Apache Spark Runtimes in Fabric
Microsoft Fabric Runtime is een geïntegreerd Azure-platform op basis van Apache Spark waarmee de uitvoering en het beheer van data engineering- en data science-ervaringen mogelijk is. Het combineert belangrijke onderdelen van zowel interne als opensource-bronnen en biedt klanten een uitgebreide oplossing. Ter vereenvoudiging verwijzen we naar Microsoft Fabric Runtime mogelijk gemaakt door Apache Spark als Fabric Runtime.
Belangrijke onderdelen van Fabric Runtime:
Apache Spark : een krachtige opensource gedistribueerde computingbibliotheek waarmee grootschalige gegevensverwerkings- en analysetaken mogelijk zijn. Apache Spark biedt een veelzijdig en krachtige platform voor data engineering- en data science-ervaringen.
Delta Lake : een opensource-opslaglaag die ACID-transacties en andere functies voor gegevensbetrouwbaarheid naar Apache Spark brengt. Delta Lake is geïntegreerd in Fabric Runtime en verbetert de mogelijkheden voor gegevensverwerking en zorgt voor gegevensconsistentie voor meerdere gelijktijdige bewerkingen.
De systeemeigen uitvoeringsengine is een transformatieve verbetering voor Apache Spark-workloads, wat aanzienlijke prestatieverbeteringen biedt door rechtstreeks Spark-query's uit te voeren op lakehouse-infrastructuur. Naadloos geïntegreerd, vereist het geen codewijzigingen en voorkomt vergrendeling van leveranciers, waarbij zowel Parquet- als Delta-indelingen worden ondersteund in Apache Spark-API's in Runtime 1.3 (Spark 3.5). Deze engine verhoogt de querysnelheden tot vier keer sneller dan traditionele OSS Spark, zoals wordt weergegeven door de TPC-DS 1TB-benchmark, waardoor de operationele kosten worden verlaagd en de efficiëntie in verschillende gegevenstaken wordt verbeterd, waaronder gegevensopname, ETL, analyse en interactieve query's. Gebouwd op Meta's Velox en Intel's Apache Gluten, optimaliseert het resourcegebruik tijdens het verwerken van diverse gegevensverwerkingsscenario's.
Pakketten op standaardniveau voor Java/Scala, Python en R - pakketten die verschillende programmeertalen en omgevingen ondersteunen. Deze pakketten worden automatisch geïnstalleerd en geconfigureerd, zodat ontwikkelaars hun favoriete programmeertalen voor gegevensverwerkingstaken kunnen toepassen.
De Microsoft Fabric Runtime is gebaseerd op een robuust opensource-besturingssysteem, waardoor de compatibiliteit met verschillende hardwareconfiguraties en systeemvereisten wordt gewaarborgd.
Hieronder vindt u een uitgebreide vergelijking van belangrijke onderdelen, waaronder Apache Spark-versies, ondersteunde besturingssystemen, Java, Scala, Python, Delta Lake en R, voor op Apache Spark gebaseerde runtimes binnen het Microsoft Fabric-platform.
Tip
Gebruik altijd de meest recente ga-runtimeversie voor uw productieworkload, die momenteel Runtime 1.3 is.
| Runtime 1.1 | Runtime 1.2 | Runtime 1.3 | |
|---|---|---|---|
| Releasefase | EOSA | GA | GA |
| Apache Spark | 3.3.1 | 3.4.1 | 3.5.0 |
| Besturingssysteem | Ubuntu 18.04 | Mariner 2.0 | Mariner 2.0 |
| Java | 8 | 11 | 11 |
| Scala | 2.12.15 | 2.12.17 | 2.12.17 |
| Python | 3.10 | 3.10 | 3.11 |
| Delta Lake | 2.2.0 | 2.4.0 | 3.2 |
| R | 4.2.2 | 4.2.2 | 4.4.1 |
Ga naar Runtime 1.1, Runtime 1.2 of Runtime 1.3 om details, nieuwe functies, verbeteringen en migratiescenario's voor de specifieke runtimeversie te verkennen.
