Azure Machine Edukacja najlepsze rozwiązania dotyczące zabezpieczeń przedsiębiorstwa
W tym artykule opisano najlepsze rozwiązania w zakresie zabezpieczeń dotyczące planowania i zarządzania bezpiecznym wdrożeniem usługi Azure Machine Edukacja. Najlepsze rozwiązania pochodzą z firmy Microsoft i środowiska klienta z usługą Azure Machine Edukacja. Poszczególne wytyczne wyjaśniają praktykę i jej uzasadnienie. Artykuł zawiera również linki do dokumentacji z instrukcjami i dokumentacją referencyjną.
Zalecana architektura zabezpieczeń sieci (sieć zarządzana)
Zalecana architektura zabezpieczeń sieci uczenia maszynowego to zarządzana sieć wirtualna. Usługa Azure Machine Edukacja zarządzana sieć wirtualna zabezpiecza obszar roboczy, skojarzone zasoby platformy Azure i wszystkie zarządzane zasoby obliczeniowe. Upraszcza konfigurację zabezpieczeń sieci i zarządzanie nimi przez wstępne skonfigurowanie wymaganych danych wyjściowych i automatyczne tworzenie zarządzanych zasobów w sieci. Za pomocą prywatnych punktów końcowych można zezwolić usługom platformy Azure na dostęp do sieci i opcjonalnie zdefiniować reguły ruchu wychodzącego, aby umożliwić sieci dostęp do Internetu.
Zarządzana sieć wirtualna ma dwa tryby, dla których można skonfigurować:
Zezwalaj na ruch wychodzący z Internetu — ten tryb umożliwia komunikację wychodzącą z zasobami znajdującymi się w Internecie, takimi jak publiczne repozytoria pakietów PyPi lub Anaconda.

Zezwalaj tylko na zatwierdzony ruch wychodzący — ten tryb zezwala tylko na minimalną komunikację wychodzącą wymaganą do działania obszaru roboczego. Ten tryb jest zalecany w przypadku obszarów roboczych, które muszą być odizolowane od Internetu. Lub tam, gdzie dostęp wychodzący jest dozwolony tylko do określonych zasobów za pośrednictwem punktów końcowych usługi, tagów usługi lub w pełni kwalifikowanych nazw domen.

Aby uzyskać więcej informacji, zobacz Zarządzana izolacja sieci wirtualnej.
Zalecana architektura zabezpieczeń sieci (Azure Virtual Network)
Jeśli nie możesz używać zarządzanej sieci wirtualnej ze względu na wymagania biznesowe, możesz użyć sieci wirtualnej platformy Azure z następującymi podsieciami:
- Trenowanie zawiera zasoby obliczeniowe używane do trenowania, takie jak wystąpienia obliczeniowe uczenia maszynowego lub klastry obliczeniowe.
- Ocenianie zawiera zasoby obliczeniowe używane do oceniania, takie jak usługa Azure Kubernetes Service (AKS).
- Zapora zawiera zaporę, która zezwala na ruch do i z publicznego Internetu, na przykład z usługi Azure Firewall.
