Zelfstudie: Een verloopvoorspellingsmodel maken, evalueren en beoordelen
In deze tutorial wordt een end-to-end voorbeeld gepresenteerd van een Synapse Data Science-workflow in Microsoft Fabric. In het scenario wordt een model gebouwd om te voorspellen of bankklanten al dan niet vertrekken. Het verlooppercentage, of het tarief van optrigering, omvat het tarief waarmee bankklanten hun bedrijf met de bank beëindigen.
In deze zelfstudie worden de volgende stappen behandeld:
- Aangepaste bibliotheken installeren
- De gegevens laden
- De gegevens begrijpen en verwerken via experimentele gegevensanalyse en het gebruik van de functie Fabric Data Wrangler weergeven
- Scikit-learn en LightGBM gebruiken om machine learning-modellen te trainen en experimenten bij te houden met de functies MLflow en Fabric Autologging.
- Het uiteindelijke machine learning-model evalueren en opslaan
- De modelprestaties weergeven met Power BI-visualisaties
Voorwaarden
Een Microsoft Fabric-abonnementophalen. Of meld u aan voor een gratis microsoft Fabric-proefversie.
Meld u aan bij Microsoft Fabric-.
Gebruik de ervaringswisselaar aan de linkerkant van de startpagina om over te schakelen naar Fabric.

- Maak indien nodig een Microsoft Fabric Lakehouse zoals beschreven in Een lakehouse maken in Microsoft Fabric.
Volg in een notitieblok
U kunt een van deze opties kiezen om bij te houden in een notitieboek:
- Open en voer het ingebouwde notebook uit.
- Upload uw notebook vanuit GitHub.
Het ingebouwde notebook openen
Het voorbeeld klantverloop notebook begeleidt deze zelfstudie.
Als u het voorbeeldnotitieblok voor deze zelfstudie wilt openen, volgt u de instructies in Uw systeem voorbereiden op zelfstudies voor gegevenswetenschap.
Zorg ervoor dat je een lakehouse koppelt aan de notebook voordat je begint met het uitvoeren van code.
Het notebook importeren vanuit GitHub
De AIsample - Bank Customer Churn.ipynb notebook begeleidt deze zelfstudie.
Als u het bijbehorende notitieblok voor deze zelfstudie wilt openen, volgt u de instructies in Uw systeem voorbereiden op zelfstudies voor gegevenswetenschap om het notebook in uw werkruimte te importeren.
Als u liever de code van deze pagina kopieert en plakt, kunt u een nieuw notitieblok maken.
Zorg ervoor dat u een lakehouse aan het notebook koppelt voordat u begint met het uitvoeren van code.
Stap 1: Aangepaste bibliotheken installeren
Voor het ontwikkelen van machine learning-modellen of ad-hocgegevensanalyse moet u mogelijk snel een aangepaste bibliotheek voor uw Apache Spark-sessie installeren. U hebt twee opties om bibliotheken te installeren.
- Gebruik de inline-installatiemogelijkheden (
%pipof%conda) van uw notitieblok om alleen een bibliotheek in uw huidige notitieblok te installeren. - U kunt ook een Fabric-omgeving maken, bibliotheken installeren uit openbare bronnen of aangepaste bibliotheken ernaar uploaden. Vervolgens kan uw werkruimtebeheerder de omgeving als standaard voor de werkruimte koppelen. Alle bibliotheken in de omgeving zijn vervolgens beschikbaar voor gebruik in notebooks en Spark-taakdefinities in de werkruimte. Zie een omgeving maken, configureren en gebruiken in Microsoft Fabricvoor meer informatie over omgevingen.
Voor deze zelfstudie gebruikt u %pip install om de imblearn-bibliotheek in uw notebook te installeren.
Notitie
De PySpark-kernel wordt opnieuw opgestart nadat %pip install wordt uitgevoerd. Installeer de benodigde bibliotheken voordat u andere cellen uitvoert.
# Use pip to install libraries
%pip install imblearn
Stap 2: de gegevens laden
De gegevensset in churn.csv bevat de verloopstatus van 10.000 klanten, samen met 14 kenmerken, waaronder:
- Kredietscore
- Geografische locatie (Duitsland, Frankrijk, Spanje)
- Geslacht (mannelijk, vrouwelijk)
- Leeftijd
- Dienstverband (aantal jaren dat de persoon klant was bij die bank)
- Saldo van rekening
- Geschat salaris
- Aantal producten dat een klant heeft gekocht via de bank
- Creditcardstatus (of een klant al dan niet een creditcard heeft)
- Status van actief lid (ongeacht of de persoon een actieve bankklant is)
De gegevensset bevat ook kolommen voor rijnummer, klant-id en achternaam van de klant. Waarden in deze kolommen mogen niet van invloed zijn op de beslissing van een klant om de bank te verlaten.
Een gebeurtenis voor het afsluiten van een bankrekening definieert het klantverloop voor die klant. De kolom van gegevensset Exited verwijst naar het afhaken van de klant. Omdat we weinig context hebben over deze kenmerken, hebben we geen achtergrondinformatie over de gegevensset nodig. We willen weten hoe deze kenmerken bijdragen aan de status van de Exited.
