Azure Synapse Analytics configureren in een kopieeractiviteit
In dit artikel wordt beschreven hoe u de kopieeractiviteit in de gegevenspijplijn gebruikt om gegevens van en naar Azure Synapse Analytics te kopiëren.
Ondersteunde configuratie
Voor de configuratie van elk tabblad onder kopieeractiviteit gaat u respectievelijk naar de volgende secties.
Algemeen
Raadpleeg de richtlijnen voor algemene instellingen voor het configureren van het tabblad Algemene instellingen.
Bron
De volgende eigenschappen worden ondersteund voor Azure Synapse Analytics op het tabblad Bron van een kopieeractiviteit.

De volgende eigenschappen zijn vereist:
Gegevensarchieftype: Selecteer Extern.
Verbinding maken ion: Selecteer een Azure Synapse Analytics-verbinding in de lijst met verbindingen. Als de verbinding niet bestaat, maakt u een nieuwe Azure Synapse Analytics-verbinding door Nieuw te selecteren.
Verbinding maken iontype: Selecteer Azure Synapse Analytics.
Query gebruiken: u kunt de procedure Tabel, Query of Opgeslagen kiezen om de brongegevens te lezen. In de volgende lijst wordt de configuratie van elke instelling beschreven:
Tabel: Gegevens lezen uit de tabel die u hebt opgegeven in Tabel als u deze knop selecteert. Selecteer de tabel in de vervolgkeuzelijst of selecteer Bewerken om de schema- en tabelnaam handmatig in te voeren.

Query: Geef de aangepaste SQL-query op om gegevens te lezen. Een voorbeeld is
select * from MyTable. Of selecteer het potloodpictogram dat u wilt bewerken in de code-editor.
Opgeslagen procedure: gebruik de opgeslagen procedure waarmee gegevens uit de brontabel worden gelezen. De laatste SQL-instructie moet een SELECT-instructie zijn in de opgeslagen procedure.
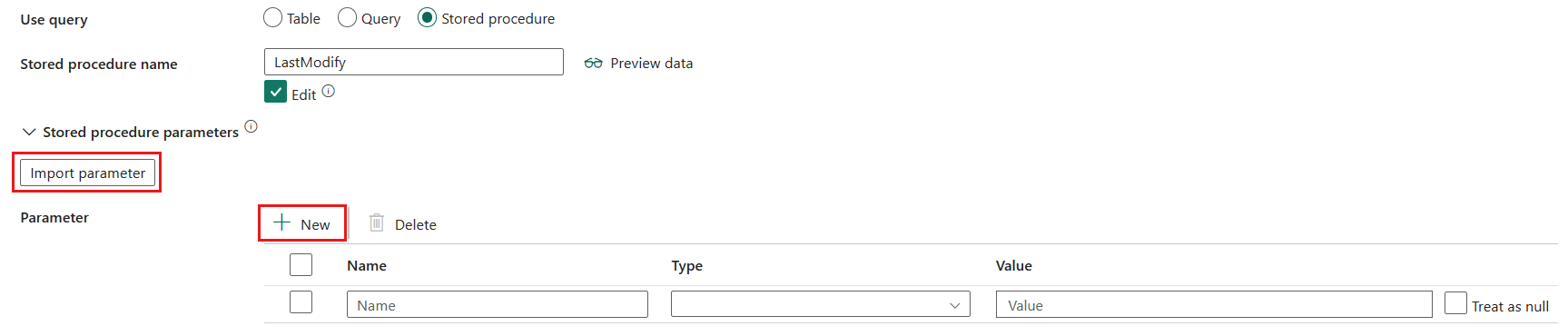
- Naam van opgeslagen procedure: selecteer de opgeslagen procedure of geef de naam van de opgeslagen procedure handmatig op wanneer u Bewerken selecteert.
- Opgeslagen procedureparameters: Selecteer Importparameters om de parameter te importeren in de opgegeven opgeslagen procedure of voeg parameters toe voor de opgeslagen procedure door + Nieuw te selecteren. Toegestane waarden zijn naam- of waardeparen. Namen en hoofdletters van parameters moeten overeenkomen met de namen en hoofdletters van de opgeslagen procedureparameters.

Onder Geavanceerd kunt u de volgende velden opgeven:
Time-out voor query 's (minuten):geef de time-out op voor het uitvoeren van queryopdrachten. De standaardwaarde is 120 minuten. Als een parameter voor deze eigenschap is ingesteld, zijn toegestane waarden tijdspanne, zoals '02:00:00' (120 minuten).
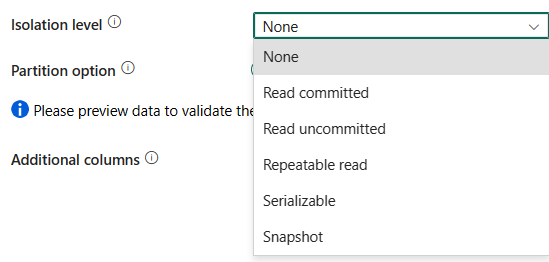
Isolatieniveau: hiermee geeft u het gedrag voor transactievergrendeling voor de SQL-bron op. De toegestane waarden zijn: None, Read commit, Read uncommitted, Repeatable read, Serializable of Snapshot. Als dit niet is opgegeven, wordt geen isolatieniveau gebruikt. Raadpleeg IsolationLevel Enum voor meer informatie.
