Monitorowanie jakości i tokenu użycia wdrożonych aplikacji przepływu monitów
Ważne
Elementy oznaczone (wersja zapoznawcza) w tym artykule są obecnie dostępne w publicznej wersji zapoznawczej. Ta wersja zapoznawcza jest udostępniana bez umowy dotyczącej poziomu usług i nie zalecamy korzystania z niej w przypadku obciążeń produkcyjnych. Niektóre funkcje mogą być nieobsługiwane lub ograniczone. Aby uzyskać więcej informacji, zobacz Uzupełniające warunki korzystania z wersji zapoznawczych platformy Microsoft Azure.
Monitorowanie aplikacji wdrażanych w środowisku produkcyjnym jest istotną częścią cyklu życia aplikacji generacyjnych sztucznej inteligencji. Zmiany w zachowaniu danych i konsumentów mogą wpływać na aplikację w czasie, co skutkuje nieaktualnymi systemami, które negatywnie wpływają na wyniki biznesowe i uwidaczniają organizacjom ryzyko związane ze zgodnością, gospodarką i reputacją.
Uwaga
Aby uzyskać ulepszony sposób ciągłego monitorowania wdrożonych aplikacji (innych niż przepływ monitów), rozważ użycie oceny online usługi Azure AI.
Monitorowanie sztucznej inteligencji platformy Azure dla generowanych aplikacji sztucznej inteligencji umożliwia monitorowanie aplikacji w środowisku produkcyjnym pod kątem użycia tokenów, jakości generowania i metryk operacyjnych.
Integracje na potrzeby monitorowania wdrożenia przepływu monitów umożliwiają:
- Zbierz dane wnioskowania produkcyjnego z wdrożonej aplikacji przepływu monitów.
- Zastosuj metryki oceny odpowiedzialnej sztucznej inteligencji, takie jak uziemienie, spójność, płynność i istotność, które są współdziałanie z metrykami oceny przepływu monitów.
- Monitoruj monity, uzupełnianie i łączne użycie tokenów w każdym wdrożeniu modelu w przepływie monitu.
- Monitorowanie metryk operacyjnych, takich jak liczba żądań, opóźnienie i szybkość błędów.
- Użyj wstępnie skonfigurowanych alertów i wartości domyślnych, aby cyklicznie uruchamiać monitorowanie.
- Korzystanie z wizualizacji danych i konfigurowanie zaawansowanego zachowania w portalu usługi Azure AI Foundry.
Wymagania wstępne
Przed wykonaniem kroków opisanych w tym artykule upewnij się, że masz następujące wymagania wstępne:
Subskrypcja platformy Azure z prawidłową formą płatności. Bezpłatne lub próbne subskrypcje platformy Azure nie są obsługiwane w tym scenariuszu. Jeśli nie masz subskrypcji platformy Azure, utwórz płatne konto platformy Azure, aby rozpocząć.
Projekt usługi Azure AI Foundry.
Przepływ monitu gotowy do wdrożenia. Jeśli go nie masz, zobacz Tworzenie przepływu monitu.
Kontrola dostępu oparta na rolach platformy Azure (RBAC) platformy Azure służy do udzielania dostępu do operacji w portalu usługi Azure AI Foundry. Aby wykonać kroki opisane w tym artykule, konto użytkownika musi mieć przypisaną rolę dewelopera usługi Azure AI w grupie zasobów. Aby uzyskać więcej informacji na temat uprawnień, zobacz Kontrola dostępu oparta na rolach w portalu usługi Azure AI Foundry.
Wymagania dotyczące metryk monitorowania
Metryki monitorowania są generowane przez niektóre najnowocześniejsze modele języka GPT skonfigurowane przy użyciu określonych instrukcji oceny (szablony monitów). Te modele działają jako modele ewaluacyjne dla zadań sekwencjonowanych. Użycie tej techniki do generowania metryk monitorowania pokazuje silne wyniki empiryczne i wysoką korelację z oceną człowieka w porównaniu ze standardowymi metrykami oceny sztucznej inteligencji. Aby uzyskać więcej informacji na temat oceny przepływu monitów, zobacz Przesyłanie testu zbiorczego oraz ocena i ocena i monitorowanie metryk dla generowania sztucznej inteligencji.
Modele GPT generujące metryki monitorowania są następujące. Te modele GPT są obsługiwane z monitorowaniem i konfigurowaniem jako zasób usługi Azure OpenAI:
- GPT-3.5 Turbo
- GPT-4
- GPT-4-32k
Obsługiwane metryki do monitorowania
Do monitorowania są obsługiwane następujące metryki:
| Metryczne | opis |
|---|---|
| Uziemienie | Mierzy, jak dobrze wygenerowane odpowiedzi modelu są zgodne z informacjami z danych źródłowych (kontekst zdefiniowany przez użytkownika). |
| Stopień zgodności | Mierzy zakres, w jakim generowane odpowiedzi modelu są odpowiednie i bezpośrednio związane z podanymi pytaniami. |
| Spójności | Mierzy zakres, w jakim wygenerowane odpowiedzi modelu są logicznie spójne i połączone. |
| Płynność | Mierzy gramatyczną biegłość przewidywaną przez generowanie sztucznej inteligencji. |
Mapowanie nazw kolumn
Podczas tworzenia przepływu należy upewnić się, że nazwy kolumn są mapowane. Następujące nazwy kolumn danych wejściowych służą do mierzenia bezpieczeństwa i jakości generowania:
| Nazwa kolumny wejściowej | Definicja | Wymagane/opcjonalnie |
|---|---|---|
| Pytanie | Oryginalny monit podany (znany również jako "dane wejściowe" lub "pytanie") | Wymagania |
| Odpowiedź | Końcowe zakończenie wywołania interfejsu API, które jest zwracane (nazywane również "danymi wyjściowymi" lub "odpowiedź") | Wymagania |
| Kontekst | Wszystkie dane kontekstowe wysyłane do wywołania interfejsu API wraz z oryginalnym monitem. Jeśli na przykład masz nadzieję uzyskać wyniki wyszukiwania tylko z określonych certyfikowanych źródeł informacji lub witryny internetowej, możesz zdefiniować ten kontekst w krokach oceny. | Opcjonalnie |
Parametry wymagane dla metryk
Parametry skonfigurowane w zasobie danych określają, jakie metryki można utworzyć, zgodnie z tą tabelą:
| Metric | Pytanie | Odpowiedź | Kontekst |
|---|---|---|---|
| Spójności | Wymagania | Wymagania | - |
| Płynność | Wymagania | Wymagania | - |
| Uziemienie | Wymagania | Wymagania | Wymagania |
| Stopień zgodności | Wymagania | Wymagania | Wymagania |
Aby uzyskać więcej informacji na temat konkretnych wymagań dotyczących mapowania danych dla każdej metryki, zobacz Wymagania dotyczące metryk zapytań i odpowiedzi.