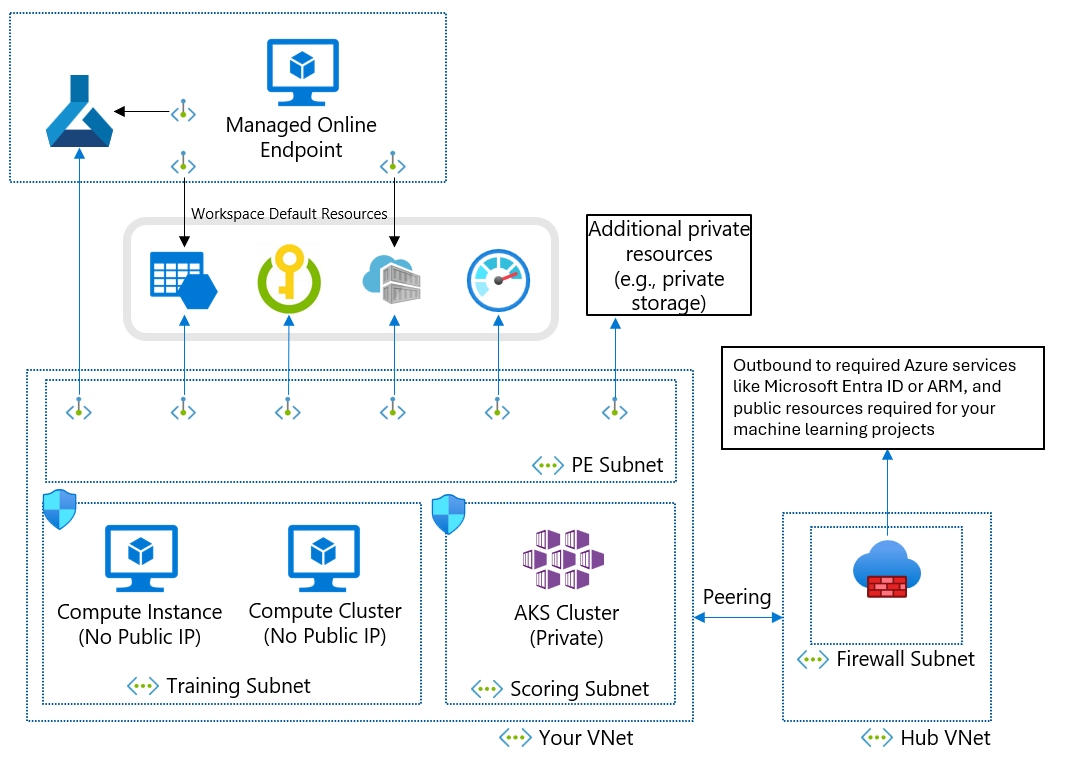
Sieć wirtualna zawiera również prywatny punkt końcowy dla obszaru roboczego uczenia maszynowego i następujące usługi zależne:
- Konto usługi Azure Storage
- Azure Key Vault
- Azure Container Registry
Komunikacja wychodząca z sieci wirtualnej musi być w stanie nawiązać połączenie z następującymi usługi firmy Microsoft:
- Uczenie maszynowe
- Microsoft Entra ID
- Usługa Azure Container Registry i określone rejestry obsługiwane przez firmę Microsoft
- Azure Front Door
- Azure Resource Manager
- Azure Storage
Klienci zdalni łączą się z siecią wirtualną przy użyciu usługi Azure ExpressRoute lub połączenia wirtualnej sieci prywatnej (VPN).
Projekt sieci wirtualnej i prywatnego punktu końcowego
Podczas projektowania sieci wirtualnej platformy Azure, podsieci i prywatnych punktów końcowych należy wziąć pod uwagę następujące wymagania:
Ogólnie rzecz biorąc, utwórz oddzielne podsieci na potrzeby trenowania i oceniania oraz użyj podsieci szkoleniowej dla wszystkich prywatnych punktów końcowych.
W przypadku adresowania IP wystąpienia obliczeniowe potrzebują jednego prywatnego adresu IP. Klastry obliczeniowe potrzebują jednego prywatnego adresu IP na węzeł. Klastry usługi AKS potrzebują wielu prywatnych adresów IP, zgodnie z opisem w temacie Planowanie adresowania IP dla klastra usługi AKS. Oddzielna podsieć dla co najmniej usługi AKS pomaga zapobiec wyczerpaniu adresów IP.
Zasoby obliczeniowe w podsieciach trenowania i oceniania muszą uzyskiwać dostęp do konta magazynu, magazynu kluczy i rejestru kontenerów. Utwórz prywatne punkty końcowe dla konta magazynu, magazynu kluczy i rejestru kontenerów.
Domyślny magazyn obszaru roboczego uczenia maszynowego wymaga dwóch prywatnych punktów końcowych: jednego dla usługi Azure Blob Storage i drugiego dla usługi Azure File Storage.
