Wdrażanie obciążenia usługi IoT Edge przy użyciu udostępniania procesora GPU w usłudze Azure Stack Edge Pro
W tym artykule opisano, jak konteneryzowane obciążenia mogą współużytkować procesory GPU na urządzeniu z procesorem GPU usługi Azure Stack Edge Pro. Podejście polega na włączeniu usługi wieloprocesowej (MPS), a następnie określeniu obciążeń procesora GPU za pośrednictwem wdrożenia usługi IoT Edge.
Wymagania wstępne
Przed rozpoczęciem upewnij się, że:
Masz dostęp do urządzenia gpu Pro usługi Azure Stack Edge, które jest aktywowane i ma skonfigurowane zasoby obliczeniowe. Masz punkt końcowy interfejsu API platformy Kubernetes i dodano ten punkt końcowy do pliku na kliencie, który będzie uzyskiwać dostęp do
hostsurządzenia.Masz dostęp do systemu klienckiego z obsługiwanym systemem operacyjnym. W przypadku korzystania z klienta systemu Windows system powinien uruchomić program PowerShell 5.0 lub nowszy, aby uzyskać dostęp do urządzenia.
Zapisz następujące wdrożenie
jsonw systemie lokalnym. Użyjesz informacji z tego pliku, aby uruchomić wdrożenie usługi IoT Edge. To wdrożenie jest oparte na prostych kontenerach CUDA, które są publicznie dostępne w firmie NVIDIA.{ "modulesContent": { "$edgeAgent": { "properties.desired": { "modules": { "cuda-sample1": { "settings": { "image": "nvidia/samples:nbody", "createOptions": "{\"Entrypoint\":[\"/bin/sh\"],\"Cmd\":[\"-c\",\"/tmp/nbody -benchmark -i=1000; while true; do echo no-op; sleep 10000;done\"],\"HostConfig\":{\"IpcMode\":\"host\",\"PidMode\":\"host\"}}" }, "type": "docker", "version": "1.0", "env": { "NVIDIA_VISIBLE_DEVICES": { "value": "0" } }, "status": "running", "restartPolicy": "never" }, "cuda-sample2": { "settings": { "image": "nvidia/samples:nbody", "createOptions": "{\"Entrypoint\":[\"/bin/sh\"],\"Cmd\":[\"-c\",\"/tmp/nbody -benchmark -i=1000; while true; do echo no-op; sleep 10000;done\"],\"HostConfig\":{\"IpcMode\":\"host\",\"PidMode\":\"host\"}}" }, "type": "docker", "version": "1.0", "env": { "NVIDIA_VISIBLE_DEVICES": { "value": "0" } }, "status": "running", "restartPolicy": "never" } }, "runtime": { "settings": { "minDockerVersion": "v1.25" }, "type": "docker" }, "schemaVersion": "1.1", "systemModules": { "edgeAgent": { "settings": { "image": "mcr.microsoft.com/azureiotedge-agent:1.0", "createOptions": "" }, "type": "docker" }, "edgeHub": { "settings": { "image": "mcr.microsoft.com/azureiotedge-hub:1.0", "createOptions": "{\"HostConfig\":{\"PortBindings\":{\"443/tcp\":[{\"HostPort\":\"443\"}],\"5671/tcp\":[{\"HostPort\":\"5671\"}],\"8883/tcp\":[{\"HostPort\":\"8883\"}]}}}" }, "type": "docker", "status": "running", "restartPolicy": "always" } } } }, "$edgeHub": { "properties.desired": { "routes": { "route": "FROM /messages/* INTO $upstream" }, "schemaVersion": "1.1", "storeAndForwardConfiguration": { "timeToLiveSecs": 7200 } } }, "cuda-sample1": { "properties.desired": {} }, "cuda-sample2": { "properties.desired": {} } } }
Weryfikowanie sterownika procesora GPU, wersja CUDA
Pierwszym krokiem jest sprawdzenie, czy na urządzeniu jest uruchomiony wymagany sterownik procesora GPU i wersje CUDA.
Uruchom następujące polecenie:
Get-HcsGpuNvidiaSmiW danych wyjściowych firmy NVIDIA zanotuj wersję procesora GPU i wersję CUDA na urządzeniu. Jeśli korzystasz z oprogramowania Azure Stack Edge 2102, ta wersja będzie odpowiadać następującym wersjom sterowników:
- Wersja sterownika procesora GPU: 460.32.03
- WERSJA CUDA: 11.2
Oto przykładowe dane wyjściowe:
[10.100.10.10]: PS>Get-HcsGpuNvidiaSmi K8S-1HXQG13CL-1HXQG13: Tue Feb 23 10:34:01 2021 +-----------------------------------------------------------------------------+ | NVIDIA-SMI 460.32.03 Driver Version: 460.32.03 CUDA Version: 11.2 | |-------------------------------+----------------------+----------------------+ | GPU Name Persistence-M| Bus-Id Disp.A | Volatile Uncorr. ECC | | Fan Temp Perf Pwr:Usage/Cap| Memory-Usage | GPU-Util Compute M. | | | | MIG M. | |===============================+======================+======================| | 0 Tesla T4 On | 0000041F:00:00.0 Off | 0 | | N/A 40C P8 15W / 70W | 0MiB / 15109MiB | 0% Default | | | | N/A | +-------------------------------+----------------------+----------------------+ +-----------------------------------------------------------------------------+ | Processes: | | GPU GI CI PID Type Process name GPU Memory | | ID ID Usage | |=============================================================================| | No running processes found | +-----------------------------------------------------------------------------+ [10.100.10.10]: PS>Pozostaw tę sesję otwartą, ponieważ będzie ona używana do wyświetlania danych wyjściowych smi firmy NVIDIA w całym artykule.
Wdrażanie bez udostępniania kontekstu
Teraz możesz wdrożyć aplikację na urządzeniu, gdy usługa wieloprocesowa nie jest uruchomiona i nie ma udostępniania kontekstu. Wdrożenie odbywa się za pośrednictwem witryny Azure Portal w iotedge przestrzeni nazw, która istnieje na urządzeniu.
Tworzenie użytkownika w przestrzeni nazw usługi IoT Edge
Najpierw utworzysz użytkownika, który połączy się z przestrzenią iotedge nazw. Moduły usługi IoT Edge są wdrażane w przestrzeni nazw iotedge. Aby uzyskać więcej informacji, zobacz Kubernetes namespaces on your device (Przestrzenie nazw kubernetes na urządzeniu).
Wykonaj następujące kroki, aby utworzyć użytkownika i przyznać użytkownikowi iotedge dostęp do przestrzeni nazw.
Utwórz nowego użytkownika w
iotedgeprzestrzeni nazw. Uruchom następujące polecenie:New-HcsKubernetesUser -UserName <user name>Oto przykładowe dane wyjściowe:
[10.100.10.10]: PS>New-HcsKubernetesUser -UserName iotedgeuser apiVersion: v1 clusters: - cluster: certificate-authority-data: ===========================//snipped //======================// snipped //============================= server: https://compute.myasegpudev.wdshcsso.com:6443 name: kubernetes contexts: - context: cluster: kubernetes user: iotedgeuser name: iotedgeuser@kubernetes current-context: iotedgeuser@kubernetes kind: Config preferences: {} users: - name: iotedgeuser user: client-certificate-data: ===========================//snipped //======================// snipped //============================= client-key-data: ===========================//snipped //======================// snipped ============================ PQotLS0tLUVORCBSU0EgUFJJVkFURSBLRVktLS0tLQo=Skopiuj dane wyjściowe wyświetlane w postaci zwykłego tekstu. Zapisz dane wyjściowe jako plik konfiguracji (bez rozszerzenia) w
.kubefolderze profilu użytkownika na komputerze lokalnym, na przykładC:\Users\<username>\.kube.Udziel utworzonemu
iotedgeużytkownikowi dostępu do przestrzeni nazw. Uruchom następujące polecenie:Grant-HcsKubernetesNamespaceAccess -Namespace iotedge -UserName <user name>Oto przykładowe dane wyjściowe:
[10.100.10.10]: PS>Grant-HcsKubernetesNamespaceAccess -Namespace iotedge -UserName iotedgeuser [10.100.10.10]: PS>
Aby uzyskać szczegółowe instrukcje, zobacz Nawiązywanie połączenia z klastrem Kubernetes i zarządzanie nim za pośrednictwem narzędzia kubectl na urządzeniu gpu Azure Stack Edge Pro.
Wdrażanie modułów za pośrednictwem portalu
Wdrażanie modułów usługi IoT Edge za pośrednictwem witryny Azure Portal. Wdrożysz publicznie dostępne przykładowe moduły NVIDIA CUDA, które uruchamiają symulację n-body.