Partitieoptie: Geef de opties voor gegevenspartitionering op die worden gebruikt voor het laden van gegevens uit Azure Synapse Analytics. Toegestane waarden zijn: Geen (standaard), Fysieke partities van tabel en Dynamisch bereik. Wanneer een partitieoptie is ingeschakeld (dat wil niet geen), wordt de mate van parallelle uitvoering om gegevens van een Azure Synapse Analytics gelijktijdig te laden, beheerd door de instelling voor parallelle kopieerbewerkingen voor de kopieeractiviteit.
Geen: kies deze instelling om geen partitie te gebruiken.
Fysieke partities van tabel: kies deze instelling als u een fysieke partitie wilt gebruiken. De partitiekolom en het mechanisme worden automatisch bepaald op basis van uw fysieke tabeldefinitie.
Dynamisch bereik: kies deze instelling als u dynamische bereikpartitie wilt gebruiken. Wanneer u query's gebruikt waarvoor parallel is ingeschakeld, is de partitieparameter(
?DfDynamicRangePartitionCondition) van het bereik nodig. Voorbeeldquery:SELECT * FROM <TableName> WHERE ?DfDynamicRangePartitionCondition.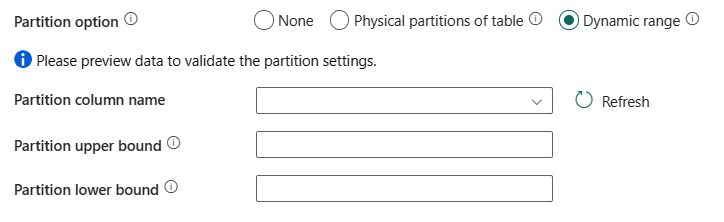
- Naam van partitiekolom: geef de naam op van de bronkolom in geheel getal of datum/datum/tijd -type (
int,bigintsmallint,date,smalldatetime, ,datetimeofdatetime2datetimeoffset) dat wordt gebruikt door bereikpartitionering voor parallelle kopie. Als dit niet is opgegeven, wordt de index of de primaire sleutel van de tabel automatisch gedetecteerd en gebruikt als de partitiekolom. - Bovengrens partitie: geef de maximumwaarde van de partitiekolom op voor het splitsen van partitiebereiken. Deze waarde wordt gebruikt om de partitie-onderdrukking te bepalen, niet voor het filteren van de rijen in de tabel. Alle rijen in de tabel of het queryresultaat worden gepartitioneerd en gekopieerd.
- Partitie ondergrens: Geef de minimumwaarde van de partitiekolom op voor het splitsen van partitiebereiken. Deze waarde wordt gebruikt om de partitie-onderdrukking te bepalen, niet voor het filteren van de rijen in de tabel. Alle rijen in de tabel of het queryresultaat worden gepartitioneerd en gekopieerd.
- Naam van partitiekolom: geef de naam op van de bronkolom in geheel getal of datum/datum/tijd -type (
Aanvullende kolommen: voeg extra gegevenskolommen toe om het relatieve pad of de statische waarde van bronbestanden op te slaan. Expressie wordt ondersteund voor de laatste. Ga naar Extra kolommen toevoegen tijdens het kopiëren voor meer informatie.
Doel
De volgende eigenschappen worden ondersteund voor Azure Synapse Analytics op het tabblad Bestemming van een kopieeractiviteit.
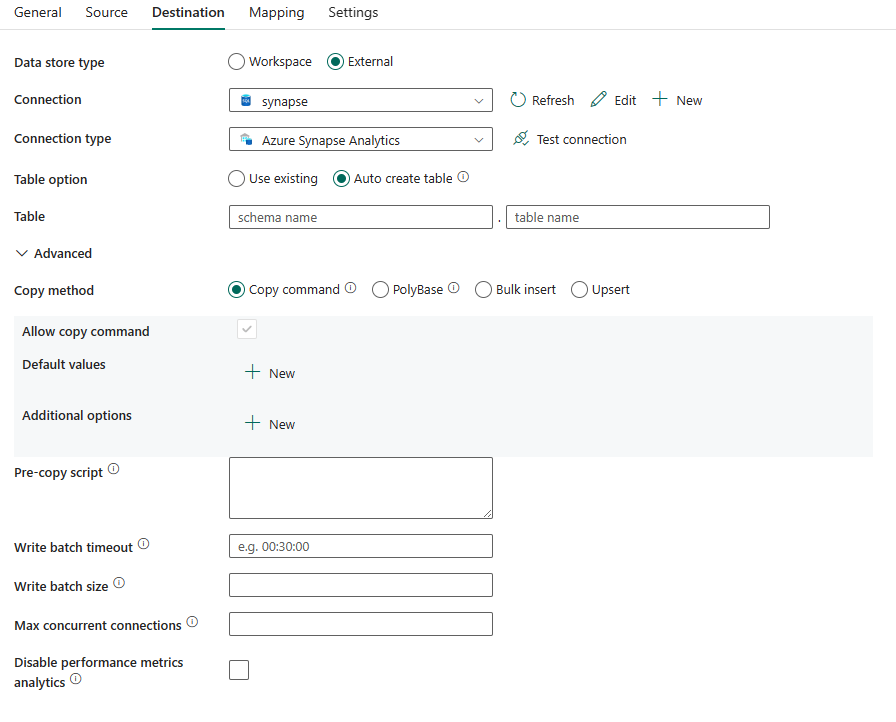
De volgende eigenschappen zijn vereist:
- Gegevensarchieftype: Selecteer Extern.
