Een prognosemodel ontwikkelen, evalueren en scoren voor de verkoop van superstores
Deze handleiding biedt een end-to-end voorbeeld van een Synapse Data Science workflow in Microsoft Fabric. In het scenario wordt een prognosemodel gebouwd dat gebruikmaakt van historische verkoopgegevens om de verkoop van productcategorie in een superstore te voorspellen.
Prognoses zijn een cruciaal activum in de verkoop. Het combineert historische gegevens en voorspellende methoden om inzicht te krijgen in toekomstige trends. Prognoses kunnen eerdere verkopen analyseren om patronen te identificeren en leren van consumentengedrag om voorraad-, productie- en marketingstrategieën te optimaliseren. Deze proactieve aanpak verbetert de aanpassingsbaarheid, reactiesnelheid en algehele prestaties van bedrijven in een dynamische marketplace.
In deze zelfstudie worden de volgende stappen behandeld:
- De gegevens laden
- Verkennende gegevensanalyse gebruiken om de gegevens te begrijpen en te verwerken
- Een machine learning-model trainen met een opensource-softwarepakket en experimenten bijhouden met MLflow en de Fabric-functie voor automatisch loggen.
- Sla het uiteindelijke machine learning-model op en maak voorspellingen
- De modelprestaties weergeven met Power BI-visualisaties
Voorwaarden
Een Microsoft Fabric-abonnementophalen. Of meld u aan voor een gratis microsoft Fabric-proefversie.
Meld u aan bij Microsoft Fabric-.
Gebruik de ervaringswisselaar aan de linkerkant van de startpagina om over te schakelen naar Fabric.

- Maak indien nodig een Microsoft Fabric Lakehouse zoals beschreven in Een lakehouse maken in Microsoft Fabric.
Volg mee in een notitieblok
U kunt een van de volgende opties kiezen om in een notitieblok bij te houden:
- Open en voer het ingebouwde notebook uit in de Synapse Data Science omgeving.
- Uw notebook uploaden van GitHub naar de Synapse Data Science-ervaring
Het ingebouwde notebook openen
Het voorbeeld Sales forecasting notebook begeleidt deze zelfstudie.
Als u het voorbeeldnotitieblok voor deze zelfstudie wilt openen, volgt u de instructies in Uw systeem voorbereiden op zelfstudies voor gegevenswetenschap.
Zorg ervoor dat je een lakehouse aan het notebook koppelt voordat je code gaat uitvoeren.
Het notebook importeren vanuit GitHub
Het AIsample - Superstore Forecast.ipynb notitieboekje hoort bij deze handleiding.
Als u het bijbehorende notitieblok voor deze zelfstudie wilt openen, volgt u de instructies in Uw systeem voorbereiden op zelfstudies voor gegevenswetenschap om het notebook in uw werkruimte te importeren.
Als u liever de code van deze pagina kopieert en plakt, kunt u een nieuw notitieblok maken.
Zorg ervoor dat een lakehouse aan het notebook koppelen voordat u begint met het uitvoeren van code.
