Konfiguracja bramy AI na punktach końcowych obsługi modelu
Z tego artykułu dowiesz się, jak skonfigurować Mosaic AI Gateway na końcowym punkcie obsługującym model.
Wymagania
- Przestrzeń robocza usługi Databricks w regionie obsługującym modele zewnętrzne lub zapewniającym przepustowość.
- Model obsługujący punkt końcowy.
- Aby utworzyć punkt końcowy dla modeli zewnętrznych, wykonaj kroki 1 i 2 Tworzenie modelu zewnętrznego obsługującego punkt końcowy.
- Aby utworzyć punkt końcowy dla przydzielonej przepustowości, zobacz API Modeli Bazowych z Przydzieloną Przepustowością.
Konfigurowanie bramy sztucznej inteligencji przy użyciu interfejsu użytkownika
W sekcji AI Gateway na stronie tworzenia punktu końcowego można indywidualnie skonfigurować jego funkcje. Zobacz Obsługiwane funkcje, aby dowiedzieć się, które funkcje są dostępne na zewnętrznych punktach końcowych obsługujących model oraz na punktach końcowych z aprowizowaną przepustowością.
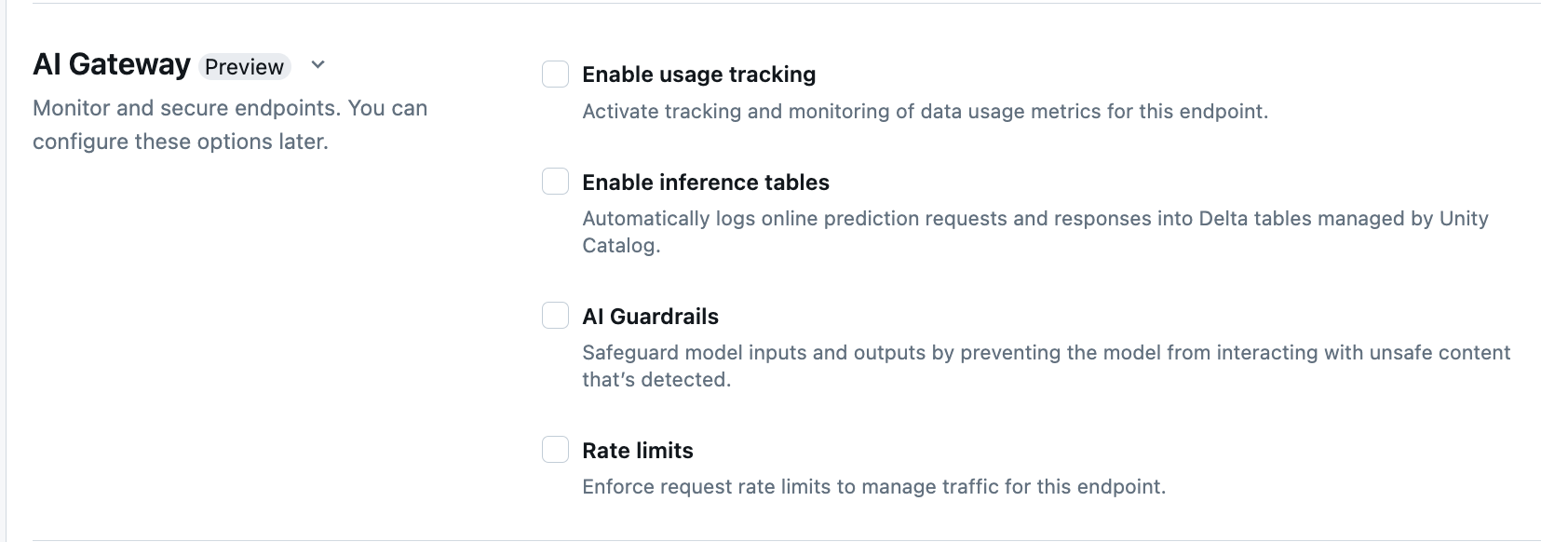
Poniższa tabela zawiera podsumowanie sposobu konfigurowania Gateway AI podczas tworzenia punktu końcowego za pomocą interfejsu obsługi. Jeśli wolisz zrobić to programowo, zobacz przykład notebooka.