Konfigurowanie monitorowania dla przepływu monitów
Aby skonfigurować monitorowanie aplikacji przepływu monitów, najpierw należy wdrożyć aplikację przepływu monitów z wnioskowaniem zbierania danych, a następnie skonfigurować monitorowanie wdrożonej aplikacji.
Wdrażanie aplikacji przepływu monitów przy użyciu wnioskowania zbierania danych
W tej sekcji dowiesz się, jak wdrożyć przepływ monitów z włączonym wnioskowaniem zbierania danych. Aby uzyskać szczegółowe informacje na temat wdrażania przepływu monitu, zobacz Wdrażanie przepływu na potrzeby wnioskowania w czasie rzeczywistym.
Zaloguj się do usługi Azure AI Foundry.
Jeśli nie jesteś jeszcze w projekcie, wybierz go.
Wybierz pozycję Monituj przepływ na pasku nawigacyjnym po lewej stronie.
Wybierz utworzony wcześniej przepływ monitu.
Uwaga
W tym artykule założono, że utworzono już przepływ monitu gotowy do wdrożenia. Jeśli go nie masz, zobacz Tworzenie przepływu monitu.
Upewnij się, że przepływ działa pomyślnie i czy wymagane dane wejściowe i wyjściowe zostały skonfigurowane dla metryk, które chcesz ocenić.
Podanie minimalnych wymaganych parametrów (pytanie/dane wejściowe i odpowiedź/wyjście) zapewnia tylko dwie metryki: spójność i płynność. Przepływ należy skonfigurować zgodnie z opisem w sekcji Wymagania dotyczące metryk monitorowania. W tym przykładzie użyto wartości (
questionPytanie) ichat_history(Kontekst) jako danych wejściowych przepływu orazanswer(Odpowiedź) jako danych wyjściowych przepływu.Wybierz pozycję Wdróż , aby rozpocząć wdrażanie przepływu.
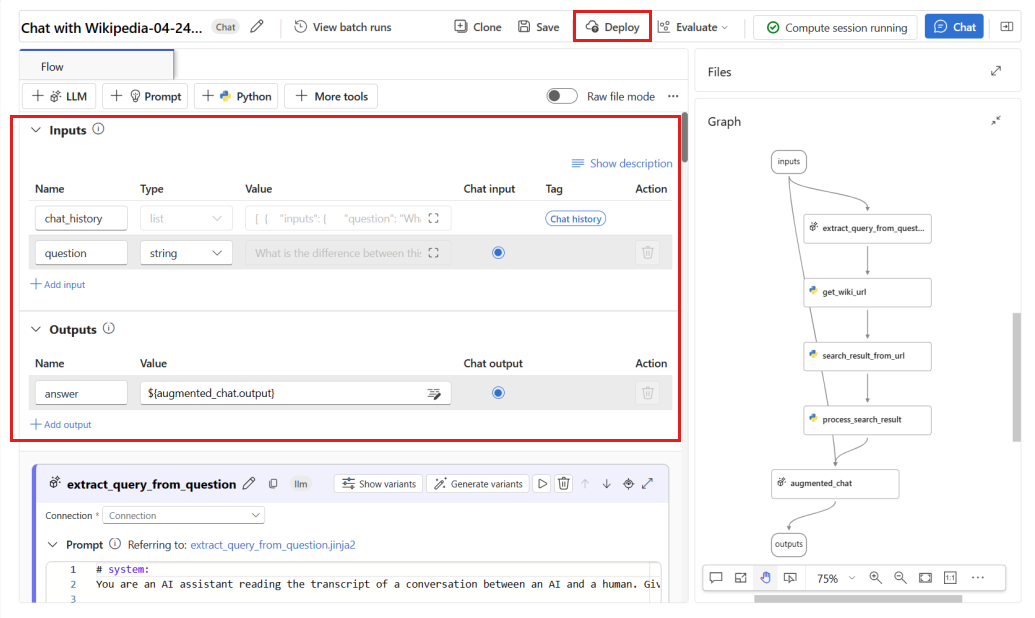
W oknie wdrażania upewnij się, że zbieranie danych wnioskowania jest włączone, co bezproblemowo będzie zbierać dane wnioskowania aplikacji do usługi Blob Storage. Ta kolekcja danych jest wymagana do monitorowania.
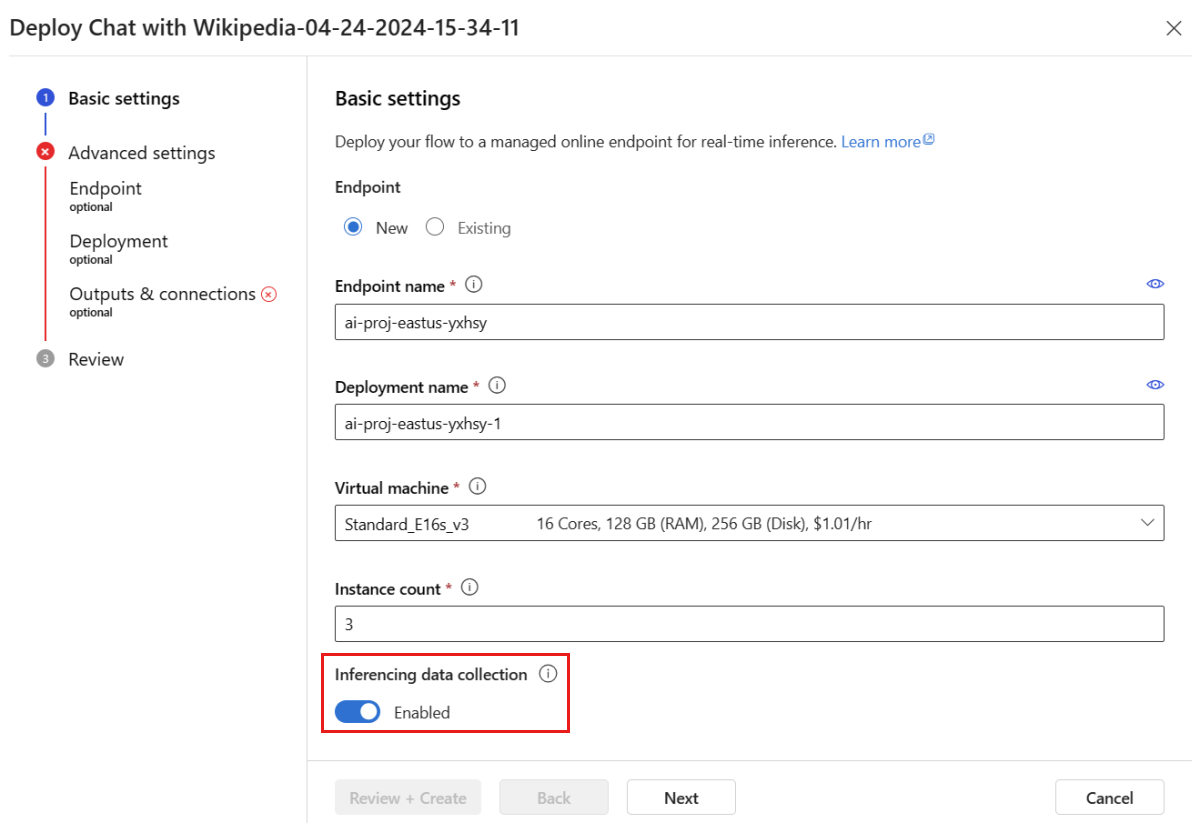
Wykonaj kroki opisane w oknie wdrażania, aby ukończyć ustawienia zaawansowane.