Stap 1: de gegevens laden
De gegevensset bevat 9.995 exemplaren van de verkoop van verschillende producten. Het bevat ook 21 kenmerken. Deze tabel is afkomstig uit het Superstore.xlsx-bestand dat in dit notebook wordt gebruikt:
| Rij-id | Order-ID | Orderdatum | Verzenddatum | Verzendmethode | Klant-id | Klantnaam | Segment | Land | Stad | Staat | Postcode | Regio | Product-ID | Categorie | Sub-Category | Productnaam | Verkoop | Hoeveelheid | Korting | Winst |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 4 | US-2015-108966 | 2015-10-11 | 2015-10-18 | Standard-klasse | SO-20335 | Sean O'Donnell | Consument | Verenigde Staten | Fort Lauderdale | Florida | 33311 | Zuiden | FUR-TA-10000577 | Meubilair | Tabellen | Bretford CR4500-serie slanke rechthoekige tafel | 957,5775 | 5 | 0.45 | -383.0310 |
| 11 | CA-2014-115812 | 2014-06-09 | 2014-06-09 | Standard-klasse | Standard-klasse | Brosina Hoffman | Consument | Verenigde Staten | Los Angeles | Californië | 90032 | Westen | FUR-TA-10001539 | Meubilair | Tabellen | Rechthoekige vergadertabellen van Chromcraft | 1706.184 | 9 | 0.2 | 85.3092 |
| 31 | US-2015-150630 | 2015-09-17 | 2015-09-21 | Standard-klasse | TB-21520 | Tracy Blumstein | Consument | Verenigde Staten | Philadelphia | Pennsylvania | 19140 | Oosten | OFF-EN-10001509 | Kantoorbenodigdheden | Enveloppen | Poly String Tie-sluitingenveloppen | 3,264 | 2 | 0.2 | 1.1016 |
Definieer deze parameters, zodat u dit notebook kunt gebruiken met verschillende gegevenssets:
IS_CUSTOM_DATA = False # If TRUE, the dataset has to be uploaded manually
IS_SAMPLE = False # If TRUE, use only rows of data for training; otherwise, use all data
SAMPLE_ROWS = 5000 # If IS_SAMPLE is True, use only this number of rows for training
DATA_ROOT = "/lakehouse/default"
DATA_FOLDER = "Files/salesforecast" # Folder with data files
DATA_FILE = "Superstore.xlsx" # Data file name
EXPERIMENT_NAME = "aisample-superstore-forecast" # MLflow experiment name
De gegevensset downloaden en uploaden naar het lakehouse
Met deze code wordt een openbaar beschikbare versie van de gegevensset gedownload en vervolgens opgeslagen in een Fabric Lakehouse:
Belangrijk
Zorg ervoor dat u een lakehouse toevoegt aan het notebook voordat u het uitvoert. Anders krijgt u een foutmelding.
import os, requests
if not IS_CUSTOM_DATA:
# Download data files into the lakehouse if they're not already there
remote_url = "https://synapseaisolutionsa.blob.core.windows.net/public/Forecast_Superstore_Sales"
file_list = ["Superstore.xlsx"]
download_path = "/lakehouse/default/Files/salesforecast/raw"
if not os.path.exists("/lakehouse/default"):
raise FileNotFoundError(
"Default lakehouse not found, please add a lakehouse and restart the session."
)
os.makedirs(download_path, exist_ok=True)
for fname in file_list:
if not os.path.exists(f"{download_path}/{fname}"):
r = requests.get(f"{remote_url}/{fname}", timeout=30)
with open(f"{download_path}/{fname}", "wb") as f:
f.write(r.content)
print("Downloaded demo data files into lakehouse.")
Het volgen van MLflow-experimenten instellen
In Microsoft Fabric worden automatisch de waarden van invoerparameters en metrische uitvoergegevens van een machine learning-model vastgelegd terwijl u het traint. Dit breidt de mogelijkheden voor automatische aanmelding van MLflow uit. De informatie wordt vervolgens vastgelegd in de werkruimte, waar u deze kunt openen en visualiseren met de MLflow-API's of het bijbehorende experiment in de werkruimte. Zie Autologging in Microsoft Fabricvoor meer informatie over automatisch aanmelden.
