Tworzenie i używanie widoków przy użyciu bezserwerowej puli SQL w usłudze Azure Synapse Analytics
W tej sekcji dowiesz się, jak tworzyć widoki i używać ich do opakowania bezserwerowych zapytań puli SQL. Widoki umożliwiają ponowne użycie tych zapytań. Widoki są również potrzebne, jeśli chcesz używać narzędzi, takich jak usługa Power BI, w połączeniu z bezserwerową pulą SQL.
Wymagania wstępne
Pierwszym krokiem jest utworzenie bazy danych, w której widok zostanie utworzony i zainicjowanie obiektów wymaganych do uwierzytelniania w usłudze Azure Storage przez wykonanie skryptu instalacji w tej bazie danych. Wszystkie zapytania w tym artykule zostaną wykonane w przykładowej bazie danych.
Widoki danych zewnętrznych
Widoki można tworzyć w taki sam sposób, jak w przypadku tworzenia zwykłych widoków programu SQL Server. Poniższe zapytanie tworzy widok odczytujący population.csv pliku.
Uwaga
Zmień pierwszy wiersz w zapytaniu, tj. [mydbname], więc używasz utworzonej bazy danych.
USE [mydbname];
GO
DROP VIEW IF EXISTS populationView;
GO
CREATE VIEW populationView AS
SELECT *
FROM OPENROWSET(
BULK 'csv/population/population.csv',
DATA_SOURCE = 'SqlOnDemandDemo',
FORMAT = 'CSV',
FIELDTERMINATOR =',',
ROWTERMINATOR = '\n'
)
WITH (
[country_code] VARCHAR (5) COLLATE Latin1_General_BIN2,
[country_name] VARCHAR (100) COLLATE Latin1_General_BIN2,
[year] smallint,
[population] bigint
) AS [r];
Widok używa elementu EXTERNAL DATA SOURCE z głównym adresem URL magazynu jako elementu DATA_SOURCE i dodaje względną ścieżkę pliku do plików.
Widoki usługi Delta Lake
Jeśli tworzysz widoki w folderze usługi Delta Lake, musisz określić lokalizację folderu głównego po BULK opcji zamiast określać ścieżkę pliku.
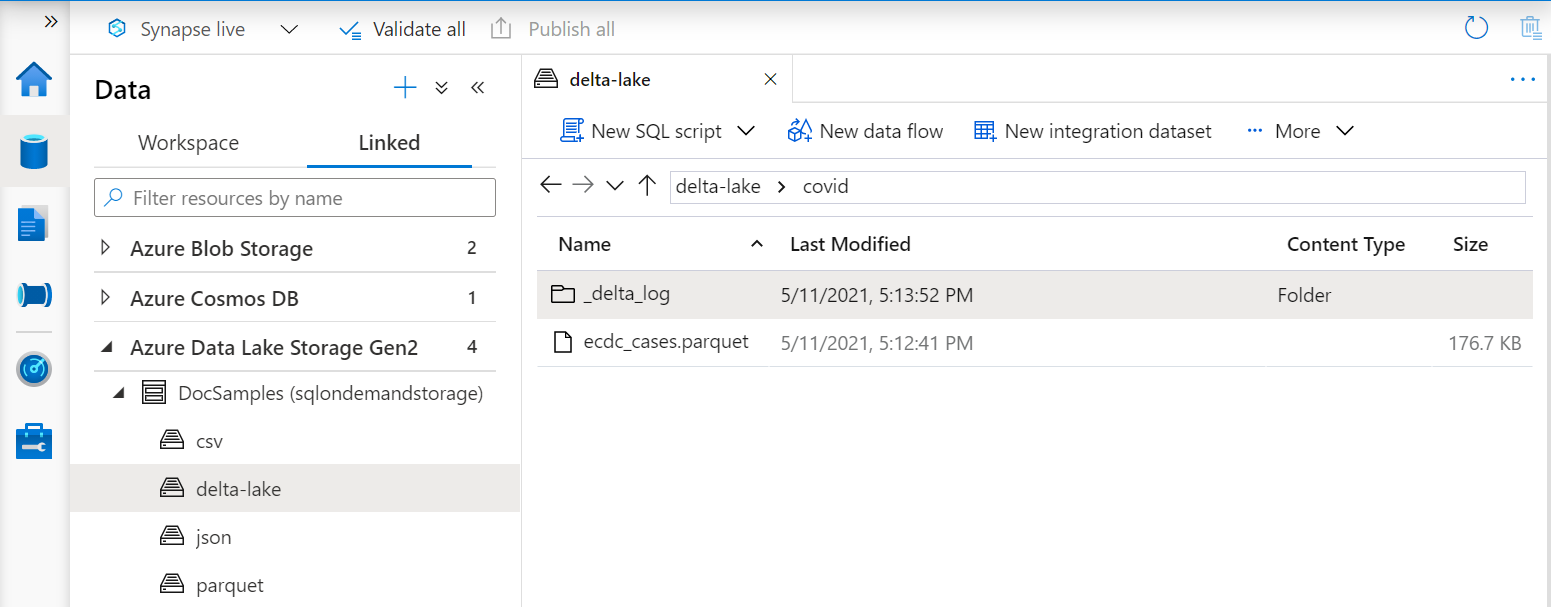
Funkcja OPENROWSET , która odczytuje dane z folderu usługi Delta Lake, zbada strukturę folderów i automatycznie zidentyfikuje lokalizacje plików.