| Funkcja | Jak włączyć | Szczegóły |
|---|---|---|
| Śledzenie użycia | Wybierz pozycję Włącz śledzenie użycia, aby włączyć śledzenie i monitorowanie metryk użycia danych. |
|
| Rejestrowanie danych ładunkowych | Wybierz pozycję Włącz tabele wnioskowania, aby automatycznie rejestrować żądania i odpowiedzi z punktu końcowego do tabel Delta zarządzanych przez Unity Catalog. |
|
| Zabezpieczenia sztucznej inteligencji | Zobacz Konfigurowanie barier AI Guardrails w interfejsie użytkownika. |
|
| Limity szybkości | Wybierz ograniczenia szybkości, aby egzekwować limity liczby żądań zarządzające ruchem dla danego użytkownika i punktu końcowego. |
|
| Dzielenie ruchu | W sekcji Obsługiwane jednostki określ procent ruchu, który ma być kierowany do określonych modeli. Aby programowo skonfigurować podział ruchu w punkcie końcowym, zobacz Obsługa wielu modeli zewnętrznych w punkcie końcowym. |
|
| Alternatywy | Wybierz pozycję Włącz mechanizmy awaryjne w sekcji Brama dla sztucznej inteligencji, aby wysłać żądanie do innych obsługiwanych modeli na punkcie końcowym jako mechanizm awaryjny. |
|
Na poniższym diagramie przedstawiono przykład, gdzie,
- Trzy obsługiwane jednostki są obsługiwane w punkcie końcowym obsługującym model.
- Żądanie jest pierwotnie kierowane do obsługiwanej jednostki 3.
- Jeśli żądanie zwróci odpowiedź 200, żądanie zakończyło się pomyślnie w Obsłużona jednostka 3, a żądanie i jego odpowiedź są rejestrowane w tabelach śledzenia użycia i rejestrowania ładunków punktu końcowego.
- Jeśli żądanie zwróci błąd 429 lub 5xx dla jednostki obsługiwanej 3, żądanie przechodzi do następnej obsługiwanej jednostki w punkcie końcowym, jednostki obsługiwanej 1.
- Jeśli żądanie zwróci błąd 429 lub 5xx dla Obsługiwanej jednostki 1, żądanie przejdzie do następnej obsługiwanej jednostki na punkcie końcowym, Obsługiwanej jednostki 2.
- Jeśli żądanie zwraca błąd 429 lub 5xx dla Obsługiwana jednostka 2, żądanie kończy się niepowodzeniem, ponieważ jest to maksymalna liczba jednostek zapasowych. Żądanie nie powiodło się i błąd odpowiedzi są rejestrowane w tabelach śledzenia użycia i rejestrowania ładunków.

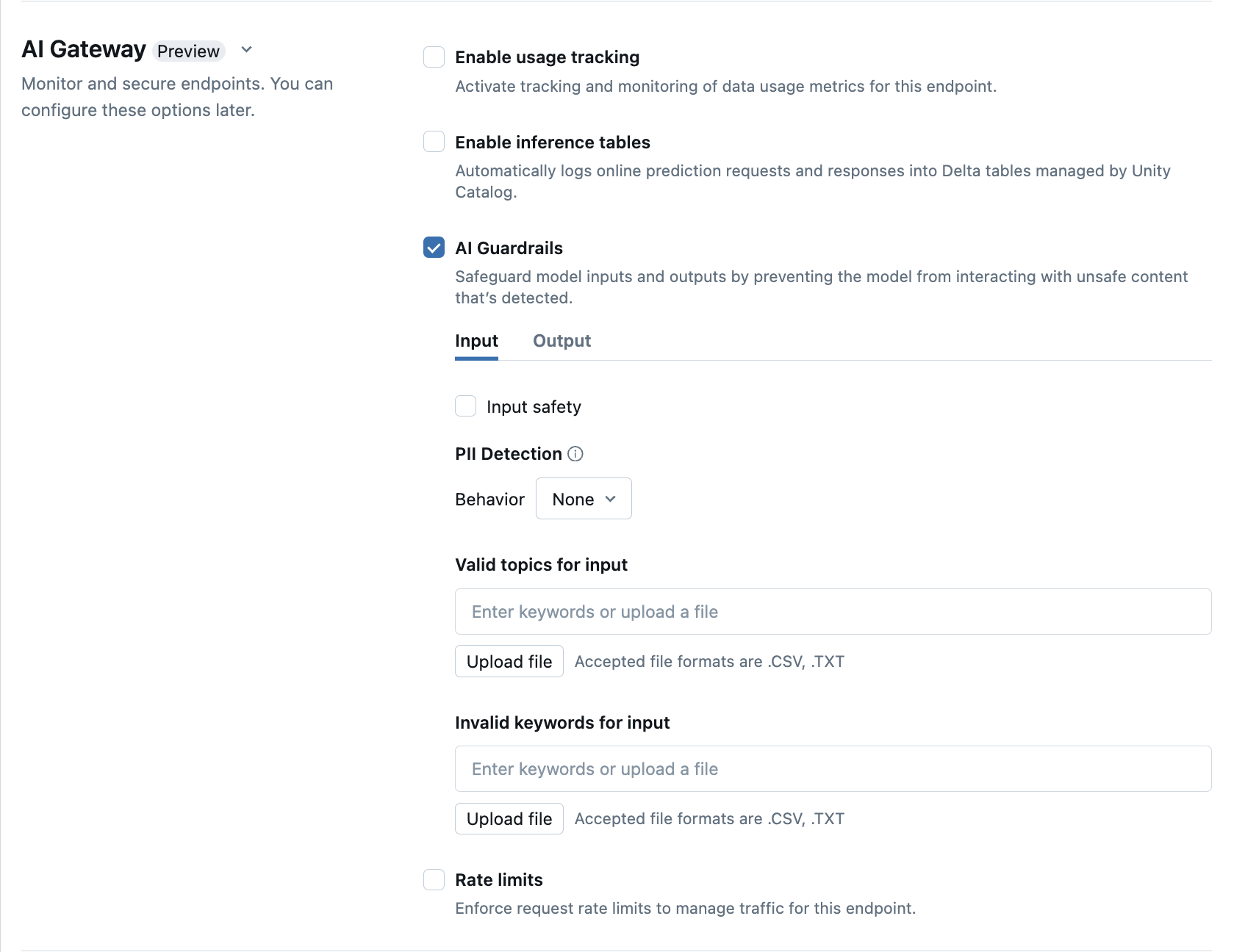
Konfigurowanie barier AI Guardrails w interfejsie użytkownika
Poniższa tabela pokazuje, jak skonfigurować obsługiwane barierki zabezpieczające .