Jeśli używasz usługi Azure Machine Edukacja Studio, prywatne punkty końcowe obszaru roboczego i magazynu powinny znajdować się w tej samej sieci wirtualnej.
Jeśli masz wiele obszarów roboczych, użyj sieci wirtualnej dla każdego obszaru roboczego, aby utworzyć jawną granicę sieci między obszarami roboczymi.
Używanie prywatnych adresów IP
Prywatne adresy IP minimalizują narażenie zasobów platformy Azure na Internet. Uczenie maszynowe korzysta z wielu zasobów platformy Azure, a prywatny punkt końcowy obszaru roboczego uczenia maszynowego nie jest wystarczający dla kompleksowego prywatnego adresu IP. W poniższej tabeli przedstawiono główne zasoby używane przez uczenie maszynowe i sposób włączania prywatnego adresu IP dla zasobów. Wystąpienia obliczeniowe i klastry obliczeniowe to jedyne zasoby, które nie mają funkcji prywatnego adresu IP.
| Zasoby | Rozwiązanie prywatnego adresu IP | Dokumentacja |
|---|---|---|
| Obszar roboczy | Prywatny punkt końcowy | Konfigurowanie prywatnego punktu końcowego dla obszaru roboczego usługi Azure Machine Learning |
| Rejestr | Prywatny punkt końcowy | Izolacja sieci za pomocą rejestrów usługi Azure Machine Edukacja |
| Skojarzone zasoby | ||
| Storage | Prywatny punkt końcowy | Zabezpieczanie kont usługi Azure Storage przy użyciu punktów końcowych usługi |
| Key Vault | Prywatny punkt końcowy | Zabezpieczanie usługi Azure Key Vault |
| Container Registry | Prywatny punkt końcowy | Włączanie usługi Azure Container Registry |
| Zasoby szkoleniowe | ||
| Wystąpienie obliczeniowe | Prywatny adres IP (bez publicznego adresu IP) | Zabezpieczanie środowisk szkoleniowych |
| Klaster obliczeniowy | Prywatny adres IP (bez publicznego adresu IP) | Zabezpieczanie środowisk szkoleniowych |
| Hostowanie zasobów | ||
| Zarządzany punkt końcowy online | Prywatny punkt końcowy | Izolacja sieci z zarządzanymi punktami końcowymi online |
| Punkt końcowy online (Kubernetes) | Prywatny punkt końcowy | Zabezpieczanie punktów końcowych online usługi Azure Kubernetes Service |
| Punkty końcowe usługi Batch | Prywatny adres IP (dziedziczony z klastra obliczeniowego) | Izolacja sieci w punktach końcowych wsadowych |
Kontrolowanie ruchu przychodzącego i wychodzącego sieci wirtualnej
Użyj zapory lub sieciowej grupy zabezpieczeń platformy Azure do kontrolowania ruchu przychodzącego i wychodzącego sieci wirtualnej. Aby uzyskać więcej informacji na temat wymagań dotyczących ruchu przychodzącego i wychodzącego, zobacz Configure inbound and outbound network traffic (Konfigurowanie ruchu przychodzącego i wychodzącego). Aby uzyskać więcej informacji na temat przepływów ruchu między składnikami, zobacz Przepływ ruchu sieciowego w zabezpieczonym obszarze roboczym.
Zapewnianie dostępu do obszaru roboczego
Aby upewnić się, że prywatny punkt końcowy może uzyskać dostęp do obszaru roboczego uczenia maszynowego, wykonaj następujące kroki:
Upewnij się, że masz dostęp do sieci wirtualnej przy użyciu połączenia sieci VPN, usługi ExpressRoute lub maszyny wirtualnej przesiadkowej z dostępem do usługi Azure Bastion. Użytkownik publiczny nie może uzyskać dostępu do obszaru roboczego uczenia maszynowego za pomocą prywatnego punktu końcowego, ponieważ jest on dostępny tylko z sieci wirtualnej. Aby uzyskać więcej informacji, zobacz Zabezpieczanie obszaru roboczego za pomocą sieci wirtualnych.