Upewnij się, że usługa IoT Edge jest uruchomiona na urządzeniu.
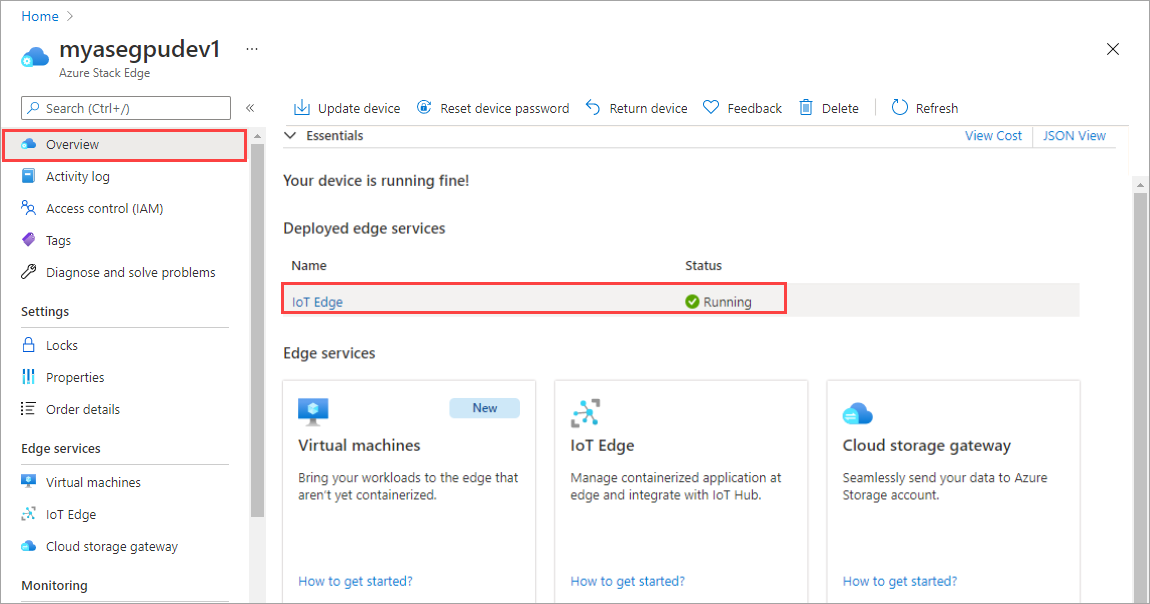
Wybierz kafelek usługi IoT Edge w okienku po prawej stronie. Przejdź do pozycji Właściwości usługi IoT Edge>. W okienku po prawej stronie wybierz zasób usługi IoT Hub skojarzony z urządzeniem.
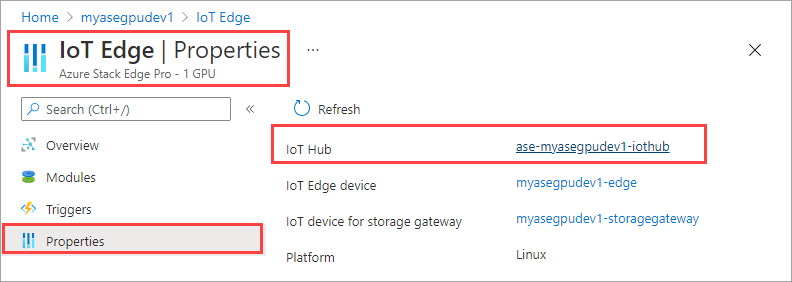
W zasobie usługi IoT Hub przejdź do pozycji Automatyczne Zarządzanie urządzeniami > usługi IoT Edge. W okienku po prawej stronie wybierz urządzenie usługi IoT Edge skojarzone z urządzeniem.
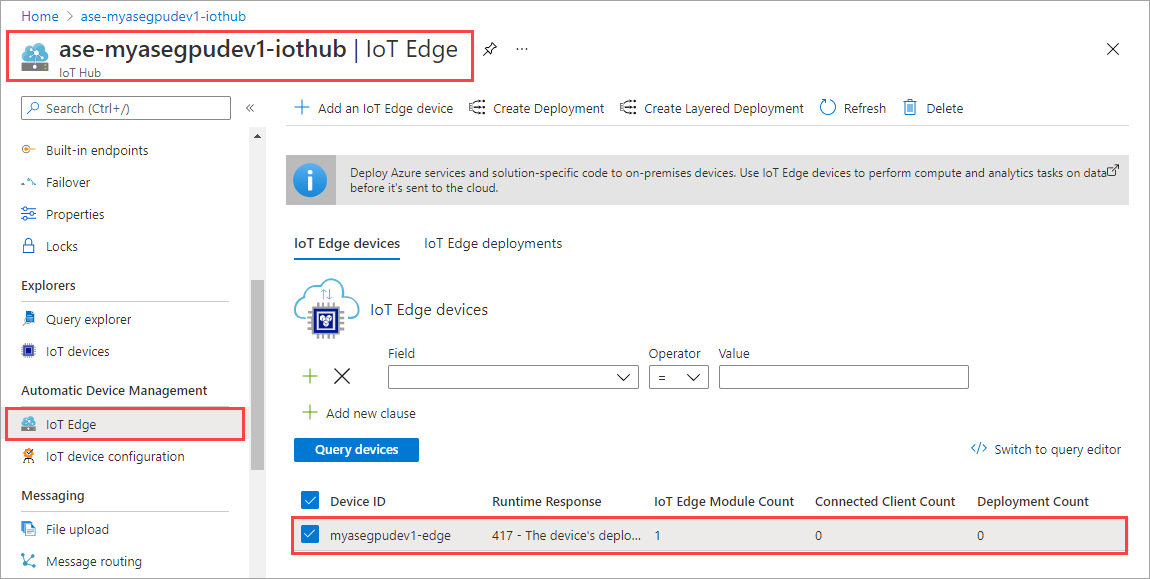
Wybierz opcję Ustaw moduły.
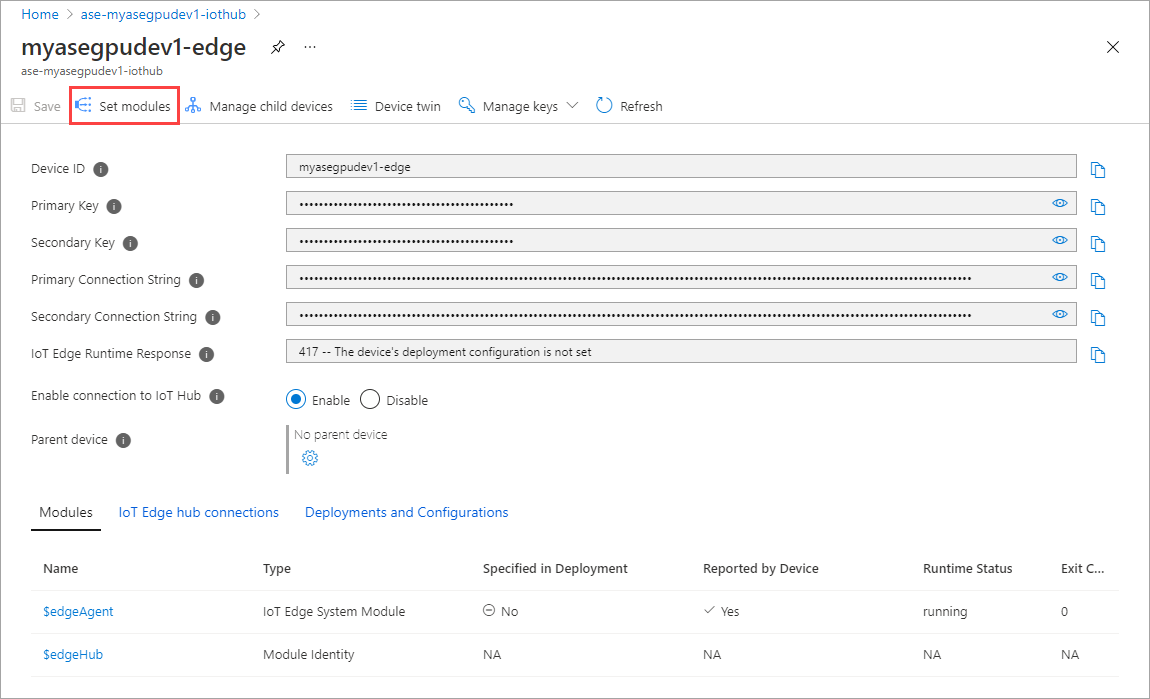
Wybierz pozycję + Dodaj > + Moduł usługi IoT Edge.
