Rozwiązywanie problemów z bezserwerową pulą SQL w usłudze Azure Synapse Analytics
Ten artykuł zawiera informacje na temat rozwiązywania najczęstszych problemów z bezserwerową pulą SQL w usłudze Azure Synapse Analytics.
Aby dowiedzieć się więcej na temat usługi Azure Synapse Analytics, zapoznaj się z tematami w temacie Przegląd.
Synapse Studio
Synapse Studio to łatwe w użyciu narzędzie, którego można użyć do uzyskiwania dostępu do danych przy użyciu przeglądarki bez konieczności instalowania narzędzi dostępu do bazy danych. Program Synapse Studio nie jest przeznaczony do odczytywania dużego zestawu danych ani pełnego zarządzania obiektami SQL.
Bezserwerowa pula SQL jest wyszarana w programie Synapse Studio
Jeśli program Synapse Studio nie może nawiązać połączenia z bezserwerową pulą SQL, zauważysz, że bezserwerowa pula SQL jest wyszarana lub jest wyświetlana stan Offline.
Zazwyczaj ten problem występuje z jednego z dwóch powodów:
- Sieć uniemożliwia komunikację z zapleczem usługi Azure Synapse Analytics. Najczęstszym przypadkiem jest zablokowanie portu TCP 1443. Aby uzyskać bezserwerową pulę SQL do działania, odblokuj ten port. Inne problemy mogą uniemożliwić też działanie bezserwerowej puli SQL. Aby uzyskać więcej informacji, zobacz Przewodnik rozwiązywania problemów.
- Nie masz uprawnień do logowania się do bezserwerowej puli SQL. Aby uzyskać dostęp, administrator obszaru roboczego usługi Azure Synapse musi dodać Cię do roli administratora obszaru roboczego lub roli administratora SQL. Aby uzyskać więcej informacji, zobacz Azure Synapse access control (Kontrola dostępu w usłudze Azure Synapse).
Połączenie protokołu WebSocket zostało nieoczekiwanie zamknięte
Zapytanie może zakończyć się niepowodzeniem z komunikatem o błędzie Ten komunikat Websocket connection was closed unexpectedly. oznacza, że połączenie przeglądarki z programem Synapse Studio zostało przerwane, na przykład z powodu problemu z siecią.
- Aby rozwiązać ten problem, uruchom ponownie zapytanie.
- Wypróbuj program Azure Data Studio lub SQL Server Management Studio, aby użyć tych samych zapytań zamiast programu Synapse Studio w celu dalszego zbadania.
- Jeśli ten komunikat występuje często w twoim środowisku, uzyskaj pomoc od administratora sieci. Możesz również sprawdzić ustawienia zapory i sprawdzić przewodnik rozwiązywania problemów.
- Jeśli problem będzie nadal występował, utwórz bilet pomocy technicznej za pośrednictwem witryny Azure Portal.
Bezserwerowe bazy danych nie są wyświetlane w programie Synapse Studio
Jeśli nie widzisz baz danych utworzonych w bezserwerowej puli SQL, sprawdź, czy uruchomiono bezserwerową pulę SQL. Jeśli bezserwerowa pula SQL jest dezaktywowana, bazy danych nie będą wyświetlane. Wykonaj dowolne zapytanie, na przykład , w bezserwerowej puli SQL, SELECT 1aby ją aktywować i ustawić, aby bazy danych pojawiły się.
Pula SQL bezserwerowa usługi Synapse jest wyświetlana jako niedostępna
Nieprawidłowa konfiguracja sieci jest często przyczyną tego zachowania. Upewnij się, że porty są prawidłowo skonfigurowane. Jeśli używasz zapory lub prywatnych punktów końcowych, sprawdź też te ustawienia.
Na koniec upewnij się, że odpowiednie role zostały przyznane i nie zostały odwołane.
Nie można utworzyć nowej bazy danych, ponieważ żądanie będzie używać starego/wygasłego klucza
Ten błąd jest spowodowany zmianą klucza zarządzanego przez klienta obszaru roboczego używanego do szyfrowania. Możesz ponownie zaszyfrować wszystkie dane w obszarze roboczym przy użyciu najnowszej wersji aktywnego klucza. Aby ponownie zaszyfrować, zmień klucz w witrynie Azure Portal na klucz tymczasowy, a następnie wróć do klucza, którego chcesz użyć do szyfrowania. Dowiedz się tutaj, jak zarządzać kluczami obszaru roboczego.
Bezserwerowa pula SQL usługi Synapse jest niedostępna po przeniesieniu subskrypcji do innej dzierżawy usługi Microsoft Entra
Jeśli subskrypcja została przeniesiona do innej dzierżawy firmy Microsoft Entra, mogą wystąpić problemy z bezserwerową pulą SQL. Utwórz bilet pomocy technicznej i pomoc techniczna platformy Azure skontaktuje się z Tobą, aby rozwiązać ten problem.
Dostęp do magazynu
Jeśli podczas próby uzyskania dostępu do plików w usłudze Azure Storage wystąpią błędy, upewnij się, że masz uprawnienia dostępu do danych. Dostęp do publicznie dostępnych plików powinien być dostępny. Jeśli spróbujesz uzyskać dostęp do danych bez poświadczeń, upewnij się, że tożsamość firmy Microsoft Entra może uzyskać bezpośredni dostęp do plików.
Jeśli masz klucz sygnatury dostępu współdzielonego, którego należy użyć do uzyskiwania dostępu do plików, upewnij się, że utworzono poświadczenia na poziomie serwera lub w zakresie bazy danych zawierające te poświadczenia. Poświadczenia są wymagane, jeśli musisz uzyskać dostęp do danych przy użyciu tożsamości zarządzanej obszaru roboczego i niestandardowej nazwy głównej usługi (SPN).
Nie można odczytać, wyświetlić listy ani uzyskać dostępu do plików w usłudze Azure Data Lake Storage
Jeśli używasz identyfikatora logowania entra firmy Microsoft bez jawnych poświadczeń, upewnij się, że tożsamość firmy Microsoft Entra może uzyskać dostęp do plików w magazynie. Aby uzyskać dostęp do plików, tożsamość firmy Microsoft entra musi mieć uprawnienie Czytelnik danych obiektów blob lub uprawnienia do list i odczytu list kontroli dostępu (ACL) w usłudze ADLS. Aby uzyskać więcej informacji, zobacz Zapytanie kończy się niepowodzeniem, ponieważ nie można otworzyć pliku.
Jeśli uzyskujesz dostęp do magazynu przy użyciu poświadczeń, upewnij się, że tożsamość zarządzana lub nazwa SPN ma rolę Czytelnik danych lub Współautor lub określone uprawnienia listy ACL. Jeśli użyto tokenu sygnatury dostępu współdzielonego, upewnij się, że ma rl uprawnienia i że nie wygasł.
Jeśli używasz identyfikatora logowania SQL i OPENROWSET funkcji bez źródła danych, upewnij się, że masz poświadczenia na poziomie serwera zgodne z identyfikatorem URI magazynu i ma uprawnienia dostępu do magazynu.
Zapytanie kończy się niepowodzeniem, ponieważ nie można otworzyć pliku
Jeśli zapytanie nie powiedzie się z powodu błędu File cannot be opened because it does not exist or it is used by another process i masz pewność, że oba pliki istnieją i nie są używane przez inny proces, bezserwerowa pula SQL nie może uzyskać dostępu do pliku. Ten problem zwykle występuje, ponieważ tożsamość firmy Microsoft Entra nie ma uprawnień dostępu do pliku lub zapora blokuje dostęp do pliku.
Domyślnie bezserwerowa pula SQL próbuje uzyskać dostęp do pliku przy użyciu tożsamości firmy Microsoft Entra. Aby rozwiązać ten problem, musisz mieć odpowiednie prawa dostępu do pliku. Najprostszym sposobem jest przyznanie sobie roli Współautor danych obiektu blob usługi Storage na koncie magazynu, którego próbujesz wykonać zapytanie.
Aby uzyskać więcej informacji, zobacz:
- Kontrola dostępu identyfikatora Entra firmy Microsoft dla magazynu
- Kontrolowanie dostępu do konta magazynu dla bezserwerowej puli SQL w usłudze Synapse Analytics
Alternatywa dla roli Współautor danych obiektu blob usługi Storage
Zamiast udzielać sobie roli Współautor danych obiektu blob usługi Storage, możesz również przyznać bardziej szczegółowe uprawnienia do podzestawu plików.
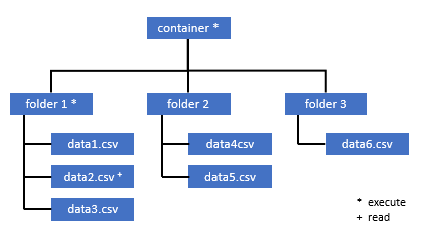
Wszyscy użytkownicy, którzy potrzebują dostępu do niektórych danych w tym kontenerze, również muszą mieć uprawnienie EXECUTE we wszystkich folderach nadrzędnych do katalogu głównego (kontenera).
Dowiedz się więcej na temat ustawiania list ACL w usłudze Azure Data Lake Storage Gen2.
Uwaga
Uprawnienia do wykonywania na poziomie kontenera muszą być ustawione w usłudze Azure Data Lake Storage Gen2. Uprawnienia do folderu można ustawić w usłudze Azure Synapse.
Jeśli chcesz wykonać zapytanie data2.csv w tym przykładzie, potrzebne są następujące uprawnienia:
- Uprawnienie do wykonywania w kontenerze
- Uprawnienie do wykonywania w folderze folder1
- Uprawnienie do odczytu na data2.csv
Zaloguj się do usługi Azure Synapse przy użyciu użytkownika administratora, który ma pełne uprawnienia do danych, do których chcesz uzyskać dostęp.
W okienku danych kliknij prawym przyciskiem myszy plik i wybierz pozycję Zarządzaj dostępem.
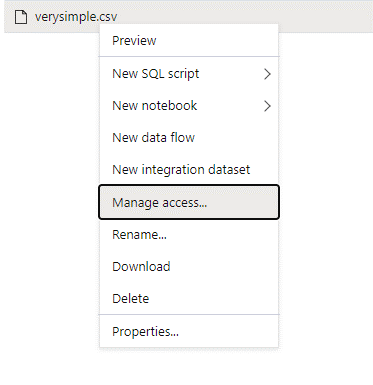
Wybierz co najmniej uprawnienie do odczytu . Wprowadź nazwę UPN użytkownika lub identyfikator obiektu, na przykład
user@contoso.com. Wybierz Dodaj.Udziel uprawnień do odczytu dla tego użytkownika.

Uwaga
W przypadku użytkowników-gości ten krok należy wykonać bezpośrednio w usłudze Azure Data Lake, ponieważ nie można wykonać go bezpośrednio za pośrednictwem usługi Azure Synapse.
