Aangepaste Spark-pools maken in Microsoft Fabric
In dit document wordt uitgelegd hoe u aangepaste Apache Spark-pools maakt in Microsoft Fabric voor uw analyseworkloads. Met Apache Spark-pools kunnen gebruikers op maat gemaakte rekenomgevingen maken op basis van hun specifieke vereisten, waardoor optimale prestaties en resourcegebruik worden gegarandeerd.
U geeft het minimum- en maximum aantal knooppunten op voor automatisch schalen. Op basis van deze waarden verwerft het systeem dynamisch knooppunten en trekt deze buiten gebruik wanneer de rekenvereisten van de taak veranderen, wat resulteert in efficiënt schalen en verbeterde prestaties. De dynamische toewijzing van uitvoerders in Spark-pools vermindert ook de noodzaak van handmatige uitvoerderconfiguratie. In plaats daarvan past het systeem het aantal uitvoerders aan, afhankelijk van het gegevensvolume en de rekenbehoeften op taakniveau. Met dit proces kunt u zich richten op uw workloads zonder dat u zich zorgen hoeft te maken over prestatieoptimalisatie en resourcebeheer.
Notitie
Als u een aangepaste Spark-pool wilt maken, hebt u beheerderstoegang tot de werkruimte nodig. De capaciteitsbeheerder moet de optie aangepaste werkruimtegroepen inschakelen in de sectie Spark Compute van Instellingen voor capaciteitsbeheerder. Zie Spark Compute Settings for Fabric Capacitiesvoor meer informatie.
Aangepaste Spark-pools maken
De Spark-pool maken of beheren die is gekoppeld aan uw werkruimte:
Ga naar uw werkruimte en selecteer werkruimte-instellingen.
Selecteer de optie Data Engineering/Science om het menu uit te vouwen en selecteer vervolgens Spark-instellingen.
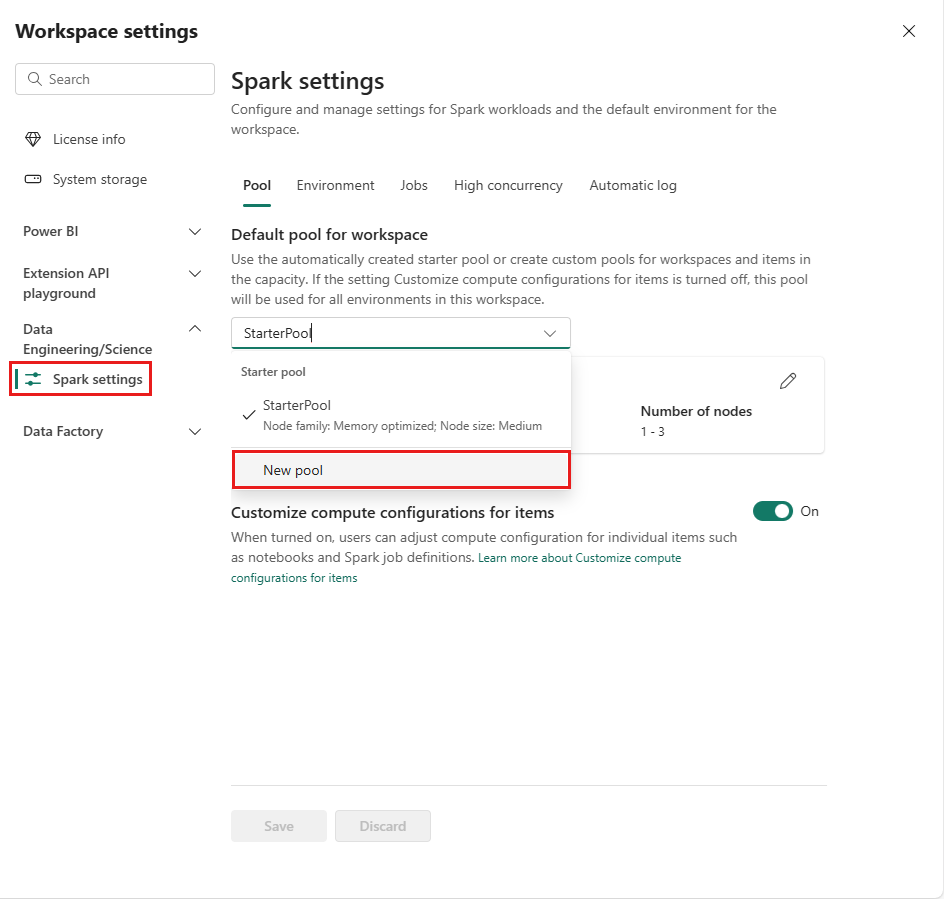
Selecteer de optie Nieuwe pool. Geef uw Spark-pool een naam op het scherm Pool maken. Kies ook de Node-familieen selecteer een Knooppuntgrootte uit de beschikbare grootten (Klein, Gemiddeld, Grote, X-Groteen XX-Groot-) op basis van de rekenvereisten voor uw workloads.