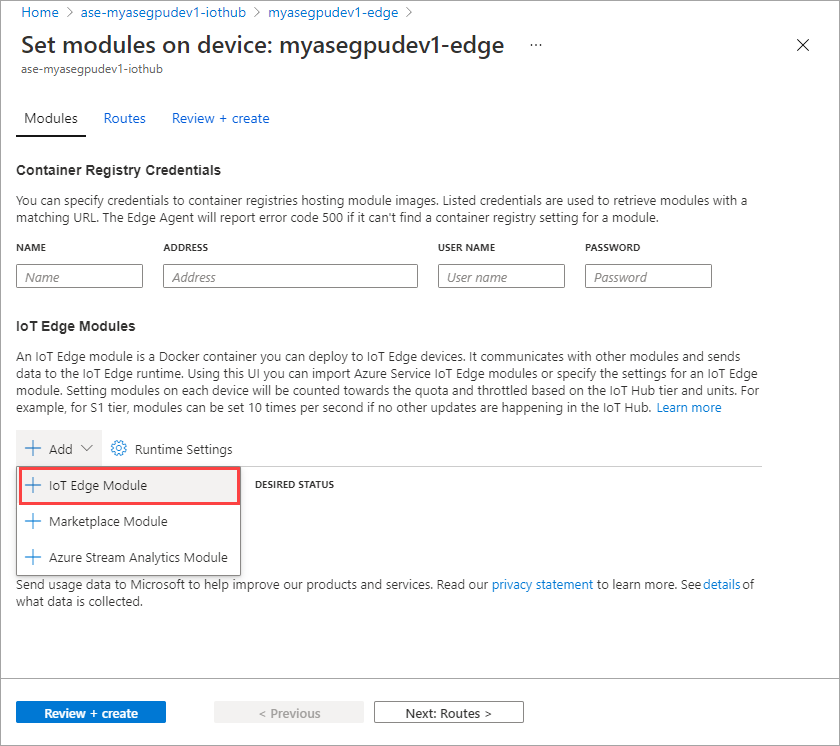
Na karcie Ustawienia modułu podaj nazwę modułu usługi IoT Edge i identyfikator URI obrazu. Ustaw zasady ściągania obrazów na wartość Wł. utwórz.
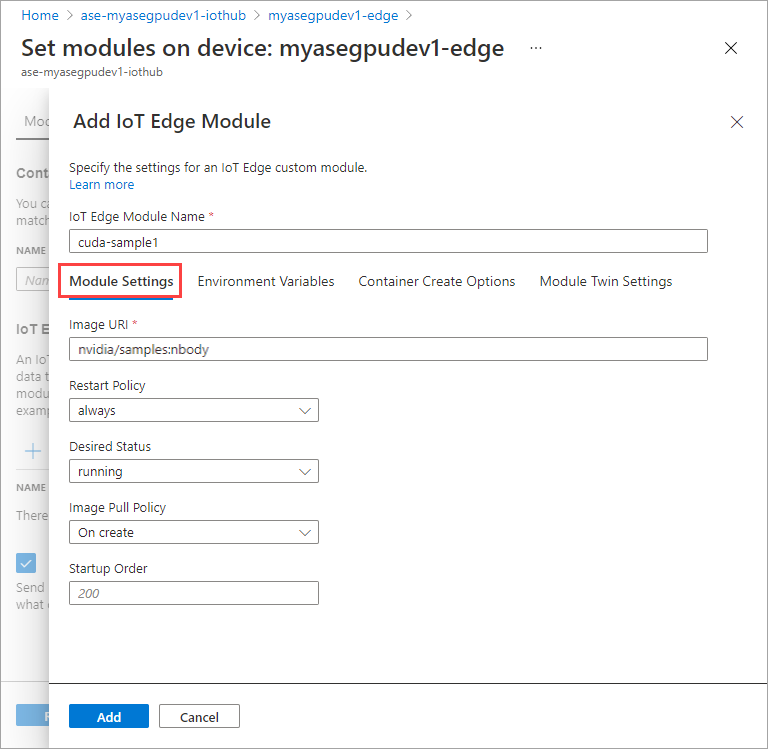
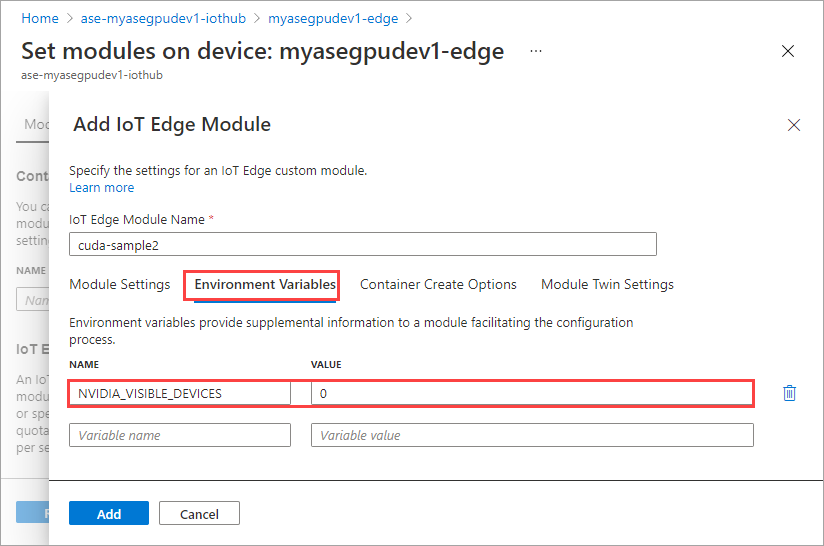
Na karcie Zmienne środowiskowe określ NVIDIA_VISIBLE_DEVICES jako 0.
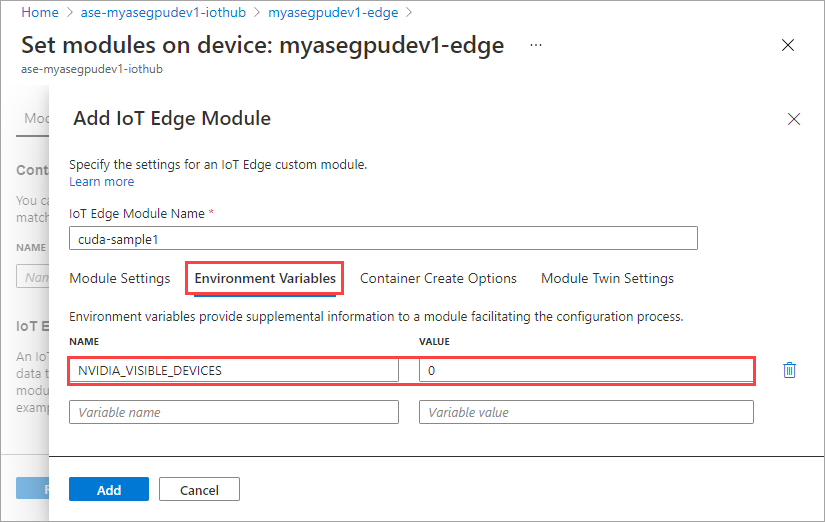
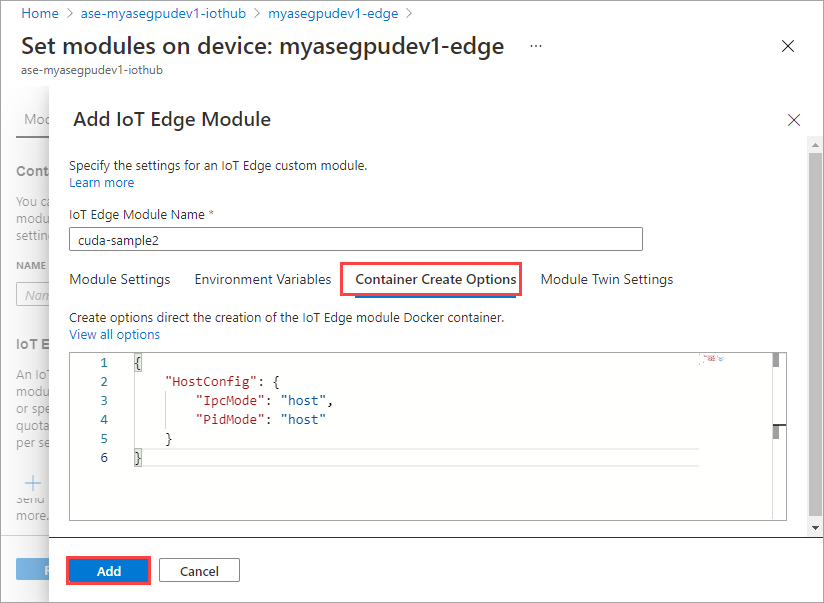
Na karcie Opcje tworzenia kontenera podaj następujące opcje:
{ "Entrypoint": [ "/bin/sh" ], "Cmd": [ "-c", "/tmp/nbody -benchmark -i=1000; while true; do echo no-op; sleep 10000;done" ], "HostConfig": { "IpcMode": "host", "PidMode": "host" } }Opcje są wyświetlane w następujący sposób:
Wybierz Dodaj.