Na stronie "Przegląd" przejrzyj konfigurację wdrożenia i wybierz pozycję Utwórz , aby wdrożyć przepływ.
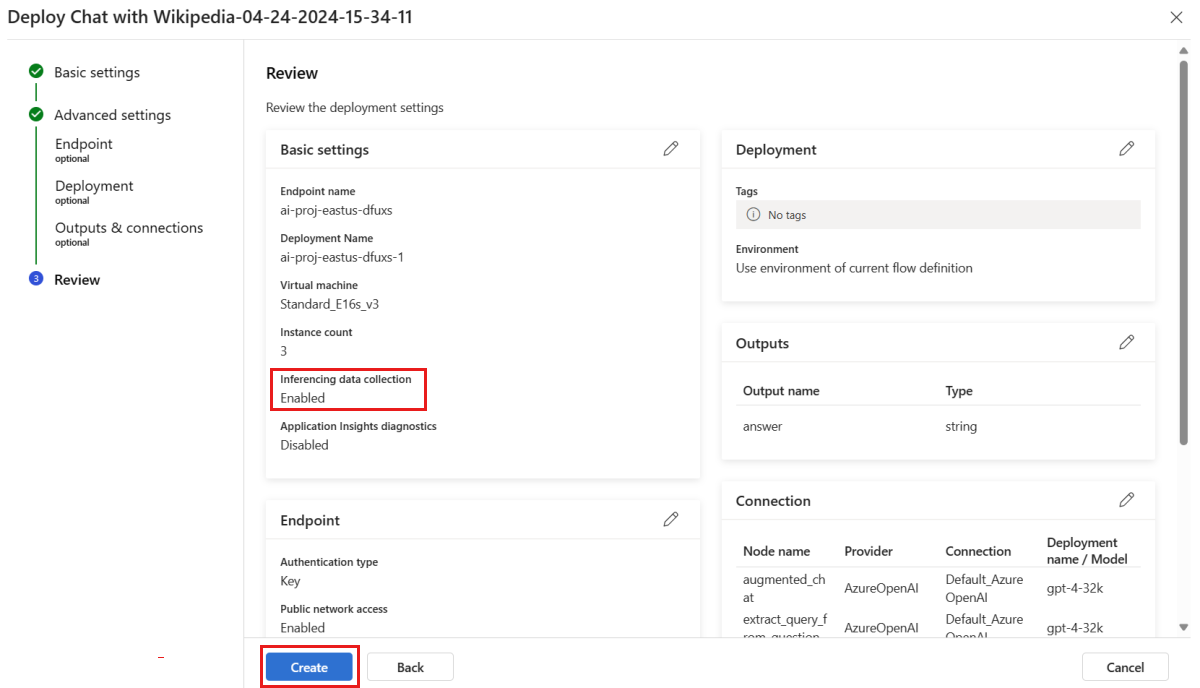
Uwaga
Domyślnie wszystkie dane wejściowe i wyjściowe wdrożonej aplikacji przepływu monitów są zbierane w usłudze Blob Storage. Ponieważ wdrożenie jest wywoływane przez użytkowników, dane są zbierane do użycia przez monitor.
Wybierz kartę Test na stronie wdrożenia i przetestuj wdrożenie, aby upewnić się, że działa prawidłowo.
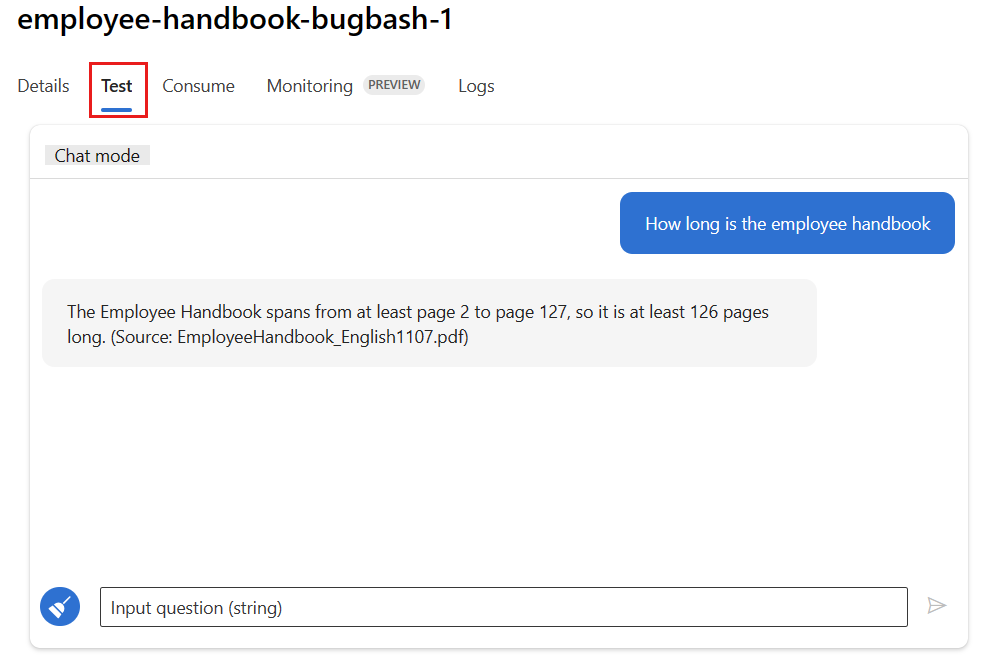
Uwaga
Monitorowanie wymaga, aby co najmniej jeden punkt danych pochodzi ze źródła innego niż karta Test we wdrożeniu. Zalecamy użycie interfejsu API REST dostępnego na karcie Użycie w celu wysyłania przykładowych żądań do wdrożenia. Aby uzyskać więcej informacji na temat wysyłania przykładowych żądań do wdrożenia, zobacz Tworzenie wdrożenia online.




