Verrijking van ongestructureerde klinische notities (preview) gebruiken in oplossingen voor gezondheidszorggegevens
[Dit artikel maakt deel uit van de voorlopige documentatie en kan nog veranderen.]
Notitie
Deze inhoud wordt momenteel bijgewerkt.
Verrijking van ongestructureerde klinische notities (preview) maakt gebruik van de service Text Analytics for Health van Azure AI Taal om belangrijke FHIR-entiteiten (Fast Healthcare Interoperability Resources) uit ongestructureerde klinische notities te extraheren. Het geeft structuur aan deze klinische notities. Vervolgens kunt u deze gestructureerde gegevens analyseren om inzichten, voorspellingen en kwaliteitsmaatregelen af te leiden waarmee u de gezondheidsresultaten van patiënten kunt verbeteren.
Voor meer informatie over de mogelijkheid en hoe u deze kunt implementeren en configureren, zie:
- Overzicht van verrijking van ongestructureerde klinische notities (preview)
- Verrijking van ongestructureerde klinische notities (preview) implementeren en configureren
De verrijking van ongestructureerde klinische notities (preview) is rechtstreeks afhankelijk van de mogelijkheden van de fundamenten voor gezondheidszorggegevens. Zorg er eerst voor dat u de pipelines van de fundamenten voor gezondheidszorggegevens instelt en uitvoert.
Vereisten
- Oplossingen voor gezondheidszorggegevens in Microsoft Fabric implementeren
- Installeer de fundamentele notitieblokken en pijplijnen in Fundamenten voor gezondheidszorggegevens implementeren.
- Stel de Azure-taalservice in zoals wordt uitgelegd in Azure Taal-service instellen.
- Verrijking van ongestructureerde klinische notities (preview) implementeren en configureren
- OMOP-transformaties implementeren en configureren. Deze stap is optioneel.
NLP-opnameservice
Het healthcare#_msft_ta4h_silver_ingestion-notitieblok voert de NLPIngestionService-module uit in de oplossingenbibliotheek voor gezondheidszorggegevens om de Text Analytics for Health-service aan te roepen. Met deze service worden ongestructureerde klinische notities uit de FHIR-resource DocumentReference.Content gehaald om uitvoer zonder opmaak te maken. Zie De configuratie van het notitieblok controleren voor meer informatie.
Gegevensopslag in zilveren laag
Na de analyse van de API voor natuurlijke taalverwerking (NLP) wordt de gestructureerde en onbewerkte uitvoer opgeslagen in de volgende native tabellen in het healthcare#_msft_silver-lakehouse:
- nlpentity: bevat de entiteiten zonder opmaak die zijn geëxtraheerd uit de ongestructureerde klinische notities. Elke rij is een enkele term die uit de ongestructureerde tekst is geëxtraheerd na het uitvoeren van de tekstuele analyse.
- nlprelationship: geeft de relatie tussen de geëxtraheerde entiteiten weer.
- nlpfhir: bevat de FHIR-uitvoerbundel als een JSON-tekenreeks.
Om het laatst bijgewerkte tijdstempel bij te houden, gebruikt de NLPIngestionService het veld parent_meta_lastUpdated in alle drie zilveren lakehouse-tabellen. Deze tracering zorgt ervoor dat het brondocument DocumentReference, de bovenliggende resource, eerst wordt opgeslagen om de referentiële integriteit te behouden. Dit proces helpt inconsistenties in de gegevens en verweesde resources te voorkomen.
Belangrijk
Momenteel retourneert Text Analytics for Health vocabulaires die vermeld staan in de UMLS Metathesaurus Vocabulary-documentatie. Zie Gegevens importeren uit UMLS voor meer informatie over deze vocabulaires.
Voor de previewversie gebruiken we de terminologieën SNOMED-CT (Systematized Nomenclature of Medicine - Clinical Terms), LOINC (Logical Observation Identifiers, Names, and Codes) en RxNorm die zijn opgenomen in de OMOP- voorbeeldgegevensset op basis van richtlijnen van Observational Health Data Sciences and Informatics (OHDSI).