Als u automatische aanmelding van Microsoft Fabric in een notitiebloksessie wilt uitschakelen, roept u mlflow.autolog() aan en stelt u disable=Truein:
# Set up MLflow for experiment tracking
import mlflow
mlflow.set_experiment(EXPERIMENT_NAME)
mlflow.autolog(disable=True) # Turn off MLflow autologging
De ruwe gegevens uit het lakehouse lezen
Lees onbewerkte gegevens uit de sectie Files van het lakehouse. Voeg meer kolommen toe voor verschillende datumonderdelen. Dezelfde informatie wordt gebruikt om een gepartitioneerde deltatabel te maken. Omdat de onbewerkte gegevens worden opgeslagen als een Excel-bestand, moet u pandas gebruiken om deze te lezen:
import pandas as pd
df = pd.read_excel("/lakehouse/default/Files/salesforecast/raw/Superstore.xlsx")
Stap 2: Experimentele gegevensanalyse uitvoeren
Bibliotheken importeren
Voordat u een analyse kunt uitvoeren, importeert u de vereiste bibliotheken:
# Importing required libraries
import warnings
import itertools
import numpy as np
import matplotlib.pyplot as plt
warnings.filterwarnings("ignore")
plt.style.use('fivethirtyeight')
import pandas as pd
import statsmodels.api as sm
import matplotlib
matplotlib.rcParams['axes.labelsize'] = 14
matplotlib.rcParams['xtick.labelsize'] = 12
matplotlib.rcParams['ytick.labelsize'] = 12
matplotlib.rcParams['text.color'] = 'k'
from sklearn.metrics import mean_squared_error,mean_absolute_percentage_error
De onbewerkte gegevens weergeven
Controleer handmatig een subset van de gegevens om de gegevensset zelf beter te begrijpen en gebruik de functie display om het DataFrame af te drukken. Daarnaast kunnen de Chart weergaven eenvoudig subsets van de gegevensset visualiseren.
display(df)
Dit notebook richt zich voornamelijk op het voorspellen van de Furniture categorieverkopen. Dit versnelt de berekening en helpt de prestaties van het model weer te geven. In dit notebook worden echter aanpasbare technieken gebruikt. U kunt deze technieken uitbreiden om de verkoop van andere productcategorieën te voorspellen.
# Select "Furniture" as the product category
furniture = df.loc[df['Category'] == 'Furniture']
print(furniture['Order Date'].min(), furniture['Order Date'].max())
De gegevens vooraf verwerken
Bedrijfsscenario's in de praktijk moeten vaak verkoop voorspellen in drie verschillende categorieën:
- Een specifieke productcategorie
- Een specifieke klantcategorie
- Een specifieke combinatie van productcategorie en klantcategorie
Verwijder eerst overbodige kolommen om de gegevens vooraf te verwerken. Sommige kolommen (Row ID, Order ID,Customer IDen Customer Name) zijn niet nodig omdat ze geen invloed hebben. We willen de totale verkoop in de staat en regio voorspellen voor een specifieke productcategorie (Furniture), zodat we de State, Region, Country, Cityen Postal Code kolommen kunnen verwijderen. Als u de verkoop voor een specifieke locatie of categorie wilt voorspellen, moet u mogelijk de stap voorverwerken dienovereenkomstig aanpassen.
# Data preprocessing
cols = ['Row ID', 'Order ID', 'Ship Date', 'Ship Mode', 'Customer ID', 'Customer Name',
'Segment', 'Country', 'City', 'State', 'Postal Code', 'Region', 'Product ID', 'Category',
'Sub-Category', 'Product Name', 'Quantity', 'Discount', 'Profit']
# Drop unnecessary columns
furniture.drop(cols, axis=1, inplace=True)
furniture = furniture.sort_values('Order Date')
furniture.isnull().sum()
De gegevensset is dagelijks gestructureerd. We moeten de kolom Order Dateher-samplen, omdat we een model willen ontwikkelen om de maandelijkse verkoop te voorspellen.
Eerst de Furniture categorie op Order Dategroeperen. Bereken vervolgens de som van de kolom Sales voor elke groep om de totale verkoop voor elke unieke Order Date waarde te bepalen. Hersample de kolom Sales met behulp van de MS frequentie om de gegevens per maand samen te voegen. Bereken ten slotte de gemiddelde verkoopwaarde voor elke maand.
