Wat zijn lakehouse-schema's (preview)?
Lakehouse ondersteunt het maken van aangepaste schema's. Met schema's kunt u uw tabellen groeperen voor betere gegevensdetectie, toegangsbeheer en meer.
Een Lakehouse-schema maken
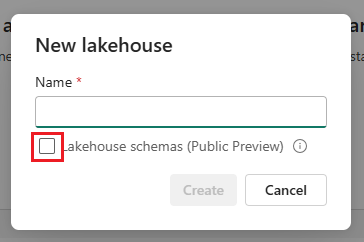
Als u schemaondersteuning voor uw lakehouse wilt inschakelen, schakelt u het selectievakje in naast Lakehouse-schema's (openbare preview) wanneer u deze maakt.
Belangrijk
Werkruimtenamen mogen alleen alfanumerieke tekens bevatten vanwege preview-beperkingen. Als er speciale tekens worden gebruikt in werkruimtenamen, werken sommige functies van Lakehouse niet.
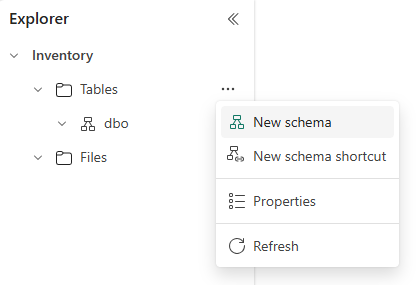
Zodra u het lakehouse hebt gemaakt, kunt u een standaardschema met de naam dbo onder Tabellen vinden. Dit schema is altijd aanwezig en kan niet worden gewijzigd of verwijderd. Als u een nieuw schema wilt maken, plaatst u de muisaanwijzer op Tabellen, selecteert u ...en kiest u Nieuw schema. Voer de naam van het schema in en selecteer Maken. Uw schema wordt weergegeven onder Tabellen in alfabetische volgorde.
Tabellen opslaan in Lakehouse-schema's
U hebt een schemanaam nodig om een tabel in een schema op te slaan. Anders wordt het standaard-dbo-schema gebruikt.
df.write.mode("Overwrite").saveAsTable("contoso.sales")
U kunt Lakehouse Explorer gebruiken om uw tabellen te rangschikken en tabelnamen naar verschillende schema's te slepen en neer te zetten.
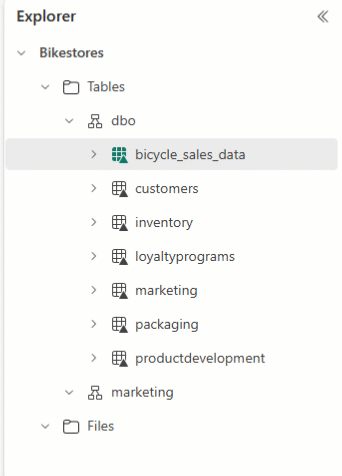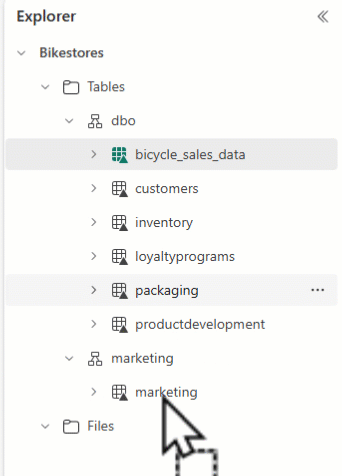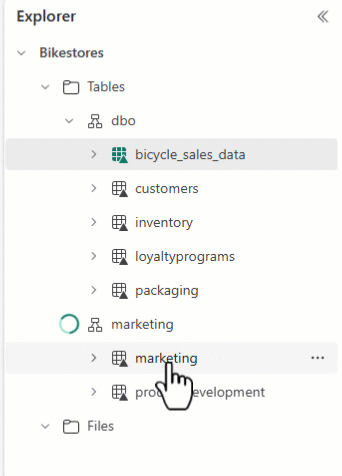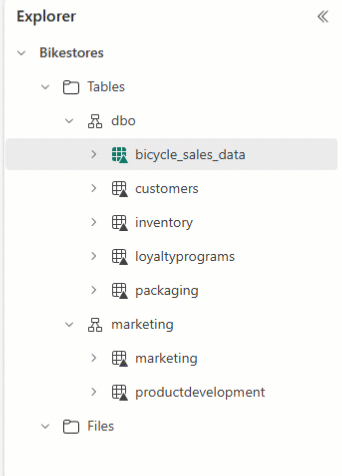
Let op
Als u de tabel wijzigt, moet u ook gerelateerde items, zoals notebookcode of gegevensstromen, bijwerken om ervoor te zorgen dat ze zijn uitgelijnd met het juiste schema.