Upewnij się, że możesz rozpoznać w pełni kwalifikowane nazwy domen obszaru roboczego (FQDN) przy użyciu prywatnego adresu IP. Jeśli używasz własnego serwera systemu nazw domen (DNS) lub scentralizowanej infrastruktury DNS, musisz skonfigurować usługę przesyłania dalej DNS. Aby uzyskać więcej informacji, zobacz Jak używać obszaru roboczego z niestandardowym serwerem DNS.
Zarządzanie dostępem do obszaru roboczego
Podczas definiowania tożsamości uczenia maszynowego i kontroli zarządzania dostępem można oddzielić mechanizmy kontroli definiujące dostęp do zasobów platformy Azure od kontrolek, które zarządzają dostępem do zasobów danych. W zależności od przypadku użycia rozważ użycie samoobsługi, skoncentrowanej na danych lub zarządzania tożsamościami i dostępem skoncentrowanym na projekcie.
Wzorzec samoobsługi
We wzorcu samoobsługowym analitycy danych mogą tworzyć obszary robocze i zarządzać nimi. Ten wzorzec najlepiej nadaje się do sytuacji weryfikacji koncepcji wymagających elastyczności w celu wypróbowania różnych konfiguracji. Wadą jest to, że analitycy danych potrzebują wiedzy, aby aprowizować zasoby platformy Azure. Takie podejście jest mniej odpowiednie, gdy wymagana jest ścisła kontrola, użycie zasobów, ślady inspekcji i dostęp do danych.
Zdefiniuj zasady platformy Azure, aby ustawić zabezpieczenia aprowizacji i użycia zasobów, takie jak dozwolone rozmiary klastrów i typy maszyn wirtualnych.
Utwórz grupę zasobów do przechowywania obszarów roboczych i przyznaj analitykom danych rolę Współautor w grupie zasobów.
Analitycy danych mogą teraz tworzyć obszary robocze i kojarzyć zasoby w grupie zasobów w sposób samoobsługowy.
Aby uzyskać dostęp do magazynu danych, utwórz tożsamości zarządzane przypisane przez użytkownika i przyznaj tożsamościom role dostępu do odczytu w magazynie.
Gdy analitycy danych tworzą zasoby obliczeniowe, mogą przypisać tożsamości zarządzane do wystąpień obliczeniowych w celu uzyskania dostępu do danych.
Aby uzyskać najlepsze rozwiązania, zobacz Uwierzytelnianie na potrzeby analizy w skali chmury.
Wzorzec skoncentrowany na danych
We wzorcu skoncentrowanym na danych obszar roboczy należy do jednego analityka danych, który może pracować nad wieloma projektami. Zaletą tego podejścia jest to, że analityk danych może ponownie używać kodu lub potoków szkoleniowych w projektach. Jeśli obszar roboczy jest ograniczony do jednego użytkownika, dostęp do danych można prześledzić z powrotem do tego użytkownika podczas inspekcji dzienników magazynu.
Wadą jest to, że dostęp do danych nie jest z podziałem na przedziały ani ograniczony dla poszczególnych projektów, a każdy użytkownik dodany do obszaru roboczego może uzyskać dostęp do tych samych zasobów.
Utwórz obszar roboczy.
Utwórz zasoby obliczeniowe z włączonymi tożsamościami zarządzanymi przypisanymi przez system.
Gdy analityk danych potrzebuje dostępu do danych dla danego projektu, przyznaj dostęp do odczytu tożsamości zarządzanej obliczeniowej do danych.
Udziel tożsamości zarządzanej obliczeniowej dostępu do innych wymaganych zasobów, takich jak rejestr kontenerów z niestandardowymi obrazami platformy Docker na potrzeby trenowania.