- Verbinding maken ion: Selecteer een Azure Synapse Analytics-verbinding in de lijst met verbindingen. Als de verbinding niet bestaat, maakt u een nieuwe Azure Synapse Analytics-verbinding door Nieuw te selecteren.
- Verbinding maken iontype: Selecteer Azure Synapse Analytics.
- Tabeloptie: u kunt bestaande, automatisch maken tabel gebruiken kiezen. In de volgende lijst wordt de configuratie van elke instelling beschreven:
- Bestaande gebruiken: Selecteer de tabel in uw database in de vervolgkeuzelijst. Of schakel Bewerken in om de naam van uw schema en tabel handmatig in te voeren.
- Tabel automatisch maken: de tabel wordt automatisch gemaakt (indien niet-bestaand) in het bronschema.
Onder Geavanceerd kunt u de volgende velden opgeven:
Kopieermethode Kies de methode die u wilt gebruiken om gegevens te kopiëren. U kunt de opdracht Kopiëren, PolyBase, Bulk insert of Upsert kiezen. In de volgende lijst wordt de configuratie van elke instelling beschreven:
Opdracht Kopiëren: gebruik de instructie COPY om gegevens uit Azure Storage te laden in Azure Synapse Analytics of SQL-pool.
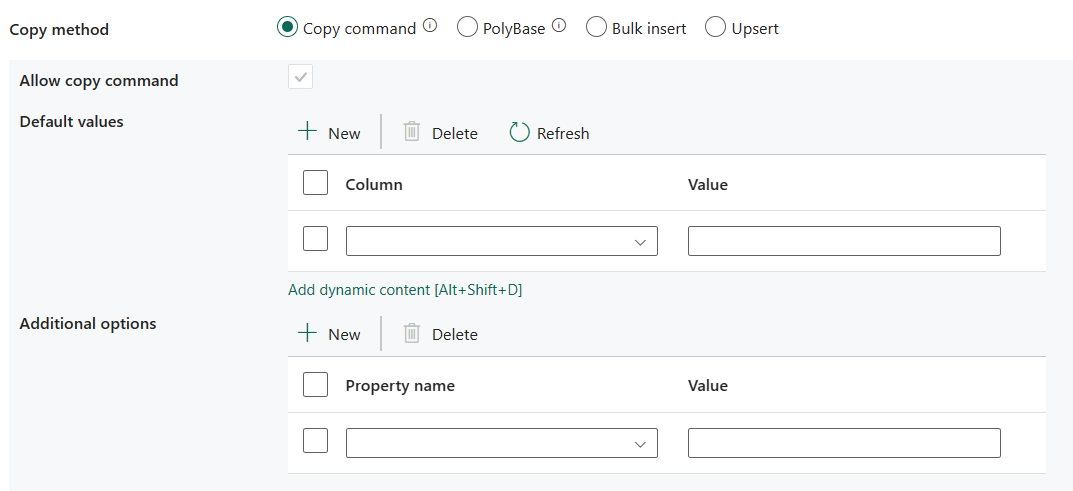
- Opdracht Kopiëren toestaan: het is verplicht om te worden geselecteerd wanneer u de opdracht Kopiëren kiest.
- Standaardwaarden: geef de standaardwaarden op voor elke doelkolom in Azure Synapse Analytics. De standaardwaarden in de eigenschap overschrijven de standaardbeperking die is ingesteld in het datawarehouse en de identiteitskolom mag geen standaardwaarde hebben.
- Aanvullende opties: Aanvullende opties die worden doorgegeven aan een Azure Synapse Analytics COPY-instructie rechtstreeks in de component 'With' in de COPY-instructie. Citeer de waarde indien nodig om te voldoen aan de vereisten voor de COPY-instructie.
PolyBase: PolyBase is een mechanisme voor hoge doorvoer. Gebruik deze om grote hoeveelheden gegevens te laden in Azure Synapse Analytics of SQL-pool.