Infrastructuuroptimalisaties
In Microsoft Fabric bevatten zowel de Spark-engine als de Delta Lake-implementaties platformspecifieke optimalisaties en -functies. Deze functies zijn ontworpen voor het gebruik van systeemeigen integraties binnen het platform. Het is belangrijk om te weten dat al deze functies kunnen worden uitgeschakeld om standaard spark- en Delta Lake-functionaliteit te bereiken. De Fabric Runtimes voor Apache Spark omvatten:
- De volledige opensource-versie van Apache Spark.
- Een verzameling van bijna 100 ingebouwde, unieke verbeteringen in queryprestaties. Deze verbeteringen omvatten functies zoals partition caching (waardoor de bestandssysteempartitiecache wordt ingeschakeld om metastore-aanroepen te verminderen) en Cross Join to Projection of Scalar Subquery.
- Ingebouwde intelligente cache.
Binnen de Fabric Runtime voor Apache Spark en Delta Lake zijn er systeemeigen schrijfmogelijkheden die twee belangrijke doeleinden dienen:
- Ze bieden gedifferentieerde prestaties voor het schrijven van workloads, waardoor het schrijfproces wordt geoptimaliseerd.
- Ze zijn standaard ingesteld op V-Order-optimalisatie van Delta Parquet-bestanden. De optimalisatie van Delta Lake V-Order is van cruciaal belang voor het leveren van superieure leesprestaties voor alle fabric-engines. Raadpleeg het speciale artikel over Optimalisatie van Delta Lake-tabellen en V-Order voor meer inzicht in hoe het werkt en hoe u het beheert.
Ondersteuning voor meerdere runtimes
Fabric ondersteunt meerdere runtimes en biedt gebruikers de flexibiliteit om naadloos tussen deze runtimes te schakelen, waardoor het risico op incompatibiliteit of onderbrekingen wordt geminimaliseerd.
Standaard gebruiken alle nieuwe werkruimten de nieuwste runtimeversie, die momenteel Runtime 1.3 is.
Als u de runtimeversie op werkruimteniveau wilt wijzigen, gaat u naar Werkruimte-instellingen>Data Engineering/Science>Spark-instellingen. Selecteer op het tabblad Environment de gewenste runtimeversie uit de beschikbare opties. Selecteer opslaan om uw selectie te bevestigen.
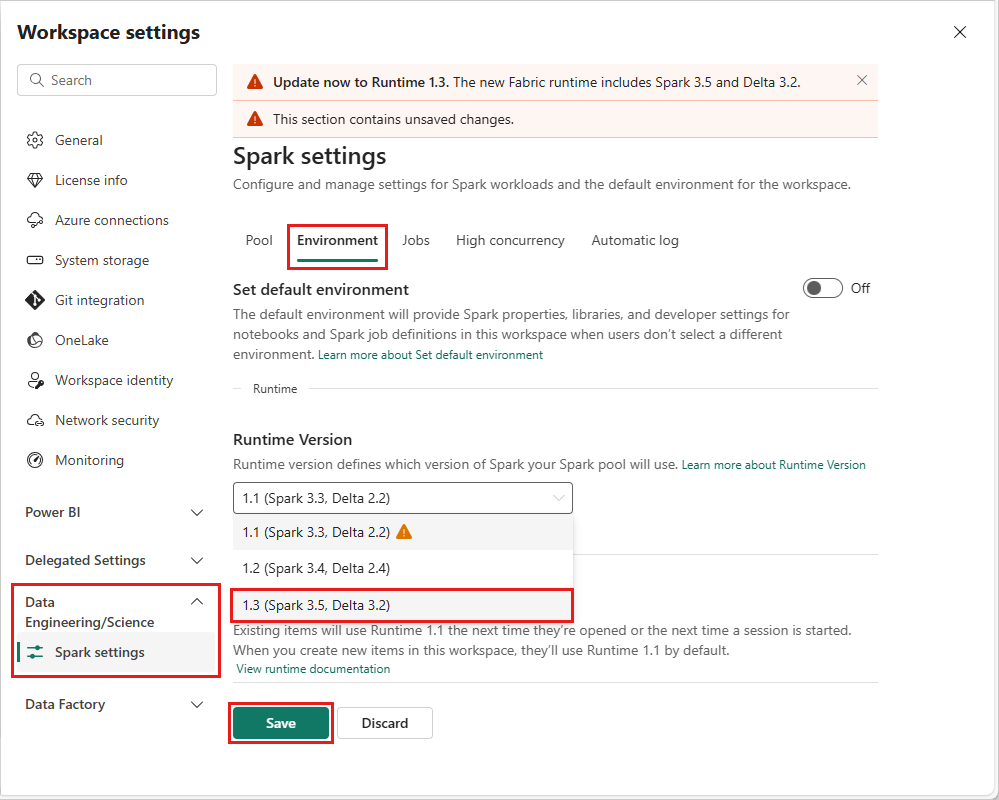
Zodra u deze wijziging hebt aangebracht, werken alle door het systeem gemaakte items in de werkruimte, waaronder Lakehouses, SJD's en Notebooks, met behulp van de zojuist geselecteerde runtimeversie op werkruimteniveau vanaf de volgende Spark-sessie. Als u momenteel een notebook gebruikt met een bestaande sessie voor een taak of een aan Lakehouse gerelateerde activiteit, gaat die Spark-sessie gewoon door. Vanaf de volgende sessie of taak wordt de geselecteerde runtimeversie echter toegepast.