# Data preparation
furniture = furniture.groupby('Order Date')['Sales'].sum().reset_index()
furniture = furniture.set_index('Order Date')
furniture.index
y = furniture['Sales'].resample('MS').mean()
y = y.reset_index()
y['Order Date'] = pd.to_datetime(y['Order Date'])
y['Order Date'] = [i+pd.DateOffset(months=67) for i in y['Order Date']]
y = y.set_index(['Order Date'])
maximim_date = y.reset_index()['Order Date'].max()
De impact van Order Date op Sales voor de categorie Furniture demonstreren:
# Impact of order date on the sales
y.plot(figsize=(12, 3))
plt.show()
Voordat u een statistische analyse hebt, moet u de statsmodels Python-module importeren. Het biedt klassen en functies voor de schatting van veel statistische modellen. Het biedt ook klassen en functies voor het uitvoeren van statistische tests en statistische gegevensverkenning.
import statsmodels.api as sm
Statistische analyse uitvoeren
In een tijdreeks worden deze gegevenselementen bijgehouden op ingestelde intervallen om de variatie van deze elementen in het tijdreekspatroon te bepalen:
niveau: het fundamentele onderdeel dat de gemiddelde waarde vertegenwoordigt voor een specifieke periode
Trend: Beschrijft of de tijdreeks afneemt, constant blijft of toeneemt in de loop van de tijd
Seasonality: beschrijft het periodieke signaal in de tijdreeks en zoekt naar cyclische gebeurtenissen die van invloed zijn op de toenemende of afnemende tijdreekspatronen
ruis/residuen: verwijst naar de willekeurige fluctuaties en variabiliteit in de tijdreeksgegevens die het model niet kan uitleggen.
In deze code bekijkt u deze elementen voor uw gegevensset na de voorverwerking:
# Decompose the time series into its components by using statsmodels
result = sm.tsa.seasonal_decompose(y, model='additive')
# Labels and corresponding data for plotting
components = [('Seasonality', result.seasonal),
('Trend', result.trend),
('Residual', result.resid),
('Observed Data', y)]
# Create subplots in a grid
fig, axes = plt.subplots(nrows=4, ncols=1, figsize=(12, 7))
plt.subplots_adjust(hspace=0.8) # Adjust vertical space
axes = axes.ravel()
# Plot the components
for ax, (label, data) in zip(axes, components):
ax.plot(data, label=label, color='blue' if label != 'Observed Data' else 'purple')
ax.set_xlabel('Time')
ax.set_ylabel(label)
ax.set_xlabel('Time', fontsize=10)
ax.set_ylabel(label, fontsize=10)
ax.legend(fontsize=10)
plt.show()
In de plots worden de seizoensgebondenheid, trends en ruis in de prognosegegevens beschreven. U kunt de onderliggende patronen vastleggen en modellen ontwikkelen die nauwkeurige voorspellingen doen die bestand zijn tegen willekeurige fluctuaties.
Stap 3: Het model trainen en volgen
Nu u de gegevens beschikbaar hebt, definieert u het prognosemodel. In dit notebook past u het prognosemodel toe met de naam seizoensgebonden autoregressief geïntegreerd zwevend gemiddelde met exogene factoren (SARIMAX). SARIMAX combineert onderdelen van autoregressieve (AR) en zwevend gemiddelde (MA), seizoensgebonden differentiëren en externe voorspellingen om nauwkeurige en flexibele voorspellingen te maken voor tijdreeksgegevens.
U gebruikt ook autologging van MLflow en Fabric om de experimenten bij te houden. Laad hier de deltatabel vanuit het lakehouse. U kunt andere deltatabellen gebruiken die het lakehouse als bron beschouwen.
# Import required libraries for model evaluation
from sklearn.metrics import mean_squared_error, mean_absolute_percentage_error
Hyperparameters afstemmen
SARIMAX houdt rekening met de parameters die betrokken zijn bij de normale modus voor autoregressief geïntegreerd zwevend gemiddelde (ARIMA) (p, d, q) en voegt de seizoensgebondenheidsparameters (P, D, Q, s). Deze SARIMAX-modelargumenten worden volgorde genoemd (p, d, q) en seizoensvolgorde ( respectievelijkP, D, Q, s), . Daarom moeten we eerst zeven parameters afstemmen om het model te trainen.
