Data engineering- en data science-instellingen configureren en beheren voor Fabric-capaciteiten
Van toepassing op:✅ Data-engineer ing en Datawetenschap in Microsoft Fabric
Wanneer u Microsoft Fabric maakt vanuit Azure Portal, wordt deze automatisch toegevoegd aan de Fabric-tenant die is gekoppeld aan het abonnement dat wordt gebruikt om de capaciteit te maken. Met de vereenvoudigde installatie in Microsoft Fabric hoeft u de capaciteit niet te koppelen aan de Fabric-tenant. Omdat de zojuist gemaakte capaciteit wordt weergegeven in het deelvenster Met beheerdersinstellingen. Deze configuratie biedt een snellere ervaring voor beheerders om de capaciteit voor hun enterprise analytics-teams in te stellen.
Als u wijzigingen wilt aanbrengen in de Data-engineer/Science-instellingen in een capaciteit, moet u de beheerdersrol voor die capaciteit hebben. Zie Rollen in capaciteiten voor meer informatie over de rollen die u aan gebruikers in een capaciteit kunt toewijzen.
Gebruik de volgende stappen om de Data-engineer/Science-instellingen voor Microsoft Fabric-capaciteit te beheren:
Selecteer de optie Instellingen om het instellingsvenster voor uw Fabric-account te openen. Beheerportal selecteren onder de sectie Governance en inzichten
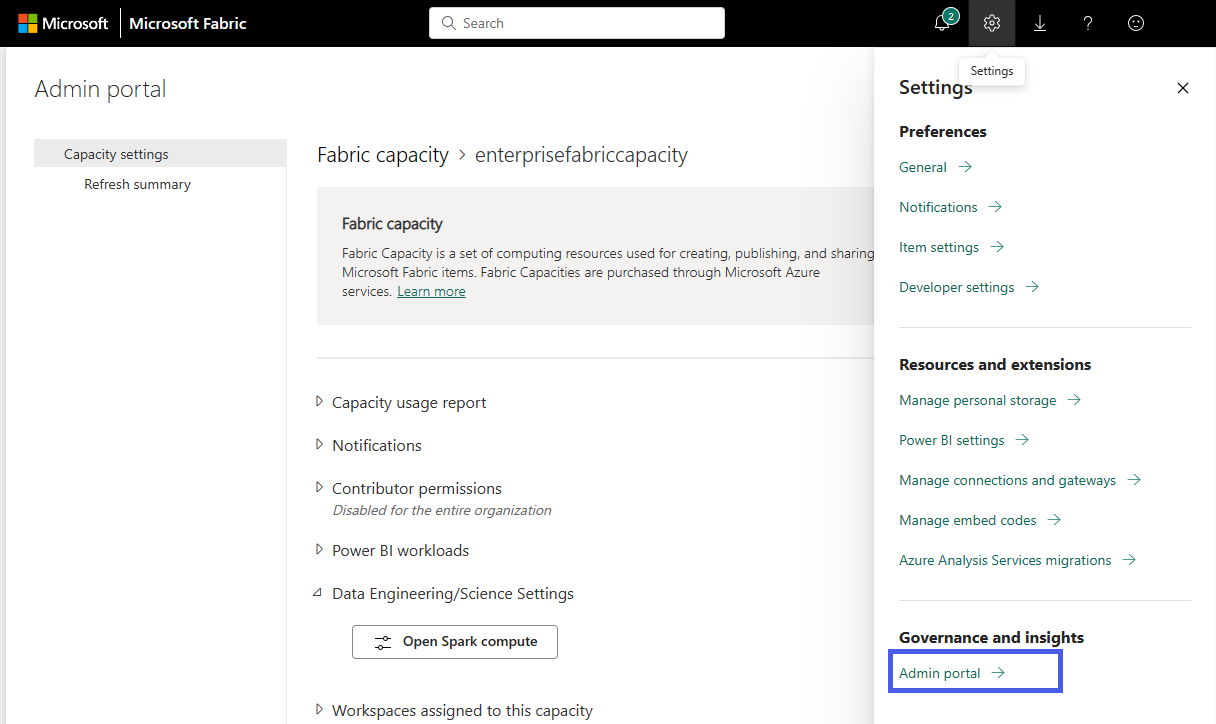
Kies de optie Capaciteitsinstellingen om het menu uit te vouwen en het tabblad Infrastructuurcapaciteit te selecteren. Hier ziet u de capaciteiten die u in uw tenant hebt gemaakt. Kies de capaciteit die u wilt configureren.
