Gegevens kopiëren met behulp van kopieeractiviteit
In Data Pipeline kunt u de Copy-activiteit gebruiken om gegevens te kopiëren tussen gegevensarchieven die zich in de cloud bevinden.
Nadat u de gegevens hebt gekopieerd, kunt u andere activiteiten gebruiken om deze verder te transformeren en te analyseren. U kunt ook de Copy-activiteit gebruiken om transformatie- en analyseresultaten te publiceren voor business intelligence (BI) en toepassingsverbruik.
Als u gegevens van een bron naar een bestemming wilt kopiëren, voert de service die de Copy-activiteit uitvoert de volgende stappen uit:
- Leest gegevens uit een brongegevensarchief.
- Serialisatie/deserialisatie, compressie/decompressie, kolomtoewijzing, enzovoort. Deze bewerkingen worden uitgevoerd op basis van de configuratie.
- Hiermee schrijft u gegevens naar het doelgegevensarchief.
Vereisten
Om aan de slag te gaan, moet u aan de volgende vereisten voldoen:
Een Microsoft Fabric-tenantaccount met een actief abonnement. Gratis een account maken
Zorg ervoor dat u een werkruimte met Microsoft Fabric hebt ingeschakeld.
Een kopieeractiviteit toevoegen met behulp van de kopieerassistent
Volg deze stappen om uw kopieeractiviteit in te stellen met behulp van de kopieerassistent.
Beginnen met de kopieerassistent
Open een bestaande gegevenspijplijn of maak een nieuwe gegevenspijplijn.
Selecteer Gegevens kopiëren op het canvas om het hulpprogramma Copy Assistant te openen om aan de slag te gaan. Of selecteer Kopieerassistent gebruiken in de vervolgkeuzelijst Gegevens kopiëren onder het tabblad Activiteiten op het lint.
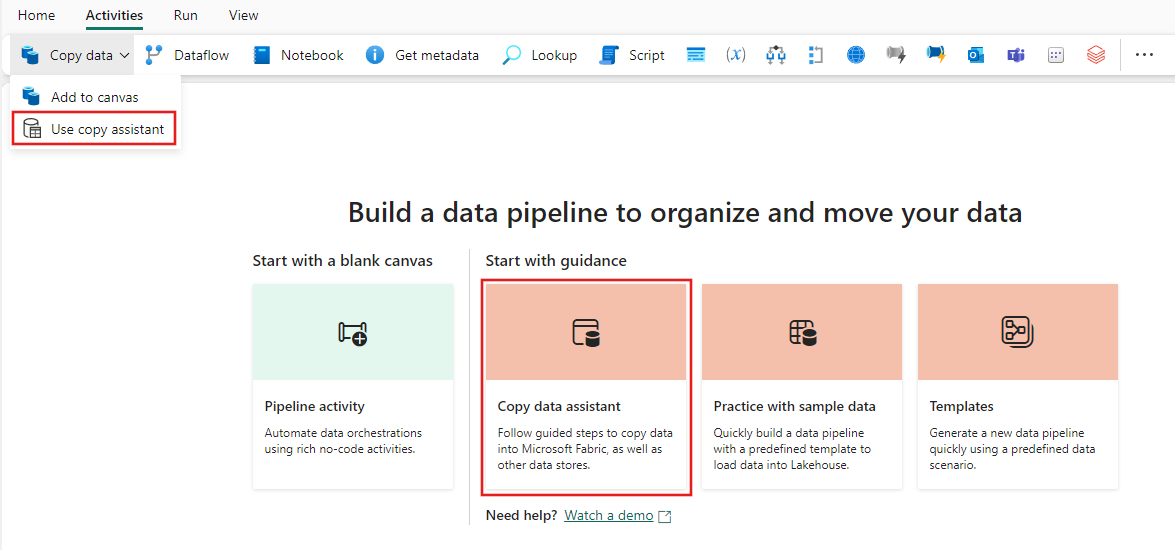

Uw bron configureren
Selecteer een gegevensbrontype in de categorie. U gebruikt Azure Blob Storage als voorbeeld. Selecteer Azure Blob Storage en selecteer vervolgens Volgende.
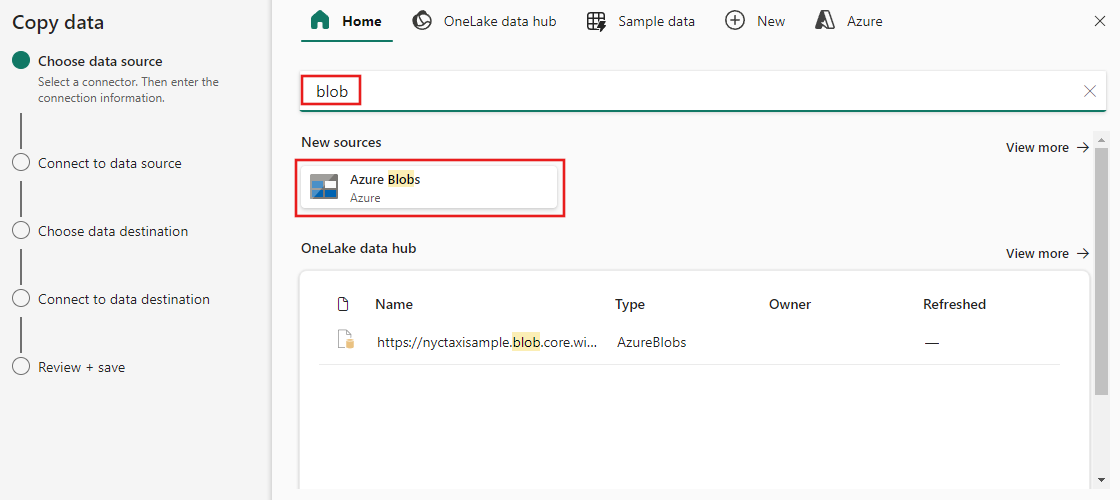
Maak een verbinding met uw gegevensbron door nieuwe verbinding maken te selecteren.
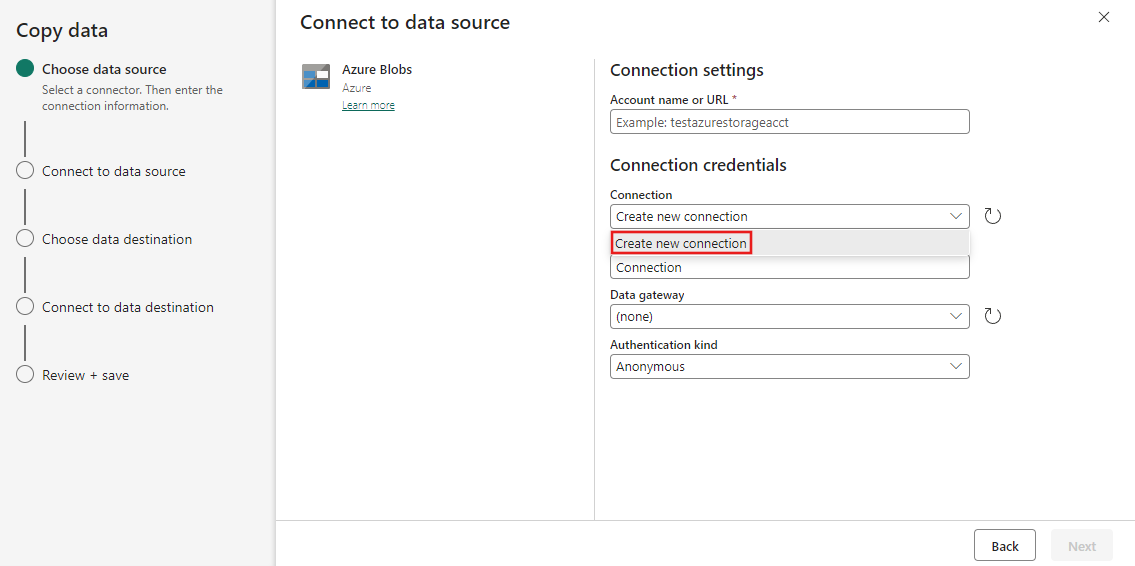
Nadat u Nieuwe verbinding maken hebt geselecteerd, vult u de vereiste verbindingsgegevens in en selecteert u Volgende. Raadpleeg elk connectorartikel voor meer informatie over het maken van een verbinding voor elk type gegevensbron.
Als u bestaande verbindingen hebt, kunt u Bestaande verbinding selecteren en uw verbinding selecteren in de vervolgkeuzelijst.