Nie można wymienić zawartości katalogu na ścieżce
Ten błąd wskazuje, że użytkownik, który wykonuje zapytanie dotyczące usługi Azure Data Lake, nie może wyświetlić listy plików w magazynie. Istnieje kilka scenariuszy, w których ten błąd może wystąpić:
- Użytkownik firmy Microsoft Entra korzystający z uwierzytelniania przekazywanego firmy Microsoft nie ma uprawnień do wyświetlania listy plików w usłudze Data Lake Storage.
- Identyfikator Entra firmy Microsoft lub użytkownik SQL, który odczytuje dane przy użyciu klucza sygnatury dostępu współdzielonego lub tożsamości zarządzanej obszaru roboczego, a ten klucz lub tożsamość nie ma uprawnień do wyświetlania listy plików w magazynie.
- Użytkownik, który uzyskuje dostęp do danych usługi Dataverse, który nie ma uprawnień do wykonywania zapytań dotyczących danych w usłudze Dataverse. Ten scenariusz może wystąpić, jeśli korzystasz z użytkowników SQL.
- Użytkownik, który uzyskuje dostęp do usługi Delta Lake, może nie mieć uprawnień do odczytu dziennika transakcji usługi Delta Lake.
Najprostszym sposobem rozwiązania tego problemu jest przyznanie sobie roli Współautor danych obiektu blob usługi Storage na koncie magazynu, którego próbujesz wykonać zapytanie.
Aby uzyskać więcej informacji, zobacz:
- Kontrola dostępu identyfikatora Entra firmy Microsoft dla magazynu
- Kontrolowanie dostępu do konta magazynu dla bezserwerowej puli SQL w usłudze Synapse Analytics
Nie można wymienić zawartości tabeli Dataverse
Jeśli używasz usługi Azure Synapse Link dla usługi Dataverse do odczytywania połączonych tabel DataVerse, musisz użyć konta Microsoft Entra, aby uzyskać dostęp do połączonych danych przy użyciu bezserwerowej puli SQL. Aby uzyskać więcej informacji, zobacz Azure Synapse Link for Dataverse with Azure Data Lake (Usługa Azure Synapse Link dla usługi Dataverse w usłudze Azure Data Lake).
Jeśli spróbujesz użyć identyfikatora logowania SQL, aby odczytać tabelę zewnętrzną odwołującą się do tabeli DataVerse, zostanie wyświetlony następujący błąd: External table '???' is not accessible because content of directory cannot be listed.
Tabele zewnętrzne usługi Dataverse zawsze używają uwierzytelniania przekazywanego firmy Microsoft. Nie można ich skonfigurować do używania klucza sygnatury dostępu współdzielonego lub tożsamości zarządzanej obszaru roboczego.
Nie można wymienić zawartości dziennika transakcji usługi Delta Lake
Następujący błąd jest zwracany, gdy bezserwerowa pula SQL nie może odczytać folderu dziennika transakcji usługi Delta Lake:
Content of directory on path 'https://.....core.windows.net/.../_delta_log/*.json' cannot be listed.
Upewnij się, że _delta_log folder istnieje. Być może wysyłasz zapytania dotyczące zwykłych plików Parquet, które nie są konwertowane na format usługi Delta Lake. _delta_log Jeśli folder istnieje, upewnij się, że masz uprawnienie Odczyt i Lista w źródłowych folderach usługi Delta Lake. Spróbuj odczytać pliki json bezpośrednio przy użyciu polecenia FORMAT='csv'. Umieść identyfikator URI w parametrze BULK:
select top 10 *
from openrowset(BULK 'https://.....core.windows.net/.../_delta_log/*.json',FORMAT='csv', FIELDQUOTE = '0x0b', FIELDTERMINATOR ='0x0b',ROWTERMINATOR = '0x0b')
with (line varchar(max)) as logs
Jeśli to zapytanie zakończy się niepowodzeniem, obiekt wywołujący nie ma uprawnień do odczytywania bazowych plików magazynu.
Wykonywanie zapytania
W następujących przypadkach mogą wystąpić błędy podczas wykonywania zapytania:
- Obiekt wywołujący nie może uzyskać dostępu do niektórych obiektów.
- Zapytanie nie może uzyskać dostępu do danych zewnętrznych.
- Zapytanie zawiera niektóre funkcje, które nie są obsługiwane w bezserwerowych pulach SQL.
Zapytanie kończy się niepowodzeniem, ponieważ nie można go wykonać z powodu bieżących ograniczeń zasobów
Zapytanie może zakończyć się niepowodzeniem z komunikatem o błędzie Ten komunikat This query cannot be executed due to current resource constraints. oznacza, że w tej chwili nie można wykonać bezserwerowej puli SQL. Poniżej przedstawiono kilka opcji rozwiązywania problemów:
- Upewnij się, że są używane typy danych o rozsądnych rozmiarach.
- Jeśli zapytanie dotyczy plików Parquet, rozważ zdefiniowanie jawnych typów dla kolumn ciągu, ponieważ będą one domyślnie typu VARCHAR(8000). Sprawdź wywnioskowane typy danych.
- Jeśli celem zapytania są pliki CSV, rozważ utworzenie statystyk.
- Aby dowiedzieć się, jak zoptymalizować zapytanie, zobacz Najlepsze rozwiązania dotyczące wydajności dla bezserwerowej puli SQL.
Upłynął limit czasu zapytania
Query timeout expired Błąd jest zwracany, jeśli zapytanie zostało wykonane ponad 30 minut w bezserwerowej puli SQL. Nie można zmienić tego limitu dla bezserwerowej puli SQL.
- Spróbuj zoptymalizować zapytanie, stosując najlepsze rozwiązania.
- Spróbuj zmaterializować części zapytań, używając polecenia create external table as select (CETAS).
- Sprawdź, czy istnieje współbieżne obciążenie uruchomione w bezserwerowej puli SQL, ponieważ inne zapytania mogą przyjmować zasoby. W takim przypadku obciążenie można podzielić na wiele obszarów roboczych.
Nieprawidłowa nazwa obiektu
Invalid object name 'table name' Błąd wskazuje, że używasz obiektu, takiego jak tabela lub widok, który nie istnieje w bezserwerowej bazie danych puli SQL. Wypróbuj następujące opcje:
Wyświetl listę tabel lub widoków i sprawdź, czy obiekt istnieje. Użyj programu SQL Server Management Studio lub azure Data Studio, ponieważ program Synapse Studio może wyświetlać tabele, które nie są dostępne w bezserwerowej puli SQL.
Jeśli widzisz obiekt, sprawdź, czy używasz sortowania bazy danych z uwzględnieniem wielkości liter/danych binarnych. Być może nazwa obiektu nie jest zgodna z nazwą użytą w zapytaniu. W przypadku
Employeesortowania binarnej bazy danych iemployeesą dwoma różnymi obiektami.Jeśli obiekt nie jest widoczny, być może próbujesz wykonać zapytanie dotyczące tabeli z bazy danych lake lub Spark. Tabela może nie być dostępna w bezserwerowej puli SQL, ponieważ:
- Tabela zawiera niektóre typy kolumn, których nie można przedstawić w bezserwerowej puli SQL.
- Tabela ma format, który nie jest obsługiwany w bezserwerowej puli SQL. Przykłady to Avro lub ORC.
Dane ciągowe lub binarne zostaną obcięte
Ten błąd występuje, jeśli długość ciągu lub typu kolumny binarnej (na przykład VARCHAR, VARBINARYlub NVARCHAR) jest krótsza niż rzeczywisty rozmiar odczytywanych danych. Ten błąd można naprawić, zwiększając długość typu kolumny:
- Jeśli kolumna ciągu jest zdefiniowana jako
VARCHAR(32)typ, a tekst ma 60 znaków, użyj typu (lub dłuższegoVARCHAR(60)) w schemacie kolumny. - Jeśli używasz wnioskowania schematu (bez schematu
WITH), wszystkie kolumny ciągów są definiowane automatycznie jakoVARCHAR(8000)typ. Jeśli wystąpi ten błąd, jawnie zdefiniuj schemat w klauzuli z większymVARCHAR(MAX)typemWITHkolumny, aby rozwiązać ten błąd. - Jeśli tabela znajduje się w bazie danych Lake, spróbuj zwiększyć rozmiar kolumny ciągu w puli Platformy Spark.
SET ANSI_WARNINGS OFFSpróbuj włączyć bezserwerową pulę SQL, aby automatycznie obcinać wartości VARCHAR, jeśli nie wpłynie to na funkcje.
Nieujawniany cudzysłów po ciągu znaku
W rzadkich przypadkach, gdy używasz operatora LIKE w kolumnie ciągu lub porównania z literałami ciągu, może wystąpić następujący błąd:
Unclosed quotation mark after the character string
Ten błąd może wystąpić, jeśli używasz sortowania Latin1_General_100_BIN2_UTF8 w kolumnie. Spróbuj ustawić Latin1_General_100_CI_AS_SC_UTF8 sortowanie w kolumnie zamiast Latin1_General_100_BIN2_UTF8 sortowania, aby rozwiązać ten problem. Jeśli błąd jest nadal zwracany, zgłoś wniosek o pomoc techniczną za pośrednictwem witryny Azure Portal.
Nie można przydzielić miejsca bazy danych tempdb podczas przesyłania danych z jednej dystrybucji do innej
Błąd Could not allocate tempdb space while transferring data from one distribution to another jest zwracany, gdy aparat wykonywania zapytania nie może przetwarzać danych i przesyłać je między węzłami, które wykonują zapytanie. Jest to specjalny przypadek błędu zapytania ogólnego , ponieważ nie można go wykonać z powodu bieżącego błędu ograniczeń zasobów. Ten błąd jest zwracany, gdy zasoby przydzielone do tempdb bazy danych nie są wystarczające do uruchomienia zapytania.
Zastosuj najlepsze rozwiązania przed złożeniem biletu pomocy technicznej.
Zapytanie kończy się niepowodzeniem z powodu błędu obsługi pliku zewnętrznego (osiągnięto maksymalną liczbę błędów)
Jeśli zapytanie zakończy się niepowodzeniem z komunikatem error handling external file: Max errors count reachedo błędzie , oznacza to, że istnieje niezgodność określonego typu kolumny i danych, które należy załadować.
Aby uzyskać więcej informacji na temat błędu i wierszy i kolumn do przejrzenia, zmień wersję analizatora z 2.0 na 1.0.
Przykład
Jeśli chcesz wykonać zapytanie dotyczące pliku names.csv za pomocą tego zapytania 1, bezserwerowa pula SQL usługi Azure Synapse zwraca następujący błąd: Na przykład: Error handling external file: 'Max error count reached'. File/External table name: [filepath].