create or alter view CovidDeltaLake
as
select *
from openrowset(
bulk 'covid',
data_source = 'DeltaLakeStorage',
format = 'delta'
) with (
date_rep date,
cases int,
geo_id varchar(6)
) as rows
Aby uzyskać więcej informacji, zapoznaj się ze stroną samodzielnej pomocy dla bezserwerowej puli SQL usługi Synapse i znanymi problemami w usłudze Azure Synapse Analytics.
Widoki podzielone na partycje
Jeśli masz zestaw plików podzielonych na partycje w strukturze folderów hierarchicznych, możesz opisać wzorzec partycji przy użyciu symboli wieloznacznych w ścieżce pliku.
FILEPATH Użyj funkcji , aby uwidocznić części ścieżki folderu jako kolumny partycjonowania.
CREATE VIEW TaxiView
AS SELECT *, nyc.filepath(1) AS [year], nyc.filepath(2) AS [month]
FROM
OPENROWSET(
BULK 'parquet/taxi/year=*/month=*/*.parquet',
DATA_SOURCE = 'sqlondemanddemo',
FORMAT='PARQUET'
) AS nyc
Widoki partycjonowane mogą zwiększyć wydajność zapytań, eliminując partycje podczas wykonywania zapytań dotyczących filtrów w kolumnach partycjonowania. Jednak nie wszystkie zapytania obsługują eliminację partycji, dlatego ważne jest, aby postępować zgodnie z najlepszymi rozwiązaniami.
Aby zapewnić eliminację partycji, należy unikać używania podzapytania w filtrach, ponieważ mogą zakłócać możliwość eliminowania partycji. Zamiast tego przekaż wynik podzapytania jako zmienną do filtru.
W przypadku korzystania z numerów JOIN w zapytaniach SQL zadeklaruj predykat filtru jako NVARCHAR, aby zmniejszyć złożoność planu zapytania i zwiększyć prawdopodobieństwo prawidłowej eliminacji partycji. Kolumny partycji są zwykle wnioskowane jako NVARCHAR(1024), dlatego użycie tego samego typu predykatu pozwala uniknąć konieczności niejawnego rzutowania, co może zwiększyć złożoność planu zapytania.
Widoki partycjonowane w usłudze Delta Lake
Jeśli tworzysz widoki partycjonowane na podstawie magazynu usługi Delta Lake, możesz określić tylko główny folder usługi Delta Lake i nie trzeba jawnie uwidaczniać kolumn partycjonowania przy użyciu FILEPATH funkcji :
CREATE OR ALTER VIEW YellowTaxiView
AS SELECT *
FROM
OPENROWSET(
BULK 'yellow',
DATA_SOURCE = 'DeltaLakeStorage',
FORMAT='DELTA'
) nyc
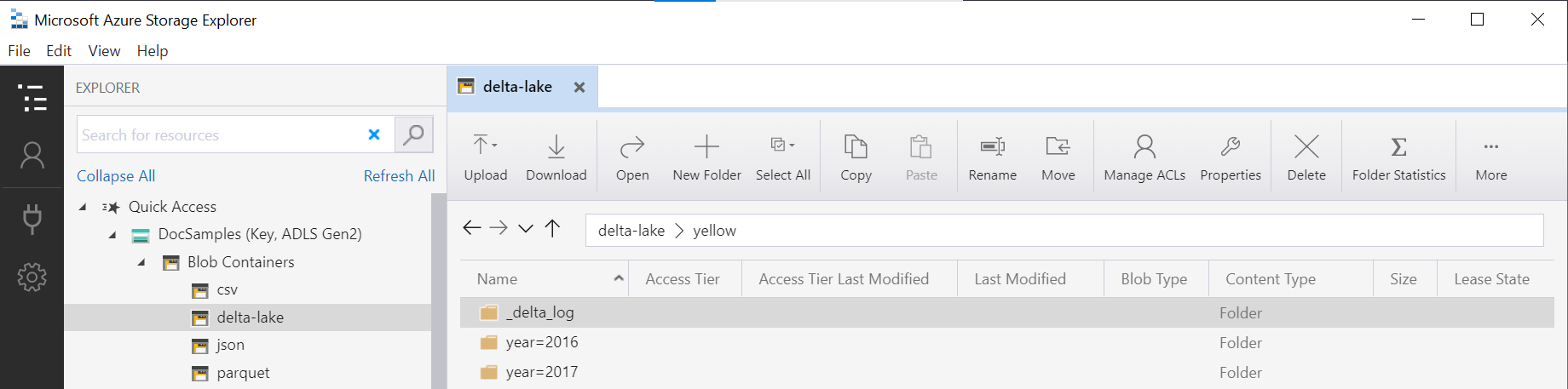
Funkcja OPENROWSET zbada strukturę bazowego folderu usługi Delta Lake i automatycznie zidentyfikuje i uwidoczni kolumny partycjonowania. Eliminacja partycji zostanie wykonana automatycznie, jeśli umieścisz kolumnę partycjonowania w WHERE klauzuli zapytania.