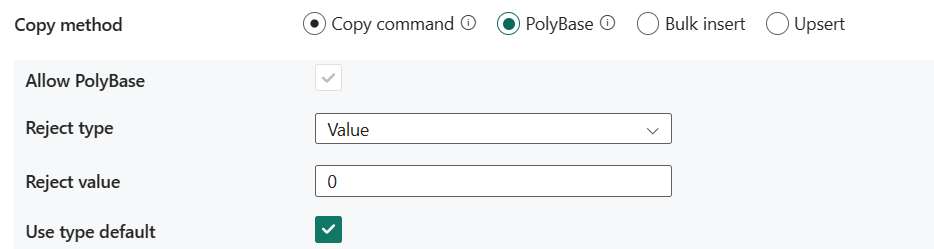
- PolyBase toestaan: het is verplicht om te worden geselecteerd wanneer u PolyBase kiest.
- Type weigeren: Geef aan of de optie rejectValue een letterlijke waarde of een percentage is. Toegestane waarden zijn Waarde (standaard) en Percentage.
- Waarde weigeren: geef het aantal of percentage rijen op dat kan worden geweigerd voordat de query mislukt. Meer informatie over de weigeringsopties van PolyBase in de sectie Argumenten van CREATE EXTERNAL TABLE (Transact-SQL). Toegestane waarden zijn 0 (standaard), 1, 2, enzovoort.
- Voorbeeldwaarde weigeren: bepaalt het aantal rijen dat moet worden opgehaald voordat PolyBase het percentage geweigerde rijen opnieuw berekent. Toegestane waarden zijn 1, 2, enzovoort. Als u Percentage kiest als type weigeren, is deze eigenschap vereist.
- Standaardtype gebruiken: geef op hoe ontbrekende waarden in tekstbestanden met scheidingstekens moeten worden verwerkt wanneer PolyBase gegevens ophaalt uit het tekstbestand. Meer informatie over deze eigenschap vindt u in de sectie Argumenten in CREATE EXTERNAL FILE FORMAT (Transact-SQL). Toegestane waarden worden geselecteerd (standaard) of niet geselecteerd.
Bulksgewijs invoegen: gebruik Bulksgewijs invoegen om gegevens bulksgewijs in te voegen.

- Tabelvergrendeling bulksgewijs invoegen: gebruik dit om de kopieerprestaties te verbeteren tijdens het bulksgewijs invoegen van tabellen zonder index van meerdere clients. Meer informatie van BULK INSERT (Transact-SQL).
Upsert: Geef de groep van de instellingen voor schrijfgedrag op wanneer u gegevens naar uw bestemming wilt verplaatsen.
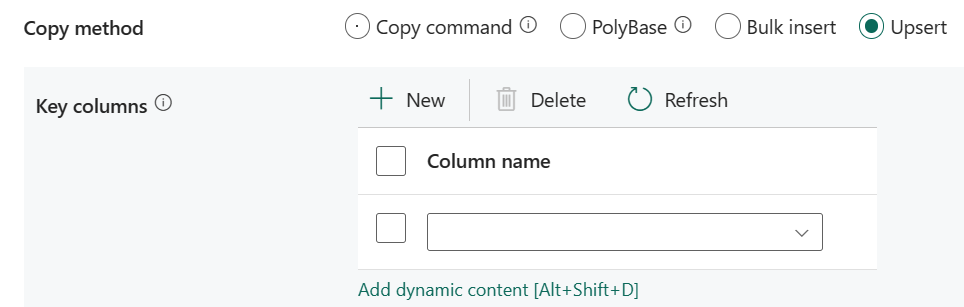
Sleutelkolommen: kies welke kolom wordt gebruikt om te bepalen of een rij uit de bron overeenkomt met een rij van het doel.
Tabelvergrendeling bulksgewijs invoegen: gebruik dit om de kopieerprestaties te verbeteren tijdens het bulksgewijs invoegen van tabellen zonder index van meerdere clients. Meer informatie van BULK INSERT (Transact-SQL).
Script vooraf kopiëren: geef een script op dat moet worden uitgevoerd voor kopieeractiviteit voordat u in elke uitvoering gegevens naar een doeltabel schrijft. U kunt deze eigenschap gebruiken om de vooraf geladen gegevens op te schonen.
Time-out voor schrijven van batch: geef de wachttijd op voordat de batchinvoegbewerking is voltooid voordat er een time-out optreedt. De toegestane waarde is tijdspanne. De standaardwaarde is '00:30:00' (30 minuten).
Batchgrootte schrijven: geef het aantal rijen op dat in de SQL-tabel per batch moet worden ingevoegd. De toegestane waarde is een geheel getal (aantal rijen). Standaard bepaalt de service dynamisch de juiste batchgrootte op basis van de rijgrootte.
Maximum aantal gelijktijdige verbindingen: geef de bovengrens op van gelijktijdige verbindingen die tijdens de uitvoering van de activiteit tot stand zijn gebracht met het gegevensarchief. Geef alleen een waarde op wanneer u gelijktijdige verbindingen wilt beperken.
Analyse van metrische gegevens voor prestaties uitschakelen: deze instelling wordt gebruikt voor het verzamelen van metrische gegevens, zoals DTU, DWU, RU, enzovoort, voor het optimaliseren en aanbevelingen van kopieerprestaties. Als u zich zorgen maakt over dit gedrag, schakelt u dit selectievakje in. Deze optie is standaard niet geselecteerd.