Plik names.csv zawiera:
Id,first name,
1, Adam
2,Bob
3,Charles
4,David
5,Eva
Zapytanie 1:
SELECT
TOP 100 *
FROM
OPENROWSET(
BULK '[FILE-PATH OF CSV FILE]',
FORMAT = 'CSV',
PARSER_VERSION='2.0',
FIELDTERMINATOR =';',
FIRSTROW = 2
)
WITH (
[ID] SMALLINT,
[Text] VARCHAR (1) COLLATE Latin1_General_BIN2
)
AS [result]
Przyczyna
Gdy tylko wersja analizatora zostanie zmieniona z wersji 2.0 na 1.0, komunikaty o błędach pomagają zidentyfikować problem. Nowy komunikat o błędzie jest teraz Bulk load data conversion error (truncation) for row 1, column 2 (Text) in data file [filepath].
Obcięcie informuje, że typ kolumny jest zbyt mały, aby dopasować dane. Najdłuższa nazwa w tym names.csv pliku ma siedem znaków. Zgodnie z typem danych, który ma być używany, powinien być co najmniej VARCHAR(7). Błąd jest spowodowany tym wierszem kodu:
[Text] VARCHAR (1) COLLATE Latin1_General_BIN2
Zmiana zapytania odpowiednio usuwa błąd. Po debugowaniu ponownie zmień wersję analizatora na 2.0, aby osiągnąć maksymalną wydajność.
Aby uzyskać więcej informacji o tym, kiedy używać wersji analizatora, zobacz Use OPENROWSET using serverless SQL pool in Synapse Analytics (Używanie zestawu OPENROWSET przy użyciu bezserwerowej puli SQL w usłudze Synapse Analytics).
SELECT
TOP 100 *
FROM
OPENROWSET(
BULK '[FILE-PATH OF CSV FILE]',
FORMAT = 'CSV',
PARSER_VERSION='2.0',
FIELDTERMINATOR =';',
FIRSTROW = 2
)
WITH (
[ID] SMALLINT,
[Text] VARCHAR (7) COLLATE Latin1_General_BIN2
)
AS [result]
Nie można załadować zbiorczo, ponieważ nie można otworzyć pliku
Błąd Cannot bulk load because the file could not be opened jest zwracany, jeśli plik jest modyfikowany podczas wykonywania zapytania. Zazwyczaj może wystąpić błąd podobny do następującego: Cannot bulk load because the file {file path} could not be opened. Operating system error code 12. (The access code is invalid.)
Bezserwerowe pule SQL nie mogą odczytywać plików, które są modyfikowane podczas uruchamiania zapytania. Zapytanie nie może zablokować plików. Jeśli wiesz, że operacja modyfikacji jest dołączana, możesz spróbować ustawić następującą opcję: {"READ_OPTIONS":["ALLOW_INCONSISTENT_READS"]}.
Aby uzyskać więcej informacji, zobacz jak wykonywać zapytania dotyczące plików tylko do dołączania lub tworzyć tabele w plikach tylko do dołączania.
Zapytanie kończy się niepowodzeniem z powodu błędu konwersji danych
Zapytanie może zakończyć się niepowodzeniem z komunikatem o błędzie Ten komunikat Bulk load data conversion error (type mismatches or invalid character for the specified code page) for row n, column m [columnname] in the data file [filepath]. oznacza, że typy danych nie pasują do rzeczywistych danych dla numeru wiersza n i kolumny m.
Jeśli na przykład spodziewasz się tylko liczb całkowitych w danych, ale w wierszu n istnieje ciąg, ten komunikat o błędzie to ten, który otrzymasz.
Aby rozwiązać ten problem, sprawdź plik i wybrane typy danych. Sprawdź również, czy ogranicznik wiersza i ustawienia terminatora pól są poprawne. W poniższym przykładzie pokazano, jak można przeprowadzić inspekcję przy użyciu funkcji VARCHAR jako typu kolumny.
Aby uzyskać więcej informacji na temat terminatorów pól, ograniczników wierszy i znaków cudzysłów ucieczki, zobacz Query CSV files (Wykonywanie zapytań w plikach CSV).
Przykład
Jeśli chcesz wykonać zapytanie dotyczące pliku names.csv:
Id, first name,
1,Adam
2,Bob
3,Charles
4,David
five,Eva
Za pomocą następującego zapytania:
Zapytanie 1:
SELECT
TOP 100 *
FROM
OPENROWSET(
BULK '[FILE-PATH OF CSV FILE]',
FORMAT = 'CSV',
PARSER_VERSION='1.0',
FIELDTERMINATOR =',',
FIRSTROW = 2
)
WITH (
[ID] SMALLINT,
[Firstname] VARCHAR (25) COLLATE Latin1_General_BIN2
)
AS [result]
Bezserwerowa pula SQL usługi Azure Synapse zwraca błąd Bulk load data conversion error (type mismatch or invalid character for the specified code page) for row 6, column 1 (ID) in data file [filepath].
Konieczne jest przeglądanie danych i podejmowanie świadomej decyzji o obsłudze tego problemu. Aby zapoznać się z danymi, które powodują ten problem, najpierw należy zmienić typ danych. Zamiast wykonywać zapytania dotyczące kolumny ID z typem danych SMALLINT, funkcja VARCHAR(100) jest teraz używana do analizowania tego problemu.
W przypadku nieco zmienionego zapytania 2 dane można teraz przetworzyć, aby zwrócić listę nazw.
Zapytanie 2:
SELECT
TOP 100 *
FROM
OPENROWSET(
BULK '[FILE-PATH OF CSV FILE]',
FORMAT = 'CSV',
PARSER_VERSION='1.0',
FIELDTERMINATOR =',',
FIRSTROW = 2
)
WITH (
[ID] VARCHAR(100),
[Firstname] VARCHAR (25) COLLATE Latin1_General_BIN2
)
AS [result]
Możesz zauważyć, że dane mają nieoczekiwane wartości identyfikatora w piątym wierszu. W takich okolicznościach ważne jest, aby dopasować się do właściciela firmy danych, aby uzgodnić, w jaki sposób można uniknąć uszkodzenia danych, takich jak w tym przykładzie. Jeśli zapobieganie nie jest możliwe na poziomie aplikacji, rozsądny rozmiar VARCHAR może być jedyną opcją tutaj.
Napiwek
Staraj się, aby VARCHAR() był możliwie najkrótszy. Unikaj funkcji VARCHAR(MAX), jeśli to możliwe, ponieważ może to pogorszyć wydajność.
Wynik zapytania nie wygląda zgodnie z oczekiwaniami
Zapytanie może nie zakończyć się niepowodzeniem, ale może się okazać, że zestaw wyników nie jest zgodnie z oczekiwaniami. Wynikowe kolumny mogą być puste lub zwracane mogą być nieoczekiwane dane. W tym scenariuszu prawdopodobnie został niepoprawnie wybrany ogranicznik wiersza lub terminator pól.
Aby rozwiązać ten problem, zapoznaj się z danymi i zmień te ustawienia. Debugowanie tego zapytania jest łatwe, jak pokazano w poniższym przykładzie.
Przykład
Jeśli chcesz wykonać zapytanie względem pliku names.csv z zapytaniem w zapytaniu 1, bezserwerowa pula SQL usługi Azure Synapse zwraca wynik, który wygląda dziwnie:
W pliku names.csv:
Id,first name,
1, Adam
2, Bob
3, Charles
4, David
5, Eva
SELECT
TOP 100 *
FROM
OPENROWSET(
BULK '[FILE-PATH OF CSV FILE]',
FORMAT = 'CSV',
PARSER_VERSION='1.0',
FIELDTERMINATOR =';',
FIRSTROW = 2
)
WITH (
[ID] VARCHAR(100),
[Firstname] VARCHAR (25) COLLATE Latin1_General_BIN2
)
AS [result]
| ID | Firstname |
| ------------- |------------- |
| 1,Adam | NULL |
| 2,Bob | NULL |
| 3,Charles | NULL |
| 4,David | NULL |
| 5,Eva | NULL |
Wydaje się, że w kolumnie Firstnamenie ma żadnej wartości . Zamiast tego wszystkie wartości były w kolumnie ID . Te wartości są rozdzielone przecinkami. Problem został spowodowany przez ten wiersz kodu, ponieważ konieczne jest wybranie przecinka zamiast symbolu średnika jako terminatora pola:
FIELDTERMINATOR =';',
Zmiana tego pojedynczego znaku rozwiązuje problem:
FIELDTERMINATOR =',',
Zestaw wyników utworzony przez zapytanie 2 wygląda teraz zgodnie z oczekiwaniami:
Zapytanie 2:
SELECT
TOP 100 *
FROM
OPENROWSET(
BULK '[FILE-PATH OF CSV FILE]',
FORMAT = 'CSV',
PARSER_VERSION='1.0',
FIELDTERMINATOR =',',
FIRSTROW = 2
)
WITH (
[ID] VARCHAR(100),
[Firstname] VARCHAR (25) COLLATE Latin1_General_BIN2
)
AS [result]
Zwraca:
| ID | Firstname |
| ------------- |------------- |
| 1 | Adam |
| 2 | Bob |
| 3 | Charles |
| 4 | David |
| 5 | Eva |
Kolumna typu nie jest zgodna z typem danych zewnętrznych
Jeśli zapytanie zakończy się niepowodzeniem z komunikatem Column [column-name] of type [type-name] is not compatible with external data type […], o błędzie, prawdopodobnie typ danych PARQUET został zamapowany na nieprawidłowy typ danych SQL.
Jeśli na przykład plik Parquet ma cenę kolumny z liczbami zmiennoprzecinkowymi (na przykład 12.89) i próbowano zamapować go na INT, ten komunikat o błędzie jest tym, który otrzymasz.
Aby rozwiązać ten problem, sprawdź plik i wybrane typy danych. Ta tabela mapowania pomaga wybrać prawidłowy typ danych SQL. Najlepszym rozwiązaniem jest określenie mapowania tylko dla kolumn, które w przeciwnym razie zostaną rozpoznane jako typ danych VARCHAR. Unikanie funkcji VARCHAR, gdy to możliwe prowadzi do lepszej wydajności zapytań.
Przykład
Jeśli chcesz wykonać zapytanie dotyczące pliku taxi-data.parquet za pomocą tego zapytania 1, pula SQL bezserwerowa usługi Azure Synapse zwraca następujący błąd:
Plik taxi-data.parquet zawiera:
|PassengerCount |SumTripDistance|AvgTripDistance |
|---------------|---------------|----------------|
| 1 | 2635668.66000064 | 6.72731710678951 |
| 2 | 172174.330000005 | 2.97915543404919 |
| 3 | 296384.390000011 | 2.8991352022851 |
| 4 | 12544348.58999806| 6.30581582240281 |
| 5 | 13091570.2799993 | 111.065989028627 |
Zapytanie 1:
SELECT
*
FROM
OPENROWSET(
BULK '<filepath>taxi-data.parquet',
FORMAT='PARQUET'
) WITh
(
PassengerCount INT,
SumTripDistance INT,
AVGTripDistance FLOAT
)
AS [result]
Column 'SumTripDistance' of type 'INT' is not compatible with external data type 'Parquet physical type: DOUBLE', please try with 'FLOAT'. File/External table name: '<filepath>taxi-data.parquet'.
