Zelfstudie: Een aanbevelingssysteem maken, evalueren en beoordelen
In deze zelfstudie vindt u een end-to-end-voorbeeld van een Synapse Data Science-werkstroom in Microsoft Fabric. In het scenario wordt een model gebouwd voor aanbevelingen voor onlineboeken.
In deze zelfstudie worden de volgende stappen behandeld:
- De gegevens uploaden naar een lakehouse
- Verkennende analyse uitvoeren op de gegevens
- Een model trainen en registreren met MLflow
- Het model laden en voorspellingen doen
Er zijn veel soorten aanbevelingsalgoritmen beschikbaar. In deze zelfstudie wordt gebruikgemaakt van het algoritme Alternating Least Squares (ALS) voor matrixfactorisatie. ALS is een op modellen gebaseerd filteralgoritme voor samenwerking.

ALS probeert de classificatiematrix R te schatten als het product van twee matrices met lagere rang, u en V. Hier, R = U * Vt. Deze benaderingen worden doorgaans factor matrices genoemd.
Het ALS-algoritme is iteratief. Elke iteratie bevat een van de factor matricesconstante, terwijl de andere wordt opgelost met behulp van de methode van minimale kwadraten. Vervolgens wordt de zojuist opgeloste factormatrix constant gehouden terwijl de andere factormatrix wordt opgelost.

Voorwaarden
Een Microsoft Fabric-abonnementophalen. Of meld u aan voor een gratis microsoft Fabric-proefversie.
Meld u aan bij Microsoft Fabric-.
Gebruik de ervaringswisselaar aan de linkerkant van de startpagina om over te schakelen naar Fabric.

- Maak indien nodig een Microsoft Fabric Lakehouse zoals beschreven in Een lakehouse maken in Microsoft Fabric.
Volg mee in een notitieblok
U kunt een van deze opties kiezen om mee te doen in een notitieblok:
- Open en voer het ingebouwde notebook uit.
- Upload uw notebook vanuit GitHub.
Het ingebouwde notebook openen
De voorbeeld Boekaanbeveling-notebook begeleidt deze zelfstudie.
Als u het voorbeeldnotitieblok voor deze zelfstudie wilt openen, volgt u de instructies in Uw systeem voorbereiden op zelfstudies voor gegevenswetenschap.
Zorg ervoor dat u een lakehouse koppelt aan het notebook voordat u begint met het uitvoeren van code.
Het notebook importeren vanuit GitHub
De AIsample - Book Recommendation.ipynb notebook begeleidt deze zelfstudie.
Als u het bijbehorende notitieblok voor deze zelfstudie wilt openen, volgt u de instructies in Uw systeem voorbereiden op zelfstudies voor gegevenswetenschap om het notebook in uw werkruimte te importeren.
Als u liever de code van deze pagina kopieert en plakt, kunt u een nieuw notitieblok maken.
Zorg ervoor dat u een lakehouse aan het notebook koppelt voordat u code uitvoert.
Stap 1: de gegevens laden
De gegevensset met aanbevelingen voor boeken in dit scenario bestaat uit drie afzonderlijke gegevenssets:
Books.csv: Een International Standard Book Number (ISBN) identificeert elk boek, met ongeldige datums die al zijn verwijderd. De gegevensset bevat ook de titel, auteur en uitgever. Voor een boek met meerdere auteurs bevat het bestand Books.csv alleen de eerste auteur. URL's verwijzen naar Amazon-websitebronnen voor de omslagafbeeldingen, in drie grootten.
ISBN Book-Title Book-Author Jaar-Of-Publication Uitgever Afbeelding -URL-S Afbeelding-URL-M Afbeelding-URL-l 0195153448 Klassieke mythe Mark P. O. Morford 2002 Oxford University Press http://images.amazon.com/images/P/0195153448.01.THUMBZZZ.jpg http://images.amazon.com/images/P/0195153448.01.MZZZZZZZ.jpg http://images.amazon.com/images/P/0195153448.01.LZZZZZZZ.jpg 0002005018 Clara Callan Richard Bruce Wright 2001 HarperFlamingo Canada http://images.amazon.com/images/P/0002005018.01.THUMBZZZ.jpg http://images.amazon.com/images/P/0002005018.01.MZZZZZZZ.jpg http://images.amazon.com/images/P/0002005018.01.LZZZZZZZ.jpg Ratings.csv: Beoordelingen voor elk boek zijn expliciet (verstrekt door gebruikers, op schaal van 1 tot 10) of impliciet (waargenomen zonder gebruikersinvoer en aangegeven door 0).