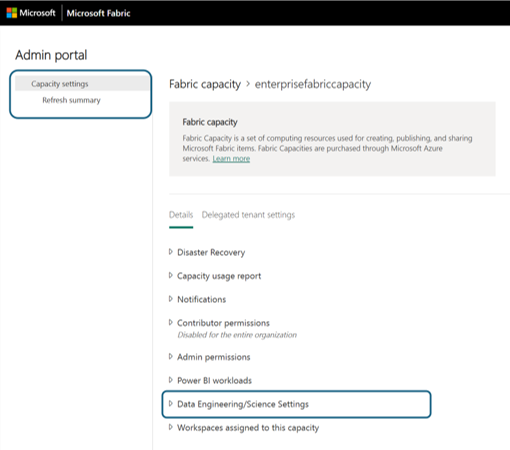
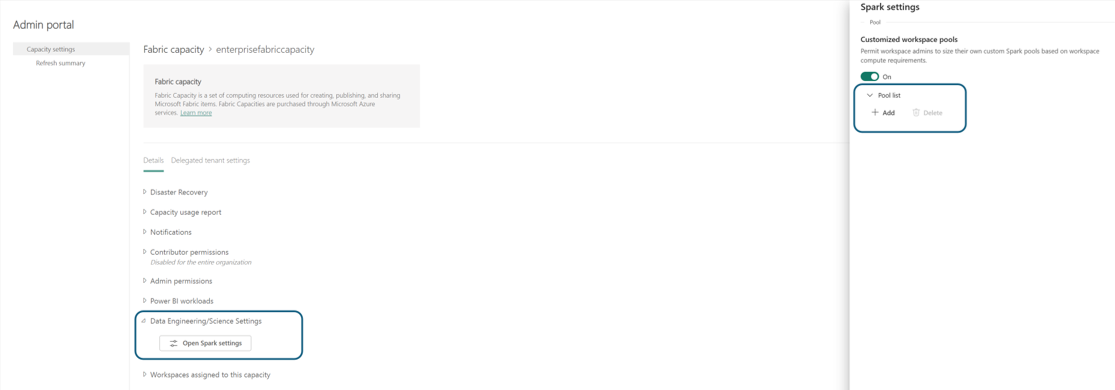
U gaat naar het detailvenster capaciteiten, waar u het gebruik en andere beheerbesturingselementen voor uw capaciteit kunt bekijken. Ga naar de sectie Data-engineer ing/Science Settings en selecteer Spark Compute openen. Configureer de volgende parameters:
Notitie
Ten minste één werkruimte moet worden gekoppeld aan de infrastructuurcapaciteit om de Data Engineering/Science-instellingen te verkennen vanuit de portal voor infrastructuurcapaciteitsbeheerders.
- Aangepaste werkruimtegroepen: U kunt rekenaanpassing beperken of democratiseren voor werkruimtebeheerders door deze optie in of uit te schakelen. Als u deze optie inschakelt, kunnen werkruimtebeheerders aangepaste Spark-pools op werkruimteniveau maken, bijwerken of verwijderen. Daarnaast kunt u de grootte ervan wijzigen op basis van de rekenvereisten binnen de maximale limiet voor kerngeheugens van een capaciteit.