Meerdere tabellen met schemasnelkoppeling gebruiken
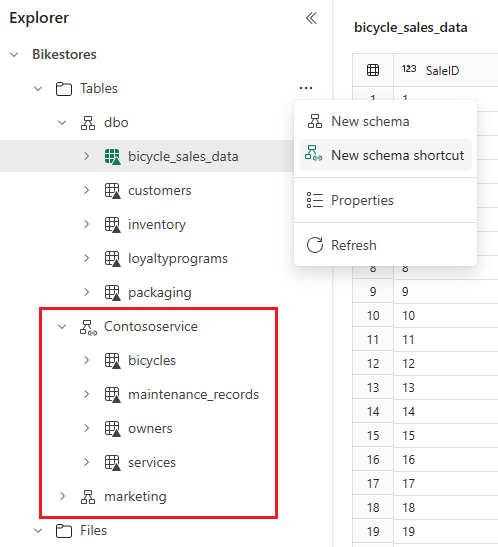
Als u wilt verwijzen naar meerdere Delta-tabellen uit andere Fabric Lakehouse of externe opslag, gebruikt u schemasnelkoppeling waarmee alle tabellen onder het gekozen schema of de gekozen map worden weergegeven. Wijzigingen in de tabellen op de bronlocatie worden ook weergegeven in het schema. Als u een schemasnelkoppeling wilt maken, plaatst u de muisaanwijzer op Tabellen, selecteert u ...en kiest u Nieuwe schemasnelkoppeling. Selecteer vervolgens een schema in een ander lakehouse of een map met Delta-tabellen in uw externe opslag, zoals Azure Data Lake Storage (ADLS) Gen2. Hiermee maakt u een nieuw schema met de tabellen waarnaar wordt verwezen.
Access Lakehouse-schema's voor Power BI-rapportage
Als u uw semantische model wilt maken, kiest u de tabellen die u wilt gebruiken. Tabellen kunnen zich in verschillende schema's bevinden. Als tabellen uit verschillende schema's dezelfde naam hebben, ziet u getallen naast tabelnamen in de modelweergave.
Lakehouse-schema's in notebook
Wanneer u kijkt naar een schema waarvoor Lakehouse is ingeschakeld in de notebook-objectverkenner, ziet u dat tabellen in schema's staan. U kunt een tabel naar een codecel slepen en neerzetten en een codefragment ophalen dat verwijst naar het schema waarin de tabel zich bevindt. Gebruik deze naamruimte om te verwijzen naar tabellen in uw code: workspace.lakehouse.schema.table. Als u een van de elementen weglaat, gebruikt de uitvoerder de standaardinstelling. Als u bijvoorbeeld alleen tabelnaam geeft, wordt standaardschema (dbo) gebruikt vanuit het standaard lakehouse voor het notebook.
Belangrijk
Als u schema's in uw code wilt gebruiken, moet u ervoor zorgen dat het standaard lakehouse voor het notebook is ingeschakeld.
Spark SQL-query's voor meerdere werkruimten
Gebruik de naamruimte workspace.lakehouse.schema.table om te verwijzen naar tabellen in uw code. Op deze manier kunt u tabellen uit verschillende werkruimten samenvoegen als de gebruiker die de code uitvoert, gemachtigd is voor toegang tot de tabellen.
SELECT *
FROM operations.hr.hrm.employees as employees
INNER JOIN global.corporate.company.departments as departments
ON employees.deptno = departments.deptno;
Belangrijk
Zorg ervoor dat u tabellen alleen uit lakehouses koppelt waarvoor schema's zijn ingeschakeld. Het samenvoegen van tabellen vanuit lakehouses waarvoor geen schema's zijn ingeschakeld, werkt niet.
Beperkingen van openbare preview
Hieronder staan niet-ondersteunde functies/functionaliteiten voor de huidige versie van openbare preview. Ze worden opgelost in de komende releases vóór algemene beschikbaarheid.
| Niet-ondersteunde functies/functionaliteit | Opmerkingen |
|---|---|
| Gedeeld lakehouse | Het gebruik van werkruimte in de naamruimte voor gedeelde lakehouses werkt niet, bijvoorbeeld wokrkspace.sharedlakehouse.schema.table. De gebruiker moet de werkruimterol hebben om de werkruimte in de namaspace te kunnen gebruiken. |
| Niet-Delta, beheerd tabelschema | Het ophalen van een schema voor beheerde, niet-Delta opgemaakte tabellen (bijvoorbeeld CSV) wordt niet ondersteund. Als u deze tabellen uitbreidt in Lakehouse Explorer, worden er geen schemagegevens weergegeven in de UX. |
| Externe Spark-tabellen | Externe Spark-tabelbewerkingen (bijvoorbeeld detectie, schema ophalen, enzovoort) worden niet ondersteund. Deze tabellen zijn niet geïdentificeerd in de UX. |
| Openbare API | Openbare API's (Lijsttabellen, Tabel laden, standaardSchema uitgebreide eigenschap, enzovoort) worden niet ondersteund voor Schema enabled Lakehouse. Bestaande openbare API's die worden aangeroepen op een schema waarvoor Lakehouse is ingeschakeld, resulteert in een fout. |
| Tabeleigenschappen bijwerken | Wordt niet ondersteund. |
| Werkruimtenaam met speciale tekens | Werkruimte met speciale tekens (bijvoorbeeld spatie, slashes) wordt niet ondersteund. Er wordt een gebruikersfout weergegeven. |
| Spark-weergaven | Wordt niet ondersteund. |
| Specifieke Hive-functies | Wordt niet ondersteund. |
| Spark.catalog-API | Wordt niet ondersteund. Gebruik in plaats daarvan Spark SQL. |
USE <schemaName> |
Werkt niet tussen werkruimten, maar wordt ondersteund binnen dezelfde werkruimte. |
| Migratie | Migratie van bestaande niet-schema Lakehouses naar op schema gebaseerde Lakehouses wordt niet ondersteund. |