User-ID ISBN Book-Rating 276725 034545104X 0 276726 0155061224 5 Users.csv: gebruikers-id's worden geanonimiseerd en toegewezen aan gehele getallen. Demografische gegevens, bijvoorbeeld locatie en leeftijd, worden verstrekt, indien beschikbaar. Als deze gegevens niet beschikbaar zijn, worden deze waarden
null.User-ID Locatie Leeftijd 1 New York City, New York, Verenigde Staten 2 "stockton california usa" 18.0
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Definieer deze parameters, zodat u dit notebook met verschillende gegevenssets kunt gebruiken:
IS_CUSTOM_DATA = False # If True, the dataset has to be uploaded manually
USER_ID_COL = "User-ID" # Must not be '_user_id' for this notebook to run successfully
ITEM_ID_COL = "ISBN" # Must not be '_item_id' for this notebook to run successfully
ITEM_INFO_COL = (
"Book-Title" # Must not be '_item_info' for this notebook to run successfully
)
RATING_COL = (
"Book-Rating" # Must not be '_rating' for this notebook to run successfully
)
IS_SAMPLE = True # If True, use only <SAMPLE_ROWS> rows of data for training; otherwise, use all data
SAMPLE_ROWS = 5000 # If IS_SAMPLE is True, use only this number of rows for training
DATA_FOLDER = "Files/book-recommendation/" # Folder that contains the datasets
ITEMS_FILE = "Books.csv" # File that contains the item information
USERS_FILE = "Users.csv" # File that contains the user information
RATINGS_FILE = "Ratings.csv" # File that contains the rating information
EXPERIMENT_NAME = "aisample-recommendation" # MLflow experiment name
De gegevens downloaden en opslaan in een lakehouse
Met deze code wordt de gegevensset gedownload en vervolgens opgeslagen in het lakehouse.
Belangrijk
Zorg ervoor dat u een lakehouse- aan het notebook toevoegt voordat u het uitvoert. Anders krijgt u een foutmelding.
if not IS_CUSTOM_DATA:
# Download data files into a lakehouse if they don't exist
import os, requests
remote_url = "https://synapseaisolutionsa.blob.core.windows.net/public/Book-Recommendation-Dataset"
file_list = ["Books.csv", "Ratings.csv", "Users.csv"]
download_path = f"/lakehouse/default/{DATA_FOLDER}/raw"
if not os.path.exists("/lakehouse/default"):
raise FileNotFoundError(
"Default lakehouse not found, please add a lakehouse and restart the session."
)
os.makedirs(download_path, exist_ok=True)
for fname in file_list:
if not os.path.exists(f"{download_path}/{fname}"):
r = requests.get(f"{remote_url}/{fname}", timeout=30)
with open(f"{download_path}/{fname}", "wb") as f:
f.write(r.content)
print("Downloaded demo data files into lakehouse.")
Het bijhouden van MLflow-experimenten instellen
Gebruik deze code om het bijhouden van MLflow-experimenten in te stellen. In dit voorbeeld wordt automatische aanmelding uitgeschakeld. Zie het artikel Autologging in Microsoft Fabric voor meer informatie.
# Set up MLflow for experiment tracking
import mlflow
mlflow.set_experiment(EXPERIMENT_NAME)
mlflow.autolog(disable=True) # Disable MLflow autologging
Gegevens lezen uit lakehouse
Nadat de juiste gegevens in het lakehouse zijn geplaatst, moet u de drie datasets als afzonderlijke Spark DataFrames inlezen in het notebook. De bestandspaden in deze code gebruiken de eerder gedefinieerde parameters.