Ten komunikat o błędzie informuje, że typy danych nie są zgodne i zawiera sugestię użycia funkcji FLOAT zamiast INT. Błąd jest spowodowany tym wierszem kodu:
SumTripDistance INT,
W przypadku nieco zmienionego zapytania 2 dane można teraz przetworzyć i wyświetlić wszystkie trzy kolumny:
Zapytanie 2:
SELECT
*
FROM
OPENROWSET(
BULK '<filepath>taxi-data.parquet',
FORMAT='PARQUET'
) WITh
(
PassengerCount INT,
SumTripDistance FLOAT,
AVGTripDistance FLOAT
)
AS [result]
Zapytanie odwołuje się do obiektu, który nie jest obsługiwany w trybie przetwarzania rozproszonego
The query references an object that is not supported in distributed processing mode Błąd wskazuje, że użyto obiektu lub funkcji, której nie można użyć podczas wykonywania zapytań dotyczących danych w usłudze Azure Storage lub magazynie analitycznym usługi Azure Cosmos DB.
Niektóre obiekty, takie jak widoki systemowe i funkcje, nie mogą być używane podczas wykonywania zapytań dotyczących danych przechowywanych w usłudze Azure Data Lake lub magazynie analitycznym usługi Azure Cosmos DB. Unikaj używania zapytań, które łączą dane zewnętrzne z widokami systemowymi, ładują dane zewnętrzne w tabeli tymczasowej lub używają niektórych funkcji zabezpieczeń lub metadanych do filtrowania danych zewnętrznych.
Wywołanie WaitIOCompletion nie powiodło się
Komunikat WaitIOCompletion call failed o błędzie wskazuje, że zapytanie nie powiodło się podczas oczekiwania na ukończenie operacji we/wy, która odczytuje dane z magazynu zdalnego usługi Azure Data Lake.
Komunikat o błędzie ma następujący wzorzec: Error handling external file: 'WaitIOCompletion call failed. HRESULT = ???'. File/External table name...
Upewnij się, że magazyn znajduje się w tym samym regionie co bezserwerowa pula SQL. Sprawdź metryki magazynu i sprawdź, czy w warstwie magazynu nie ma żadnych innych obciążeń, takich jak przekazywanie nowych plików, które mogą nasycać żądania we/wy.
Pole HRESULT zawiera kod wyniku. Poniższe kody błędów są najbardziej typowe wraz z ich potencjalnymi rozwiązaniami.
Ten kod błędu oznacza, że plik źródłowy nie znajduje się w magazynie.
Istnieją powody, dla których ten kod błędu może wystąpić:
- Plik został usunięty przez inną aplikację.
- W tym typowym scenariuszu zostanie uruchomione wykonanie zapytania, wyliczenie plików i odnalezienie plików. Później podczas wykonywania zapytania plik zostanie usunięty. Można go na przykład usunąć za pomocą usługi Databricks, Spark lub Azure Data Factory. Zapytanie kończy się niepowodzeniem, ponieważ nie można odnaleźć pliku.
- Ten problem może również wystąpić w formacie delty. Zapytanie może zakończyć się pomyślnie ponawianie próby, ponieważ istnieje nowa wersja tabeli, a usunięty plik nie jest ponownie odpytywalny.
- Buforowany jest nieprawidłowy plan wykonania.
- Jako tymczasowy środek zaradczy uruchom polecenie
DBCC FREEPROCCACHE. Jeśli problem będzie się powtarzać, utwórz bilet pomocy technicznej.
- Jako tymczasowy środek zaradczy uruchom polecenie
Nieprawidłowa składnia w pobliżu NOT
Incorrect syntax near 'NOT' Błąd wskazuje, że istnieją pewne tabele zewnętrzne z kolumnami, które zawierają ograniczenie NOT NULL w definicji kolumny.
- Zaktualizuj tabelę, aby usunąć wartość NOT NULL z definicji kolumny.
- Ten błąd może wystąpić również przejściowo z tabelami utworzonymi na podstawie instrukcji CETAS. Jeśli problem nie zostanie rozwiązany, możesz spróbować usunąć i ponownie utworzyć tabelę zewnętrzną.
Kolumna partycji zwraca wartości NULL
Jeśli zapytanie zwraca wartości NULL zamiast partycjonowania kolumn lub nie może znaleźć kolumn partycji, możesz wykonać kilka możliwych kroków rozwiązywania problemów:
- Jeśli używasz tabel do wykonywania zapytań dotyczących partycjonowanego zestawu danych, tabele nie obsługują partycjonowania. Zastąp tabelę widokami podzielonymi na partycje.
- Jeśli używasz widoków partycjonowanych z funkcją OPENROWSET, która wykonuje zapytania dotyczące plików partycjonowanych przy użyciu funkcji FILEPATH(), upewnij się, że poprawnie określono wzorzec wieloznaczny w lokalizacji i użyto odpowiedniego indeksu do odwoływania się do symboli wieloznacznych.
- Jeśli wysyłasz zapytania do plików bezpośrednio w folderze podzielonym na partycje, kolumny partycjonowania nie są częściami kolumn plików. Wartości partycjonowania są umieszczane w ścieżkach folderów, a nie w plikach. Z tego powodu pliki nie zawierają wartości partycjonowania.
Wstawianie wartości do partii dla typu kolumny DATETIME2 nie powiodło się
Inserting value to batch for column type DATETIME2 failed Błąd wskazuje, że pula bezserwerowa nie może odczytać wartości daty z bazowych plików. Wartość datetime przechowywana w pliku Parquet lub Delta Lake nie może być reprezentowana jako kolumna DATETIME2 .
Sprawdź minimalną wartość w pliku przy użyciu platformy Spark i sprawdź, czy niektóre daty są mniejsze niż 0001-01-03. Jeśli pliki są przechowywane przy użyciu wersji platformy Spark 2.4 (nieobsługiwanej wersji środowiska uruchomieniowego) lub nowszej wersji platformy Spark, która nadal używa starszego formatu magazynu datetime, wartości daty/godziny przed zapisaną przy użyciu kalendarza Juliana, który nie jest zgodny z proleptycznym kalendarzem gregoriańskim używanym w bezserwerowych pulach SQL.
Może istnieć dwudniowa różnica między kalendarzem juliana używanym do zapisywania wartości w Parquet (w niektórych wersjach platformy Spark) i proleptycznego kalendarza gregoriańskiego używanego w bezserwerowej puli SQL. Ta różnica może spowodować konwersję na ujemną wartość daty, która jest nieprawidłowa.
Spróbuj użyć platformy Spark, aby zaktualizować te wartości, ponieważ są traktowane jako nieprawidłowe wartości dat w języku SQL. W poniższym przykładzie pokazano, jak zaktualizować wartości, które są poza zakresami dat SQL, na wartość NULL w usłudze Delta Lake:
from delta.tables import *
from pyspark.sql.functions import *
deltaTable = DeltaTable.forPath(spark,
"abfss://my-container@myaccount.dfs.core.windows.net/delta-lake-data-set")
deltaTable.update(col("MyDateTimeColumn") < '0001-02-02', { "MyDateTimeColumn": null } )
Ta zmiana usuwa wartości, których nie można przedstawić. Inne wartości daty mogą być poprawnie załadowane, ale niepoprawnie reprezentowane, ponieważ nadal istnieje różnica między kalendarzami juliana i proleptycznymi kalendarzami gregoriańskimi. Jeśli używasz platformy Spark 3.0 lub starszych wersji, może wystąpić nieoczekiwane zmiany dat nawet dla dat wcześniej 1900-01-01 .
Rozważ migrację do platformy Spark 3.1 lub nowszej i przełączenie do kalendarza proleptycznego gregoriańskiego. Najnowsze wersje platformy Spark domyślnie używają proleptycznego kalendarza gregoriańskiego, który jest zgodny z kalendarzem w bezserwerowej puli SQL. Załaduj ponownie starsze dane przy użyciu nowszej wersji platformy Spark i użyj następującego ustawienia, aby poprawić daty:
spark.conf.set("spark.sql.legacy.parquet.int96RebaseModeInWrite", "CORRECTED")
Zapytanie nie powiodło się z powodu zmiany topologii lub błędu kontenera obliczeniowego
Ten błąd może wskazywać, że w bezserwerowej puli SQL wystąpił problem z procesem wewnętrznym. Utwórz bilet pomocy technicznej ze wszystkimi niezbędnymi szczegółami, które mogą pomóc zespołowi pomoc techniczna platformy Azure zbadać problem.
Opisz wszystkie elementy, które mogą być nietypowe w porównaniu z regularnym obciążeniem. Na przykład może wystąpiła duża liczba współbieżnych żądań lub specjalne obciążenie lub rozpoczęto wykonywanie zapytania, zanim wystąpi ten błąd.
Przekroczono limit czasu rozszerzania symboli wieloznacznych
Zgodnie z opisem w sekcji Foldery zapytań i wiele plików bezserwerowa pula SQL obsługuje odczytywanie wielu plików/folderów przy użyciu symboli wieloznacznych. Istnieje maksymalny limit 10 symboli wieloznacznych na zapytanie. Należy pamiętać, że ta funkcja jest kosztem. Wyświetlenie listy wszystkich plików, które mogą być zgodne z symbolem wieloznacznymi, zajmuje trochę czasu. Spowoduje to opóźnienie, a to opóźnienie może wzrosnąć, jeśli liczba plików, które próbujesz wykonać zapytanie, jest wysoka. W takim przypadku można napotkać następujący błąd:
"Wildcard expansion timed out after X seconds."
Istnieje kilka kroków zaradczych, które można wykonać, aby tego uniknąć:
- Zastosuj najlepsze rozwiązania opisane w artykule Best Practices Serverless SQL Pool (Najlepsze rozwiązania bezserwerowej puli SQL).
- Spróbuj zmniejszyć liczbę plików, które próbujesz wykonać zapytanie, kompaktowając pliki na większe. Spróbuj zachować rozmiary plików powyżej 100 MB.
- Upewnij się, że filtry w kolumnach partycjonowania są używane wszędzie tam, gdzie to możliwe.
- Jeśli używasz formatu pliku różnicowego, użyj funkcji optymalizowania zapisu na platformie Spark. Może to poprawić wydajność zapytań, zmniejszając ilość danych, które muszą być odczytywane i przetwarzane. Jak używać optymalizacji zapisu opisano w temacie Korzystanie z optymalizacji zapisu na platformie Apache Spark.