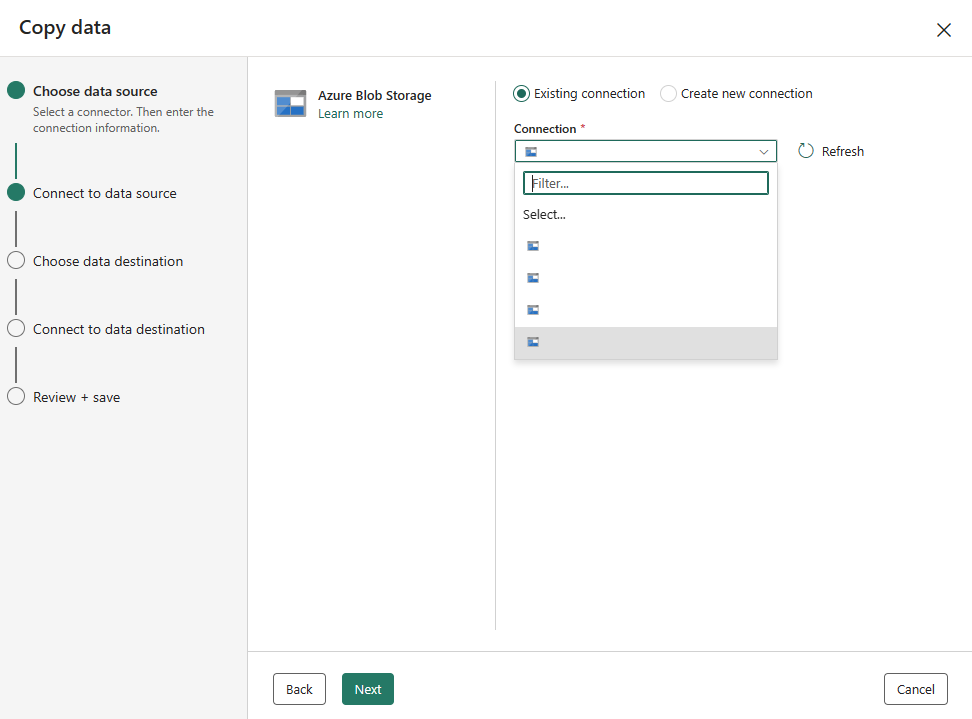
Kies het bestand of de map die u wilt kopiëren in deze bronconfiguratiestap en selecteer vervolgens Volgende.
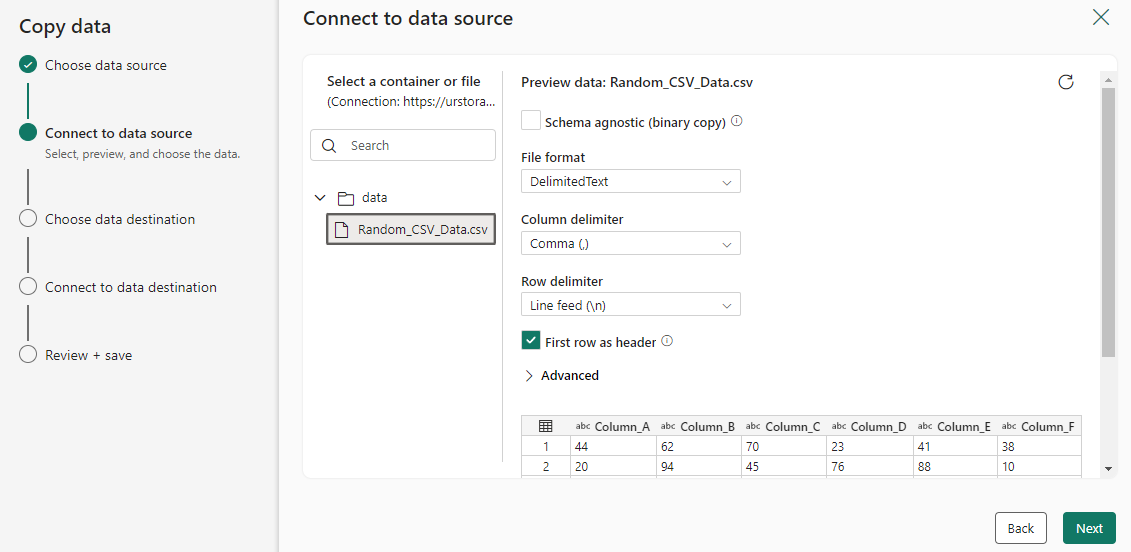




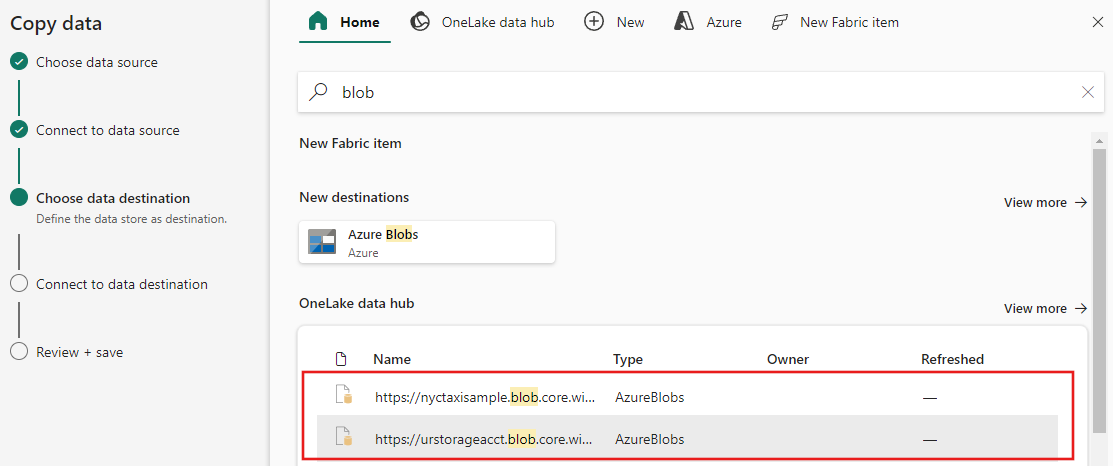
Uw bestemming configureren
Selecteer een gegevensbrontype in de categorie. U gebruikt Azure Blob Storage als voorbeeld. U kunt een nieuwe verbinding maken die is gekoppeld aan een nieuw Azure Blob Storage-account door de stappen in de vorige sectie te volgen of een bestaande verbinding te gebruiken in de vervolgkeuzelijst voor verbindingen. De mogelijkheden van Verbinding testen en Bewerken zijn beschikbaar voor elke geselecteerde verbinding.
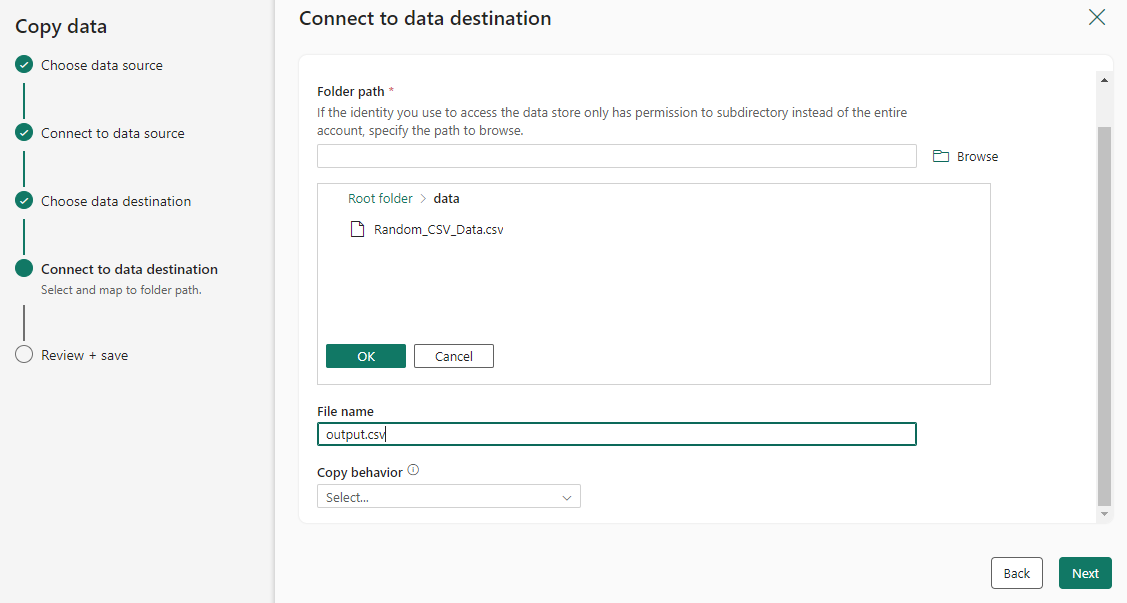
Configureer en wijs uw brongegevens toe aan uw bestemming. Selecteer vervolgens Volgende om de doelconfiguraties te voltooien.
