Kopiowanie i przekształcanie danych w usłudze Microsoft Fabric Warehouse przy użyciu usługi Azure Data Factory lub Azure Synapse Analytics
DOTYCZY:  Azure Data Factory Azure Synapse Analytics
Azure Data Factory Azure Synapse Analytics
Napiwek
Wypróbuj usługę Data Factory w usłudze Microsoft Fabric — rozwiązanie analityczne typu all-in-one dla przedsiębiorstw. Usługa Microsoft Fabric obejmuje wszystko, od przenoszenia danych do nauki o danych, analizy w czasie rzeczywistym, analizy biznesowej i raportowania. Dowiedz się, jak bezpłatnie rozpocząć nową wersję próbną !
W tym artykule opisano sposób używania działania kopiowania do kopiowania danych z i do usługi Microsoft Fabric Warehouse. Aby dowiedzieć się więcej, przeczytaj artykuł wprowadzający dotyczący usługi Azure Data Factory lub Azure Synapse Analytics.
Obsługiwane możliwości
Ten łącznik usługi Microsoft Fabric Warehouse jest obsługiwany w następujących funkcjach:
| Obsługiwane możliwości | IR | Zarządzany prywatny punkt końcowy |
|---|---|---|
| działanie Kopiuj (źródło/ujście) | (1) (2) | ✓ |
| Przepływ danych mapowania (źródło/ujście) | (1) | ✓ |
| Działanie Lookup | (1) (2) | ✓ |
| Działanie GetMetadata | (1) (2) | ✓ |
| Działanie skryptu | (1) (2) | ✓ |
| Działanie procedury składowanej | (1) (2) | ✓ |
(1) Środowisko Azure Integration Runtime (2) Self-hosted Integration Runtime
Rozpocznij
Aby wykonać działanie Kopiuj za pomocą potoku, możesz użyć jednego z następujących narzędzi lub zestawów SDK:
- Narzędzie do kopiowania danych
- Witryna Azure Portal
- Zestaw SDK platformy .NET
- Zestaw SDK języka Python
- Azure PowerShell
- Interfejs API REST
- Szablon usługi Azure Resource Manager
Tworzenie połączonej usługi Microsoft Fabric Warehouse przy użyciu interfejsu użytkownika
Wykonaj poniższe kroki, aby utworzyć połączoną usługę Microsoft Fabric Warehouse w interfejsie użytkownika witryny Azure Portal.
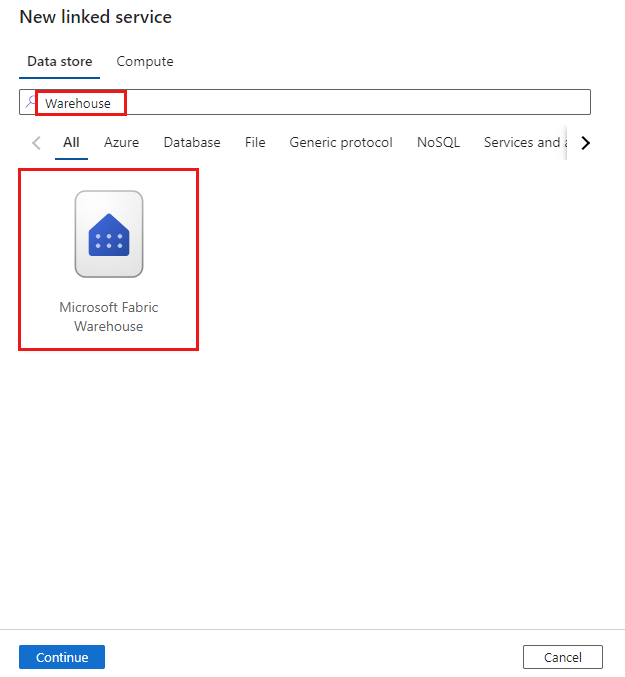
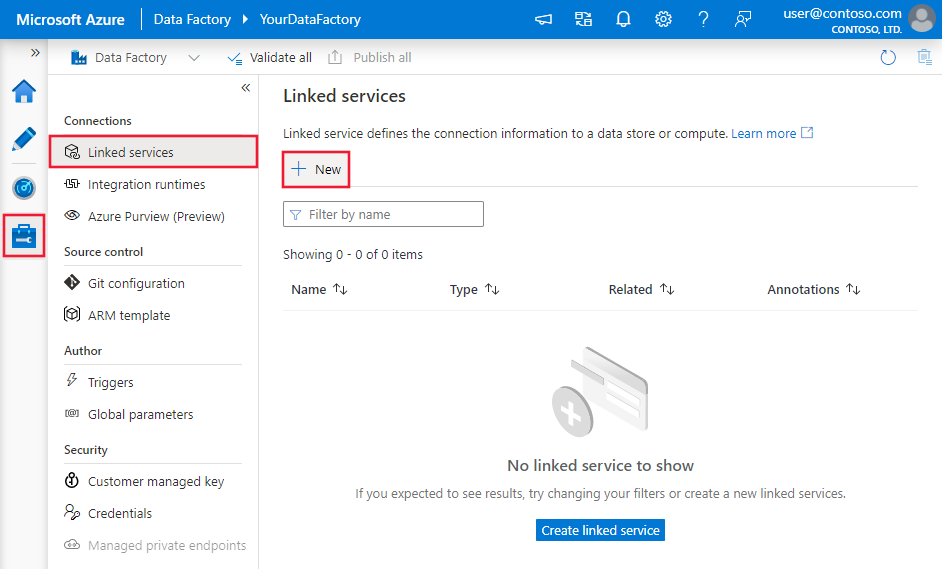
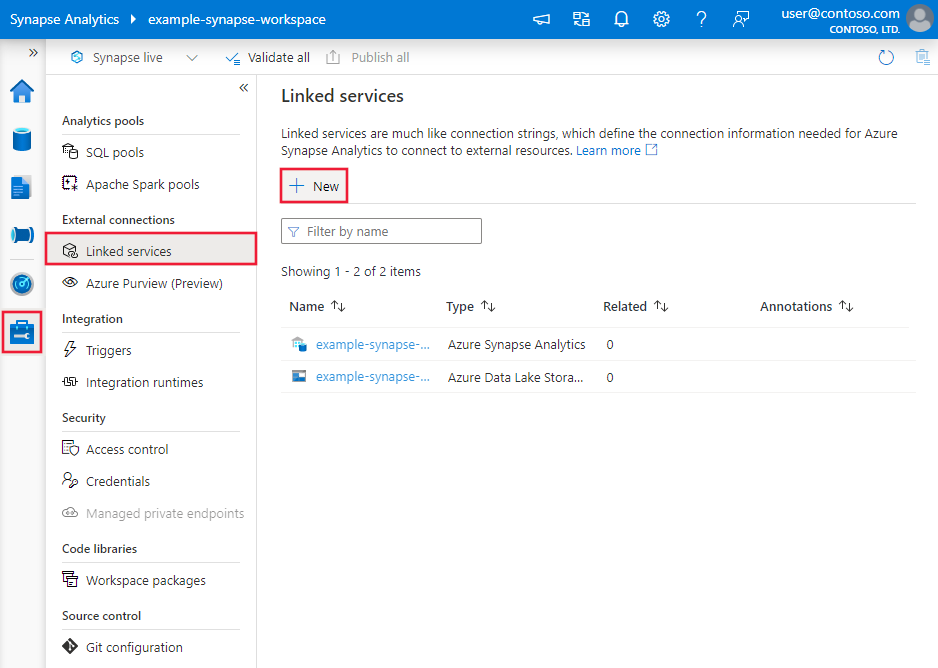
Przejdź do karty Zarządzanie w obszarze roboczym usługi Azure Data Factory lub Synapse i wybierz pozycję Połączone usługi, a następnie wybierz pozycję Nowe:
Wyszukaj pozycję Magazyn i wybierz łącznik.