Directe kopie met de opdracht COPY
De azure Synapse Analytics COPY-opdracht biedt rechtstreeks ondersteuning voor Azure Blob Storage en Azure Data Lake Storage Gen2 als brongegevensopslag. Als uw brongegevens voldoen aan de criteria die in deze sectie worden beschreven, gebruikt u de opdracht COPY om rechtstreeks vanuit het brongegevensarchief naar Azure Synapse Analytics te kopiëren.
De brongegevens en -indeling bevatten de volgende typen en verificatiemethoden:
Ondersteund type brongegevensarchief Ondersteunde indeling Ondersteund type bronverificatie Azure Blob-opslag Tekst met scheidingstekens
ParquetAnonieme verificatie
Verificatie van accountsleutels
Shared Access Signature AuthenticationAzure Data Lake Storage Gen2 Tekst met scheidingstekens
ParquetVerificatie van accountsleutels
Shared Access Signature AuthenticationDe volgende indelingsinstellingen kunnen worden ingesteld:
- Voor Parquet: Het compressietype kan geen, snappy of gzip zijn.
- Voor DelimitedText:
- Rijscheidingsteken: Wanneer u tekst met scheidingstekens kopieert naar Azure Synapse Analytics via de opdracht Direct COPY, geeft u het scheidingsteken voor rijen expliciet op (\r; \n; of \r\n). Alleen wanneer het rijscheidingsteken van het bronbestand \r\n is, werkt de standaardwaarde (\r, \n of \r\n) . Schakel anders fasering in voor uw scenario.
- Null-waarde blijft standaard staan of is ingesteld op een lege tekenreeks (').<
/a0> - Codering blijft standaard staan of ingesteld op UTF-8 of UTF-16.
- Het aantal regels overslaan blijft standaard staan of is ingesteld op 0.
- Het type compressie kan Geen of gzip zijn.
Als uw bron een map is, moet u het selectievakje Recursief inschakelen.
Begintijd (UTC) en eindtijd (UTC) in Filter op laatst gewijzigd, Voorvoegsel, Partitiedetectie inschakelen en Aanvullende kolommen worden niet opgegeven.
Zie dit artikel voor meer informatie over het opnemen van gegevens in uw Azure Synapse Analytics met behulp van de opdracht COPY.
Als uw brongegevensarchief en -indeling niet oorspronkelijk wordt ondersteund door een COPY-opdracht, gebruikt u in plaats daarvan de gefaseerde kopie met behulp van de functie COPY-opdracht. De gegevens worden automatisch geconverteerd naar een indeling die compatibel is met de COPY-opdracht en roept vervolgens een COPY-opdracht aan om gegevens te laden in Azure Synapse Analytics.
Toewijzing
Als u Azure Synapse Analytics met automatisch maken als bestemming niet toepast voor de configuratie van het tabblad Toewijzing , gaat u naar Toewijzing.
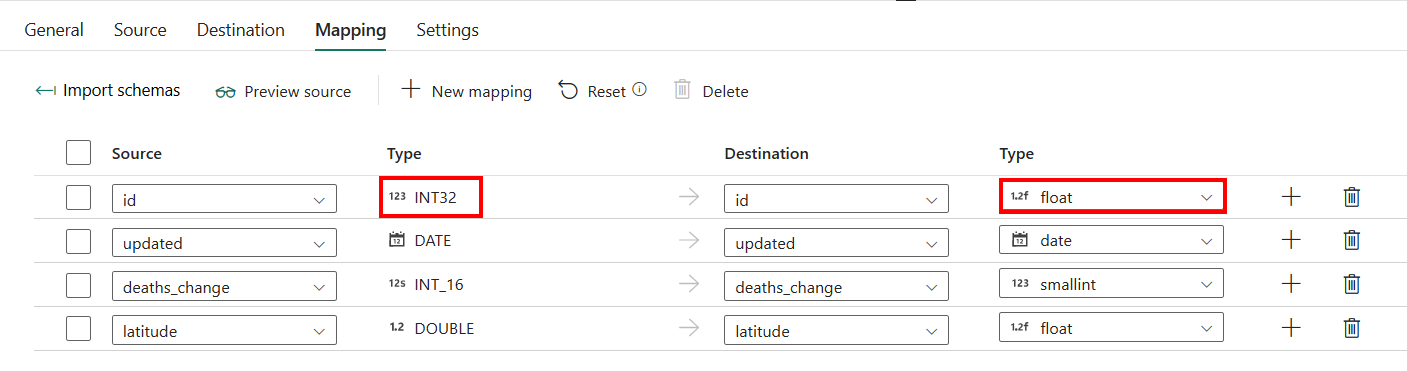
Als u Azure Synapse Analytics met automatisch maken als bestemming toepast, met uitzondering van de configuratie in Toewijzing, kunt u het type voor de doelkolommen bewerken. Nadat u Importschema's hebt geselecteerd, kunt u het kolomtype opgeven in uw bestemming.
Het type voor de id-kolom in de bron is bijvoorbeeld int en u kunt dit wijzigen in floattype bij het toewijzen aan de doelkolom.
