CREATE EXTERNAL TABLE (Transact-SQL)
Hiermee maakt u een externe tabel.
Dit artikel bevat de syntaxis, argumenten, opmerkingen, machtigingen en voorbeelden voor het SQL-product dat u kiest.
Zie Transact-SQL syntaxisconventiesvoor meer informatie over de syntaxisconventies.
Een product selecteren
Selecteer in de volgende rij de productnaam waarin u geïnteresseerd bent en alleen de informatie van dat product wordt weergegeven.
* SQL Server *
Overzicht: SQL Server
Met deze opdracht maakt u een externe tabel voor PolyBase voor toegang tot gegevens die zijn opgeslagen in een Hadoop-cluster of een externe Azure Blob Storage PolyBase-tabel die verwijst naar gegevens die zijn opgeslagen in een Hadoop-cluster of Azure Blob Storage.
van toepassing op: SQL Server 2016 (of hoger)
Gebruik een externe tabel met een externe gegevensbron voor PolyBase-query's. Externe gegevensbronnen worden gebruikt om connectiviteit tot stand te brengen en deze primaire use cases te ondersteunen:
- Gegevensvirtualisatie en gegevensbelasting met PolyBase-
- Bewerkingen voor bulksgewijs laden met behulp van SQL Server of SQL Database met behulp van
BULK INSERTofOPENROWSET
Zie ook CREATE EXTERNAL DATA SOURCE en DROP EXTERNAL TABLE.
Syntaxis
-- Create a new external table
CREATE EXTERNAL TABLE { database_name.schema_name.table_name | schema_name.table_name | table_name }
( <column_definition> [ ,...n ] )
WITH (
LOCATION = 'folder_or_filepath',
DATA_SOURCE = external_data_source_name,
[ FILE_FORMAT = external_file_format_name ]
[ , <reject_options> [ ,...n ] ]
)
[;]
<reject_options> ::=
{
| REJECT_TYPE = value | percentage
| REJECT_VALUE = reject_value
| REJECT_SAMPLE_VALUE = reject_sample_value,
| REJECTED_ROW_LOCATION = '/REJECT_Directory'
}
<column_definition> ::=
column_name <data_type>
[ COLLATE collation_name ]
[ NULL | NOT NULL ]
Argumenten
{ database_name.schema_name.table_name | schema_name.table_name | table_name }
De naam van één tot drie delen van de tabel die u wilt maken. Voor een externe tabel slaat SQL alleen de metagegevens van de tabel op, samen met basisstatistieken over het bestand of de map waarnaar wordt verwezen in Hadoop of Azure Blob Storage. Er worden geen werkelijke gegevens verplaatst of opgeslagen in SQL Server.
Belangrijk
Als het stuurprogramma van de externe gegevensbron een driedelige naam ondersteunt, wordt het ten zeerste aangeraden om de driedelige naam op te geven.
<column_definition> [ ,...n ]
CREATE EXTERNAL TABLE biedt ondersteuning voor de mogelijkheid om kolomnaam, gegevenstype, null-functionaliteit en sortering te configureren. U kunt de STANDAARDBEPERKING niet gebruiken voor externe tabellen.
De kolomdefinities, inclusief de gegevenstypen en het aantal kolommen, moeten overeenkomen met de gegevens in de externe bestanden. Als er sprake is van een onjuiste overeenkomst, worden de bestandsrijen geweigerd bij het opvragen van de werkelijke gegevens.
LOCATION = 'folder_or_filepath'
Hiermee geeft u de map of het bestandspad en de bestandsnaam op voor de werkelijke gegevens in Hadoop of Azure Blob Storage. Daarnaast wordt S3-compatibele objectopslag ondersteund vanaf SQL Server 2022 (16.x)). De locatie begint vanuit de hoofdmap. De hoofdmap is de gegevenslocatie die is opgegeven in de externe gegevensbron.
In SQL Server maakt de CREATE EXTERNAL TABLE instructie het pad en de map als deze nog niet bestaat. Vervolgens kunt u INSERT INTO gebruiken om gegevens uit een lokale SQL Server-tabel te exporteren naar de externe gegevensbron. Zie PolyBase-query'svoor meer informatie.
Als u LOCATION opgeeft als een map, haalt een PolyBase-query die uit de externe tabel selecteert bestanden op uit de map en alle bijbehorende submappen. Net als Hadoop retourneert PolyBase geen verborgen mappen. Het retourneert ook geen bestanden waarvoor de bestandsnaam begint met een onderstreping (_) of een punt (.).
Als LOCATION='/webdata/'in het volgende afbeeldingsvoorbeeld retourneert een PolyBase-query rijen uit mydata.txt en mydata2.txt. Het retourneert geen mydata3.txt omdat het een bestand in een verborgen submap is. En het retourneert geen _hidden.txt omdat het een verborgen bestand is.
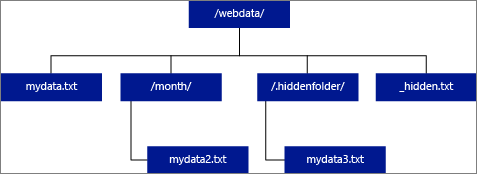
Als u de standaardinstelling wilt wijzigen en alleen wilt lezen uit de hoofdmap, stelt u het kenmerk <polybase.recursive.traversal> in op 'false' in het core-site.xml configuratiebestand. Dit bestand bevindt zich onder <SqlBinRoot>\PolyBase\Hadoop\Conf onder de bin hoofdmap van SQL Server. Bijvoorbeeld C:\Program Files\Microsoft SQL Server\MSSQL13.XD14\MSSQL\Binn.
DATA_SOURCE = external_data_source_name
Hiermee geeft u de naam op van de externe gegevensbron die de locatie van de externe gegevens bevat. Deze locatie is een Hadoop File System (HDFS), een Azure Blob Storage-container of Azure Data Lake Store. Als u een externe gegevensbron wilt maken, gebruikt u CREATE EXTERNAL DATA SOURCE.
FILE_FORMAT = external_file_format_name
Hiermee geeft u de naam op van het externe bestandsindelingsobject waarin het bestandstype en de compressiemethode voor de externe gegevens worden opgeslagen. Als u een externe bestandsindeling wilt maken, gebruikt u CREATE EXTERNAL FILE FORMAT.
Externe bestandsindelingen kunnen opnieuw worden gebruikt door meerdere vergelijkbare externe bestanden.
Opties voor weigeren
Deze optie kan alleen worden gebruikt met externe gegevensbronnen waarbij TYPE = HADOOP.
U kunt weigeringsparameters opgeven die bepalen hoe PolyBase vuile records verwerkt die worden opgehaald uit de externe gegevensbron. Een gegevensrecord wordt beschouwd als 'vuil' als het werkelijke gegevenstypen of het aantal kolommen niet overeenkomt met de kolomdefinities van de externe tabel.
Wanneer u geen afkeuringswaarden opgeeft of wijzigt, gebruikt PolyBase standaardwaarden. Deze informatie over de geweigerde parameters wordt opgeslagen als aanvullende metagegevens wanneer u een externe tabel maakt met de instructie CREATE EXTERNAL TABLE. Wanneer een toekomstige SELECT-instructie of SELECT INTO SELECT-instructie gegevens uit de externe tabel selecteert, gebruikt PolyBase de opties voor weigeren om het aantal of het percentage rijen te bepalen dat kan worden geweigerd voordat de werkelijke query mislukt. De query retourneert (gedeeltelijke) resultaten totdat de drempelwaarde voor weigeren is overschreden. Het mislukt vervolgens met het juiste foutbericht.
REJECT_TYPE = waarde | percentage
Verduidelijkt of de optie REJECT_VALUE is opgegeven als een letterlijke waarde of een percentage.
waarde
REJECT_VALUE is een letterlijke waarde, geen percentage. De query mislukt wanneer het aantal geweigerde rijen groter is dan reject_value.
Als bijvoorbeeld REJECT_VALUE = 5 en REJECT_TYPE = value, mislukt de SELECT-query nadat vijf rijen zijn geweigerd.
percentage
REJECT_VALUE is een percentage, geen letterlijke waarde. Een query mislukt wanneer het percentage mislukte rijen groter is dan reject_value. Het percentage mislukte rijen wordt berekend met intervallen.
REJECT_VALUE = reject_value
Hiermee geeft u de waarde of het percentage rijen op dat kan worden geweigerd voordat de query mislukt.
Voor REJECT_TYPE = waarde moet reject_value een geheel getal tussen 0 en 2.147.483.647 zijn.
Voor REJECT_TYPE = percentage moet reject_value een float tussen 0 en 100 zijn.
REJECT_SAMPLE_VALUE = reject_sample_value
Dit kenmerk is vereist wanneer u REJECT_TYPE = percentage opgeeft. Het bepaalt het aantal rijen dat moet worden opgehaald voordat polybase het percentage geweigerde rijen opnieuw berekent.
De parameter reject_sample_value moet een geheel getal tussen 0 en 2.147.483.647 zijn.
Als bijvoorbeeld REJECT_SAMPLE_VALUE = 1000, berekent PolyBase het percentage mislukte rijen nadat is geprobeerd 1000 rijen uit het externe gegevensbestand te importeren. Als het percentage mislukte rijen kleiner is dan reject_value, probeert PolyBase nog eens 1000 rijen op te halen. Het percentage mislukte rijen wordt nog steeds herberekend nadat wordt geprobeerd om elke extra 1000 rijen te importeren.
Notitie
Omdat PolyBase het percentage mislukte rijen berekent met intervallen, kan het werkelijke percentage mislukte rijen groter zijn dan reject_value.
Voorbeeld:
In dit voorbeeld ziet u hoe de drie weigeringsopties met elkaar communiceren. Als bijvoorbeeld REJECT_TYPE = percentage, REJECT_VALUE = 30 en REJECT_SAMPLE_VALUE = 100, kan het volgende scenario optreden:
- PolyBase probeert de eerste 100 rijen op te halen; 25 mislukken en 75 slagen.
- Het percentage mislukte rijen wordt berekend als 25%, wat kleiner is dan de weigeringswaarde van 30%. Als gevolg hiervan blijft PolyBase gegevens ophalen uit de externe gegevensbron.
- PolyBase probeert de volgende 100 rijen te laden; deze keer slagen 25 rijen en mislukken 75 rijen.
- Het percentage mislukte rijen wordt opnieuw berekend als 50%. Het percentage mislukte rijen heeft de waarde van 30% weigeren overschreden.
- De PolyBase-query mislukt met 50% geweigerde rijen na een poging om de eerste 200 rijen te retourneren. U ziet dat overeenkomende rijen zijn geretourneerd voordat de PolyBase-query detecteert dat de drempelwaarde voor weigeren is overschreden.
REJECTED_ROW_LOCATION = maplocatie
van toepassing op: SQL Server 2019 CU6 en latere versies, Azure Synapse Analytics.
Hiermee geeft u de map in de externe gegevensbron op dat de geweigerde rijen en het bijbehorende foutbestand moeten worden geschreven.
Als het opgegeven pad niet bestaat, maakt PolyBase er een namens u. Er wordt een onderliggende map gemaakt met de naam _rejectedrows. Het _ teken zorgt ervoor dat de map wordt ontsnapt voor andere gegevensverwerking, tenzij deze expliciet is benoemd in de locatieparameter. In deze map is er een map gemaakt op basis van het tijdstip van het indienen van de belasting in de indeling YearMonthDay -HourMinuteSecond (bijvoorbeeld 20230330-173205). In deze map worden twee typen bestanden geschreven, het _reason-bestand en het gegevensbestand. Deze optie kan alleen worden gebruikt met externe gegevensbronnen waarbij TYPE = HADOOP en voor externe tabellen met behulp van DELIMITEDTEXTFORMAT_TYPE. Zie CREATE EXTERNAL DATA SOURCE en CREATE EXTERNAL FILE FORMATvoor meer informatie.
