Gegevensarchitectuur en -beheer in oplossingen voor gezondheidszorggegevens in Microsoft Fabric
Het framework voor oplossingen voor gezondheidszorggegevens maakt gebruik van een gespecialiseerde medaillonarchitectuur om de organisatie en verwerking van gegevens te stroomlijnen. Dit ontwerp zorgt voor een voortdurende verbetering van de kwaliteit en structuur van de gegevens, zodat u uw zorggegevens effectiever kunt beheren. In dit artikel worden de belangrijkste kenmerken en voordelen van deze architectuur besproken en wordt een uitgebreid overzicht gegeven van hoe gegevens binnen dit framework worden beheerd.
Medaillon lakehouse-ontwerp
Zoals wordt uitgelegd in de oplossingsarchitectuur, maken oplossingen voor gezondheidszorggegevens gebruik van de medaillon lakehouse-architectuur om gegevens in meerdere lagen te organiseren en te verwerken. Terwijl de gegevens door elke laag heen bewegen, worden de structuur en kwaliteit ervan voortdurend verbeterd. In de kern bestaat het medaillon lakehouse-ontwerp in oplossingen voor gezondheidszorggegevens uit de volgende belangrijke lakehouses:
Bronzen lakehouse: ook wel bekend als de onbewerkte zone - het bronzen lakehouse is de eerste laag die brongegevens in de oorspronkelijke bestandsindeling organiseert. Het verwerkt bronbestanden in OneLake en/of maakt snelkoppelingen van native opslagbronnen. Het slaat ook gestructureerde en semi-gestructureerde gegevens uit de bron op in deltatabellen, ook wel aangeduid als faseringstabellen. Deze tabellen zijn gecomprimeerd en kolomgeïndexeerd ter ondersteuning van efficiënte transformaties en gegevensverwerking. De gegevens in deze laag kunnen doorgaans alleen worden toegevoegd en zijn onveranderlijk.
Bestanden in het bronzen lakehouse (hetzij bewaard of snelkoppelingen) dienen als bron van waarheid. Ze leggen de basis voor gegevensherkomst over het gehele gegevenspark in oplossingen voor gezondheidszorggegevens. Faseringstabellen in de bronzen laag bestaan doorgaans uit een paar kolommen en zijn ontworpen om elke gegevensmodaliteit en -indeling in één tabel te bewaren (bijvoorbeeld ClinicalFhir- en ImagingDicom-tabellen). U mag deze faseringstabellen in de bronze lakehouse niet uitbreiden, aanpassen of er afhankelijkheden op bouwen om de volgende redenen:
- Interne implementatie: de faseringstabellen worden intern specifiek geïmplementeerd voor oplossingen voor gezondheidszorggegevens in Microsoft Fabric. Hun schema is speciaal ontwikkeld voor oplossingen voor gezondheidszorggegevens en volgt geen branche- of community-gegevensstandaard.
- Tijdelijke opslag: nadat de gegevens zijn verwerkt en getransformeerd van de bronzen lakehouse-faseringstabellen naar de afgeplatte en genormaliseerde deltatabellen in het zilveren lakehouse, worden de gegevens uit de bronzen faseringstabel als gereed beschouwd om te worden verwijderd. Dit model zorgt voor kostenefficiëntie en opslagefficiëntie en vermindert de gegevensredundantie tussen bronbestanden en faseringstabellen in het bronzen lakehouse.
Zilveren lakehouse: ook wel de verrijkte zone genoemd. Het zilveren lakehouse verfijnt gegevens van het bronzen lakehouse. Het omvat validatiecontroles en verrijkingstechnieken om de nauwkeurigheid van gegevens voor downstream-analyses te verbeteren. In tegenstelling tot de bronzen laag worden bij de zilveren lakehouse-gegevens regels gebruikt die zijn gebaseerd op deterministische ID's en wijzigingstijdstempels om invoegingen en updates in records te beheren.
Gouden lakehouse: ook wel de speciaal samengestelde zone genoemd. Het gouden lakehouse verfijnt gegevens van het zilveren lakehouse verder om te voldoen aan specifieke zakelijke en analytische vereisten. Deze laag fungeert als primaire bron voor hoogwaardige, geaggregeerde gegevenssets die klaar zijn voor uitgebreide analyses en het verkrijgen van inzichten. Hoewel oplossingen voor gezondheidszorggegevens per implementatie één bronzen en één zilveren lakehouse implementeren, kunt u meerdere gouden lakehouses hebben om verschillende business units en persona's te bedienen.