Instellingen
Ga voor Instellingen tabbladconfiguratie naar Uw andere instellingen configureren op het tabblad Instellingen.
Parallel kopiëren vanuit Azure Synapse Analytics
De Azure Synapse Analytics-connector in kopieeractiviteit biedt ingebouwde gegevenspartitionering om gegevens parallel te kopiëren. U vindt opties voor gegevenspartitionering op het tabblad Bron van de kopieeractiviteit.
Wanneer u gepartitioneerde kopie inschakelt, voert de kopieeractiviteit parallelle query's uit op uw Azure Synapse Analytics-bron om gegevens te laden op partities. De parallelle graad wordt bepaald door de mate van kopieerparallelisme op het tabblad Instellingen voor kopieeractiviteit. Als u bijvoorbeeld mate van parallelle kopieerbewerking instelt op vier, genereert de service gelijktijdig vier query's op basis van de opgegeven partitieoptie en -instellingen en haalt elke query een deel van de gegevens op uit uw Azure Synapse Analytics.
U wordt aangeraden parallelle kopieën met gegevenspartitionering in te schakelen, met name wanneer u grote hoeveelheden gegevens uit Azure Synapse Analytics laadt. Hier volgen voorgestelde configuraties voor verschillende scenario's. Wanneer u gegevens kopieert naar een bestandsgegevensarchief, is het raadzaam om naar een map te schrijven als meerdere bestanden (alleen mapnaam opgeven), in welk geval de prestaties beter zijn dan schrijven naar één bestand.
| Scenario | Voorgestelde instellingen |
|---|---|
| Volledige belasting van grote tabellen, met fysieke partities. | Partitieoptie: fysieke partities van de tabel. Tijdens de uitvoering detecteert de service automatisch de fysieke partities en kopieert de gegevens per partitie. Als u wilt controleren of uw tabel een fysieke partitie heeft of niet, kunt u naar deze query verwijzen. |
| Volledige belasting van grote tabellen, zonder fysieke partities, terwijl met een geheel getal of datum/tijd-kolom voor gegevenspartitionering. | Partitieopties: partitie dynamisch bereik. Partitiekolom (optioneel): Geef de kolom op die wordt gebruikt om gegevens te partitioneren. Als deze niet is opgegeven, wordt de index- of primaire-sleutelkolom gebruikt. Bovengrens en partitieondergrens partitioneren (optioneel): Geef op of u de partitie-onderdrukking wilt bepalen. Dit is niet voor het filteren van de rijen in de tabel, alle rijen in de tabel worden gepartitioneerd en gekopieerd. Als dit niet is opgegeven, detecteert de kopieeractiviteit automatisch de waarden. Als de partitiekolom 'ID' bijvoorbeeld waarden heeft tussen 1 en 100 en u de ondergrens instelt op 20 en de bovengrens als 80, met parallelle kopie als 4, haalt de service gegevens op met 4 partities - id's in bereik <=20, [21, 50], [51, 80] en >=81. |
| Laad een grote hoeveelheid gegevens met behulp van een aangepaste query, zonder fysieke partities, terwijl u een geheel getal of een datum/datum/tijd-kolom gebruikt voor gegevenspartitionering. | Partitieopties: partitie dynamisch bereik. Query: SELECT * FROM <TableName> WHERE ?DfDynamicRangePartitionCondition AND <your_additional_where_clause>.Partitiekolom: Geef de kolom op die wordt gebruikt om gegevens te partitioneren. Bovengrens en partitieondergrens partitioneren (optioneel): Geef op of u de partitie-onderdrukking wilt bepalen. Dit is niet voor het filteren van de rijen in de tabel, alle rijen in het queryresultaat worden gepartitioneerd en gekopieerd. Als dit niet is opgegeven, detecteert kopieeractiviteit automatisch de waarde. Als de partitiekolom 'ID' bijvoorbeeld waarden heeft tussen 1 en 100 en u de ondergrens instelt op 20 en de bovengrens als 80, waarbij de parallelle kopie als 4 is, haalt de service gegevens op met 4 partities- id's in het bereik <=20, [21, 50], [51, 80] en >=81. Hier volgen meer voorbeeldquery's voor verschillende scenario's: • Voer een query uit op de hele tabel: SELECT * FROM <TableName> WHERE ?DfDynamicRangePartitionCondition• Query's uitvoeren vanuit een tabel met kolomselectie en aanvullende where-componentfilters: SELECT <column_list> FROM <TableName> WHERE ?DfDynamicRangePartitionCondition AND <your_additional_where_clause>• Query's uitvoeren met subquery's: SELECT <column_list> FROM (<your_sub_query>) AS T WHERE ?DfDynamicRangePartitionCondition AND <your_additional_where_clause>• Query uitvoeren met partitie in subquery: SELECT <column_list> FROM (SELECT <your_sub_query_column_list> FROM <TableName> WHERE ?DfDynamicRangePartitionCondition) AS T |
Aanbevolen procedures voor het laden van gegevens met partitieoptie:
- Kies een onderscheidende kolom als partitiekolom (zoals primaire sleutel of unieke sleutel) om scheeftrekken van gegevens te voorkomen.