Skonfiguruj szczegóły usługi, przetestuj połączenie i utwórz nową połączoną usługę.
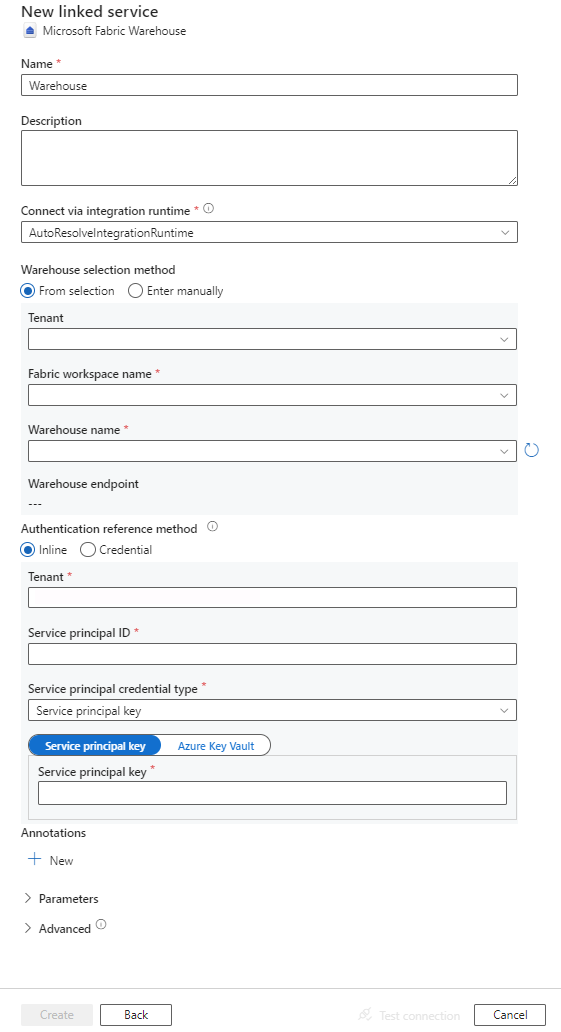
Szczegóły konfiguracji łącznika
Poniższe sekcje zawierają szczegółowe informacje o właściwościach używanych do definiowania jednostek usługi Data Factory specyficznych dla usługi Microsoft Fabric Warehouse.
Właściwości połączonej usługi
Łącznik usługi Microsoft Fabric Warehouse obsługuje następujące typy uwierzytelniania. Aby uzyskać szczegółowe informacje, zobacz odpowiednie sekcje:
Uwierzytelnianie nazwy głównej usługi
Aby użyć uwierzytelniania jednostki usługi, wykonaj następujące kroki.
Zarejestruj aplikację przy użyciu platformy Tożsamości Microsoft i dodaj wpis tajny klienta. Następnie zanotuj te wartości, których użyjesz do zdefiniowania połączonej usługi:
- Identyfikator aplikacji (klienta), który jest identyfikatorem jednostki usługi w połączonej usłudze.
- Wartość wpisu tajnego klienta, która jest kluczem jednostki usługi w połączonej usłudze.
- Identyfikator dzierżawy
Udziel jednostce usługi co najmniej roli Współautor w obszarze roboczym usługi Microsoft Fabric. Wykonaj te kroki:
Przejdź do obszaru roboczego usługi Microsoft Fabric, wybierz pozycję Zarządzaj dostępem na górnym pasku. Następnie wybierz pozycję Dodaj osoby lub grupy.
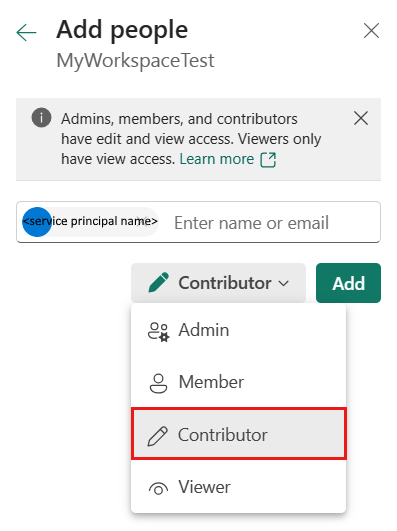
W okienku Dodawanie osób wprowadź nazwę główną usługi i wybierz jednostkę usługi z listy rozwijanej.
Określ rolę Współautor lub wyższy (Administrator, Członek), a następnie wybierz pozycję Dodaj.
Jednostka usługi jest wyświetlana w okienku Zarządzanie dostępem .