df_items = (
spark.read.option("header", True)
.option("inferSchema", True)
.csv(f"{DATA_FOLDER}/raw/{ITEMS_FILE}")
.cache()
)
df_ratings = (
spark.read.option("header", True)
.option("inferSchema", True)
.csv(f"{DATA_FOLDER}/raw/{RATINGS_FILE}")
.cache()
)
df_users = (
spark.read.option("header", True)
.option("inferSchema", True)
.csv(f"{DATA_FOLDER}/raw/{USERS_FILE}")
.cache()
)
Stap 2: Experimentele gegevensanalyse uitvoeren
Onbewerkte gegevens weergeven
Verken de DataFrames met de opdracht display. Met deze opdracht kunt u dataframestatistieken op hoog niveau bekijken en begrijpen hoe verschillende gegevenssetkolommen zich met elkaar verhouden. Voordat u de gegevenssets verkent, gebruikt u deze code om de vereiste bibliotheken te importeren:
import pyspark.sql.functions as F
from pyspark.ml.feature import StringIndexer
import matplotlib.pyplot as plt
import seaborn as sns
color = sns.color_palette() # Adjusting plotting style
import pandas as pd # DataFrames
Gebruik deze code om te kijken naar het DataFrame dat de boekgegevens bevat:
display(df_items, summary=True)
Voeg een _item_id kolom toe voor later gebruik. De _item_id-waarde moet een geheel getal zijn voor aanbevelingsmodellen. Deze code maakt gebruik van StringIndexer om ITEM_ID_COL te transformeren naar indexen:
df_items = (
StringIndexer(inputCol=ITEM_ID_COL, outputCol="_item_id")
.setHandleInvalid("skip")
.fit(df_items)
.transform(df_items)
.withColumn("_item_id", F.col("_item_id").cast("int"))
)
Geef het DataFrame weer en controleer of de _item_id waarde monotonisch en opeenvolgend toeneemt, zoals verwacht:
display(df_items.sort(F.col("_item_id").desc()))
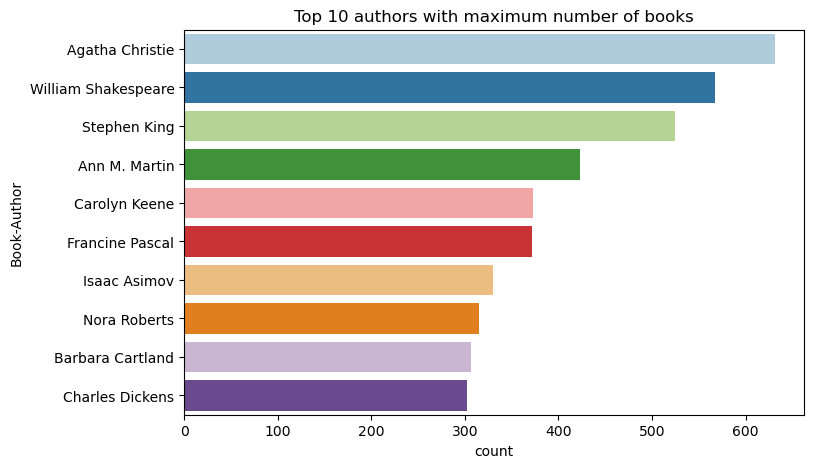
Gebruik deze code om de tien belangrijkste auteurs in aflopende volgorde te tekenen op aantal geschreven boeken. Agatha Christie is de toonaangevende auteur met meer dan 600 boeken, gevolgd door William Shakespeare.
df_books = df_items.toPandas() # Create a pandas DataFrame from the Spark DataFrame for visualization
plt.figure(figsize=(8,5))
sns.countplot(y="Book-Author",palette = 'Paired', data=df_books,order=df_books['Book-Author'].value_counts().index[0:10])
plt.title("Top 10 authors with maximum number of books")
Geef vervolgens het DataFrame weer dat de gebruikersgegevens bevat:
display(df_users, summary=True)
Als een rij een ontbrekende User-ID waarde heeft, zet u die rij neer. Ontbrekende waarden in een aangepaste gegevensset veroorzaken geen problemen.
df_users = df_users.dropna(subset=(USER_ID_COL))
display(df_users, summary=True)
Voeg een _user_id kolom toe voor later gebruik. Voor aanbevelingsmodellen moet de _user_id waarde een geheel getal zijn. In het volgende codevoorbeeld wordt StringIndexer gebruikt om USER_ID_COL te transformeren naar indexen.