Konfigurowanie monitorowania
W tej sekcji dowiesz się, jak skonfigurować monitorowanie dla wdrożonej aplikacji przepływu monitów.
Na lewym pasku nawigacyjnym przejdź do pozycji Moje zasoby>Modele i punkty końcowe.
Wybierz utworzone wdrożenie przepływu monitu.
Wybierz pozycję Włącz w polu Włącz monitorowanie jakości generacji.
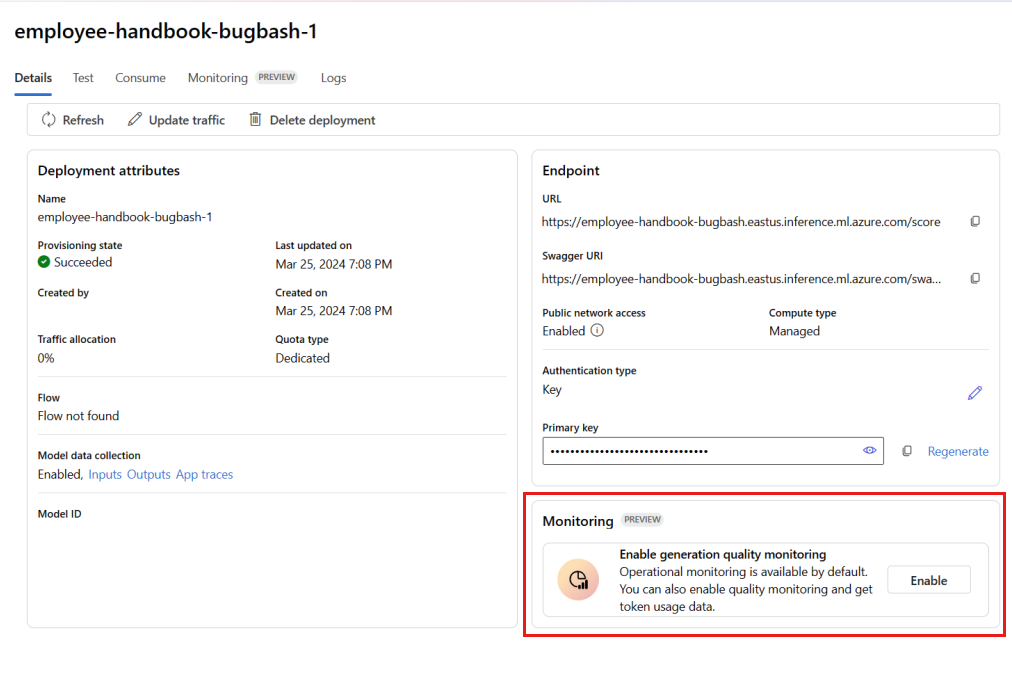
Rozpocznij konfigurowanie monitorowania, wybierając żądane metryki.
Upewnij się, że nazwy kolumn są mapowane z przepływu zgodnie z definicją w mapowaniu nazw kolumn.
Wybierz połączenie azure OpenAI i wdrożenie, którego chcesz użyć do monitorowania aplikacji przepływu monitów.
Wybierz pozycję Opcje zaawansowane, aby wyświetlić więcej opcji do skonfigurowania.
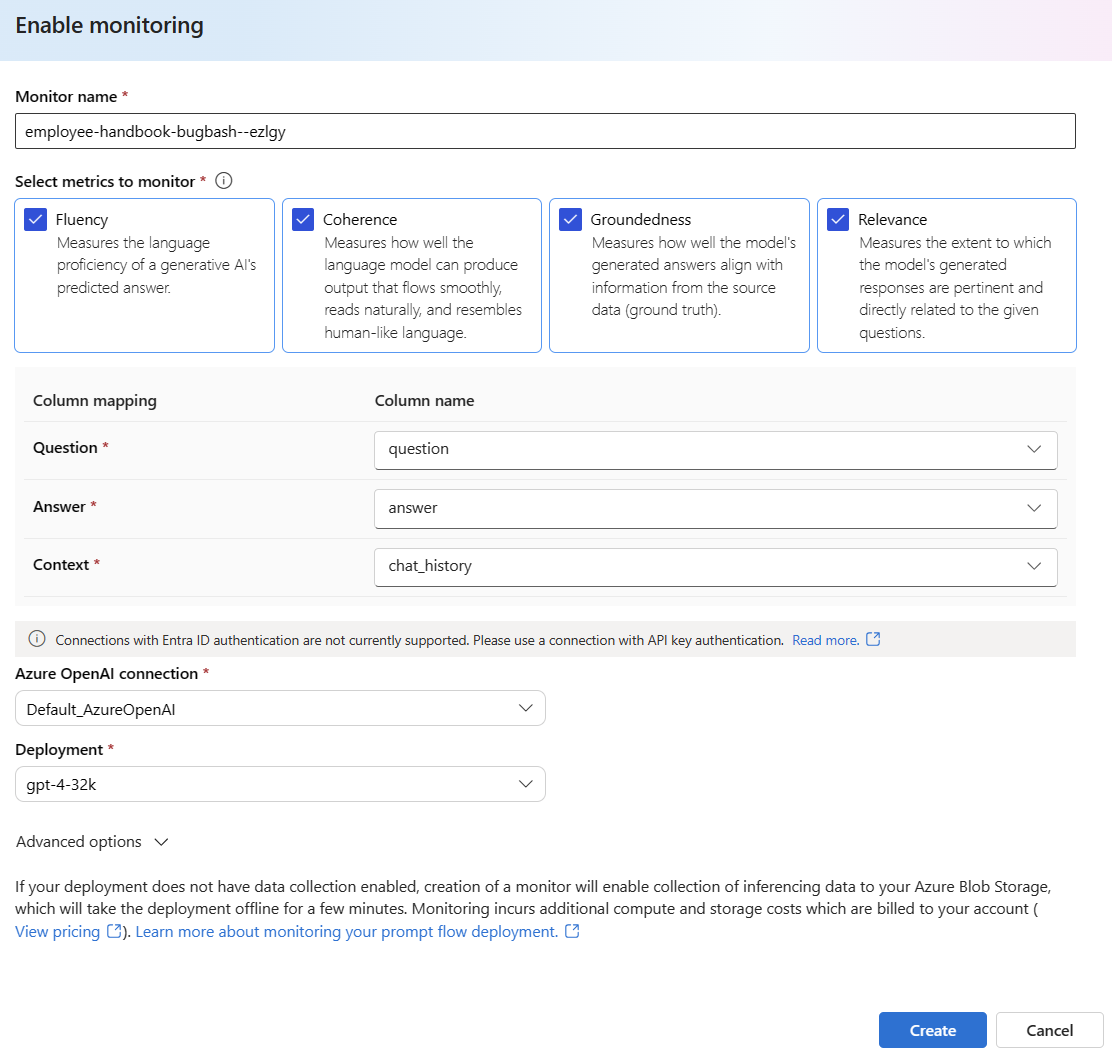
Dostosuj częstotliwość próbkowania, progi dla skonfigurowanych metryk i określ adresy e-mail, które powinny otrzymywać alerty, gdy średni wynik dla danej metryki spadnie poniżej progu.