- Aby uniknąć niektórych symboli wieloznacznych najwyższego poziomu, skutecznie hardcoding niejawnych filtrów w kolumnach partycjonowania używają dynamicznego języka SQL.
Brak kolumny podczas korzystania z automatycznego wnioskowania schematu
Możesz łatwo wykonywać zapytania dotyczące plików bez znajomości lub określania schematu, pomijając klauzulę WITH. W takim przypadku nazwy kolumn i typy danych zostaną wywnioskowane z plików. Należy pamiętać, że jeśli odczytujesz jednocześnie liczbę plików, schemat zostanie wywnioskowany z pierwszej usługi plików pobieranej z magazynu. Może to oznaczać, że niektóre oczekiwane kolumny zostaną pominięte, ponieważ plik używany przez usługę do zdefiniowania schematu nie zawiera tych kolumn. Aby jawnie określić schemat, użyj klauzuli OPENROWSET WITH. W przypadku określenia schematu (przy użyciu tabeli zewnętrznej lub klauzuli OPENROWSET WITH) zostanie użyty domyślny tryb ścieżki lax. Oznacza to, że kolumny, które nie istnieją w niektórych plikach, zostaną zwrócone jako listy NUL (w przypadku wierszy z tych plików). Aby dowiedzieć się, jak jest używany tryb ścieżki, zapoznaj się z następującą dokumentacją i przykładową dokumentacją.
Konfigurowanie
Bezserwerowe pule SQL umożliwiają konfigurowanie obiektów bazy danych przy użyciu języka T-SQL. Istnieją pewne ograniczenia:
- Nie można tworzyć obiektów w bazach danych platformy Spark ani w
masterbazachlakehousedanych platformy Spark. - Aby utworzyć poświadczenia, musisz mieć klucz główny.
- Musisz mieć uprawnienia do odwołowywania się do danych używanych w obiektach.
Nie można utworzyć bazy danych
Jeśli wystąpi błąd CREATE DATABASE failed. User database limit has been already reached., utworzono maksymalną liczbę baz danych obsługiwanych w jednym obszarze roboczym. Aby uzyskać więcej informacji, zobacz Ograniczenia.
- Jeśli musisz oddzielić obiekty, użyj schematów w bazach danych.
- Jeśli musisz odwołać się do usługi Azure Data Lake Storage, utwórz bazy danych lakehouse lub bazy danych platformy Spark, które zostaną zsynchronizowane w bezserwerowej puli SQL.
Tworzenie lub zmienianie tabeli nie powiodło się, ponieważ minimalny rozmiar wiersza przekracza maksymalny dozwolony rozmiar wiersza tabeli wynoszący 8060 bajtów
Każda tabela może mieć maksymalnie 8 KB rozmiaru na wiersz (nie obejmuje danych OFF-row VARCHAR(MAX)/VARBINARY(MAX). Jeśli utworzysz tabelę, w której całkowity rozmiar komórek w wierszu przekracza 8060 bajtów, zostanie wyświetlony następujący błąd:
Msg 1701, Level 16, State 1, Line 3
Creating or altering table '<table name>' failed because the minimum row size would be <???>,
including <???> bytes of internal overhead.
This exceeds the maximum allowable table row size of 8060 bytes.
Ten błąd może również wystąpić w bazie danych Lake, jeśli tworzysz tabelę Spark z rozmiarami kolumn przekraczającymi 8060 bajtów, a bezserwerowa pula SQL nie może utworzyć tabeli odwołującej się do danych tabeli Spark.
Jako ograniczenie ryzyka należy unikać używania typów o stałym rozmiarze, takich jak CHAR(N) i zastępować je zmiennymi typami rozmiarów VARCHAR(N) , lub zmniejszyć rozmiar w programie CHAR(N). Zobacz ograniczenie grupy wierszy 8 KB w programie SQL Server.
Utwórz klucz główny w bazie danych lub otwórz klucz główny w sesji przed wykonaniem tej operacji
Jeśli zapytanie zakończy się niepowodzeniem z komunikatem Please create a master key in the database or open the master key in the session before performing this operation.o błędzie , oznacza to, że baza danych użytkownika nie ma obecnie dostępu do klucza głównego.
Najprawdopodobniej utworzono nową bazę danych użytkownika i nie utworzono jeszcze klucza głównego.
Aby rozwiązać ten problem, utwórz klucz główny przy użyciu następującego zapytania:
CREATE MASTER KEY [ ENCRYPTION BY PASSWORD ='strongpasswordhere' ];
Uwaga
Zastąp 'strongpasswordhere' element innym wpisem tajnym tutaj.
Instrukcja CREATE nie jest obsługiwana w bazie danych master
Jeśli zapytanie zakończy się niepowodzeniem z komunikatem Failed to execute query. Error: CREATE EXTERNAL TABLE/DATA SOURCE/DATABASE SCOPED CREDENTIAL/FILE FORMAT is not supported in master database.o błędzie , oznacza to, że master baza danych w bezserwerowej puli SQL nie obsługuje tworzenia:
- Tabele zewnętrzne.
- Zewnętrzne źródła danych.
- Poświadczenia o zakresie bazy danych.
- Formaty plików zewnętrznych.
Oto rozwiązanie:
Utwórz bazę danych użytkownika:
CREATE DATABASE <DATABASE_NAME>Wykonaj instrukcję CREATE w kontekście <DATABASE_NAME>, która nie powiodła się wcześniej dla
masterbazy danych.Oto przykład tworzenia formatu pliku zewnętrznego:
USE <DATABASE_NAME> CREATE EXTERNAL FILE FORMAT [SynapseParquetFormat] WITH ( FORMAT_TYPE = PARQUET)
Nie można utworzyć nazwy logowania ani użytkownika w usłudze Microsoft Entra
Jeśli podczas próby utworzenia nowego identyfikatora logowania lub użytkownika usługi Microsoft Entra w bazie danych wystąpi błąd, sprawdź identyfikator logowania użyty do nawiązania połączenia z bazą danych. Identyfikator logowania, który próbuje utworzyć nowego użytkownika firmy Microsoft Entra, musi mieć uprawnienia dostępu do domeny Microsoft Entra i sprawdzić, czy użytkownik istnieje. Należy pamiętać, że:
- Identyfikatory logowania SQL nie mają tego uprawnienia, dlatego ten błąd będzie zawsze wyświetlany, jeśli używasz uwierzytelniania SQL.
- Jeśli do tworzenia nowych logowań używasz nazwy logowania firmy Microsoft Entra, sprawdź, czy masz uprawnienia dostępu do domeny Microsoft Entra.
Azure Cosmos DB
Bezserwerowe pule SQL umożliwiają wykonywanie zapytań względem magazynu analitycznego OPENROWSET usługi Azure Cosmos DB przy użyciu funkcji . Upewnij się, że kontener usługi Azure Cosmos DB ma magazyn analityczny. Upewnij się, że poprawnie określono konto, bazę danych i nazwę kontenera. Upewnij się również, że klucz konta usługi Azure Cosmos DB jest prawidłowy. Aby uzyskać więcej informacji, zobacz Wymagania wstępne.
Nie można wykonywać zapytań dotyczących usługi Azure Cosmos DB przy użyciu funkcji OPENROWSET
Jeśli nie możesz nawiązać połączenia z kontem usługi Azure Cosmos DB, zapoznaj się z wymaganiami wstępnymi. Możliwe błędy i akcje rozwiązywania problemów są wymienione w poniższej tabeli.
| Błąd | Główna przyczyna |
|---|---|
| Błędy składniowe: - Nieprawidłowa składnia w pobliżu OPENROWSET.- ... nie jest rozpoznawaną BULK OPENROWSET opcją dostawcy.- Nieprawidłowa składnia w pobliżu .... |
Możliwe główne przyczyny: — Nieużywaj usługi Azure Cosmos DB jako pierwszego parametru. — Używanie literału ciągu zamiast identyfikatora w trzecim parametrze. — Nie określa trzeciego parametru (nazwa kontenera). |
| Wystąpił błąd w parametry połączenia usługi Azure Cosmos DB. | — Nie określono konta, bazy danych lub klucza. — Opcja w parametry połączenia nie jest rozpoznawana. - Średnik ( ;) jest umieszczony na końcu parametry połączenia. |
| Rozwiązywanie problemu ze ścieżką usługi Azure Cosmos DB nie powiodło się z powodu błędu "Nieprawidłowa nazwa konta" lub "Nieprawidłowa nazwa bazy danych". | Nie można odnaleźć określonej nazwy konta, nazwy bazy danych lub kontenera albo nie włączono magazynu analitycznego dla określonej kolekcji. |
| Rozwiązywanie problemu ze ścieżką usługi Azure Cosmos DB nie powiodło się z powodu błędu "Nieprawidłowa wartość wpisu tajnego" lub "Wpis tajny ma wartość null lub jest pusta". | Klucz konta jest nieprawidłowy lub brakuje go. |
Zwracane jest ostrzeżenie dotyczące sortowania UTF-8 podczas odczytywania typów ciągów usługi Azure Cosmos DB
Bezserwerowa pula SQL zwraca ostrzeżenie czasu kompilacji, jeśli OPENROWSET sortowanie kolumn nie ma kodowania UTF-8. Sortowanie domyślne dla wszystkich OPENROWSET funkcji uruchomionych w bieżącej bazie danych można łatwo zmienić przy użyciu instrukcji języka T-SQL:
ALTER DATABASE CURRENT COLLATE Latin1_General_100_CI_AS_SC_UTF8;
Sortowanie Latin1_General_100_BIN2_UTF8 zapewnia najlepszą wydajność podczas filtrowania danych przy użyciu predykatów ciągów.
Brak wierszy w magazynie analitycznym usługi Azure Cosmos DB
Niektóre elementy z usługi Azure Cosmos DB mogą nie być zwracane przez OPENROWSET funkcję. Należy pamiętać, że:
- Występuje opóźnienie synchronizacji między magazynem transakcyjnym i analitycznym. Dokument wprowadzony w magazynie transakcyjnym usługi Azure Cosmos DB może pojawić się w magazynie analitycznym po dwóch do trzech minutach.
- Dokument może naruszać pewne ograniczenia schematu.
Zapytanie zwraca wartości NULL w niektórych elementach usługi Azure Cosmos DB
Usługa Azure Synapse SQL zwraca wartość NULL zamiast wartości widocznych w magazynie transakcji w następujących przypadkach:
- Występuje opóźnienie synchronizacji między magazynem transakcyjnym i analitycznym. Wartość wprowadzona w magazynie transakcyjnym usługi Azure Cosmos DB może pojawić się w magazynie analitycznym po dwóch do trzech minutach.
