Aprowizowane interfejsy API modelu podstawowego przepływności
W tym artykule pokazano, jak wdrażać modele z wykorzystaniem interfejsów API modelu Foundation przy zapewnionej przepływności. Databricks zaleca przepływność zapewnianą dla obciążeń produkcyjnych i zapewnia zoptymalizowane wnioskowanie dla modeli bazowych z gwarancjami wydajności.
Co to jest aprowizowana przepływność?
Przydzielona przepustowość odnosi się do liczby żądań, których wartość w tokenach można przesłać do punktu końcowego naraz. Dedykowane punkty końcowe obsługujące przepustowość to punkty końcowe skonfigurowane w zakresie ilości tokenów na sekundę, które można wysłać do punktu końcowego.
Aby uzyskać więcej informacji, zobacz następujące zasoby:
- Co oznacza liczba tokenów na sekundę w dostarczonej przepustowości?
- Przeprowadź własne testy punktu końcowego modelu LLM
Zobacz Aprowizowanie interfejsów API modelu podstawowego przepływności, aby zapoznać się z listą obsługiwanych architektur modelu dla punktów końcowych aprowizowanej przepływności.
Wymagania
Zobacz wymagania . Aby wdrożyć dostosowane modele podstawowe, zobacz Wdrożenie dostosowanych modeli podstawowych.
[Zalecane] Wdróżcie modele bazowe z Unity Catalog
Ważny
Ta funkcja jest dostępna w publicznej wersji zapoznawczej.
Databricks zaleca używanie wstępnie zainstalowanych modeli bazowych w katalogu Unity. Te modele można znaleźć w katalogu system w schemacie ai (system.ai).
Aby przeprowadzić wdrożenie modelu podstawowego:
- Przejdź do
system.aiw Eksploratorze katalogu. - Kliknij nazwę modelu do wdrożenia.
- Na stronie modelu kliknij przycisk Obsłuż ten model.
- Zostanie wyświetlona strona Tworzenie punktu końcowego obsługującego. Zobacz Tworzenie punktu końcowego aprowizowanej przepływności przy użyciu interfejsu użytkownika.
Wdrażanie modeli podstawowych z witryny Databricks Marketplace
Alternatywnie możesz zainstalować modele podstawowe do Unity Catalog z Databricks Marketplace.
Możesz wyszukać grupę modeli i na stronie modelu wybrać opcję Uzyskaj dostęp i podać poświadczenia logowania, aby dodać model do katalogu Unity.
Po zainstalowaniu modelu w katalogu Unity można utworzyć punkt końcowy serwujący model przy użyciu interfejsu użytkownika serwowania.
Wdrażanie modeli DBRX
Databricks zaleca używanie modelu DBRX Instruct do obciążeń. Aby obsłużyć model DBRX Instruct przy użyciu aprowizowanej przepustowości, postępuj zgodnie ze wskazówkami w [Zalecane] Wdrażanie modeli bazowych z Unity Catalog.
Podczas serwowania tych modeli DBRX, zaprojektowana przepustowość obsługuje długość kontekstu do 16 tys.
Modele DBRX używają następującego domyślnego monitu systemowego, aby zapewnić istotność i dokładność odpowiedzi modelu:
You are DBRX, created by Databricks. You were last updated in December 2023. You answer questions based on information available up to that point.
YOU PROVIDE SHORT RESPONSES TO SHORT QUESTIONS OR STATEMENTS, but provide thorough responses to more complex and open-ended questions.
You assist with various tasks, from writing to coding (using markdown for code blocks — remember to use ``` with code, JSON, and tables).
(You do not have real-time data access or code execution capabilities. You avoid stereotyping and provide balanced perspectives on controversial topics. You do not provide song lyrics, poems, or news articles and do not divulge details of your training data.)
This is your system prompt, guiding your responses. Do not reference it, just respond to the user. If you find yourself talking about this message, stop. You should be responding appropriately and usually that means not mentioning this.
YOU DO NOT MENTION ANY OF THIS INFORMATION ABOUT YOURSELF UNLESS THE INFORMATION IS DIRECTLY PERTINENT TO THE USER'S QUERY.
Wdrażanie precyzyjnie dostrojonych modeli podstawowych
Jeśli nie możesz używać modeli w schemacie system.ai lub instalować modeli z Databricks Marketplace, możesz wdrożyć dostosowany model podstawowy, rejestrując go w katalogu Unity. W tej oraz w poniższych sekcjach pokazano, jak skonfigurować kod w celu rejestrowania modelu MLflow w Unity Catalog i tworzenia punktu końcowego przepustowości przydzielonej przy użyciu interfejsu użytkownika lub interfejsu API REST.