Te właściwości są obsługiwane w przypadku połączonej usługi:
| Właściwości | Opis | Wymagania |
|---|---|---|
| type | Właściwość type musi być ustawiona na Wartość Warehouse. | Tak |
| endpoint | Punkt końcowy serwera usługi Microsoft Fabric Warehouse. | Tak |
| workspaceId | Identyfikator obszaru roboczego usługi Microsoft Fabric. | Tak |
| artifactId | Identyfikator obiektu usługi Microsoft Fabric Warehouse. | Tak |
| tenant | Określ informacje o dzierżawie (nazwę domeny lub identyfikator dzierżawy), w ramach których znajduje się aplikacja. Pobierz go, umieszczając wskaźnik myszy w prawym górnym rogu witryny Azure Portal. | Tak |
| servicePrincipalId | Określ identyfikator klienta aplikacji. | Tak |
| servicePrincipalCredentialType | Typ poświadczeń do użycia na potrzeby uwierzytelniania jednostki usługi. Dozwolone wartości to ServicePrincipalKey i ServicePrincipalCert. | Tak |
| servicePrincipalCredential | Poświadczenie jednostki usługi. W przypadku użycia klucza ServicePrincipalKey jako typu poświadczeń określ wartość klucza tajnego klienta aplikacji. Oznacz to pole jako SecureString , aby bezpiecznie je przechowywać lub odwołuje się do wpisu tajnego przechowywanego w usłudze Azure Key Vault. Jeśli używasz klasy ServicePrincipalCert jako poświadczenia, odwołaj się do certyfikatu w usłudze Azure Key Vault i upewnij się, że typ zawartości certyfikatu to PKCS #12. |
Tak |
| connectVia | Środowisko Integration Runtime do nawiązania połączenia z magazynem danych. Możesz użyć środowiska Azure Integration Runtime lub własnego środowiska Integration Runtime, jeśli magazyn danych znajduje się w sieci prywatnej. Jeśli nie zostanie określony, zostanie użyte domyślne środowisko Azure Integration Runtime. | Nie. |
Przykład: używanie uwierzytelniania klucza jednostki usługi
Klucz jednostki usługi można również przechowywać w usłudze Azure Key Vault.
{
"name": "MicrosoftFabricWarehouseLinkedService",
"properties": {
"type": "Warehouse",
"typeProperties": {
"endpoint": "<Microsoft Fabric Warehouse server endpoint>",
"workspaceId": "<Microsoft Fabric workspace ID>",
"artifactId": "<Microsoft Fabric Warehouse object ID>",
"tenant": "<tenant info, e.g. microsoft.onmicrosoft.com>",
"servicePrincipalId": "<service principal id>",
"servicePrincipalCredentialType": "ServicePrincipalKey",
"servicePrincipalCredential": {
"type": "SecureString",
"value": "<service principal key>"
}
},
"connectVia": {
"referenceName": "<name of Integration Runtime>",
"type": "IntegrationRuntimeReference"
}
}
}
Właściwości zestawu danych
Aby uzyskać pełną listę sekcji i właściwości dostępnych do definiowania zestawów danych, zobacz artykuł Zestawy danych.
Następujące właściwości są obsługiwane w przypadku zestawu danych usługi Microsoft Fabric Warehouse:
| Właściwości | Opis | Wymagania |
|---|---|---|
| type | Właściwość type zestawu danych musi być ustawiona na Wartość WarehouseTable. | Tak |
| schema | Nazwa schematu. | Nie dla źródła, Tak dla ujścia |
| table | Nazwa tabeli/widoku. | Nie dla źródła, Tak dla ujścia |
Przykład właściwości zestawu danych
{
"name": "FabricWarehouseTableDataset",
"properties": {
"type": "WarehouseTable",
"linkedServiceName": {
"referenceName": "<Microsoft Fabric Warehouse linked service name>",
"type": "LinkedServiceReference"
},
"schema": [ < physical schema, optional, retrievable during authoring >
],
"typeProperties": {
"schema": "<schema_name>",
"table": "<table_name>"
}
}
}
Właściwości działania kopiowania
Aby uzyskać pełną listę sekcji i właściwości dostępnych do definiowania działań, zobacz działanie Kopiuj konfiguracje i potoki i działania. Ta sekcja zawiera listę właściwości obsługiwanych przez źródło i ujście magazynu Microsoft Fabric Warehouse.
Microsoft Fabric Warehouse jako źródło
Napiwek
Aby wydajnie ładować dane z usługi Microsoft Fabric Warehouse przy użyciu partycjonowania danych, dowiedz się więcej na temat kopiowania równoległego z usługi Microsoft Fabric Warehouse.
Aby skopiować dane z usługi Microsoft Fabric Warehouse, ustaw właściwość type w źródle działania kopiowania na wartość WarehouseSource. Następujące właściwości są obsługiwane w sekcji Źródło działania kopiowania:
| Właściwości | Opis | Wymagania |
|---|---|---|
| type | Właściwość type źródła działania kopiowania musi być ustawiona na Wartość WarehouseSource. | Tak |
| sqlReaderQuery | Użyj niestandardowego zapytania SQL, aby odczytać dane. Przykład: select * from MyTable. |
Nie. |
| sqlReaderStoredProcedureName | Nazwa procedury składowanej, która odczytuje dane z tabeli źródłowej. Ostatnia instrukcja SQL musi być instrukcją SELECT w procedurze składowanej. | Nie. |
| storedProcedureParameters | Parametry procedury składowanej. Dozwolone wartości to pary nazw lub wartości. Nazwy i wielkość liter parametrów muszą być zgodne z nazwami i wielkością parametrów procedury składowanej. |
Nie. |
| queryTimeout | Określa limit czasu wykonywania polecenia zapytania. Wartość domyślna to 120 minut. | Nie. |
| isolationLevel | Określa zachowanie blokowania transakcji dla źródła SQL. Dozwolona wartość to Migawka. Jeśli nie zostanie określony, zostanie użyty domyślny poziom izolacji bazy danych. Aby uzyskać więcej informacji, zobacz system.data.isolationlevel. | Nie. |
| partitionOptions | Określa opcje partycjonowania danych używane do ładowania danych z usługi Microsoft Fabric Warehouse. Dozwolone wartości to: Brak (wartość domyślna) i DynamicRange. Jeśli opcja partycji jest włączona (czyli nie None), stopień równoległości równoczesnego ładowania danych z usługi Microsoft Fabric Warehouse jest kontrolowany przez parallelCopies ustawienie działania kopiowania. |
Nie. |
| partitionSettings | Określ grupę ustawień partycjonowania danych. Zastosuj, gdy opcja partycji nie Nonejest . |
Nie. |
W obszarze partitionSettings: |
||