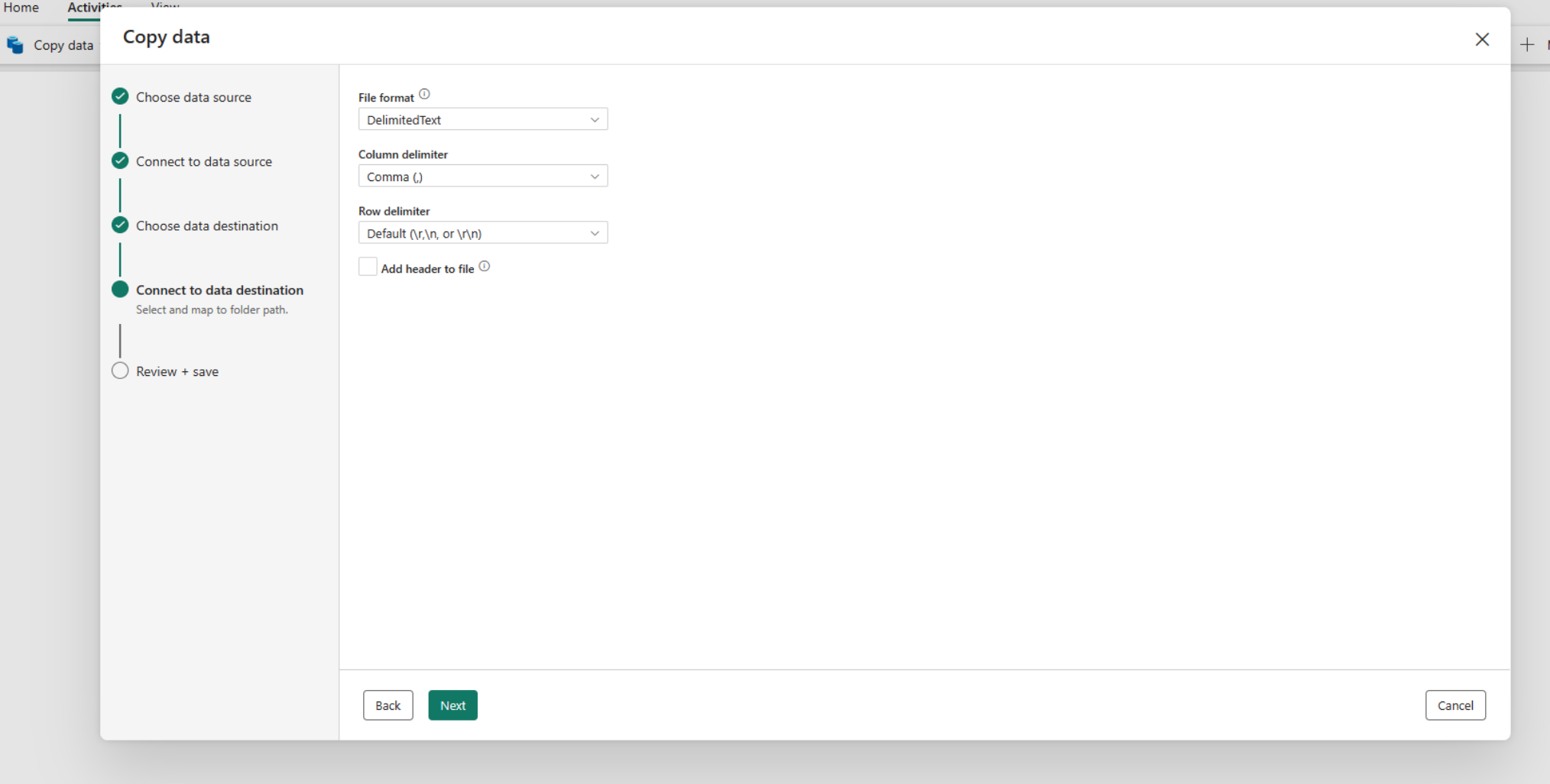
Notitie
U kunt slechts één on-premises gegevensgateway binnen dezelfde Copy-activiteit gebruiken. Als zowel bron- als sink on-premises gegevensbronnen zijn, moeten ze dezelfde gateway gebruiken. Als u gegevens wilt verplaatsen tussen on-premises gegevensbronnen met verschillende gateways, moet u kopiëren met behulp van de eerste gateway naar een tussenliggende cloudbron in één Copy-activiteit. Vervolgens kunt u een andere Copy-activiteit gebruiken om deze te kopiëren vanuit de tussenliggende cloudbron met behulp van de tweede gateway.



Uw kopieeractiviteit controleren en maken
Controleer de instellingen voor de kopieeractiviteit in de vorige stappen en selecteer OK om te voltooien. U kunt ook teruggaan naar de vorige stappen om uw instellingen zo nodig in het hulpprogramma te bewerken.


Zodra de kopieeractiviteit is voltooid, wordt deze toegevoegd aan uw gegevenspijplijncanvas. Alle instellingen, inclusief geavanceerde instellingen voor deze kopieeractiviteit, zijn beschikbaar onder de tabbladen wanneer deze is geselecteerd.

U kunt nu uw gegevenspijplijn opslaan met deze enkele kopieeractiviteit of doorgaan met het ontwerpen van uw gegevenspijplijn.
Een kopieeractiviteit rechtstreeks toevoegen
Volg deze stappen om een kopieeractiviteit rechtstreeks toe te voegen.
Een kopieeractiviteit toevoegen
Open een bestaande gegevenspijplijn of maak een nieuwe gegevenspijplijn.
Voeg een kopieeractiviteit toe door pijplijnactiviteit toevoegen te selecteren Copy-activiteit of door Gegevens kopiëren>naar canvas te selecteren op het tabblad Activiteiten.>
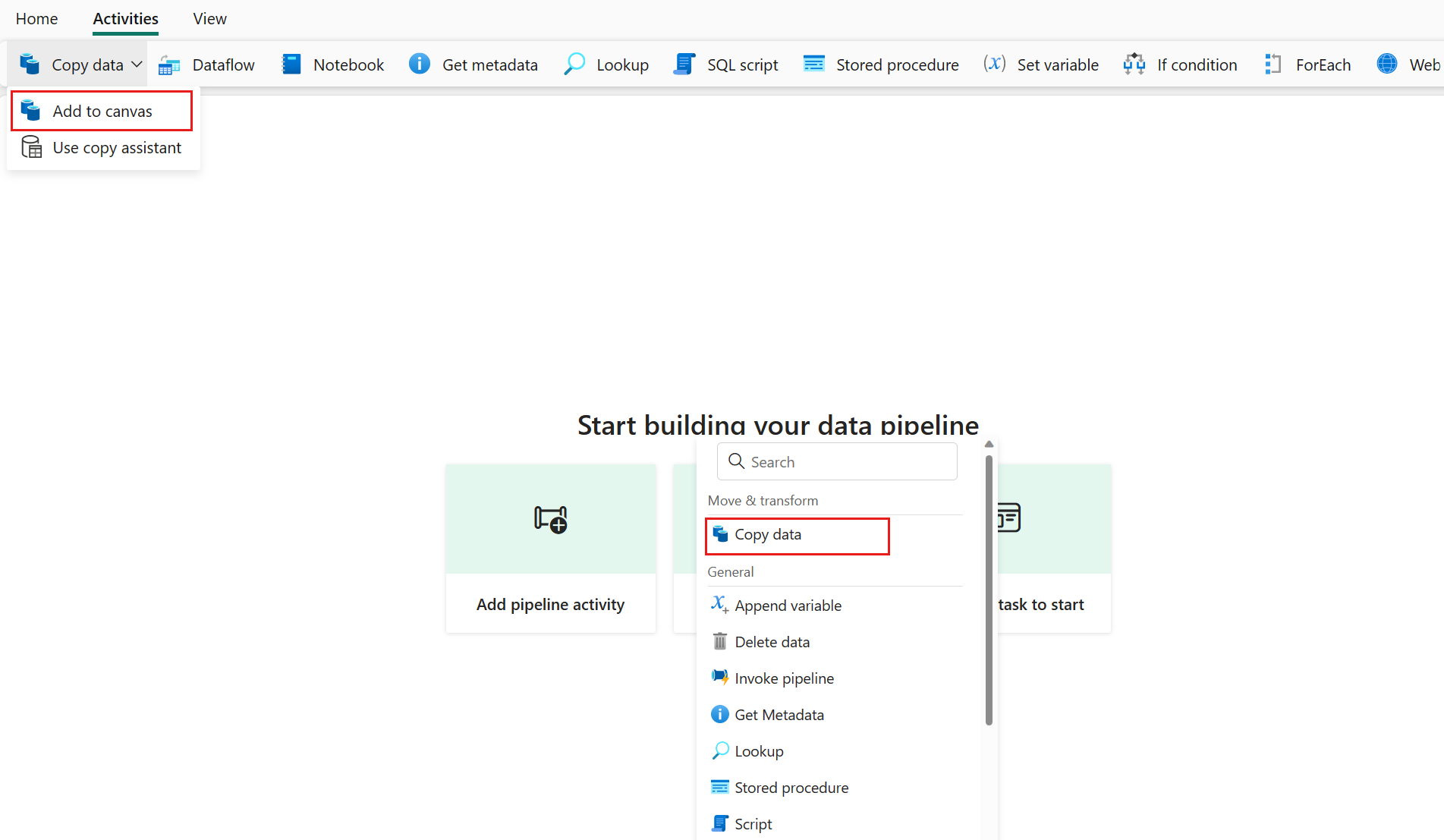

Uw algemene instellingen configureren op het tabblad Algemeen
Zie Algemeen voor meer informatie over het configureren van uw algemene instellingen.
Uw bron configureren op het tabblad Bron
Selecteer + Nieuw naast de verbinding om een verbinding met uw gegevensbron te maken.