De redenbestanden en de gegevensbestanden hebben beide de queryID gekoppeld aan de CTAS-instructie. Omdat de gegevens en de reden zich in afzonderlijke bestanden bevinden, hebben de bijbehorende bestanden een overeenkomend achtervoegsel.
Machtigingen
Hiervoor zijn deze gebruikersmachtigingen vereist:
- CREATE TABLE-
- ALLE SCHEMA- WIJZIGEN
- EEN EXTERNE GEGEVENSBRON WIJZIGEN
- ALTER ANY EXTERNAL FILE FORMAT (alleen van toepassing op Externe Gegevensbronnen van Hadoop en Azure Storage)
- CONTROL DATABASE- (alleen van toepassing op externe Hadoop- en Azure Storage-gegevensbronnen)
Opmerking: de externe aanmelding die is opgegeven in de DATABASE SCOPED CREDENTIAL die in de opdracht CREATE EXTERNAL TABLE wordt gebruikt, moet machtiging lezen hebben voor het pad/de tabel/verzameling van de externe gegevensbron die is opgegeven in de parameter LOCATION. Als u van plan bent om deze EXTERNE TABEL te gebruiken om gegevens te exporteren naar een externe Hadoop- of Azure Storage-gegevensbron, moet de opgegeven aanmelding schrijfmachtiging hebben voor het pad dat is opgegeven in LOCATION. Houd er rekening mee dat Hadoop niet wordt ondersteund in SQL Server 2022 (16.x).
Voor Azure Blob Storage configureert u bij het configureren van de toegangssleutels en SAS (Shared Access Signature) in Azure Portal de Azure Blob Storage- of ADLS Gen2-opslagaccounts de Toegestane machtigingen om ten minste lezen en machtigingen voor schrijven te verlenen. machtiging lijst kan ook vereist zijn bij het zoeken in verschillende mappen. U moet ook zowel Container als Object selecteren als de toegestane resourcetypen.
Belangrijk
Met de machtiging ALTER ANY EXTERNAL DATA SOURCE verleent elke principal de mogelijkheid om een extern gegevensbronobject te maken en te wijzigen, waardoor het ook de mogelijkheid verleent om toegang te krijgen tot alle referenties binnen het databasebereik. Deze machtiging moet worden beschouwd als zeer bevoegd en moet daarom alleen worden verleend aan vertrouwde principals in het systeem.
Foutafhandeling
Tijdens het uitvoeren van de CREATE EXTERNAL TABLE-instructie probeert PolyBase verbinding te maken met de externe gegevensbron. Als de poging om verbinding te maken mislukt, mislukt de instructie en wordt de externe tabel niet gemaakt. Het kan een minuut of langer duren voordat de opdracht mislukt, omdat PolyBase de verbinding opnieuw probeert uit te voeren voordat de query uiteindelijk mislukt.
Opmerkingen
In ad-hocqueryscenario's, zoals SELECT FROM EXTERNAL TABLE, slaat PolyBase de rijen op die worden opgehaald uit de externe gegevensbron in een tijdelijke tabel. Nadat de query is voltooid, verwijdert PolyBase de tijdelijke tabel en verwijdert deze. Er worden geen permanente gegevens opgeslagen in SQL-tabellen.
In het importscenario, zoals SELECT INTO FROM EXTERNAL TABLE, slaat PolyBase daarentegen de rijen op die uit de externe gegevensbron worden opgehaald als permanente gegevens in de SQL-tabel. De nieuwe tabel wordt gemaakt tijdens het uitvoeren van query's wanneer PolyBase de externe gegevens ophaalt.
PolyBase kan een deel van de queryberekening naar Hadoop pushen om de queryprestaties te verbeteren. Deze actie wordt predicaatpushdown genoemd. Als u dit wilt inschakelen, geeft u de locatieoptie Hadoop resource manager op in CREATE EXTERNAL DATA SOURCE.
U kunt veel externe tabellen maken die verwijzen naar dezelfde of verschillende externe gegevensbronnen.
Beperkingen en beperkingen
Omdat de gegevens voor een externe tabel niet onder het directe beheer van SQL Server staan, kunnen deze op elk gewenst moment door een extern proces worden gewijzigd of verwijderd. Als gevolg hiervan zijn queryresultaten voor een externe tabel niet gegarandeerd deterministisch. Dezelfde query kan verschillende resultaten retourneren telkens wanneer deze wordt uitgevoerd op een externe tabel. Op dezelfde manier kan een query mislukken als de externe gegevens worden verplaatst of verwijderd.
U kunt meerdere externe tabellen maken die elk verwijzen naar verschillende externe gegevensbronnen. Als u gelijktijdig query's uitvoert op verschillende Hadoop-gegevensbronnen, moet elke Hadoop-bron dezelfde configuratie-instelling voor hadoop-connectiviteit gebruiken. U kunt bijvoorbeeld geen query tegelijk uitvoeren op een Cloudera Hadoop-cluster en een Hortonworks Hadoop-cluster, omdat deze verschillende configuratie-instellingen gebruiken. Zie PolyBase Connectivity Configurationvoor de configuratie-instellingen en ondersteunde combinaties.
Wanneer de externe tabel gebruikmaakt van DELIMITEDTEXT, CSV, PARQUETof DELTA als gegevenstypen, ondersteunen externe tabellen alleen statistieken voor één kolom per CREATE STATISTICS opdracht.
Alleen deze DDL-instructies (Data Definition Language) zijn toegestaan voor externe tabellen:
- CREATE TABLE en DROP TABLE
- STATISTIEKEN MAKEN EN STATISTIEKEN VERWIJDEREN
- WEERGAVE EN DROP VIEW MAKEN
Constructies en bewerkingen worden niet ondersteund:
- De standaardbeperking voor externe tabelkolommen
- DML-bewerkingen (Data Manipulation Language) voor verwijderen, invoegen en bijwerken
Querybeperkingen
PolyBase kan maximaal 33.000 bestanden per map gebruiken bij het uitvoeren van 32 gelijktijdige PolyBase-query's. Dit maximumaantal omvat zowel bestanden als submappen in elke HDFS-map. Als de mate van gelijktijdigheid kleiner is dan 32, kan een gebruiker PolyBase-query's uitvoeren op mappen in HDFS die meer dan 33k-bestanden bevatten. U wordt aangeraden externe bestandspaden kort te houden en niet meer dan 30k bestanden per HDFS-map te gebruiken. Wanneer er te veel bestanden naar worden verwezen, kan er een JVM-uitzondering (Java Virtual Machine) optreden.
Beperkingen voor tabelbreedte
PolyBase in SQL Server 2016 heeft een rijbreedtelimiet van 32 kB op basis van de maximale grootte van één geldige rij per tabeldefinitie. Als de som van het kolomschema groter is dan 32 kB, kan PolyBase geen query's uitvoeren op de gegevens.
Beperkingen voor gegevenstypen
De volgende gegevenstypen kunnen niet worden gebruikt in externe PolyBase-tabellen:
- geografie
- geometrie
- hierarchyid-
- afbeelding
- tekst
- xml--
- Elk door de gebruiker gedefinieerd type
Specifieke beperkingen voor gegevensbronnen
Orakel
Oracle-synoniemen worden niet ondersteund voor gebruik met PolyBase.
Externe tabellen voor MongoDB-verzamelingen die matrices bevatten
Als u externe tabellen wilt maken voor MongoDB-verzamelingen die matrices bevatten, moet u de extensie Data Virtualization voor Azure Data Studio gebruiken om een CREATE EXTERNAL TABLE-instructie te maken op basis van het schema dat is gedetecteerd door het PolyBase ODBC-stuurprogramma voor MongoDB. De afvlakkende acties worden automatisch uitgevoerd door het stuurprogramma. U kunt ook sp_data_source_objects (Transact-SQL) gebruiken om het verzamelingsschema (kolommen) te detecteren en de externe tabel handmatig te maken. De sp_data_source_table_columns opgeslagen procedure voert ook automatisch het platmaken uit via het PolyBase ODBC-stuurprogramma voor mongoDB-stuurprogramma. De datavirtualisatie-extensie voor Azure Data Studio en sp_data_source_table_columns dezelfde interne opgeslagen procedures gebruiken om een query uit te voeren op het externe schema.
Vergrendeling
Gedeelde vergrendeling op het OBJECT SCHEMARESOLUTION.
Veiligheid
De gegevensbestanden voor een externe tabel worden opgeslagen in Hadoop of Azure Blob Storage. Deze gegevensbestanden worden gemaakt en beheerd door uw eigen processen. Het is uw verantwoordelijkheid om de beveiliging van de externe gegevens te beheren.
Voorbeelden
Een. Een externe tabel maken met gegevens in tekstscheidingstekens
In dit voorbeeld ziet u alle stappen die nodig zijn voor het maken van een externe tabel met gegevens die zijn opgemaakt in door tekst gescheiden bestanden. Het definieert een externe gegevensbron mydatasource en een externe bestandsindeling myfileformat. Deze objecten op databaseniveau worden vervolgens in de CREATE EXTERNAL TABLE-instructie verwezen. Zie CREATE EXTERNAL DATA SOURCE en CREATE EXTERNAL FILE FORMATvoor meer informatie.
CREATE EXTERNAL DATA SOURCE mydatasource
WITH (
TYPE = HADOOP,
LOCATION = 'hdfs://xxx.xxx.xxx.xxx:8020'
)
CREATE EXTERNAL FILE FORMAT myfileformat
WITH (
FORMAT_TYPE = DELIMITEDTEXT,
FORMAT_OPTIONS (FIELD_TERMINATOR ='|')
);
CREATE EXTERNAL TABLE ClickStream (
url varchar(50),
event_date date,
user_IP varchar(50)
)
WITH (
LOCATION='/webdata/employee.tbl',
DATA_SOURCE = mydatasource,
FILE_FORMAT = myfileformat
)
;
B. Een externe tabel maken met gegevens in RCFile-indeling
In dit voorbeeld ziet u alle stappen die nodig zijn voor het maken van een externe tabel met gegevens die zijn opgemaakt als RCFiles. Het definieert een externe gegevensbron mydatasource_rc en een externe bestandsindeling myfileformat_rc. Deze objecten op databaseniveau worden vervolgens in de CREATE EXTERNAL TABLE-instructie verwezen. Zie CREATE EXTERNAL DATA SOURCE en CREATE EXTERNAL FILE FORMATvoor meer informatie.
CREATE EXTERNAL DATA SOURCE mydatasource_rc
WITH (
TYPE = HADOOP,
LOCATION = 'hdfs://xxx.xxx.xxx.xxx:8020'
)
CREATE EXTERNAL FILE FORMAT myfileformat_rc
WITH (
FORMAT_TYPE = RCFILE,
SERDE_METHOD = 'org.apache.hadoop.hive.serde2.columnar.LazyBinaryColumnarSerDe'
)
;
CREATE EXTERNAL TABLE ClickStream_rc (
url varchar(50),
event_date date,
user_ip varchar(50)
)
WITH (
LOCATION='/webdata/employee_rc.tbl',
DATA_SOURCE = mydatasource_rc,
FILE_FORMAT = myfileformat_rc
)
;
C. Een externe tabel maken met gegevens in ORC-indeling
In dit voorbeeld ziet u alle stappen die nodig zijn voor het maken van een externe tabel met gegevens die zijn opgemaakt als ORC-bestanden. Het definieert een externe gegevensbron mydatasource_orc en een externe bestandsindeling myfileformat_orc. Deze objecten op databaseniveau worden vervolgens in de CREATE EXTERNAL TABLE-instructie verwezen. Zie CREATE EXTERNAL DATA SOURCE en CREATE EXTERNAL FILE FORMATvoor meer informatie.
