Data-engineer instellingen voor werkruimtebeheer in Microsoft Fabric
Van toepassing op:✅ Data-engineer ing en Datawetenschap in Microsoft Fabric
Wanneer u een werkruimte maakt in Microsoft Fabric, wordt automatisch een starterspool gemaakt die aan die werkruimte is gekoppeld. Met de vereenvoudigde installatie in Microsoft Fabric hoeft u niet de grootte van het knooppunt of de machine te kiezen, omdat deze opties achter de schermen voor u worden afgehandeld. Deze configuratie biedt een snellere (5-10 seconden) Apache Spark-sessie voor gebruikers om aan de slag te gaan en uw Apache Spark-taken uit te voeren in veel voorkomende scenario's zonder dat u zich zorgen hoeft te maken over het instellen van de berekening. Voor geavanceerde scenario's met specifieke rekenvereisten kunnen gebruikers een aangepaste Apache Spark-pool maken en de grootte van de knooppunten aanpassen op basis van hun prestatiebehoeften.
Als u wijzigingen wilt aanbrengen in de Apache Spark-instellingen in een werkruimte, moet u de beheerdersrol voor die werkruimte hebben. Zie Rollen in werkruimten voor meer informatie.
De Spark-instellingen beheren voor de pool die is gekoppeld aan uw werkruimte:
Ga naar de werkruimte-instellingen in uw werkruimte en kies de optie Data-engineer ing/Science om het menu uit te vouwen:
U ziet de Spark Compute-optie in het menu aan de linkerkant:
Notitie
Als u de standaardpool wijzigt van Starter-pool in een aangepaste Spark-pool, ziet u mogelijk dat de sessie langer wordt gestart (~3 minuten).

Groep
Standaardgroep voor de werkruimte
U kunt de automatisch gemaakte starterspool gebruiken of aangepaste pools maken voor de werkruimte.
Starter Pool: Vooraf gehydrateerde live pools automatisch gemaakt voor uw snellere ervaring. Deze clusters zijn gemiddeld. De starterspool is ingesteld op een standaardconfiguratie op basis van de infrastructuurcapaciteits-SKU die is aangeschaft. Beheerders kunnen de maximale knooppunten en uitvoerders aanpassen op basis van hun Vereisten voor Spark-workloadschaal. Zie Starter-pools configureren voor meer informatie
Aangepaste Spark-pool: u kunt de knooppunten, automatische schaalaanpassing en dynamisch uitvoerders toewijzen op basis van uw Spark-taakvereisten. Als u een aangepaste Spark-pool wilt maken, moet de capaciteitsbeheerder de optie Aangepaste werkruimtegroepen inschakelen in de sectie Spark Compute van de instellingen voor capaciteitsbeheerder .
Notitie
Het capaciteitsniveaubeheer voor aangepaste werkruimtegroepen is standaard ingeschakeld. Zie Data Engineering- en data science-instellingen configureren en beheren voor fabric-capaciteiten voor meer informatie.
Beheerders kunnen aangepaste Spark-pools maken op basis van hun rekenvereisten door de optie Nieuwe pool te selecteren.

Apache Spark voor Microsoft Fabric ondersteunt clusters met één knooppunt, waardoor gebruikers een minimale knooppuntconfiguratie van 1 kunnen selecteren. In dat geval wordt het stuurprogramma en de uitvoerprogramma uitgevoerd in één knooppunt. Deze clusters met één knooppunt bieden herstelbare hoge beschikbaarheid tijdens knooppuntfouten en betere taakbetrouwbaarheid voor workloads met kleinere rekenvereisten. U kunt de optie voor automatisch schalen ook in- of uitschakelen voor uw aangepaste Spark-pools. Wanneer deze functie is ingeschakeld met automatische schaalaanpassing, krijgt de pool nieuwe knooppunten binnen de maximale knooppuntlimiet die door de gebruiker is opgegeven en worden buiten gebruik gesteld nadat de taak is uitgevoerd voor betere prestaties.
U kunt ook de optie selecteren om uitvoerders dynamisch toe te wijzen aan pool automatisch optimaal aantal uitvoerders binnen de maximale opgegeven grens op basis van het gegevensvolume voor betere prestaties.

