Transformaties van CMS-claimgegevens (preview) gebruiken in oplossingen voor gezondheidszorggegevens
[Dit artikel maakt deel uit van de voorlopige documentatie en kan nog veranderen.]
Met transformatie van CMS-claimgegevens (preview) kunt u claimgegevens opnemen, opslaan en analyseren in CMS (Centers for Medicare & Medicaid Services) CCLF-indeling (Claim and Claim Line Feed). Voor meer informatie over de mogelijkheid en hoe u deze kunt implementeren en configureren, zie:
- Overzicht van gegevenstransformaties van CMS-claims (preview)
- Transformatie van CMS-claimgegevens implementeren en configureren (preview)
Het transformatiemechanisme begrijpen
De pijplijn voor de transformatie van claimgegevens verwerkt claimbestanden in een native of gecomprimeerde indeling in het lakehouse. De end-to-end transformatie volgt deze opeenvolgende, hoogwaardige stappen:
- De claimbestanden transformeren in OneLake
- De claimbestanden ordenen in OneLake
- Claimgegevens extraheren in het bronzen lakehouse
- Claimgegevens converteren naar FHIR NDJSON-bestanden
- Claimgegevens transformeren naar afgeplatte FHIR-tabellen in het bronzen lakehouse
- Claimgegevens transformeren naar relationele FHIR-tabellen in het zilveren lakehouse
De pijplijn voor transformatie van claimgegevens uitvoeren
Zorg ervoor dat u de stappen in Voorbeeldclaimgegevens claims instellen voltooit voordat u de pijplijn voor transformatie van claimgegevens uitvoert.