Dodany moduł powinien być wyświetlany jako Uruchomiony.
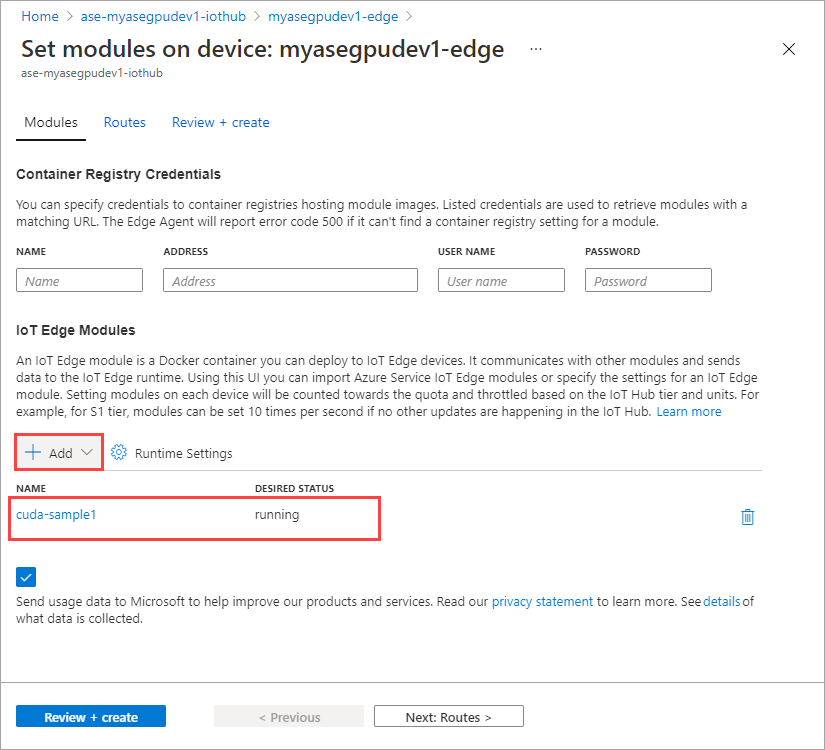
Powtórz wszystkie kroki, aby dodać moduł, który wykonano podczas dodawania pierwszego modułu. W tym przykładzie podaj nazwę modułu jako
cuda-sample2.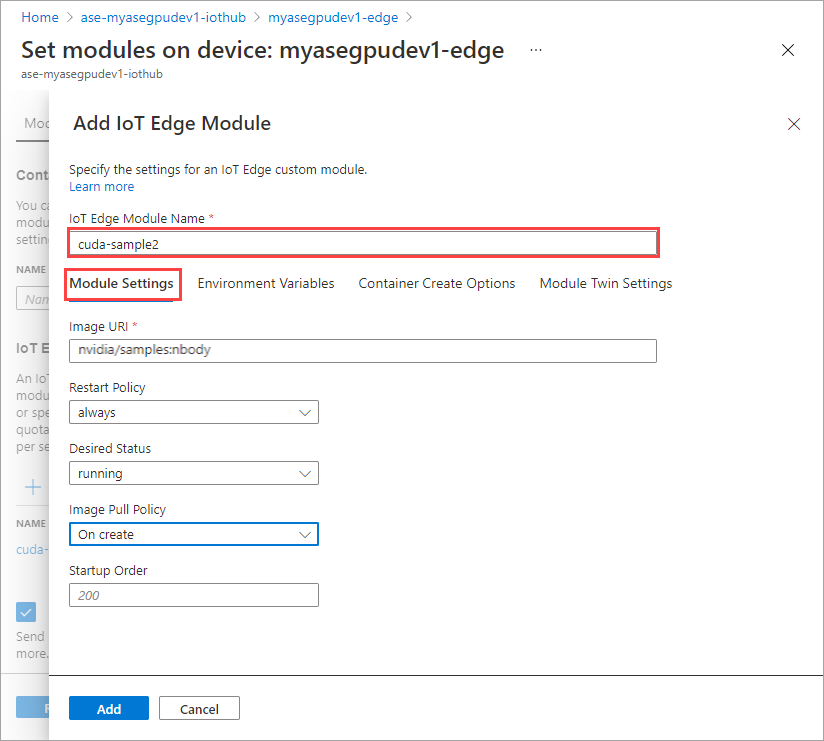
Użyj tej samej zmiennej środowiskowej, co oba moduły będą współdzielić ten sam procesor GPU.
Użyj tych samych opcji tworzenia kontenera podanych dla pierwszego modułu i wybierz pozycję Dodaj.
Na stronie Ustawianie modułów wybierz pozycję Przejrzyj i utwórz , a następnie wybierz pozycję Utwórz.
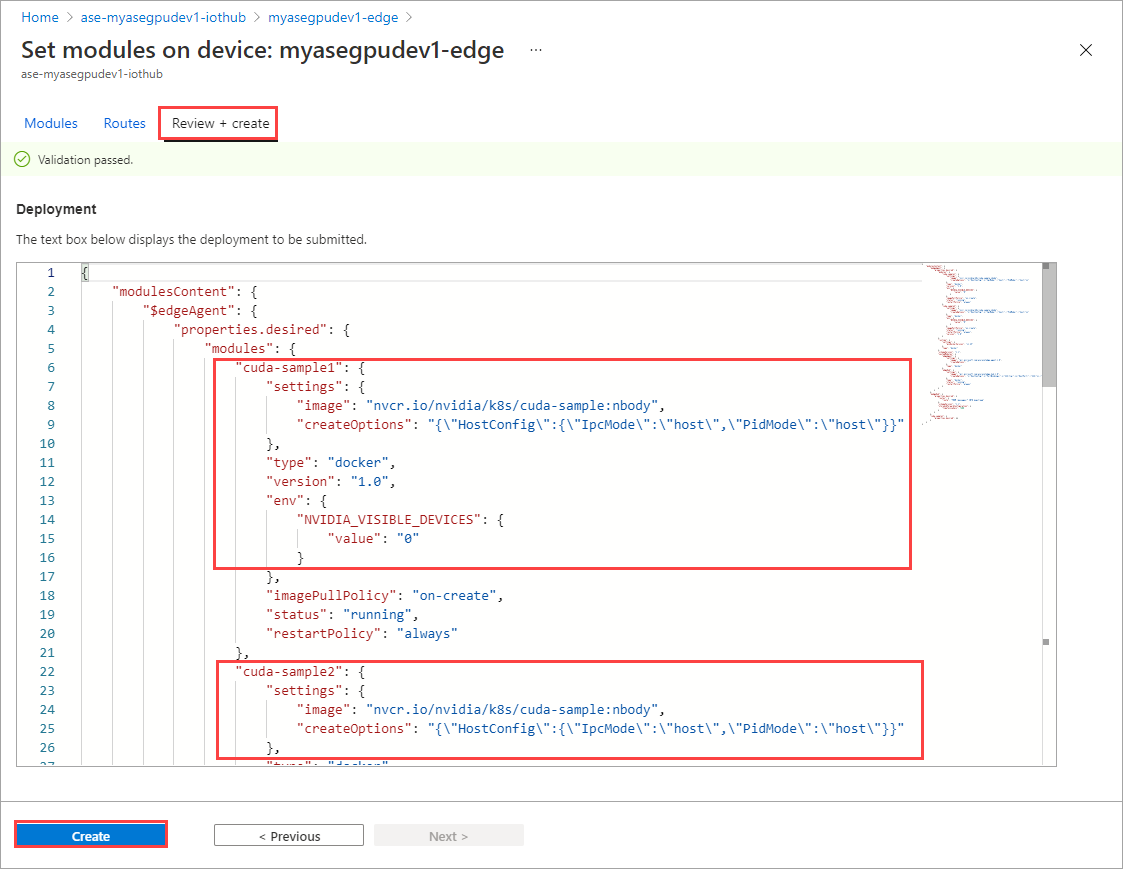
Stan środowiska uruchomieniowego obu modułów powinien teraz być wyświetlany jako Uruchomione.