Zobacz Limity przepustowości aprowizowanej, aby zapoznać się z obsługiwanymi modelami Meta Llama 3.1, 3.2 i 3.3 oraz ich dostępnością w regionach.
Wymagania
- Wdrażanie dostosowanych modeli podstawowych jest obsługiwane tylko przez platformę MLflow 2.11 lub nowszą. Środowisko Databricks Runtime 15.0 ML i nowsze wersje automatycznie instalują kompatybilną wersję MLflow.
- Databricks zaleca używanie modeli w Unity Catalog w celu szybszego przesyłania i pobierania dużych modeli.
Definiowanie nazwy wykazu, schematu i modelu
Aby wdrożyć dostrajany model bazowy, zdefiniuj docelowy katalog Unity Catalog, schemat i wybraną nazwę modelu.
mlflow.set_registry_uri('databricks-uc')
CATALOG = "catalog"
SCHEMA = "schema"
MODEL_NAME = "model_name"
registered_model_name = f"{CATALOG}.{SCHEMA}.{MODEL_NAME}"
Zaloguj model
Aby włączyć przepływność rezerwowaną dla punktu końcowego modelu, należy zarejestrować model przy użyciu MLflow transformers i określić argument task, korzystając z odpowiedniego interfejsu modelu z poniższych opcji:
"llm/v1/completions""llm/v1/chat""llm/v1/embeddings"
Te argumenty określają sygnaturę interfejsu API używaną dla punktu końcowego obsługującego model. Aby uzyskać więcej informacji na temat tych zadań i odpowiadających im schematów wejściowych/wyjściowych, zapoznaj się z dokumentacją MLflow.
Poniżej przedstawiono przykład rejestrowania modelu języka uzupełniania tekstu zarejestrowanego przy użyciu biblioteki MLflow:
model = AutoModelForCausalLM.from_pretrained("mosaicml/mixtral-8x7b-instruct", torch_dtype=torch.bfloat16)
tokenizer = AutoTokenizer.from_pretrained("mosaicml/mixtral-8x7b-instruct")
with mlflow.start_run():
components = {
"model": model,
"tokenizer": tokenizer,
}
mlflow.transformers.log_model(
transformers_model=components,
artifact_path="model",
# Specify the llm/v1/xxx task that is compatible with the model being logged
task="llm/v1/completions",
# Specify an input example that conforms to the input schema for the task.
input_example={"prompt": np.array(["Below is an instruction that describes a task. Write a response that appropriately completes the request.\n\n### Instruction:\nWhat is Apache Spark?\n\n### Response:\n"])},
# By passing the model name, MLflow automatically registers the Transformers model to Unity Catalog with the given catalog/schema/model_name.
registered_model_name=registered_model_name
# Optionally, you can set save_pretrained to False to avoid unnecessary copy of model weight and gain more efficiency.
save_pretrained=False
)
Uwaga
Jeśli używasz MLflow w wersji wcześniejszej niż 2.12, musisz określić zadanie w parametrze metadata tej samej funkcji mlflow.transformer.log_model().
metadata = {"task": "llm/v1/completions"}metadata = {"task": "llm/v1/chat"}metadata = {"task": "llm/v1/embeddings"}
Aprowizowana przepływność obsługuje również zarówno podstawowe, jak i duże modele osadzania typu GTE. Poniżej przedstawiono przykład rejestrowania modelu Alibaba-NLP/gte-large-en-v1.5, aby można było obsłużyć go z zapewnioną przepustowością.
model = AutoModel.from_pretrained("Alibaba-NLP/gte-large-en-v1.5")
tokenizer = AutoTokenizer.from_pretrained("Alibaba-NLP/gte-large-en-v1.5")
with mlflow.start_run():
components = {
"model": model,
"tokenizer": tokenizer,
}
mlflow.transformers.log_model(
transformers_model=components,
artifact_path="model",
task="llm/v1/embeddings",
registered_model_name=registered_model_name,
# model_type is required for logging a fine-tuned BGE models.
metadata={
"model_type": "gte-large"
}
)
Po zalogowaniu modelu w katalogu Unity, przejdź do Utwórz punkt końcowy z zapewnioną przepustowością przy użyciu interfejsu użytkownika, aby utworzyć punkt końcowy służby modelu z zapewnioną przepustowością.