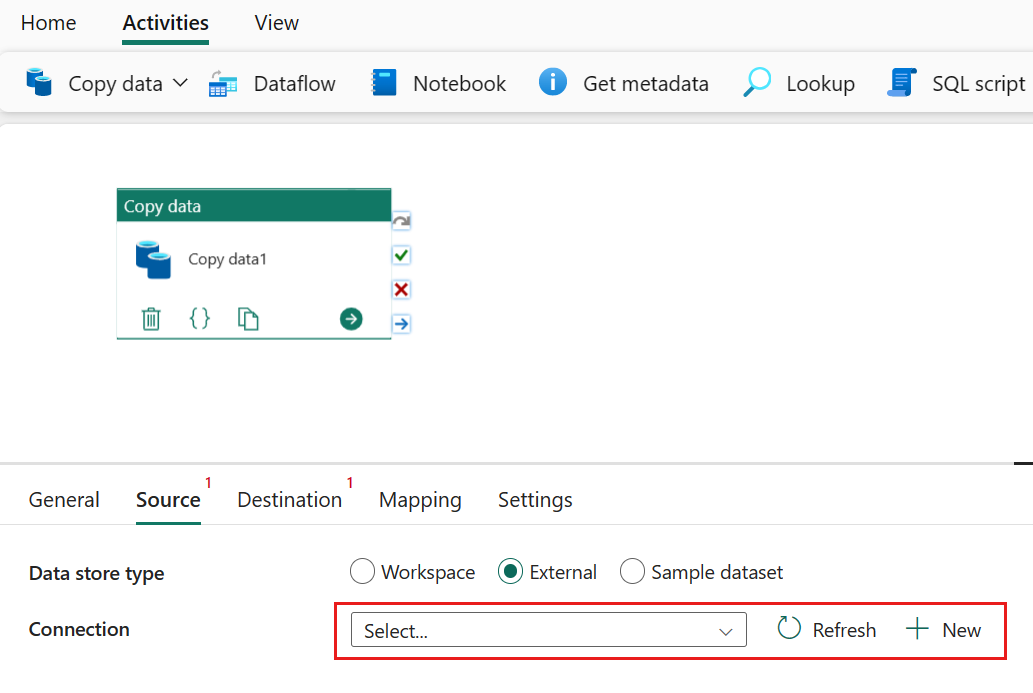
Kies het gegevensbrontype in het pop-upvenster. U gebruikt Azure SQL Database als voorbeeld. Selecteer Azure SQL Database en vervolgens Doorgaan.
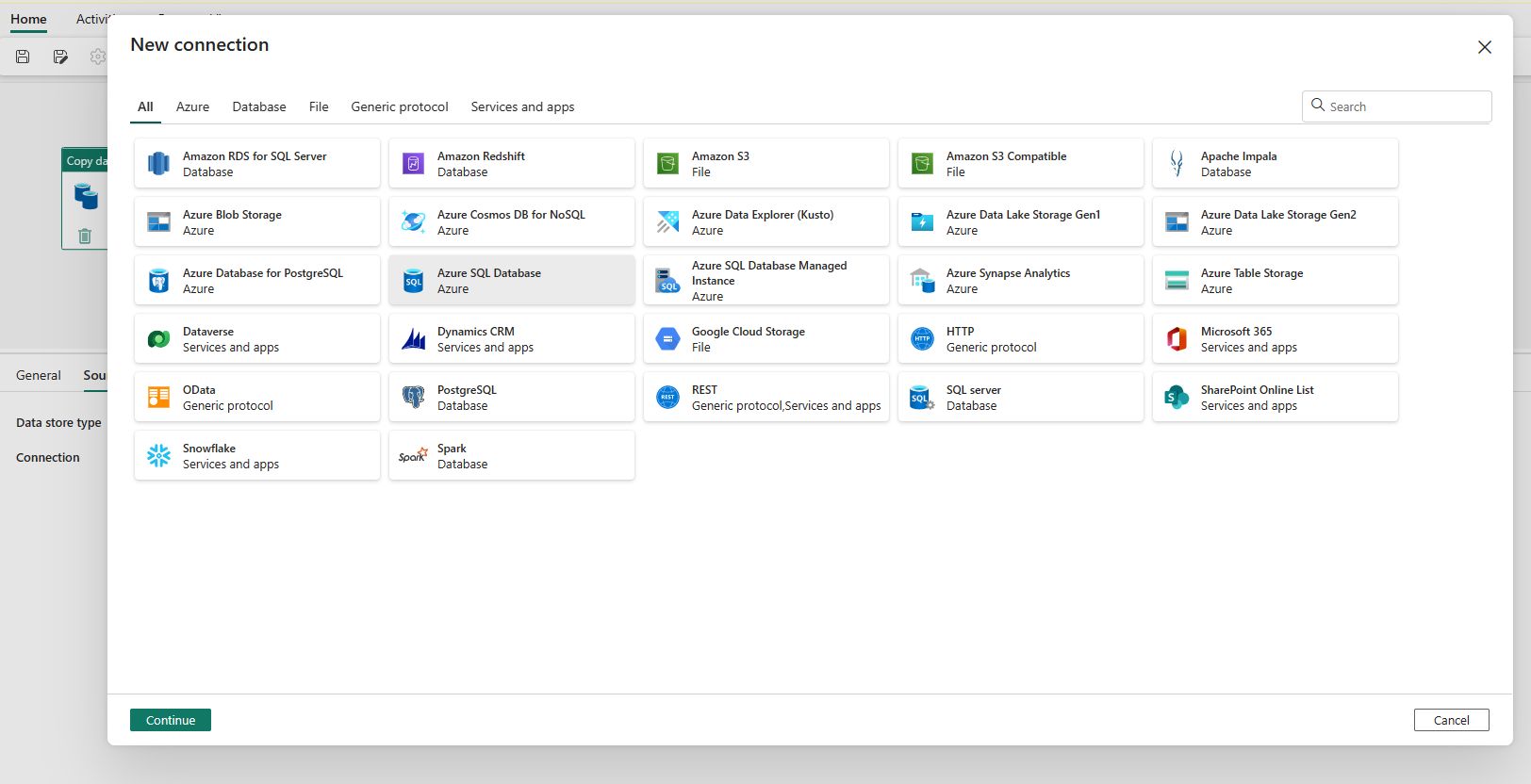
Hiermee gaat u naar de pagina voor het maken van de verbinding. Vul de vereiste verbindingsgegevens in het deelvenster in en selecteer Vervolgens Maken. Raadpleeg elk connectorartikel voor meer informatie over het maken van een verbinding voor elk type gegevensbron.
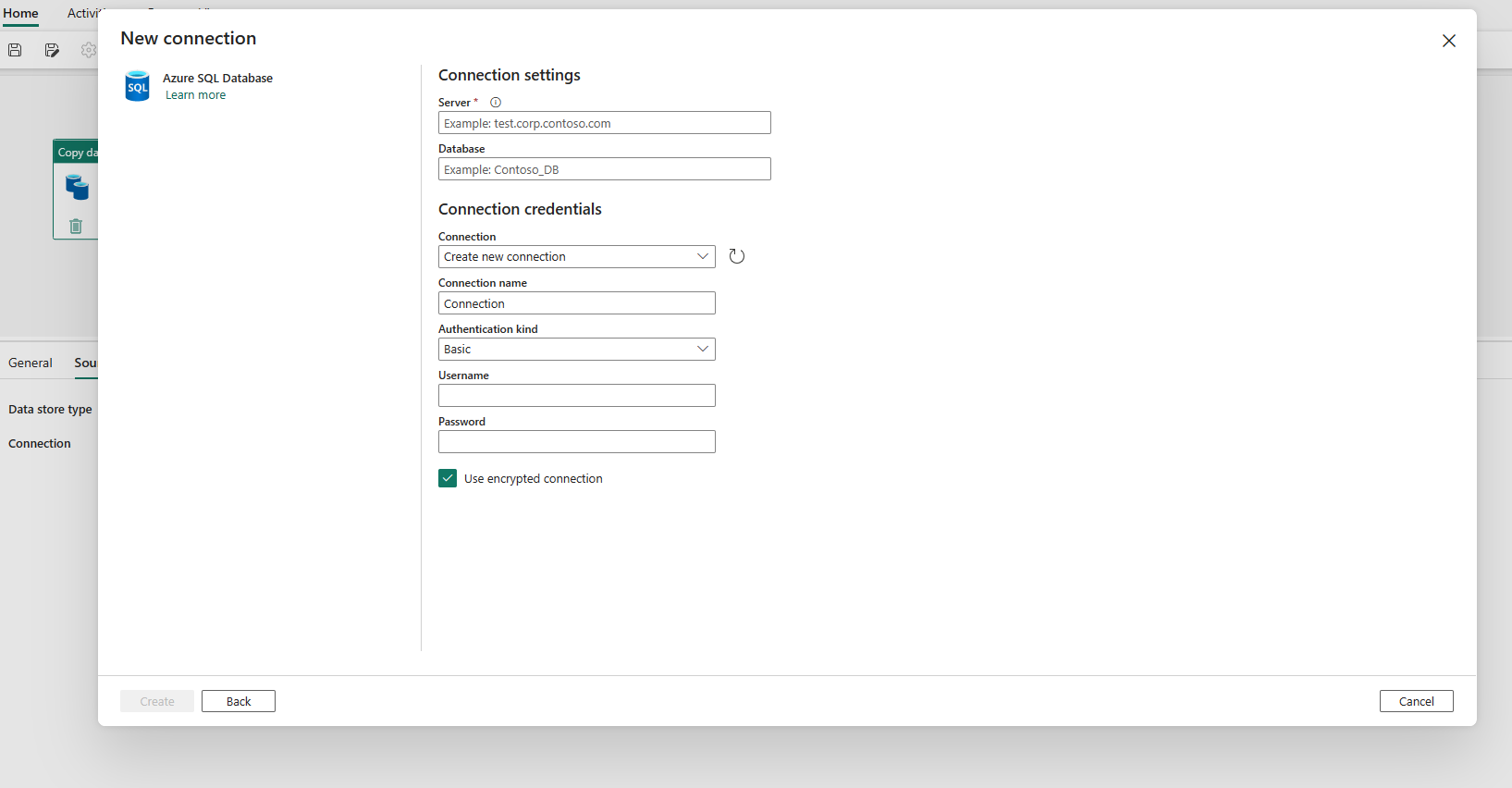
Zodra de verbinding is gemaakt, gaat u terug naar de gegevenspijplijnpagina. Selecteer Vervolgens Vernieuwen om de verbinding op te halen die u hebt gemaakt in de vervolgkeuzelijst. U kunt ook rechtstreeks in de vervolgkeuzelijst een bestaande Azure SQL Database-verbinding kiezen als u deze al hebt gemaakt. De mogelijkheden van Verbinding testen en Bewerken zijn beschikbaar voor elke geselecteerde verbinding. Selecteer vervolgens Azure SQL Database in verbindingstype .