Nazwa folderu w OPENROWSET funkcji (yellow w tym przykładzie) połączona z identyfikatorem LOCATION URI zdefiniowanym w DeltaLakeStorage źródle danych musi odwoływać się do głównego folderu usługi Delta Lake zawierającego podfolder o nazwie _delta_log.
Aby uzyskać więcej informacji, zapoznaj się ze stroną samodzielnej pomocy dla bezserwerowej puli SQL usługi Synapse i znanymi problemami w usłudze Azure Synapse Analytics.
Widoki JSON
Widoki są dobrym wyborem, jeśli musisz wykonać dodatkowe przetwarzanie na podstawie zestawu wyników pobieranego z plików. Przykładem może być analizowanie plików JSON, w których musimy zastosować funkcje JSON w celu wyodrębnienia wartości z dokumentów JSON:
CREATE OR ALTER VIEW CovidCases
AS
select
*
from openrowset(
bulk 'latest/ecdc_cases.jsonl',
data_source = 'covid',
format = 'csv',
fieldterminator ='0x0b',
fieldquote = '0x0b'
) with (doc nvarchar(max)) as rows
cross apply openjson (doc)
with ( date_rep datetime2,
cases int,
fatal int '$.deaths',
country varchar(100) '$.countries_and_territories')
Funkcja OPENJSON analizuje każdy wiersz z pliku JSONL zawierającego jeden dokument JSON na wiersz w formacie tekstowym.
Widoki usługi Azure Cosmos DB dla kontenerów
Widoki można tworzyć na podstawie kontenerów usługi Azure Cosmos DB, jeśli magazyn analityczny usługi Azure Cosmos DB jest włączony w kontenerze. W widoku należy dodać nazwę konta usługi Azure Cosmos DB, nazwę bazy danych i nazwę kontenera, a klucz dostępu tylko do odczytu powinien zostać umieszczony w poświadczeniu w zakresie bazy danych, do którego odwołuje się widok.
Ten przykładowy skrypt używa bazy danych i kontenera, które można skonfigurować, postępując zgodnie z tymi instrukcjami.
Ważne
W skrypcie zastąp te wartości własnymi wartościami:
- your-cosmosdb — nazwa konta usługi Cosmos DB
- access-key — klucz konta usługi Cosmos DB
CREATE DATABASE SCOPED CREDENTIAL MyCosmosDbAccountCredential
WITH IDENTITY = 'SHARED ACCESS SIGNATURE', SECRET = 'access-key';
GO
CREATE OR ALTER VIEW Ecdc
AS SELECT *
FROM OPENROWSET(
PROVIDER = 'CosmosDB',
CONNECTION = 'Account=your-cosmosdb;Database=covid',
OBJECT = 'Ecdc',
CREDENTIAL = 'MyCosmosDbAccountCredential'
) with ( date_rep varchar(20), cases bigint, geo_id varchar(6) ) as rows
Aby uzyskać więcej informacji, zobacz Query Azure Cosmos DB data with a serverless SQL pool in Azure Synapse Link (Wykonywanie zapytań o dane usługi Azure Cosmos DB przy użyciu bezserwerowej puli SQL w usłudze Azure Synapse Link).
Korzystanie z widoku
Podczas kwerend można używać widoków w taki sam sposób jak w przypadku widoków w kwerendach programu SQL Server.
Poniższe zapytanie demonstruje użycie widoku population_csv utworzonego w obszarze Tworzenie widoku. Zwraca nazwy krajów/regionów z ich populacją w 2019 r. w kolejności malejącej.
Uwaga
Zmień pierwszy wiersz w zapytaniu, tj. [mydbname], więc używasz utworzonej bazy danych.
USE [mydbname];
GO
SELECT
country_name, population
FROM populationView
WHERE
[year] = 2019
ORDER BY
[population] DESC;
Podczas wykonywania zapytań dotyczących widoku mogą wystąpić błędy lub nieoczekiwane wyniki. Prawdopodobnie oznacza to, że widok odwołuje się do kolumn lub obiektów, które zostały zmodyfikowane lub już nie istnieją. Musisz ręcznie dostosować definicję widoku, aby dopasować je do podstawowych zmian schematu.
Powiązana zawartość
Aby uzyskać informacje na temat wykonywania zapytań dotyczących różnych typów plików, zapoznaj się z artykułami Query single CSV file , Query Parquet files (Zapytania dotyczące plików Parquet) i Query JSON files (Zapytania dotyczące plików JSON).