- W klauzuli WITH może występować nieprawidłowa nazwa kolumny lub wyrażenie ścieżki. Nazwa kolumny (lub wyrażenie ścieżki po typie kolumny) w klauzuli WITH musi być zgodna z nazwami właściwości w kolekcji usługi Azure Cosmos DB. Porównanie uwzględnia wielkość liter. Na przykład
productCodeiProductCodesą różnymi właściwościami. Upewnij się, że nazwy kolumn są dokładnie zgodne z nazwami właściwości usługi Azure Cosmos DB. - Właściwość może nie zostać przeniesiona do magazynu analitycznego, ponieważ narusza pewne ograniczenia schematu, takie jak ponad 1000 właściwości lub więcej niż 127 poziomów zagnieżdżania.
- Jeśli używasz dobrze zdefiniowanej reprezentacji schematu, wartość w magazynie transakcyjnym może mieć nieprawidłowy typ. Dobrze zdefiniowany schemat blokuje typy dla każdej właściwości przez próbkowanie dokumentów. Każda wartość dodana w magazynie transakcyjnym, który nie jest zgodny z typem, jest traktowana jako nieprawidłowa wartość i nie jest migrowana do magazynu analitycznego.
- Jeśli używasz reprezentacji schematu o pełnej wierności, upewnij się, że dodajesz sufiks typu po nazwie właściwości, takiej jak
$.price.int64. Jeśli nie widzisz wartości dla ścieżki, do której odwołuje się odwołanie, może jest ona przechowywana w innej ścieżce typu, na przykład$.price.float64. Aby uzyskać więcej informacji, zobacz Query Azure Cosmos DB collections in the full-fidelity schema (Wykonywanie zapytań względem kolekcji usługi Azure Cosmos DB w schemacie pełnej wierności).
Kolumna nie jest zgodna z typem danych zewnętrznych
Błąd Column 'column name' of the type 'type name' is not compatible with the external data type 'type name'. jest zwracany, jeśli określony typ kolumny w klauzuli WITH nie jest zgodny z typem w kontenerze usługi Azure Cosmos DB. Spróbuj zmienić typ kolumny zgodnie z opisem w sekcji Azure Cosmos DB na mapowania typów SQL lub użyć typu VARCHAR.
Rozwiązywanie problemu: ścieżka usługi Azure Cosmos DB nie powiodła się z powodu błędu
Jeśli zostanie wyświetlony błąd, Resolving Azure Cosmos DB path has failed with error 'This request is not authorized to perform this operation'. sprawdź, czy w usłudze Azure Cosmos DB użyto prywatnych punktów końcowych. Aby zezwolić bezserwerowej puli SQL na dostęp do magazynu analitycznego z prywatnymi punktami końcowymi, należy skonfigurować prywatne punkty końcowe dla magazynu analitycznego usługi Azure Cosmos DB.
Problemy z wydajnością usługi Azure Cosmos DB
Jeśli wystąpią nieoczekiwane problemy z wydajnością, upewnij się, że zastosowano najlepsze rozwiązania, takie jak:
- Upewnij się, że aplikacja kliencka, pula bezserwerowa i magazyn analityczny usługi Azure Cosmos DB zostały umieszczone w tym samym regionie.
- Upewnij się, że używasz klauzuli WITH z optymalnymi typami danych.
- Upewnij się, że używasz sortowania Latin1_General_100_BIN2_UTF8 podczas filtrowania danych przy użyciu predykatów ciągów.
- Jeśli masz powtarzające się zapytania, które mogą być buforowane, spróbuj użyć instrukcji CETAS do przechowywania wyników zapytań w usłudze Azure Data Lake Storage.
Delta Lake
Istnieją pewne ograniczenia, które mogą być widoczne w obsłudze usługi Delta Lake w bezserwerowych pulach SQL:
- Upewnij się, że odwołujesz się do głównego folderu usługi Delta Lake w funkcji OPENROWSET lub lokalizacji tabeli zewnętrznej.
- Folder główny musi mieć podfolder o nazwie
_delta_log. Zapytanie kończy się niepowodzeniem, jeśli nie_delta_logma folderu. Jeśli ten folder nie jest widoczny, odwołujesz się do zwykłych plików Parquet, które muszą zostać przekonwertowane na usługę Delta Lake przy użyciu pul platformy Apache Spark. - Nie należy określać symboli wieloznacznych do opisania schematu partycji. Zapytanie usługi Delta Lake automatycznie identyfikuje partycje usługi Delta Lake.
- Folder główny musi mieć podfolder o nazwie
- Tabele usługi Delta Lake utworzone w pulach platformy Apache Spark są automatycznie dostępne w bezserwerowej puli SQL, ale schemat nie jest aktualizowany (ograniczenie publicznej wersji zapoznawczej). Jeśli dodasz kolumny w tabeli delty przy użyciu puli Spark, zmiany nie będą wyświetlane w bezserwerowej bazie danych puli SQL.
- Tabele zewnętrzne nie obsługują partycjonowania. Użyj widoków partycjonowanych w folderze usługi Delta Lake, aby użyć eliminacji partycji. Zobacz znane problemy i obejścia w dalszej części artykułu.
- Bezserwerowe pule SQL nie obsługują zapytań dotyczących podróży w czasie. Użyj pul platformy Apache Spark w usłudze Synapse Analytics, aby odczytywać dane historyczne.
- Bezserwerowe pule SQL nie obsługują aktualizowania plików usługi Delta Lake. Do wykonywania zapytań dotyczących najnowszej wersji usługi Delta Lake można użyć bezserwerowej puli SQL. Użyj pul platformy Apache Spark w usłudze Synapse Analytics, aby zaktualizować usługę Delta Lake.
- Wyniki zapytań nie można przechowywać w magazynie w formacie usługi Delta Lake przy użyciu polecenia CETAS. Polecenie CETAS obsługuje tylko formaty wyjściowe Parquet i CSV.
- Bezserwerowe pule SQL w usłudze Synapse Analytics są zgodne z czytnikiem różnicowym w wersji 1.
- Bezserwerowe pule SQL w usłudze Synapse Analytics nie obsługują zestawów danych z filtrem BLOOM. Bezserwerowa pula SQL ignoruje filtry BLOOM.
- Obsługa usługi Delta Lake nie jest dostępna w dedykowanych pulach SQL. Upewnij się, że do wykonywania zapytań dotyczących plików usługi Delta Lake używasz bezserwerowych pul SQL.
- Aby uzyskać więcej informacji na temat znanych problemów z bezserwerowymi pulami SQL, zobacz Znane problemy z usługą Azure Synapse Analytics.
Bezserwerowa obsługa wersji delta 1.0
Bezserwerowe pule SQL odczytują tylko wersję usługi Delta Lake 1.0. Bezserwerowe pule SQL to czytnik różnicowy z poziomem 1 i nie obsługuje następujących funkcji:
- Mapowania kolumn są ignorowane — bezserwerowe pule SQL będą zwracać oryginalne nazwy kolumn.
- Wektory usuwania są ignorowane, a stara wersja usuniętych/zaktualizowanych wierszy zostanie zwrócona (prawdopodobnie nieprawidłowe wyniki).
- Następujące funkcje usługi Delta Lake nie są obsługiwane: punkty kontrolne w wersji 2, znacznik czasu bez strefy czasowej, sprawdzanie protokołu VACUUM
Wektory usuwania są ignorowane
Jeśli tabela usługi Delta Lake jest skonfigurowana do używania składnika zapisywania różnicowego w wersji 7, będzie przechowywać usunięte wiersze i stare wersje zaktualizowanych wierszy w kodzie Delete Vectors (DV). Ponieważ bezserwerowe pule SQL mają poziom czytnika różnicowego 1, zignoruje wektory usuwania i prawdopodobnie generują nieprawidłowe wyniki podczas odczytywania nieobsługiwanej wersji usługi Delta Lake.
Zmiana nazwy kolumny w tabeli delty nie jest obsługiwana
Bezserwerowa pula SQL nie obsługuje wykonywania zapytań dotyczących tabel usługi Delta Lake z kolumnami o zmienionej nazwie. Bezserwerowa pula SQL nie może odczytać danych z kolumny o zmienionej nazwie.
Wartość kolumny w tabeli delty ma wartość NULL
Jeśli używasz zestawu danych delty, który wymaga czytnika różnicowego w wersji 2 lub nowszej i używasz funkcji, które nie są obsługiwane w wersji 1 (na przykład — zmienianie nazw kolumn, upuszczanie kolumn lub mapowanie kolumn), wartości w przywoływanych kolumnach mogą nie być wyświetlane.
Tekst JSON nie jest poprawnie sformatowany
Ten błąd wskazuje, że bezserwerowa pula SQL nie może odczytać dziennika transakcji usługi Delta Lake. Prawdopodobnie zostanie wyświetlony następujący błąd:
Msg 13609, Level 16, State 4, Line 1
JSON text is not properly formatted. Unexpected character '' is found at position 263934.
Msg 16513, Level 16, State 0, Line 1
Error reading external metadata.
Upewnij się, że zestaw danych usługi Delta Lake nie jest uszkodzony. Sprawdź, czy możesz odczytać zawartość folderu usługi Delta Lake przy użyciu puli platformy Apache Spark w usłudze Azure Synapse. W ten sposób upewnisz się, że _delta_log plik nie jest uszkodzony.
Obejście
Spróbuj utworzyć punkt kontrolny w zestawie danych usługi Delta Lake przy użyciu puli platformy Apache Spark i ponownie uruchomić zapytanie. Punkt kontrolny agreguje transakcyjne pliki dziennika JSON i może rozwiązać ten problem.
Jeśli zestaw danych jest prawidłowy, utwórz bilet pomocy technicznej i podaj więcej informacji:
- Nie wprowadzaj żadnych zmian, takich jak dodawanie lub usuwanie kolumn ani optymalizowanie tabeli, ponieważ ta operacja może zmienić stan plików dziennika transakcji usługi Delta Lake.
- Skopiuj zawartość
_delta_logfolderu do nowego pustego folderu. Nie kopiuj.parquet dataplików. - Spróbuj odczytać zawartość skopiowaną w nowym folderze i sprawdzić, czy występuje ten sam błąd.
- Wyślij zawartość skopiowanego
_delta_logpliku do pomoc techniczna platformy Azure.
Teraz możesz kontynuować korzystanie z folderu usługi Delta Lake z pulą platformy Spark. Jeśli zezwolisz na udostępnianie tych informacji, przekażesz skopiowane dane do pomocy technicznej firmy Microsoft. Zespół platformy Azure zbada zawartość delta_log pliku i przekaże więcej informacji o możliwych błędach i obejściach.
Rozwiązywanie problemów z niepowodzeniem dzienników różnicowych
Następujący błąd wskazuje, że bezserwerowa pula SQL nie może rozpoznać dzienników różnicowych: Resolving Delta logs on path '%ls' failed with error: Cannot parse json object from log folder. Najczęstszą przyczyną jest to, że last_checkpoint_file w _delta_log folderze jest więcej niż 200 bajtów ze względu na checkpointSchema pole dodane na platformie Spark 3.3.
Dostępne są dwie opcje obejścia tego błędu:
- Zmodyfikuj odpowiednią konfigurację w notesie platformy Spark i wygeneruj nowy punkt kontrolny, aby
last_checkpoint_filezostał utworzony ponownie. W przypadku korzystania z usługi Azure Databricks modyfikacja konfiguracji jest następująca:spark.conf.set("spark.databricks.delta.checkpointSchema.writeThresholdLength", 0); - Obniżanie poziomu do platformy Spark w wersji 3.2.1.
Nasz zespół inżynierów pracuje obecnie nad pełną obsługą platformy Spark 3.3.
Tabela różnicowa utworzona na platformie Spark nie jest wyświetlana w bezserwerowej puli
Uwaga
Replikacja tabel delty utworzonych na platformie Spark jest nadal dostępna w publicznej wersji zapoznawczej.
Jeśli utworzono tabelę delty na platformie Spark i nie jest ona wyświetlana w bezserwerowej puli SQL, sprawdź następujące kwestie:
- Poczekaj trochę czasu (zwykle 30 sekund), ponieważ tabele platformy Spark są synchronizowane z opóźnieniem.
- Jeśli tabela nie pojawiła się w bezserwerowej puli SQL po pewnym czasie, sprawdź schemat tabeli delta platformy Spark. Tabele platformy Spark z złożonymi typami lub typami, które nie są obsługiwane w trybie bezserwerowym, nie są dostępne. Spróbuj utworzyć tabelę Spark Parquet z tym samym schematem w bazie danych lake i sprawdź, czy tabela jest wyświetlana w bezserwerowej puli SQL.
- Sprawdź folder Delta Lake dostępu do tożsamości zarządzanej obszaru roboczego, do którego odwołuje się tabela. Bezserwerowa pula SQL używa tożsamości zarządzanej obszaru roboczego, aby uzyskać informacje o kolumnie tabeli z magazynu w celu utworzenia tabeli.
Baza danych typu lake
Tabele bazy danych Lake utworzone przy użyciu platformy Spark lub projektanta usługi Synapse są automatycznie dostępne w bezserwerowej puli SQL na potrzeby wykonywania zapytań. Bezserwerowa pula SQL umożliwia wykonywanie zapytań względem tabel Parquet, CSV i Delta Lake utworzonych przy użyciu puli Spark oraz dodawania innych schematów, widoków, procedur, funkcji tabel i użytkowników usługi Microsoft Entra w db_datareader roli do bazy danych Lake. Możliwe problemy są wymienione w tej sekcji.
Tabela utworzona na platformie Spark nie jest dostępna w bezserwerowej puli
Utworzone tabele mogą nie być natychmiast dostępne w bezserwerowej puli SQL.
- Tabele będą dostępne w pulach bezserwerowych z pewnym opóźnieniem. Może być konieczne odczekenie 5–10 minut po utworzeniu tabeli na platformie Spark, aby zobaczyć ją w bezserwerowej puli SQL.
- Tylko tabele odwołujące się do formatów Parquet, CSV i Delta są dostępne w bezserwerowej puli SQL. Inne typy tabel nie są dostępne.
- Tabela zawierająca nieobsługiwane typy kolumn nie będzie dostępna w bezserwerowej puli SQL.
- Uzyskiwanie dostępu do tabel usługi Delta Lake w bazach danych usługi Lake jest dostępne w publicznej wersji zapoznawczej. Sprawdź inne problemy wymienione w tej sekcji lub w sekcji usługi Delta Lake.
Tabela zewnętrzna utworzona na platformie Spark pokazuje nieoczekiwane wyniki w puli bezserwerowej
Może się zdarzyć, że istnieje niezgodność między źródłową tabelą zewnętrzną Platformy Spark a replikowanymi tabelami zewnętrznymi w puli bezserwerowej. Może się tak zdarzyć, jeśli pliki używane podczas tworzenia tabel zewnętrznych platformy Spark są bez rozszerzeń. Aby uzyskać odpowiednie wyniki, upewnij się, że wszystkie pliki mają rozszerzenia, takie jak .parquet.
Operacja nie jest dozwolona dla replikowanej bazy danych
Ten błąd jest zwracany, jeśli próbujesz zmodyfikować bazę danych lake, utworzyć tabele zewnętrzne, zewnętrzne źródła danych, poświadczenia o zakresie bazy danych lub inne obiekty w bazie danych Lake. Te obiekty można tworzyć tylko w bazach danych SQL.
Bazy danych usługi Lake są replikowane z puli platformy Apache Spark i zarządzane przez platformę Apache Spark. W związku z tym nie można tworzyć obiektów, takich jak w bazach danych SQL Database, przy użyciu języka T-SQL.
Tylko następujące operacje są dozwolone w bazach danych lake:
- Tworzenie, upuszczanie lub zmienianie widoków, procedur i wbudowanych funkcji table-value (iTVF) w schematach innych niż
dbo. - Tworzenie i usuwanie użytkowników bazy danych z identyfikatora Entra firmy Microsoft.
- Dodawanie lub usuwanie użytkowników bazy danych ze
db_datareaderschematu.
Inne operacje nie są dozwolone w bazach danych usługi Lake.
Uwaga
Jeśli tworzysz widok, procedurę lub funkcję w dbo schemacie (lub pomijasz schemat i używasz domyślnego, który jest zwykle dbo), zostanie wyświetlony komunikat o błędzie.
Tabele różnicowe w bazach danych usługi Lake nie są dostępne w bezserwerowej puli SQL
Upewnij się, że tożsamość zarządzana obszaru roboczego ma dostęp do odczytu w magazynie usługi ADLS zawierającym folder delta. Bezserwerowa pula SQL odczytuje schemat tabeli usługi Delta Lake z dzienników delty umieszczonych w usłudze ADLS i używa tożsamości zarządzanej obszaru roboczego do uzyskiwania dostępu do dzienników transakcji usługi Delta.
Spróbuj skonfigurować źródło danych w usłudze SQL Database, które odwołuje się do usługi Azure Data Lake Storage przy użyciu poświadczeń tożsamości zarządzanej, i spróbuj utworzyć zewnętrzną tabelę na podstawie źródła danych z tożsamością zarządzaną, aby potwierdzić, że tabela z tożsamością zarządzaną może uzyskać dostęp do magazynu.
Tabele różnicowe w bazach danych usługi Lake nie mają identycznego schematu w pulach platformy Spark i bezserwerowych
Bezserwerowe pule SQL umożliwiają uzyskiwanie dostępu do tabel Parquet, CSV i Delta utworzonych w bazie danych usługi Lake przy użyciu narzędzia Spark lub projektanta usługi Synapse. Uzyskiwanie dostępu do tabel delty jest nadal dostępne w publicznej wersji zapoznawczej, a obecnie bezserwerowa synchronizuje tabelę różnicową z platformą Spark w momencie tworzenia, ale nie zaktualizuje schematu, jeśli kolumny zostaną dodane później przy użyciu ALTER TABLE instrukcji w platformie Spark.
Jest to ograniczenie publicznej wersji zapoznawczej. Upuść i ponownie utwórz tabelę delta na platformie Spark (jeśli jest to możliwe) zamiast zmieniać tabele, aby rozwiązać ten problem.
Wydajność
Bezserwerowa pula SQL przypisuje zasoby do zapytań na podstawie rozmiaru zestawu danych i złożoności zapytań. Nie można zmienić ani ograniczyć zasobów dostarczanych do zapytań. Istnieje kilka przypadków, w których może wystąpić nieoczekiwane obniżenie wydajności zapytań i może być konieczne zidentyfikowanie głównych przyczyn.
Czas trwania zapytania jest bardzo długi
Jeśli masz zapytania z czasem trwania zapytania dłuższym niż 30 minut, zapytanie powoli zwraca wyniki do klienta. Bezserwerowa pula SQL ma limit 30 minut na potrzeby wykonywania. Więcej czasu poświęca się na przesyłanie strumieniowe wyników. Wypróbuj następujące rozwiązania:
- Jeśli używasz programu Synapse Studio, spróbuj odtworzyć problemy z inną aplikacją, na przykład SQL Server Management Studio lub Azure Data Studio.
- Jeśli zapytanie działa wolno po wykonaniu przy użyciu programu SQL Server Management Studio, Azure Data Studio, Power BI lub innej aplikacji, sprawdź problemy z siecią i najlepsze rozwiązania.
- Umieść zapytanie w poleceniu CETAS i zmierz czas trwania zapytania. Polecenie CETAS przechowuje wyniki w usłudze Azure Data Lake Storage i nie zależy od połączenia klienta. Jeśli polecenie CETAS zakończy się szybciej niż oryginalne zapytanie, sprawdź przepustowość sieci między klientem a bezserwerową pulą SQL.
Zapytanie działa wolno po wykonaniu przy użyciu programu Synapse Studio
Jeśli używasz programu Synapse Studio, spróbuj użyć klienta klasycznego, takiego jak SQL Server Management Studio lub Azure Data Studio. Synapse Studio to klient internetowy, który łączy się z bezserwerową pulą SQL przy użyciu protokołu HTTP, który jest zazwyczaj wolniejszy niż natywne połączenia SQL używane w programie SQL Server Management Studio lub Azure Data Studio.
Zapytanie działa wolno po wykonaniu przy użyciu aplikacji
Sprawdź następujące problemy, jeśli występują powolne wykonywanie zapytań:
- Upewnij się, że aplikacje klienckie są sortowane z bezserwerowym punktem końcowym puli SQL. Wykonanie zapytania w całym regionie może spowodować dodatkowe opóźnienie i powolne przesyłanie strumieniowe zestawu wyników.
- Upewnij się, że nie masz problemów z siecią, które mogą powodować powolne przesyłanie strumieniowe zestawu wyników
- Upewnij się, że aplikacja kliencka ma wystarczającą ilość zasobów (na przykład nie używa 100% procesora CPU).
- Upewnij się, że konto magazynu lub magazyn analityczny usługi Azure Cosmos DB znajdują się w tym samym regionie co bezserwerowy punkt końcowy SQL.
Zobacz najlepsze rozwiązania dotyczące sortowania zasobów.
Duże różnice w czasie trwania zapytań
Jeśli wykonujesz to samo zapytanie i obserwujesz różnice w czasie trwania zapytania, kilka powodów może spowodować to zachowanie:
- Sprawdź, czy jest to pierwsze wykonanie zapytania. Pierwsze wykonanie zapytania zbiera statystyki wymagane do utworzenia planu. Statystyki są zbierane przez skanowanie bazowych plików i może zwiększyć czas trwania zapytania. W programie Synapse Studio zobaczysz zapytania "globalne tworzenie statystyk" na liście żądań SQL, które są wykonywane przed zapytaniem.