Beheer-lakehouse: het beheer-lakehouse bevat bestanden voor gegevens-governance en traceerbaarheid over de lakehouse-lagen heen, inclusief globale configuratie- en validatiefouten die zijn opgeslagen in de BusinessEvent-tabel. Zie voor meer informatie Beheer-lakehouse.
Uniforme mapstructuur
Klanten in de gezondheidszorg en de biowetenschappen hebben te maken met enorme hoeveelheden gegevens uit verschillende bronsystemen, via meerdere gegevensmodaliteiten en bestandsindelingen, waaronder:
- Klinische modaliteit: FHIR NDJSON-bestanden, FHIR-bundels en HL7.
- Beeldvormende modaliteit: DICOM, NIFTI en NDPI.
- Genomica-modaliteit: BAM, BCL, FASTQ en VCF.
- Claims: CCLF en CSV.
Waarbij geldt:
- FHIR: Fast Healthcare Interoperability Resources
- HL7: Health Level Seven International
- DICOM: Digital Imaging and Communications in Medicine
- NIFTI: Neuroimaging Informatics Technology Initiative
- NDPI: Nano-dimensional Pathology Imaging
- BAM: Binary Alignment Map
- BCL: Base Call
- FASTQ: een op tekst gebaseerde indeling voor het opslaan van een biologische sequentie en de bijbehorende kwaliteitsscores
- VCF: Variant Call Format
- CCLF: Claim and Claim Line Feed
- CSV: Comma-separated values (door komma's gescheiden waarden)
OneLake in Microsoft Fabric biedt een logisch datalake voor uw organisatie. Oplossingen voor gezondheidszorggegevens in Microsoft Fabric bieden een uniforme mapstructuur waarmee u gegevens over verschillende modaliteiten en formaten kunt ordenen. Deze structuur stroomlijnt de gegevensopname en -verwerking, terwijl de gegevensherkomst op het niveau van het bronbestand en het bronsysteem in het bronzen lakehouse behouden blijft.
De zes hoofdmappen zijn:
- Extern
- Mislukt
- Opnemen
- Verwerken
- ReferenceData
- SampleData
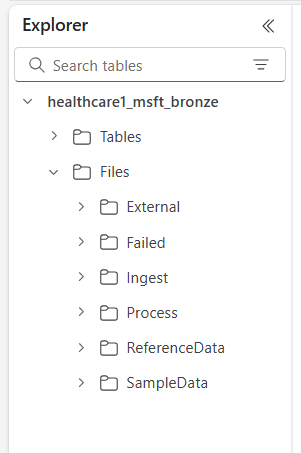
De submappen zijn als volgt georganiseerd:
Files\Ingest\[DataModality]\[DataFormat]\[Namespace]Files\External\[DataModality]\[DataFormat]\[Namespace]\[BYOSShortcutname]\Files\SampleData\[DataModality]\[DataFormat]\[Namespace]\Files\ReferenceData\[DataModality]\[DataFormat]\[Namespace]\Files\Failed\[DataModality]\[DataFormat]\[Namespace]\YYYY\MM\DDFiles\Process\[DataModality]\[DataFormat]\[Namespace]\YYYY\MM\DD
Mapbeschrijvingen
Naamruimte (verplicht): identificeert het bronsysteem voor ontvangen bestanden, cruciaal om de uniciteit van de ID per bronsysteem te waarborgen.
Opnamemap: werkt als een neerzet- of wachtrijmap. In deze map kunt u de bestanden die u wilt opnemen, in de juiste modaliteit- en indelingssubmappen neerzetten. Nadat de opname is gestart, worden de bestanden overgebracht naar de desbetreffende map Verwerken of de map Mislukt bij fouten.