CREATE EXTERNAL DATA SOURCE mydatasource_orc
WITH (
TYPE = HADOOP,
LOCATION = 'hdfs://xxx.xxx.xxx.xxx:8020'
)
CREATE EXTERNAL FILE FORMAT myfileformat_orc
WITH (
FORMAT = ORC,
COMPRESSION = 'org.apache.hadoop.io.compress.SnappyCodec'
)
;
CREATE EXTERNAL TABLE ClickStream_orc (
url varchar(50),
event_date date,
user_ip varchar(50)
)
WITH (
LOCATION='/webdata/',
DATA_SOURCE = mydatasource_orc,
FILE_FORMAT = myfileformat_orc
)
;
D. Hadoop-gegevens opvragen
ClickStream is een externe tabel die verbinding maakt met het employee.tbl tekstbestand met scheidingstekens in een Hadoop-cluster. De volgende query ziet eruit als een query op basis van een standaardtabel. Deze query haalt echter gegevens op uit Hadoop en berekent vervolgens de resultaten.
SELECT TOP 10 (url) FROM ClickStream WHERE user_ip = 'xxx.xxx.xxx.xxx';
E. Hadoop-gegevens samenvoegen met SQL-gegevens
Deze query ziet eruit als een standaard-JOIN in twee SQL-tabellen. Het verschil is dat PolyBase de clickstream-gegevens van Hadoop ophaalt en deze vervolgens aan de UrlDescription tabel koppelt. De ene tabel is een externe tabel en de andere is een standaard SQL-tabel.
SELECT url.description
FROM ClickStream cs
JOIN UrlDescription url ON cs.url = url.name
WHERE cs.url = 'msdn.microsoft.com';
F. Gegevens uit Hadoop importeren in een SQL-tabel
In dit voorbeeld wordt een nieuwe SQL-tabel gemaakt ms_user waarmee het resultaat van een join tussen de standaard SQL-tabel user en de externe tabel permanent wordt opgeslagen ClickStream.
SELECT DISTINCT user.FirstName, user.LastName
INTO ms_user
FROM user INNER JOIN (
SELECT * FROM ClickStream WHERE cs.url = 'www.microsoft.com'
) AS ms
ON user.user_ip = ms.user_ip;
G. Een externe tabel maken voor SQL Server
Voordat u een databasereferentie in het bereik maakt, moet de gebruikersdatabase een hoofdsleutel hebben om de referentie te beveiligen. Zie CREATE MASTER KEY en CREATE DATABASE SCOPED CREDENTIALvoor meer informatie.
-- Create a Master Key
CREATE MASTER KEY ENCRYPTION BY PASSWORD = 'S0me!nfo';
GO
/* specify credentials to external data source
* IDENTITY: user name for external source.
* SECRET: password for external source.
*/
CREATE DATABASE SCOPED CREDENTIAL SqlServerCredentials
WITH IDENTITY = 'username', Secret = 'password';
GO
Maak een nieuwe externe gegevensbron met de naam SQLServerInstanceen een externe tabel met de naam sqlserver.customer:
/* LOCATION: Location string should be of format '<vendor>://<server>[:<port>]'.
* PUSHDOWN: specify whether computation should be pushed down to the source. ON by default.
* CREDENTIAL: the database scoped credential, created above.
*/
CREATE EXTERNAL DATA SOURCE SQLServerInstance
WITH (
LOCATION = 'sqlserver://SqlServer',
-- PUSHDOWN = ON | OFF,
CREDENTIAL = SQLServerCredentials
);
GO
CREATE SCHEMA sqlserver;
GO
/* LOCATION: sql server table/view in 'database_name.schema_name.object_name' format
* DATA_SOURCE: the external data source, created above.
*/
CREATE EXTERNAL TABLE sqlserver.customer(
C_CUSTKEY INT NOT NULL,
C_NAME VARCHAR(25) NOT NULL,
C_ADDRESS VARCHAR(40) NOT NULL,
C_NATIONKEY INT NOT NULL,
C_PHONE CHAR(15) NOT NULL,
C_ACCTBAL DECIMAL(15,2) NOT NULL,
C_MKTSEGMENT CHAR(10) NOT NULL,
C_COMMENT VARCHAR(117) NOT NULL
)
WITH (
LOCATION='tpch_10.dbo.customer',
DATA_SOURCE=SqlServerInstance
);
Ik. Een externe tabel maken voor Oracle
-- Create a Master Key
CREATE MASTER KEY ENCRYPTION BY PASSWORD = 'password';
/*
* Specify credentials to external data source
* IDENTITY: user name for external source.
* SECRET: password for external source.
*/
CREATE DATABASE SCOPED CREDENTIAL credential_name
WITH IDENTITY = 'username', Secret = 'password';
/*
* LOCATION: Location string should be of format '<vendor>://<server>[:<port>]'.
* PUSHDOWN: specify whether computation should be pushed down to the source. ON by default.
* CONNECTION_OPTIONS: Specify driver location
* CREDENTIAL: the database scoped credential, created above.
*/
CREATE EXTERNAL DATA SOURCE external_data_source_name
WITH (
LOCATION = 'oracle://<server address>[:<port>]',
-- PUSHDOWN = ON | OFF,
CREDENTIAL = credential_name)
/*
* LOCATION: Oracle table/view in '<database_name>.<schema_name>.<object_name>' format. Note this may be case sensitive in the Oracle database.
* DATA_SOURCE: the external data source, created above.
*/
CREATE EXTERNAL TABLE customers(
[O_ORDERKEY] DECIMAL(38) NOT NULL,
[O_CUSTKEY] DECIMAL(38) NOT NULL,
[O_ORDERSTATUS] CHAR COLLATE Latin1_General_BIN NOT NULL,
[O_TOTALPRICE] DECIMAL(15,2) NOT NULL,
[O_ORDERDATE] DATETIME2(0) NOT NULL,
[O_ORDERPRIORITY] CHAR(15) COLLATE Latin1_General_BIN NOT NULL,
[O_CLERK] CHAR(15) COLLATE Latin1_General_BIN NOT NULL,
[O_SHIPPRIORITY] DECIMAL(38) NOT NULL,
[O_COMMENT] VARCHAR(79) COLLATE Latin1_General_BIN NOT NULL
)
WITH (
LOCATION='DB1.mySchema.customer',
DATA_SOURCE= external_data_source_name
);
J. Een externe tabel maken voor Teradata
-- Create a Master Key
CREATE MASTER KEY ENCRYPTION BY PASSWORD = 'password';
/*
* Specify credentials to external data source
* IDENTITY: user name for external source.
* SECRET: password for external source.
*/
CREATE DATABASE SCOPED CREDENTIAL credential_name
WITH IDENTITY = 'username', Secret = 'password';
/* LOCATION: Location string should be of format '<vendor>://<server>[:<port>]'.
* PUSHDOWN: specify whether computation should be pushed down to the source. ON by default.
* CONNECTION_OPTIONS: Specify driver location
* CREDENTIAL: the database scoped credential, created above.
*/
CREATE EXTERNAL DATA SOURCE external_data_source_name
WITH (
LOCATION = teradata://<server address>[:<port>],
-- PUSHDOWN = ON | OFF,
CREDENTIAL =credential_name
);
/* LOCATION: Teradata table/view in '<database_name>.<object_name>' format
* DATA_SOURCE: the external data source, created above.
*/
CREATE EXTERNAL TABLE customer(
L_ORDERKEY INT NOT NULL,
L_PARTKEY INT NOT NULL,
L_SUPPKEY INT NOT NULL,
L_LINENUMBER INT NOT NULL,
L_QUANTITY DECIMAL(15,2) NOT NULL,
L_EXTENDEDPRICE DECIMAL(15,2) NOT NULL,
L_DISCOUNT DECIMAL(15,2) NOT NULL,
L_TAX DECIMAL(15,2) NOT NULL,
L_RETURNFLAG CHAR NOT NULL,
L_LINESTATUS CHAR NOT NULL,
L_SHIPDATE DATE NOT NULL,
L_COMMITDATE DATE NOT NULL,
L_RECEIPTDATE DATE NOT NULL,
L_SHIPINSTRUCT CHAR(25) NOT NULL,
L_SHIPMODE CHAR(10) NOT NULL,
L_COMMENT VARCHAR(44) NOT NULL
)
WITH (
LOCATION='customer',
DATA_SOURCE= external_data_source_name
);
K. Een externe tabel maken voor MongoDB
-- Create a Master Key
CREATE MASTER KEY ENCRYPTION BY PASSWORD = 'password';
/*
* Specify credentials to external data source
* IDENTITY: user name for external source.
* SECRET: password for external source.
*/
CREATE DATABASE SCOPED CREDENTIAL credential_name
WITH IDENTITY = 'username', Secret = 'password';
/* LOCATION: Location string should be of format '<type>://<server>[:<port>]'.
* PUSHDOWN: specify whether computation should be pushed down to the source. ON by default.
* CONNECTION_OPTIONS: Specify driver location
* CREDENTIAL: the database scoped credential, created above.
*/
CREATE EXTERNAL DATA SOURCE external_data_source_name
WITH (
LOCATION = mongodb://<server>[:<port>],
-- PUSHDOWN = ON | OFF,
CREDENTIAL = credential_name
);
/* LOCATION: MongoDB table/view in '<database_name>.<schema_name>.<object_name>' format
* DATA_SOURCE: the external data source, created above.
*/
CREATE EXTERNAL TABLE customers(
[O_ORDERKEY] DECIMAL(38) NOT NULL,
[O_CUSTKEY] DECIMAL(38) NOT NULL,
[O_ORDERSTATUS] CHAR COLLATE Latin1_General_BIN NOT NULL,
[O_TOTALPRICE] DECIMAL(15,2) NOT NULL,
[O_ORDERDATE] DATETIME2(0) NOT NULL,
[O_COMMENT] VARCHAR(79) COLLATE Latin1_General_BIN NOT NULL
)
WITH (
LOCATION='customer',
DATA_SOURCE= external_data_source_name
);
L. Query's uitvoeren op S3-compatibele objectopslag via externe tabel
Van toepassing op: SQL Server 2022 (16.x) en hoger
In het volgende voorbeeld ziet u hoe u met T-SQL een query uitvoert op een parquet-bestand dat is opgeslagen in S3-compatibele objectopslag via het uitvoeren van query's op externe tabellen. In het voorbeeld wordt een relatief pad in de externe gegevensbron gebruikt.
CREATE EXTERNAL DATA SOURCE s3_ds
WITH
( LOCATION = 's3://<ip_address>:<port>/'
, CREDENTIAL = s3_dc
);
GO
CREATE EXTERNAL FILE FORMAT ParquetFileFormat WITH(FORMAT_TYPE = PARQUET);
GO
CREATE EXTERNAL TABLE Region(
r_regionkey BIGINT,
r_name CHAR(25),
r_comment VARCHAR(152) )
WITH (LOCATION = '/region/', DATA_SOURCE = 's3_ds',
FILE_FORMAT = ParquetFileFormat);
GO
Volgende stappen
Meer informatie over gerelateerde concepten vindt u in de volgende artikelen:
* Azure SQL Database *
Overzicht: Azure SQL Database
In Azure SQL Database maakt u een externe tabel voor elastische query's (in preview).
Zie ook CREATE EXTERNAL DATA SOURCE.
Syntaxis
-- Create a table for use with elastic query
CREATE EXTERNAL TABLE { database_name.schema_name.table_name | schema_name.table_name | table_name }
( <column_definition> [ ,...n ] )
WITH ( <sharded_external_table_options> )
[;]
<column_definition> ::=
column_name <data_type>
[ COLLATE collation_name ]
[ NULL | NOT NULL ]
<sharded_external_table_options> ::=
DATA_SOURCE = external_data_source_name,
SCHEMA_NAME = N'nonescaped_schema_name',
OBJECT_NAME = N'nonescaped_object_name',
[DISTRIBUTION = SHARDED(sharding_column_name) | REPLICATED | ROUND_ROBIN]]
)
[;]
Argumenten
{ database_name.schema_name.table_name | schema_name.table_name | table_name }
De naam van één tot drie delen van de tabel die u wilt maken. Voor een externe tabel slaat SQL alleen de metagegevens van de tabel op, samen met basisstatistieken over het bestand of de map waarnaar wordt verwezen in Azure SQL Database. Er worden geen werkelijke gegevens verplaatst of opgeslagen in Azure SQL Database.