- Statystyki mogą wygasnąć po pewnym czasie. Okresowo możesz zaobserwować wpływ na wydajność, ponieważ pula bezserwerowa musi skanować i ponownie kompilować statystyki. Możesz zauważyć inne zapytania "globalne tworzenie statystyk" na liście żądań SQL, które są wykonywane przed zapytaniem.
- Sprawdź, czy w tym samym punkcie końcowym jest uruchomione pewne obciążenie, gdy zapytanie zostało wykonane z dłuższym czasem trwania. Bezserwerowy punkt końcowy SQL równo przydziela zasoby do wszystkich zapytań wykonywanych równolegle, a zapytanie może być opóźnione.
Połączenia
Bezserwerowa pula SQL umożliwia nawiązywanie połączeń przy użyciu protokołu TDS i używanie języka T-SQL do wykonywania zapytań o dane. Większość narzędzi, które mogą łączyć się z programem SQL Server lub usługą Azure SQL Database, może również łączyć się z bezserwerową pulą SQL.
Pula SQL rozgrzewa się
Po dłuższym okresie braku aktywności bezserwerowa pula SQL zostanie zdezaktywowana. Aktywacja odbywa się automatycznie w pierwszym następnym działaniu, takim jak pierwsza próba połączenia. Proces aktywacji może potrwać nieco dłużej niż jeden interwał próby połączenia, więc jest wyświetlany komunikat o błędzie. Ponawianie próby nawiązania połączenia powinno wystarczyć.
Najlepszym rozwiązaniem dla klientów, którzy go obsługują, użyj słów kluczowych ConnectionRetryCount i ConnectRetryInterval parametry połączenia, aby kontrolować zachowanie ponownego nawiązywania połączenia.
Jeśli komunikat o błędzie będzie się powtarzać, utwórz bilet pomocy technicznej za pośrednictwem witryny Azure Portal.
Nie można nawiązać połączenia z programu Synapse Studio
Nie można nawiązać połączenia z pulą usługi Azure Synapse z poziomu narzędzia
Niektóre narzędzia mogą nie mieć jawnej opcji, której można użyć do nawiązania połączenia z bezserwerową pulą SQL usługi Azure Synapse. Użyj opcji, która służy do nawiązywania połączenia z programem SQL Server lub usługą SQL Database. Okno dialogowe połączenia nie musi być oznaczane jako "Synapse", ponieważ bezserwerowa pula SQL używa tego samego protokołu co program SQL Server lub sql Database.
Nawet jeśli narzędzie umożliwia wprowadzenie tylko nazwy serwera logicznego i wstępnie zdefiniowanej database.windows.net domeny, umieść nazwę obszaru roboczego usługi Azure Synapse, a następnie -ondemand sufiks i domenę database.windows.net .
Zabezpieczenia
Upewnij się, że użytkownik ma uprawnienia dostępu do baz danych, uprawnień do wykonywania poleceń i uprawnień dostępu do magazynu usługi Azure Data Lake lub Azure Cosmos DB.
Nie można uzyskać dostępu do konta usługi Azure Cosmos DB
Aby uzyskać dostęp do magazynu analitycznego, musisz użyć klucza tylko do odczytu usługi Azure Cosmos DB, aby upewnić się, że magazyn analityczny nie wygasł lub że nie został ponownie wygenerowany.
Jeśli zostanie wyświetlony błąd "Rozwiązywanie ścieżki usługi Azure Cosmos DB nie powiodło się z powodu błędu", upewnij się, że skonfigurowano zaporę.
Nie można uzyskać dostępu do bazy danych Lakehouse lub Spark
Jeśli użytkownik nie może uzyskać dostępu do bazy danych lakehouse lub Spark, może nie mieć uprawnień dostępu do bazy danych i odczytu jej. Użytkownik z uprawnieniem CONTROL SERVER powinien mieć pełny dostęp do wszystkich baz danych. Jako ograniczone uprawnienie możesz spróbować użyć OPCJI POŁĄCZ DOWOLNĄ BAZĘ DANYCH i WYBRAĆ WSZYSTKICH UŻYTKOWNIKÓW ZABEZPIECZANYCH.
Użytkownik SQL nie może uzyskać dostępu do tabel usługi Dataverse
Tabele dataverse uzyskują dostęp do magazynu przy użyciu tożsamości firmy Microsoft entra obiektu wywołującego. Użytkownik SQL z wysokimi uprawnieniami może spróbować wybrać dane z tabeli, ale tabela nie będzie mogła uzyskać dostępu do danych usługi Dataverse. Ten scenariusz nie jest obsługiwany.
Błędy logowania jednostki usługi Microsoft Entra podczas tworzenia przypisania roli przez spi
Jeśli chcesz utworzyć przypisanie roli dla identyfikatora jednostki usługi (SPI) lub aplikacji Microsoft Entra przy użyciu innej jednostki usługi lub została już utworzona i nie można się zalogować, prawdopodobnie wystąpi następujący błąd: Login error: Login failed for user '<token-identified principal>'.
W przypadku jednostek usługi należy utworzyć identyfikator logowania z identyfikatorem aplikacji jako identyfikatorem zabezpieczeń (SID), a nie identyfikatorem obiektu. Istnieje znane ograniczenie dla jednostek usługi, które uniemożliwia usłudze Azure Synapse pobranie identyfikatora aplikacji z usługi Microsoft Graph podczas tworzenia przypisania roli dla innego identyfikatora SPI lub innej aplikacji.
Rozwiązanie 1
Przejdź do witryny Azure Portal>Synapse Studio>Zarządzaj>kontrolą dostępu i ręcznie dodaj administratora usługi Synapse lub administratora usługi Synapse SQL dla żądanej jednostki usługi.
Rozwiązanie 2
Musisz ręcznie utworzyć odpowiednie dane logowania przy użyciu kodu SQL:
use master
go
CREATE LOGIN [<service_principal_name>] FROM EXTERNAL PROVIDER;
go
ALTER SERVER ROLE sysadmin ADD MEMBER [<service_principal_name>];
go
Rozwiązanie 3
Możesz również skonfigurować jednostkę usługi Azure Synapse admin przy użyciu programu PowerShell. Musisz mieć zainstalowany moduł Az.Synapse.
Rozwiązaniem jest użycie polecenia cmdlet New-AzSynapseRoleAssignment z poleceniem -ObjectId "parameter". W tym polu parametru podaj identyfikator aplikacji zamiast identyfikatora obiektu przy użyciu poświadczeń jednostki usługi platformy Azure administratora obszaru roboczego.
Skrypt programu PowerShell:
$spAppId = "<app_id_which_is_already_an_admin_on_the_workspace>"
$SPPassword = "<application_secret>"
$tenantId = "<tenant_id>"
$secpasswd = ConvertTo-SecureString -String $SPPassword -AsPlainText -Force
$cred = New-Object -TypeName System.Management.Automation.PSCredential -ArgumentList $spAppId, $secpasswd
Connect-AzAccount -ServicePrincipal -Credential $cred -Tenant $tenantId
New-AzSynapseRoleAssignment -WorkspaceName "<workspaceName>" -RoleDefinitionName "Synapse Administrator" -ObjectId "<app_id_to_add_as_admin>" [-Debug]
Uwaga
W takim przypadku interfejs użytkownika programu synapse data studio nie wyświetli przypisania roli dodanego przez powyższą metodę, dlatego zaleca się dodanie przypisania roli zarówno do identyfikatora obiektu, jak i identyfikatora aplikacji w tym samym czasie, aby można było go również wyświetlić w interfejsie użytkownika.
New-AzSynapseRoleAssignment -WorkspaceName "<workspaceName" -RoleDefinitionName> "Administrator synapse" -ObjectId "<object_id_to_add_as_admin>" [-Debug]
Weryfikacja
Połącz się z bezserwerowym punktem końcowym SQL i sprawdź, czy nazwa logowania zewnętrznego przy użyciu identyfikatora SID (app_id_to_add_as_admin w poprzednim przykładzie) została utworzona:
SELECT name, convert(uniqueidentifier, sid) AS sid, create_date
FROM sys.server_principals
WHERE type in ('E', 'X');
Możesz też spróbować zalogować się w bezserwerowym punkcie końcowym SQL przy użyciu ustawionej aplikacji administracyjnej.
Ograniczenia
Niektóre ogólne ograniczenia systemowe mogą mieć wpływ na obciążenie:
| Właściwości | Ograniczenie |
|---|---|
| Maksymalna liczba obszarów roboczych usługi Azure Synapse na subskrypcję | Zobacz limity. |
| Maksymalna liczba baz danych na pulę bezserwerową | 100 (nie obejmuje baz danych synchronizowanych z puli platformy Apache Spark). |
| Maksymalna liczba baz danych synchronizowanych z puli platformy Apache Spark | Nie ogranicza się. |
| Maksymalna liczba obiektów baz danych na bazę danych | Suma liczby wszystkich obiektów w bazie danych nie może przekroczyć 2147 483 647. Zobacz Ograniczenia aparatu bazy danych programu SQL Server. |
| Maksymalna długość identyfikatora w znakach | 128. Zobacz Ograniczenia aparatu bazy danych programu SQL Server. |
| Maksymalny czas trwania zapytania | 30 minut. |
| Maksymalny rozmiar zestawu wyników | Do 400 GB współdzielone między zapytaniami współbieżnymi. |
| Maksymalna współbieżność | Nie ogranicza się i zależy od złożoności zapytania i ilości skanowanych danych. Jedna bezserwerowa pula SQL może jednocześnie obsługiwać 1000 aktywnych sesji, które wykonują zapytania o małej objętości. Liczby spadną, jeśli zapytania są bardziej złożone lub skanują większą ilość danych, dlatego w takim przypadku rozważ zmniejszenie współbieżności i wykonywanie zapytań w dłuższym okresie, jeśli jest to możliwe. |
| Maksymalny rozmiar nazwy tabeli zewnętrznej | 100 znaków. |
Nie można utworzyć bazy danych w bezserwerowej puli SQL
Bezserwerowe pule SQL mają ograniczenia i nie można utworzyć więcej niż 100 baz danych na obszar roboczy. Jeśli musisz oddzielić obiekty i odizolować je, użyj schematów.
Jeśli wystąpi błąd CREATE DATABASE failed. User database limit has been already reached , który został utworzony, maksymalna liczba baz danych obsługiwanych w jednym obszarze roboczym.
Nie musisz używać oddzielnych baz danych do izolowania danych dla różnych dzierżaw. Wszystkie dane są przechowywane zewnętrznie w usłudze Data Lake i Azure Cosmos DB. Metadane, takie jak tabela, widoki i definicje funkcji, można pomyślnie odizolować przy użyciu schematów. Izolacja oparta na schemacie jest również używana na platformie Spark, gdzie bazy danych i schematy są tymi samymi pojęciami.