Uwaga
Jeśli wdrożenie nie ma włączonego zbierania danych, utworzenie monitora umożliwi zbieranie danych wnioskowania do usługi Azure Blob Storage, co potrwa kilka minut.
Wybierz pozycję Utwórz , aby utworzyć monitor.



Korzystanie z wyników monitorowania
Po utworzeniu monitora będzie on uruchamiany codziennie, aby obliczyć użycie tokenu i metryki jakości generowania.
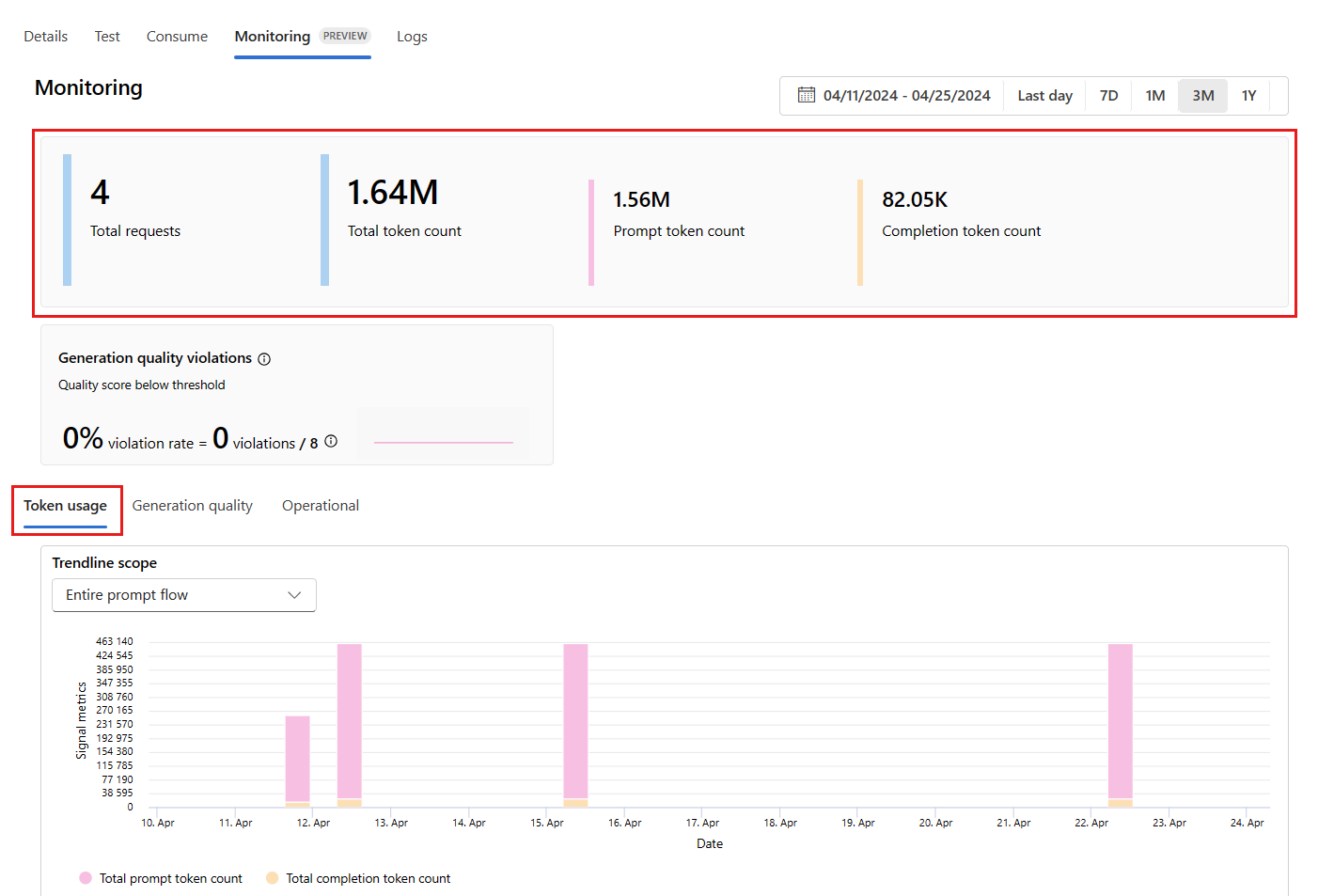
Przejdź do karty Monitorowanie (wersja zapoznawcza) z poziomu wdrożenia, aby wyświetlić wyniki monitorowania. W tym miejscu zobaczysz przegląd wyników monitorowania w wybranym przedziale czasu. Możesz użyć selektora dat, aby zmienić przedział czasu monitorowanych danych. W tym omówieniu są dostępne następujące metryki:
- Łączna liczba żądań: łączna liczba żądań wysłanych do wdrożenia w wybranym przedziale czasu.
- Łączna liczba tokenów: łączna liczba tokenów używanych przez wdrożenie w wybranym przedziale czasu.
- Liczba tokenów monitu: liczba tokenów monitu używanych przez wdrożenie w wybranym przedziale czasu.
- Liczba tokenów ukończenia: liczba tokenów ukończenia używanych przez wdrożenie w wybranym przedziale czasu.
Wyświetl metryki na karcie Użycie tokenu (ta karta jest domyślnie zaznaczona). W tym miejscu możesz wyświetlić użycie tokenu aplikacji w czasie. Możesz również wyświetlić rozkład tokenów monitu i ukończenia w czasie. Zakres linii trendu można zmienić, aby monitorować wszystkie tokeny w całej aplikacji lub użycie tokenu dla określonego wdrożenia (na przykład gpt-4) używanego w aplikacji.