- Als de tabel een ingebouwde partitie heeft, gebruikt u de partitieoptie Fysieke partities van de tabel om betere prestaties te krijgen.
- Azure Synapse Analytics kan maximaal 32 query's tegelijk uitvoeren. Het instellen van mate van kopieerparallelisme kan leiden tot een probleem met synapse-beperking.
Voorbeeldquery om fysieke partitie te controleren
SELECT DISTINCT s.name AS SchemaName, t.name AS TableName, c.name AS ColumnName, CASE WHEN c.name IS NULL THEN 'no' ELSE 'yes' END AS HasPartition
FROM sys.tables AS t
LEFT JOIN sys.objects AS o ON t.object_id = o.object_id
LEFT JOIN sys.schemas AS s ON o.schema_id = s.schema_id
LEFT JOIN sys.indexes AS i ON t.object_id = i.object_id
LEFT JOIN sys.index_columns AS ic ON ic.partition_ordinal > 0 AND ic.index_id = i.index_id AND ic.object_id = t.object_id
LEFT JOIN sys.columns AS c ON c.object_id = ic.object_id AND c.column_id = ic.column_id
LEFT JOIN sys.types AS y ON c.system_type_id = y.system_type_id
WHERE s.name='[your schema]' AND t.name = '[your table name]'
Als de tabel een fysieke partitie heeft, ziet u HasPartition als Ja.
Tabelsamenvatting
De volgende tabellen bevatten meer informatie over de kopieeractiviteit in Azure Synapse Analytics.
Bron
| Name | Beschrijving | Waarde | Vereist | JSON-scripteigenschap |
|---|---|---|---|---|
| Gegevensarchieftype | Het gegevensarchieftype. | Extern | Ja | / |
| Verbinding | Uw verbinding met het brongegevensarchief. | < uw verbinding > | Ja | verbinding |
| Verbindingstype | Uw bronverbindingstype. | Azure Synapse Analytics | Ja | / |
| Query gebruiken | De manier om gegevens te lezen. | •Tabel •Query • Opgeslagen procedure |
Ja | • typeProperties (onder typeProperties ->source)- schema -Tabel • sqlReaderQuery • sqlReaderStoredProcedureName storedProcedureParameters -Naam -Waarde |
| Time-out van query | De time-out voor het uitvoeren van queryopdrachten is standaard 120 minuten. | tijdsbestek | Nee | queryTimeout |
| Isolatieniveau | Het gedrag voor transactievergrendeling voor de SQL-bron. | •Geen • Lees vastgelegd • Niet-verzonden lezen • Herhaalbare leesbewerking •Serializable •Momentopname |
Nee | Isolationlevel: • ReadCommitted • ReadUncommitted • Herhaalbaar gelezen •Serializable •Momentopname |
| Partitieoptie | De opties voor gegevenspartitionering die worden gebruikt voor het laden van gegevens uit Azure SQL Database. | •Geen • Fysieke partities van tabel • Dynamisch bereik - Naam van partitiekolom - Bovengrens partitioneren - Ondergrens partitioneren |
Nee | partitionOption: • PhysicalPartitionsOfTable • DynamicRange partitie Instellingen: - partitionColumnName - partitionUpperBound - partitionLowerBound |
| Aanvullende kolommen | Voeg extra gegevenskolommen toe om het relatieve pad of de statische waarde van bronbestanden op te slaan. Expressie wordt ondersteund voor de laatste. | • Naam •Waarde |
Nee | additionalColumns: •Naam •Waarde |
Doel
| Name | Beschrijving | Waarde | Vereist | JSON-scripteigenschap |
|---|---|---|---|---|
| Gegevensarchieftype | Het gegevensarchieftype. | Extern | Ja | / |
| Verbinding | Uw verbinding met het doelgegevensarchief. | < uw verbinding > | Ja | verbinding |
| Verbindingstype | Uw doelverbindingstype. | Azure Synapse Analytics | Ja | / |
| Tabeloptie | De optie voor de doelgegevenstabel. | • Bestaande gebruiken • Tabel automatisch maken |
Ja | • typeProperties (onder typeProperties ->sink)- schema -Tabel • tableOption: - autoCreate typeProperties (onder typeProperties ->sink)- schema -Tabel |
| Methode kopiëren | De methode die wordt gebruikt om gegevens te kopiëren. | • Opdracht Kopiëren • PolyBase • Bulksgewijs invoegen • Upsert |
Nee | / |
| Bij het selecteren van de opdracht Kopiëren | Gebruik de instructie COPY om gegevens uit Azure Storage te laden in Azure Synapse Analytics of SQL-pool. | / | Nee Toepassen wanneer u COPY gebruikt. |
allowCopyCommand: true copyCommand Instellingen |
| Standaardwaarden | Geef de standaardwaarden op voor elke doelkolom in Azure Synapse Analytics. De standaardwaarden in de eigenschap overschrijven de standaardbeperking die is ingesteld in het datawarehouse en de identiteitskolom mag geen standaardwaarde hebben. | < standaardwaarden > | Nee | defaultValues: -Kolomnaam -Standaardwaarde |