Przyznaj również rolę dostępu do odczytu tożsamości zarządzanej obszaru roboczego na danych w celu włączenia podglądu danych.
Udziel analitykowi danych dostępu do obszaru roboczego.
Analityk danych może teraz tworzyć magazyny danych w celu uzyskiwania dostępu do danych wymaganych dla projektów i przesyłania przebiegów szkoleniowych korzystających z danych.
Opcjonalnie utwórz grupę zabezpieczeń Entra firmy Microsoft i przyznaj jej dostęp do odczytu do danych, a następnie dodaj tożsamości zarządzane do grupy zabezpieczeń. Takie podejście zmniejsza liczbę bezpośrednich przypisań ról w zasobach, aby uniknąć osiągnięcia limitu subskrypcji dla przypisań ról.
Wzorzec skoncentrowany na projekcie
Wzorzec skoncentrowany na projekcie tworzy obszar roboczy uczenia maszynowego dla określonego projektu, a wielu analityków danych współpracuje w ramach tego samego obszaru roboczego. Dostęp do danych jest ograniczony do konkretnego projektu, dzięki czemu podejście jest odpowiednie do pracy z danymi poufnymi. Ponadto proste jest dodawanie lub usuwanie analityków danych z projektu.
Wadą tego podejścia jest to, że udostępnianie zasobów w projektach może być trudne. Śledzenie dostępu do danych do określonych użytkowników podczas inspekcji jest również trudne.
Tworzenie obszaru roboczego
Zidentyfikuj wystąpienia magazynu danych wymagane dla projektu, utwórz tożsamość zarządzaną przypisaną przez użytkownika i przyznaj tożsamości dostęp do odczytu do magazynu.
Opcjonalnie przyznaj tożsamości zarządzanej obszaru roboczego dostęp do magazynu danych, aby umożliwić wyświetlanie podglądu danych. Możesz pominąć ten dostęp dla poufnych danych, które nie są odpowiednie dla wersji zapoznawczej.
Tworzenie magazynów danych bez poświadczeń dla zasobów magazynu.
Utwórz zasoby obliczeniowe w obszarze roboczym i przypisz tożsamość zarządzaną do zasobów obliczeniowych.
Udziel tożsamości zarządzanej obliczeniowej dostępu do innych wymaganych zasobów, takich jak rejestr kontenerów z niestandardowymi obrazami platformy Docker na potrzeby trenowania.
Udziel analitykom danych pracę nad projektem rolą w obszarze roboczym.
Korzystając z kontroli dostępu opartej na rolach (RBAC) platformy Azure, można ograniczyć analitykom danych możliwość tworzenia nowych magazynów danych lub nowych zasobów obliczeniowych przy użyciu różnych tożsamości zarządzanych. Ta praktyka uniemożliwia dostęp do danych, które nie są specyficzne dla projektu.
Opcjonalnie, aby uprościć zarządzanie członkostwem w projekcie, możesz utworzyć grupę zabezpieczeń Firmy Microsoft dla członków projektu i udzielić grupie dostępu do obszaru roboczego.
Usługa Azure Data Lake Storage z przekazywaniem poświadczeń
Tożsamość użytkownika firmy Microsoft Entra umożliwia dostęp do magazynu interakcyjnego z usługi Machine Learning Studio. Usługa Data Lake Storage z włączoną hierarchiczną przestrzenią nazw umożliwia rozszerzoną organizację zasobów danych na potrzeby magazynowania i współpracy. Dzięki hierarchicznej przestrzeni nazw usługi Data Lake Storage można podzielić dostęp do danych, zapewniając różnym użytkownikom dostęp do listy kontroli dostępu (ACL) do różnych folderów i plików. Na przykład można przyznać tylko podzestawowi użytkowników dostęp do poufnych danych.
Kontrola dostępu oparta na rolach i role niestandardowe
Kontrola dostępu oparta na rolach platformy Azure pomaga zarządzać osobami mającymi dostęp do zasobów uczenia maszynowego i konfigurować, kto może wykonywać operacje. Na przykład możesz przyznać tylko określonym użytkownikom rolę administratora obszaru roboczego do zarządzania zasobami obliczeniowymi.