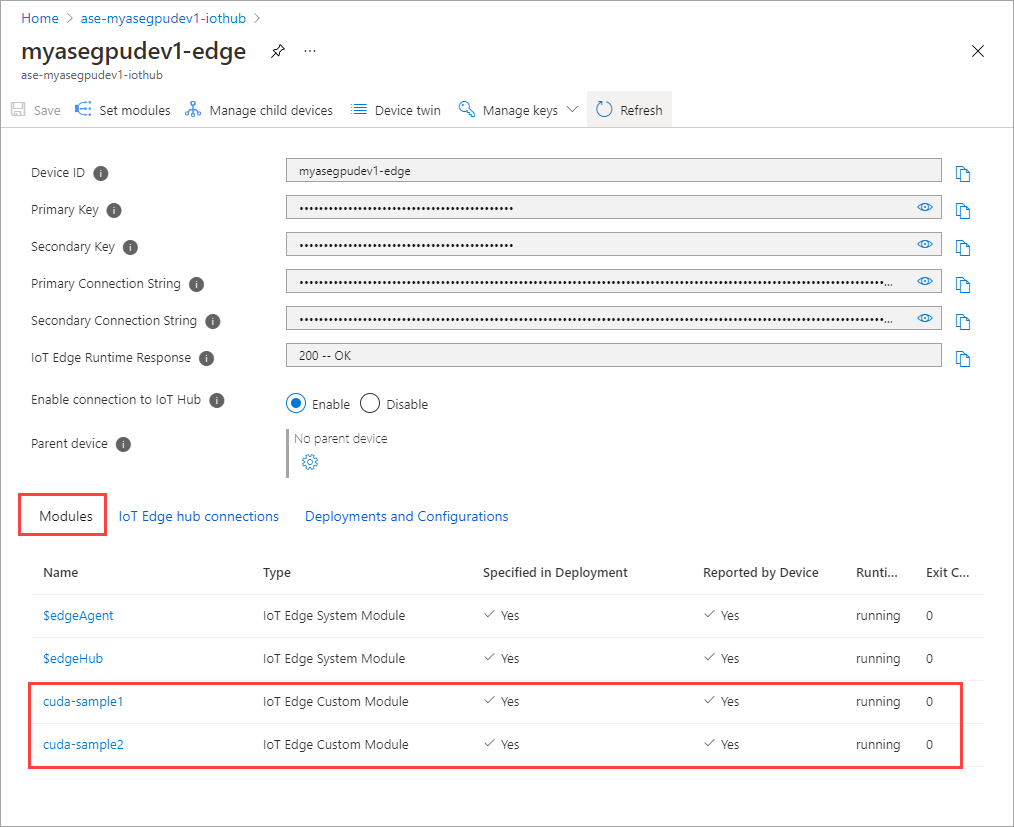
Monitorowanie wdrożenia obciążenia
Otwórz nową sesję programu PowerShell.
Wyświetl listę zasobników uruchomionych w
iotedgeprzestrzeni nazw. Uruchom następujące polecenie:kubectl get pods -n iotedgeOto przykładowe dane wyjściowe:
PS C:\WINDOWS\system32> kubectl get pods -n iotedge --kubeconfig C:\GPU-sharing\kubeconfigs\configiotuser1 NAME READY STATUS RESTARTS AGE cuda-sample1-869989578c-ssng8 2/2 Running 0 5s cuda-sample2-6db6d98689-d74kb 2/2 Running 0 4s edgeagent-79f988968b-7p2tv 2/2 Running 0 6d21h edgehub-d6c764847-l8v4m 2/2 Running 0 24h iotedged-55fdb7b5c6-l9zn8 1/1 Running 1 6d21h PS C:\WINDOWS\system32>Na urządzeniu znajdują się dwa zasobniki i
cuda-sample1-97c494d7f-lnmnscuda-sample2-d9f6c4688-2rld9uruchomione.Chociaż oba kontenery uruchamiają symulację n-body, wyświetl wykorzystanie procesora GPU z danych wyjściowych smi firmy NVIDIA. Przejdź do interfejsu programu PowerShell urządzenia i uruchom polecenie
Get-HcsGpuNvidiaSmi.Oto przykładowe dane wyjściowe, gdy oba kontenery uruchamiają symulację n-treści:
[10.100.10.10]: PS>Get-HcsGpuNvidiaSmi K8S-1HXQG13CL-1HXQG13: Fri Mar 5 13:31:16 2021 +-----------------------------------------------------------------------------+ | NVIDIA-SMI 460.32.03 Driver Version: 460.32.03 CUDA Version: 11.2 | |-------------------------------+----------------------+----------------------+ | GPU Name Persistence-M| Bus-Id Disp.A | Volatile Uncorr. ECC | | Fan Temp Perf Pwr:Usage/Cap| Memory-Usage | GPU-Util Compute M. | | | | MIG M. | |===============================+======================+======================| | 0 Tesla T4 On | 00002C74:00:00.0 Off | 0 | | N/A 52C P0 69W / 70W | 221MiB / 15109MiB | 100% Default | | | | N/A | +-------------------------------+----------------------+----------------------+ +-----------------------------------------------------------------------------+ | Processes: | | GPU GI CI PID Type Process name GPU Memory | | ID ID Usage | |=============================================================================| | 0 N/A N/A 188342 C /tmp/nbody 109MiB | | 0 N/A N/A 188413 C /tmp/nbody 109MiB | +-----------------------------------------------------------------------------+ [10.100.10.10]: PS>Jak widać, istnieją dwa kontenery uruchomione z symulacją n-body na procesorze GPU 0. Możesz również wyświetlić odpowiednie użycie pamięci.
Po zakończeniu symulacji dane wyjściowe smi firmy NVIDIA pokażą, że na urządzeniu nie są uruchomione żadne procesy.
[10.100.10.10]: PS>Get-HcsGpuNvidiaSmi K8S-1HXQG13CL-1HXQG13: Fri Mar 5 13:54:48 2021 +-----------------------------------------------------------------------------+ | NVIDIA-SMI 460.32.03 Driver Version: 460.32.03 CUDA Version: 11.2 | |-------------------------------+----------------------+----------------------+ | GPU Name Persistence-M| Bus-Id Disp.A | Volatile Uncorr. ECC | | Fan Temp Perf Pwr:Usage/Cap| Memory-Usage | GPU-Util Compute M. | | | | MIG M. | |===============================+======================+======================| | 0 Tesla T4 On | 00002C74:00:00.0 Off | 0 | | N/A 34C P8 9W / 70W | 0MiB / 15109MiB | 0% Default | | | | N/A | +-------------------------------+----------------------+----------------------+ +-----------------------------------------------------------------------------+ | Processes: | | GPU GI CI PID Type Process name GPU Memory | | ID ID Usage | |=============================================================================| | No running processes found | +-----------------------------------------------------------------------------+ [10.100.10.10]: PS>Po zakończeniu symulacji n-body wyświetl dzienniki, aby zrozumieć szczegóły wdrożenia i czas wymagany do ukończenia symulacji.
Oto przykładowe dane wyjściowe z pierwszego kontenera:
PS C:\WINDOWS\system32> kubectl -n iotedge --kubeconfig C:\GPU-sharing\kubeconfigs\configiotuser1 logs cuda-sample1-869989578c-ssng8 cuda-sample1 Run "nbody -benchmark [-numbodies=<numBodies>]" to measure performance. ==============// snipped //===================// snipped //============= > Windowed mode > Simulation data stored in video memory > Single precision floating point simulation > 1 Devices used for simulation GPU Device 0: "Turing" with compute capability 7.5 > Compute 7.5 CUDA device: [Tesla T4] 40960 bodies, total time for 10000 iterations: 170171.531 ms = 98.590 billion interactions per second = 1971.801 single-precision GFLOP/s at 20 flops per interaction no-op PS C:\WINDOWS\system32>Oto przykładowe dane wyjściowe z drugiego kontenera:
PS C:\WINDOWS\system32> kubectl -n iotedge --kubeconfig C:\GPU-sharing\kubeconfigs\configiotuser1 logs cuda-sample2-6db6d98689-d74kb cuda-sample2 Run "nbody -benchmark [-numbodies=<numBodies>]" to measure performance. ==============// snipped //===================// snipped //============= > Windowed mode > Simulation data stored in video memory > Single precision floating point simulation > 1 Devices used for simulation GPU Device 0: "Turing" with compute capability 7.5 > Compute 7.5 CUDA device: [Tesla T4] 40960 bodies, total time for 10000 iterations: 170054.969 ms = 98.658 billion interactions per second = 1973.152 single-precision GFLOP/s at 20 flops per interaction no-op PS C:\WINDOWS\system32>Zatrzymaj wdrożenie modułu. W zasobie usługi IoT Hub dla urządzenia:
Przejdź do pozycji Automatyczne wdrażanie > urządzeń IoT Edge. Wybierz urządzenie usługi IoT Edge odpowiadające urządzeniu.
Przejdź do pozycji Ustaw moduły i wybierz moduł.