Van die 10.000 klanten verlieten slechts 2037 (ongeveer 20%) de bank. Vanwege de verhouding tussen klasse-onevenwichtigheid raden we aan synthetische gegevens te genereren. Verwarringsmatrixnauwkeurigheid heeft mogelijk geen relevantie voor onevenwichtige classificatie. We kunnen de nauwkeurigheid meten met behulp van het gebied onder de Precision-Recall curve (AUPRC).
- In deze tabel ziet u een voorbeeld van de
churn.csvgegevens:
| Klant-ID | Achternaam | Kredietscore | Geografie | Geslacht | Leeftijd | Ambtstermijn | Evenwicht | NumOfProducts | HasCrCard | IsActiefLid | Geschat Salaris | Uitgegaan |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 15634602 | Hargrave | 619 | Frankrijk | Vrouwelijk | 42 | 2 | 0.00 | 1 | 1 | 1 | 101348.88 | 1 |
| 15647311 | Heuvel | 608 | Spanje | Vrouwelijk | 41 | 1 | 83807.86 | 1 | 0 | 1 | 112542.58 | 0 |
De gegevensset downloaden en uploaden naar het lakehouse
Definieer deze parameters, zodat u dit notebook kunt gebruiken met verschillende gegevenssets:
IS_CUSTOM_DATA = False # If TRUE, the dataset has to be uploaded manually
IS_SAMPLE = False # If TRUE, use only SAMPLE_ROWS of data for training; otherwise, use all data
SAMPLE_ROWS = 5000 # If IS_SAMPLE is True, use only this number of rows for training
DATA_ROOT = "/lakehouse/default"
DATA_FOLDER = "Files/churn" # Folder with data files
DATA_FILE = "churn.csv" # Data file name
Met deze code wordt een openbaar beschikbare versie van de gegevensset gedownload en wordt die gegevensset vervolgens opgeslagen in een Fabric Lakehouse:
Belangrijk
Voeg een lakehouse toe aan het notebook voordat u het uitvoert. Als u dit niet doet, treedt er een fout op.
import os, requests
if not IS_CUSTOM_DATA:
# With an Azure Synapse Analytics blob, this can be done in one line
# Download demo data files into the lakehouse if they don't exist
remote_url = "https://synapseaisolutionsa.blob.core.windows.net/public/bankcustomerchurn"
file_list = ["churn.csv"]
download_path = "/lakehouse/default/Files/churn/raw"
if not os.path.exists("/lakehouse/default"):
raise FileNotFoundError(
"Default lakehouse not found, please add a lakehouse and restart the session."
)
os.makedirs(download_path, exist_ok=True)
for fname in file_list:
if not os.path.exists(f"{download_path}/{fname}"):
r = requests.get(f"{remote_url}/{fname}", timeout=30)
with open(f"{download_path}/{fname}", "wb") as f:
f.write(r.content)
print("Downloaded demo data files into lakehouse.")
Begin met het opnemen van de tijd die nodig is om het notebook uit te voeren.
# Record the notebook running time
import time
ts = time.time()
Onbewerkte gegevens lezen uit de lakehouse
Deze code leest onbewerkte gegevens uit de sectie Files van het lakehouse en voegt meer kolommen toe voor verschillende datumonderdelen. Voor het maken van de gepartitioneerde deltatabel wordt gebruikgemaakt van deze informatie.
df = (
spark.read.option("header", True)
.option("inferSchema", True)
.csv("Files/churn/raw/churn.csv")
.cache()
)
Een Pandas DataFrame maken op basis van de gegevensset
Met deze code wordt het Spark DataFrame geconverteerd naar een Pandas DataFrame, voor eenvoudigere verwerking en visualisatie:
df = df.toPandas()
Stap 3: Verkennende gegevensanalyse uitvoeren
Onbewerkte gegevens weergeven
Verken de onbewerkte gegevens met display, bereken enkele basisstatistieken en geef grafiekweergaven weer. U moet eerst de vereiste bibliotheken importeren voor gegevensvisualisatie, bijvoorbeeld seaborn-. Seaborn is een Bibliotheek voor gegevensvisualisatie in Python en biedt een interface op hoog niveau voor het bouwen van visuals op gegevensframes en matrices.
import seaborn as sns
sns.set_theme(style="whitegrid", palette="tab10", rc = {'figure.figsize':(9,6)})
import matplotlib.pyplot as plt
import matplotlib.ticker as mticker
from matplotlib import rc, rcParams
import numpy as np
import pandas as pd
import itertools
display(df, summary=True)
Data Wrangler gebruiken om initiële gegevens op te schonen
Start Data Wrangler rechtstreeks vanuit het notebook om pandas-dataframes te verkennen en te transformeren. Selecteer de vervolgkeuzelijst Data Wrangler op de horizontale werkbalk om door de geactiveerde Pandas DataFrames te bladeren die beschikbaar zijn voor bewerking. Selecteer het DataFrame dat u wilt openen in Data Wrangler.