| Aanvullende opties | Aanvullende opties die worden doorgegeven aan een Azure Synapse Analytics COPY-instructie, rechtstreeks in de component 'With' in de COPY-instructie. Citeer de waarde indien nodig om te voldoen aan de vereisten voor de COPY-instructie. | < aanvullende opties > | Nee | additionalOptions: - <eigenschapsnaam> : <waarde> |
| Bij het selecteren van PolyBase | PolyBase is een mechanisme voor hoge doorvoer. Gebruik deze om grote hoeveelheden gegevens te laden in Azure Synapse Analytics of SQL-pool. | / | Nee Toepassen bij het gebruik van PolyBase. |
allowPolyBase: true polyBase Instellingen |
| Type weigeren | Het type weigeringswaarde. | •Waarde •Percentage |
Nee | rejectType: -Waarde -Percentage |
| Waarde negeren | Het aantal of het percentage rijen dat kan worden geweigerd voordat de query mislukt. | 0 (standaard), 1, 2, enzovoort. | Nee | rejectValue |
| Voorbeeldwaarde weigeren | Bepaalt het aantal rijen dat moet worden opgehaald voordat PolyBase het percentage geweigerde rijen opnieuw berekent. | 1, 2, enz. | Ja wanneer u Percentage opgeeft als uw weigeringstype | rejectSampleValue |
| Standaardtype gebruiken | Geef op hoe ontbrekende waarden in tekstbestanden met scheidingstekens moeten worden verwerkt wanneer PolyBase gegevens ophaalt uit het tekstbestand. Meer informatie over deze eigenschap vindt u in de sectie Argumenten in CREATE EXTERNAL FILE FORMAT (Transact-SQL) | geselecteerd (standaard) of niet geselecteerd. | Nee | useTypeDefault: waar (standaard) of onwaar |
| Bij het selecteren van bulksgewijs invoegen | Gegevens bulksgewijs naar bestemming invoegen. | / | Nee | writeBehavior: Invoegen |
| Tabelvergrendeling bulksgewijs invoegen | Gebruik dit om de kopieerprestaties te verbeteren tijdens het bulksgewijs invoegen van tabellen zonder index van meerdere clients. Meer informatie van BULK INSERT (Transact-SQL). | geselecteerd of niet geselecteerd (standaard) | Nee | sqlWriterUseTableLock: waar of onwaar (standaard) |
| Bij het selecteren van Upsert | Geef de groep van de instellingen voor schrijfgedrag op wanneer u gegevens naar uw bestemming wilt verplaatsen. | / | Nee | writeBehavior: Upsert |
| Sleutelkolommen | Geeft aan welke kolom wordt gebruikt om te bepalen of een rij uit de bron overeenkomt met een rij van het doel. | < kolomnaam> | Nee | upsert Instellingen: - sleutels: < kolomnaam > - interimSchemaName |
| Tabelvergrendeling bulksgewijs invoegen | Gebruik dit om de kopieerprestaties te verbeteren tijdens het bulksgewijs invoegen van tabellen zonder index van meerdere clients. Meer informatie van BULK INSERT (Transact-SQL). | geselecteerd of niet geselecteerd (standaard) | Nee | sqlWriterUseTableLock: waar of onwaar (standaard) |
| Script vooraf kopiëren | Een script voor kopieeractiviteit dat moet worden uitgevoerd voordat gegevens in een doeltabel in elke uitvoering worden geschreven. U kunt deze eigenschap gebruiken om de vooraf geladen gegevens op te schonen. | < script vooraf kopiëren > (tekenreeks) |
Nee | preCopyScript |
| Time-out voor batchbewerkingen schrijven | De wachttijd voordat de batchinvoegbewerking is voltooid voordat er een time-out optreedt. De toegestane waarde is tijdspanne. De standaardwaarde is '00:30:00' (30 minuten). | tijdsbestek | Nee | writeBatchTimeout |
| Grootte van schrijfbatch | Het aantal rijen dat moet worden ingevoegd in de SQL-tabel per batch. Standaard bepaalt de service dynamisch de juiste batchgrootte op basis van de rijgrootte. | < aantal rijen > (geheel getal) |
Nee | writeBatchSize |
| Maximum aantal gelijktijdige verbindingen | De bovengrens van gelijktijdige verbindingen die tijdens de uitvoering van de activiteit tot stand zijn gebracht met het gegevensarchief. Geef alleen een waarde op wanneer u gelijktijdige verbindingen wilt beperken. | < bovengrens van gelijktijdige verbindingen > (geheel getal) |
Nee | maxConcurrent Verbinding maken ions |
| Analyse van metrische prestatiegegevens uitschakelen | Deze instelling wordt gebruikt voor het verzamelen van metrische gegevens, zoals DTU, DWU, RU, enzovoort, voor het optimaliseren van kopieerprestaties en aanbevelingen. Als u zich zorgen maakt over dit gedrag, schakelt u dit selectievakje in. | selecteren of de selectie opheffen (standaard) | Nee | disableMetricsCollection: waar of onwaar (standaard) |