Meer informatie over Apache Spark Compute voor Fabric.
- Rekenconfiguratie aanpassen voor items: als werkruimtebeheerder kunt u gebruikers toestaan rekenconfiguraties aan te passen (eigenschappen op sessieniveau, waaronder Driver/Executor Core, Driver/Executor Memory) voor afzonderlijke items, zoals notebooks, Spark-taakdefinities met behulp van de omgeving.
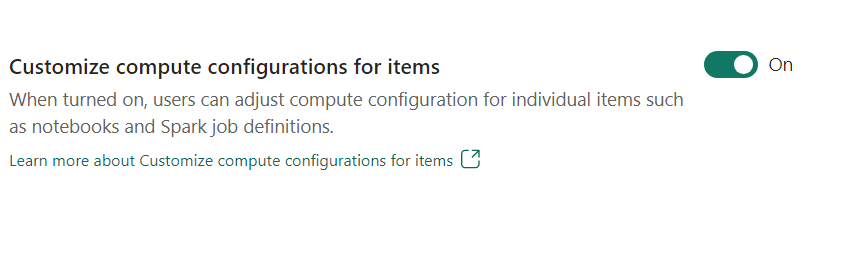
Als de instelling is uitgeschakeld door de werkruimtebeheerder, worden de standaardgroep en de rekenconfiguraties ervan gebruikt voor alle omgevingen in de werkruimte.
Omgeving
De omgeving biedt flexibele configuraties voor het uitvoeren van uw Spark-taken (notebooks, Spark-taakdefinities). In een omgeving kunt u rekeneigenschappen configureren, verschillende runtime selecteren, afhankelijkheden van bibliotheekpakketten instellen op basis van uw workloadvereisten.
Op het tabblad Omgeving kunt u de standaardomgeving instellen. U kunt kiezen welke versie van Spark u wilt gebruiken voor de werkruimte.
Als beheerder van een infrastructuurwerkruimte kunt u een omgeving selecteren als standaardomgeving voor de werkruimte.
U kunt ook een nieuwe maken via de vervolgkeuzelijst Omgeving .

Als u de optie voor een standaardomgeving uitschakelt, kunt u de fabric-runtimeversie selecteren in de beschikbare runtimeversies die worden vermeld in de vervolgkeuzelijst.

Meer informatie over Apache Spark-runtimes.
Projecten
Met taakinstellingen kunnen beheerders de toegangslogica voor taken voor alle Spark-taken in de werkruimte beheren.

Standaard zijn alle werkruimten ingeschakeld met Optimistische taaktoegang. Meer informatie over toegang tot taken voor Spark in Microsoft Fabric.
U kunt de maximale kernen van reserve voor actieve Spark-taken inschakelen om de benadering op basis van optimistische toegang tot taken te veranderen en maximale kernen voor hun Spark-taken te reserveren.
U kunt ook de time-out van de Spark-sessie instellen om het verlopen van de sessie voor alle interactieve notebooksessies aan te passen.
Notitie
Het verlopen van de standaardsessie is ingesteld op 20 minuten voor de interactieve Spark-sessies.
Hoge gelijktijdigheid
Met de modus Voor hoge gelijktijdigheid kunnen gebruikers dezelfde Spark-sessies delen in Apache Spark for Fabric-data engineering- en data science-workloads. Een item zoals een notebook maakt gebruik van een Spark-sessie voor de uitvoering en wanneer deze functie is ingeschakeld, kunnen gebruikers één Spark-sessie delen in meerdere notebooks.

Meer informatie over hoge gelijktijdigheid in Apache Spark for Fabric.
Automatische logboekregistratie voor Machine Learning-modellen en -experimenten
Beheerders kunnen nu automatisch registreren inschakelen voor hun machine learning-modellen en experimenten. Met deze optie worden automatisch de waarden van invoerparameters, metrische uitvoergegevens en uitvoeritems van een machine learning-model vastgelegd terwijl het wordt getraind. Meer informatie over automatisch inloggen.

Gerelateerde inhoud
- Meer informatie over Apache Spark Runtimes in Fabric: overzicht, versiebeheer, ondersteuning voor meerdere runtimes en het upgraden van Delta Lake Protocol.
- Meer informatie vindt u in de openbare documentatie van Apache Spark.
- Antwoorden vinden op veelgestelde vragen: Veelgestelde vragen over de beheerinstellingen voor Apache Spark-werkruimten.