Notitie
Data Wrangler kan niet worden geopend terwijl de notebook-kernel bezet is. De uitvoering van de cel moet voltooid zijn voordat u Data Wrangler start. Meer informatie over Data Wrangler.

Nadat Data Wrangler is gestart, wordt er een beschrijvend overzicht van het gegevenspaneel gegenereerd, zoals wordt weergegeven in de volgende afbeeldingen. Het overzicht bevat informatie over de dimensie van het DataFrame, eventuele ontbrekende waarden, enzovoort. U kunt Data Wrangler gebruiken om het script te genereren om de rijen met ontbrekende waarden, de dubbele rijen en de kolommen met specifieke namen te verwijderen. Vervolgens kunt u het script naar een cel kopiëren. In de volgende cel ziet u dat gekopieerde script.


def clean_data(df):
# Drop rows with missing data across all columns
df.dropna(inplace=True)
# Drop duplicate rows in columns: 'RowNumber', 'CustomerId'
df.drop_duplicates(subset=['RowNumber', 'CustomerId'], inplace=True)
# Drop columns: 'RowNumber', 'CustomerId', 'Surname'
df.drop(columns=['RowNumber', 'CustomerId', 'Surname'], inplace=True)
return df
df_clean = clean_data(df.copy())
Kenmerken bepalen
Deze code bepaalt de categorische, numerieke en doelkenmerken:
# Determine the dependent (target) attribute
dependent_variable_name = "Exited"
print(dependent_variable_name)
# Determine the categorical attributes
categorical_variables = [col for col in df_clean.columns if col in "O"
or df_clean[col].nunique() <=5
and col not in "Exited"]
print(categorical_variables)
# Determine the numerical attributes
numeric_variables = [col for col in df_clean.columns if df_clean[col].dtype != "object"
and df_clean[col].nunique() >5]
print(numeric_variables)
De samenvatting met vijf getallen weergeven
Boxplots gebruiken om het overzicht van vijf getallen weer te geven
- de minimale score
- eerste kwartiel
- mediaan
- derde kwartiel
- maximum score
voor de numerieke kenmerken.
df_num_cols = df_clean[numeric_variables]