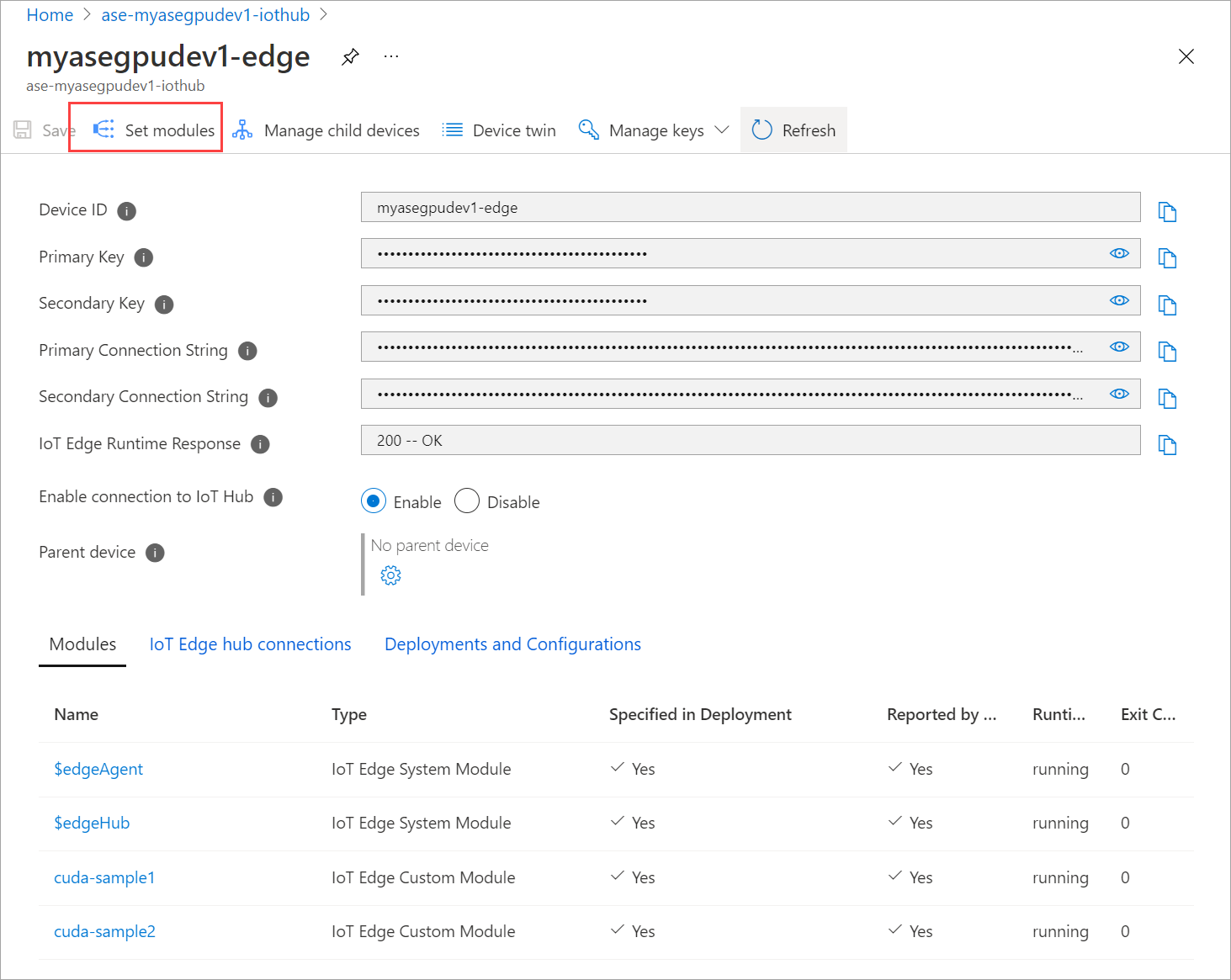
Na karcie Moduły wybierz moduł.
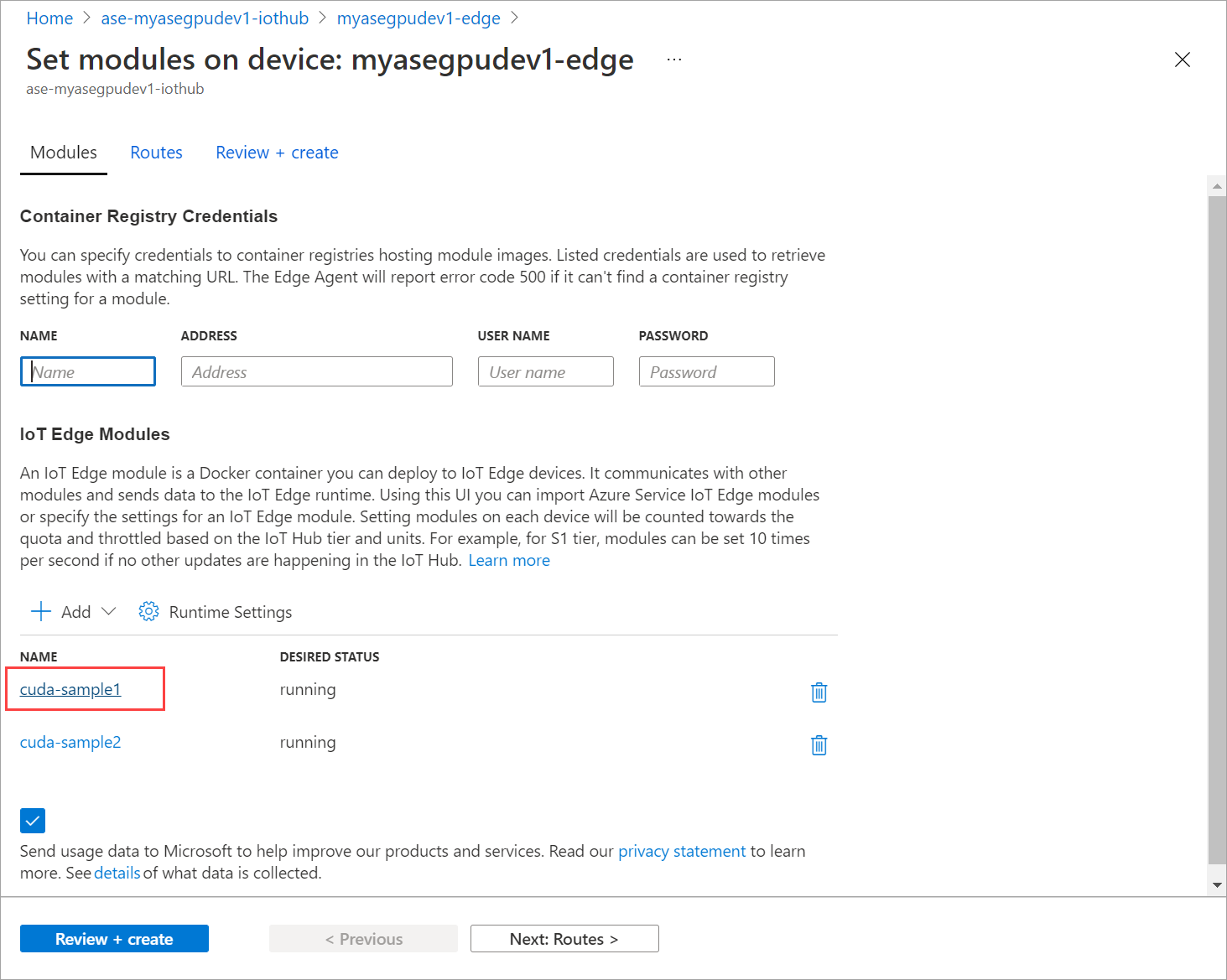
Na karcie Ustawienia modułu ustaw żądany stan na zatrzymany. Wybierz Aktualizuj.