OMOP-transformatie
Oplossingen voor gezondheidszorggegevens in Microsoft Fabric bieden ook een andere mogelijkheid voor transformaties van Observational Medical Outcomes Partnership (OMOP). Wanneer u deze mogelijkheid uitvoert, transformeert de onderliggende transformatie van het zilveren lakehouse naar het OMOP gouden lakehouse ook de gestructureerde en onbewerkte uitvoer van de ongestructureerde analyse van klinische notities. De transformatie leest uit de nlpentity-tabel in het zilveren lakehouse en koppelt de uitvoer aan de NOTE_NLP-tabel in het OMOP gouden lakehouse.
Zie voor meer informatie: Overzicht van OMOP-transformaties.
Hier is het schema voor de gestructureerde NLP-uitvoer, met de bijbehorende NOTE_NLP-kolomtoewijzing naar het OMOP Common Data Model:
| Referentie document zonder opmaak | Omschrijving | Note_NLP-toewijzing | Voorbeeldgegevens |
|---|---|---|---|
| id | Unieke id voor de entiteit. Samengestelde sleutel van parent_id, offset en length. |
note_nlp_id |
1380 |
| parent_id | Een externe sleutel voor de documentreferencecontent-tekst zonder opmaak waaruit de term is geëxtraheerd. | note_id |
625 |
| sms verzenden | Entiteitstekst zoals wordt weergegeven in het document. | lexical_variant |
Geen bekende allergieën |
| Verschuiving | Tekenverschuiving van de geëxtraheerde term in de invoertekst documentreferencecontent. | offset |
294 |
| data_source_entity_id | Id van de entiteit in de opgegeven broncatalogus. | note_nlp_concept_id en note_nlp_source_concept_id |
37396387 |
| nlp_last_executed | De datum van de tekstanalyseverwerking van documentreferencecontent. | nlp_date_time en nlp_date |
2023-05-17T00:00:00.0000000 |
| model | Naam en versie van het NLP-systeem (naam van het Text Analytics for Health NLP-systeem en de versie). | nlp_system |
MSFT TA4H |

Servicelimieten voor Text Analytics for Health
- Het maximale aantal tekens per document is 125.000.
- De maximale grootte van de documenten in de volledige aanvraag is 1 MB.