Map Verwerken: de uiteindelijke bestemming voor alle succesvol verwerkte bestanden binnen elke combinatie van modaliteit en indeling. Deze map volgt het patroon
YYYY/MM/DDop basis van de verwerkingsdatum. De mappartitionering is in overeenstemming met de Best practices voor gebruik van Azure Data Lake Storage voor een betere organisatie, gefilterde zoekopdrachten, automatisering en mogelijke parallelle verwerking.Externe map: dient als de bovenliggende map voor de BYOS-snelkoppelingsmappen (Bring Your Own Storage). De standaardimplementatie biedt een suggestieve mapstructuur voor claims, klinische, genomische en beeldvormende modaliteiten. De beeldvormings- en klinische modaliteiten hebben standaardindelingen en -naamruimten die zijn geconfigureerd ter ondersteuning van DICOM- en FHIR-services in Azure Health Data Services. Deze indeling is alleen van toepassing als u snel gegevens snel naar OneLake wilt kopiëren. Oplossingen voor gezondheidszorggegevens in Microsoft Fabric hebben alleen-lezentoegang tot bestanden in deze snelkoppelingsmappen.
Map Mislukt: als er een fout optreedt tijdens het verplaatsen of verwerken van bestanden in de mappen Opnemen of Verwerken, worden de desbetreffende bestanden verplaatst naar de map Mislukt, overeenstemmend met hun combinatie van modaliteit en indeling. Er is een fout vastgelegd in de tabel BusinessEvent in het beheer-lakehouse. Deze map gebruikt het patroon
YYYY/MM/DDop basis van de datum van verwerking/storing. Bestanden in deze map worden niet verwijderd en blijven hier staan totdat u ze herstelt en opnieuw opneemt volgens hetzelfde oorspronkelijke opnamepatroon.Map met voorbeeldgegevens: bevat synthetische, referentiële en/of openbare gegevenssets. De standaardimplementatie biedt voorbeeldgegevens voor verschillende combinaties van modaliteit en indeling, zodat notitieblokken en pipelines na implementatie direct kunnen worden uitgevoerd. Deze map maakt geen
YYYY/MM/DD-submappen.Map met verwijzingsgegevens: bevat referentiële en bovenliggende gegevenssets uit openbare of gebruikerspecifieke bronnen. Deze map maakt geen
YYYY/MM/DD-submappen. De standaardimplementatie biedt een voorgestelde mapstructuur voor OMOP-vocabulaires (Observational Medical Outcomes Partnership).
Gegevensopnamepatronen
Op basis van de eerder geschetste uniforme mapstructuur ondersteunen oplossingen voor gezondheidszorggegevens in Microsoft Fabric twee verschillende opnamepatronen. In beide gevallen maken de oplossingen gebruik van gestructureerde streaming in Spark om binnenkomende bestanden in de desbetreffende mappen te verwerken.
Opnamepatroon
Bij dit patroon worden bestanden die moeten worden opgenomen, in de map Opnemen onder de juiste modaliteit, indeling en naamruimte geplaatst. De opname-pipelines controleren deze map op net geplaatste bestanden en verplaatsen deze naar de overeenkomstige map Verwerken. Als de opname van bestandsgegevens in de bronzen lakehouse-faseringstabel is gelukt, wordt het bestand gecomprimeerd en opgeslagen met een tijdstempelvoorvoegsel in de map Verwerken, volgens het patroon YYYY/MM/DD, op basis van het moment van verwerking. Dit voorvoegsel zorgt voor unieke bestandsnamen. U kunt de compressie naar wens configureren of uitschakelen.
Als de bestandsverwerking mislukt, worden de mislukte bestanden verplaatst van de map Opnemen naar de map Mislukt voor elke combinatie van modaliteit en indeling, en wordt een fout vastgelegd in de tabel BusinessEvent in het beheer-lakehouse.
Dit opnamepatroon is ideaal voor dagelijkse incrementele opnames of wanneer u gegevens fysiek naar Azure Data Lake Storage of OneLake verplaatst.
BYOS-patroon (Bring Your Own Storage)
Soms zijn er al gegevens en bestanden aanwezig in Azure of andere cloudopslagservices, met bestaande downstream-implementaties en afhankelijkheden van die bestanden. In de gezondheidszorg en de biowetenschappen kunnen de datavolumes oplopen tot meerdere terabytes of zelfs petabytes, vooral voor medische beeldvorming en genomica. Om deze redenen is het directe opnamepatroon mogelijk niet haalbaar.