Capaciteitspools voor Data-engineer en Datawetenschap in Microsoft Fabric (openbare preview)
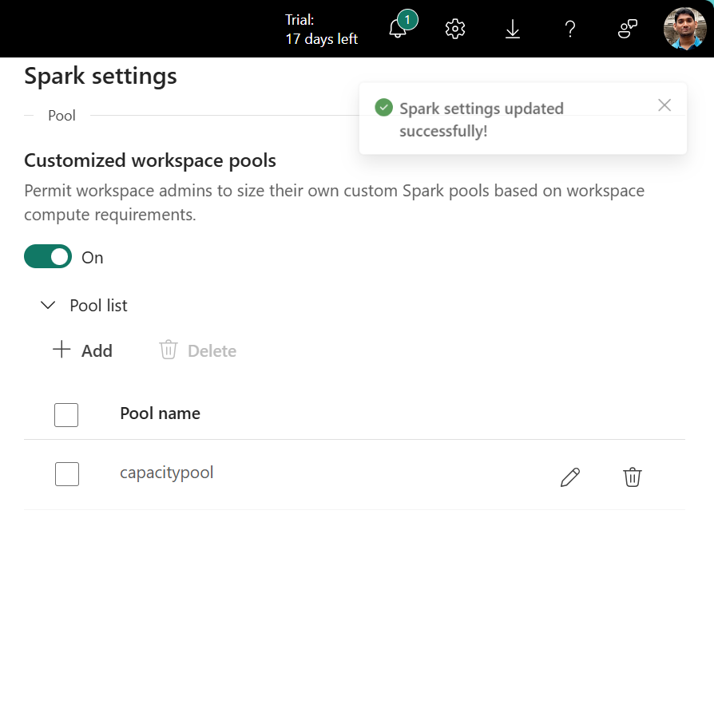
Klik in de sectie Poollijst van Spark-instellingen op de optie Toevoegen om een aangepaste pool te maken voor uw infrastructuurcapaciteit.
U gaat naar de sectie Pool maken, waarin u de naam van de pool, de knooppuntfamilie, de knooppuntgrootte selecteert en de knooppunten Min en Max voor uw aangepaste pool instelt, automatische schaalaanpassing en dynamische toewijzing van uitvoerders inschakelt/uitschakelt.
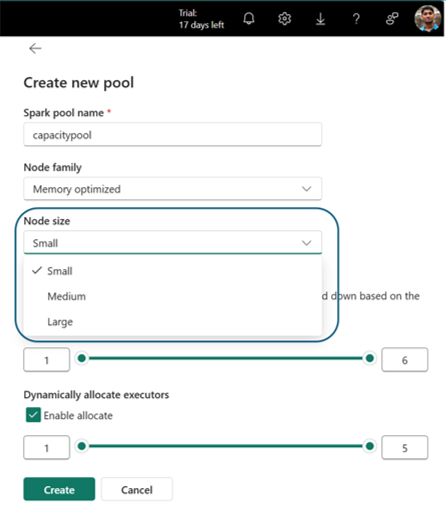
Selecteer De instellingen maken en opslaan.

Notitie
De aangepaste pools die in de capaciteitsinstellingen zijn gemaakt, hebben een latentie van 2 minuten tot 3 minuten, omdat dit sessies op aanvraag zijn, in tegenstelling tot de sessies die worden uitgevoerd via Starter-pools.
De zojuist gemaakte capaciteitspool is nu beschikbaar als een compute-optie in het menu Poolselectie in alle werkruimten die aan deze infrastructuurcapaciteit zijn gekoppeld.
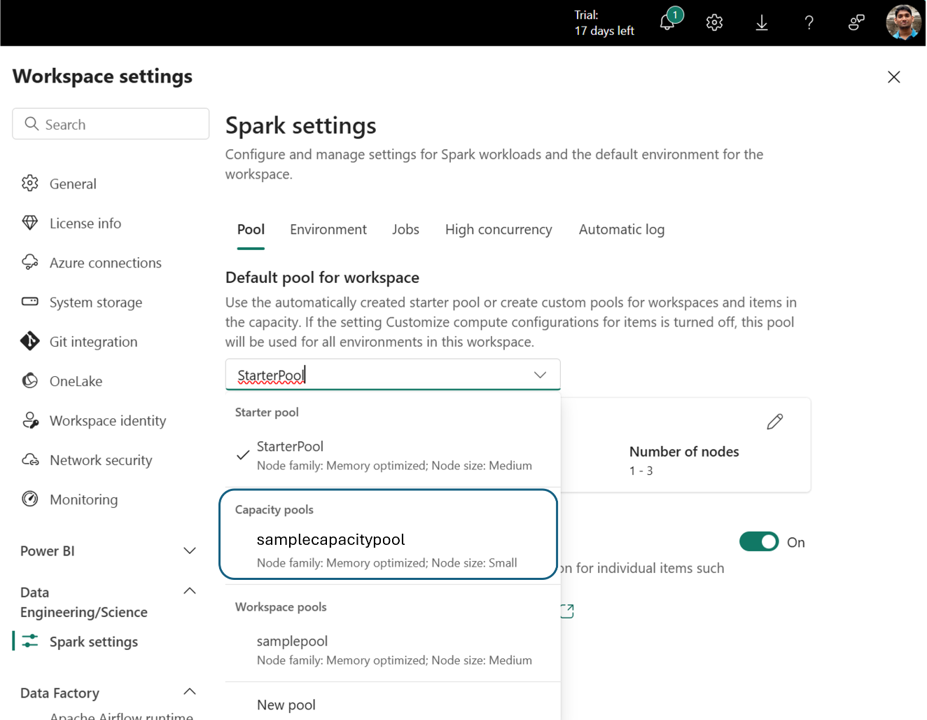
U kunt de gemaakte capaciteitspool ook weergeven als een rekenoptie in het omgevingsitem in de werkruimten.