De orderparameters:
p: de volgorde van het AR-onderdeel, dat het aantal eerdere waarnemingen in de tijdreeks aangeeft dat wordt gebruikt om de huidige waarde te voorspellen.Deze parameter moet doorgaans een niet-negatief geheel getal zijn. Gemeenschappelijke waarden bevinden zich in het bereik van
0tot3, hoewel hogere waarden mogelijk zijn, afhankelijk van de specifieke gegevenskenmerken. Een hogerepwaarde geeft een langer geheugen aan van eerdere waarden in het model.d: De differentiërende volgorde, die het aantal keren aangeeft dat de tijdreeks moet worden aangepast, om stationariteit te bereiken.Deze parameter moet een niet-negatief geheel getal zijn. Algemene waarden bevinden zich in het bereik van
0tot2. Eendwaarde van0betekent dat de tijdreeks al stationair is. Hogere waarden geven het aantal differentiërende bewerkingen aan dat nodig is om het stationair te maken.q: de volgorde van het MA-onderdeel, dat het aantal eerdere fouttermen voor witruis aangeeft dat wordt gebruikt om de huidige waarde te voorspellen.Deze parameter moet een niet-negatief geheel getal zijn. Algemene waarden bevinden zich in het bereik van
0tot3, maar voor bepaalde tijdreeksen kunnen hogere waarden nodig zijn. Een hogereqwaarde geeft een sterkere afhankelijkheid aan van eerdere fouttermen om voorspellingen te doen.
De parameters voor seizoensorders:
-
P: De seizoensvolgorde van het AR-onderdeel, vergelijkbaar metpmaar voor het seizoensonderdeel -
D: De seizoensgebonden volgorde van differentiëren, vergelijkbaar metdmaar voor het seizoensgebonden deel -
Q: De seizoensgebonden volgorde van het MA-onderdeel, vergelijkbaar metq, maar voor het seizoensonderdeel -
s: Het aantal tijdstappen per seizoensgebonden cyclus (bijvoorbeeld 12 voor maandelijkse gegevens met een jaarlijkse seizoensgebondenheid)
# Hyperparameter tuning
p = d = q = range(0, 2)
pdq = list(itertools.product(p, d, q))
seasonal_pdq = [(x[0], x[1], x[2], 12) for x in list(itertools.product(p, d, q))]
print('Examples of parameter combinations for Seasonal ARIMA...')
print('SARIMAX: {} x {}'.format(pdq[1], seasonal_pdq[1]))
print('SARIMAX: {} x {}'.format(pdq[1], seasonal_pdq[2]))
print('SARIMAX: {} x {}'.format(pdq[2], seasonal_pdq[3]))
print('SARIMAX: {} x {}'.format(pdq[2], seasonal_pdq[4]))
SARIMAX heeft andere parameters:
enforce_stationarity: Of het model moet zorgen voor stationariteit in de tijdreeksgegevens, voordat het SARIMAX-model wordt toegepast.Als
enforce_stationarityis ingesteld opTrue(de standaardinstelling), geeft dit aan dat het SARIMAX-model stationariteit moet afdwingen op de tijdreeksgegevens. Het SARIMAX-model past vervolgens automatisch differentiatie toe op de gegevens om het stationair te maken, zoals gespecificeerd door dedenDvolgorden, voordat het model wordt aangepast. Dit is gebruikelijk omdat veel tijdreeksmodellen, waaronder SARIMAX, ervan uitgaan dat de gegevens stationair zijn.Voor een niet-stationaire tijdreeks (bijvoorbeeld wanneer het trends of seizoensgebondenheid vertoont); is het een goede gewoonte om
enforce_stationarityin te stellen opTrueen het SARIMAX-model het differentiëren te laten afhandelen om stationariteit te bereiken. Voor een stationaire tijdreeks (bijvoorbeeld één zonder trends of seizoensgebondenheid), stelt uenforce_stationarityin opFalseom onnodige differentiëren te voorkomen.enforce_invertibility: Bepaalt of het model tijdens het optimalisatieproces de omkeerbaarheid moet afdwingen bij de geschatte parameters.Als
enforce_invertibilityis ingesteld opTrue(de standaardinstelling), geeft dit aan dat het SARIMAX-model invertibility moet afdwingen voor de geschatte parameters. Invertibility zorgt ervoor dat het model goed is gedefinieerd en dat de geschatte AR- en MA-coëfficiënten binnen het bereik van stationariteit terechtkomen.Afdwingbaarheid helpt ervoor te zorgen dat het SARIMAX-model voldoet aan de theoretische vereisten voor een stabiel tijdreeksmodel. Het helpt ook problemen met modelraming en stabiliteit te voorkomen.