sns.set(font_scale = 0.7)
fig, axes = plt.subplots(nrows = 2, ncols = 3, gridspec_kw = dict(hspace=0.3), figsize = (17,8))
fig.tight_layout()
for ax,col in zip(axes.flatten(), df_num_cols.columns):
sns.boxplot(x = df_num_cols[col], color='green', ax = ax)
# fig.suptitle('visualize and compare the distribution and central tendency of numerical attributes', color = 'k', fontsize = 12)
fig.delaxes(axes[1,2])
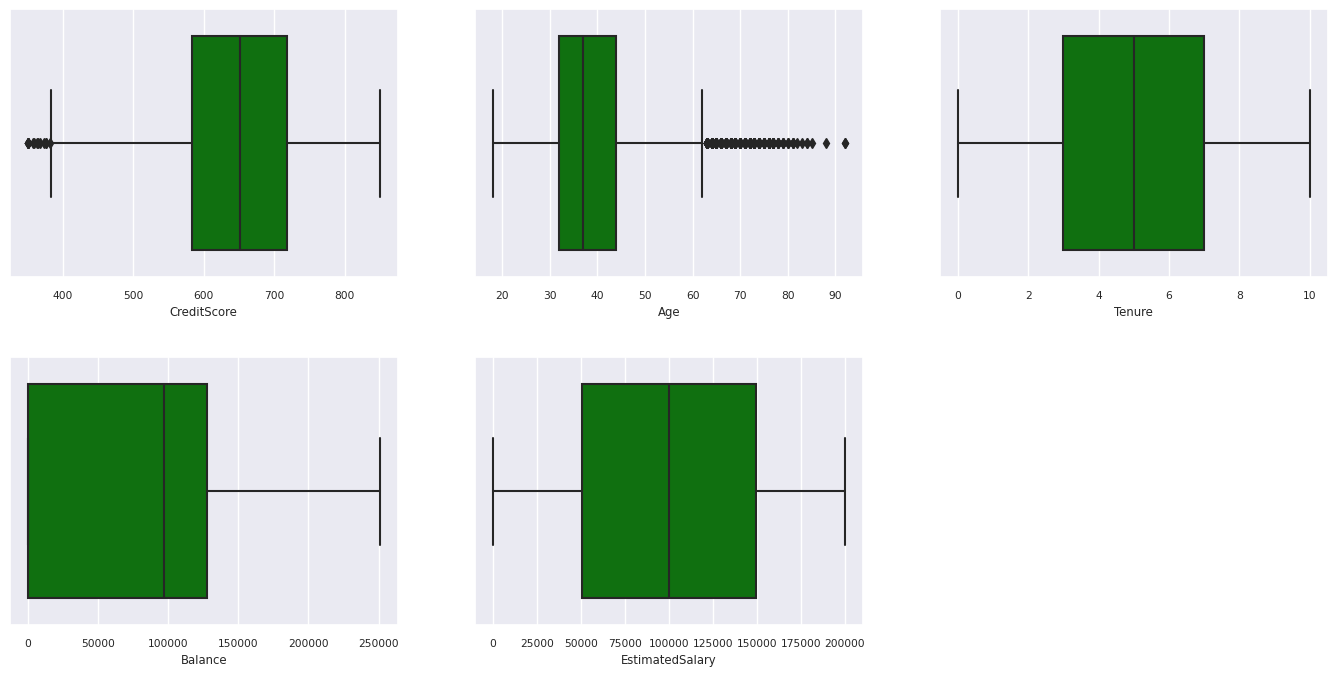
De distributie van afgesloten en niet-afgesloten klanten weergeven
De verdeling van vertrokken versus niet-vertrokken klanten tonen over de categorische kenmerken:
attr_list = ['Geography', 'Gender', 'HasCrCard', 'IsActiveMember', 'NumOfProducts', 'Tenure']
fig, axarr = plt.subplots(2, 3, figsize=(15, 4))
for ind, item in enumerate (attr_list):
sns.countplot(x = item, hue = 'Exited', data = df_clean, ax = axarr[ind%2][ind//2])
fig.subplots_adjust(hspace=0.7)
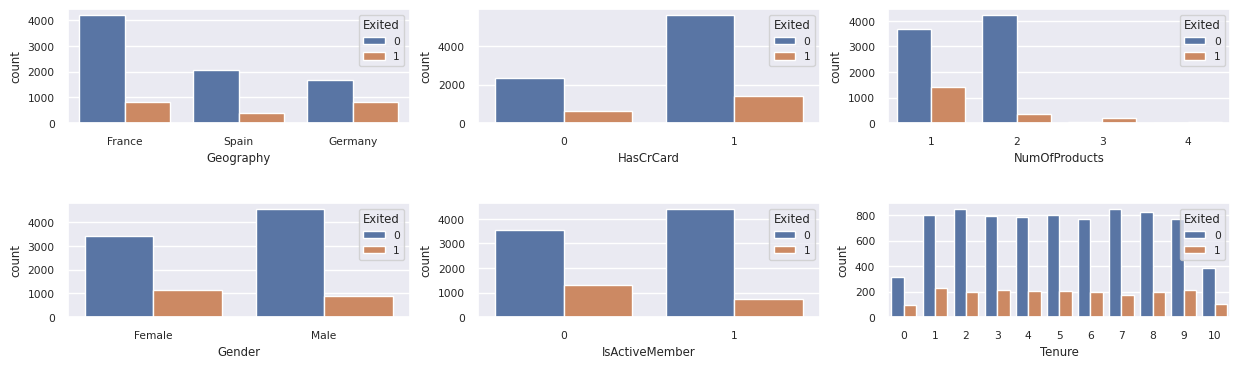
De verdeling van numerieke kenmerken weergeven
Gebruik een histogram om de frequentieverdeling van numerieke kenmerken weer te geven:
columns = df_num_cols.columns[: len(df_num_cols.columns)]
fig = plt.figure()
fig.set_size_inches(18, 8)
length = len(columns)
for i,j in itertools.zip_longest(columns, range(length)):
plt.subplot((length // 2), 3, j+1)
plt.subplots_adjust(wspace = 0.2, hspace = 0.5)
df_num_cols[i].hist(bins = 20, edgecolor = 'black')
plt.title(i)
# fig = fig.suptitle('distribution of numerical attributes', color = 'r' ,fontsize = 14)
plt.show()
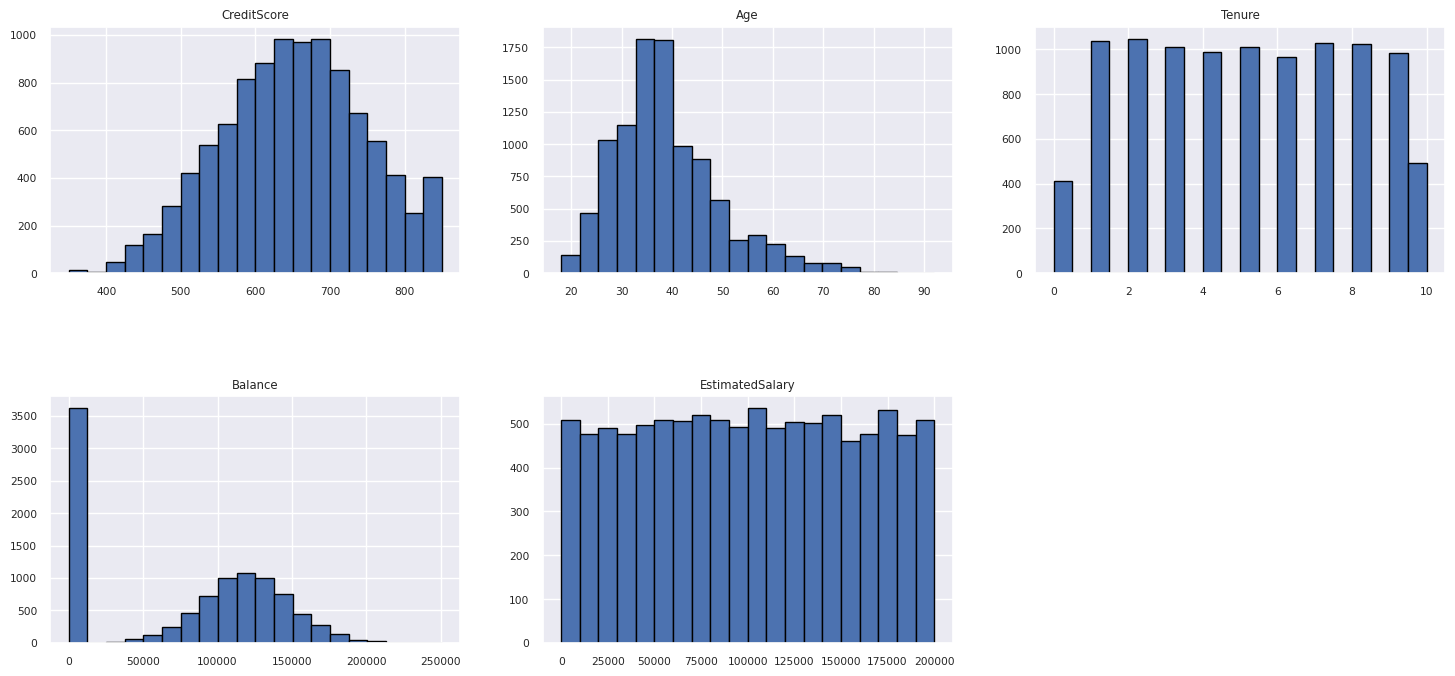
Functie-engineering uitvoeren
Met deze functie-engineering worden nieuwe kenmerken gegenereerd op basis van de huidige kenmerken:
df_clean["NewTenure"] = df_clean["Tenure"]/df_clean["Age"]
df_clean["NewCreditsScore"] = pd.qcut(df_clean['CreditScore'], 6, labels = [1, 2, 3, 4, 5, 6])
df_clean["NewAgeScore"] = pd.qcut(df_clean['Age'], 8, labels = [1, 2, 3, 4, 5, 6, 7, 8])