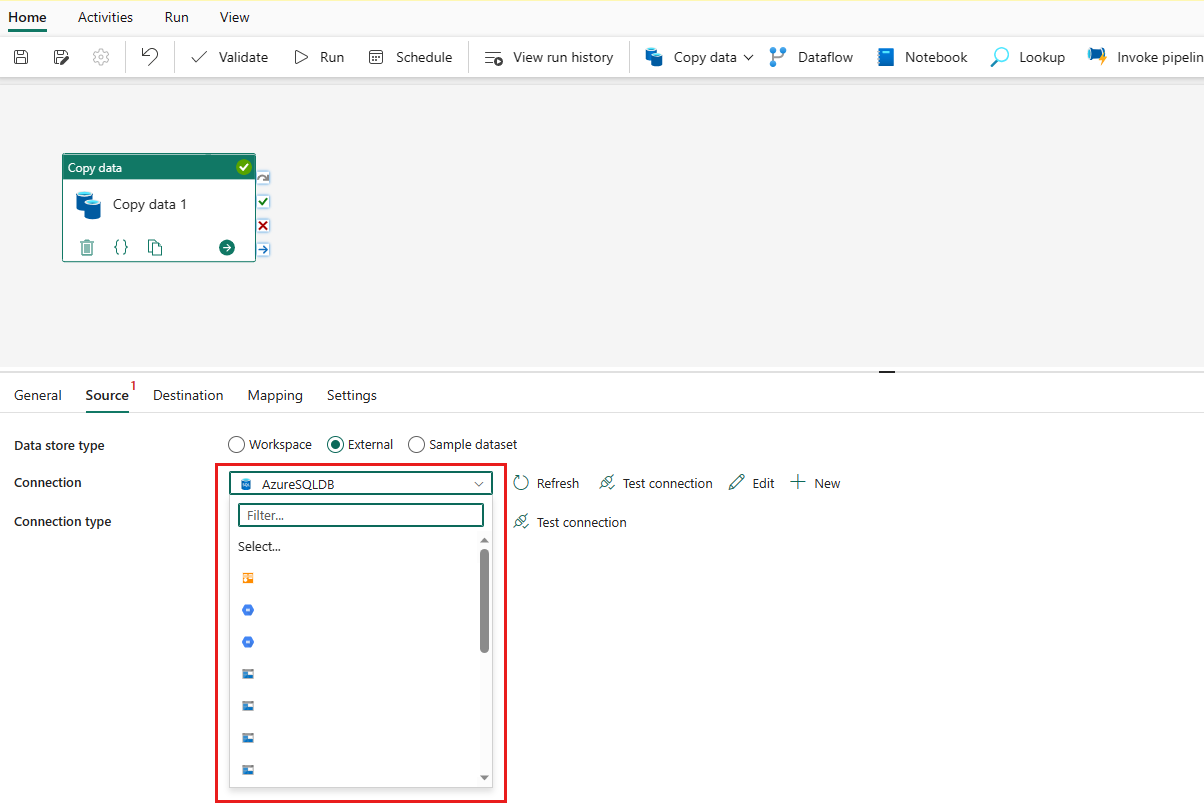
Geef een tabel op die moet worden gekopieerd. Selecteer Voorbeeldgegevens om een voorbeeld van uw brontabel te bekijken. U kunt ook de query- en opgeslagen procedure gebruiken om gegevens uit uw bron te lezen.
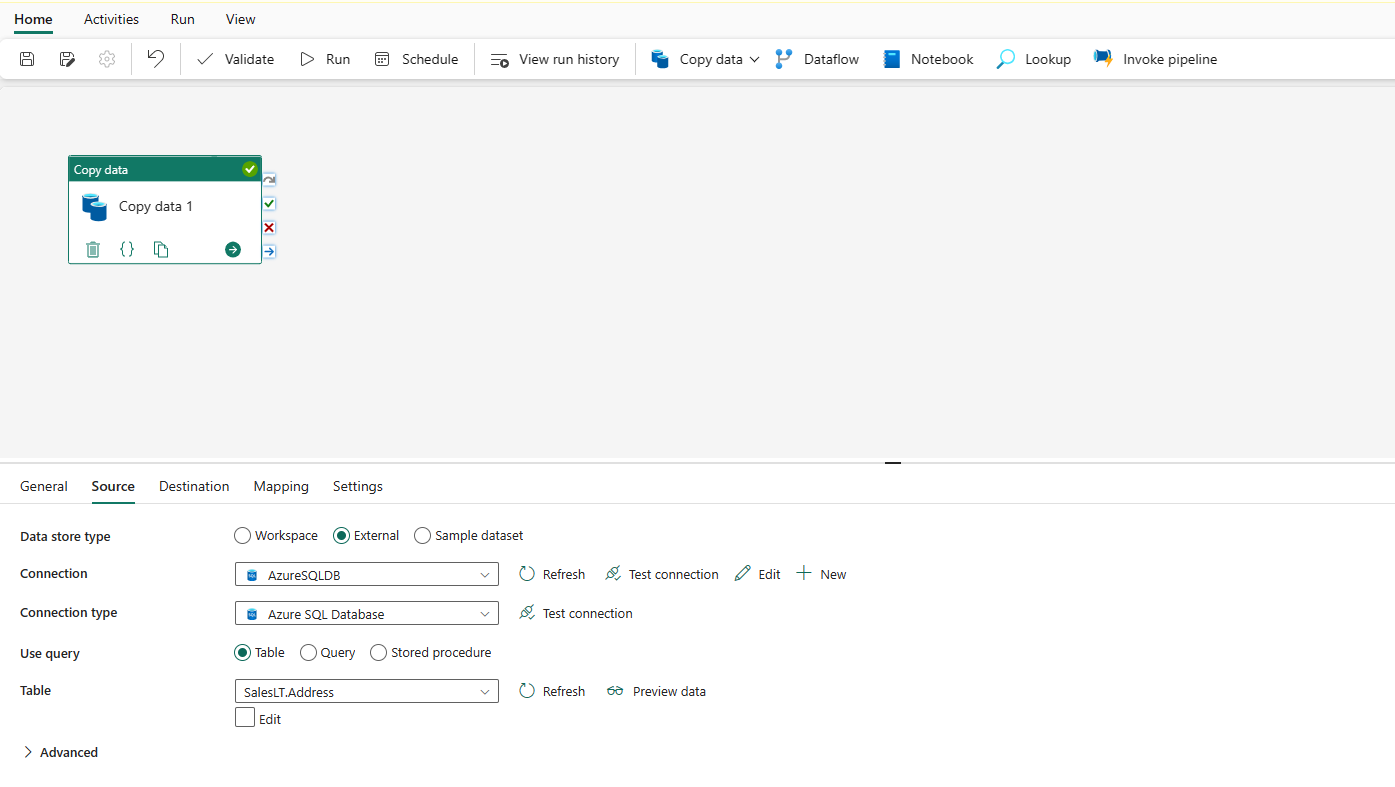
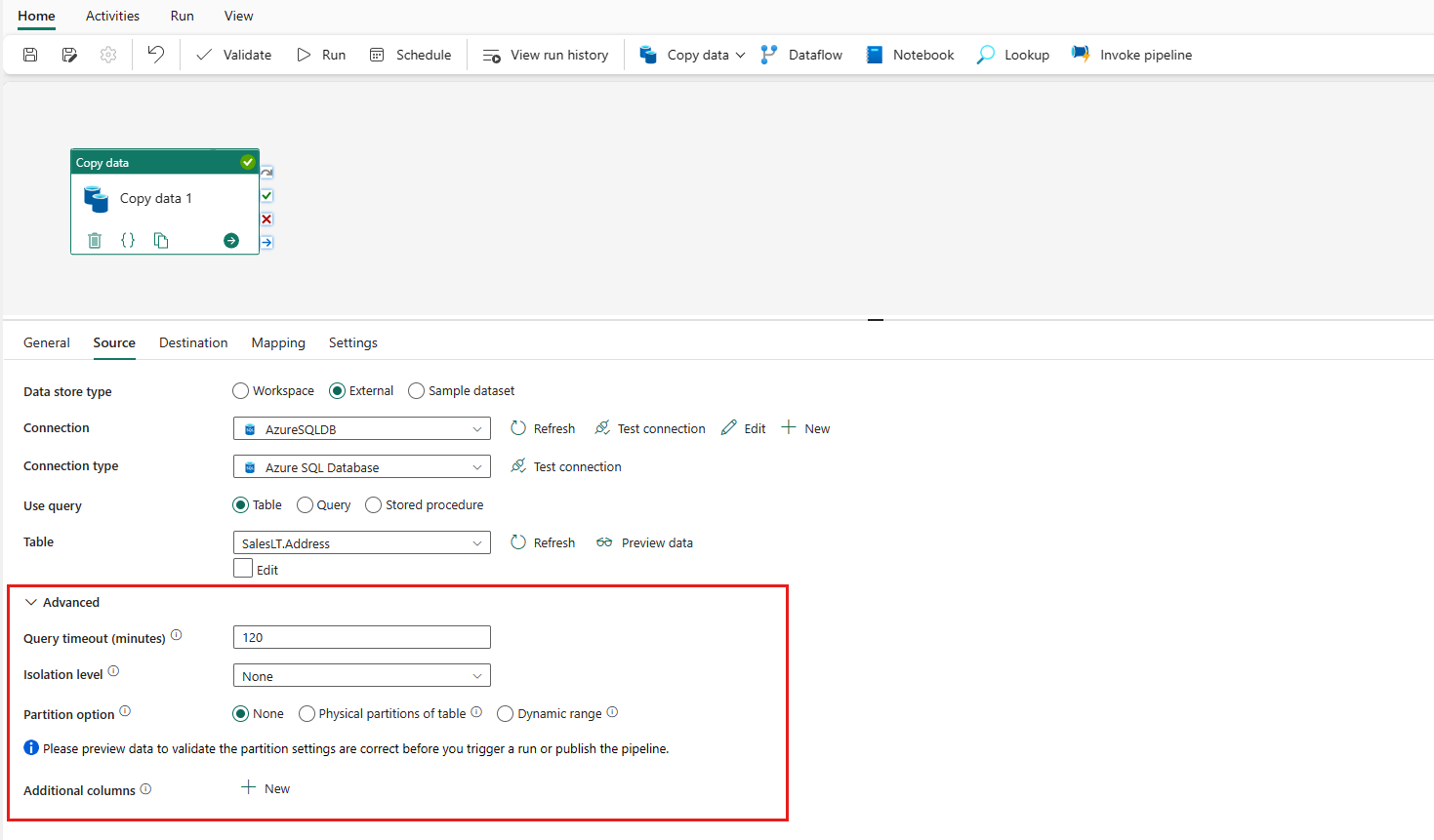
Vouw Geavanceerd uit voor meer geavanceerde instellingen.