Zakres dostępu może się różnić między środowiskami. W środowisku produkcyjnym możesz ograniczyć możliwość aktualizowania punktów końcowych wnioskowania przez użytkowników. Zamiast tego możesz przyznać to uprawnienie autoryzowanej jednostce usługi.
Uczenie maszynowe ma kilka ról domyślnych: właściciel, współautor, czytelnik i analityk danych. Możesz również utworzyć własne role niestandardowe, na przykład aby utworzyć uprawnienia odzwierciedlające strukturę organizacyjną. Aby uzyskać więcej informacji, zobacz Zarządzanie dostępem do obszaru roboczego usługi Azure Machine Edukacja.
Z czasem skład zespołu może ulec zmianie. Jeśli tworzysz grupę Entra firmy Microsoft dla każdej roli zespołu i obszaru roboczego, możesz przypisać rolę RBAC platformy Azure do grupy Microsoft Entra oraz oddzielnie zarządzać dostępem do zasobów i grupami użytkowników.
Jednostki użytkownika i jednostki usługi mogą być częścią tej samej grupy firmy Microsoft Entra. Na przykład podczas tworzenia tożsamości zarządzanej przypisanej przez użytkownika używanej przez usługę Azure Data Factory do wyzwalania potoku uczenia maszynowego można dołączyć tożsamość zarządzaną w grupie wykonawczej potoków uczenia maszynowego firmy Microsoft.
Centralne zarządzanie obrazami platformy Docker
Usługa Azure Machine Edukacja udostępnia wyselekcjonowane obrazy platformy Docker, których można użyć do trenowania i wdrażania. Jednak wymagania dotyczące zgodności przedsiębiorstwa mogą być wymagane przy użyciu obrazów z prywatnego repozytorium zarządzanego przez firmę. Uczenie maszynowe ma dwa sposoby korzystania z centralnego repozytorium:
Użyj obrazów z centralnego repozytorium jako obrazów podstawowych. Zarządzanie środowiskiem uczenia maszynowego instaluje pakiety i tworzy środowisko języka Python, w którym jest uruchamiany kod trenowania lub wnioskowania. Dzięki temu podejściu można łatwo aktualizować zależności pakietów bez modyfikowania obrazu podstawowego.
Używaj obrazów w sposób as-is, bez korzystania z zarządzania środowiskiem uczenia maszynowego. Takie podejście zapewnia wyższy stopień kontroli, ale także wymaga starannego konstruowania środowiska języka Python w ramach obrazu. Aby uruchomić kod, musisz spełnić wszystkie niezbędne zależności, a wszystkie nowe zależności wymagają ponownego skompilowania obrazu.
Aby uzyskać więcej informacji, zobacz Zarządzanie środowiskami.
Szyfrowanie danych
Dane uczenia maszynowego magazynowane mają dwa źródła danych:
Magazyn zawiera wszystkie dane, w tym dane trenowania i trenowania modelu, z wyjątkiem metadanych. Odpowiadasz za szyfrowanie magazynu.
Usługa Azure Cosmos DB zawiera metadane, w tym informacje o historii uruchamiania, takie jak nazwa eksperymentu i data przesyłania eksperymentu. W większości obszarów roboczych usługa Azure Cosmos DB znajduje się w subskrypcji firmy Microsoft i jest szyfrowana za pomocą klucza zarządzanego przez firmę Microsoft.
Jeśli chcesz zaszyfrować metadane przy użyciu własnego klucza, możesz użyć obszaru roboczego klucza zarządzanego przez klienta. Wadą jest to, że musisz mieć usługę Azure Cosmos DB w ramach subskrypcji i zapłacić jej koszt. Aby uzyskać więcej informacji, zobacz Szyfrowanie danych za pomocą usługi Azure Machine Edukacja.