df_clean["NewBalanceScore"] = pd.qcut(df_clean['Balance'].rank(method="first"), 5, labels = [1, 2, 3, 4, 5])
df_clean["NewEstSalaryScore"] = pd.qcut(df_clean['EstimatedSalary'], 10, labels = [1, 2, 3, 4, 5, 6, 7, 8, 9, 10])
Data Wrangler gebruiken om one-hot codering uit te voeren
Gebruik dezelfde stappen als eerder besproken om de Data Wrangler te starten en voer one-hot codering uit met de Data Wrangler. In deze cel ziet u het gekopieerde gegenereerde script voor one-hot codering:


df_clean = pd.get_dummies(df_clean, columns=['Geography', 'Gender'])
Een deltatabel maken om het Power BI-rapport te genereren
table_name = "df_clean"
# Create a PySpark DataFrame from pandas
sparkDF=spark.createDataFrame(df_clean)
sparkDF.write.mode("overwrite").format("delta").save(f"Tables/{table_name}")
print(f"Spark DataFrame saved to delta table: {table_name}")
Samenvatting van waarnemingen van de verkennende gegevensanalyse
- De meeste klanten komen uit Frankrijk. Spanje heeft het laagste verloop, vergeleken met Frankrijk en Duitsland.
- De meeste klanten hebben creditcards
- Sommige klanten zijn allebei ouder dan 60 en hebben kredietscores onder de 400. Ze kunnen echter niet worden beschouwd als uitzonderingen
- Zeer weinig klanten hebben meer dan twee bankproducten
- Inactieve klanten hebben een hogere verloopsnelheid
- Geslachts- en dienstjaren hebben weinig invloed op de beslissing van een klant om een bankrekening te sluiten
Stap 4: Modeltraining en -tracering uitvoeren
Nu de gegevens zijn geïmplementeerd, kunt u het model definiëren. Pas willekeurige forest- en LightGBM-modellen toe in dit notebook.
Gebruik de scikit-learn- en LightGBM-bibliotheken om de modellen te implementeren, met een paar regels code. Gebruik daarnaast MLfLow en Fabric Autologging om de experimenten bij te houden.
Dit codevoorbeeld laadt de deltatabel uit het lakehouse. U kunt andere deltatabellen gebruiken die zelf het lakehouse als bron gebruiken.