De gegevensset van het boek heeft al een User-ID-kolom voor gehele getallen. Het toevoegen van een _user_id kolom voor compatibiliteit met verschillende gegevenssets maakt dit voorbeeld echter robuuster. Gebruik deze code om de kolom _user_id toe te voegen:
df_users = (
StringIndexer(inputCol=USER_ID_COL, outputCol="_user_id")
.setHandleInvalid("skip")
.fit(df_users)
.transform(df_users)
.withColumn("_user_id", F.col("_user_id").cast("int"))
)
display(df_users.sort(F.col("_user_id").desc()))
Gebruik deze code om de classificatiegegevens weer te geven:
display(df_ratings, summary=True)
Haal de afzonderlijke classificaties op en sla deze op voor later gebruik in een lijst met de naam ratings:
ratings = [i[0] for i in df_ratings.select(RATING_COL).distinct().collect()]
print(ratings)
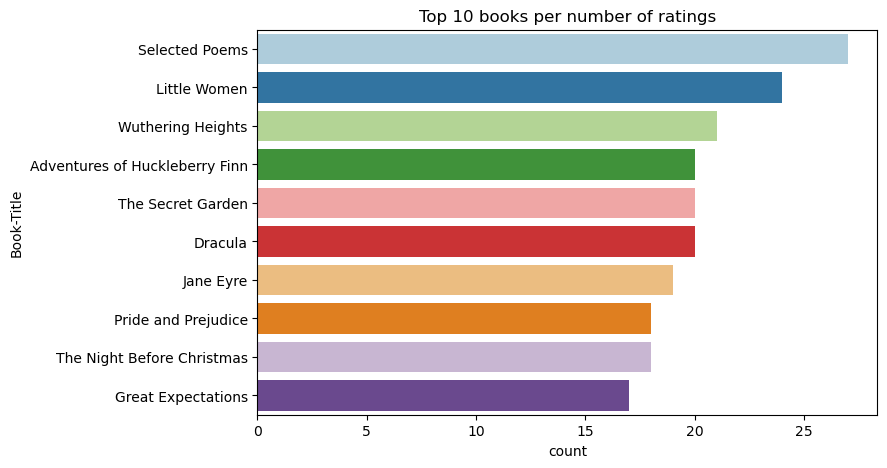
Gebruik deze code om de top 10 boeken met de hoogste waarderingen weer te geven:
plt.figure(figsize=(8,5))
sns.countplot(y="Book-Title",palette = 'Paired',data= df_books, order=df_books['Book-Title'].value_counts().index[0:10])
plt.title("Top 10 books per number of ratings")
Volgens de beoordelingen is Geselecteerde gedichten het populairste boek. Adventures of Huckleberry Finn, The Secret Gardenen Dracula dezelfde waardering hebben.
Gegevens samenvoegen
Voeg de drie DataFrames samen in één DataFrame voor een uitgebreidere analyse:
df_all = df_ratings.join(df_users, USER_ID_COL, "inner").join(
df_items, ITEM_ID_COL, "inner"
)
df_all_columns = [
c for c in df_all.columns if c not in ["_user_id", "_item_id", RATING_COL]
]
# Reorder the columns to ensure that _user_id, _item_id, and Book-Rating are the first three columns
df_all = (
df_all.select(["_user_id", "_item_id", RATING_COL] + df_all_columns)
.withColumn("id", F.monotonically_increasing_id())
.cache()
)
display(df_all)
Gebruik deze code om het aantal afzonderlijke gebruikers, boeken en interacties weer te geven:
print(f"Total Users: {df_users.select('_user_id').distinct().count()}")
print(f"Total Items: {df_items.select('_item_id').distinct().count()}")
print(f"Total User-Item Interactions: {df_all.count()}")
De populairste items berekenen en uitzetten
Gebruik deze code om de tien populairste boeken te berekenen en weer te geven:
# Compute top popular products
df_top_items = (
df_all.groupby(["_item_id"])
.count()
.join(df_items, "_item_id", "inner")
.sort(["count"], ascending=[0])
)
# Find top <topn> popular items
topn = 10
pd_top_items = df_top_items.limit(topn).toPandas()
pd_top_items.head(10)
Fooi
Gebruik de <topn> waarde voor populaire of secties met aanbevolen aanbevelingen.