Om de claimgegevens van het bronzen lakehouse naar het zilveren lakehouse te transformeren, opent u de gegevenspijplijn healthcare#_msft_clinical_claims_cclf_data_transformation en selecteert u Uitvoeren.
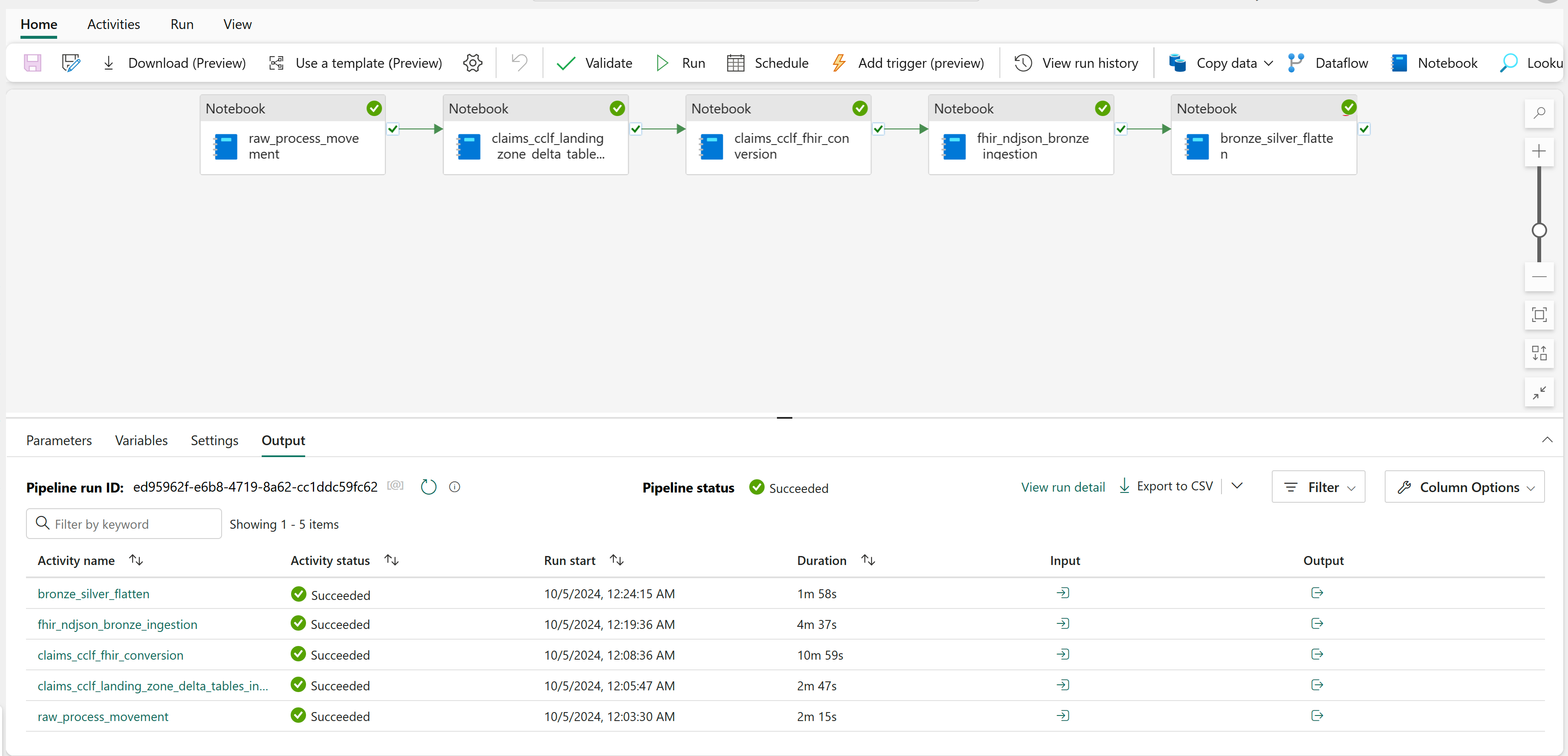
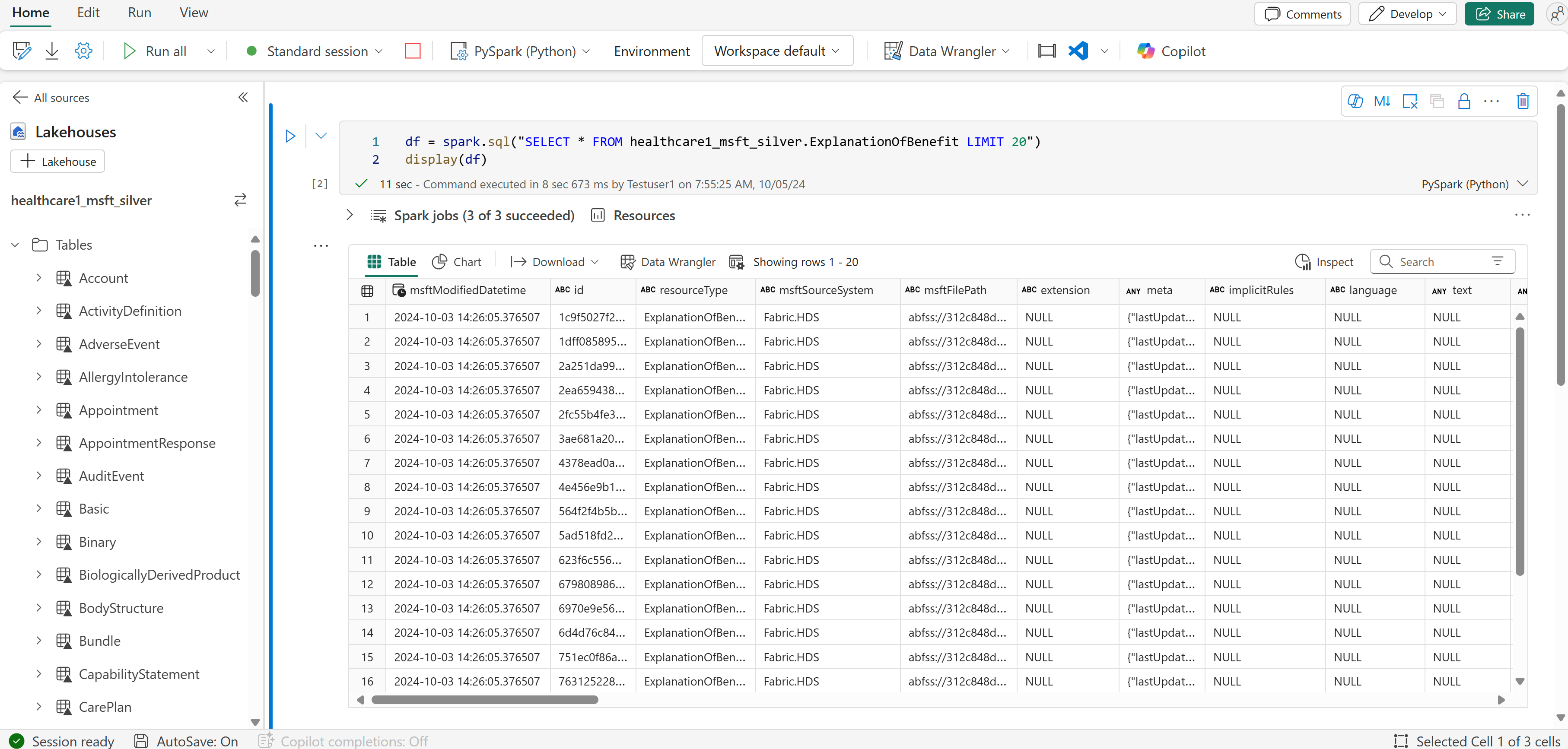
Nadat de pijplijn is uitgevoerd, opent u de tabel ExplanationOfBenefit in het zilveren lakehouse om de getransformeerde gegevens te bekijken.


Gebruiksoverwegingen
Lees deze belangrijke punten door voordat u de mogelijkheid voor transformatie van CMS-claimgegevens (preview) gebruikt.
Spark-versie
De notebooks zijn vooraf geconfigureerd om te worden uitgevoerd met Spark runtime versie 1.2 (Spark 3.4, Delta 2.4). Zorg dat u deze instelling op omgevingsniveau handhaaft. Zie Spark-runtimeversie opnieuw instellen in de Fabric-werkruimte voor meer informatie.
Bestandsextensie
De geüploade CCLF-bestanden moeten de volgende extensie-indeling hebben: *.T1000001 tot *.T1000009. Bestanden met onjuiste extensies worden verplaatst naar de map Mislukt in het bronzen lakehouse.
Recordlengte
Een recordlengteverschil in CCLF-bestanden treedt op wanneer een of meer records afwijken van de vereiste indeling met vaste lengte. Deze mismatch kan leiden tot verkeerde uitlijning van de gegevens, onvolledige gegevensregistratie of verwerkingsfouten. Bestanden met records die niet aan de verwachte lengte voldoen, worden verplaatst naar de map Mislukt in het bronzen lakehouse.