Uw bestemming configureren op het doeltabblad
Kies uw doeltype. Dit kan uw interne eersteklas gegevensarchief zijn vanuit uw werkruimte, zoals Lakehouse of uw externe gegevensarchieven. U gebruikt Lakehouse als voorbeeld.
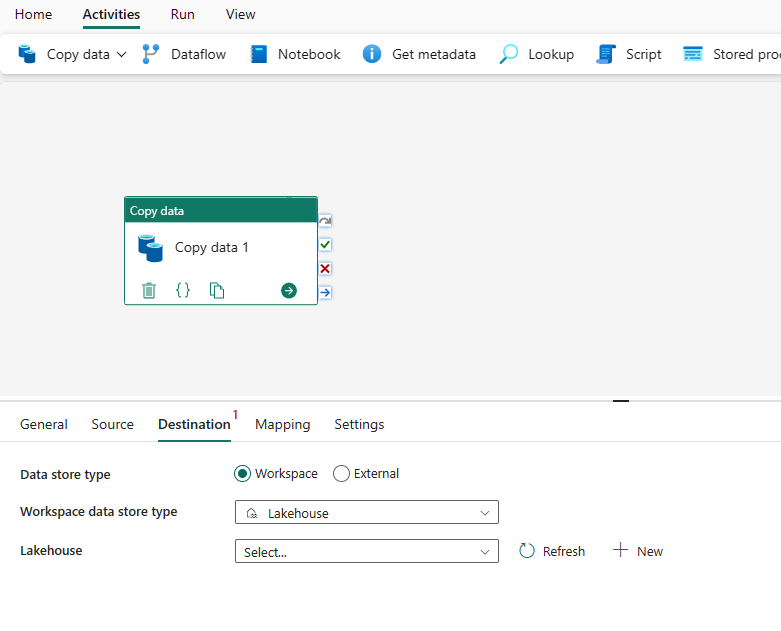
Kies ervoor om Lakehouse te gebruiken in het gegevensarchieftype Werkruimte. Selecteer + Nieuw en hiermee gaat u naar de pagina voor het maken van Lakehouse. Geef uw Lakehouse-naam op en selecteer Vervolgens Maken.
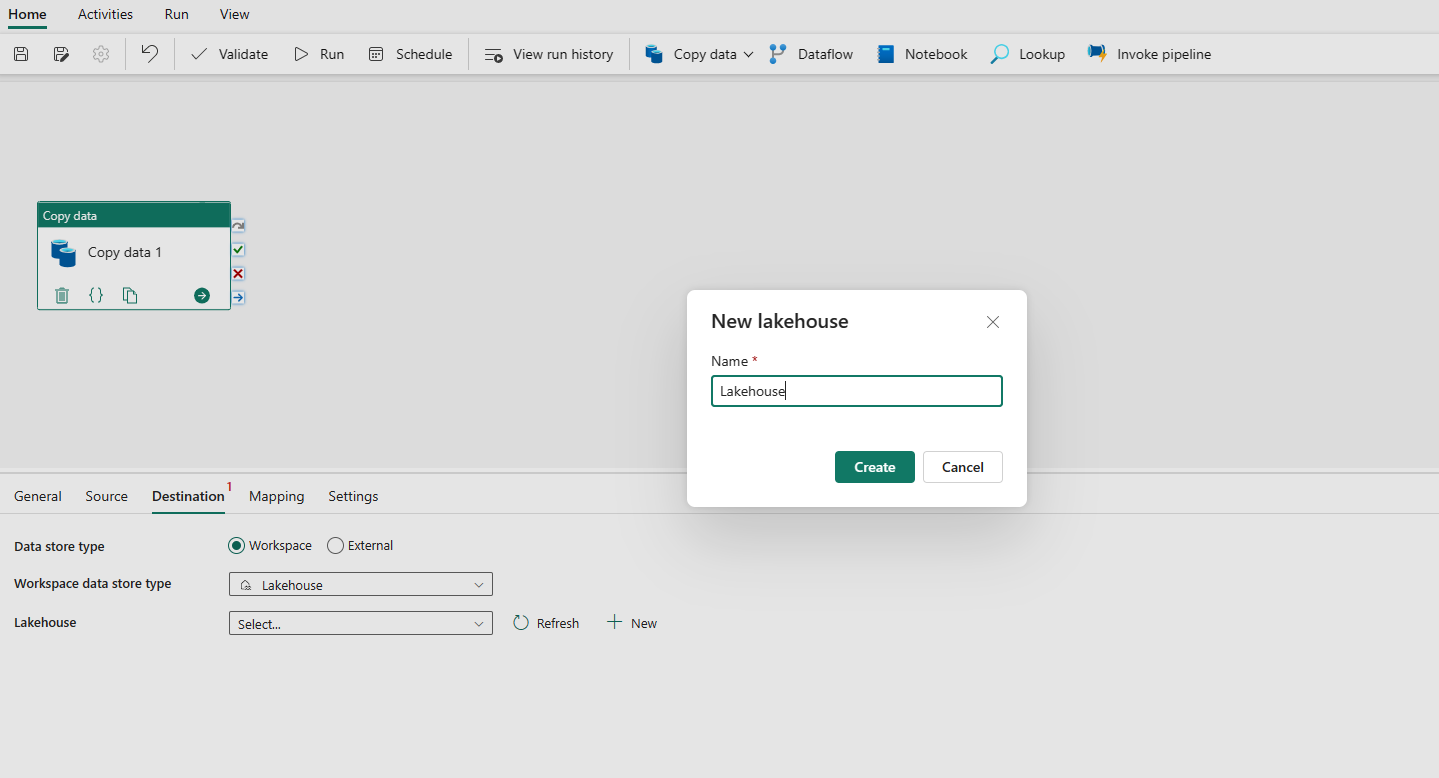
Zodra de verbinding is gemaakt, gaat u terug naar de gegevenspijplijnpagina. Selecteer Vervolgens Vernieuwen om de verbinding op te halen die u hebt gemaakt in de vervolgkeuzelijst. U kunt ook een bestaande Lakehouse-verbinding in de vervolgkeuzelijst rechtstreeks kiezen als u deze al eerder hebt gemaakt.
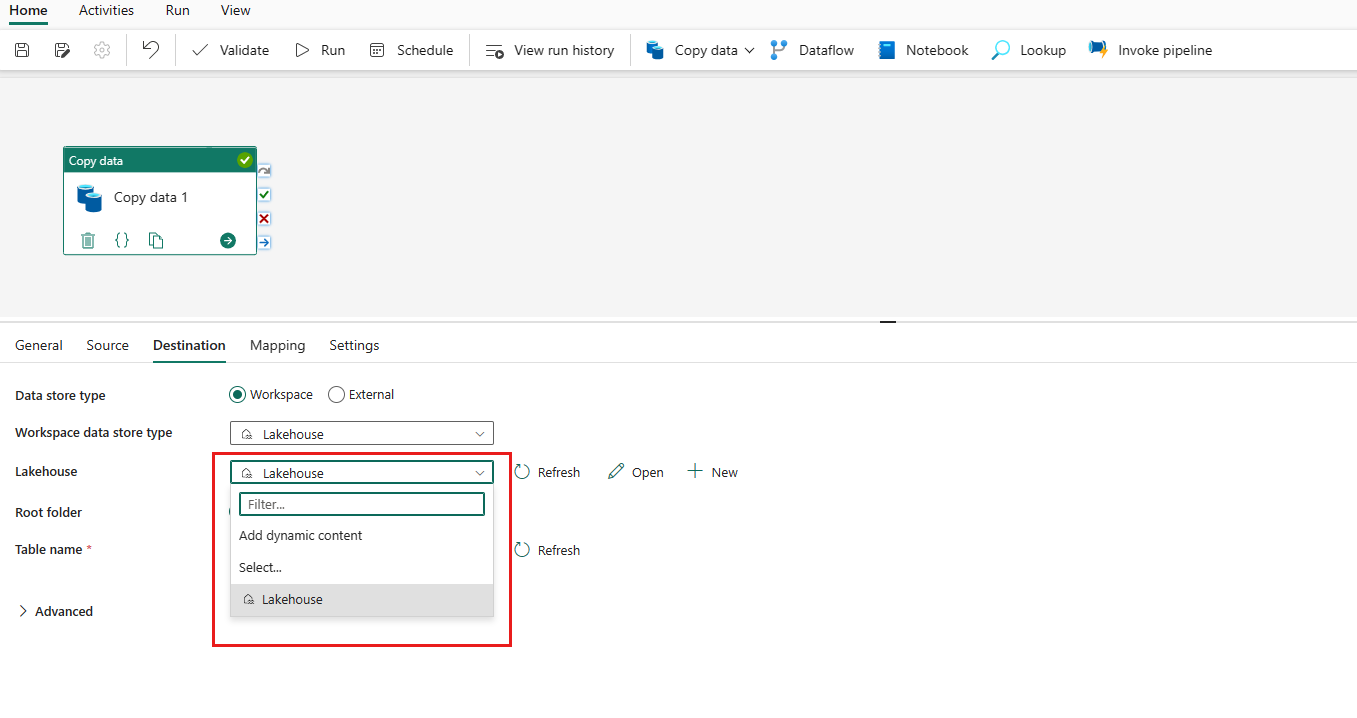
Geef een tabel op of stel het bestandspad in om het bestand of de map als doel te definiëren. Selecteer hier Tabellen en geef een tabel op om gegevens te schrijven.
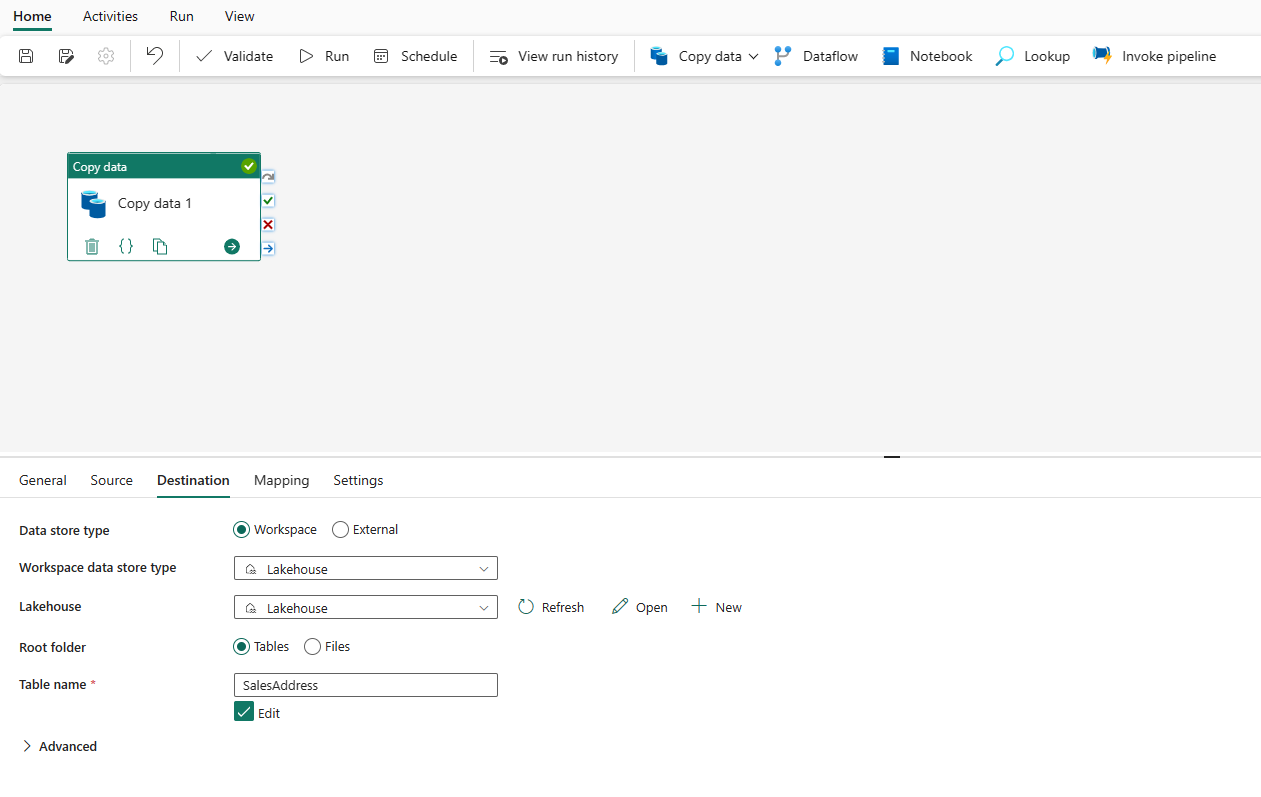
Vouw Geavanceerd uit voor meer geavanceerde instellingen.
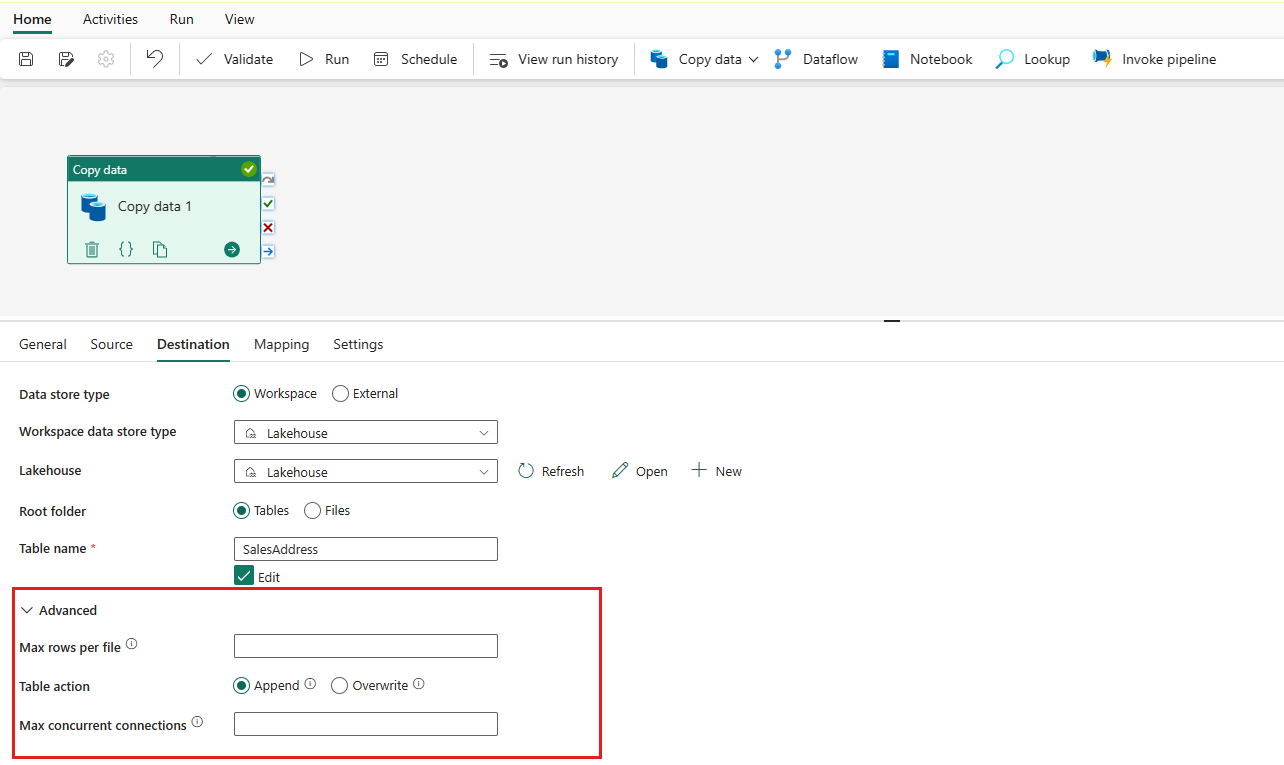





U kunt nu uw gegevenspijplijn opslaan met deze enkele kopieeractiviteit of doorgaan met het ontwerpen van uw gegevenspijplijn.
Uw toewijzingen configureren op het tabblad Toewijzing
Als de connector die u toepast ondersteuning biedt voor toewijzing, gaat u naar het tabblad Toewijzing om uw toewijzing te configureren.
Selecteer Schema's importeren om uw gegevensschema te importeren.
