordy naruszające oczekiwania są dodawane do docelowego zestawu danych wraz z prawidłowymi rekordami:
Pyton
@dlt.expect("valid timestamp", "timestamp > '2012-01-01'")
SQL
CONSTRAINT valid_timestamp EXPECT (timestamp > '2012-01-01')
Usuwanie nieprawidłowych rekordów
Użyj operatora expect_or_drop, aby zapobiec dalszemu przetwarzaniu nieprawidłowych rekordów. Rekordy naruszające oczekiwania są porzucane z docelowego zestawu danych:
Pyton
@dlt.expect_or_drop("valid_current_page", "current_page_id IS NOT NULL AND current_page_title IS NOT NULL")
SQL
CONSTRAINT valid_current_page EXPECT (current_page_id IS NOT NULL and current_page_title IS NOT NULL) ON VIOLATION DROP ROW
Niepowodzenie przy nieprawidłowych rekordach
Jeśli nieprawidłowe rekordy są niedopuszczalne, użyj operatora expect_or_fail, aby natychmiast zatrzymać wykonywanie, gdy rekord zakończy się niepowodzeniem. Jeśli operacja jest aktualizacją tabeli, system atomowo cofa transakcję.
Pyton
@dlt.expect_or_fail("valid_count", "count > 0")
SQL
CONSTRAINT valid_count EXPECT (count > 0) ON VIOLATION FAIL UPDATE
Ważny
Jeśli masz wiele przepływów równoległych zdefiniowanych w potoku, awaria pojedynczego przepływu nie spowoduje awarii innych przepływów.
wykres objaśniający błędy przepływu DLT 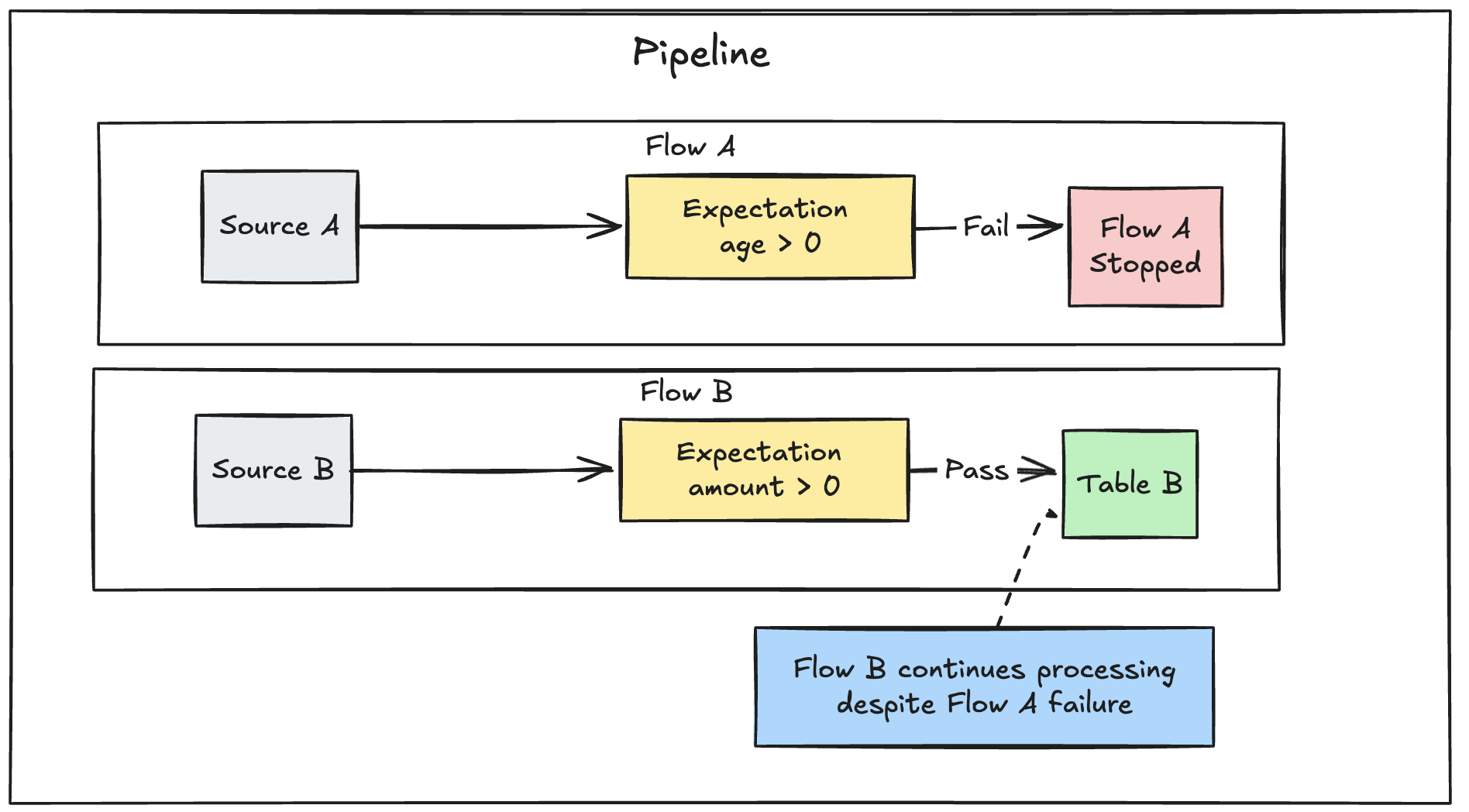
Rozwiązywanie problemów z aktualizacjami, które nie spełniają oczekiwań
Gdy pipeline zakończy się niepowodzeniem z powodu naruszenia oczekiwań, należy naprawić kod pipeline, aby poprawnie obsłużyć nieprawidłowe dane przed ponownym uruchomieniem.