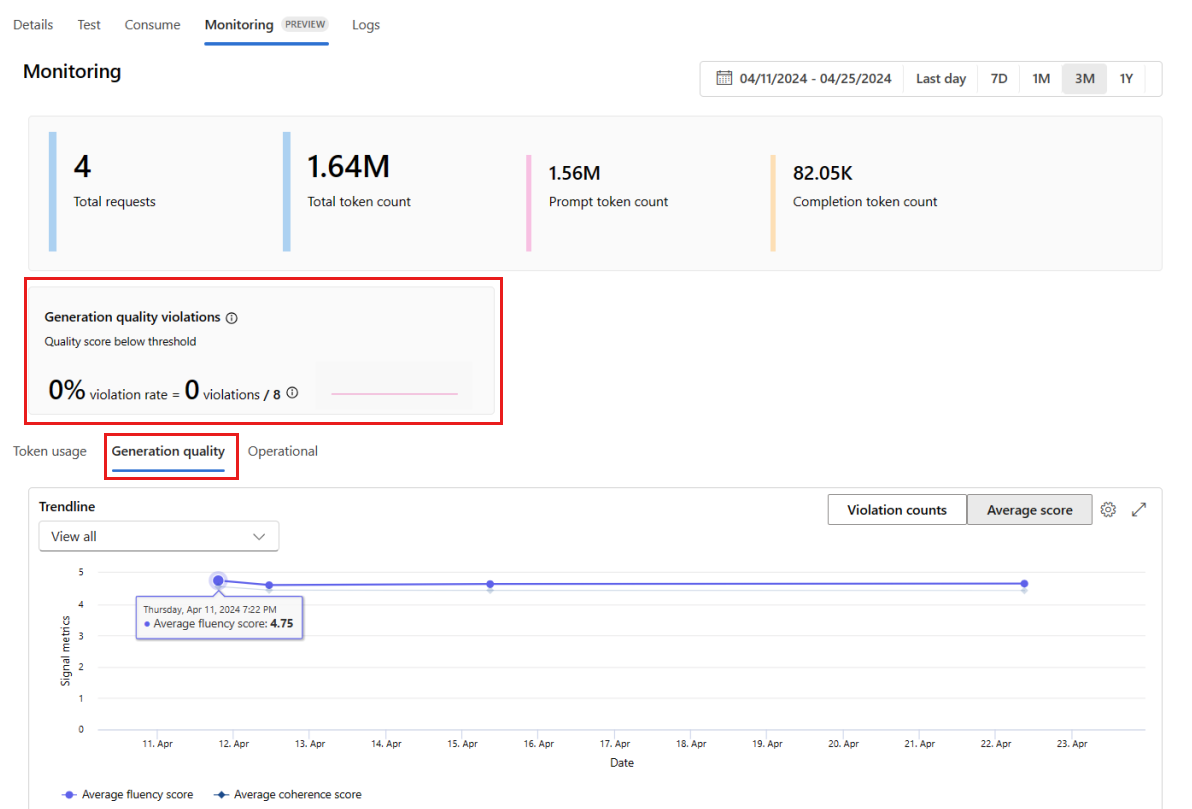
Przejdź do karty Jakość generacji, aby monitorować jakość aplikacji w czasie. W wykresie czasowym są wyświetlane następujące metryki:
- Liczba naruszeń: liczba naruszeń dla danej metryki (na przykład Fluency) to suma naruszeń w wybranym przedziale czasu. Naruszenie występuje w przypadku metryki, gdy metryki są obliczane (wartość domyślna to codziennie), jeśli obliczona wartość metryki spadnie poniżej ustawionej wartości progowej.
- Średni wynik: średni wynik dla danej metryki (na przykład Fluency) to suma wyników dla wszystkich wystąpień (lub żądań) podzielona przez liczbę wystąpień (lub żądań) w wybranym przedziale czasu.
Karta Naruszenia jakości generowania pokazuje współczynnik naruszeń w wybranym przedziale czasu. Współczynnik naruszeń to liczba naruszeń podzielona przez łączną liczbę możliwych naruszeń. Możesz dostosować progi metryk w ustawieniach. Domyślnie metryki są obliczane codziennie; tę częstotliwość można również dostosować w ustawieniach.
Na karcie Monitorowanie (wersja zapoznawcza) możesz również wyświetlić kompleksową tabelę wszystkich przykładowych żądań wysyłanych do wdrożenia w wybranym przedziale czasu.
Uwaga
Monitorowanie ustawia domyślną częstotliwość próbkowania na 10%. Oznacza to, że jeśli do wdrożenia zostanie wysłanych 100 żądań, 10 zostanie próbkowanych i użytych do obliczenia metryk jakości generowania. Częstotliwość próbkowania można dostosować w ustawieniach.
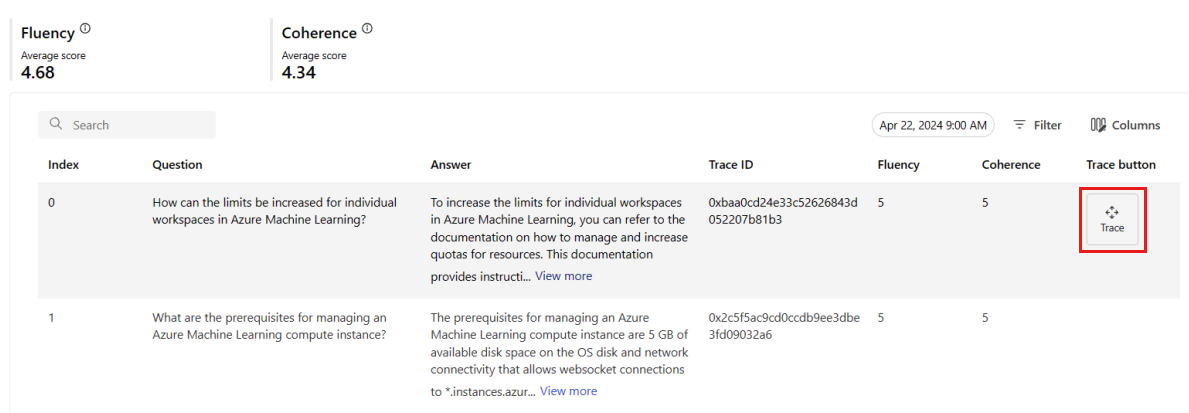
Wybierz przycisk Śledzenie po prawej stronie wiersza w tabeli, aby wyświetlić szczegóły śledzenia dla danego żądania. Ten widok zawiera szczegółowe informacje dotyczące śledzenia żądania do aplikacji.