De standaardwaarde is een AR(1) model. Dit verwijst naar (1, 0, 0). Het is echter gebruikelijk om verschillende combinaties van de orderparameters en seizoensgebonden orderparameters uit te proberen en de modelprestaties voor een gegevensset te evalueren. De juiste waarden kunnen variëren van de ene tijdreeks naar de andere.
Het bepalen van de optimale waarden omvat vaak een analyse van de functie autocorrectie (ACF) en een gedeeltelijke functie voor autocorrectie (PACF) van de tijdreeksgegevens. Het omvat ook vaak het gebruik van modelselectiecriteria, bijvoorbeeld het Akaike-informatiecriterium (AIC) of het Bayesiaanse informatiecriterium (BIC).
De hyperparameters afstemmen:
# Tune the hyperparameters to determine the best model
for param in pdq:
for param_seasonal in seasonal_pdq:
try:
mod = sm.tsa.statespace.SARIMAX(y,
order=param,
seasonal_order=param_seasonal,
enforce_stationarity=False,
enforce_invertibility=False)
results = mod.fit(disp=False)
print('ARIMA{}x{}12 - AIC:{}'.format(param, param_seasonal, results.aic))
except:
continue
Na de evaluatie van de voorgaande resultaten kunt u de waarden voor zowel de orderparameters als de seizoensgebonden orderparameters bepalen. De keuze is order=(0, 1, 1) en seasonal_order=(0, 1, 1, 12), die de laagste AIC bieden (bijvoorbeeld 279,58). Gebruik deze waarden om het model te trainen.
Het model trainen
# Model training
mod = sm.tsa.statespace.SARIMAX(y,
order=(0, 1, 1),
seasonal_order=(0, 1, 1, 12),
enforce_stationarity=False,
enforce_invertibility=False)
results = mod.fit(disp=False)
print(results.summary().tables[1])
Met deze code wordt een tijdreeksprognose voor verkoopgegevens van meubels gevisualiseerd. In de getekende resultaten worden zowel de waargenomen gegevens als de éénstapsprognose weergegeven, met een gearceerd gebied voor het betrouwbaarheidsinterval.
# Plot the forecasting results
pred = results.get_prediction(start=maximim_date, end=maximim_date+pd.DateOffset(months=6), dynamic=False) # Forecast for the next 6 months (months=6)
pred_ci = pred.conf_int() # Extract the confidence intervals for the predictions
ax = y['2019':].plot(label='observed')
pred.predicted_mean.plot(ax=ax, label='One-step ahead forecast', alpha=.7, figsize=(12, 7))
ax.fill_between(pred_ci.index,
pred_ci.iloc[:, 0],
pred_ci.iloc[:, 1], color='k', alpha=.2)
ax.set_xlabel('Date')
ax.set_ylabel('Furniture Sales')
plt.legend()
plt.show()
# Validate the forecasted result
predictions = results.get_prediction(start=maximim_date-pd.DateOffset(months=6-1), dynamic=False)
# Forecast on the unseen future data
predictions_future = results.get_prediction(start=maximim_date+ pd.DateOffset(months=1),end=maximim_date+ pd.DateOffset(months=6),dynamic=False)
Gebruik predictions om de prestaties van het model te beoordelen door het te vergelijken met de werkelijke waarden. De predictions_future waarde geeft toekomstige prognoses aan.