SEED = 12345
df_clean = spark.read.format("delta").load("Tables/df_clean").toPandas()
Een experiment genereren voor het bijhouden en vastleggen van de modellen met behulp van MLflow
In deze sectie ziet u hoe u een experiment genereert en geeft u het model en de trainingsparameters en de scoregegevens op. Daarnaast ziet u hoe u de modellen traint, ze in een logboek opslaat en de getrainde modellen opslaat voor later gebruik.
import mlflow
# Set up the experiment name
EXPERIMENT_NAME = "sample-bank-churn-experiment" # MLflow experiment name
Met automatisch registreren worden zowel de invoerparameterwaarden als de metrische uitvoergegevens van een machine learning-model vastgelegd, terwijl dat model wordt getraind. Deze informatie wordt vervolgens geregistreerd bij uw werkruimte, waar de MLflow-API's of het bijbehorende experiment in uw werkruimte deze kunnen openen en visualiseren.
Als u klaar bent, lijkt uw experiment op deze afbeelding:

Alle experimenten met hun respectieve namen worden geregistreerd en u kunt de parameters en metrische prestatiegegevens bijhouden. Zie Autologging in Microsoft Fabricvoor meer informatie over automatisch aanmelden.
Specificaties voor experimenten en automatische logboeken instellen
mlflow.set_experiment(EXPERIMENT_NAME) # Use a date stamp to append to the experiment
mlflow.autolog(exclusive=False)
Scikit-learn en LightGBM importeren
# Import the required libraries for model training
from sklearn.model_selection import train_test_split
from lightgbm import LGBMClassifier
from sklearn.ensemble import RandomForestClassifier
from sklearn.metrics import accuracy_score, f1_score, precision_score, confusion_matrix, recall_score, roc_auc_score, classification_report
Trainings- en testgegevenssets voorbereiden
y = df_clean["Exited"]
X = df_clean.drop("Exited",axis=1)
# Train/test separation
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.20, random_state=SEED)
SMOTE toepassen op de trainingsgegevens
Onevenwichtige classificatie heeft een probleem, omdat er te weinig voorbeelden zijn van de minderheidsklasse voor een model om de beslissingsgrens effectief te leren. Om dit te doen, is Synthetic Minority Oversampling Technique (SMOTE) de meest gebruikte techniek om nieuwe steekproeven voor de minderheidsklasse te synthetiseren. Open SMOTE met de imblearn-bibliotheek die u in stap 1 hebt geïnstalleerd.
Pas SMOTE alleen toe op de trainingsgegevensset. U moet de testgegevensset in de oorspronkelijke onevenwichtige verdeling laten staan om een geldige benadering van de modelprestaties op de oorspronkelijke gegevens te krijgen. Dit experiment vertegenwoordigt de situatie in productie.
from collections import Counter
from imblearn.over_sampling import SMOTE
sm = SMOTE(random_state=SEED)
X_res, y_res = sm.fit_resample(X_train, y_train)
new_train = pd.concat([X_res, y_res], axis=1)
Zie SMOTE en Van willekeurige oversampling naar SMOTE en ADASYNvoor meer informatie. De onevenwichtige learn-website host deze resources.
Het model trainen
Gebruik Random Forest om het model te trainen, met een maximale diepte van vier en met vier functies:
mlflow.sklearn.autolog(registered_model_name='rfc1_sm') # Register the trained model with autologging
rfc1_sm = RandomForestClassifier(max_depth=4, max_features=4, min_samples_split=3, random_state=1) # Pass hyperparameters
with mlflow.start_run(run_name="rfc1_sm") as run:
rfc1_sm_run_id = run.info.run_id # Capture run_id for model prediction later
print("run_id: {}; status: {}".format(rfc1_sm_run_id, run.info.status))
# rfc1.fit(X_train,y_train) # Imbalanced training data
rfc1_sm.fit(X_res, y_res.ravel()) # Balanced training data
rfc1_sm.score(X_test, y_test)
y_pred = rfc1_sm.predict(X_test)
cr_rfc1_sm = classification_report(y_test, y_pred)
cm_rfc1_sm = confusion_matrix(y_test, y_pred)
roc_auc_rfc1_sm = roc_auc_score(y_res, rfc1_sm.predict_proba(X_res)[:, 1])
Gebruik Random Forest om het model te trainen, met een maximale diepte van acht en met zes functies:
mlflow.sklearn.autolog(registered_model_name='rfc2_sm') # Register the trained model with autologging
rfc2_sm = RandomForestClassifier(max_depth=8, max_features=6, min_samples_split=3, random_state=1) # Pass hyperparameters
with mlflow.start_run(run_name="rfc2_sm") as run:
rfc2_sm_run_id = run.info.run_id # Capture run_id for model prediction later
print("run_id: {}; status: {}".format(rfc2_sm_run_id, run.info.status))
# rfc2.fit(X_train,y_train) # Imbalanced training data
rfc2_sm.fit(X_res, y_res.ravel()) # Balanced training data
rfc2_sm.score(X_test, y_test)
y_pred = rfc2_sm.predict(X_test)
cr_rfc2_sm = classification_report(y_test, y_pred)
cm_rfc2_sm = confusion_matrix(y_test, y_pred)
roc_auc_rfc2_sm = roc_auc_score(y_res, rfc2_sm.predict_proba(X_res)[:, 1])
Train het model met LightGBM:
# lgbm_model
mlflow.lightgbm.autolog(registered_model_name='lgbm_sm') # Register the trained model with autologging
lgbm_sm_model = LGBMClassifier(learning_rate = 0.07,
max_delta_step = 2,
n_estimators = 100,
max_depth = 10,
eval_metric = "logloss",
objective='binary',
random_state=42)
with mlflow.start_run(run_name="lgbm_sm") as run:
lgbm1_sm_run_id = run.info.run_id # Capture run_id for model prediction later
# lgbm_sm_model.fit(X_train,y_train) # Imbalanced training data
lgbm_sm_model.fit(X_res, y_res.ravel()) # Balanced training data
y_pred = lgbm_sm_model.predict(X_test)
accuracy = accuracy_score(y_test, y_pred)
cr_lgbm_sm = classification_report(y_test, y_pred)
cm_lgbm_sm = confusion_matrix(y_test, y_pred)
roc_auc_lgbm_sm = roc_auc_score(y_res, lgbm_sm_model.predict_proba(X_res)[:, 1])
Het experimentartefact weergeven om modelprestaties bij te houden
De uitvoeringen van het experiment worden automatisch opgeslagen in het artefact van het experiment. U vindt dat artefact in de werkruimte. Een artefactnaam is gebaseerd op de naam die wordt gebruikt om het experiment in te stellen. Alle getrainde modellen, hun uitvoeringen, prestatiegegevens en modelparameters worden geregistreerd op de experimentpagina.