Wij raden aan het BYOS-patroon te gebruiken voor het opnemen van historische gegevens wanneer u al aanzienlijke hoeveelheden gegevens beschikbaar hebt in Azure of andere cloud- en on-premises opslag die het S3-protocol ondersteunt. Dit patroon gebruikt OneLake-snelkoppelingen in Fabric en de map Extern in het bronzen lakehouse om verwerking ter plaatse van bronbestanden mogelijk te maken. Het is niet meer nodig bestanden te verplaatsen of te kopiëren en er worden geen uitvoerkosten en duplicatie van gegevens in rekening gebracht.
Ondanks de efficiëntie die het BYOS-opnamepatroon biedt, moet u rekening houden met de volgende aandachtspunten:
- Bestandsupdates ter plaatse (inhoudelijke updates binnen het bestand) worden niet gecontroleerd. Er wordt van u verwacht dat u voor alle updates een nieuw bestand (met een andere naam) maakt, omdat de opname-pipeline alleen nieuwe bestanden controleert. Deze beperking heeft te maken met gestructureerde streaming in Spark.
- Gegevens worden niet gecomprimeerd.
- Het BYOS-patroon maakt geen geoptimaliseerde mapstructuur volgens het patroon
YYYY/MM/DD. - Als de bestandsverwerking mislukt, worden de mislukte bestanden niet naar de map Mislukt verplaatst. Er wordt echter een fout vastgelegd in de tabel BusinessEvent in het beheer-lakehouse.
- Er wordt van uitgegaan dat de brongegevens alleen-lezen zijn.
- Er is geen controle over de herkomst of beschikbaarheid van de brongegevens na opname.
Gegevenscompressie
Oplossingen voor gezondheidszorggegevens in Microsoft Fabric ondersteunen compressie-by-design in het medaillon lakehouse-ontwerp. Gegevens die in de deltatabellen van het medaillon lakehouse worden ingevoerd, worden opgeslagen in een gecomprimeerde kolomindeling met behulp van Parquet-bestanden. In het opnamepatroon worden de bestanden na de verwerking standaard gecomprimeerd wanneer ze van de map Opnemen naar de map Verwerken worden verplaatst. U kunt de compressie naar wens configureren of uitschakelen. Voor de beeldvormings- en claimmogelijkheden kunnen de opname-pipelines ook onbewerkte bestanden verwerken in een gecomprimeerde ZIP-indeling.
Model voor gezondheidszorggegevens
Zoals beschreven in het medaillon lakehouse-ontwerp implementeren de bronzen lakehouse-faseringstabellen intern speciaal gebouwde tabellen voor oplossingen voor gezondheidszorggegevens en volgen ze geen branche- of community-gegevensstandaard.
Het model voor gezondheidszorggegevens in het zilveren lakehouse is gebaseerd op de FHIR R4-standaard. Het biedt een gemeenschappelijke gegevenstaal waarmee gegevensanalisten, datawetenschappers en ontwikkelaars kunnen samenwerken en gegevensgestuurde oplossingen kunnen bouwen die de patiëntresultaten en bedrijfsprestaties verbeteren. Het ondersteunt gegevens uit verschillende domeinen van de gezondheidszorg, zoals klinisch, administratief, financieel en sociaal. Het model voor gezondheidszorggegevens legt gegevens vast die zijn gedefinieerd door de FHIR-standaard en organiseert de FHIR-bronnen met behulp van tabellen en kolommen binnen het lakehouse.
Door FHIR-gegevens samen te voegen in delta parquet-tabellen, kunt u vertrouwde hulpmiddelen als T-SQL en Spark SQL gebruiken voor het verkennen en analyseren van gegevens. Voor niet-klinische gegevens buiten het bereik van FHIR gebruiken we schema's uit de Azure Synapse-databasesjablonen. Deze implementatie maakt het mogelijk niet-klinische informatie, zoals patiëntbetrokkenheidsgegevens, te integreren in het patiëntprofiel.
Het model voor gezondheidszorggegevens in het zilveren lakehouse is ontworpen om een end-to-end enterprise-overzicht van gezondheidszorggegevens in business units en onderzoeksdomeinen weer te geven.