# Log the model and parameters
model_name = f"{EXPERIMENT_NAME}-Sarimax"
with mlflow.start_run(run_name="Sarimax") as run:
mlflow.statsmodels.log_model(results,model_name,registered_model_name=model_name)
mlflow.log_params({"order":(0,1,1),"seasonal_order":(0, 1, 1, 12),'enforce_stationarity':False,'enforce_invertibility':False})
model_uri = f"runs:/{run.info.run_id}/{model_name}"
print("Model saved in run %s" % run.info.run_id)
print(f"Model URI: {model_uri}")
mlflow.end_run()
# Load the saved model
loaded_model = mlflow.statsmodels.load_model(model_uri)
Stap 4: Het model beoordelen en voorspellingen opslaan
Integreer de werkelijke waarden met de voorspelde waarden om een Power BI-rapport te maken. Sla deze resultaten op in een tabel in het lakehouse.
# Data preparation for Power BI visualization
Future = pd.DataFrame(predictions_future.predicted_mean).reset_index()
Future.columns = ['Date','Forecasted_Sales']
Future['Actual_Sales'] = np.NAN
Actual = pd.DataFrame(predictions.predicted_mean).reset_index()
Actual.columns = ['Date','Forecasted_Sales']
y_truth = y['2023-02-01':]
Actual['Actual_Sales'] = y_truth.values
final_data = pd.concat([Actual,Future])
# Calculate the mean absolute percentage error (MAPE) between 'Actual_Sales' and 'Forecasted_Sales'
final_data['MAPE'] = mean_absolute_percentage_error(Actual['Actual_Sales'], Actual['Forecasted_Sales']) * 100
final_data['Category'] = "Furniture"
final_data[final_data['Actual_Sales'].isnull()]
input_df = y.reset_index()
input_df.rename(columns = {'Order Date':'Date','Sales':'Actual_Sales'}, inplace=True)
input_df['Category'] = 'Furniture'
input_df['MAPE'] = np.NAN
input_df['Forecasted_Sales'] = np.NAN
# Write back the results into the lakehouse
final_data_2 = pd.concat([input_df,final_data[final_data['Actual_Sales'].isnull()]])
table_name = "Demand_Forecast_New_1"
spark.createDataFrame(final_data_2).write.mode("overwrite").format("delta").save(f"Tables/{table_name}")
print(f"Spark DataFrame saved to delta table: {table_name}")
Stap 5: Visualiseren in Power BI
In het Power BI-rapport wordt een gemiddelde absolute percentagefout (MAPE) van 16,58 weergegeven. De metriek MAPE bepaalt de nauwkeurigheid van een voorspellingsmethode. Het vertegenwoordigt de nauwkeurigheid van de geraamde hoeveelheden, in vergelijking met de werkelijke hoeveelheden.
MAPE is een eenvoudige metrische waarde. Een MAPE van 10% geeft aan dat de gemiddelde afwijking tussen de voorspelde waarden en de werkelijke waarden 10%is, ongeacht of de afwijking positief of negatief was. De normen van wenselijke MAPE-waarden verschillen per bedrijfstak.
De lichtblauwe lijn in deze grafiek vertegenwoordigt de werkelijke verkoopwaarden. De donkerblauwe lijn vertegenwoordigt de voorspelde verkoopwaarden. Vergelijking van de werkelijke en geraamde verkoop blijkt dat het model de verkoop voor de Furniture categorie in de eerste zes maanden van 2023 effectief voorspelt.