Belangrijk
Als het stuurprogramma van de externe gegevensbron een driedelige naam ondersteunt, wordt het ten zeerste aangeraden om de driedelige naam op te geven.
<column_definition> [ ,...n ]
CREATE EXTERNAL TABLE biedt ondersteuning voor de mogelijkheid om kolomnaam, gegevenstype, null-functionaliteit en sortering te configureren. U kunt de STANDAARDBEPERKING niet gebruiken voor externe tabellen.
Notitie
De tekst, ntext, xml-en json gegevenstypen worden niet ondersteund voor kolommen in externe tabellen voor Azure SQL Database.
De kolomdefinities, inclusief de gegevenstypen en het aantal kolommen, moeten overeenkomen met de gegevens in de externe bestanden. Als er sprake is van een onjuiste overeenkomst, worden de bestandsrijen geweigerd bij het opvragen van de werkelijke gegevens.
Shard-opties voor externe tabellen
Hiermee geeft u de externe gegevensbron (een niet-SQL Server-gegevensbron) en een distributiemethode voor de elastische query.
DATA_SOURCE
De DATA_SOURCE-component definieert de externe gegevensbron (een shard-toewijzing) die wordt gebruikt voor de externe tabel. Zie Externe tabellen makenvoor een voorbeeld.
Belangrijk
Azure SQL Database biedt ondersteuning voor het maken van externe tabellen voor EXTERN GEGEVENSBRONtypen RDMS en SHARD_MAP_MANAGER. Azure SQL Database biedt geen ondersteuning voor het maken van externe tabellen in Azure Blob Storage.
SCHEMA_NAME en OBJECT_NAME
De SCHEMA_NAME- en OBJECT_NAME-componenten wijzen de definitie van de externe tabel toe aan een tabel in een ander schema. Als u dit weglaat, wordt ervan uitgegaan dat het schema van het externe object 'dbo' is en dat de naam ervan identiek is aan de naam van de externe tabel die wordt gedefinieerd. Dit is handig als de naam van de externe tabel al wordt gebruikt in de database waarin u de externe tabel wilt maken. U wilt bijvoorbeeld een externe tabel definiëren om een geaggregeerde weergave van catalogusweergaven of DMV's op de uitgeschaalde gegevenslaag op te halen. Omdat catalogusweergaven en DMV's al lokaal bestaan, kunt u hun namen niet gebruiken voor de definitie van de externe tabel. Gebruik in plaats daarvan een andere naam en gebruik de naam van de catalogusweergave of de DMV in de SCHEMA_NAME- en/of OBJECT_NAME-componenten. Zie Externe tabellen makenvoor een voorbeeld.
DISTRIBUTIE
Facultatief. Dit argument is alleen vereist voor databases van het type SHARD_MAP_MANAGER. Met dit argument bepaalt u of een tabel wordt behandeld als een shardtabel of een gerepliceerde tabel. Met SHARDED- (kolomnaam) worden de gegevens uit verschillende tabellen niet overlapt. GEREPLICEERDE geeft aan dat tabellen dezelfde gegevens op elke shard hebben. ROUND_ROBIN geeft aan dat een toepassingsspecifieke methode wordt gebruikt om de gegevens te distribueren.
De DISTRIBUTION-component geeft de gegevensdistributie op die voor deze tabel wordt gebruikt. De queryprocessor maakt gebruik van de informatie in de DISTRIBUTION-component om de meest efficiënte queryplannen te bouwen.
- SHARDED betekent dat gegevens horizontaal worden gepartitioneerd over de databases. De partitioneringssleutel voor de gegevensdistributie is de
sharding_column_nameparameter. - GEREPLICEERD betekent dat identieke kopieën van de tabel aanwezig zijn in elke database. Het is uw verantwoordelijkheid om ervoor te zorgen dat de replica's identiek zijn in de databases.
- ROUND_ROBIN betekent dat de tabel horizontaal wordt gepartitioneerd met behulp van een toepassingsafhankelijke distributiemethode.
Machtigingen
Gebruikers met toegang tot de externe tabel krijgen automatisch toegang tot de onderliggende externe tabellen onder de referentie die is opgegeven in de definitie van de externe gegevensbron. Vermijd ongewenste uitbreiding van bevoegdheden via de referentie van de externe gegevensbron. Gebruik GRANT of REVOKE voor een externe tabel, net zoals een gewone tabel. Zodra u uw externe gegevensbron en uw externe tabellen hebt gedefinieerd, kunt u nu volledige T-SQL gebruiken voor uw externe tabellen.
Foutafhandeling
Wanneer de CREATE EXTERNAL TABLE-instructie wordt uitgevoerd, mislukt de instructie als de poging om verbinding te maken mislukt en wordt de externe tabel niet gemaakt. Het kan een minuut of langer duren voordat de opdracht mislukt, omdat sql Database de verbinding opnieuw probeert uit te voeren voordat de query uiteindelijk mislukt.
Opmerkingen
In ad-hocqueryscenario's, zoals SELECT FROM EXTERNAL TABLE, slaat SQL Database de rijen op die worden opgehaald uit de externe gegevensbron in een tijdelijke tabel. Nadat de query is voltooid, verwijdert en verwijdert SQL Database de tijdelijke tabel. Er worden geen permanente gegevens opgeslagen in SQL-tabellen.
In het importscenario, zoals SELECT INTO FROM EXTERNAL TABLE, slaat SQL Database daarentegen de rijen op die uit de externe gegevensbron worden opgehaald als permanente gegevens in de SQL-tabel. De nieuwe tabel wordt gemaakt tijdens het uitvoeren van query's wanneer SQL Database de externe gegevens ophaalt.
U kunt veel externe tabellen maken die verwijzen naar dezelfde of verschillende externe gegevensbronnen.
U kunt meerdere externe tabellen maken die elk verwijzen naar verschillende externe gegevensbronnen.
Beperkingen
isolatiesemantiek: toegang tot gegevens via een externe tabel voldoet niet aan de isolatiesemantiek binnen SQL Server. Dit betekent dat het uitvoeren van query's op een externe tabel geen vergrendeling of isolatie van momentopnamen met zich meebrengt. Gegevens retourneren kan daarom veranderen als de gegevens in de externe gegevensbron worden gewijzigd. Dezelfde query kan verschillende resultaten retourneren telkens wanneer deze wordt uitgevoerd op een externe tabel. Op dezelfde manier kan een query mislukken als de externe gegevens worden verplaatst of verwijderd.
Constructies en bewerkingen worden niet ondersteund:
- De standaardbeperking voor kolommen in externe tabellen.
- DML-bewerkingen (Data Manipulation Language) voor verwijderen, invoegen en bijwerken.
- dynamische gegevensmaskering voor externe tabelkolommen.
- Cursors worden niet ondersteund voor externe tabellen in Azure SQL Database.
Alleen letterlijke predicaten: Alleen letterlijke predicaten die in een query zijn gedefinieerd, kunnen naar de externe gegevensbron worden gepusht. Dit is in tegenstelling tot gekoppelde servers en toegang tot waar predicaten die tijdens de uitvoering van de query worden bepaald, kunnen worden gebruikt, dat wil zeggen, wanneer deze wordt gebruikt met een geneste lus in een queryplan. Dit leidt er vaak toe dat de hele externe tabel lokaal wordt gekopieerd en vervolgens lid wordt.
Als
External.Ordersin het volgende voorbeeld een externe tabel is enCustomereen lokale tabel is, kopieert de query de hele externe tabel lokaal omdat het benodigde predicaat tijdens het compileren niet bekend is.SELECT Orders.OrderId, Orders.OrderTotal FROM External.Orders WHERE CustomerId IN ( SELECT TOP 1 CustomerId FROM Customer WHERE CustomerName = 'MyCompany' );Geen parallelle uitvoering: Gebruik van externe tabellen voorkomt het gebruik van parallelle uitvoering in het queryplan.
uitgevoerd als externe query: externe tabellen worden geïmplementeerd als externe query, dus het geschatte aantal geretourneerde rijen is over het algemeen 1000. Er zijn andere regels gebaseerd op het type predicaat dat wordt gebruikt om de externe tabel te filteren. Dit zijn schattingen op basis van regels in plaats van schattingen op basis van de werkelijke gegevens in de externe tabel. De optimizer heeft geen toegang tot de externe gegevensbron om een nauwkeurigere schatting te krijgen.
Niet ondersteund voor privé-eindpunten: externe tabelquery's worden niet ondersteund wanneer de verbinding met een externe tabel een privé-eindpunt is.
Beperkingen voor gegevenstypen
De volgende gegevenstypen kunnen niet worden gebruikt in externe PolyBase-tabellen:
- geografie
- geometrie
- hierarchyid-
- afbeelding
- tekst
- xml--
- Elk door de gebruiker gedefinieerd type
Vergrendeling
Gedeelde vergrendeling op het OBJECT SCHEMARESOLUTION.
Voorbeelden
Een. Externe tabel maken voor Azure SQL Database
CREATE EXTERNAL TABLE [dbo].[CustomerInformation]
( [CustomerID] [int] NOT NULL,
[CustomerName] [varchar](50) NOT NULL,
[Company] [varchar](50) NOT NULL)
WITH
( DATA_SOURCE = MyElasticDBQueryDataSrc)
B. Een externe tabel maken voor een shard-gegevensbron
In dit voorbeeld wordt een externe DMV opnieuw toewijzen aan een externe tabel met behulp van de SCHEMA_NAME- en OBJECT_NAME-componenten.
CREATE EXTERNAL TABLE [dbo].[all_dm_exec_requests]([session_id] smallint NOT NULL,
[request_id] int NOT NULL,
[start_time] datetime NOT NULL,
[status] nvarchar(30) NOT NULL,
[command] nvarchar(32) NOT NULL,
[sql_handle] varbinary(64),
[statement_start_offset] int,
[statement_end_offset] int,
[cpu_time] int NOT NULL)
WITH
(
DATA_SOURCE = MyExtSrc,
SCHEMA_NAME = 'sys',
OBJECT_NAME = 'dm_exec_requests',
DISTRIBUTION=ROUND_ROBIN
);
Volgende stappen
Meer informatie over externe tabellen in Azure SQL Database vindt u in de volgende artikelen:
- Overzicht van elastische query's in Azure SQL Database
- rapportage over uitgeschaalde clouddatabases
- Aan de slag met query's voor meerdere databases (verticale partitionering)
* Azure Synapse
Analyse *
Overzicht: Azure Synapse Analytics
Gebruik een externe tabel om:
- Toegewezen SQL-pools kunnen gegevens opvragen, importeren en opslaan vanuit Hadoop, Azure Blob Storage en Azure Data Lake Storage Gen1 en Gen2.
- Serverloze SQL-pools kunnen gegevens opvragen, importeren en opslaan vanuit Azure Blob Storage, Azure Data Lake Storage Gen1 en Gen2. Serverloos biedt geen ondersteuning voor
TYPE=Hadoop.
Zie ook CREATE EXTERNAL DATA SOURCE en DROP EXTERNAL TABLE.
Zie Externe tabellen gebruiken met Synapse sqlvoor meer richtlijnen en voorbeelden over het gebruik van externe tabellen met Azure Synapse SQL.