Aby uzyskać informacje na temat sposobu szyfrowania danych przesyłanych przez usługę Azure Machine Edukacja, zobacz Szyfrowanie podczas przesyłania.
Monitorowanie
Podczas wdrażania zasobów uczenia maszynowego skonfiguruj mechanizmy rejestrowania i inspekcji pod kątem możliwości obserwowania. Motywacje do obserwowania danych mogą się różnić w zależności od tego, kto analizuje dane. Scenariusze obejmują:
Praktycy lub zespoły ds. operacji uczenia maszynowego chcą monitorować kondycję potoku uczenia maszynowego. Obserwatorzy muszą zrozumieć problemy związane z zaplanowanym wykonywaniem lub problemami z jakością danych lub oczekiwaną wydajnością trenowania. Możesz tworzyć pulpity nawigacyjne platformy Azure, które monitorują dane usługi Azure Machine Edukacja lub tworzą przepływy pracy sterowane zdarzeniami.
Menedżerowie pojemności, praktycy uczenia maszynowego lub zespoły ds. operacji mogą chcieć utworzyć pulpit nawigacyjny w celu obserwowania wykorzystania zasobów obliczeniowych i przydziałów. Aby zarządzać wdrożeniem przy użyciu wielu obszarów roboczych usługi Azure Machine Edukacja, rozważ utworzenie centralnego pulpitu nawigacyjnego w celu zrozumienia wykorzystania limitów przydziału. Limity przydziału są zarządzane na poziomie subskrypcji, więc widok dla całego środowiska jest ważny dla optymalizacji.
Zespoły IT i operacyjne mogą skonfigurować rejestrowanie diagnostyczne w celu inspekcji dostępu do zasobów i zmiany zdarzeń w obszarze roboczym.
Rozważ utworzenie pulpitów nawigacyjnych, które monitorują ogólną kondycję infrastruktury na potrzeby uczenia maszynowego i zasobów zależnych, takich jak magazyn. Na przykład połączenie metryk usługi Azure Storage z danymi wykonywania potoku może pomóc zoptymalizować infrastrukturę pod kątem lepszej wydajności lub wykryć główne przyczyny problemu.
Platforma Azure automatycznie zbiera i przechowuje metryki platformy oraz dzienniki aktywności. Dane można kierować do innych lokalizacji przy użyciu ustawienia diagnostycznego. Skonfiguruj rejestrowanie diagnostyczne w scentralizowanym obszarze roboczym usługi Log Analytics w celu obserwowania w kilku wystąpieniach obszaru roboczego. Użyj usługi Azure Policy, aby automatycznie skonfigurować rejestrowanie dla nowych obszarów roboczych uczenia maszynowego w tym centralnym obszarze roboczym usługi Log Analytics.
Azure Policy
Za pomocą usługi Azure Policy można wymusić i przeprowadzić inspekcję użycia funkcji zabezpieczeń w obszarach roboczych. Zalecenia:
- Wymuszanie szyfrowania kluczy zarządzanych przez użytkownika.
- Wymuszanie usługi Azure Private Link i prywatnych punktów końcowych.
- Wymuszanie prywatnych stref DNS.
- Wyłącz uwierzytelnianie spoza usługi Azure AD, takie jak Secure Shell (SSH).
Aby uzyskać więcej informacji, zobacz Wbudowane definicje zasad dla usługi Azure Machine Edukacja.
Możesz również użyć niestandardowych definicji zasad, aby zarządzać zabezpieczeniami obszaru roboczego w elastyczny sposób.
Klastry obliczeniowe i wystąpienia
Poniższe zagadnienia i zalecenia dotyczą klastrów obliczeniowych i wystąpień uczenia maszynowego.