| Poręcze | Jak włączyć | Szczegóły |
|---|---|---|
| Bezpieczeństwo | Wybierz pozycję Safety , aby umożliwić ochronę, aby uniemożliwić modelowi interakcję z niebezpieczną i szkodliwą zawartością. | |
| Wykrywanie danych osobowych | Wybierz wykrywanie PII, aby wykrywać dane osobowe, takie jak imiona, adresy, numery kart kredytowych. | |
| Prawidłowe tematy | Tematy można wpisać bezpośrednio w tym polu. Jeśli masz wiele wpisów, pamiętaj, aby nacisnąć Enter po każdym temacie. Alternatywnie możesz przekazać plik .csv lub .txt . |
Można określić maksymalnie 50 prawidłowych tematów. Każdy temat nie może przekraczać 100 znaków |
| Nieprawidłowe słowa kluczowe | Tematy można wpisać bezpośrednio w tym polu. Jeśli masz wiele wpisów, pamiętaj, aby nacisnąć Enter po każdym temacie. Alternatywnie możesz przekazać plik .csv lub .txt . |
Można określić maksymalnie 50 nieprawidłowych słów kluczowych. Każde słowo kluczowe nie może przekraczać 100 znaków. |
Schematy tabel śledzenia użycia
W poniższych sekcjach podsumowano schematy tabeli śledzenia użycia dla tabel systemu system.serving.served_entities i system.serving.endpoint_usage.
schemat tabeli śledzenia użycia system.serving.served_entities
Tabela systemu śledzenia użycia system.serving.served_entities ma następujący schemat:
| Nazwa kolumny | opis | Typ |
|---|---|---|
served_entity_id |
Unikatowy identyfikator obsługiwanej jednostki. | STRUNA |
account_id |
Identyfikator konta klienta dla Delta Sharing. | STRUNA |
workspace_id |
Identyfikator obszaru roboczego klienta punktu końcowego obsługi. | STRUNA |
created_by |
Identyfikator twórcy. | STRUNA |
endpoint_name |
Nazwa obsługującego punktu końcowego. | STRUNA |
endpoint_id |
Unikatowy identyfikator punktu końcowego obsługi. | STRUNA |
served_entity_name |
Nazwa obsługiwanej jednostki. | STRUNA |
entity_type |
Typ obsługiwanej jednostki. Może to być FEATURE_SPEC, EXTERNAL_MODEL, FOUNDATION_MODELlub CUSTOM_MODEL |
STRUNA |
entity_name |
Podstawowa nazwa jednostki. Różni się od served_entity_name, które jest nazwą podaną przez użytkownika. Na przykład entity_name jest nazwą modelu Unity Catalog. |
STRUNA |
entity_version |
Wersja obsługiwanej jednostki. | STRUNA |
endpoint_config_version |
Wersja konfiguracji punktu końcowego. | INT |
task |
Typ zadania. Może to być llm/v1/chat, llm/v1/completionslub llm/v1/embeddings. |
STRUNA |
external_model_config |
Konfiguracje modeli zewnętrznych. Na przykład {Provider: OpenAI} |
STRUKTURA |
foundation_model_config |
Konfiguracje modeli podstawowych. Na przykład{min_provisioned_throughput: 2200, max_provisioned_throughput: 4400} |
STRUKTURA |
custom_model_config |
Konfiguracje modeli niestandardowych. Na przykład{ min_concurrency: 0, max_concurrency: 4, compute_type: CPU } |
STRUCT |
feature_spec_config |
Konfiguracje specyfikacji funkcji. Na przykład { min_concurrency: 0, max_concurrency: 4, compute_type: CPU } |
STRUKTURA |
change_time |
Sygnatura czasowa zmiany dla obsługiwanej jednostki. | TIMESTAMP |
endpoint_delete_time |
Sygnatura czasowa usuwania jednostki. Punkt końcowy jest kontenerem dla obsługiwanej jednostki. Po usunięciu punktu końcowego obsługiwana jednostka zostanie również usunięta. | TIMESTAMP |
schemat tabeli monitorowania użycia system.serving.endpoint_usage
Tabela systemu śledzenia użycia system.serving.endpoint_usage ma następujący schemat:
| Nazwa kolumny | opis | Typ |
|---|---|---|
account_id |