Syntaxis
CREATE EXTERNAL TABLE { database_name.schema_name.table_name | schema_name.table_name | table_name }
( <column_definition> [ ,...n ] )
WITH (
LOCATION = 'hdfs_folder_or_filepath',
DATA_SOURCE = external_data_source_name,
FILE_FORMAT = external_file_format_name
[ , <reject_options> [ ,...n ] ]
)
[;]
<column_definition> ::=
column_name <data_type>
[ COLLATE collation_name ]
[ NULL | NOT NULL ]
<reject_options> ::=
{
| REJECT_TYPE = value | percentage,
| REJECT_VALUE = reject_value,
| REJECT_SAMPLE_VALUE = reject_sample_value,
| REJECTED_ROW_LOCATION = '/REJECT_Directory'
}
Argumenten
{ database_name.schema_name.table_name | schema_name.table_name | table_name }
De naam van één tot drie delen van de tabel die u wilt maken. Voor een externe tabel worden alleen de metagegevens van de tabel samen met basisstatistieken over het bestand of de map waarnaar wordt verwezen in Azure Data Lake, Hadoop of Azure Blob Storage. Er worden geen werkelijke gegevens verplaatst of opgeslagen wanneer externe tabellen worden gemaakt.
Belangrijk
Als het stuurprogramma van de externe gegevensbron een driedelige naam ondersteunt, wordt het ten zeerste aangeraden om de driedelige naam op te geven.
<column_definition> [ ,...n ]
CREATE EXTERNAL TABLE biedt ondersteuning voor de mogelijkheid om kolomnaam, gegevenstype, null-functionaliteit en sortering te configureren. U kunt de STANDAARDBEPERKING niet gebruiken voor externe tabellen.
Notitie
De gegevenstypen tekst, ntexten xml- worden niet ondersteund voor kolommen in externe tabellen voor Synapse Analytics.
- Bij het lezen van bestanden met scheidingstekens moeten de kolomdefinities, inclusief de gegevenstypen en het aantal kolommen, overeenkomen met de gegevens in de externe bestanden. Als er sprake is van een onjuiste overeenkomst, worden de bestandsrijen geweigerd bij het opvragen van de werkelijke gegevens.
- Wanneer u leest vanuit Parquet-bestanden, kunt u alleen de kolommen opgeven die u wilt lezen en de rest overslaan.
LOCATION = 'folder_or_filepath'
Hiermee geeft u de map of het bestandspad en de bestandsnaam op voor de werkelijke gegevens in Azure Data Lake, Hadoop of Azure Blob Storage. De locatie begint vanuit de hoofdmap. De hoofdmap is de gegevenslocatie die is opgegeven in de externe gegevensbron. De instructie CREATE EXTERNAL TABLE AS SELECT maakt het pad en de map als deze niet bestaat.
CREATE EXTERNAL TABLE maakt het pad en de map niet.
Als u LOCATION opgeeft als een map, haalt een PolyBase-query die uit de externe tabel selecteert bestanden op uit de map en alle bijbehorende submappen. Net als Hadoop retourneert PolyBase geen verborgen mappen. Het retourneert ook geen bestanden waarvoor de bestandsnaam begint met een onderstreping (_) of een punt (.).
Als LOCATION='/webdata/'in het volgende afbeeldingsvoorbeeld retourneert een PolyBase-query rijen uit mydata.txt en mydata2.txt. Het retourneert geen mydata3.txt omdat deze zich in een submap van een verborgen map bevindt. En het retourneert geen _hidden.txt omdat het een verborgen bestand is.
In tegenstelling tot externe Hadoop-tabellen retourneren systeemeigen externe tabellen geen submappen, tenzij u /** aan het einde van het pad opgeeft. Als LOCATION='/webdata/'in dit voorbeeld een serverloze SQL-poolquery retourneert, worden rijen uit mydata.txtgeretourneerd. Het retourneert geen mydata2.txt en mydata3.txt omdat deze zich in een submap bevinden. Hadoop-tabellen retourneren alle bestanden in een submap.
Zowel Hadoop als systeemeigen externe tabellen slaan de bestanden over met de namen die beginnen met een onderstreping (_) of een punt (.).
DATA_SOURCE = external_data_source_name
Hiermee geeft u de naam op van de externe gegevensbron die de locatie van de externe gegevens bevat. Deze locatie bevindt zich in Azure Data Lake. Als u een externe gegevensbron wilt maken, gebruikt u CREATE EXTERNAL DATA SOURCE.
FILE_FORMAT = external_file_format_name
Hiermee geeft u de naam op van het externe bestandsindelingsobject waarin het bestandstype en de compressiemethode voor de externe gegevens worden opgeslagen. Als u een externe bestandsindeling wilt maken, gebruikt u CREATE EXTERNAL FILE FORMAT.
TABLE_OPTIONS
Hiermee geeft u de set opties die beschrijven hoe de onderliggende bestanden moeten worden gelezen. Op dit moment is de enige optie die beschikbaar is {"READ_OPTIONS":["ALLOW_INCONSISTENT_READS"]} die de externe tabel opdracht geeft om de updates te negeren die zijn aangebracht op de onderliggende bestanden, zelfs als dit kan leiden tot inconsistente leesbewerkingen. Gebruik deze optie alleen in speciale gevallen waarin u regelmatig bestanden hebt toegevoegd. Deze optie is beschikbaar in een serverloze SQL-pool voor CSV-indeling.
WEIGERINGsopties
Opties voor weigeren zijn in preview voor serverloze SQL-pools in Azure Synapse Analytics.
Deze optie kan alleen worden gebruikt met externe gegevensbronnen waarbij TYPE = HADOOP.
U kunt weigeringsparameters opgeven die bepalen hoe PolyBase vuile records verwerkt die worden opgehaald uit de externe gegevensbron. Een gegevensrecord wordt beschouwd als 'vuil' als het werkelijke gegevenstypen of het aantal kolommen niet overeenkomt met de kolomdefinities van de externe tabel.
Wanneer u geen afkeuringswaarden opgeeft of wijzigt, gebruikt PolyBase standaardwaarden. Deze informatie over de geweigerde parameters wordt opgeslagen als aanvullende metagegevens wanneer u een externe tabel maakt met de instructie CREATE EXTERNAL TABLE. Wanneer een toekomstige SELECT-instructie of SELECT INTO SELECT-instructie gegevens uit de externe tabel selecteert, gebruikt PolyBase de opties voor weigeren om het aantal of het percentage rijen te bepalen dat kan worden geweigerd voordat de werkelijke query mislukt. De query retourneert (gedeeltelijke) resultaten totdat de drempelwaarde voor weigeren is overschreden. Het mislukt vervolgens met het juiste foutbericht.
De optie PARSER_VERSION-indeling wordt alleen ondersteund in serverloze SQL-pools.
REJECT_TYPE = waarde | percentage
Verduidelijkt of de optie REJECT_VALUE is opgegeven als een letterlijke waarde of een percentage.
waarde
REJECT_VALUE is een letterlijke waarde, geen percentage. De PolyBase-query mislukt wanneer het aantal geweigerde rijen groter is dan reject_value.
Als bijvoorbeeld REJECT_VALUE = 5 en REJECT_TYPE = waarde, mislukt de PolyBase SELECT-query nadat vijf rijen zijn geweigerd.
percentage
REJECT_VALUE is een percentage, geen letterlijke waarde. Een PolyBase-query mislukt wanneer het percentage van mislukte rijen groter is dan reject_value. Het percentage mislukte rijen wordt berekend met intervallen.
REJECT_VALUE = reject_value
Hiermee geeft u de waarde of het percentage rijen op dat kan worden geweigerd voordat de query mislukt.
- Voor REJECT_TYPE = waarde moet reject_value een geheel getal tussen 0 en 2.147.483.647 zijn.
- Voor REJECT_TYPE = percentage moet reject_value een float tussen 0 en 100 zijn. Percentage is alleen geldig voor toegewezen SQL-pools waarbij
TYPE=HADOOP.
De query mislukt wanneer het aantal geweigerde rijen groter is dan reject_value. Als bijvoorbeeld REJECT_VALUE = 5 en REJECT_TYPE = waarde, mislukt de SELECT-query nadat vijf rijen zijn geweigerd.
REJECT_SAMPLE_VALUE = reject_sample_value
Dit kenmerk is vereist wanneer u REJECT_TYPE = percentage opgeeft. Het bepaalt het aantal rijen dat moet worden opgehaald voordat polybase het percentage geweigerde rijen opnieuw berekent.
De parameter reject_sample_value moet een geheel getal tussen 0 en 2.147.483.647 zijn.
Als bijvoorbeeld REJECT_SAMPLE_VALUE = 1000, berekent PolyBase het percentage mislukte rijen nadat is geprobeerd 1000 rijen uit het externe gegevensbestand te importeren. Als het percentage mislukte rijen kleiner is dan reject_value, probeert PolyBase nog eens 1000 rijen op te halen. Het percentage mislukte rijen wordt nog steeds herberekend nadat wordt geprobeerd om elke extra 1000 rijen te importeren.
Notitie
Omdat PolyBase het percentage mislukte rijen berekent met intervallen, kan het werkelijke percentage mislukte rijen groter zijn dan reject_value.
Voorbeeld:
In dit voorbeeld ziet u hoe de drie weigeringsopties met elkaar communiceren. Als bijvoorbeeld REJECT_TYPE = percentage, REJECT_VALUE = 30 en REJECT_SAMPLE_VALUE = 100, kan het volgende scenario optreden:
- PolyBase probeert de eerste 100 rijen op te halen; 25 mislukken en 75 slagen.
- Het percentage mislukte rijen wordt berekend als 25%, wat kleiner is dan de weigeringswaarde van 30%. Als gevolg hiervan blijft PolyBase gegevens ophalen uit de externe gegevensbron.
- PolyBase probeert de volgende 100 rijen te laden; deze keer slagen 25 rijen en mislukken 75 rijen.
- Het percentage mislukte rijen wordt opnieuw berekend als 50%. Het percentage mislukte rijen heeft de waarde van 30% weigeren overschreden.
- De PolyBase-query mislukt met 50% geweigerde rijen na een poging om de eerste 200 rijen te retourneren. U ziet dat overeenkomende rijen zijn geretourneerd voordat de PolyBase-query detecteert dat de drempelwaarde voor weigeren is overschreden.
REJECTED_ROW_LOCATION = maplocatie
Hiermee geeft u de map in de externe gegevensbron op dat de geweigerde rijen en het bijbehorende foutbestand moeten worden geschreven.
Als het opgegeven pad niet bestaat, wordt het gemaakt. Er wordt een onderliggende map gemaakt met de naam _rejectedrows. Het _ teken zorgt ervoor dat de map wordt ontsnapt voor andere gegevensverwerking, tenzij deze expliciet is benoemd in de locatieparameter.
- In serverloze SQL-pools wordt het pad
YearMonthDay_HourMinuteSecond_StatementID. U kuntstatementIDgebruiken om de map te correleren met de query die deze heeft gegenereerd. - In toegewezen SQL-pools is het gemaakte pad gebaseerd op het tijdstip van het indienen van de belasting in de indeling
YearMonthDay -HourMinuteSecond, bijvoorbeeld20180330-173205.
In deze map worden twee typen bestanden geschreven, het _reason-bestand en het gegevensbestand.
Zie CREATE EXTERNAL DATA SOURCEvoor meer informatie.
De redenbestanden en de gegevensbestanden hebben beide de query-id gekoppeld aan de CTAS-instructie. Omdat de gegevens en de reden zich in afzonderlijke bestanden bevinden, hebben de bijbehorende bestanden een overeenkomend achtervoegsel.