Szyfrowanie dysków
Dysk systemu operacyjnego dla wystąpienia obliczeniowego lub węzła klastra obliczeniowego jest przechowywany w usłudze Azure Storage i szyfrowany przy użyciu kluczy zarządzanych przez firmę Microsoft. Każdy węzeł ma również lokalny dysk tymczasowy. Dysk tymczasowy jest również szyfrowany przy użyciu kluczy zarządzanych przez firmę Microsoft, jeśli obszar roboczy został utworzony za pomocą parametru hbi_workspace = True . Aby uzyskać więcej informacji, zobacz Szyfrowanie danych za pomocą usługi Azure Machine Edukacja.
Tożsamość zarządzana
Klastry obliczeniowe obsługują uwierzytelnianie w zasobach platformy Azure przy użyciu tożsamości zarządzanych. Użycie tożsamości zarządzanej dla klastra umożliwia uwierzytelnianie zasobów bez uwidaczniania poświadczeń w kodzie. Aby uzyskać więcej informacji, zobacz Tworzenie klastra obliczeniowego usługi Azure Machine Edukacja.
Skrypt instalacji
Skrypt konfiguracji umożliwia zautomatyzowanie dostosowywania i konfiguracji wystąpień obliczeniowych podczas tworzenia. Jako administrator możesz napisać skrypt dostosowywania do użycia podczas tworzenia wszystkich wystąpień obliczeniowych w obszarze roboczym. Za pomocą usługi Azure Policy można wymusić użycie skryptu konfiguracji w celu utworzenia każdego wystąpienia obliczeniowego. Aby uzyskać więcej informacji, zobacz Tworzenie wystąpienia obliczeniowego usługi Azure Machine Edukacja i zarządzanie nim.
Utwórz w imieniu
Jeśli nie chcesz, aby analitycy danych aprowizować zasoby obliczeniowe, możesz tworzyć wystąpienia obliczeniowe w ich imieniu i przypisywać je do analityków danych. Aby uzyskać więcej informacji, zobacz Tworzenie wystąpienia obliczeniowego usługi Azure Machine Edukacja i zarządzanie nim.
Prywatny obszar roboczy z obsługą punktu końcowego
Użyj wystąpień obliczeniowych z prywatnym obszarem roboczym z obsługą punktu końcowego. Wystąpienie obliczeniowe odrzuca cały publiczny dostęp spoza sieci wirtualnej. Ta konfiguracja uniemożliwia również filtrowanie pakietów.
Obsługa usługi Azure Policy
W przypadku korzystania z sieci wirtualnej platformy Azure można użyć usługi Azure Policy, aby upewnić się, że każdy klaster obliczeniowy lub wystąpienie jest tworzony w sieci wirtualnej i określa domyślną sieć wirtualną i podsieć. Zasady nie są potrzebne w przypadku korzystania z zarządzanej sieci wirtualnej, ponieważ zasoby obliczeniowe są tworzone automatycznie w zarządzanej sieci wirtualnej.
Możesz również użyć zasad, aby wyłączyć uwierzytelnianie spoza usługi Azure AD, takie jak SSH.
Następne kroki
Dowiedz się więcej o konfiguracjach zabezpieczeń uczenia maszynowego:
- Zabezpieczenia i ład przedsiębiorstwa
- Zabezpieczanie zasobów obszaru roboczego przy użyciu sieci wirtualnych
Wprowadzenie do wdrożenia opartego na szablonie uczenia maszynowego:
- Szablony szybkiego startu platformy Azure (
microsoft.com) - Analiza w skali przedsiębiorstwa i strefa docelowa danych sztucznej inteligencji
Przeczytaj więcej artykułów na temat zagadnień dotyczących architektury dotyczących wdrażania uczenia maszynowego:
Dowiedz się, jak struktura zespołu, środowisko lub ograniczenia regionalne wpływają na konfigurację obszaru roboczego.
Zobacz, jak zarządzać kosztami obliczeniowymi i budżetem w zespołach i użytkownikach.
Dowiedz się więcej o metodyce DevOps (MLOps), która korzysta z kombinacji osób, procesów i technologii w celu dostarczania niezawodnych, niezawodnych i zautomatyzowanych rozwiązań uczenia maszynowego.