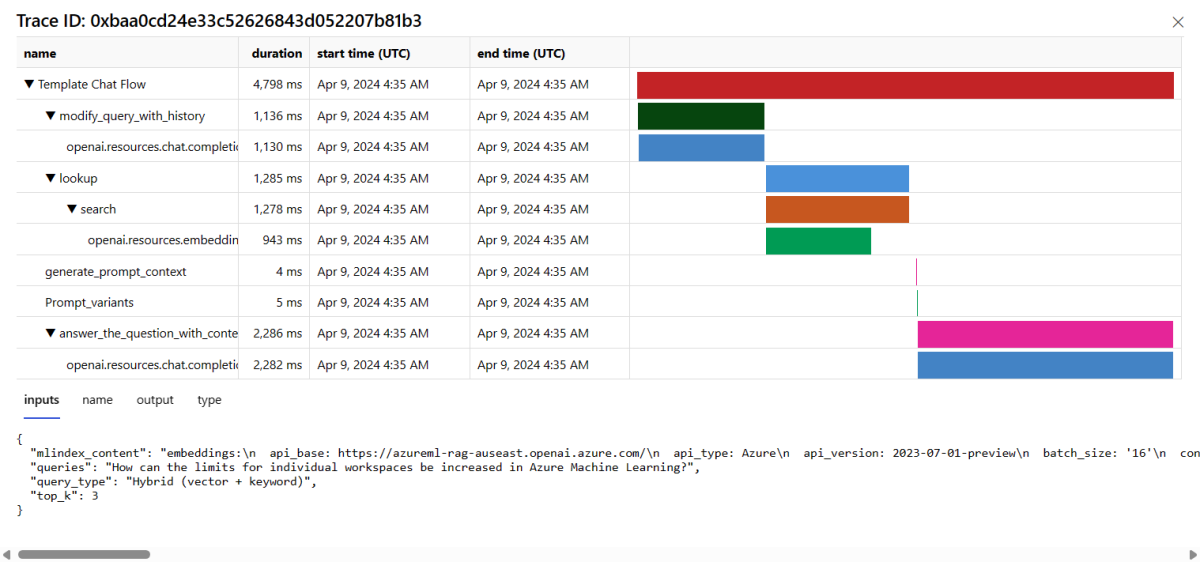
Zamknij widok Śledzenie.
Przejdź do karty Operacyjne, aby wyświetlić metryki operacyjne wdrożenia niemal w czasie rzeczywistym. Obsługujemy następujące metryki operacyjne:
- Liczba żądań
- Opóźnienie
- Częstotliwość błędów
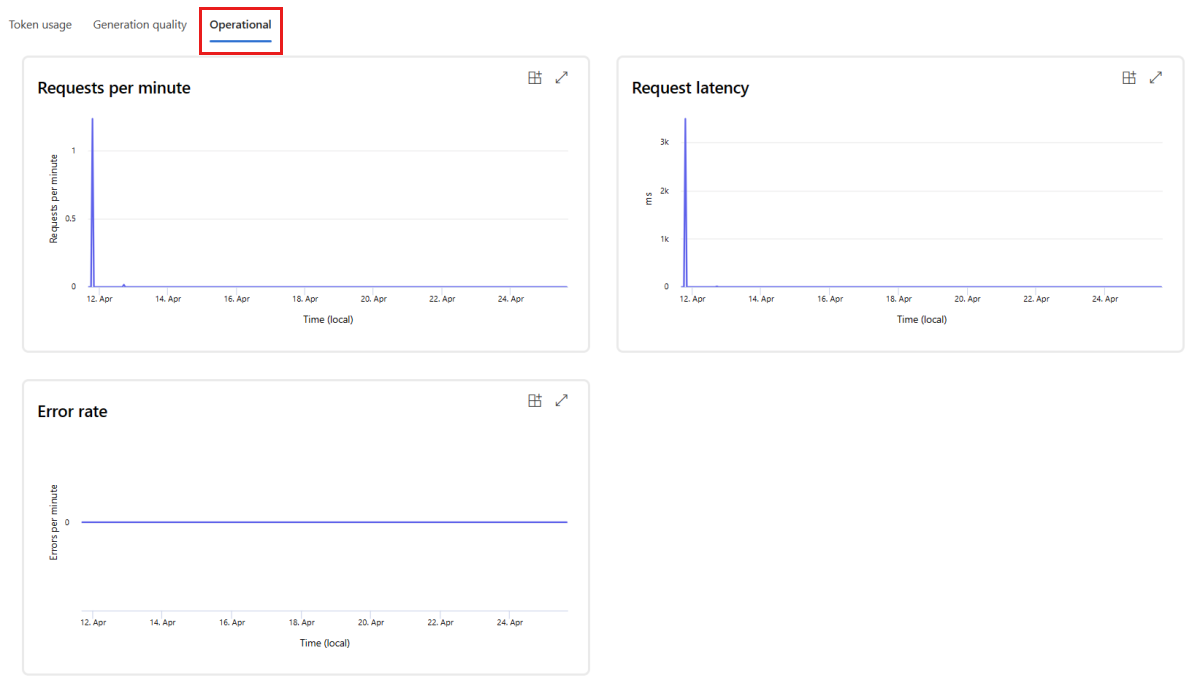





Wyniki na karcie Monitorowanie (wersja zapoznawcza) wdrożenia zapewniają szczegółowe informacje ułatwiające proaktywne zwiększenie wydajności aplikacji przepływu monitów.