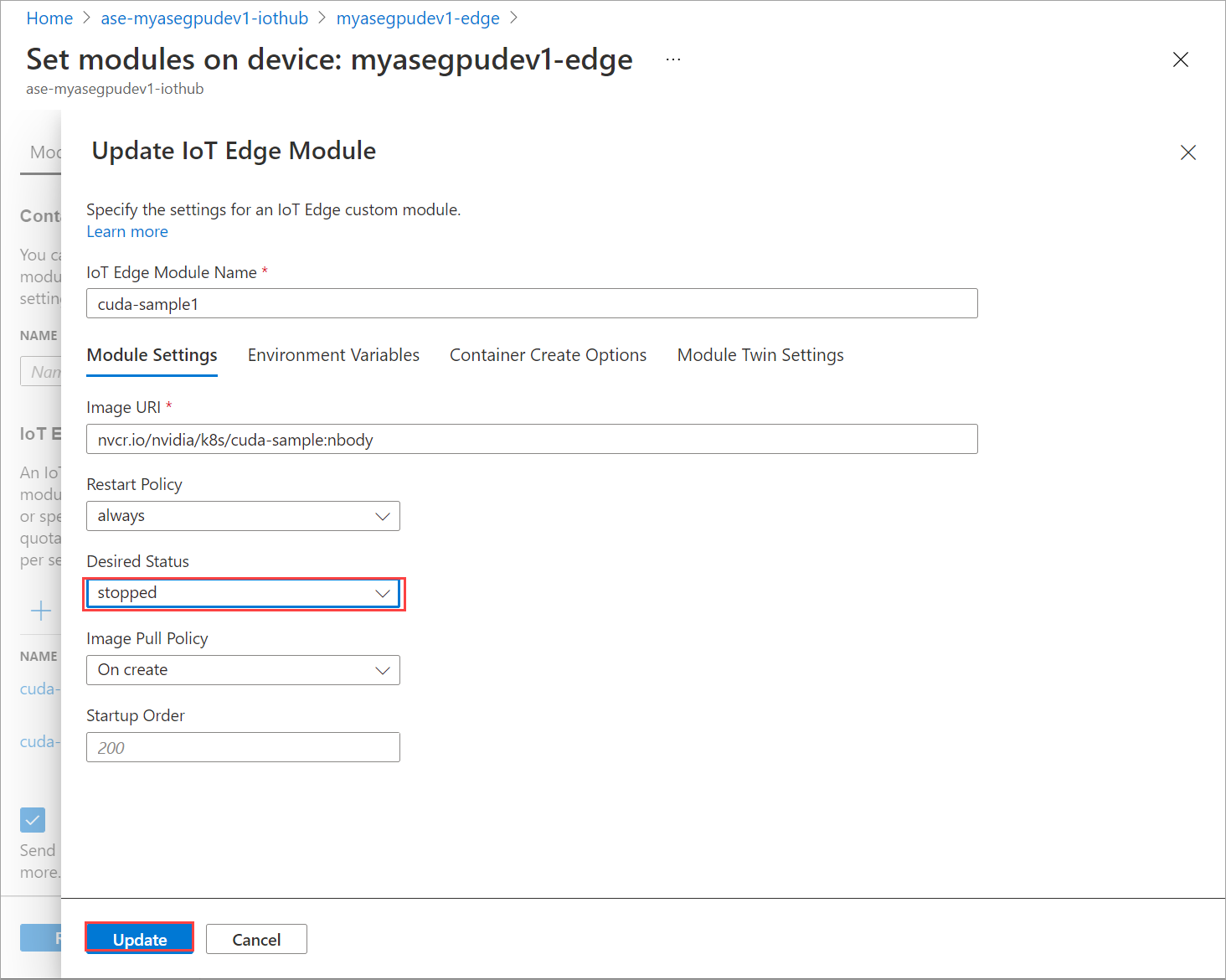
Powtórz kroki, aby zatrzymać drugi moduł wdrożony na urządzeniu. Wybierz pozycję Przeglądanie i tworzenie, a następnie wybierz pozycję Utwórz. Powinno to zaktualizować wdrożenie.
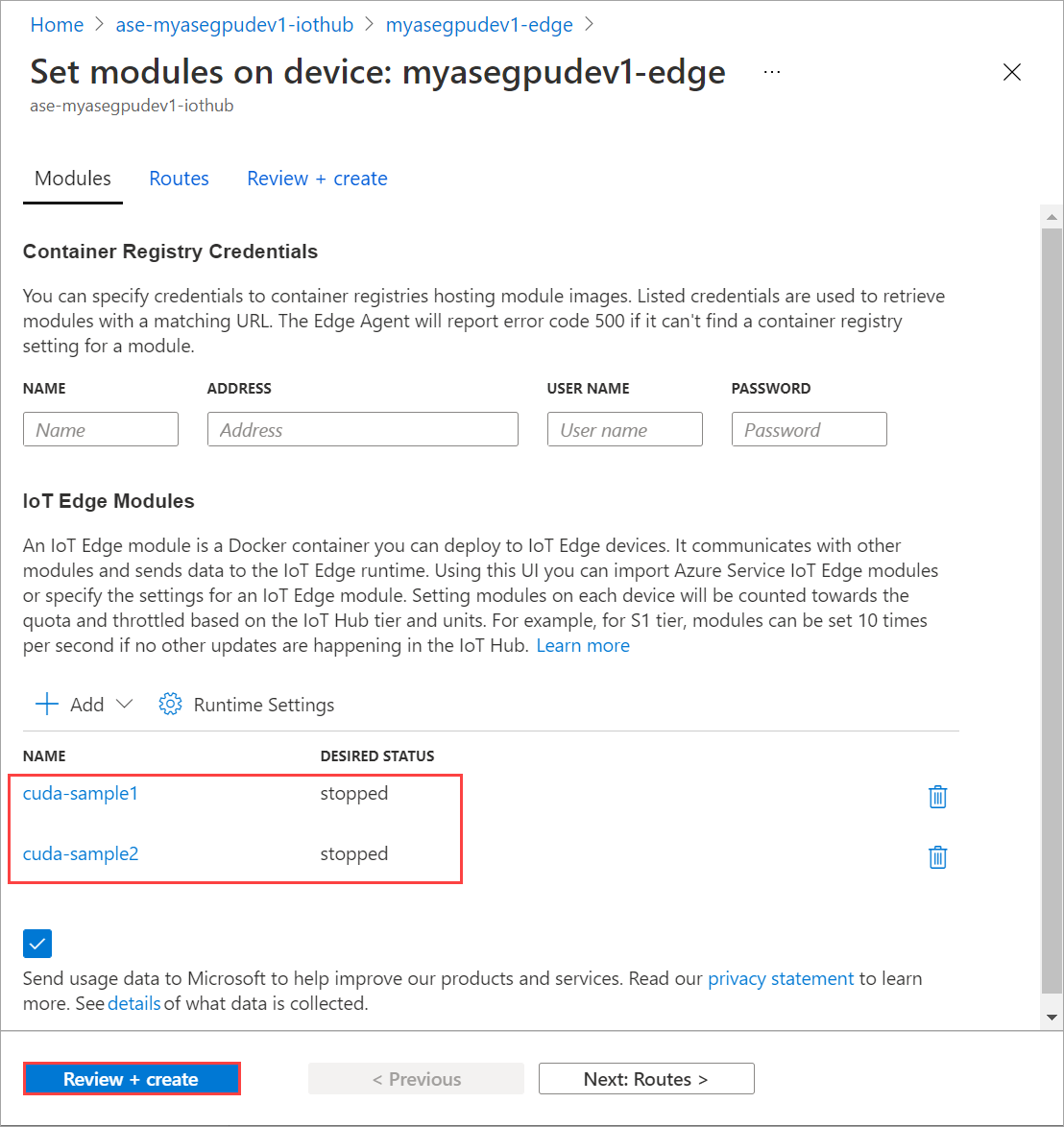
Odśwież stronę Zestaw modułów wiele razy. dopóki stan środowiska uruchomieniowego modułu nie będzie wyświetlany jako Zatrzymany.