| partitionColumnName | Określ nazwę kolumny źródłowej w liczbą całkowitą lub typ daty/daty/godziny (int, smallint, bigintdate, , ), datetime2który będzie używany przez partycjonowanie zakresu na potrzeby kopiowania równoległego. Jeśli nie zostanie określony, indeks lub klucz podstawowy tabeli jest wykrywany automatycznie i używany jako kolumna partycji.Zastosuj, gdy opcja partycji to DynamicRange. Jeśli używasz zapytania do pobierania danych źródłowych, należy podłączyć ?DfDynamicRangePartitionCondition się do klauzuli WHERE. Aby zapoznać się z przykładem, zobacz sekcję Kopia równoległa z usługi Microsoft Fabric Warehouse . |
Nie. |
| partitionUpperBound | Maksymalna wartość kolumny partycji dla podziału zakresu partycji. Ta wartość służy do decydowania o kroku partycji, a nie do filtrowania wierszy w tabeli. Wszystkie wiersze w tabeli lub wyniku zapytania zostaną podzielone na partycje i skopiowane. Jeśli nie zostanie określony, działanie kopiowania automatycznie wykrywa wartość. Zastosuj, gdy opcja partycji to DynamicRange. Aby zapoznać się z przykładem, zobacz sekcję Kopia równoległa z usługi Microsoft Fabric Warehouse . |
Nie. |
| partitionLowerBound | Minimalna wartość kolumny partycji dla podziału zakresu partycji. Ta wartość służy do decydowania o kroku partycji, a nie do filtrowania wierszy w tabeli. Wszystkie wiersze w tabeli lub wyniku zapytania zostaną podzielone na partycje i skopiowane. Jeśli nie zostanie określony, działanie kopiowania automatycznie wykrywa wartość. Zastosuj, gdy opcja partycji to DynamicRange. Aby zapoznać się z przykładem, zobacz sekcję Kopia równoległa z usługi Microsoft Fabric Warehouse . |
Nie. |
Uwaga
W przypadku używania procedury składowanej w źródle do pobierania danych należy pamiętać, że procedura składowana jest zaprojektowana jako zwracanie innego schematu po przekazaniu innej wartości parametru, może wystąpić błąd lub nieoczekiwany wynik podczas importowania schematu z interfejsu użytkownika lub kopiowania danych do usługi Microsoft Fabric Warehouse z automatycznym tworzeniem tabeli.
Przykład: używanie zapytania SQL
"activities":[
{
"name": "CopyFromMicrosoftFabricWarehouse",
"type": "Copy",
"inputs": [
{
"referenceName": "<Microsoft Fabric Warehouse input dataset name>",
"type": "DatasetReference"
}
],
"outputs": [
{
"referenceName": "<output dataset name>",
"type": "DatasetReference"
}
],
"typeProperties": {
"source": {
"type": "WarehouseSource",
"sqlReaderQuery": "SELECT * FROM MyTable"
},
"sink": {
"type": "<sink type>"
}
}
}
]
Przykład: używanie procedury składowanej
"activities":[
{
"name": "CopyFromMicrosoftFabricWarehouse",
"type": "Copy",
"inputs": [
{
"referenceName": "<Microsoft Fabric Warehouse input dataset name>",
"type": "DatasetReference"
}
],
"outputs": [
{
"referenceName": "<output dataset name>",
"type": "DatasetReference"
}
],
"typeProperties": {
"source": {
"type": "WarehouseSource",
"sqlReaderStoredProcedureName": "CopyTestSrcStoredProcedureWithParameters",
"storedProcedureParameters": {
"stringData": { "value": "str3" },
"identifier": { "value": "$$Text.Format('{0:yyyy}', <datetime parameter>)", "type": "Int"}
}
},
"sink": {
"type": "<sink type>"
}
}
}
]
Przykładowa procedura składowana:
CREATE PROCEDURE CopyTestSrcStoredProcedureWithParameters
(
@stringData varchar(20),
@identifier int
)
AS
SET NOCOUNT ON;
BEGIN
select *
from dbo.UnitTestSrcTable
where dbo.UnitTestSrcTable.stringData != stringData
and dbo.UnitTestSrcTable.identifier != identifier
END
GO
Microsoft Fabric Warehouse jako typ ujścia
Potoki usług Azure Data Factory i Synapse obsługują instrukcję Use COPY to load data into Microsoft Fabric Warehouse (Używanie instrukcji COPY do ładowania danych do usługi Microsoft Fabric Warehouse).
Aby skopiować dane do usługi Microsoft Fabric Warehouse, ustaw typ ujścia w obszarze Działanie kopiowania na WarehouseSink. Następujące właściwości są obsługiwane w sekcji ujścia działania kopiowania:
| Właściwości | Opis | Wymagania |
|---|---|---|
| type | Właściwość type ujścia działania kopiowania musi być ustawiona na WarehouseSink. | Tak |
| allowCopyCommand | Wskazuje, czy używać instrukcji COPY do ładowania danych do usługi Microsoft Fabric Warehouse. Zobacz Sekcję Używanie instrukcji COPY do ładowania danych do usługi Microsoft Fabric Warehouse , aby uzyskać informacje o ograniczeniach i szczegółach. Dozwolona wartość to True. |
Tak |
| copyCommandSettings | Grupa właściwości, które można określić, gdy allowCopyCommand właściwość jest ustawiona na wartość TRUE. |
Nie. |
| writeBatchTimeout | Ta właściwość określa czas oczekiwania na ukończenie operacji wstawiania, operacji upsert i procedury składowanej przed przekroczeniem limitu czasu. Dozwolone wartości są dla przedziału czasu. Przykładem jest "00:30:00" przez 30 minut. Jeśli żadna wartość nie zostanie określona, limit czasu zostanie domyślnie ustawiona na "00:30:00" |
Nie. |
| preCopyScript | Określ zapytanie SQL dla działania kopiowania, które ma zostać uruchomione przed zapisaniem danych w usłudze Microsoft Fabric Warehouse w każdym uruchomieniu. Użyj tej właściwości, aby wyczyścić wstępnie załadowane dane. | Nie. |
| tableOption | Określa, czy automatycznie utworzyć tabelę ujścia, jeśli nie istnieje na podstawie schematu źródłowego. Dozwolone wartości to: none (wartość domyślna), autoCreate. |
Nie. |
| disableMetricsCollection | Usługa zbiera metryki dotyczące optymalizacji wydajności kopiowania i zaleceń, które wprowadzają dodatkowy dostęp do głównej bazy danych. Jeśli interesuje Cię to zachowanie, określ true , aby go wyłączyć. |
Nie (wartość domyślna to false) |
Przykład: ujście usługi Microsoft Fabric Warehouse
"activities":[
{
"name": "CopyToMicrosoftFabricWarehouse",
"type": "Copy",
"inputs": [
{
"referenceName": "<input dataset name>",
"type": "DatasetReference"
}
],
"outputs": [
{
"referenceName": "<Microsoft Fabric Warehouse output dataset name>",
"type": "DatasetReference"
}
],
"typeProperties": {
"source": {
"type": "<source type>"
},
"sink": {
"type": "WarehouseSink",
"allowCopyCommand": true,
"tableOption": "autoCreate",
"disableMetricsCollection": false
}
}
}
]
Kopiowanie równoległe z usługi Microsoft Fabric Warehouse
Łącznik usługi Microsoft Fabric Warehouse w działaniu kopiowania zapewnia wbudowane partycjonowanie danych w celu równoległego kopiowania danych. Opcje partycjonowania danych można znaleźć na karcie Źródło działania kopiowania.