- Het maximale aantal documenten per aanvraag is:
- 25 voor de webgebaseerde API.
- 1000 voor de container.
Logboeken inschakelen
Volg deze stappen om aanvraag- en responsregistratie in te schakelen voor de Text Analytics for Health-API:
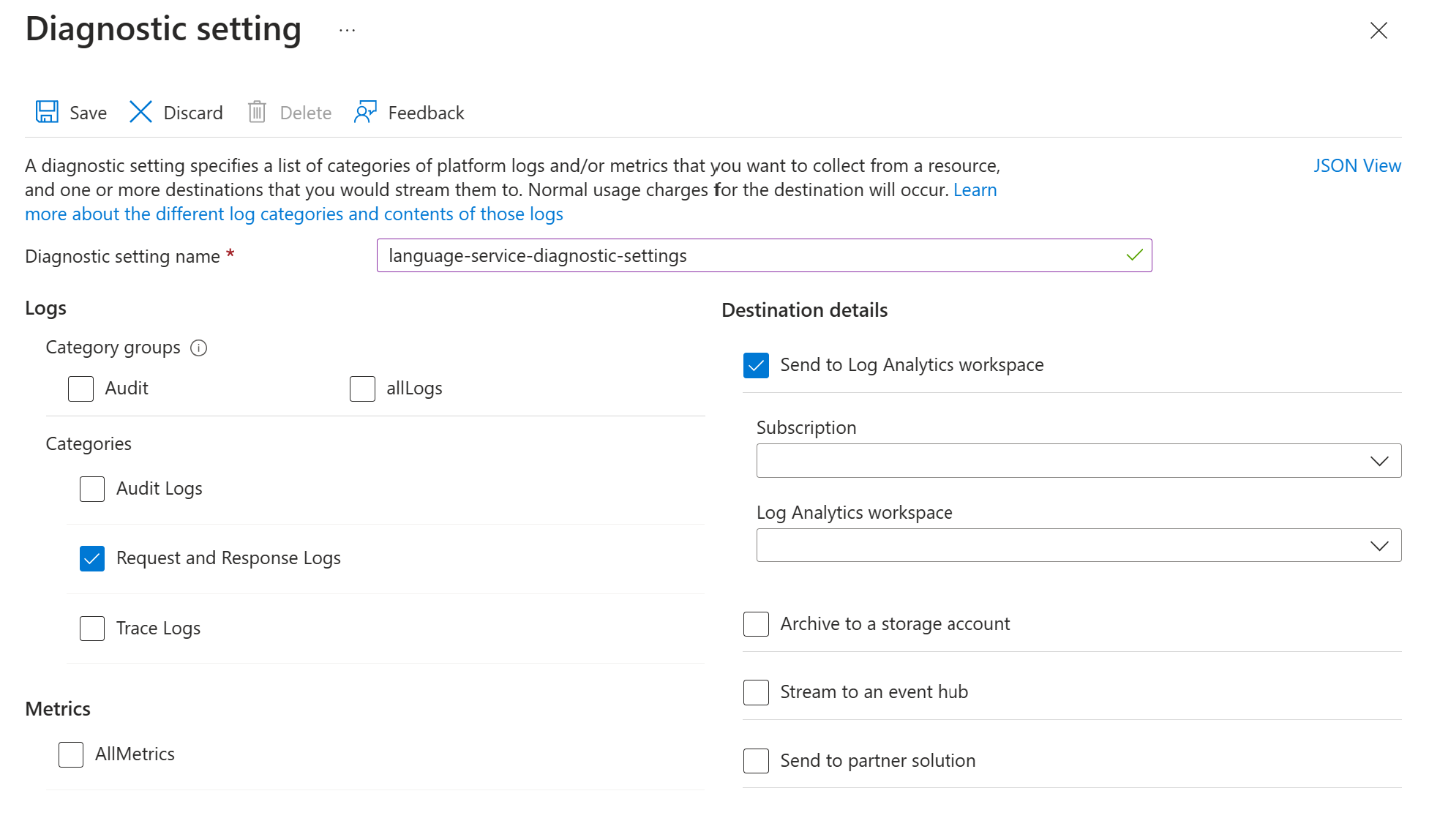
Schakel de diagnostische instellingen voor uw Azure Taal-servicebron in volgens de instructies in Diagnostische logboekregistratie inschakelen voor Azure AI-services. Deze bron is dezelfde taalservice die u tijdens de implementatiestap Azure Taal-service instellen hebt gemaakt.
- Voer een naam in voor de diagnostische instelling.
- Stel de categorie in op Aanvraag- en responslogboeken.
- Selecteer Verzenden naar Log Analytics-werkruimte voor bestemmingsdetails en selecteer de vereiste Log Analytics-werkruimte. Als u nog geen werkruimte hebt, maakt u er een volgens de aanwijzingen.
- Sla de instellingen op.
Ga naar de sectie NLP-configuratie in het NLP-opnameservicenotitieblok. Werk de waarde van de configuratieparameter
enable_text_analytics_logsbij naarTrue. Voor meer informatie over dit notitieblok raadpleegt u De configuratie van het notitieblok controleren.

Logboeken weergeven in Azure Log Analytics
De logboekanalysegegevens verkennen:
- Navigeer naar de Log Analytics-werkruimte.
- Zoek en selecteer Logboeken. Vanaf deze pagina kunt u query's uitvoeren op uw logboeken.
Voorbeeldquery
Hieronder vindt u een eenvoudige Kusto-query waarmee u uw logboekgegevens kunt onderzoeken. Met deze voorbeeldquery worden alle mislukte verzoeken van de resourceprovider Azure Cognitive Services van de afgelopen dag opgehaald, gegroepeerd op fouttype:
AzureDiagnostics
| where TimeGenerated > ago(1d)
| where Category == "RequestResponse"
| where ResourceProvider == "MICROSOFT.COGNITIVESERVICES"
| where tostring(ResultSignature) startswith "4" or tostring(ResultSignature) startswith "5"
| summarize NumberOfFailedRequests = count() by ResultSignature