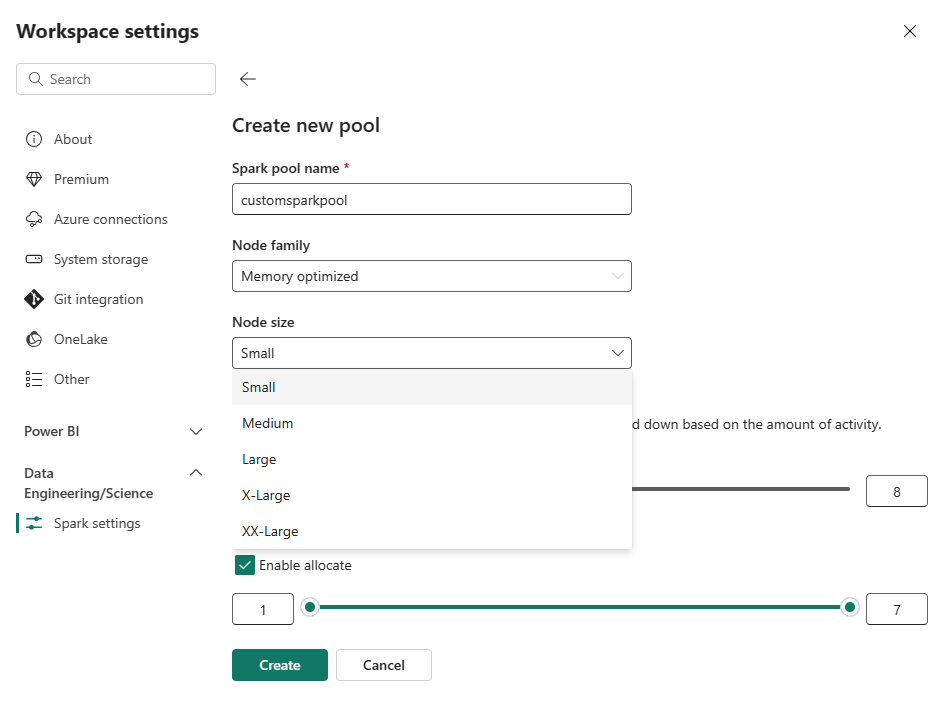
U kunt de minimale knooppuntconfiguratie voor uw aangepaste pools instellen op 1. Omdat Fabric Spark een herstelbare beschikbaarheid biedt voor clusters met één knooppunt, hoeft u zich geen zorgen te maken over taakfouten, verlies van sessie tijdens storingen of over het betalen van rekenkracht voor kleinere Spark-taken.
U kunt automatische schaalaanpassing voor uw aangepaste Spark-pools in- of uitschakelen. Wanneer automatisch schalen is ingeschakeld, verkrijgt de pool dynamisch nieuwe knooppunten tot de maximale knooppuntlimiet die door de gebruiker is opgegeven en wordt deze vervolgens buiten gebruik gesteld nadat de taak is uitgevoerd. Deze functie zorgt voor betere prestaties door resources aan te passen op basis van de taakvereisten. U kunt de grootte van de knooppunten instellen, die binnen de capaciteitseenheden passen die zijn aangeschaft als onderdeel van de Fabric-capaciteits-SKU.
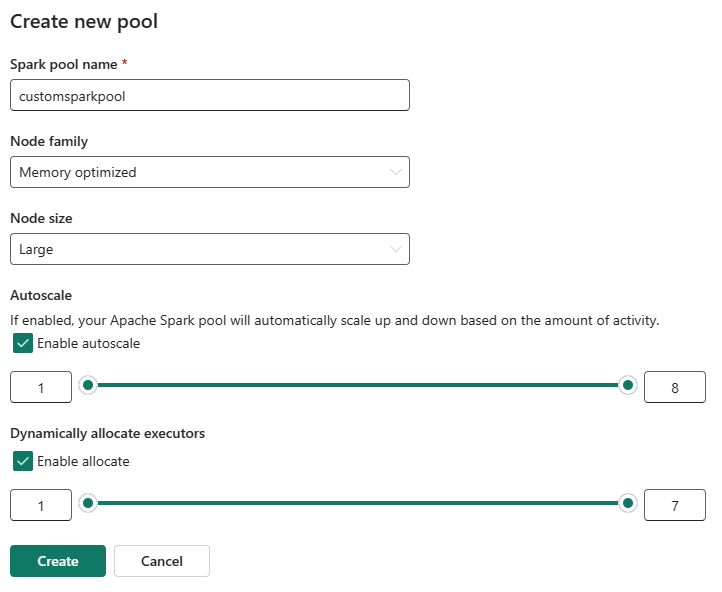
U kunt er ook voor kiezen om dynamische uitvoerdertoewijzing in te schakelen voor uw Spark-pool, waarmee automatisch het optimale aantal uitvoerders binnen de door de gebruiker opgegeven maximumgrens wordt bepaald. Met deze functie wordt het aantal uitvoerders aangepast op basis van het gegevensvolume, wat resulteert in verbeterde prestaties en resourcegebruik.

Deze aangepaste pools hebben een standaard autopauseperiode van 2 minuten. Zodra de duur van de automatischepause is bereikt, verloopt de sessie en worden de clusters niet toegewezen. Er worden kosten in rekening gebracht op basis van het aantal knooppunten en de duur waarvoor de aangepaste Spark-pools worden gebruikt.
Verwante inhoud
- Meer informatie vindt u in de openbare documentatie van Apache Spark .
- Aan de slag met beheerinstellingen voor Spark-werkruimten in Microsoft Fabric.