Po włączeniu kopii partycjonowanej działanie kopiowania uruchamia zapytania równoległe względem źródła usługi Microsoft Fabric Warehouse w celu załadowania danych według partycji. Stopień równoległy jest kontrolowany przez parallelCopies ustawienie działania kopiowania. Jeśli na przykład ustawiono parallelCopies wartość cztery, usługa jednocześnie generuje i uruchamia cztery zapytania na podstawie określonej opcji partycji i ustawień, a każde zapytanie pobiera część danych z magazynu Microsoft Fabric Warehouse.
Zaleca się włączenie kopiowania równoległego przy użyciu partycjonowania danych, szczególnie w przypadku ładowania dużej ilości danych z magazynu usługi Microsoft Fabric. Poniżej przedstawiono sugerowane konfiguracje dla różnych scenariuszy. Podczas kopiowania danych do magazynu danych opartego na plikach zaleca się zapisywanie w folderze jako wielu plików (tylko określ nazwę folderu), w tym przypadku wydajność jest lepsza niż zapisywanie w jednym pliku.
| Scenariusz | Sugerowane ustawienia |
|---|---|
| Pełne ładowanie z dużej tabeli, natomiast z liczbą całkowitą lub kolumną datetime na potrzeby partycjonowania danych. | Opcje partycji: partycja zakresu dynamicznego. Kolumna partycji (opcjonalnie): określ kolumnę używaną do partycjonowania danych. Jeśli nie zostanie określony, zostanie użyta kolumna indeksu lub klucza podstawowego. Górna granica partycji i dolna granica partycji (opcjonalnie): określ, czy chcesz określić krok partycji. Nie dotyczy to filtrowania wierszy w tabeli, a wszystkie wiersze w tabeli będą partycjonowane i kopiowane. Jeśli nie zostanie określony, działanie kopiowania automatycznie wykrywa wartości. Jeśli na przykład kolumna partycji "ID" zawiera wartości z zakresu od 1 do 100, a dolna granica zostanie ustawiona na wartość 20, a górna granica to 80, z kopią równoległą jako 4, usługa pobiera dane według 4 partycji — identyfikatory w zakresie <=20, [21, 50], [51, 80] i >=81. |
| Załaduj dużą ilość danych przy użyciu zapytania niestandardowego, a kolumna całkowita lub data/data/godzina na potrzeby partycjonowania danych. | Opcje partycji: partycja zakresu dynamicznego. Zapytanie: SELECT * FROM <TableName> WHERE ?DfDynamicRangePartitionCondition AND <your_additional_where_clause>.Kolumna partycji: określ kolumnę używaną do partycjonowania danych. Górna granica partycji i dolna granica partycji (opcjonalnie): określ, czy chcesz określić krok partycji. Nie dotyczy to filtrowania wierszy w tabeli, a wszystkie wiersze w wyniku zapytania będą partycjonowane i kopiowane. Jeśli nie zostanie określony, działanie kopiowania automatycznie wykrywa wartość. Jeśli na przykład kolumna partycji "ID" zawiera wartości z zakresu od 1 do 100, a dolna granica zostanie ustawiona jako 20 i górna granica jako 80, z kopią równoległą jako 4, usługa pobiera dane według 4 partycji — identyfikatory w zakresie <=20, [21, 50], [51, 80] i >=81. Poniżej przedstawiono więcej przykładowych zapytań dla różnych scenariuszy: 1. Wykonaj zapytanie względem całej tabeli: SELECT * FROM <TableName> WHERE ?DfDynamicRangePartitionCondition2. Kwerenda z tabeli z zaznaczeniem kolumny i dodatkowymi filtrami klauzuli where: SELECT <column_list> FROM <TableName> WHERE ?DfDynamicRangePartitionCondition AND <your_additional_where_clause>3. Kwerenda z podzapytaniami: SELECT <column_list> FROM (<your_sub_query>) AS T WHERE ?DfDynamicRangePartitionCondition AND <your_additional_where_clause>4. Kwerenda z partycją w podzapytaniu: SELECT <column_list> FROM (SELECT <your_sub_query_column_list> FROM <TableName> WHERE ?DfDynamicRangePartitionCondition) AS T |
Najlepsze rozwiązania dotyczące ładowania danych z opcją partycji:
- Wybierz charakterystyczną kolumnę jako kolumnę partycji (np. klucz podstawowy lub unikatowy klucz), aby uniknąć niesymetryczności danych.
- Jeśli używasz środowiska Azure Integration Runtime do kopiowania danych, możesz ustawić większe wartości "Integracja danych Units (DIU)" (>4) w celu korzystania z większej liczby zasobów obliczeniowych. Sprawdź odpowiednie scenariusze.
- "Stopień równoległości kopiowania" steruje numerami partycji, ustawiając tę liczbę zbyt dużą, czasami boli wydajność, zaleca się ustawienie tej liczby jako (DIU lub liczba węzłów własnego środowiska IR) * (od 2 do 4).
- Należy pamiętać, że usługa Microsoft Fabric Warehouse może wykonywać maksymalnie 32 zapytania w danym momencie, ustawiając zbyt duży stopień równoległości kopiowania, może spowodować problem z ograniczaniem przepustowości magazynu.
Przykład: zapytanie z partycją zakresu dynamicznego
"source": {
"type": "WarehouseSource",
"query": "SELECT * FROM <TableName> WHERE ?DfDynamicRangePartitionCondition AND <your_additional_where_clause>",
"partitionOption": "DynamicRange",
"partitionSettings": {
"partitionColumnName": "<partition_column_name>",
"partitionUpperBound": "<upper_value_of_partition_column (optional) to decide the partition stride, not as data filter>",
"partitionLowerBound": "<lower_value_of_partition_column (optional) to decide the partition stride, not as data filter>"
}
}
Ładowanie danych do usługi Microsoft Fabric Warehouse przy użyciu instrukcji COPY
Użycie instrukcji COPY to prosty i elastyczny sposób ładowania danych do usługi Microsoft Fabric Warehouse z wysoką przepływnością. Aby dowiedzieć się więcej, zobacz Zbiorcze ładowanie danych przy użyciu instrukcji COPY
- Jeśli dane źródłowe są w usłudze Azure Blob lub Azure Data Lake Storage Gen2, a format jest zgodny z instrukcją COPY, możesz użyć działania kopiowania, aby bezpośrednio wywołać instrukcję COPY, aby umożliwić usłudze Microsoft Fabric Warehouse ściąganie danych ze źródła. Aby uzyskać szczegółowe informacje, zobacz Direct copy by using COPY statement (Kopiowanie bezpośrednie przy użyciu instrukcji COPY).
- Jeśli źródłowy magazyn danych i format nie są pierwotnie obsługiwane przez instrukcję COPY, użyj funkcji kopiowania etapowego przy użyciu funkcji instrukcji COPY. Funkcja kopiowania etapowego zapewnia również lepszą przepływność. Automatycznie konwertuje dane na format zgodny z instrukcją COPY, przechowuje dane w usłudze Azure Blob Storage, a następnie wywołuje instrukcję COPY w celu załadowania danych do usługi Microsoft Fabric Warehouse.
Napiwek
W przypadku korzystania z instrukcji COPY w środowisku Azure Integration Runtime obowiązująca liczba jednostek Integracja danych (DIU) zawsze wynosi 2. Dostrajanie jednostek DIU nie wpływa na wydajność.
Kopiowanie bezpośrednie przy użyciu instrukcji COPY
Instrukcja COPY magazynu usługi Microsoft Fabric bezpośrednio obsługuje usługi Azure Blob, Azure Data Lake Storage Gen1 i Azure Data Lake Storage Gen2. Jeśli dane źródłowe spełniają kryteria opisane w tej sekcji, użyj instrukcji COPY, aby skopiować bezpośrednio ze źródłowego magazynu danych do usługi Microsoft Fabric Warehouse. W przeciwnym razie użyj instrukcji COPY z instrukcją COPY. Usługa sprawdza ustawienia i kończy się niepowodzeniem działania kopiowania, jeśli kryteria nie zostały spełnione.
Źródłowa połączona usługa i format mają następujące typy i metody uwierzytelniania:
Obsługiwany typ magazynu danych źródłowych Obsługiwany format Obsługiwany typ uwierzytelniania źródłowego Azure Blob Rozdzielany tekst Uwierzytelnianie klucza konta, uwierzytelnianie za pomocą sygnatury dostępu współdzielonego Parkiet Uwierzytelnianie klucza konta, uwierzytelnianie za pomocą sygnatury dostępu współdzielonego Azure Data Lake Storage Gen2 Rozdzielany tekst
ParkietUwierzytelnianie klucza konta, uwierzytelnianie za pomocą sygnatury dostępu współdzielonego Ustawienia formatu są następujące:
- W przypadku parquet:
compressionnie może być kompresją, snappy lubGZip. - W przypadku tekstu rozdzielanego:
rowDelimiterjest jawnie ustawiana jako pojedynczy znak lub "\r\n", wartość domyślna nie jest obsługiwana.nullValuejest pozostawiony jako domyślny lub ustawiony na pusty ciąg ("").encodingNamejest pozostawiony jako domyślny lub ustawiony na utf-8 lub utf-16.escapeCharmusi być taka sama jakquoteChar, i nie jest pusta.skipLineCountjest pozostawiona jako domyślna lub ustawiona na 0.compressionnie może być kompresją aniGZip.
- W przypadku parquet:
Jeśli źródło jest folderem,
recursivew działaniu kopiowania musi być ustawiona wartość true iwildcardFilenamemusi mieć*wartość lub*.*.wildcardFolderPath,wildcardFilename(inne niż*lub*.*),modifiedDateTimeStart,modifiedDateTimeEnd,prefixenablePartitionDiscoveryiadditionalColumnsnie są określone.
Następujące ustawienia instrukcji COPY są obsługiwane allowCopyCommand w działaniu kopiowania:
| Właściwości | Opis | Wymagania |
|---|---|---|
| defaultValues | Określa wartości domyślne dla każdej kolumny docelowej w usłudze Microsoft Fabric Warehouse. Wartości domyślne we właściwości zastępują ograniczenie DOMYŚLNE ustawione w magazynie danych, a kolumna tożsamości nie może mieć wartości domyślnej. | Nie. |
| additionalOptions | Dodatkowe opcje, które zostaną przekazane do instrukcji COPY magazynu Usługi Microsoft Fabric bezpośrednio w klauzuli "With" w instrukcji COPY. Podaj wartość zgodnie z potrzebami, aby dopasować się do wymagań instrukcji COPY. | Nie. |
"activities":[
{
"name": "CopyFromAzureBlobToMicrosoftFabricWarehouseViaCOPY",
"type": "Copy",
"inputs": [
{
"referenceName": "ParquetDataset",
"type": "DatasetReference"
}
],
"outputs": [
{
"referenceName": "MicrosoftFabricWarehouseDataset",
"type": "DatasetReference"
}
],
"typeProperties": {
"source": {
"type": "ParquetSource",
"storeSettings":{
"type": "AzureBlobStorageReadSettings",
"recursive": true
}
},
"sink": {
"type": "WarehouseSink",
"allowCopyCommand": true,
"copyCommandSettings": {
"defaultValues": [
{
"columnName": "col_string",
"defaultValue": "DefaultStringValue"
}
],
"additionalOptions": {
"MAXERRORS": "10000",
"DATEFORMAT": "'ymd'"
}
}
},
"enableSkipIncompatibleRow": true
}
}
]
Kopiowanie etapowe przy użyciu instrukcji COPY
Jeśli dane źródłowe nie są natywnie zgodne z instrukcją COPY, włącz kopiowanie danych za pośrednictwem tymczasowego przejściowego obiektu blob platformy Azure lub usługi Azure Data Lake Storage Gen2 (nie może to być usługa Azure Premium Storage). W takim przypadku usługa automatycznie konwertuje dane w celu spełnienia wymagań dotyczących formatu danych instrukcji COPY. Następnie wywołuje instrukcję COPY w celu załadowania danych do usługi Microsoft Fabric Warehouse. Na koniec czyści dane tymczasowe z magazynu. Zobacz Kopiowanie etapowe, aby uzyskać szczegółowe informacje na temat kopiowania danych za pośrednictwem przemieszczania.