Identyfikator konta klienta. | STRUNA |
workspace_id |
Identyfikator obszaru roboczego klienta obsługującego punkt końcowy. | STRUNA |
client_request_id |
Użytkownik podał identyfikator żądania, który można określić w treści żądania obsługującego model. | STRUNA |
databricks_request_id |
Identyfikator żądania wygenerowany przez Azure Databricks dołączony do wszystkich żądań obsługi modelu. | STRUNA |
requester |
Identyfikator użytkownika lub jednostki usługi, którego uprawnienia są wykorzystywane do żądania wywołania obsługiwanego punktu końcowego. | STRUNA |
status_code |
Kod stanu HTTP zwrócony z modelu. | LICZBA CAŁKOWITA |
request_time |
Moment otrzymania żądania. | TIMESTAMP |
input_token_count |
Liczba tokenów danych wejściowych. | DŁUGI |
output_token_count |
Liczba tokenów danych wyjściowych. | DŁUGI |
input_character_count |
Liczba znaków ciągu wejściowego lub monitu. | DŁUGI |
output_character_count |
Liczba znaków ciągu wyjściowego odpowiedzi. | DŁUGI |
usage_context |
Użytkownik podał mapę zawierającą identyfikatory użytkownika końcowego lub aplikacji klienta, która wykonuje wywołanie punktu końcowego. Zobacz Dalsze definiowanie użycia za pomocą usage_context. |
MAPA |
request_streaming |
Czy żądanie jest w trybie strumienia. | BOOLEAN |
served_entity_id |
Unikatowy identyfikator używany do łączenia z tabelą wymiarów system.serving.served_entities dla wyszukiwania informacji o punkcie docelowym i obsługiwanej jednostce. |
STRUNA |
Dalsze definiowanie użycia za pomocą polecenia usage_context
Podczas wykonywania zapytań dla modelu zewnętrznego z włączonym śledzeniem użycia można podać parametr usage_context o typie Map[String, String]. Mapowanie kontekstu użycia jest wyświetlane w tabeli śledzenia użycia w kolumnie usage_context. Rozmiar usage_context mapy nie może przekraczać 10 KiB.
Administratorzy kont mogą agregować różne wiersze na podstawie kontekstu użycia, aby uzyskać szczegółowe informacje i połączyć te informacje z informacjami w tabeli rejestrowania ładunków. Możesz na przykład dodać end_user_to_charge do usage_context w celu śledzenia przypisania kosztów dla użytkowników końcowych.
{
"messages": [
{
"role": "user",
"content": "What is Databricks?"
}
],
"max_tokens": 128,
"usage_context":
{
"use_case": "external",
"project": "project1",
"priority": "high",
"end_user_to_charge": "abcde12345",
"a_b_test_group": "group_a"
}
}
Aktualizacja funkcji AI Gateway na endpointach
Można zaktualizować funkcje bramy sztucznej inteligencji na punktach końcowych do serwowania modeli, które miały wcześniej włączone te funkcje, jak również na tych, które ich nie miały. Zastosowanie aktualizacji konfiguracji bramy sztucznej inteligencji trwa około 20–40 sekund, jednak ograniczanie szybkości aktualizacji może potrwać do 60 sekund.
Poniżej pokazano, jak zaktualizować funkcje bramy AI w punkcie końcowym obsługującym model przy użyciu interfejsu użytkownika Serving UI.
W sekcji Brama strony punktu końcowego można zobaczyć, które funkcje są włączone. Aby zaktualizować te funkcje, kliknij Edytuj bramkę AI.

Przykład notebooka
W poniższym zeszycie pokazano, jak programowo włączyć i używać funkcji bramy Databricks Mosaic AI Gateway do zarządzania i nadzorowania modeli pochodzących od dostawców. Aby uzyskać szczegółowe informacje o interfejsie API REST, zobacz PUT /api/2.0/serving-endpoints/{name}/ai-gateway.
Włącz funkcje usługi Databricks Mosaic AI Gateway
Weź notesnik