Gegevensherkomst en traceerbaarheid
Om de herkomst en traceerbaarheid op record- en bestandsniveau te waarborgen, bevatten de tabellen van het model voor gezondheidszorggegevens de volgende kolommen:
| Kolom | Omschrijving |
|---|---|
msftCreatedDatetime |
Tijdstempel van het moment waarop het record voor het eerst werd gemaakt in het zilveren lakehouse. |
msftModifiedDatetime |
Tijdstempel van de laatste wijziging van het record. |
msftFilePath |
Volledig pad naar het bronbestand in het bronzen lakehouse, inclusief snelkoppelingen. |
msftSourceSystem |
Het bronsysteem van het record, dat overeenkomt met de Namespace specificatie in de uniforme mapstructuur. |
Als een veld wordt genormaliseerd, zonder opmaak wordt weergegeven of gewijzigd, blijft de oorspronkelijke waarde in een {columnName}Orig-kolom behouden. In de tabel Patiënt in het zilveren lakehouse kunt u bijvoorbeeld de volgende kolommen vinden:
| Kolom | Omschrijving |
|---|---|
meta_lastUpdatedOrig |
Behoudt de oorspronkelijke waarde in de onbewerkte indeling (tekenreeks of datum) en slaat deze op als datum/tijd. |
idOrig en identifierOrig |
ID's en aanduidingen zijn geharmoniseerd in het zilveren lakehouse. |
birthdateOrig en deceasedDateTimeOrig |
Behoudt de oorspronkelijke datumwaarden met een andere tijdstempelnotatie. |
Als een kolom zonder opmaak wordt weergegeven (bijvoorbeeld meta_lastUpdated) of wordt omgezet in een tekenreeks (bijvoorbeeld meta_string), duiden we deze aan met een achtervoegsel dat begint met een onderstrepingsteken (_).
Verwerken van updates
Wanneer nieuwe gegevens van het bronzen in het zilveren lakehouse worden opgenomen, worden de binnenkomende records door middel van een updatebewerking vergeleken met de doeltabellen in het zilveren lakehouse voor elk resource- en tabeltype. Voor FHIR-tabellen in het zilveren lakehouse controleert deze vergelijking zowel de {FHIRResource}.id- als {FHIRResource}.meta_lastUpdated-waarden tegen de kolommen id en lastUpdated in de faseringstabel ClinicalFhir van het bronzen lakehouse.
- Als er een match wordt gevonden en het inkomende record nieuw is, wordt het zilveren record bijgewerkt.
- Als het binnenkomende record oud is, wordt het zilveren record genegeerd.
- Als er geen match wordt gevonden, wordt het nieuwe record in het zilveren lakehouse geplaatst.
Beheer-lakehouse
Het beheer-lakehouse beheert de configuratie van lakehouses, de algemene configuratie, statusrapportage en tracering voor oplossingen voor gezondheidszorggegevens in Microsoft Fabric.
Algemene configuratie
De map system-configurations van het beheer-lakehouse centraliseert de parameters van de algemene configuratie. De drie configuratiebestanden bevatten vooraf geconfigureerde waarden voor de standaardimplementatie van alle mogelijkheden voor oplossingen voor gezondheidszorggegevens. U hoeft geen van deze waarden opnieuw te configureren om de voorbeeldgegevens of gegevens-pipelines voor welke mogelijkheid dan ook uit te voeren.

Het bestand deploymentParametersConfiguration.json bevat algemene parameters onder activitiesGlobalParameters en activiteitsspecifieke parameters voor notitieblokken en pipelines onder activities. De betreffende richtlijnen voor de mogelijkheden bevatten specifieke configuratiedetails voor elke mogelijkheid. De bestandsparameters van validatie_config.json worden uitgelegd in Gegevensvalidatie.