Aby użyć tej funkcji, utwórz połączoną usługę Azure Blob Storage lub połączoną usługę Azure Data Lake Storage Gen2 z kluczem konta lub uwierzytelnianiem tożsamości zarządzanej przez system, które odnosi się do konta usługi Azure Storage jako magazynu tymczasowego.
Ważne
- Korzystając z uwierzytelniania tożsamości zarządzanej dla połączonej usługi przejściowej, zapoznaj się z wymaganymi konfiguracjami odpowiednio dla usług Azure Blob i Azure Data Lake Storage Gen2 .
- Jeśli tymczasowa usługa Azure Storage jest skonfigurowana z punktem końcowym usługi sieci wirtualnej, musisz użyć uwierzytelniania tożsamości zarządzanej z włączoną funkcją "zezwalaj na zaufaną usługę firmy Microsoft" na koncie magazynu, zapoznaj się z tematem Wpływ używania punktów końcowych usługi sieci wirtualnej z usługą Azure Storage.
Ważne
Jeśli tymczasowa usługa Azure Storage jest skonfigurowana przy użyciu zarządzanego prywatnego punktu końcowego i ma włączoną zaporę magazynu, musisz użyć uwierzytelniania tożsamości zarządzanej i przyznać uprawnienia Czytelnik danych obiektu blob usługi Storage do programu Synapse SQL Server, aby upewnić się, że będzie on mógł uzyskać dostęp do plików przygotowanych podczas ładowania instrukcji COPY.
"activities":[
{
"name": "CopyFromSQLServerToMicrosoftFabricWarehouseViaCOPYstatement",
"type": "Copy",
"inputs": [
{
"referenceName": "SQLServerDataset",
"type": "DatasetReference"
}
],
"outputs": [
{
"referenceName": "MicrosoftFabricWarehouseDataset",
"type": "DatasetReference"
}
],
"typeProperties": {
"source": {
"type": "SqlSource",
},
"sink": {
"type": "WarehouseSink",
"allowCopyCommand": true
},
"stagingSettings": {
"linkedServiceName": {
"referenceName": "MyStagingStorage",
"type": "LinkedServiceReference"
}
}
}
}
]
Właściwości przepływu mapowania danych
Podczas przekształcania danych w przepływie mapowania danych można odczytywać i zapisywać w tabelach z usługi Microsoft Fabric Warehouse. Aby uzyskać więcej informacji, zobacz przekształcanie źródła i przekształcanie ujścia w przepływach danych mapowania.
Microsoft Fabric Warehouse jako źródło
Ustawienia specyficzne dla usługi Microsoft Fabric Warehouse są dostępne na karcie Opcje źródła przekształcenia źródła.
| Nazwa/nazwisko | opis | Wymagania | Dozwolone wartości | Właściwość skryptu przepływu danych |
|---|---|---|---|---|
| Dane wejściowe | Wybierz, czy wskazujesz źródło w tabeli (odpowiednik polecenia Select * z tabeli tablename), czy wprowadzasz niestandardowe zapytanie SQL, czy pobierasz dane z procedury składowanej. Zapytanie: w przypadku wybrania pozycji Zapytanie w polu wejściowym wprowadź zapytanie SQL dla źródła. To ustawienie zastępuje dowolną tabelę wybraną w zestawie danych. Klauzule Order By nie są obsługiwane w tym miejscu, ale można ustawić pełną instrukcję SELECT FROM. Można również użyć funkcji tabeli zdefiniowanych przez użytkownika. select * from udfGetData() to funkcja zdefiniowana przez użytkownika w języku SQL, która zwraca tabelę. To zapytanie utworzy tabelę źródłową, której można użyć w przepływie danych. Korzystanie z zapytań to również doskonały sposób na zmniejszenie liczby wierszy na potrzeby testowania lub wyszukiwania. Przykład sql: Select * from MyTable where customerId > 1000 and customerId < 2000 |
Tak | Tabela lub kwerenda lub procedura składowana | format: "table" |
| Rozmiar partii | Wprowadź rozmiar partii, aby podzielić duże dane na odczyty. W przepływach danych to ustawienie będzie używane do ustawiania buforowania kolumn platformy Spark. Jest to pole opcji, które będzie używać wartości domyślnych platformy Spark, jeśli pozostanie puste. | Nie. | Wartości liczbowe | batchSize: 1234 |
| Poziom izolacji | Domyślne dla źródeł SQL w przepływie mapowania danych jest odczytywanie niezatwierdzonych. W tym miejscu można zmienić poziom izolacji na jedną z następujących wartości:• Odczyt zatwierdzony • Odczyt niezatwierdzony • Powtarzalny odczyt • Z możliwością serializacji • Brak (ignoruj poziom izolacji) | Tak | • Odczyt zatwierdzony • Odczyt niezatwierdzony • Powtarzalny odczyt • Serializowalny • Brak (ignoruj poziom izolacji) | isolationLevel |
Uwaga
Odczyt za pośrednictwem przemieszczania nie jest obsługiwany. Obsługa usługi CDC dla źródła usługi Microsoft Fabric Warehouse jest obecnie niedostępna.