Zaawansowana konfiguracja monitorowania przy użyciu zestawu SDK w wersji 2
Monitorowanie obsługuje również zaawansowane opcje konfiguracji z zestawem SDK w wersji 2. Obsługiwane są następujące scenariusze:
Włączanie monitorowania użycia tokenów
Jeśli interesuje Cię tylko włączanie monitorowania użycia tokenów dla wdrożonej aplikacji przepływu monitów, możesz dostosować następujący skrypt do swojego scenariusza:
from azure.ai.ml import MLClient
from azure.ai.ml.entities import (
MonitorSchedule,
CronTrigger,
MonitorDefinition,
ServerlessSparkCompute,
MonitoringTarget,
AlertNotification,
GenerationTokenStatisticsSignal,
)
from azure.ai.ml.entities._inputs_outputs import Input
from azure.ai.ml.constants import MonitorTargetTasks, MonitorDatasetContext
# Authentication package
from azure.identity import DefaultAzureCredential
credential = DefaultAzureCredential()
# Update your azure resources details
subscription_id = "INSERT YOUR SUBSCRIPTION ID"
resource_group = "INSERT YOUR RESOURCE GROUP NAME"
project_name = "INSERT YOUR PROJECT NAME" # This is the same as your Azure AI Foundry project name
endpoint_name = "INSERT YOUR ENDPOINT NAME" # This is your deployment name without the suffix (e.g., deployment is "contoso-chatbot-1", endpoint is "contoso-chatbot")
deployment_name = "INSERT YOUR DEPLOYMENT NAME"
# These variables can be renamed but it is not necessary
monitor_name ="gen_ai_monitor_tokens"
defaulttokenstatisticssignalname ="token-usage-signal"
# Determine the frequency to run the monitor, and the emails to recieve email alerts
trigger_schedule = CronTrigger(expression="15 10 * * *")
notification_emails_list = ["test@example.com", "def@example.com"]
ml_client = MLClient(
credential=credential,
subscription_id=subscription_id,
resource_group_name=resource_group,
workspace_name=project_name,
)
spark_compute = ServerlessSparkCompute(instance_type="standard_e4s_v3", runtime_version="3.3")
monitoring_target = MonitoringTarget(
ml_task=MonitorTargetTasks.QUESTION_ANSWERING,
endpoint_deployment_id=f"azureml:{endpoint_name}:{deployment_name}",
)
# Create an instance of token statistic signal
token_statistic_signal = GenerationTokenStatisticsSignal()
monitoring_signals = {
defaulttokenstatisticssignalname: token_statistic_signal,
}
monitor_settings = MonitorDefinition(
compute=spark_compute,
monitoring_target=monitoring_target,
monitoring_signals = monitoring_signals,
alert_notification=AlertNotification(emails=notification_emails_list),
)
model_monitor = MonitorSchedule(
name = monitor_name,
trigger=trigger_schedule,
create_monitor=monitor_settings
)
ml_client.schedules.begin_create_or_update(model_monitor)
Włączanie monitorowania pod kątem jakości generowania
Jeśli interesuje Cię tylko włączanie monitorowania jakości generacji dla wdrożonej aplikacji przepływu monitów, możesz dostosować następujący skrypt do scenariusza:
from azure.ai.ml import MLClient
from azure.ai.ml.entities import (
MonitorSchedule,
CronTrigger,
MonitorDefinition,
ServerlessSparkCompute,
MonitoringTarget,
AlertNotification,
GenerationSafetyQualityMonitoringMetricThreshold,
GenerationSafetyQualitySignal,
BaselineDataRange,
LlmData,
)
from azure.ai.ml.entities._inputs_outputs import Input
from azure.ai.ml.constants import MonitorTargetTasks, MonitorDatasetContext
# Authentication package
from azure.identity import DefaultAzureCredential
credential = DefaultAzureCredential()
# Update your azure resources details
subscription_id = "INSERT YOUR SUBSCRIPTION ID"
resource_group = "INSERT YOUR RESOURCE GROUP NAME"
project_name = "INSERT YOUR PROJECT NAME" # This is the same as your Azure AI Foundry project name
endpoint_name = "INSERT YOUR ENDPOINT NAME" # This is your deployment name without the suffix (e.g., deployment is "contoso-chatbot-1", endpoint is "contoso-chatbot")
deployment_name = "INSERT YOUR DEPLOYMENT NAME"
aoai_deployment_name ="INSERT YOUR AOAI DEPLOYMENT NAME"
aoai_connection_name = "INSERT YOUR AOAI CONNECTION NAME"
# These variables can be renamed but it is not necessary
app_trace_name = "app_traces"
app_trace_Version = "1"
monitor_name ="gen_ai_monitor_generation_quality"
defaultgsqsignalname ="gsq-signal"
# Determine the frequency to run the monitor, and the emails to recieve email alerts
trigger_schedule = CronTrigger(expression="15 10 * * *")
notification_emails_list = ["test@example.com", "def@example.com"]
ml_client = MLClient(
credential=credential,
subscription_id=subscription_id,
resource_group_name=resource_group,
workspace_name=project_name,
)
spark_compute = ServerlessSparkCompute(instance_type="standard_e4s_v3", runtime_version="3.3")
monitoring_target = MonitoringTarget(
ml_task=MonitorTargetTasks.QUESTION_ANSWERING,
endpoint_deployment_id=f"azureml:{endpoint_name}:{deployment_name}",
)
# Set thresholds for passing rate (0.7 = 70%)
aggregated_groundedness_pass_rate = 0.7
aggregated_relevance_pass_rate = 0.7
aggregated_coherence_pass_rate = 0.7
aggregated_fluency_pass_rate = 0.7
# Create an instance of gsq signal
generation_quality_thresholds = GenerationSafetyQualityMonitoringMetricThreshold(
groundedness = {"aggregated_groundedness_pass_rate": aggregated_groundedness_pass_rate},
relevance={"aggregated_relevance_pass_rate": aggregated_relevance_pass_rate},
coherence={"aggregated_coherence_pass_rate": aggregated_coherence_pass_rate},
fluency={"aggregated_fluency_pass_rate": aggregated_fluency_pass_rate},
)
input_data = Input(
type="uri_folder",
path=f"{endpoint_name}-{deployment_name}-{app_trace_name}:{app_trace_Version}",
)
data_window = BaselineDataRange(lookback_window_size="P7D", lookback_window_offset="P0D")
production_data = LlmData(
data_column_names={"prompt_column": "question", "completion_column": "answer", "context_column": "context"},
input_data=input_data,
data_window=data_window,
)
gsq_signal = GenerationSafetyQualitySignal(
connection_id=f"/subscriptions/{subscription_id}/resourceGroups/{resource_group}/providers/Microsoft.MachineLearningServices/workspaces/{project_name}/connections/{aoai_connection_name}",
metric_thresholds=generation_quality_thresholds,
production_data=[production_data],
sampling_rate=1.0,
properties={
"aoai_deployment_name": aoai_deployment_name,
"enable_action_analyzer": "false",
"azureml.modelmonitor.gsq_thresholds": '[{"metricName":"average_fluency","threshold":{"value":4}},{"metricName":"average_coherence","threshold":{"value":4}}]',
},
)
monitoring_signals = {
defaultgsqsignalname: gsq_signal,
}
monitor_settings = MonitorDefinition(
compute=spark_compute,
monitoring_target=monitoring_target,
monitoring_signals = monitoring_signals,
alert_notification=AlertNotification(emails=notification_emails_list),
)
model_monitor = MonitorSchedule(
name = monitor_name,
trigger=trigger_schedule,
create_monitor=monitor_settings
)
ml_client.schedules.begin_create_or_update(model_monitor)
Po utworzeniu monitora na podstawie zestawu SDK możesz użyć wyników monitorowania w portalu usługi Azure AI Foundry.
Powiązana zawartość
- Dowiedz się więcej o tym, co można zrobić w usłudze Azure AI Foundry.
- Uzyskaj odpowiedzi na często zadawane pytania w artykule Azure AI FAQ (Często zadawane pytania dotyczące sztucznej inteligencji platformy Azure).