In serverloze SQL-pools bevat het error.json-bestand een JSON-matrix met fouten met betrekking tot geweigerde rijen. Elk element dat een fout vertegenwoordigt, bevat de volgende kenmerken:
| Attribuut | Beschrijving |
|---|---|
| Fout | Reden waarom rij wordt geweigerd. |
| Roeien | Afgekeurd rijnummer in bestand. |
| Kolom | Afgekeurd kolomnummer. |
| Waarde | Geweigerde kolomwaarde. Als de waarde groter is dan 100 tekens, worden alleen de eerste 100 tekens weergegeven. |
| Bestand | Pad naar het bestand waartoe die rij behoort. |
Machtigingen
Hiervoor zijn deze gebruikersmachtigingen vereist:
- CREATE TABLE-
- ALLE SCHEMA- WIJZIGEN
- EEN EXTERNE GEGEVENSBRON WIJZIGEN
- EEN EXTERNE BESTANDSINDELING WIJZIGEN
Notitie
CONTROL DATABASE-machtigingen zijn vereist om alleen de HOOFDSLEUTEL, DATABASE SCOPED CREDENTIAL en EXTERNAL DATA SOURCE te maken
Houd er rekening mee dat de aanmelding die de externe gegevensbron maakt, gemachtigd moet zijn om de externe gegevensbron te lezen en schrijven, die zich in Hadoop of Azure Blob Storage bevindt.
Belangrijk
Met de machtiging ALTER ANY EXTERNAL DATA SOURCE verleent elke principal de mogelijkheid om een extern gegevensbronobject te maken en te wijzigen, waardoor het ook de mogelijkheid verleent om toegang te krijgen tot alle referenties binnen het databasebereik. Deze machtiging moet worden beschouwd als zeer bevoegd en moet daarom alleen worden verleend aan vertrouwde principals in het systeem.
Foutafhandeling
Tijdens het uitvoeren van de CREATE EXTERNAL TABLE-instructie probeert PolyBase verbinding te maken met de externe gegevensbron. Als de poging om verbinding te maken mislukt, mislukt de instructie en wordt de externe tabel niet gemaakt. Het kan een minuut of langer duren voordat de opdracht mislukt, omdat PolyBase de verbinding opnieuw probeert uit te voeren voordat de query uiteindelijk mislukt.
Opmerkingen
In ad-hocqueryscenario's, zoals SELECT FROM EXTERNAL TABLE, slaat PolyBase de rijen op die worden opgehaald uit de externe gegevensbron in een tijdelijke tabel. Nadat de query is voltooid, verwijdert PolyBase de tijdelijke tabel en verwijdert deze. Er worden geen permanente gegevens opgeslagen in SQL-tabellen.
In het importscenario, zoals SELECT INTO FROM EXTERNAL TABLE, slaat PolyBase daarentegen de rijen op die uit de externe gegevensbron worden opgehaald als permanente gegevens in de SQL-tabel. De nieuwe tabel wordt gemaakt tijdens het uitvoeren van query's wanneer PolyBase de externe gegevens ophaalt.
PolyBase kan een deel van de queryberekening naar Hadoop pushen om de queryprestaties te verbeteren. Deze actie wordt predicaatpushdown genoemd. Als u dit wilt inschakelen, geeft u de locatieoptie Hadoop resource manager op in CREATE EXTERNAL DATA SOURCE.
U kunt veel externe tabellen maken die verwijzen naar dezelfde of verschillende externe gegevensbronnen.
Let op brongegevens met behulp van de UTF-8-sortering. Voor alle brongegevens die gebruikmaken van de UTF-8-sortering, moet u handmatig een niet-UTF-8-sortering opgeven voor elke UTF-8-kolom in de CREATE EXTERNAL TABLE-instructie. Dit komt doordat UTF-8-ondersteuning niet wordt uitgebreid naar externe tabellen. Wanneer u een externe tabel probeert te maken met een UTF-8-sortering, ontvangt u een Unsupported collation foutbericht. Als de databasesortering van de externe tabel een UTF-8-sortering is, mislukt het maken van externe tabellen tenzij u een expliciete niet-UTF-8-kolomsortering opgeeft, bijvoorbeeld [UTF8_column] varchar(128) COLLATE LATIN1_GENERAL_100_CI_AS_KS_WS NOT NULL,.
Serverloze en toegewezen SQL-pools in Azure Synapse Analytics gebruiken verschillende codedatabases voor gegevensvirtualisatie. Serverloze SQL-pools ondersteunen een systeemeigen technologie voor gegevensvirtualisatie. Toegewezen SQL-pools ondersteunen zowel systeemeigen als PolyBase-gegevensvirtualisatie. PolyBase-gegevensvirtualisatie wordt gebruikt wanneer de EXTERNE GEGEVENSBRON wordt gemaakt met TYPE=HADOOP.
Beperkingen en beperkingen
Omdat de gegevens voor een externe tabel niet onder het directe beheer van Azure Synapse staan, kunnen deze op elk gewenst moment door een extern proces worden gewijzigd of verwijderd. Als gevolg hiervan zijn queryresultaten voor een externe tabel niet gegarandeerd deterministisch. Dezelfde query kan verschillende resultaten retourneren telkens wanneer deze wordt uitgevoerd op een externe tabel. Op dezelfde manier kan een query mislukken als de externe gegevens worden verplaatst of verwijderd.
U kunt meerdere externe tabellen maken die elk verwijzen naar verschillende externe gegevensbronnen.
Alleen deze DDL-instructies (Data Definition Language) zijn toegestaan voor externe tabellen:
- CREATE TABLE en DROP TABLE
- STATISTIEKEN MAKEN EN STATISTIEKEN VERWIJDEREN
- WEERGAVE EN DROP VIEW MAKEN
Constructies en bewerkingen worden niet ondersteund:
- De standaardbeperking voor externe tabelkolommen
- DML-bewerkingen (Data Manipulation Language) voor verwijderen, invoegen en bijwerken
- dynamische gegevensmaskering voor externe tabelkolommen
Querybeperkingen
Het wordt aanbevolen niet meer dan 30.000 bestanden per map te overschrijden. Wanneer er te veel bestanden naar worden verwezen, kan er een JVM-uitzondering (Java Virtual Machine) optreden of kunnen de prestaties afnemen.
Beperkingen voor tabelbreedte
PolyBase in Azure Data Warehouse heeft een rijbreedtelimiet van 1 MB op basis van de maximale grootte van één geldige rij per tabeldefinitie. Als de som van het kolomschema groter is dan 1 MB, kan PolyBase geen query's uitvoeren op de gegevens.
Beperkingen voor gegevenstypen
De volgende gegevenstypen kunnen niet worden gebruikt in externe PolyBase-tabellen:
- geografie
- geometrie
- hierarchyid-
- afbeelding
- tekst
- xml--
- Elk door de gebruiker gedefinieerd type
Vergrendeling
Gedeelde vergrendeling op het OBJECT SCHEMARESOLUTION.
Voorbeelden
Een. Gegevens importeren uit ADLS Gen 2 in Azure Synapse Analytics
Zie Externe gegevensbron makenvoor voorbeelden van Gen ADLS Gen 1.
-- These values come from your Azure Active Directory Application used to authenticate to ADLS Gen 2.
CREATE DATABASE SCOPED CREDENTIAL ADLUser
WITH IDENTITY = '<clientID>@\<OAuth2.0TokenEndPoint>',
SECRET = '<KEY>' ;
CREATE EXTERNAL DATA SOURCE AzureDataLakeStore
WITH (TYPE = HADOOP,
LOCATION = 'abfss://data@pbasetr.azuredatalakestore.net'
);
CREATE EXTERNAL FILE FORMAT TextFileFormat
WITH
(
FORMAT_TYPE = DELIMITEDTEXT
, FORMAT_OPTIONS ( FIELD_TERMINATOR = '|'
, STRING_DELIMITER = ''
, DATE_FORMAT = 'yyyy-MM-dd HH:mm:ss.fff'
, USE_TYPE_DEFAULT = FALSE
)
);
CREATE EXTERNAL TABLE [dbo].[DimProduct_external]
( [ProductKey] [int] NOT NULL,
[ProductLabel] nvarchar NULL,
[ProductName] nvarchar NULL )
WITH
(
LOCATION='/DimProduct/' ,
DATA_SOURCE = AzureDataLakeStore ,
FILE_FORMAT = TextFileFormat ,
REJECT_TYPE = VALUE ,
REJECT_VALUE = 0
);
CREATE TABLE [dbo].[DimProduct]
WITH (DISTRIBUTION = HASH([ProductKey] ) )
AS SELECT * FROM
[dbo].[DimProduct_external] ;
B. Gegevens uit Parquet importeren in Azure Synapse Analytics
In het volgende voorbeeld wordt een externe tabel gemaakt. Vervolgens wordt de eerste rij geretourneerd:
CREATE EXTERNAL TABLE census_external_table
(
decennialTime varchar(20),
stateName varchar(100),
countyName varchar(100),
population int,
race varchar(50),
sex varchar(10),
minAge int,
maxAge int
)
WITH (
LOCATION = '/parquet/',
DATA_SOURCE = population_ds,
FILE_FORMAT = census_file_format
);
GO
SELECT TOP 1 * FROM census_external_table;
Volgende stappen
Meer informatie over externe tabellen en gerelateerde concepten vindt u in de volgende artikelen:
* Analyse
Platform System (PDW) *
Overzicht: Analytics Platform System
Gebruik een externe tabel om:
- Query's uitvoeren op Hadoop- of Azure Blob Storage-gegevens met Transact-SQL instructies.
- Gegevens uit Hadoop of Azure Blob Storage importeren en opslaan in het Analytics Platform System.
Zie ook CREATE EXTERNAL DATA SOURCE en DROP EXTERNAL TABLE.
Syntaxis
CREATE EXTERNAL TABLE { database_name.schema_name.table_name | schema_name.table_name | table_name }
( <column_definition> [ ,...n ] )
WITH (
LOCATION = 'hdfs_folder_or_filepath',
DATA_SOURCE = external_data_source_name,
FILE_FORMAT = external_file_format_name
[ , <reject_options> [ ,...n ] ]
)
[;]
<column_definition> ::=
column_name <data_type>
[ COLLATE collation_name ]
[ NULL | NOT NULL ]
<reject_options> ::=
{
| REJECT_TYPE = value | percentage,
| REJECT_VALUE = reject_value,
| REJECT_SAMPLE_VALUE = reject_sample_value,
}
Argumenten
{ database_name.schema_name.table_name | schema_name.table_name | table_name }
De naam van één tot drie delen van de tabel die u wilt maken. Voor een externe tabel slaat Analytics Platform System alleen de metagegevens van de tabel op, samen met basisstatistieken over het bestand of de map waarnaar wordt verwezen in Hadoop of Azure Blob Storage. Er worden geen werkelijke gegevens verplaatst of opgeslagen in het Analytics Platform System.
Belangrijk
Als het stuurprogramma van de externe gegevensbron een driedelige naam ondersteunt, wordt het ten zeerste aangeraden om de driedelige naam op te geven.
<column_definition> [ ,...n ]
CREATE EXTERNAL TABLE biedt ondersteuning voor de mogelijkheid om kolomnaam, gegevenstype, null-functionaliteit en sortering te configureren. U kunt de STANDAARDBEPERKING niet gebruiken voor externe tabellen.
De kolomdefinities, inclusief de gegevenstypen en het aantal kolommen, moeten overeenkomen met de gegevens in de externe bestanden. Als er sprake is van een onjuiste overeenkomst, worden de bestandsrijen geweigerd bij het opvragen van de werkelijke gegevens.
LOCATION = 'folder_or_filepath'
Hiermee geeft u de map of het bestandspad en de bestandsnaam op voor de werkelijke gegevens in Hadoop of Azure Blob Storage. De locatie begint vanuit de hoofdmap. De hoofdmap is de gegevenslocatie die is opgegeven in de externe gegevensbron.
In Analytics Platform System maakt de CREATE EXTERNAL TABLE AS SELECT instructie het pad en de map als deze niet bestaat.
CREATE EXTERNAL TABLE maakt het pad en de map niet.