Uw experimenten weergeven:
- Selecteer uw werkruimte in het linkerdeelvenster.
- Zoek en selecteer in dit geval de naam van het experiment sample-bank-churn-experiment.
Stap 5: Het uiteindelijke machine learning-model evalueren en opslaan
Open het opgeslagen experiment in de werkruimte om het beste model te selecteren en op te slaan:
# Define run_uri to fetch the model
# MLflow client: mlflow.model.url, list model
load_model_rfc1_sm = mlflow.sklearn.load_model(f"runs:/{rfc1_sm_run_id}/model")
load_model_rfc2_sm = mlflow.sklearn.load_model(f"runs:/{rfc2_sm_run_id}/model")
load_model_lgbm1_sm = mlflow.lightgbm.load_model(f"runs:/{lgbm1_sm_run_id}/model")
De prestaties van de opgeslagen modellen op de testgegevensset beoordelen
ypred_rfc1_sm = load_model_rfc1_sm.predict(X_test) # Random forest with maximum depth of 4 and 4 features
ypred_rfc2_sm = load_model_rfc2_sm.predict(X_test) # Random forest with maximum depth of 8 and 6 features
ypred_lgbm1_sm = load_model_lgbm1_sm.predict(X_test) # LightGBM
Waar-/fout-positieven/negatieven weergeven met behulp van een verwarringsmatrix
Als u de nauwkeurigheid van de classificatie wilt evalueren, maakt u een script waarmee de verwarringsmatrix wordt uitplot. U kunt ook een verwarringsmatrix tekenen met behulp van SynapseML-hulpprogramma's, zoals wordt weergegeven in het voorbeeld van fraudedetectie.
def plot_confusion_matrix(cm, classes,
normalize=False,
title='Confusion matrix',
cmap=plt.cm.Blues):
print(cm)
plt.figure(figsize=(4,4))
plt.rcParams.update({'font.size': 10})
plt.imshow(cm, interpolation='nearest', cmap=cmap)
plt.title(title)
plt.colorbar()
tick_marks = np.arange(len(classes))
plt.xticks(tick_marks, classes, rotation=45, color="blue")
plt.yticks(tick_marks, classes, color="blue")
fmt = '.2f' if normalize else 'd'
thresh = cm.max() / 2.