U kunt zien dat de automatische toewijzing wordt weergegeven. Geef de kolom Bron en de doelkolom op. Als u een nieuwe tabel in het doel maakt, kunt u hier de naam van de doelkolom aanpassen. Als u gegevens naar de bestaande doeltabel wilt schrijven, kunt u de naam van de bestaande doelkolom niet wijzigen. U kunt ook het type bron- en doelkolommen weergeven.
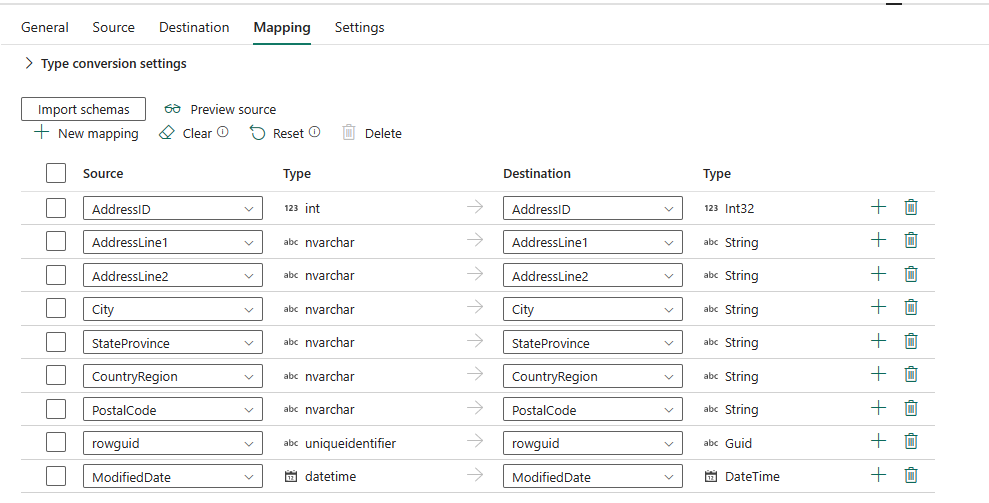


Bovendien kunt u + Nieuwe toewijzing selecteren om nieuwe toewijzing toe te voegen, wissen om alle toewijzingsinstellingen te wissen en Opnieuw instellen selecteren om alle toewijzingsbronkolom opnieuw in te stellen.
Uw andere instellingen configureren op het tabblad Instellingen
Het tabblad Instellingen bevat de instellingen van prestaties, fasering, enzovoort.

Zie de volgende tabel voor de beschrijving van elke instelling.
| Instelling | Beschrijving | JSON-scripteigenschap |
|---|---|---|
| Intelligente doorvoeroptimalisatie | Geef op om de doorvoer te optimaliseren. U kunt kiezen uit: • Automatisch • Standaard • Evenwichtig • Maximum Wanneer u Auto kiest, wordt de optimale instelling dynamisch toegepast op basis van uw bron-doelpaar en gegevenspatroon. U kunt ook uw doorvoer aanpassen en aangepaste waarde kan 2-256 zijn, terwijl een hogere waarde meer winst impliceert. |
dataIntegrationUnits |
| Mate van kopieerparallelisme | Geef de mate van parallelle uitvoering op die wordt gebruikt voor het laden van gegevens. | parallelcopies |
| Fouttolerantie | Wanneer u deze optie selecteert, kunt u enkele fouten negeren die tijdens het kopieerproces zijn opgetreden. Bijvoorbeeld incompatibele rijen tussen bron- en doelopslag, bestand dat wordt verwijderd tijdens gegevensverplaatsing, enzovoort. | • enableSkipIncompatibleRow • skipErrorFile: fileMissing fileForbidden invalidFileName |
| Logboekregistratie inschakelen | Wanneer u deze optie selecteert, kunt u gekopieerde bestanden vastleggen, bestanden en rijen overgeslagen. | / |
| Fasering inschakelen | Geef op of u gegevens wilt kopiëren via een tussentijdse faseringsopslag. Schakel fasering alleen in voor de gunstige scenario's. | enableStaging |
| Gegevensarchieftype | Wanneer u fasering inschakelt, kunt u Werkruimte en Extern kiezen als gegevensarchieftype. | / |
| Voor werkruimte | ||
| Werkruimte | Geef op dat u ingebouwde faseringsopslag wilt gebruiken. | / |
| Voor extern | ||
| Verbinding met faseringsaccount | Geef de verbinding op van een Azure Blob Storage of Azure Data Lake Storage Gen2, die verwijst naar het exemplaar van Storage dat u gebruikt als een tijdelijke faseringsopslag. Maak een faseringsverbinding als u deze niet hebt. | verbinding (onder externalReferences) |
| Opslagpad | Geef het pad op dat u de gefaseerde gegevens wilt bevatten. Als u geen pad opgeeft, maakt de service een container voor het opslaan van tijdelijke gegevens. Geef alleen een pad op als u Opslag gebruikt met een handtekening voor gedeelde toegang of als u tijdelijke gegevens op een specifieke locatie wilt plaatsen. | path |
| Compressie inschakelen | Hiermee geeft u op of gegevens moeten worden gecomprimeerd voordat ze naar de bestemming worden gekopieerd. Deze instelling vermindert het aantal gegevens dat wordt overgedragen. | enableCompression |
| Bewaren | Geef op of metagegevens/ACL's moeten worden bewaard tijdens het kopiëren van gegevens. | bewaren |
Notitie
Als u gefaseerde kopie gebruikt met compressie ingeschakeld, wordt de verificatie van de service-principal voor faseringsblobverbinding niet ondersteund.
Parameters configureren in een kopieeractiviteit
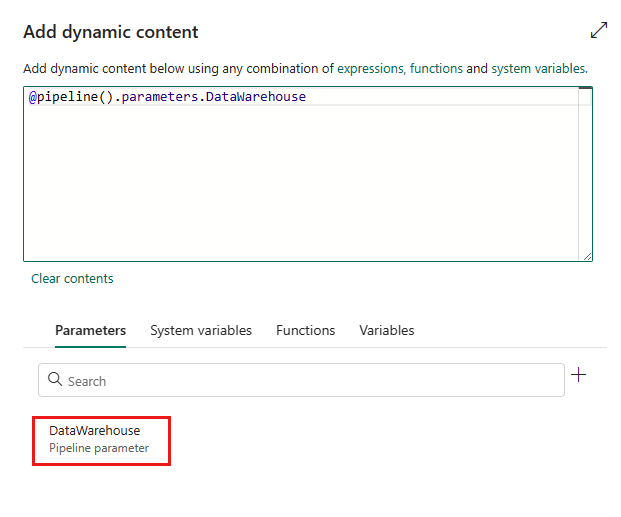
Parameters kunnen worden gebruikt om het gedrag van een pijplijn en de bijbehorende activiteiten te beheren. U kunt dynamische inhoud toevoegen gebruiken om parameters op te geven voor de eigenschappen van de kopieeractiviteit. Laten we lakehouse/datawarehouse/KQL-database als voorbeeld opgeven om te zien hoe u deze kunt gebruiken.
Selecteer in uw bron of doel, nadat u Werkruimte als gegevensarchieftype hebt geselecteerd en Lakehouse/Data Warehouse/KQL-database hebt opgegeven als gegevensarchieftype werkruimte, dynamische inhoud toevoegen in de vervolgkeuzelijst van Lakehouse of Data Warehouse of KQL Database.
Selecteer in het pop-upvenster Dynamische inhoud toevoegen, onder het tabblad Parameters , de optie +.
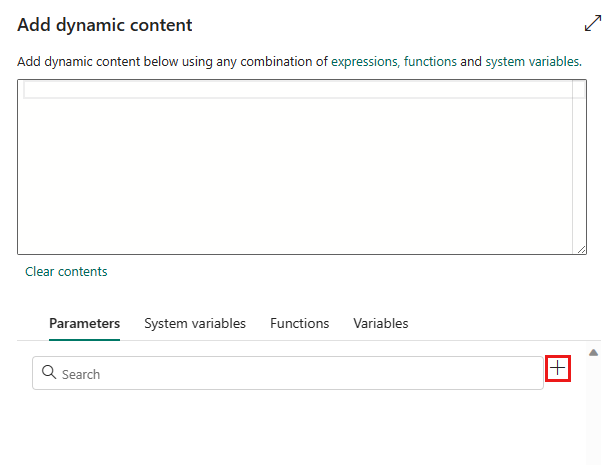
Geef de naam voor de parameter op en geef deze desgewenst een standaardwaarde op, of u kunt de waarde voor de parameter opgeven nadat u Uitvoeren in de pijplijn hebt geselecteerd.

Houd er rekening mee dat de parameterwaarde Lakehouse/Data Warehouse/KQL Database-object-id moet zijn. Als u uw Lakehouse/Data Warehouse/KQL Database-object-id wilt ophalen, opent u uw Lakehouse-/Data Warehouse/KQL-database in uw werkruimte en bevindt de id zich na
/lakehouses/of/datawarehouses//databases/in uw URL.Lakehouse-object-id:

Object-id datawarehouse:

KQL Database-object-id:

Selecteer Opslaan om terug te gaan naar het deelvenster Dynamische inhoud toevoegen. Selecteer vervolgens de parameter zodat deze wordt weergegeven in het expressievak. Selecteer vervolgens OK. U gaat terug naar de pijplijnpagina en ziet dat de parameterexpressie is opgegeven na de object-id van het Lakehouse-object-id//KQL Database-object-id.