Als u LOCATION opgeeft als een map, haalt een PolyBase-query die uit de externe tabel selecteert bestanden op uit de map en alle bijbehorende submappen. Net als Hadoop retourneert PolyBase geen verborgen mappen. Het retourneert ook geen bestanden waarvoor de bestandsnaam begint met een onderstreping (_) of een punt (.).
Als LOCATION='/webdata/'in het volgende afbeeldingsvoorbeeld retourneert een PolyBase-query rijen uit mydata.txt en mydata2.txt. Het retourneert geen mydata3.txt omdat deze zich in een submap van een verborgen map bevindt. En het retourneert geen _hidden.txt omdat het een verborgen bestand is.
Als u de standaardinstelling wilt wijzigen en alleen wilt lezen uit de hoofdmap, stelt u het kenmerk <polybase.recursive.traversal> in op 'false' in het core-site.xml configuratiebestand. Dit bestand bevindt zich onder <SqlBinRoot>\PolyBase\Hadoop\Conf\ onder de bin hoofdmap van SQL Server. Bijvoorbeeld C:\Program Files\Microsoft SQL Server\MSSQL13.XD14\MSSQL\Binn\.
DATA_SOURCE = external_data_source_name
Hiermee geeft u de naam op van de externe gegevensbron die de locatie van de externe gegevens bevat. Deze locatie is een Hadoop of Azure Blob Storage. Als u een externe gegevensbron wilt maken, gebruikt u CREATE EXTERNAL DATA SOURCE.
FILE_FORMAT = external_file_format_name
Hiermee geeft u de naam op van het externe bestandsindelingsobject waarin het bestandstype en de compressiemethode voor de externe gegevens worden opgeslagen. Als u een externe bestandsindeling wilt maken, gebruikt u CREATE EXTERNAL FILE FORMAT.
Opties voor weigeren
Deze optie kan alleen worden gebruikt met externe gegevensbronnen waarbij TYPE = HADOOP.
U kunt weigeringsparameters opgeven die bepalen hoe PolyBase vuile records verwerkt die worden opgehaald uit de externe gegevensbron. Een gegevensrecord wordt beschouwd als 'vuil' als het werkelijke gegevenstypen of het aantal kolommen niet overeenkomt met de kolomdefinities van de externe tabel.
Wanneer u geen afkeuringswaarden opgeeft of wijzigt, gebruikt PolyBase standaardwaarden. Deze informatie over de geweigerde parameters wordt opgeslagen als aanvullende metagegevens wanneer u een externe tabel maakt met de instructie CREATE EXTERNAL TABLE. Wanneer een toekomstige SELECT-instructie of SELECT INTO SELECT-instructie gegevens uit de externe tabel selecteert, gebruikt PolyBase de opties voor weigeren om het aantal of het percentage rijen te bepalen dat kan worden geweigerd voordat de werkelijke query mislukt. De query retourneert (gedeeltelijke) resultaten totdat de drempelwaarde voor weigeren is overschreden. Het mislukt vervolgens met het juiste foutbericht.
REJECT_TYPE = waarde | percentage
Verduidelijkt of de optie REJECT_VALUE is opgegeven als een letterlijke waarde of een percentage.
waarde
REJECT_VALUE is een letterlijke waarde, geen percentage. De PolyBase-query mislukt wanneer het aantal geweigerde rijen groter is dan reject_value.
Als bijvoorbeeld REJECT_VALUE = 5 en REJECT_TYPE = waarde, mislukt de PolyBase SELECT-query nadat vijf rijen zijn geweigerd.
percentage
REJECT_VALUE is een percentage, geen letterlijke waarde. Een PolyBase-query mislukt wanneer het percentage van mislukte rijen groter is dan reject_value. Het percentage mislukte rijen wordt berekend met intervallen.
REJECT_VALUE = reject_value
Hiermee geeft u de waarde of het percentage rijen op dat kan worden geweigerd voordat de query mislukt.
Voor REJECT_TYPE = waarde moet reject_value een geheel getal tussen 0 en 2.147.483.647 zijn.
Voor REJECT_TYPE = percentage moet reject_value een float tussen 0 en 100 zijn.
REJECT_SAMPLE_VALUE = reject_sample_value
Dit kenmerk is vereist wanneer u REJECT_TYPE = percentage opgeeft. Het bepaalt het aantal rijen dat moet worden opgehaald voordat polybase het percentage geweigerde rijen opnieuw berekent.
De parameter reject_sample_value moet een geheel getal tussen 0 en 2.147.483.647 zijn.
Als bijvoorbeeld REJECT_SAMPLE_VALUE = 1000, berekent PolyBase het percentage mislukte rijen nadat is geprobeerd 1000 rijen uit het externe gegevensbestand te importeren. Als het percentage mislukte rijen kleiner is dan reject_value, probeert PolyBase nog eens 1000 rijen op te halen. Het percentage mislukte rijen wordt nog steeds herberekend nadat wordt geprobeerd om elke extra 1000 rijen te importeren.
Notitie
Omdat PolyBase het percentage mislukte rijen berekent met intervallen, kan het werkelijke percentage mislukte rijen groter zijn dan reject_value.
Voorbeeld:
In dit voorbeeld ziet u hoe de drie weigeringsopties met elkaar communiceren. Als bijvoorbeeld REJECT_TYPE = percentage, REJECT_VALUE = 30 en REJECT_SAMPLE_VALUE = 100, kan het volgende scenario optreden:
- PolyBase probeert de eerste 100 rijen op te halen; 25 mislukken en 75 slagen.
- Het percentage mislukte rijen wordt berekend als 25%, wat kleiner is dan de weigeringswaarde van 30%. Als gevolg hiervan blijft PolyBase gegevens ophalen uit de externe gegevensbron.
- PolyBase probeert de volgende 100 rijen te laden; deze keer slagen 25 rijen en mislukken 75 rijen.
- Het percentage mislukte rijen wordt opnieuw berekend als 50%. Het percentage mislukte rijen heeft de waarde van 30% weigeren overschreden.
- De PolyBase-query mislukt met 50% geweigerde rijen na een poging om de eerste 200 rijen te retourneren. U ziet dat overeenkomende rijen zijn geretourneerd voordat de PolyBase-query detecteert dat de drempelwaarde voor weigeren is overschreden.
Machtigingen
Hiervoor zijn deze gebruikersmachtigingen vereist:
- CREATE TABLE-
- ALLE SCHEMA- WIJZIGEN
- EEN EXTERNE GEGEVENSBRON WIJZIGEN
- EEN EXTERNE BESTANDSINDELING WIJZIGEN
- CONTROL DATABASE-
Houd er rekening mee dat de aanmelding die de externe gegevensbron maakt, gemachtigd moet zijn om de externe gegevensbron te lezen en schrijven, die zich in Hadoop of Azure Blob Storage bevindt.
Belangrijk
Met de machtiging ALTER ANY EXTERNAL DATA SOURCE verleent elke principal de mogelijkheid om een extern gegevensbronobject te maken en te wijzigen, waardoor het ook de mogelijkheid verleent om toegang te krijgen tot alle referenties binnen het databasebereik. Deze machtiging moet worden beschouwd als zeer bevoegd en moet daarom alleen worden verleend aan vertrouwde principals in het systeem.
Foutafhandeling
Tijdens het uitvoeren van de CREATE EXTERNAL TABLE-instructie probeert PolyBase verbinding te maken met de externe gegevensbron. Als de poging om verbinding te maken mislukt, mislukt de instructie en wordt de externe tabel niet gemaakt. Het kan een minuut of langer duren voordat de opdracht mislukt, omdat PolyBase de verbinding opnieuw probeert uit te voeren voordat de query uiteindelijk mislukt.
Opmerkingen
In ad-hocqueryscenario's, zoals SELECT FROM EXTERNAL TABLE, slaat PolyBase de rijen op die worden opgehaald uit de externe gegevensbron in een tijdelijke tabel. Nadat de query is voltooid, verwijdert PolyBase de tijdelijke tabel en verwijdert deze. Er worden geen permanente gegevens opgeslagen in SQL-tabellen.
In het importscenario, zoals SELECT INTO FROM EXTERNAL TABLE, slaat PolyBase daarentegen de rijen op die uit de externe gegevensbron worden opgehaald als permanente gegevens in de SQL-tabel. De nieuwe tabel wordt gemaakt tijdens het uitvoeren van query's wanneer PolyBase de externe gegevens ophaalt.
PolyBase kan een deel van de queryberekening naar Hadoop pushen om de queryprestaties te verbeteren. Deze actie wordt predicaatpushdown genoemd. Als u dit wilt inschakelen, geeft u de locatieoptie Hadoop resource manager op in CREATE EXTERNAL DATA SOURCE.
U kunt veel externe tabellen maken die verwijzen naar dezelfde of verschillende externe gegevensbronnen.
Beperkingen en beperkingen
Omdat de gegevens voor een externe tabel niet onder het directe beheer van het apparaat staan, kunnen deze op elk gewenst moment door een extern proces worden gewijzigd of verwijderd. Als gevolg hiervan zijn queryresultaten voor een externe tabel niet gegarandeerd deterministisch. Dezelfde query kan verschillende resultaten retourneren telkens wanneer deze wordt uitgevoerd op een externe tabel. Op dezelfde manier kan een query mislukken als de externe gegevens worden verplaatst of verwijderd.
U kunt meerdere externe tabellen maken die elk verwijzen naar verschillende externe gegevensbronnen. Als u gelijktijdig query's uitvoert op verschillende Hadoop-gegevensbronnen, moet elke Hadoop-bron dezelfde configuratie-instelling voor hadoop-connectiviteit gebruiken. U kunt bijvoorbeeld geen query tegelijk uitvoeren op een Cloudera Hadoop-cluster en een Hortonworks Hadoop-cluster, omdat deze verschillende configuratie-instellingen gebruiken. Zie PolyBase Connectivity Configurationvoor de configuratie-instellingen en ondersteunde combinaties.
Alleen deze DDL-instructies (Data Definition Language) zijn toegestaan voor externe tabellen:
- CREATE TABLE en DROP TABLE
- STATISTIEKEN MAKEN EN STATISTIEKEN VERWIJDEREN
- WEERGAVE EN DROP VIEW MAKEN
Constructies en bewerkingen worden niet ondersteund:
- De standaardbeperking voor externe tabelkolommen
- DML-bewerkingen (Data Manipulation Language) voor verwijderen, invoegen en bijwerken
- dynamische gegevensmaskering voor externe tabelkolommen
Querybeperkingen
PolyBase kan maximaal 33.000 bestanden per map gebruiken bij het uitvoeren van 32 gelijktijdige PolyBase-query's. Dit maximumaantal omvat zowel bestanden als submappen in elke HDFS-map. Als de mate van gelijktijdigheid kleiner is dan 32, kan een gebruiker PolyBase-query's uitvoeren op mappen in HDFS die meer dan 33k-bestanden bevatten. U wordt aangeraden externe bestandspaden kort te houden en niet meer dan 30k bestanden per HDFS-map te gebruiken. Wanneer er te veel bestanden naar worden verwezen, kan er een JVM-uitzondering (Java Virtual Machine) optreden.
Beperkingen voor tabelbreedte
PolyBase in SQL Server 2016 heeft een rijbreedtelimiet van 32 kB op basis van de maximale grootte van één geldige rij per tabeldefinitie. Als de som van het kolomschema groter is dan 32 kB, kan PolyBase geen query's uitvoeren op de gegevens.
In Azure Synapse Analytics is deze beperking verhoogd tot 1 MB.
Beperkingen voor gegevenstypen
De volgende gegevenstypen kunnen niet worden gebruikt in externe PolyBase-tabellen:
- geografie
- geometrie
- hierarchyid-
- afbeelding
- tekst
- xml--
- Elk door de gebruiker gedefinieerd type
Vergrendeling
Gedeelde vergrendeling op het OBJECT SCHEMARESOLUTION.