# Plot top <topn> items
f, ax = plt.subplots(figsize=(10, 5))
plt.xticks(rotation="vertical")
sns.barplot(y=ITEM_INFO_COL, x="count", data=pd_top_items)
ax.tick_params(axis='x', rotation=45)
plt.xlabel("Number of Ratings for the Item")
plt.show()

Trainings- en testgegevenssets voorbereiden
De ALS-matrix vereist enige gegevensvoorbereiding vóór de training. Gebruik dit codevoorbeeld om de gegevens voor te bereiden. De code voert deze acties uit:
- Cast de classificatiekolom naar het juiste type
- Voorbeeld van de trainingsgegevens met gebruikersbeoordelingen
- Gegevens splitsen in trainings- en testdatasets
if IS_SAMPLE:
# Must sort by '_user_id' before performing limit to ensure that ALS works normally
# If training and test datasets have no common _user_id, ALS will fail
df_all = df_all.sort("_user_id").limit(SAMPLE_ROWS)
# Cast the column into the correct type
df_all = df_all.withColumn(RATING_COL, F.col(RATING_COL).cast("float"))
# Using a fraction between 0 and 1 returns the approximate size of the dataset; for example, 0.8 means 80% of the dataset
# Rating = 0 means the user didn't rate the item, so it can't be used for training
# We use the 80% of the dataset with rating > 0 as the training dataset
fractions_train = {0: 0}
fractions_test = {0: 0}
for i in ratings:
if i == 0:
continue
fractions_train[i] = 0.8
fractions_test[i] = 1
# Training dataset
train = df_all.sampleBy(RATING_COL, fractions=fractions_train)
# Join with leftanti will select all rows from df_all with rating > 0 and not in the training dataset; for example, the remaining 20% of the dataset
# test dataset
test = df_all.join(train, on="id", how="leftanti").sampleBy(
RATING_COL, fractions=fractions_test
)
Sparsity verwijst naar sparse feedbackgegevens, waarmee overeenkomsten in de interesses van gebruikers niet kunnen worden geïdentificeerd. Gebruik deze code om de spaarzaamheid van de gegevensset te berekenen voor een beter begrip van zowel de gegevens als het huidige probleem:
# Compute the sparsity of the dataset
def get_mat_sparsity(ratings):
# Count the total number of ratings in the dataset - used as numerator
count_nonzero = ratings.select(RATING_COL).count()
print(f"Number of rows: {count_nonzero}")
# Count the total number of distinct user_id and distinct product_id - used as denominator
total_elements = (
ratings.select("_user_id").distinct().count()
* ratings.select("_item_id").distinct().count()
)
# Calculate the sparsity by dividing the numerator by the denominator
sparsity = (1.0 - (count_nonzero * 1.0) / total_elements) * 100
print("The ratings DataFrame is ", "%.4f" % sparsity + "% sparse.")
get_mat_sparsity(df_all)
# Check the ID range
# ALS supports only values in the integer range
print(f"max user_id: {df_all.agg({'_user_id': 'max'}).collect()[0][0]}")
print(f"max user_id: {df_all.agg({'_item_id': 'max'}).collect()[0][0]}")
Stap 3: Het model ontwikkelen en trainen
Train een ALS-model om gebruikers persoonlijke aanbevelingen te geven.
Het model definiëren
Spark ML biedt een handige API voor het bouwen van het ALS-model. Het model verwerkt echter niet op betrouwbare wijze problemen zoals gegevensschaarste en het cold start-probleem (het doen van aanbevelingen wanneer de gebruikers of items nieuw zijn). Om de modelprestaties te verbeteren, combineert u kruisvalidatie en automatische afstemming van hyperparameters.
Gebruik deze code om de bibliotheken te importeren die vereist zijn voor modeltraining en -evaluatie:
# Import Spark required libraries
from pyspark.ml.evaluation import RegressionEvaluator
from pyspark.ml.recommendation import ALS
from pyspark.ml.tuning import ParamGridBuilder, CrossValidator, TrainValidationSplit
# Specify the training parameters
num_epochs = 1 # Number of epochs; here we use 1 to reduce the training time
rank_size_list = [64] # The values of rank in ALS for tuning
reg_param_list = [0.01, 0.1] # The values of regParam in ALS for tuning
model_tuning_method = "TrainValidationSplit" # TrainValidationSplit or CrossValidator
# Build the recommendation model by using ALS on the training data
# We set the cold start strategy to 'drop' to ensure that we don't get NaN evaluation metrics
als = ALS(
maxIter=num_epochs,
userCol="_user_id",
itemCol="_item_id",
ratingCol=RATING_COL,
coldStartStrategy="drop",
implicitPrefs=False,
nonnegative=True,
)
Modelhyperparameters afstemmen
In het volgende codevoorbeeld wordt een parameterraster samengesteld om te zoeken naar de hyperparameters. De code maakt ook een regressie-evaluator die gebruikmaakt van de RMSE (root-mean-square error) als de metrische evaluatiewaarde:
# Construct a grid search to select the best values for the training parameters
param_grid = (
ParamGridBuilder()
.addGrid(als.rank, rank_size_list)
.addGrid(als.regParam, reg_param_list)
.build()
)
print("Number of models to be tested: ", len(param_grid))
# Define the evaluator and set the loss function to the RMSE
evaluator = RegressionEvaluator(
metricName="rmse", labelCol=RATING_COL, predictionCol="prediction"
)
In het volgende codevoorbeeld worden verschillende methoden voor het afstemmen van modellen gestart op basis van de vooraf geconfigureerde parameters. Zie ML Tuning: modelselectie en hyperparameterafstemming op de Apache Spark-website voor meer informatie over het afstemmen van modellen.
# Build cross-validation by using CrossValidator and TrainValidationSplit
if model_tuning_method == "CrossValidator":
tuner = CrossValidator(
estimator=als,
estimatorParamMaps=param_grid,
evaluator=evaluator,
numFolds=5,
collectSubModels=True,
)
elif model_tuning_method == "TrainValidationSplit":
tuner = TrainValidationSplit(
estimator=als,
estimatorParamMaps=param_grid,
evaluator=evaluator,
# 80% of the training data will be used for training; 20% for validation
trainRatio=0.8,
collectSubModels=True,
)
else:
raise ValueError(f"Unknown model_tuning_method: {model_tuning_method}")
Het model evalueren
U moet modules evalueren op basis van de testgegevens. Een goed getraind model moet hoge metrische gegevens over de gegevensset hebben.
Een overgepast model heeft mogelijk een toename van de grootte van de trainingsgegevens nodig, of een vermindering van een aantal redundante functies. De modelarchitectuur moet mogelijk worden gewijzigd of de parameters moeten mogelijk worden aangepast.
Notitie
Een negatieve R-kwadraatswaarde geeft aan dat het getrainde model slechter presteert dan een horizontale rechte lijn. Deze bevindingen suggereren dat het getrainde model de gegevens niet verklaart.
Gebruik deze code om een evaluatiefunctie te definiëren:
def evaluate(model, data, verbose=0):
"""
Evaluate the model by computing rmse, mae, r2, and variance over the data.
"""
predictions = model.transform(data).withColumn(
"prediction", F.col("prediction").cast("double")
)
if verbose > 1:
# Show 10 predictions
predictions.select("_user_id", "_item_id", RATING_COL, "prediction").limit(
10
).show()
# Initialize the regression evaluator
evaluator = RegressionEvaluator(predictionCol="prediction", labelCol=RATING_COL)
_evaluator = lambda metric: evaluator.setMetricName(metric).evaluate(predictions)
rmse = _evaluator("rmse")
mae = _evaluator("mae")
r2 = _evaluator("r2")
var = _evaluator("var")
if verbose > 0:
print(f"RMSE score = {rmse}")
print(f"MAE score = {mae}")
print(f"R2 score = {r2}")
print(f"Explained variance = {var}")
return predictions, (rmse, mae, r2, var)
Het experiment bijhouden met behulp van MLflow
Gebruik MLflow om alle experimenten bij te houden en parameters, metrische gegevens en modellen te registreren. Gebruik deze code om modeltraining en -evaluatie te starten:
from mlflow.models.signature import infer_signature
with mlflow.start_run(run_name="als"):
# Train models
models = tuner.fit(train)
best_metrics = {"RMSE": 10e6, "MAE": 10e6, "R2": 0, "Explained variance": 0}
best_index = 0
# Evaluate models
# Log models, metrics, and parameters
for idx, model in enumerate(models.subModels):
with mlflow.start_run(nested=True, run_name=f"als_{idx}") as run:
print("\nEvaluating on test data:")
print(f"subModel No. {idx + 1}")
predictions, (rmse, mae, r2, var) = evaluate(model, test, verbose=1)
signature = infer_signature(
train.select(["_user_id", "_item_id"]),
predictions.select(["_user_id", "_item_id", "prediction"]),
)
print("log model:")
mlflow.spark.log_model(
model,
f"{EXPERIMENT_NAME}-alsmodel",
signature=signature,
registered_model_name=f"{EXPERIMENT_NAME}-alsmodel",
dfs_tmpdir="Files/spark",
)
print("log metrics:")
current_metric = {
"RMSE": rmse,
"MAE": mae,
"R2": r2,
"Explained variance": var,
}
mlflow.log_metrics(current_metric)
if rmse < best_metrics["RMSE"]:
best_metrics = current_metric
best_index = idx
print("log parameters:")
mlflow.log_params(
{
"subModel_idx": idx,
"num_epochs": num_epochs,
"rank_size_list": rank_size_list,
"reg_param_list": reg_param_list,
"model_tuning_method": model_tuning_method,
"DATA_FOLDER": DATA_FOLDER,
}
)
# Log the best model and related metrics and parameters to the parent run
mlflow.spark.log_model(
models.subModels[best_index],
f"{EXPERIMENT_NAME}-alsmodel",
signature=signature,
registered_model_name=f"{EXPERIMENT_NAME}-alsmodel",
dfs_tmpdir="Files/spark",
)
mlflow.log_metrics(best_metrics)
mlflow.log_params(
{
"subModel_idx": idx,
"num_epochs": num_epochs,
"rank_size_list": rank_size_list,
"reg_param_list": reg_param_list,
"model_tuning_method": model_tuning_method,
"DATA_FOLDER": DATA_FOLDER,
}
)
Selecteer het experiment met de naam aisample-recommendation in uw werkruimte om de vastgelegde gegevens voor de trainingsuitvoering weer te geven. Als u de naam van het experiment hebt gewijzigd, selecteert u het experiment met de nieuwe naam. De vastgelegde informatie lijkt op deze afbeelding:

Stap 4: Het uiteindelijke model laden voor scoren en voorspellingen doen
Nadat u de modeltraining hebt voltooid en het beste model hebt geselecteerd, laadt u het model voor evalueren (ook wel inferentie genoemd). Met deze code wordt het model geladen en worden voorspellingen gebruikt om de tien beste boeken voor elke gebruiker aan te bevelen:
# Load the best model
# MLflow uses PipelineModel to wrap the original model, so we extract the original ALSModel from the stages
model_uri = f"models:/{EXPERIMENT_NAME}-alsmodel/1"
loaded_model = mlflow.spark.load_model(model_uri, dfs_tmpdir="Files/spark").stages[-1]
# Generate top 10 book recommendations for each user
userRecs = loaded_model.recommendForAllUsers(10)
# Represent the recommendations in an interpretable format
userRecs = (
userRecs.withColumn("rec_exp", F.explode("recommendations"))
.select("_user_id", F.col("rec_exp._item_id"), F.col("rec_exp.rating"))
.join(df_items.select(["_item_id", "Book-Title"]), on="_item_id")
)
userRecs.limit(10).show()
De uitvoer lijkt op deze tabel:
| _item_id | _user_id | beoordeling | Book-Title |
|---|---|---|---|
| 44865 | 7 | 7.9996786 | Lasher: Levens van ... |
| 786 | 7 | 6.2255826 | De D van de Pianoman... |
| 45330 | 7 | 4.980466 | Gemoedstoestand |
| 38960 | 7 | 4.980466 | Alles wat hij ooit wilde |
| 125415 | 7 | 4.505084 | Harry Potter en ... |
| 44939 | 7 | 4.3579073 | Taltos: Levens van ... |
| 175247 | 7 | 4.3579073 | De Bonesetter is ... |
| 170183 | 7 | 4.228735 | Het leven van de eenvoudige... |
| 88503 | 7 | 4.221206 | Eiland van de Blu... |
| 32894 | 7 | 3.9031885 | Winter Solstice |
De voorspellingen opslaan in het lakehouse
Gebruik deze code om de aanbevelingen terug te schrijven naar het lakehouse:
# Code to save userRecs into the lakehouse
userRecs.write.format("delta").mode("overwrite").save(
f"{DATA_FOLDER}/predictions/userRecs"
)