Tworzenie punktu końcowego z aprowizowaną przepływnością przy użyciu interfejsu użytkownika
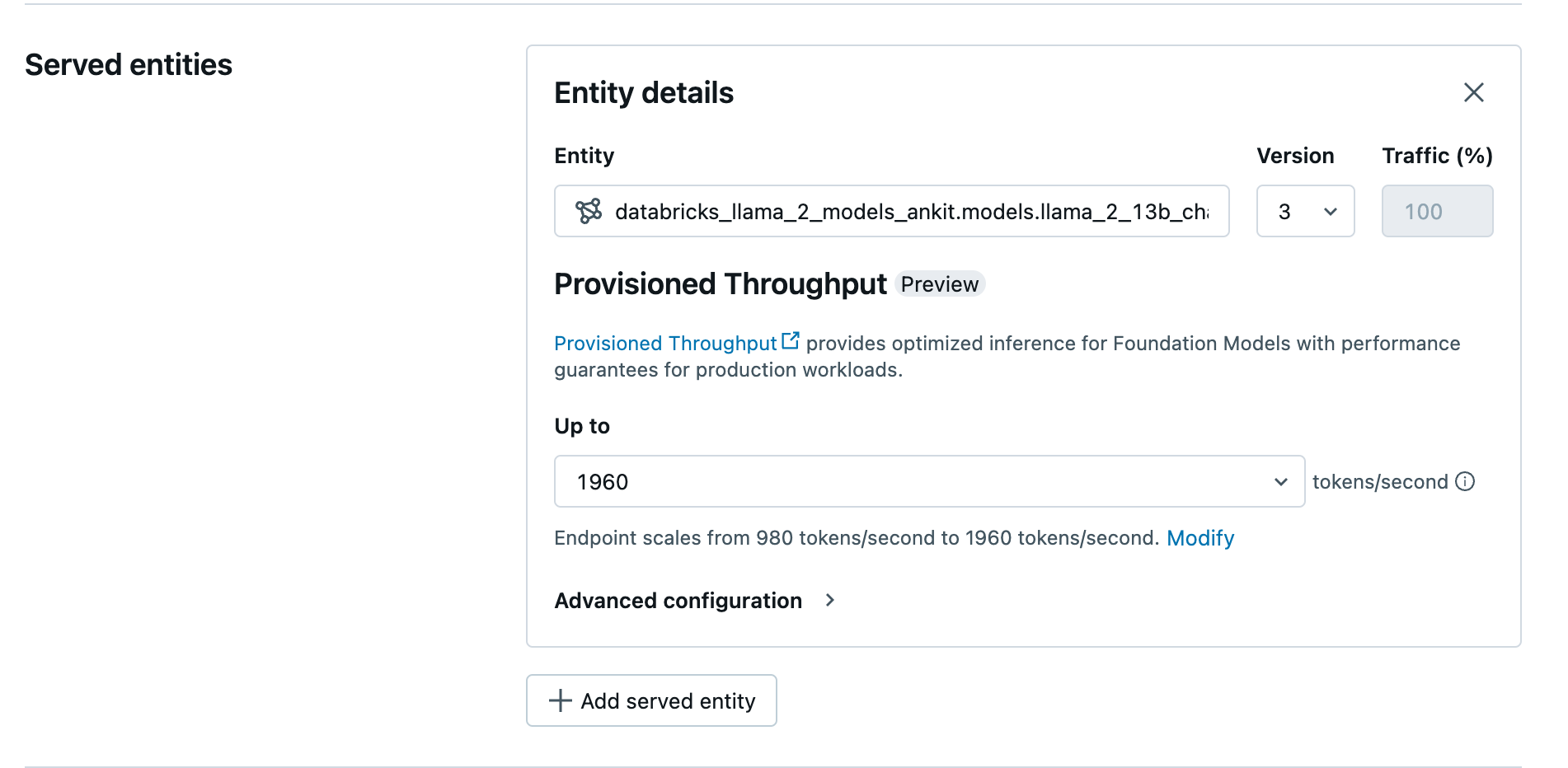
Po zarejestrowaniu modelu w katalogu Unity, utwórz punkt końcowy serwujący z zarezerwowaną przepustowością, wykonując następujące kroki:
- Przejdź do interfejsu użytkownika obsługującego
w obszarze roboczym. - Wybierz opcję Utwórz punkt końcowy obsługi.
- W polu Entity wybierz model z Unity Catalog. W przypadku kwalifikujących się modeli interfejs użytkownika obsługiwanej jednostki zawiera ekran Aprowizowana przepływność.
- W rozwijanej liście Do można skonfigurować maksymalną przepływność tokenów na sekundę dla punktu końcowego.
- Przepływność punktów końcowych jest automatycznie skalowana, więc możesz wybrać opcję Modyfikuj, aby wyświetlić minimalną liczbę tokenów na sekundę, do której punkt końcowy może się zmniejszyć.