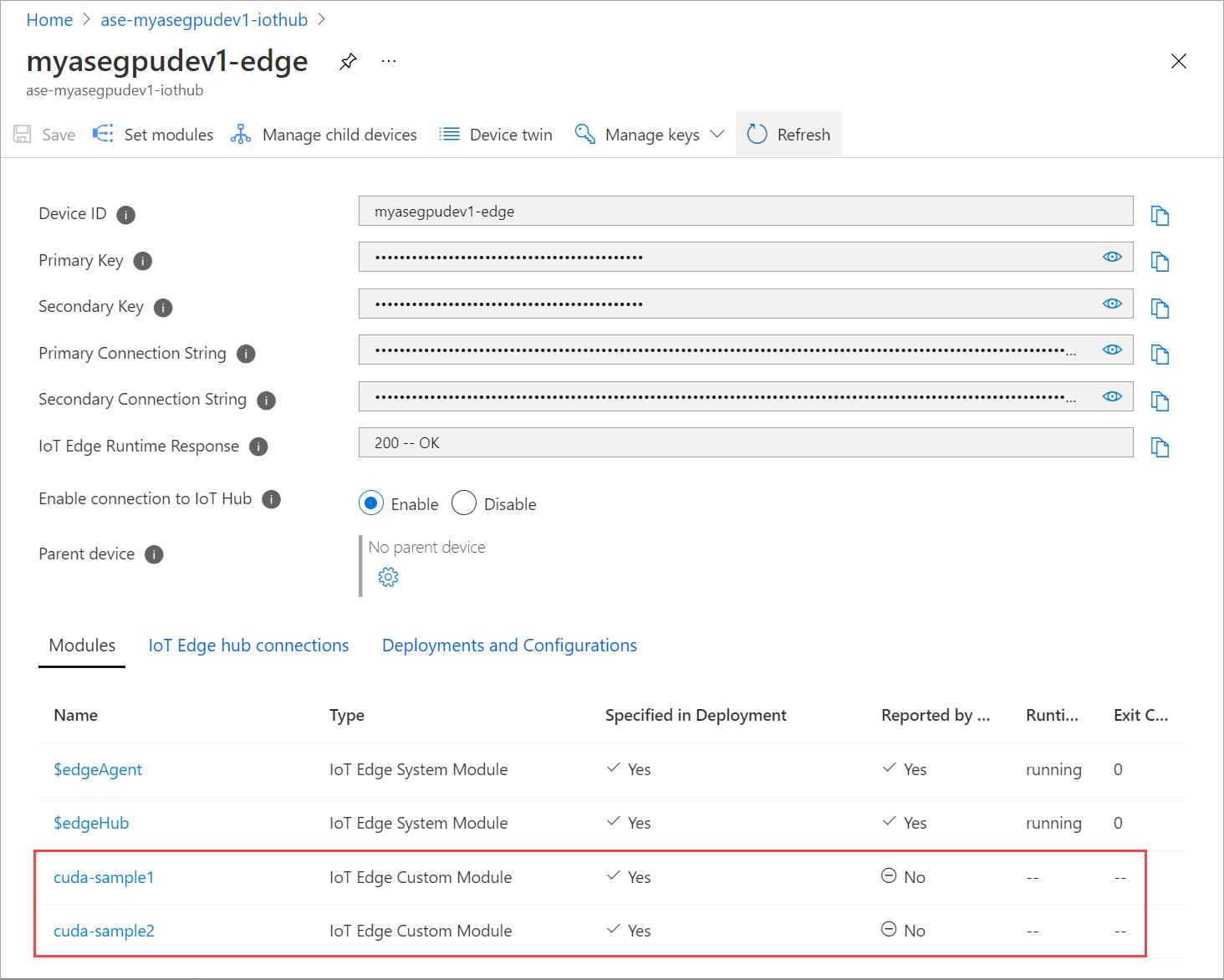
Wdrażanie przy użyciu udostępniania kontekstu
Teraz można wdrożyć symulację n-treści na dwóch kontenerach CUDA, gdy usługa MPS jest uruchomiona na urządzeniu. Najpierw włączysz usługę MPS na urządzeniu.
Aby włączyć usługę MPS na urządzeniu
Start-HcsGpuMPS, uruchom polecenie .[10.100.10.10]: PS>Start-HcsGpuMPS K8S-1HXQG13CL-1HXQG13: Set compute mode to EXCLUSIVE_PROCESS for GPU 0000191E:00:00.0. All done. Created nvidia-mps.service [10.100.10.10]: PS>Pobierz dane wyjściowe smi firmy NVIDIA z interfejsu programu PowerShell urządzenia. Możesz zobaczyć, że
nvidia-cuda-mps-serverproces lub usługa MPS jest uruchomiona na urządzeniu.Oto przykładowe dane wyjściowe:
[10.100.10.10]: PS>Get-HcsGpuNvidiaSmi K8S-1HXQG13CL-1HXQG13: Thu Mar 4 12:37:39 2021 +-----------------------------------------------------------------------------+ | NVIDIA-SMI 460.32.03 Driver Version: 460.32.03 CUDA Version: 11.2 | |-------------------------------+----------------------+----------------------+ | GPU Name Persistence-M| Bus-Id Disp.A | Volatile Uncorr. ECC | | Fan Temp Perf Pwr:Usage/Cap| Memory-Usage | GPU-Util Compute M. | | | | MIG M. | |===============================+======================+======================| | 0 Tesla T4 On | 00002C74:00:00.0 Off | 0 | | N/A 36C P8 9W / 70W | 28MiB / 15109MiB | 0% E. Process | | | | N/A | +-------------------------------+----------------------+----------------------+ +-----------------------------------------------------------------------------+ | Processes: | | GPU GI CI PID Type Process name GPU Memory | | ID ID Usage | |=============================================================================| | 0 N/A N/A 122792 C nvidia-cuda-mps-server 25MiB | +-----------------------------------------------------------------------------+ [10.100.10.10]: PS>Get-HcsGpuNvidiaSmiWdróż wcześniej zatrzymane moduły. Ustaw żądany stan na uruchomiony za pomocą pozycji Ustaw moduły.
Oto przykładowe dane wyjściowe:
PS C:\WINDOWS\system32> kubectl get pods -n iotedge --kubeconfig C:\GPU-sharing\kubeconfigs\configiotuser1 NAME READY STATUS RESTARTS AGE cuda-sample1-869989578c-2zxh6 2/2 Running 0 44s cuda-sample2-6db6d98689-fn7mx 2/2 Running 0 44s edgeagent-79f988968b-7p2tv 2/2 Running 0 5d20h edgehub-d6c764847-l8v4m 2/2 Running 0 27m iotedged-55fdb7b5c6-l9zn8 1/1 Running 1 5d20h PS C:\WINDOWS\system32>Zobaczysz, że moduły są wdrażane i uruchomione na urządzeniu.
Po wdrożeniu modułów symulacja n-treści również uruchamia się na obu kontenerach. Oto przykładowe dane wyjściowe po zakończeniu symulacji w pierwszym kontenerze:
PS C:\WINDOWS\system32> kubectl -n iotedge logs cuda-sample1-869989578c-2zxh6 cuda-sample1 Run "nbody -benchmark [-numbodies=<numBodies>]" to measure performance. ==============// snipped //===================// snipped //============= > Windowed mode > Simulation data stored in video memory > Single precision floating point simulation > 1 Devices used for simulation GPU Device 0: "Turing" with compute capability 7.5 > Compute 7.5 CUDA device: [Tesla T4] 40960 bodies, total time for 10000 iterations: 155256.062 ms = 108.062 billion interactions per second = 2161.232 single-precision GFLOP/s at 20 flops per interaction no-op PS C:\WINDOWS\system32>Oto przykładowe dane wyjściowe po zakończeniu symulacji w drugim kontenerze:
PS C:\WINDOWS\system32> kubectl -n iotedge --kubeconfig C:\GPU-sharing\kubeconfigs\configiotuser1 logs cuda-sample2-6db6d98689-fn7mx cuda-sample2 Run "nbody -benchmark [-numbodies=<numBodies>]" to measure performance. ==============// snipped //===================// snipped //============= > Windowed mode > Simulation data stored in video memory > Single precision floating point simulation > 1 Devices used for simulation GPU Device 0: "Turing" with compute capability 7.5 > Compute 7.5 CUDA device: [Tesla T4] 40960 bodies, total time for 10000 iterations: 155366.359 ms = 107.985 billion interactions per second = 2159.697 single-precision GFLOP/s at 20 flops per interaction no-op PS C:\WINDOWS\system32>Pobierz dane wyjściowe smi firmy NVIDIA z interfejsu programu PowerShell urządzenia, gdy oba kontenery uruchamiają symulację n-body. Oto przykładowe dane wyjściowe. Istnieją trzy procesy,
nvidia-cuda-mps-serverproces (typ C) odpowiada usłudze MPS, a/tmp/nbodyprocesy (typ M + C) odpowiadają obciążeniam n-body wdrożonym przez moduły.[10.100.10.10]: PS>Get-HcsGpuNvidiaSmi K8S-1HXQG13CL-1HXQG13: Thu Mar 4 12:59:44 2021 +-----------------------------------------------------------------------------+ | NVIDIA-SMI 460.32.03 Driver Version: 460.32.03 CUDA Version: 11.2 | |-------------------------------+----------------------+----------------------+ | GPU Name Persistence-M| Bus-Id Disp.A | Volatile Uncorr. ECC | | Fan Temp Perf Pwr:Usage/Cap| Memory-Usage | GPU-Util Compute M. | | | | MIG M. | |===============================+======================+======================| | 0 Tesla T4 On | 00002C74:00:00.0 Off | 0 | | N/A 54C P0 69W / 70W | 242MiB / 15109MiB | 100% E. Process | | | | N/A | +-------------------------------+----------------------+----------------------+ +-----------------------------------------------------------------------------+ | Processes: | | GPU GI CI PID Type Process name GPU Memory | | ID ID Usage | |=============================================================================| | 0 N/A N/A 56832 M+C /tmp/nbody 107MiB | | 0 N/A N/A 56900 M+C /tmp/nbody 107MiB | | 0 N/A N/A 122792 C nvidia-cuda-mps-server 25MiB | +-----------------------------------------------------------------------------+ [10.100.10.10]: PS>Get-HcsGpuNvidiaSmi