Veiligheid
De gegevensbestanden voor een externe tabel worden opgeslagen in Hadoop of Azure Blob Storage. Deze gegevensbestanden worden gemaakt en beheerd door uw eigen processen. Het is uw verantwoordelijkheid om de beveiliging van de externe gegevens te beheren.
Voorbeelden
Een. HDFS-gegevens samenvoegen met Analytics Platform System-gegevens
SELECT cs.user_ip FROM ClickStream cs
JOIN [User] u ON cs.user_ip = u.user_ip
WHERE cs.url = 'www.microsoft.com';
B. Rijgegevens uit HDFS importeren in een gedistribueerde analyseplatformsysteemtabel
CREATE TABLE ClickStream_PDW
WITH ( DISTRIBUTION = HASH (url) )
AS SELECT url, event_date, user_ip FROM ClickStream;
C. Rijgegevens uit HDFS importeren in een gerepliceerde analyseplatformsysteemtabel
CREATE TABLE ClickStream_PDW
WITH ( DISTRIBUTION = REPLICATE )
AS SELECT url, event_date, user_ip
FROM ClickStream;
Volgende stappen
Meer informatie over externe tabellen in Analytics Platform System vindt u in de volgende artikelen:
* Azure SQL Managed Instance *
Overzicht: Azure SQL Managed Instance
Hiermee maakt u een externe gegevenstabel in Azure SQL Managed Instance. Zie Gegevensvirtualisatie met Azure SQL Managed Instancevoor volledige informatie.
Gegevensvirtualisatie in Azure SQL Managed Instance biedt toegang tot externe gegevens in verschillende bestandsindelingen in Azure Data Lake Storage Gen2 of Azure Blob Storage, en om ze te doorzoeken met T-SQL-instructies, zelfs gegevens te combineren met lokaal opgeslagen relationele gegevens met behulp van joins.
Zie ook CREATE EXTERNAL DATA SOURCE en DROP EXTERNAL TABLE.
Syntaxis
CREATE EXTERNAL TABLE { database_name.schema_name.table_name | schema_name.table_name | table_name }
( <column_definition> [ ,...n ] )
WITH (
LOCATION = 'filepath',
DATA_SOURCE = external_data_source_name,
FILE_FORMAT = external_file_format_name
)
[;]
<column_definition> ::=
column_name <data_type>
[ COLLATE collation_name ]
[ NULL | NOT NULL ]
Argumenten
{ database_name.schema_name.table_name | schema_name.table_name | table_name }
De naam van één tot drie delen van de tabel die u wilt maken. Voor een externe tabel worden alleen de metagegevens van de tabel samen met basisstatistieken over het bestand of de map waarnaar wordt verwezen in Azure Data Lake of Azure Blob Storage. Er worden geen werkelijke gegevens verplaatst of opgeslagen wanneer externe tabellen worden gemaakt.
Belangrijk
Als het stuurprogramma van de externe gegevensbron een driedelige naam ondersteunt, wordt het ten zeerste aangeraden om de driedelige naam op te geven.
<column_definition> [ ,...n ]
CREATE EXTERNAL TABLE biedt ondersteuning voor de mogelijkheid om kolomnaam, gegevenstype, null-functionaliteit en sortering te configureren. U kunt de STANDAARDBEPERKING niet gebruiken voor externe tabellen.
De kolomdefinities, inclusief de gegevenstypen en het aantal kolommen, moeten overeenkomen met de gegevens in de externe bestanden. Als er een onjuiste overeenkomst is, worden de bestandsrijen geweigerd bij het uitvoeren van query's op de werkelijke gegevens.
LOCATION = 'folder_or_filepath'
Hiermee geeft u de map of het bestandspad en de bestandsnaam op voor de werkelijke gegevens in Azure Data Lake of Azure Blob Storage. De locatie begint vanuit de hoofdmap. De hoofdmap is de gegevenslocatie die is opgegeven in de externe gegevensbron.
CREATE EXTERNAL TABLE maakt het pad en de map niet.
Als u LOCATION opgeeft als een map, haalt de query van Azure SQL Managed Instance die uit de externe tabel selecteert bestanden op uit de map, maar niet alle submappen.
Azure SQL Managed Instance kan geen bestanden vinden in submappen of verborgen mappen. Het retourneert ook geen bestanden waarvoor de bestandsnaam begint met een onderstreping (_) of een punt (.).
In het volgende afbeeldingsvoorbeeld, als LOCATION='/webdata/', retourneert een query rijen uit mydata.txt. Het retourneert geen mydata2.txt omdat deze zich in een submap bevindt, het retourneert geen mydata3.txt omdat deze zich in een verborgen map bevindt en het _hidden.txt niet retourneert omdat het een verborgen bestand is.
DATA_SOURCE = external_data_source_name
Hiermee geeft u de naam op van de externe gegevensbron die de locatie van de externe gegevens bevat. Deze locatie bevindt zich in Azure Data Lake. Als u een externe gegevensbron wilt maken, gebruikt u CREATE EXTERNAL DATA SOURCE.
FILE_FORMAT = external_file_format_name
Hiermee geeft u de naam op van het externe bestandsindelingsobject waarin het bestandstype en de compressiemethode voor de externe gegevens worden opgeslagen. Als u een externe bestandsindeling wilt maken, gebruikt u CREATE EXTERNAL FILE FORMAT.
Machtigingen
Hiervoor zijn deze gebruikersmachtigingen vereist:
- CREATE TABLE-
- ALLE SCHEMA- WIJZIGEN
- EEN EXTERNE GEGEVENSBRON WIJZIGEN
- EEN EXTERNE BESTANDSINDELING WIJZIGEN
Notitie
CONTROL DATABASE-machtigingen zijn vereist om alleen de HOOFDSLEUTEL, DATABASE SCOPED CREDENTIAL en EXTERNAL DATA SOURCE te maken
Houd er rekening mee dat de aanmelding die de externe gegevensbron maakt, gemachtigd moet zijn om de externe gegevensbron te lezen en schrijven, die zich in Hadoop of Azure Blob Storage bevindt.
Belangrijk
Met de machtiging ALTER ANY EXTERNAL DATA SOURCE verleent elke principal de mogelijkheid om een extern gegevensbronobject te maken en te wijzigen, waardoor het ook de mogelijkheid verleent om toegang te krijgen tot alle referenties binnen het databasebereik. Deze machtiging moet worden beschouwd als zeer bevoegd en moet daarom alleen worden verleend aan vertrouwde principals in het systeem.
Opmerkingen
In ad-hocqueryscenario's, zoals SELECT FROM EXTERNAL TABLE, worden de rijen die uit de externe gegevensbron worden opgehaald, opgeslagen in een tijdelijke tabel. Nadat de query is voltooid, worden de rijen verwijderd en wordt de tijdelijke tabel verwijderd. Er worden geen permanente gegevens opgeslagen in SQL-tabellen.
In het importscenario, zoals SELECT INTO FROM EXTERNAL TABLE, worden de rijen die worden opgehaald uit de externe gegevensbron daarentegen opgeslagen als permanente gegevens in de SQL-tabel. De nieuwe tabel wordt gemaakt tijdens het uitvoeren van de query wanneer de externe gegevens worden opgehaald.
Op dit moment is gegevensvirtualisatie met Azure SQL Managed Instance alleen-lezen.
U kunt veel externe tabellen maken die verwijzen naar dezelfde of verschillende externe gegevensbronnen.
Beperkingen en beperkingen
Omdat de gegevens voor een externe tabel niet onder het directe beheer van Azure SQL Managed Instance staan, kunnen deze op elk gewenst moment door een extern proces worden gewijzigd of verwijderd. Als gevolg hiervan zijn queryresultaten voor een externe tabel niet gegarandeerd deterministisch. Dezelfde query kan verschillende resultaten retourneren telkens wanneer deze wordt uitgevoerd op een externe tabel. Op dezelfde manier kan een query mislukken als de externe gegevens worden verplaatst of verwijderd.
U kunt meerdere externe tabellen maken die elk verwijzen naar verschillende externe gegevensbronnen.
Alleen deze DDL-instructies (Data Definition Language) zijn toegestaan voor externe tabellen:
- CREATE TABLE en DROP TABLE
- STATISTIEKEN MAKEN EN STATISTIEKEN VERWIJDEREN
- WEERGAVE EN DROP VIEW MAKEN
Constructies en bewerkingen worden niet ondersteund:
- De standaardbeperking voor externe tabelkolommen
- DML-bewerkingen (Data Manipulation Language) voor verwijderen, invoegen en bijwerken
Beperkingen voor tabelbreedte
De rijbreedtelimiet van 1 MB is gebaseerd op de maximale grootte van één geldige rij per tabeldefinitie. Als de som van het kolomschema groter is dan 1 MB, mislukken gegevensvirtualisatiequery's.
Beperkingen voor gegevenstypen
De volgende gegevenstypen kunnen niet worden gebruikt in externe tabellen in Azure SQL Managed Instance:
- geografie
- geometrie
- hierarchyid-
- afbeelding
- tekst
- xml--
- json-
- Elk door de gebruiker gedefinieerd type
Vergrendeling
Gedeelde vergrendeling op het OBJECT SCHEMARESOLUTION.
Voorbeelden
Een. Query's uitvoeren op externe gegevens uit Azure SQL Managed Instance met een externe tabel
Zie Externe gegevensbron maken of zie Gegevensvirtualisatie met Azure SQL Managed Instancevoor meer voorbeelden.
Maak de hoofdsleutel van de database als deze niet bestaat.
-- Optional: Create MASTER KEY if it doesn't exist in the database: CREATE MASTER KEY ENCRYPTION BY PASSWORD = '<Strong Password>' GOMaak de databasereferentie met behulp van een SAS-token. U kunt ook een beheerde identiteit gebruiken.
CREATE DATABASE SCOPED CREDENTIAL MyCredential WITH IDENTITY = 'SHARED ACCESS SIGNATURE', SECRET = '<KEY>' ; --Removing leading '?' GOMaak de externe gegevensbron met behulp van de referentie.
--Create external data source pointing to the file path, and referencing database-scoped credential: CREATE EXTERNAL DATA SOURCE MyPrivateExternalDataSource WITH ( LOCATION = 'abs://public@pandemicdatalake.blob.core.windows.net/curated/covid-19/bing_covid-19_data/latest' CREDENTIAL = [MyCredential] ) GOMaak een EXTERNAL FILE FORMAT en een EXTERNAL TABLE om een query uit te voeren op de gegevens alsof het een lokale tabel is.
-- Or, create an EXTERNAL FILE FORMAT and an EXTERNAL TABLE --Create external file format CREATE EXTERNAL FILE FORMAT DemoFileFormat WITH ( FORMAT_TYPE=PARQUET ) GO --Create external table: CREATE EXTERNAL TABLE tbl_TaxiRides( vendorID VARCHAR(100) COLLATE Latin1_General_BIN2, tpepPickupDateTime DATETIME2, tpepDropoffDateTime DATETIME2, passengerCount INT, tripDistance FLOAT, puLocationId VARCHAR(8000), doLocationId VARCHAR(8000), startLon FLOAT, startLat FLOAT, endLon FLOAT, endLat FLOAT, rateCodeId SMALLINT, storeAndFwdFlag VARCHAR(8000), paymentType VARCHAR(8000), fareAmount FLOAT, extra FLOAT, mtaTax FLOAT, improvementSurcharge VARCHAR(8000), tipAmount FLOAT, tollsAmount FLOAT, totalAmount FLOAT ) WITH ( LOCATION = 'yellow/puYear=*/puMonth=*/*.parquet', DATA_SOURCE = NYCTaxiExternalDataSource, FILE_FORMAT = MyFileFormat ); GO --Then, query the data via an external table with T-SQL: SELECT TOP 10 * FROM tbl_TaxiRides; GO
Volgende stappen
Meer informatie over externe tabellen en gerelateerde concepten vindt u in de volgende artikelen: