Monitorowanie usługi Azure Data Explorer
Usługa Azure Monitor zbiera i agreguje metryki i dzienniki z systemu w celu monitorowania dostępności, wydajności i odporności oraz powiadamiania o problemach wpływających na system. Do konfigurowania i wyświetlania danych monitorowania można użyć witryny Azure Portal, programu PowerShell, interfejsu wiersza polecenia platformy Azure, interfejsu API REST lub bibliotek klienckich.
Różne metryki i dzienniki są dostępne dla różnych typów zasobów. W tym artykule opisano typy danych monitorowania, które można zbierać dla tej usługi i sposoby analizowania tych danych.
Zbieranie danych za pomocą usługi Azure Monitor
W tej tabeli opisano sposób zbierania danych w celu monitorowania usługi oraz czynności, które można wykonać z danymi po zebraniu:
| Dane do zbierania | Opis | Jak zbierać i kierować dane | Gdzie wyświetlić dane | Obsługiwane dane |
|---|---|---|---|---|
| Dane metryczne | Metryki to wartości liczbowe, które opisują aspekt systemu w określonym punkcie w czasie. Metryki mogą być agregowane przy użyciu algorytmów, w porównaniu z innymi metrykami i analizowane pod kątem trendów w czasie. | — Zbierane automatycznie w regularnych odstępach czasu.
— możesz kierować niektóre metryki platformy do obszaru roboczego usługi Log Analytics w celu wykonywania zapytań o inne dane. Sprawdź ustawienie eksportowania DS dla każdej metryki, aby sprawdzić, czy możesz użyć ustawienia diagnostycznego do kierowania danymi metryk. |
eksplorator metryk | metryki usługi Azure Data Explorer obsługiwane przez usługę Azure Monitor |
| Dane dziennika zasobów | Zdarzenia systemowe są rejestrowane w dziennikach z przypisanym znacznikiem czasu. Dzienniki mogą zawierać różne typy danych i mieć strukturę lub dowolny tekst. Dane dziennika zasobów można kierować do obszarów roboczych usługi Log Analytics na potrzeby wykonywania zapytań i analizy. | Utwórz ustawienie diagnostyczne do zbierania i kierowania danych dziennika zasobów. | Log Analytics | danych dziennika zasobów usługi Azure Data Explorer obsługiwanych przez usługę Azure Monitor |
| Dane dziennika aktywności | Dziennik aktywności usługi Azure Monitor zapewnia wgląd w zdarzenia na poziomie subskrypcji. Dziennik aktywności zawiera informacje, takie jak po zmodyfikowaniu zasobu lub uruchomieniu maszyny wirtualnej. | — Zbierane automatycznie.
- Utwórz ustawienie diagnostyczne do obszaru roboczego usługi Log Analytics bez opłat. |
dziennika aktywności |
Aby uzyskać listę wszystkich danych obsługiwanych przez usługę Azure Monitor, zobacz:
Wbudowane monitorowanie dla usługi Azure Data Explorer
Usługa Azure Data Explorer oferuje metryki i dzienniki do monitorowania usługi.
Monitorowanie wydajności, kondycji i użycia usługi Azure Data Explorer za pomocą metryk
Metryki usługi Azure Data Explorer zapewniają kluczowe wskaźniki dotyczące kondycji i wydajności zasobów klastra usługi Azure Data Explorer. Użyj metryk, aby monitorować użycie, kondycję i wydajność klastra usługi Azure Data Explorer w określonym scenariuszu jako metryki autonomiczne. Możesz również użyć metryk jako podstawy dla operacyjnych pulpitów nawigacyjnych platformy Azure i alertów platformy Azure.
Aby użyć metryk do monitorowania zasobów usługi Azure Data Explorer w witrynie Azure Portal:
- Zaloguj się do portalu Azure.
- W okienku po lewej stronie twojego klastra Azure Data Explorer wyszukaj metryki .
- Wybierz pozycję Metrics, żeby otworzyć okienko metryk i rozpocząć analizę w Twoim klastrze.
W okienku metryk wybierz określone metryki do śledzenia, wybierz sposób agregowania danych i tworzenie wykresów metryk do wyświetlenia na pulpicie nawigacyjnym.