for i, j in itertools.product(range(cm.shape[0]), range(cm.shape[1])):
plt.text(j, i, format(cm[i, j], fmt),
horizontalalignment="center",
color="red" if cm[i, j] > thresh else "black")
plt.tight_layout()
plt.ylabel('True label')
plt.xlabel('Predicted label')
Maak een verwarringsmatrix voor de willekeurige forestclassificatie, met een maximale diepte van vier, met vier functies:
cfm = confusion_matrix(y_test, y_pred=ypred_rfc1_sm)
plot_confusion_matrix(cfm, classes=['Non Churn','Churn'],
title='Random Forest with max depth of 4')
tn, fp, fn, tp = cfm.ravel()
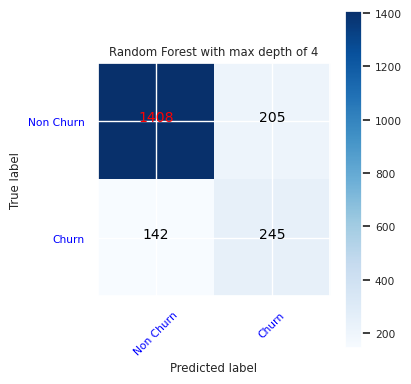
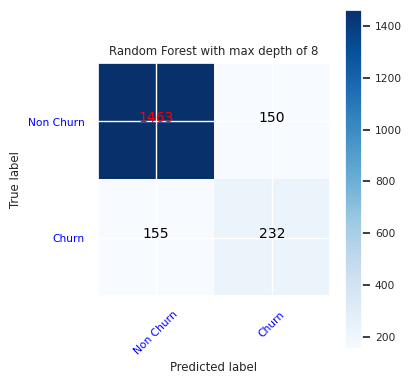
Maak een verwarringsmatrix voor de willekeurige forestclassificatie met een maximale diepte van acht, met zes functies:
cfm = confusion_matrix(y_test, y_pred=ypred_rfc2_sm)
plot_confusion_matrix(cfm, classes=['Non Churn','Churn'],
title='Random Forest with max depth of 8')
tn, fp, fn, tp = cfm.ravel()
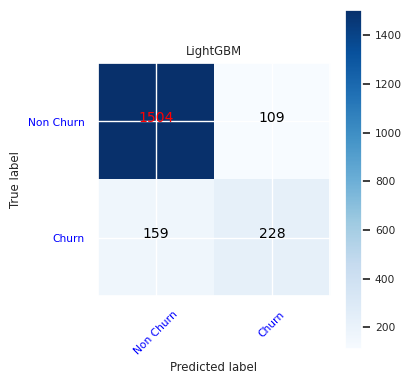
Maak een verwarringsmatrix voor LightGBM:
cfm = confusion_matrix(y_test, y_pred=ypred_lgbm1_sm)
plot_confusion_matrix(cfm, classes=['Non Churn','Churn'],
title='LightGBM')
tn, fp, fn, tp = cfm.ravel()
Resultaten opslaan voor Power BI
Sla het deltaframe op in het lakehouse om de voorspellingsresultaten van het model te verplaatsen naar een Power BI-visualisatie.
df_pred = X_test.copy()
df_pred['y_test'] = y_test
df_pred['ypred_rfc1_sm'] = ypred_rfc1_sm
df_pred['ypred_rfc2_sm'] =ypred_rfc2_sm
df_pred['ypred_lgbm1_sm'] = ypred_lgbm1_sm
table_name = "df_pred_results"
sparkDF=spark.createDataFrame(df_pred)
sparkDF.write.mode("overwrite").format("delta").option("overwriteSchema", "true").save(f"Tables/{table_name}")
print(f"Spark DataFrame saved to delta table: {table_name}")
Stap 6: Toegang tot visualisaties in Power BI
Open de opgeslagen tabel in Power BI:
- Selecteer aan de linkerkant OneLake.
- Selecteer het lakehouse dat u aan dit notitieblok hebt toegevoegd.
- Selecteer in de sectie Dit Lakehouse- openen openen.
- Selecteer op het lint nieuw semantisch model. Selecteer
df_pred_resultsen selecteer vervolgens Bevestig om een nieuw semantisch Power BI-model te maken dat is gekoppeld aan de voorspellingen. - Open een nieuw semantisch model. U vindt deze in OneLake.
- Selecteer Nieuw rapport maken onder bestand in de hulpprogramma's boven aan de pagina met semantische modellen om de pagina voor het ontwerpen van Power BI-rapporten te openen.
In de volgende schermopname ziet u enkele voorbeeldvisualisaties. In het gegevensvenster ziet u de deltatabellen en -kolommen die u uit een tabel kunt selecteren. Nadat u de juiste categorieas (x) en waardeas (y) hebt geselecteerd, kunt u de filters en functies kiezen, bijvoorbeeld som of gemiddelde van de tabelkolom.
Notitie
In deze schermopname beschrijft het geïllustreerde voorbeeld de analyse van de opgeslagen voorspellingsresultaten in Power BI:

Voor een echte use-case voor klantverloop heeft de gebruiker echter mogelijk een uitgebreidere set vereisten van de visualisaties nodig om te maken, op basis van expertise op het gebied van het onderwerp en wat het bedrijf en het bedrijfsanalyseteam en het bedrijf hebben gestandaardiseerd als metrische gegevens.
Het Power BI-rapport laat zien dat klanten die meer dan twee van de bankproducten gebruiken, een hoger verloop hebben. Maar weinig klanten hadden meer dan twee producten. (Zie de plot in het deelvenster linksonder.) De bank moet meer gegevens verzamelen, maar moet ook andere functies onderzoeken die correleren met meer producten.
Bankklanten in Duitsland hebben een hoger verloop in vergelijking met klanten in Frankrijk en Spanje. (Zie de plot in het deelvenster rechtsonder). Op basis van de rapportresultaten kan een onderzoek naar de factoren die klanten aanmoedigen om te vertrekken, helpen.
Er zijn meer middelgrote klanten (tussen 25 en 45). Klanten tussen de 45 en 60 jaar hebben de neiging om meer te vertrekken.
Ten slotte zouden klanten met lagere kredietscores de bank waarschijnlijk verlaten voor andere financiële instellingen. De bank moet manieren verkennen om klanten met lagere kredietscores en rekeningsaldi aan te moedigen om bij de bank te blijven.
# Determine the entire runtime
print(f"Full run cost {int(time.time() - ts)} seconds.")