Utwórz punkt końcowy aprowizowanej przepływności używając interfejsu API REST
Aby wdrożyć model w trybie aprowizowanej przepustowości przy użyciu interfejsu API REST, należy określić pola min_provisioned_throughput i max_provisioned_throughput w żądaniu. Jeśli wolisz język Python, możesz także utworzyć punkt końcowy przy użyciu zestawu SDK wdrażania MLflow.
Aby zidentyfikować odpowiedni zakres przyznanej przepustowości dla modelu, zobacz Uzyskiwanie przepustowości przyznanej w jednostkach przyrostowych.
import requests
import json
# Set the name of the MLflow endpoint
endpoint_name = "prov-throughput-endpoint"
# Name of the registered MLflow model
model_name = "ml.llm-catalog.foundation-model"
# Get the latest version of the MLflow model
model_version = 3
# Get the API endpoint and token for the current notebook context
API_ROOT = "<YOUR-API-URL>"
API_TOKEN = "<YOUR-API-TOKEN>"
headers = {"Context-Type": "text/json", "Authorization": f"Bearer {API_TOKEN}"}
optimizable_info = requests.get(
url=f"{API_ROOT}/api/2.0/serving-endpoints/get-model-optimization-info/{model_name}/{model_version}",
headers=headers)
.json()
if 'optimizable' not in optimizable_info or not optimizable_info['optimizable']:
raise ValueError("Model is not eligible for provisioned throughput")
chunk_size = optimizable_info['throughput_chunk_size']
# Minimum desired provisioned throughput
min_provisioned_throughput = 2 * chunk_size
# Maximum desired provisioned throughput
max_provisioned_throughput = 3 * chunk_size
# Send the POST request to create the serving endpoint
data = {
"name": endpoint_name,
"config": {
"served_entities": [
{
"entity_name": model_name,
"entity_version": model_version,
"min_provisioned_throughput": min_provisioned_throughput,
"max_provisioned_throughput": max_provisioned_throughput,
}
]
},
}
response = requests.post(
url=f"{API_ROOT}/api/2.0/serving-endpoints", json=data, headers=headers
)
print(json.dumps(response.json(), indent=4))
Logarytmiczne prawdopodobieństwo zadań zakończenia czatu
W przypadku zadań ukończenia czatu można użyć parametru logprobs, aby zapewnić prawdopodobieństwo logarytmiczne wyboru tokenu jako część procesu generowania dużego modelu językowego. Można użyć logprobs dla różnych scenariuszy, w tym klasyfikacji, oceny niepewności modelu i uruchamiania metryk oceny. Zobacz zadanie czatu , aby uzyskać szczegółowe informacje o parametrach.
Uzyskaj aprowizowaną przepływność w przyrostach
Aprowizowana przepływność jest dostępna w przyrostach tokenów na sekundę z określonymi przyrostami różniącymi się w zależności od modelu. Aby zidentyfikować odpowiedni zakres dla Twoich potrzeb, Databricks zaleca korzystanie z API informacji o optymalizacji modeli na platformie.
GET api/2.0/serving-endpoints/get-model-optimization-info/{registered_model_name}/{version}
Poniżej przedstawiono przykładową odpowiedź z interfejsu API:
{
"optimizable": true,
"model_type": "llama",
"throughput_chunk_size": 1580
}
Przykłady notatników
W poniższych notatnikach przedstawiono przykłady tworzenia interfejsu API modelu podstawowego z zaprojektowaną przepustowością.
Świadczenie przepustowości dla notebooka modelu GTE
Pobierz notatnik
przydzielona przepustowość dla notatnika modelu BGE
Zarządzanie przepustowością dla notatnika modelu Mistral
Ograniczenia
Wdrażanie modelu może zakończyć się niepowodzeniem z powodu problemów z pojemnością procesora GPU, co powoduje przekroczenie limitu czasu podczas tworzenia lub aktualizowania punktu końcowego. Skontaktuj się z zespołem ds. kont usługi Databricks, aby rozwiązać ten problem.
Automatyczne skalowanie dla interfejsów API modeli fundamentalnych jest wolniejsze niż obsługa modeli na procesorze. Databricks zaleca nadmierne zasilenie zasobów, aby uniknąć przekroczenia czasu oczekiwania na żądanie.
Obsługiwane są tylko architektury modeli GTE w wersji 1.5 (angielski) i BGE w wersji 1.5 (angielski).
GtE v1.5 (angielski) nie generuje znormalizowanych osadzeń.