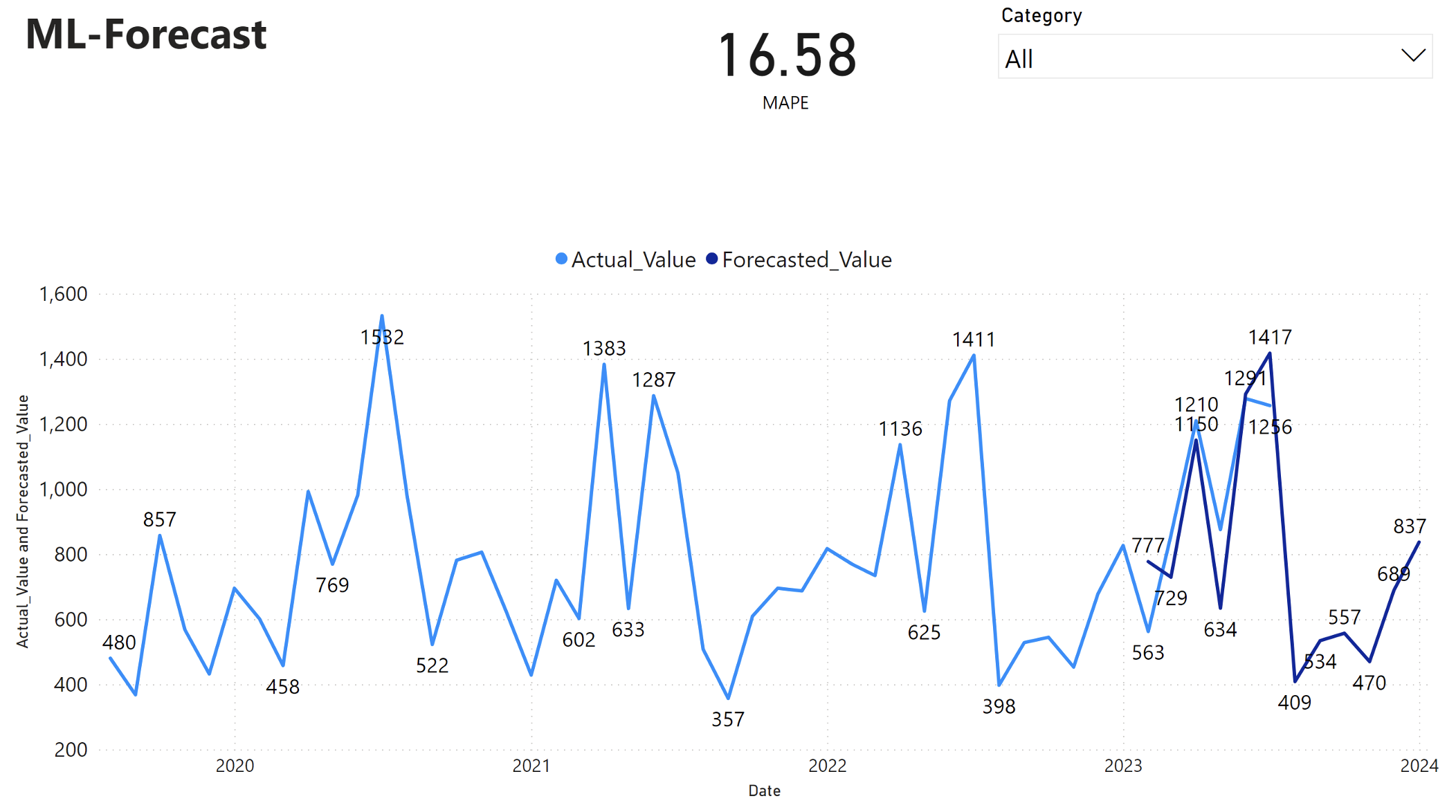
Op basis van deze observatie kunnen we vertrouwen hebben in de prognosemogelijkheden van het model, voor de totale verkoop in de afgelopen zes maanden van 2023 en uitbreiden tot 2024. Dit vertrouwen kan strategische beslissingen geven over voorraadbeheer, inkoop van grondstoffen en andere zakelijke overwegingen.