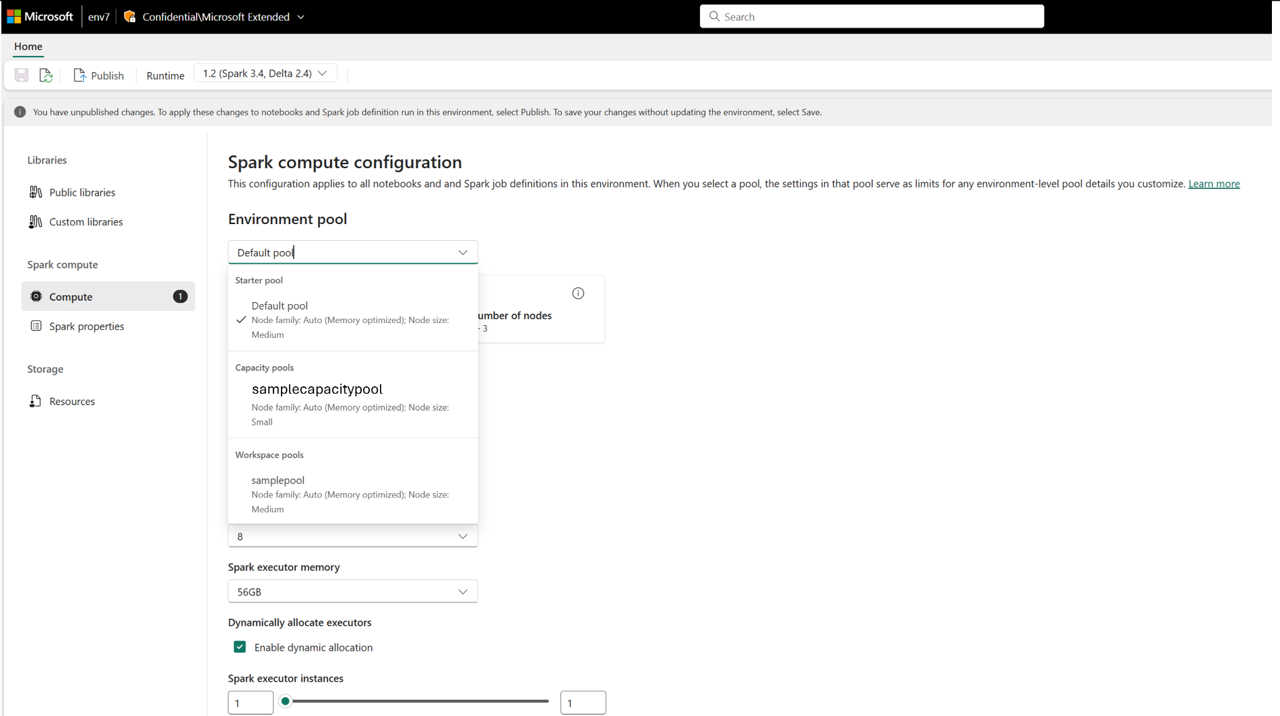
Dit biedt andere beheeropties voor het beheren van rekenbeheer voor uw Spark-rekenproces in Microsoft Fabric. Als capaciteitsbeheerder kunt u pools voor werkruimten maken en aanpassingen op werkruimteniveau uitschakelen, waardoor werkruimtebeheerders geen aangepaste pools kunnen maken.