In de volgende tabel worden alle algemene configuratieparameters weergegeven.
| Sectie | Configuratieparameters |
|---|---|
activitiesGlobalParameters |
•administration_lakehouse_id: aanduiding beheer-lakehouse.• bronze_lakehouse_id: aanduiding bronzen lakehouse.• silver_lakehouse_id: aanduiding zilveren lakehouse.• keyvault_name: Azure Key Vault-waarde bij implementatie met de Azure Marketplace-aanbieding.• enable_hds_logs: schakelt logboekregistratie in; standaardwaarde ingesteld op true.• movement_config_path: pad naar het bestand file_orchestration_config.• bronze_imaging_delta_table_path: Fabric-pad voor de tabel voor de beeldvormingsmodaliteit (indien geïmplementeerd).• bronze_imaging_table_schema_path: Fabric-pad voor het schema voor de beeldvormingsmodaliteit (indien geïmplementeerd).• omop_lakehouse_id: aanduiding gouden lakehouse (indien geïmplementeerd). |
| Activiteiten voor healthcare#_msft_fhir_ndjson_bronze_ingestion | •source_path_pattern: OneLake-pad naar de map Verwerken.• move_failed_files_enabled: markering om te bepalen of een mislukt bestand moet worden verplaatst van de map Opnemen naar de map Mislukt.• compression_enabled: markering om te bepalen of de onbewerkte NDJSON-bestanden na verwerking worden gecomprimeerd.• target_table_name: naam van de klinische opnametabel in het bronzen lakehouse.• target_tables_path: OneLake-pad voor alle deltatabellen in het bronzen lakehouse.• max_files_per_trigger: aantal bestanden dat bij elke uitvoering wordt verwerkt.• max_structured_streaming_queries: aantal verwerkingsquery's dat parallel kan worden uitgevoerd.• checkpoint_path: OneLake-pad voor de checkpointmap.• schema_dir_path: OneLake-pad voor de bronzen schemamap.• validation_config_key: validatieconfiguratie op bovenliggend niveau. Zie Gegevensvalidatie voor meer informatie.• file_extension: de extensie van het opgenomen onbewerkte bestand. |
| Activiteiten voor healthcare#_msft_bronze_silver_flatten | •source_table_name: naam van de klinische opnametabel in het bronzen lakehouse.• config_path: OneLake-pad naar het configuratiebestand zonder opmaak.• source_tables_path: OneLake-pad naar de bron-deltatabellen in het bronzen lakehouse.• target_tables_path: OneLake-pad naar de doel-deltatabellen in het zilveren lakehouse.• checkpoint_path: OneLake-pad voor de checkpointmap.• schema_dir_path: OneLake-pad voor de bronzen schemamap.• max_files_per_trigger: aantal bestanden dat binnen elke uitvoering wordt verwerkt.• max_bytes_per_trigger: aantal bytes dat binnen elke uitvoering wordt verwerkt.• max_structured_streaming_queries: aantal verwerkingsquery's dat parallel kan worden uitgevoerd. |
| Activiteiten voor healthcare#_msft_imaging_dicom_extract_bronze_ingestion | •byos_enabled: markering die bepaalt of de opname van de DICOM-beeldvormingsgegevensset in het bronzen lakehouse afkomstig is uit een externe opslaglocatie via OneLake-snelkoppelingen. In dit geval worden de bestanden niet verplaatst naar de map Verwerken, zoals anders het geval zou zijn.• external_source_path: OneLake-pad voor de snelkoppelingsmap Extern in het bronzen lakehouse.• process_source_path: OneLake-pad voor de map Verwerken in het bronzen lakehouse.• checkpoint_path: OneLake-pad voor de checkpointmap.• move_failed_files: markering die bepaalt of een mislukt bestand wordt verplaatst van de map Opnemen naar de map Mislukt.• compression_enabled: markering die bepaalt of de onbewerkte NDJSON-bestanden na verwerking worden gecomprimeerd.• max_files_per_trigger: aantal bestanden dat binnen elke uitvoering wordt verwerkt.• num_retries: aantal pogingen voor elke bestandsverwerking voordat er een fout optreedt. |
| Activiteiten voor healthcare#_msft_imaging_dicom_fhir_conversion | •fhir_ndjson_files_root_path: OneLake-pad naar de map Verwerken.• avro_schema_path: OneLake-pad voor de zilveren schemamap.• dicom_to_fhir_config_path: OneLake-pad voor het toewijzen van configuratie van DICOM-metatags aan de FHIR ImagingStudy-resource.• checkpoint_path: OneLake-pad voor de checkpointmap.• max_records_per_ndjson: aantal records dat in één NDJSON-bestand wordt verwerkt in elke uitvoering.• subject_id_type_code: waardecode voor het medisch nummer van de patiënt in de DICOM-metagegevens. De standaardwaarde is ingesteld op MR. Dit komt overeen met Medical Record Number in FHIR.• subject_id_type_code_system: het codesysteem voor het medisch nummer van de patiënt in de DICOM-metagegevens.• subject_id_system: het object-id voor het codesysteem voor het medisch nummer van de patiënt in de DICOM-metagegevens. |
| Activiteiten voor healthcare#_msft_omop_silver_gold_transformation | •vocab_path: OneLake-pad naar de map met verwijzingsgegevens in het bronzen lakehouse waar de OMOP-vocabulairegegevenssets zijn opgeslagen.• vocab_checkpoint_path: OneLake-pad voor de checkpointmap.• omop_config_path: OneLake-pad voor het toewijzen van de configuratie van het zilveren lakehouse naar het gouden OMOP-lakehouse. |
BusinessEvents-tabel
De BusinessEvents-deltatabel legt alle validatiefouten, waarschuwingen en andere meldingen of uitzonderingen vast die kunnen optreden tijdens opname- en transformatieprocessen. Gebruik deze tabel om de voortgang van het opnameproces te bewaken op zowel gebruikers- als functioneel niveau en niet alleen op systeemlogboekniveau. Het identificeert bijvoorbeeld welke onbewerkte bestanden validatiefouten of waarschuwingen bevatten tijdens de opname. Voor logboeken op systeemniveau en om Apache Spark-activiteiten in alle lakehouses te monitoren, kunt u de Fabric Monitoring-hub gebruiken, met de optie om Azure Log Analytics te integreren.
In de volgende tabel staan de kolommen in de BusinessEvent-tabel:
| Kolom | Omschrijving |
|---|---|
id |
Unieke id (GUID) voor elke rij in de tabel. |
activityName |
Naam van de activiteit of het notitieblok die de fout en/of de validatiefout of -waarschuwing heeft gegenereerd. |
targetTableName |
Doeltabel voor de gegevensactiviteit die de gebeurtenis heeft gegenereerd. |
targetFilePath |
Pad voor het doelbestand voor de gegevensactiviteit die de gebeurtenis heeft gegenereerd. |
sourceTableName |
Brontabel voor de gegevensactiviteit die de gebeurtenis heeft gegenereerd. |
sourceLakehouseName |
Bron-lakehouse voor de gegevensactiviteit die de gebeurtenis heeft gegenereerd. |
targetLakehouseName |
Doel-lakehouse voor de gegevensactiviteit die de gebeurtenis heeft gegenereerd. |
sourceFilePath |
Pad voor het bronbestand voor de gegevensactiviteit die de gebeurtenis heeft gegenereerd. |
runId |
Uitvoerings-id voor de gegevensactiviteit die de gebeurtenis heeft gegenereerd. |
severity |
Ernstniveau van de gebeurtenis, dat een van de volgende twee waarden kan hebben: Error of Warning. Error betekent dat u deze gebeurtenis moet oplossen voordat u verder kunt gaan met de gegevensactiviteit. Warning fungeert als een passieve melding, waarvoor doorgaans geen onmiddellijke actie vereist is. |
eventType |
Maakt onderscheid tussen gebeurtenissen die door de validatie-engine worden gegenereerd en algemene gebeurtenissen die door gebruikers worden gegenereerd of onverwerkte/systeemuitzonderingen die gebruikers in de BusinessEvent-tabel willen weergeven. |
recordIdentifier |
Id voor het bronrecord. Deze kolom verschilt van de kolom id, omdat deze een nieuwe en unieke id voor elke gebeurtenis in de BusinessEvents-tabel vertegenwoordigt. |
recordIdentifierSource |
Bronsysteem voor de id van het bronrecord. Als het bronsysteem bijvoorbeeld EMD is, dan fungeert de EMD-naam of URL als bron. |
active |
Markering die aangeeft of de gebeurtenis (fout of waarschuwing) is opgelost. |
message |
Beschrijvend bericht voor de fout of waarschuwing bij de gebeurtenis. |
exception |
Bericht over onverwerkte/systeemuitzondering. |
customDimensions |
Van toepassing wanneer de brongegevens van de validatie of uitzondering geen afzonderlijke kolom in een tabel zijn. Wanneer de brongegevens bijvoorbeeld een kenmerk zijn binnen een JSON-object dat is opgeslagen als een tekenreeks in één kolom, wordt het volledige JSON-object als de aangepaste dimensie verstrekt. |
eventDateTime |
Tijdstempel waarop de gebeurtenis of uitzondering wordt gegenereerd. |
Gegevensvalidatie
De gegevensvalidatie-engine binnen de oplossingen voor gezondheidszorggegevens in Microsoft Fabric zorgt ervoor dat de onbewerkte gegevens voldoen aan vooraf gedefinieerde criteria voordat ze in het bronzen lakehouse worden opgenomen. U kunt de validatieregels op tabel- en kolomniveau configureren in het bronzen lakehouse. Momenteel worden deze regels uitsluitend geïmplementeerd tijdens het opnameproces, van onbewerkte bestanden tot deltatabellen in het bronzen lakehouse.
Wanneer een onbewerkt bestand wordt verwerkt, worden de validatieregels op opnameniveau toegepast. Er zijn twee ernstniveaus voor validatie: Error en Warning. Als een validatieregel is ingesteld op Error, stopt de pipeline wanneer de regel wordt overtreden en het defecte bestand wordt verplaatst naar de map Mislukt. Als de ernst is ingesteld op Warning, gaat de pipeline door met verwerken en wordt het bestand verplaatst naar de map Verwerken. In beide gevallen worden vermeldingen over de fouten of waarschuwingen gemaakt in de BusinessEvents-tabel in het beheer-lakehouse.
De BusinessEvents-tabel legt logboeken en gebeurtenissen op bedrijfsniveau vast in alle lakehouses voor elke activiteit, notitieblok of gegevens-pipeline binnen oplossingen voor gezondheidszorggegevens. De huidige configuratie dwingt echter alleen validatieregels af tijdens de opname, wat ertoe kan leiden dat sommige kolommen in de BusinessEvents-tabel leeg blijft vanwege validatiefouten en waarschuwingen.
U kunt de regels voor gegevensvalidatie configureren in het bestand validation_config.json in het beheer-lakehouse. Standaard worden de kolommen meta.lastUpdated en id in de ClinicalFhir-tabel van het bronzen lakehouse ingesteld als vereist. Deze kolommen zijn van cruciaal belang om te bepalen hoe updates en invoegingen worden beheerd in het zilveren lakehouse, zoals uitgelegd in Verwerken van updates.
De volgende tabel bevat de configuratieparameters voor gegevensvalidatie:
| Configuratietype | Parameters |
|---|---|
| Lakehouse-niveau | bronze: het bereik van de validatie- en record-id-knooppunten. In dit geval is de waarde ingesteld op het bronzen lakehouse. |
| Validaties | •validationType: het validatietype exists controleert of er een waarde voor het geconfigureerde kenmerk in het onbewerkte bestand (brongegevens) aanwezig is.• attributeName: de naam van het kenmerk dat wordt gevalideerd.• validationMessage: bericht waarin de validatiefout of -waarschuwing wordt beschreven.• severity: geeft het niveau van het probleem aan, dat Error of Warning kan zijn.• tableName: de naam van de tabel die wordt gevalideerd. Een asterisk (*) geeft aan dat deze regel van toepassing is op alle tabellen binnen het bereik van dat lakehouse. |
recordIdentifier |
•attributeName: record-id van het bronbestand of het onbewerkte bestand dat in de kolom recordIdentifier in de BusinessEvent-tabel is geplaatst.• jsonPath: optionele waarde die het JSON-pad van een kolom of kenmerk vertegenwoordigt voor de waarde die in de kolom recordIdentifier in de BusinessEvent-tabel moet worden geplaatst. Deze waarde is van toepassing wanneer de brongegevens voor de validatie geen afzonderlijke kolom in een tabel zijn. Als de brongegevens bijvoorbeeld een kenmerk zijn binnen een JSON-object dat is opgeslagen als een tekenreeks in één kolom, verwijst het JSON-pad naar het specifieke kenmerk dat dient als record-id. |