Selektory
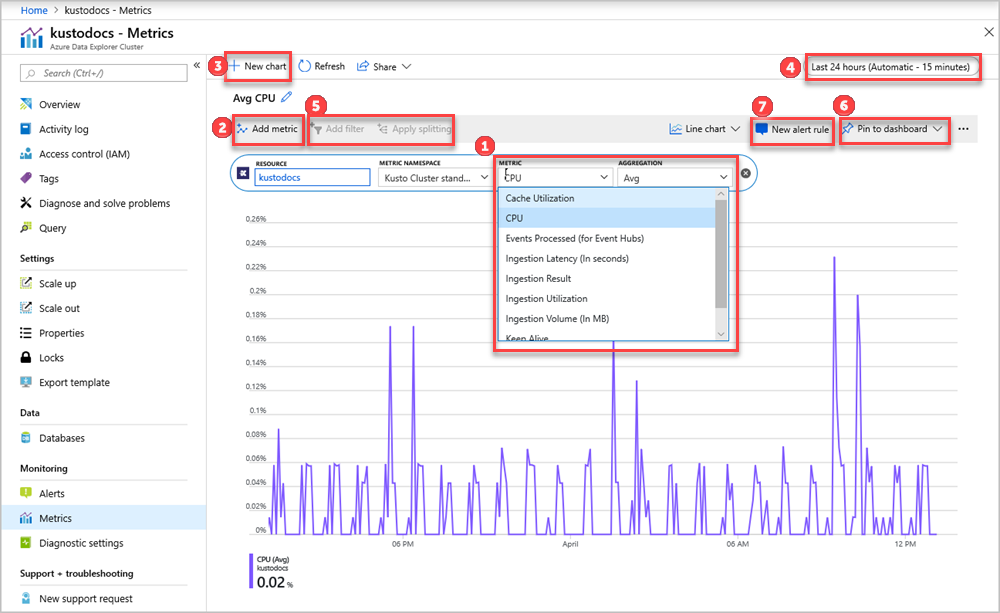
- Aby utworzyć wykres metryki, wybierz nazwę Metryki i odpowiednią agregację dla metryki. Aby uzyskać więcej informacji na temat różnych metryk, zobacz obsługiwane metryki usługi Azure Data Explorer.
- Wybierz Dodaj metrykę, aby zobaczyć wiele metryk wykreślonych na tym samym wykresie.
- Wybierz pozycję + Nowy wykres, aby wyświetlić wiele wykresów w jednym widoku.
- Użyj selektora czasu, aby zmienić zakres czasu (wartość domyślna: ostatnie 24 godziny).
- Użyj , dodaj filtr i , zastosuj dzielenie dla metryk, które mają wymiary.
- Wybierz pozycję Przypnij do pulpitu nawigacyjnego, aby dodać konfigurację wykresu do pulpitów nawigacyjnych, aby można było wyświetlić go ponownie.
- Aby wizualizować swoje metryki za pomocą ustawionych kryteriów, skonfiguruj nową regułę alertu . Nowa reguła alertów zawiera zasób docelowy, metrykę, kryteria podziału oraz wymiary filtra z wykresu. Zmodyfikuj te ustawienia w okienku tworzenia reguły alertu .
Monitoruj pozyskiwanie, polecenia, zapytania i tabele w usłudze Azure Data Explorer za pomocą dzienników diagnostycznych
Azure Data Explorer to szybka, w pełni zarządzana usługa analizy danych na potrzeby analizy danych w czasie rzeczywistym na dużych ilościach danych przesyłanych strumieniowo z aplikacji, witryn internetowych, urządzeń IoT i innych. Dzienniki diagnostyczne Azure Monitor udostępniają dane dotyczące działania zasobów Azure. Usługa Azure Data Explorer używa dzienników diagnostycznych w celu uzyskania szczegółowych informacji na temat pozyskiwania, poleceń, zapytań i tabel. Dzienniki operacji można eksportować do usługi Azure Storage, centrum zdarzeń lub usługi Log Analytics, aby monitorować pozyskiwanie, polecenia i stan zapytania. Dzienniki z usług Azure Storage i Azure Event Hubs można kierować do tabeli w klastrze usługi Azure Data Explorer w celu dalszej analizy.
Ważny
Dane dziennika diagnostycznego mogą zawierać poufne dane. Ogranicz uprawnienia miejsca docelowego dzienników zgodnie z potrzebami monitorowania.