Oczekiwania ustawione do wykrywania błędów w potokach modyfikują plan zapytania Spark w twoich przekształceniach, aby śledzić informacje potrzebne do wykrywania i raportowania naruszeń. Te informacje umożliwiają określenie, który rekord wejściowy spowodował naruszenie wielu zapytań. Poniżej przedstawiono przykładowe oczekiwania:
Expectation Violated:
{
"flowName": "sensor-pipeline",
"verboseInfo": {
"expectationsViolated": [
"temperature_in_valid_range"
],
"inputData": {
"id": "TEMP_001",
"temperature": -500,
"timestamp_ms": "1710498600"
},
"outputRecord": {
"sensor_id": "TEMP_001",
"temperature": -500,
"change_time": "2024-03-15 10:30:00"
},
"missingInputData": false
}
}
zarządzanie wieloma oczekiwaniami
Notatka
Chociaż zarówno język SQL, jak i Python obsługują wiele oczekiwań w ramach jednego zestawu danych, tylko język Python umożliwia grupowanie wielu oddzielnych oczekiwań i określanie zbiorczych akcji.
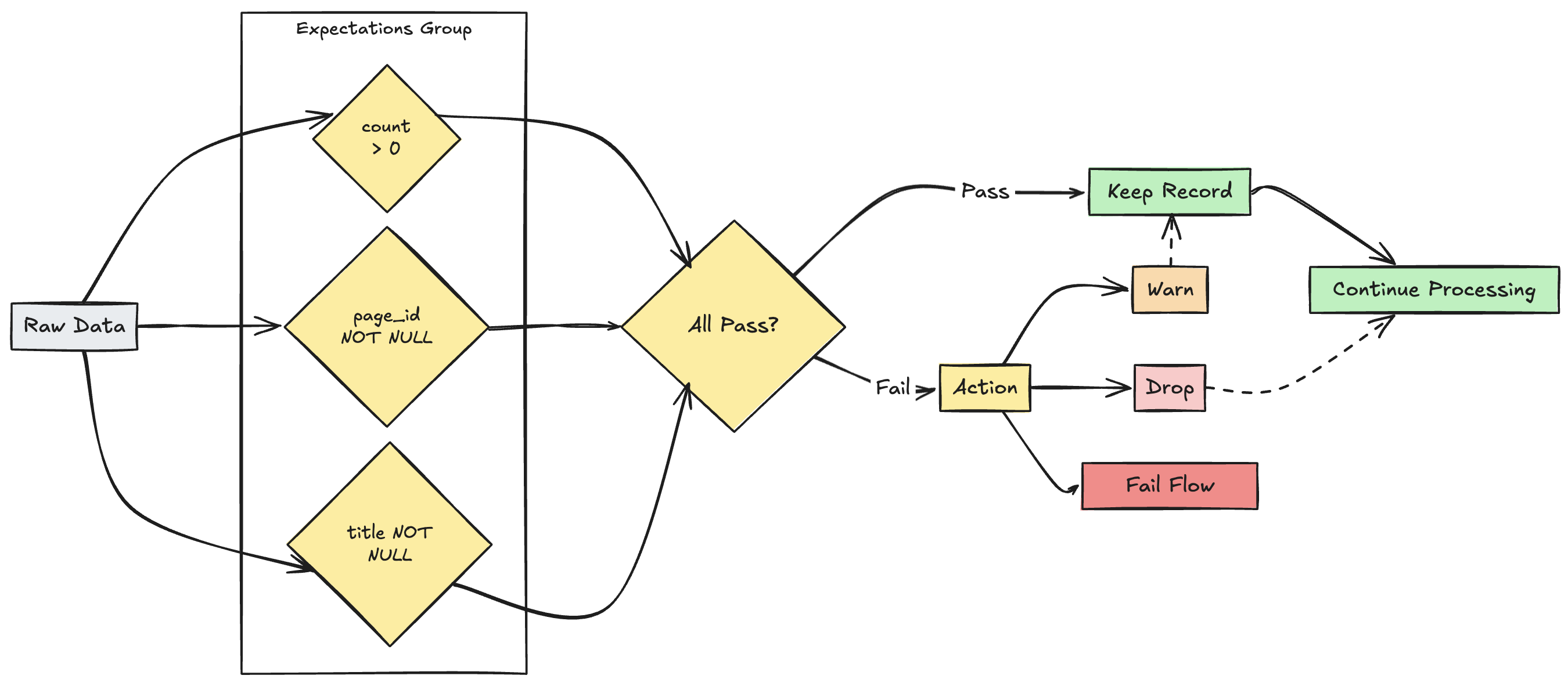
Można grupować wiele oczekiwań i określać akcje zbiorowe przy użyciu funkcji expect_all, expect_all_or_dropi expect_all_or_fail.
Te dekoratory akceptują słownik języka Python jako argument, gdzie klucz jest nazwą oczekiwania, a wartość jest ograniczeniem oczekiwania. Możesz ponownie użyć tego samego zestawu oczekiwań w wielu zestawach danych w potoku danych. Poniżej przedstawiono przykłady poszczególnych operatorów języka Python expect_all:
valid_pages = {"valid_count": "count > 0", "valid_current_page": "current_page_id IS NOT NULL AND current_page_title IS NOT NULL"}
@dlt.table
@dlt.expect_all(valid_pages)
def raw_data():
# Create a raw dataset
@dlt.table
@dlt.expect_all_or_drop(valid_pages)
def prepared_data():
# Create a cleaned and prepared dataset
@dlt.table
@dlt.expect_all_or_fail(valid_pages)
def customer_facing_data():
# Create cleaned and prepared to share the dataset