Microsoft Fabric Warehouse jako ujście
Ustawienia specyficzne dla usługi Microsoft Fabric Warehouse są dostępne na karcie Ustawienia przekształcenia ujścia.
| Nazwa/nazwisko | opis | Wymagania | Dozwolone wartości | Właściwość skryptu przepływu danych |
|---|---|---|---|---|
| Metoda aktualizacji | Określa, jakie operacje są dozwolone w miejscu docelowym bazy danych. Ustawieniem domyślnym jest zezwalanie tylko na wstawianie. Aby zaktualizować, upsert lub usunąć wiersze, do tagowania wierszy dla tych akcji jest wymagane przekształcenie alter-row. W przypadku aktualizacji, operacji upsert i usuwania należy ustawić kolumnę klucza lub kolumny w celu określenia, który wiersz ma zostać zmieniony. | Tak | prawda lub fałsz | możliwość wstawienia możliwego do usunięcia elementu upsertable z możliwością aktualizacji |
| Akcja tabeli | Określa, czy należy ponownie utworzyć lub usunąć wszystkie wiersze z tabeli docelowej przed zapisem.• Brak: Żadna akcja nie zostanie wykonana w tabeli. • Utwórz ponownie: tabela zostanie porzucona i utworzona ponownie. Wymagane w przypadku dynamicznego tworzenia nowej tabeli.• Obcinanie: wszystkie wiersze z tabeli docelowej zostaną usunięte. | Nie. | Brak lub ponowne utworzenie lub obcięcie | recreate: true obcinanie: true |
| Włączanie trybu przejściowego | Magazyn przejściowy jest skonfigurowany w działaniu Wykonaj Przepływ danych. Jeśli używasz uwierzytelniania tożsamości zarządzanej dla połączonej usługi magazynu, zapoznaj się z wymaganymi konfiguracjami odpowiednio dla usług Azure Blob i Azure Data Lake Storage Gen2 . Jeśli usługa Azure Storage jest skonfigurowana z punktem końcowym usługi sieci wirtualnej, musisz użyć uwierzytelniania tożsamości zarządzanej z włączoną funkcją "zezwalaj na zaufaną usługę firmy Microsoft" na koncie magazynu, zapoznaj się z tematem Wpływ używania punktów końcowych usługi sieci wirtualnej z usługą Azure Storage. | Nie. | prawda lub fałsz | etapowe: prawda |
| Rozmiar partii | Określa liczbę wierszy zapisywanych w każdym zasobniku. Większe rozmiary partii zwiększają kompresję i optymalizację pamięci, ale ryzykuj z wyjątków pamięci podczas buforowania danych. | Nie. | Wartości liczbowe | batchSize: 1234 |
| Korzystanie ze schematu ujścia | Domyślnie tabela tymczasowa zostanie utworzona w schemacie ujścia jako tymczasowa. Alternatywnie można usunąć zaznaczenie opcji Użyj schematu ujścia, a zamiast tego w obszarze Wybierz schemat bazy danych użytkownika określ nazwę schematu, w którym usługa Data Factory utworzy tabelę przejściową w celu załadowania danych nadrzędnych i automatycznego czyszczenia ich po zakończeniu. Upewnij się, że masz uprawnienie do tworzenia tabeli w bazie danych i zmień uprawnienia w schemacie. | Nie. | prawda lub fałsz | stagingSchemaName |
| Skrypty pre-sql i post | Wprowadź wielowierszowe skrypty SQL, które będą wykonywane przed (przetwarzanie wstępne) i po (przetwarzaniu po przetworzeniu) dane są zapisywane w bazie danych ujścia | Nie. | Skrypty SQL | preSQLs:['set IDENTITY_INSERT mytable ON'] postSQLs:['set IDENTITY_INSERT mytable OFF'], |
Obsługa wierszy błędów
Domyślnie uruchomienie przepływu danych zakończy się niepowodzeniem podczas pierwszego błędu, który zostanie wyświetlony. Możesz wybrać opcję Kontynuuj przy błędzie, który umożliwia ukończenie przepływu danych, nawet jeśli poszczególne wiersze zawierają błędy. Usługa udostępnia różne opcje obsługi tych wierszy błędów.
Zatwierdzenie transakcji: wybierz, czy dane są zapisywane w jednej transakcji, czy w partiach. Pojedyncza transakcja zapewni lepszą wydajność i żadne zapisane dane nie będą widoczne dla innych do momentu zakończenia transakcji. Transakcje wsadowe mają słabszą wydajność, ale mogą działać w przypadku dużych zestawów danych.
Dane wyjściowe odrzucone: jeśli to ustawienie jest włączone, możesz wyświetlić wiersze błędów w pliku csv w usłudze Azure Blob Storage lub na wybranym koncie usługi Azure Data Lake Storage Gen2. Spowoduje to zapisanie wierszy błędów z trzema dodatkowymi kolumnami: operacją SQL, taką jak INSERT lub UPDATE, kodem błędu przepływu danych i komunikatem o błędzie w wierszu.
Zgłoś powodzenie w przypadku błędu: w przypadku włączenia przepływu danych przepływ danych zostanie oznaczony jako powodzenie, nawet jeśli zostaną znalezione wiersze błędów.
Uwaga
W przypadku połączonej usługi Microsoft Fabric Warehouse obsługiwany typ uwierzytelniania dla jednostki usługi to "Klucz"; Uwierzytelnianie "Certyfikat" nie jest obsługiwane.
Właściwości działania wyszukiwania
Aby dowiedzieć się więcej o właściwościach, sprawdź działanie Wyszukiwania.
Właściwości działania GetMetadata
Aby dowiedzieć się więcej o właściwościach, sprawdź działanie GetMetadata
Mapowanie typów danych dla usługi Microsoft Fabric Warehouse
Podczas kopiowania danych z usługi Microsoft Fabric Warehouse następujące mapowania są używane z typów danych usługi Microsoft Fabric Warehouse do tymczasowych typów danych w ramach usługi wewnętrznie. Aby dowiedzieć się, jak działanie kopiowania mapuje schemat źródłowy i typ danych na ujście, zobacz Mapowania schematu i typu danych.
| Typ danych usługi Microsoft Fabric Warehouse | Typ danych tymczasowych usługi Data Factory |
|---|---|
| bigint | Int64 |
| dane binarne | Bajt[] |
| bitowe | Wartość logiczna |
| char | Ciąg, Znak[] |
| data | DateTime |
| datetime2 | DateTime |
| Dziesiętne | Dziesiętne |
| ATRYBUT FILESTREAM (varbinary(max)) | Bajt[] |
| Liczba zmiennoprzecinkowa | Liczba rzeczywista |
| int | Int32 |
| numeryczne | Dziesiętne |
| rzeczywiste | Pojedynczy |
| smallint | Int16 |
| time | przedział_czasu |
| uniqueidentifier | Identyfikator GUID |
| varbinary | Bajt[] |
| varchar | Ciąg, Znak[] |
Następne kroki
Aby uzyskać listę magazynów danych obsługiwanych jako źródła i ujścia działania kopiowania, zobacz Obsługiwane magazyny danych.