Notatka
W portalu Azure nieprzetworzone dane metryk dla stron Metryki i Wgląd są przechowywane w usłudze Azure Monitor. Zapytania na tych stronach bezpośrednio wysyłają zapytania o surowe dane metryk, aby zapewnić najdokładniejsze wyniki. W przypadku korzystania z funkcji ustawień diagnostycznych można migrować nieprzetworzone dane metryk do obszaru roboczego usługi Log Analytics. Podczas migracji niektóre precyzje danych mogą zostać utracone z powodu zaokrąglania; w związku z tym wyniki zapytania mogą się nieznacznie różnić od oryginalnych danych. Margines błędu jest mniejszy niż jeden procent.
Dzienniki diagnostyczne mogą być użyte do skonfigurowania zbierania następujących danych dziennika:
Notatka
- Dzienniki pozyskiwania są obsługiwane w przypadku pozyskiwania w kolejce do identyfikatora URI pozyskiwania danych przy użyciu bibliotek klienckich usługi Kusto i łączników danych .
- Dzienniki pozyskiwania nie są obsługiwane w przypadku pozyskiwania danych przesyłanych strumieniowo, bezpośredniego pozyskiwania do identyfikatora URI klastra, pozyskiwania z zapytania lub poleceń
.set-or-append.
Notatka
Dzienniki operacji pobierania danych zakończone niepowodzeniem są zgłaszane tylko dla ostatecznego stanu operacji pobierania danych, w przeciwieństwie do metryki wyniku pozyskiwania , która jest emitowana dla przejściowych błędów ponawianych wewnętrznie.
- Pomyślne operacje pozyskiwania: te dzienniki zawierają informacje o pomyślnym zakończeniu operacji pozyskiwania.
- Nieudane operacje pobierania danych: te dzienniki zawierają szczegółowe informacje na temat nieudanych operacji pobierania, w tym szczegóły błędu.
- operacje wsadowego przesyłania: te dzienniki zawierają szczegółowe statystyki partii gotowych do przesyłania (czas trwania, rozmiar partii, liczba blobów i typy wsadowania ).
Możesz wysłać dane dziennika do obszaru roboczego usługi Log Analytics, konta magazynu lub przesłać je strumieniowo do centrum zdarzeń.
Dzienniki diagnostyczne są domyślnie wyłączone. Aby włączyć dzienniki diagnostyczne dla klastra, wykonaj następujące czynności:
W witrynie Azure Portalwybierz zasób klastra, który chcesz monitorować.
W obszarze Monitorowaniewybierz Ustawienia diagnostyczne .
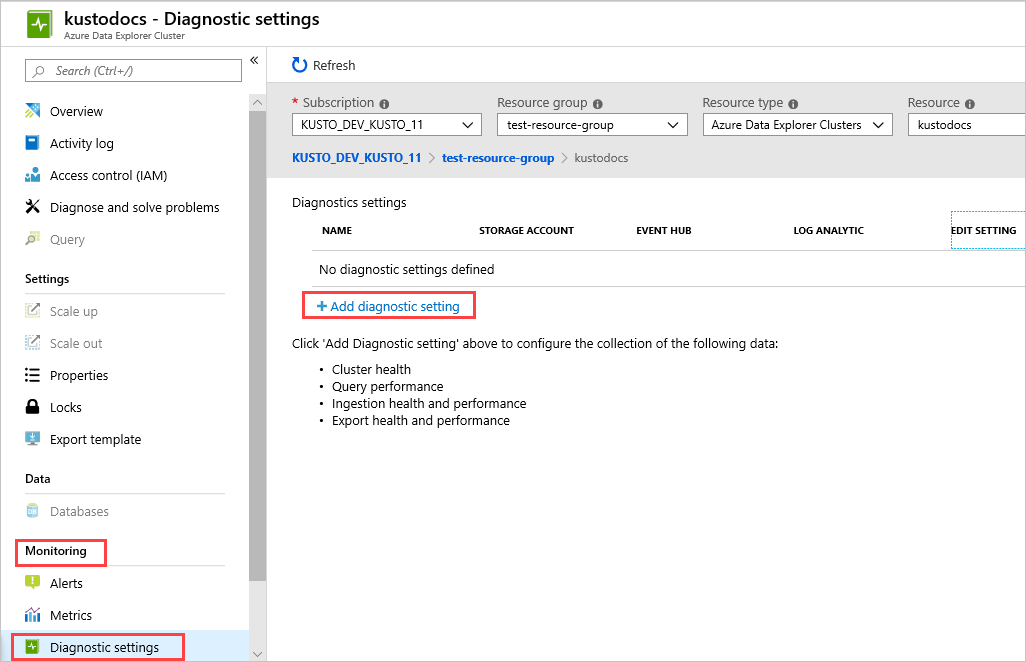
Wybierz pozycję Dodaj ustawienie diagnostyczne.