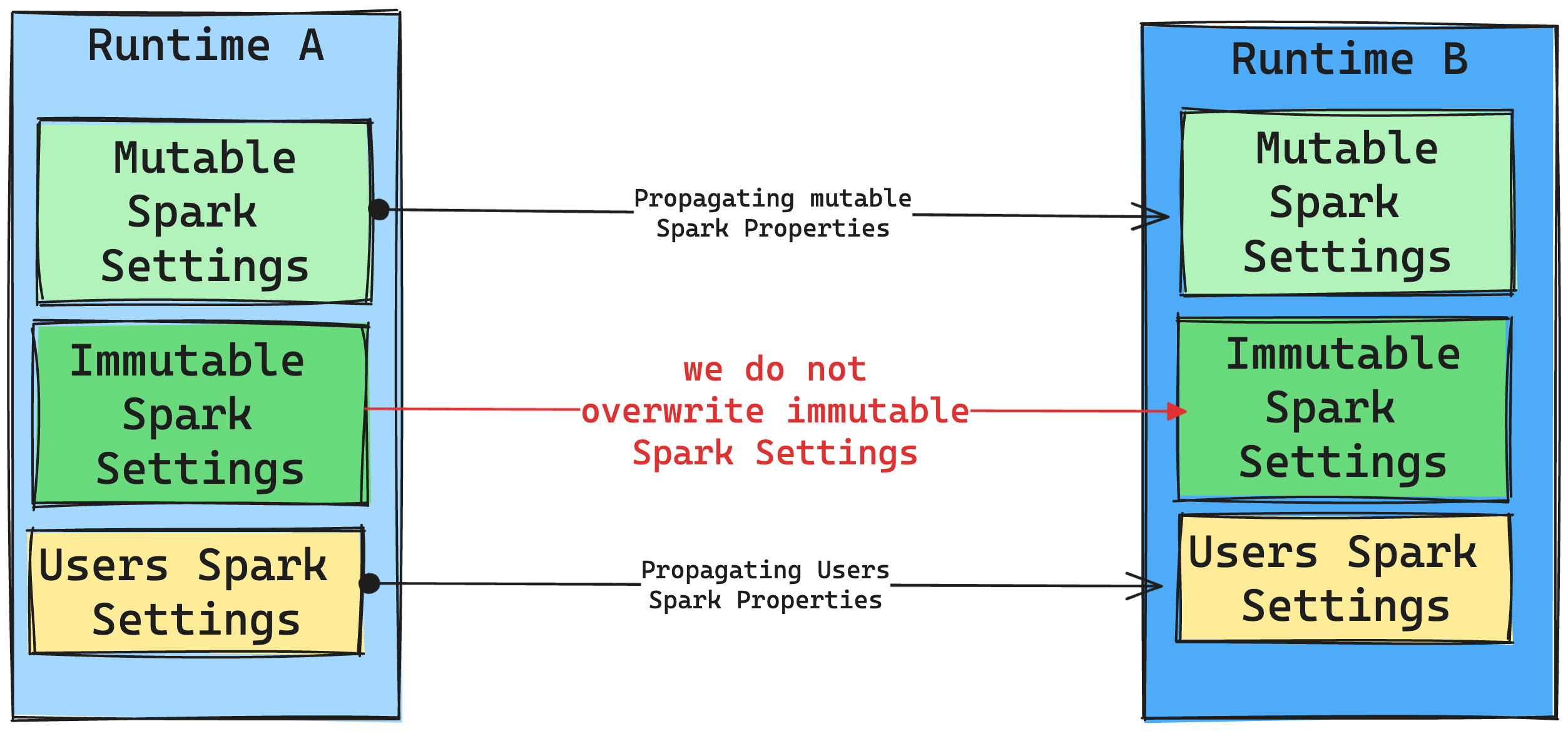
Gevolgen van runtimewijzigingen in Spark-instellingen
Over het algemeen streven we ernaar om alle Spark-instellingen te migreren. Als we echter vaststellen dat de Spark-instelling niet compatibel is met Runtime B, geven we een waarschuwingsbericht en onthouden we van het implementeren van de instelling.
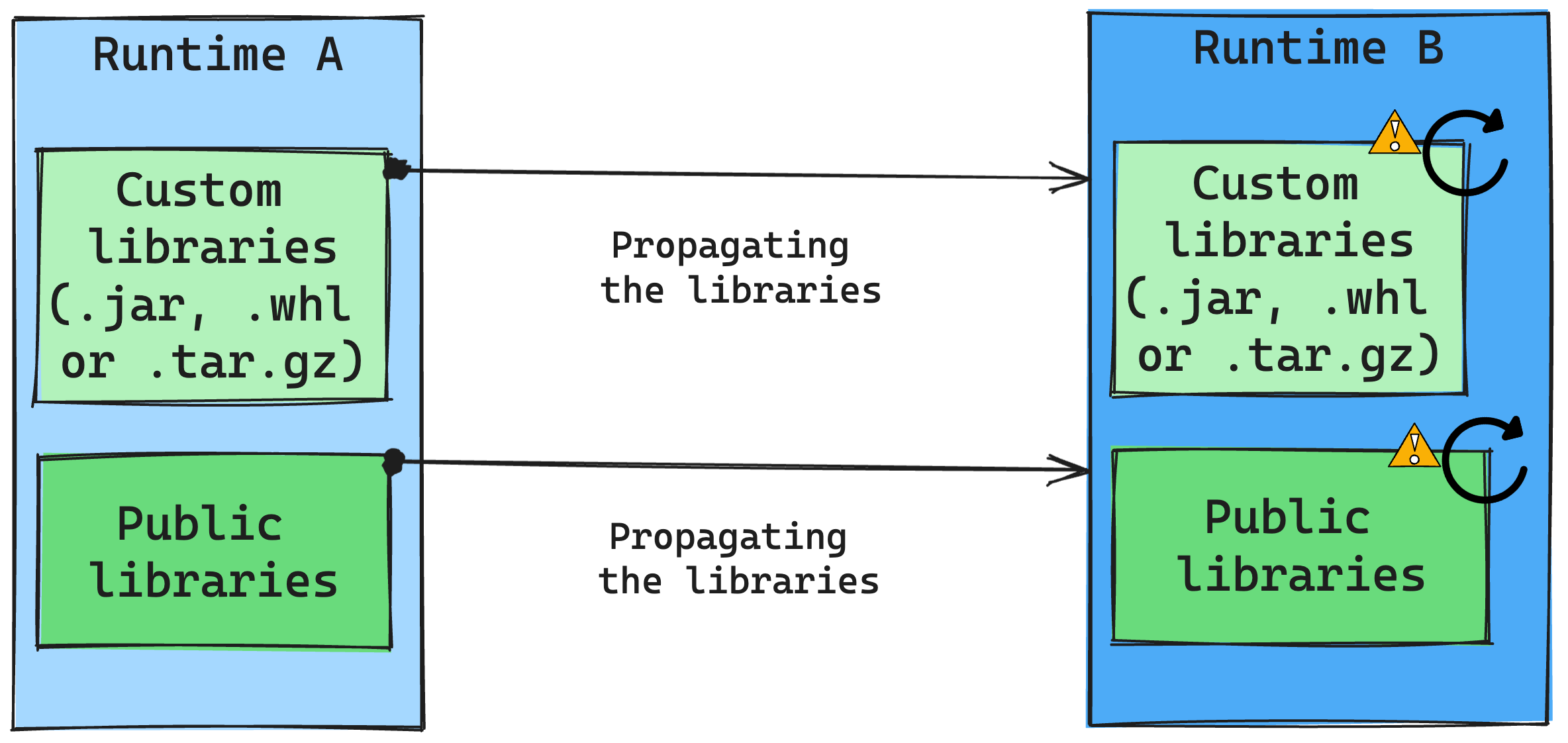
Gevolgen van runtimewijzigingen in bibliotheekbeheer
Over het algemeen is het migreren van alle bibliotheken van Runtime A naar Runtime B, inclusief openbare en aangepaste runtimes. Als de Python- en R-versies ongewijzigd blijven, moeten de bibliotheken goed werken. Voor Jars is er echter een aanzienlijke kans dat ze niet werken vanwege wijzigingen in afhankelijkheden en andere factoren, zoals wijzigingen in Scala, Java, Spark en het besturingssysteem.
De gebruiker is verantwoordelijk voor het bijwerken of vervangen van bibliotheken die niet werken met Runtime B. Als er een conflict is, wat betekent dat Runtime B een bibliotheek bevat die oorspronkelijk is gedefinieerd in Runtime A, probeert ons bibliotheekbeheersysteem de benodigde afhankelijkheid voor Runtime B te maken op basis van de instellingen van de gebruiker. Het bouwproces mislukt echter als er een conflict optreedt. In het foutenlogboek kunnen gebruikers zien welke bibliotheken conflicten veroorzaken en wijzigingen aanbrengen in hun versies of specificaties.
Delta Lake-protocol upgraden
Delta Lake-functies zijn altijd achterwaarts compatibel, zodat tabellen die zijn gemaakt in een lagere Delta Lake-versie naadloos kunnen communiceren met hogere versies. Wanneer bepaalde functies echter zijn ingeschakeld (bijvoorbeeld met behulp van een delta.upgradeTableProtocol(minReaderVersion, minWriterVersion) methode, kan de compatibiliteit met lagere Delta Lake-versies worden aangetast. In dergelijke gevallen is het essentieel om workloads te wijzigen die verwijzen naar de bijgewerkte tabellen om te worden afgestemd op een Delta Lake-versie die compatibiliteit onderhoudt.
Elke Delta-tabel is gekoppeld aan een protocolspecificatie en definieert de functies die worden ondersteund. Toepassingen die communiceren met de tabel, voor lezen of schrijven, zijn afhankelijk van deze protocolspecificatie om te bepalen of ze compatibel zijn met de functieset van de tabel. Als een toepassing niet beschikt over de mogelijkheid om een functie te verwerken die wordt vermeld als ondersteund in het protocol van de tabel, kan deze niet worden gelezen van of naar die tabel worden geschreven.
De protocolspecificatie is onderverdeeld in twee afzonderlijke onderdelen: het leesprotocol en het schrijfprotocol. Ga naar de pagina 'Hoe beheert Delta Lake functiecompatibiliteit?' voor meer informatie.

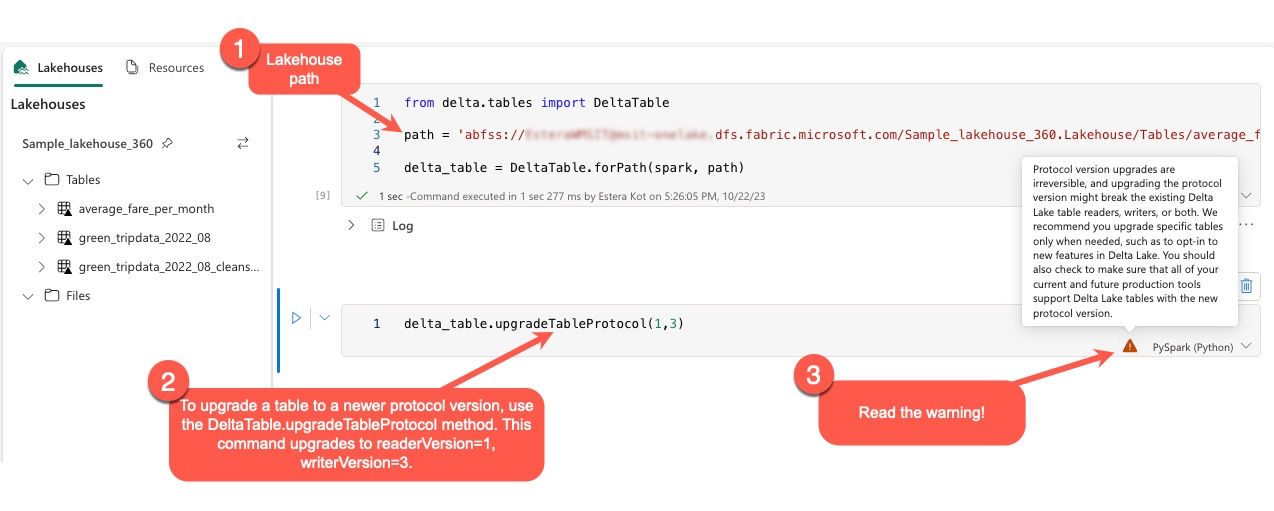
Gebruikers kunnen de opdracht delta.upgradeTableProtocol(minReaderVersion, minWriterVersion) uitvoeren in de PySpark-omgeving en in Spark SQL en Scala. Met deze opdracht kunnen ze een update initiëren in de Delta-tabel.
Het is essentieel om te weten dat gebruikers bij het uitvoeren van deze upgrade een waarschuwing ontvangen die aangeeft dat het upgraden van de Delta-protocolversie een niet-omkeerbaar proces is. Dit betekent dat nadat de update is uitgevoerd, deze niet ongedaan kan worden gemaakt.
Upgrades van protocolversies kunnen mogelijk van invloed zijn op de compatibiliteit van bestaande Delta Lake-tabellezers, schrijvers of beide. Daarom is het raadzaam om voorzichtig te blijven en de protocolversie alleen bij te werken wanneer dat nodig is, zoals bij het aannemen van nieuwe functies in Delta Lake.
Daarnaast moeten gebruikers controleren of alle huidige en toekomstige productieworkloads en -processen compatibel zijn met Delta Lake-tabellen met behulp van de nieuwe protocolversie om een naadloze overgang te garanderen en mogelijke onderbrekingen te voorkomen.
Delta 2.2 versus Delta 2.4-wijzigingen
In de nieuwste Fabric Runtime, versie 1.3 en Fabric Runtime, versie 1.2, is de standaardtabelindeling (spark.sql.sources.default) nu delta. In eerdere versies van Fabric Runtime, versie 1.1 en op alle Synapse Runtime voor Apache Spark met Spark 3.3 of lager, is de standaardtabelindeling gedefinieerd als parquet. Raadpleeg de tabel met configuratiedetails van Apache Spark voor verschillen tussen Azure Synapse Analytics en Microsoft Fabric.
Alle tabellen die zijn gemaakt met Spark SQL, PySpark, Scala Spark en Spark R, wanneer het tabeltype wordt weggelaten, maken de tabel standaard delta . Als scripts expliciet de tabelindeling instellen, wordt dat gerespecteerd. De opdracht USING DELTA in Spark create table commands wordt redundant.
Scripts die de parquet-tabelindeling verwachten of aannemen, moeten worden gewijzigd. De volgende opdrachten worden niet ondersteund in Delta-tabellen:
ANALYZE TABLE $partitionedTableName PARTITION (p1) COMPUTE STATISTICSALTER TABLE $partitionedTableName ADD PARTITION (p1=3)ALTER TABLE DROP PARTITIONALTER TABLE RECOVER PARTITIONSALTER TABLE SET SERDEPROPERTIESLOAD DATAINSERT OVERWRITE DIRECTORYSHOW CREATE TABLECREATE TABLE LIKE