W oknie ustawień diagnostycznych:
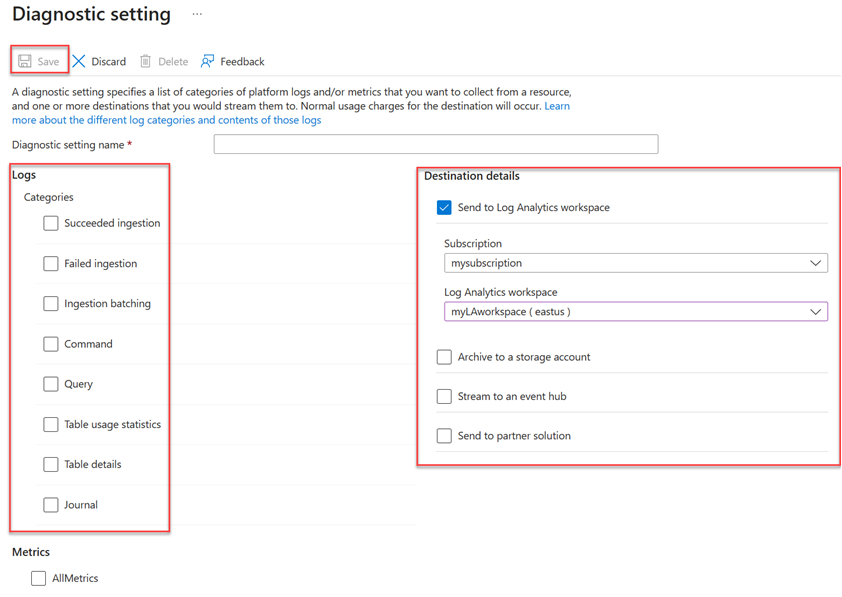
- Wprowadź nazwę ustawienia diagnostycznego .
- Wybierz co najmniej jeden cel dla miejsca docelowego: Log Analytics workspace, konto magazynowe lub centrum zdarzeń.
- Wybierz dzienniki do zebrania: zakończone powodzeniem pozyskiwanie, pozyskiwanie niepowodzeniem, pozyskiwanie wsadowe, komenda, zapytanie, statystyki użycia tabeli, szczegóły tabeli, lub dziennik.
- Wybierz metryki do zebrania (opcjonalnie).
- Wybierz pozycję Zapisz, aby zapisać nowe ustawienia i metryki dzienników diagnostycznych.
Gdy ustawienia będą gotowe, dzienniki zaczynają pojawiać się w skonfigurowanych miejscach docelowych: koncie magazynu, centrum zdarzeń lub obszarze roboczym usługi Log Analytics.
Notatka
Jeśli wysyłasz dzienniki do obszaru roboczego usługi Log Analytics, dzienniki SucceededIngestion, FailedIngestion, IngestionBatching, Command, Query, TableUsageStatistics, TableDetailsi Journal są przechowywane w tabelach usługi Log Analytics o nazwie: SucceededIngestion, FailedIngestion, ADXIngestionBatching, ADXCommand, ADXQuery, ADXTableUsageStatistics, ADXTableDetailsi ADXJournal.
Analizowanie danych przy użyciu narzędzi usługi Azure Monitor
Te narzędzia usługi Azure Monitor są dostępne w witrynie Azure Portal, aby ułatwić analizowanie danych monitorowania:
Niektóre usługi platformy Azure mają wbudowany pulpit nawigacyjny monitorowania w witrynie Azure Portal. Te pulpity nawigacyjne są nazywane szczegółowych informacjii można je znaleźć w sekcji Insights usługi Azure Monitor w witrynie Azure Portal.
Eksplorator metryk umożliwia wyświetlanie i analizowanie metryk dla zasobów platformy Azure. Aby uzyskać więcej informacji, zobacz Analizowanie metryk za pomocą eksploratora metryk usługi Azure Monitor.
Log Analytics umożliwia wykonywanie zapytań i analizowanie danych dziennika przy użyciu języka zapytań Kusto (KQL). Aby uzyskać więcej informacji, zobacz Rozpoczynanie pracy z zapytaniami dzienników w usłudze Azure Monitor.
Portal Azure ma interfejs użytkownika do przeglądania i podstawowego wyszukiwania w dzienniku aktywności . Aby przeprowadzić bardziej szczegółową analizę, należy kierować dane do dzienników usługi Azure Monitor i uruchamiać bardziej złożone zapytania w usłudze Log Analytics.
application insights monitoruje dostępność, wydajność i użycie aplikacji internetowych, dzięki czemu można identyfikować i diagnozować błędy bez oczekiwania na ich zgłaszanie przez użytkownika.
Application Insights zawiera punkty połączenia z różnymi narzędziami programistycznymi i integruje się z programem Visual Studio w celu obsługi procesów DevOps. Aby uzyskać więcej informacji, zobacz Monitorowanie aplikacji dla usługi App Service.
Narzędzia, które umożliwiają bardziej złożoną wizualizację, obejmują:
- Pulpity nawigacyjne, które umożliwiają łączenie różnych rodzajów danych w jednym okienku w witrynie Azure Portal.
- Skoroszyty, dostosowywalne raporty, które można tworzyć w usłudze Azure Portal. Skoroszyty mogą zawierać tekst, metryki i zapytania dziennika.
- Grafana, otwarta platforma narzędziowa, która wyróżnia się na pulpitach nawigacyjnych do monitorowania działania. Za pomocą narzędzia Grafana można tworzyć pulpity nawigacyjne zawierające dane z wielu źródeł innych niż usługa Azure Monitor.
- Power BI, usługę analizy biznesowej, która udostępnia interaktywne wizualizacje z różnych źródeł danych. Usługę Power BI można skonfigurować tak, aby automatycznie importować dane dziennika z usługi Azure Monitor, aby korzystać z tych wizualizacji.
Eksportowanie danych usługi Azure Monitor
Dane z usługi Azure Monitor można wyeksportować do innych narzędzi przy użyciu:
Metryki: Użyj REST API dla metryk, aby wyodrębnić dane metryczne z bazy danych metryk Azure Monitor. Aby uzyskać więcej informacji, zobacz Dokumentacja interfejsu API REST usługi Azure Monitor.
Dzienniki: Użyj REST API lub odpowiednich bibliotek klienckich.
eksportowanie danych z obszaru roboczego usługi Log Analytics.
Aby rozpocząć pracę z interfejsem API REST usługi Azure Monitor, zobacz przewodnik po interfejsie API REST monitorowania platformy Azure.
Używanie zapytań Kusto do analizowania danych dziennika
Dane dziennika usługi Azure Monitor można analizować przy użyciu języka zapytań Kusto (KQL). Aby uzyskać więcej informacji, zobacz Zapytania dziennika w usłudze Azure Monitor.
Używanie alertów usługi Azure Monitor do powiadamiania o problemach
alerty usługi Azure Monitor umożliwiają identyfikowanie i rozwiązywanie problemów w systemie oraz proaktywne powiadamianie o znalezieniu określonych warunków w danych monitorowania przed ich zauważeniem przez klientów. Możesz otrzymywać alerty dotyczące dowolnej metryki lub źródła danych dziennika na platformie danych usługi Azure Monitor. Istnieją różne typy alertów usługi Azure Monitor w zależności od usług, które monitorujesz i zbieranych danych monitorowania. Zobacz Wybieranie odpowiedniego typu reguły alertu.
Przykłady typowych alertów dotyczących zasobów platformy Azure można znaleźć w temacie Przykładowe zapytania alertów dziennika.
Implementowanie alertów na dużą skalę
W przypadku niektórych usług można monitorować na dużą skalę, stosując tę samą regułę alertu dotyczącego metryki do wielu zasobów tego samego typu, które istnieją w tym samym regionie Azure. Alerty bazowe usługi Azure Monitor (AMBA) udostępniają częściowo zautomatyzowaną metodę wdrażania ważnych alertów metryk platformy, dashboardów i wytycznych na dużą skalę.
Uzyskiwanie spersonalizowanych zaleceń przy użyciu usługi Azure Advisor
W przypadku niektórych usług, jeśli w portalu podczas operacji zasobów wystąpią krytyczne warunki lub nieuchronne zmiany, na stronie Przegląd usługi zostanie wyświetlony alert. Więcej informacji i zalecanych poprawek alertu można znaleźć w rekomendacji usługi
Aby uzyskać więcej informacji na temat usługi Azure Advisor, zobacz Omówienie usługi Azure Advisor.