Azure Stream Analytics-oplossingspatronen
Net als bij veel andere services in Azure wordt Stream Analytics het beste gebruikt met andere services om een grotere end-to-end-oplossing te maken. In dit artikel worden eenvoudige Azure Stream Analytics-oplossingen en verschillende architectuurpatronen besproken. U kunt bouwen op deze patronen om complexere oplossingen te ontwikkelen. De patronen die in dit artikel worden beschreven, kunnen worden gebruikt in een groot aantal scenario's. Voorbeelden van scenariospecifieke patronen zijn beschikbaar in Azure-oplossingsarchitecturen.
Een Stream Analytics-taak maken om realtime dashboarding mogelijk te maken
Met Azure Stream Analytics kunt u snel realtime dashboards en waarschuwingen maken. Een eenvoudige oplossing neemt gebeurtenissen van Event Hubs of IoT Hub op en voert het Power BI-dashboard met een streaminggegevensset in. Zie de gedetailleerde zelfstudie Frauduleuze gespreksgegevens analyseren met Stream Analytics en resultaten visualiseren in het Power BI-dashboard voor meer informatie.
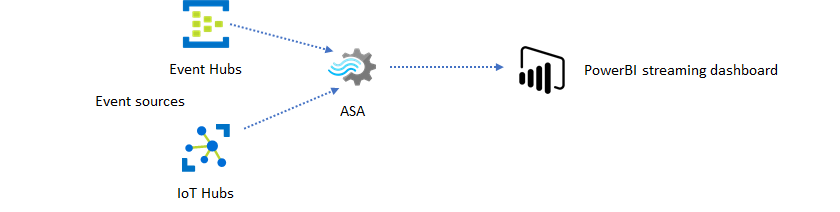
U kunt deze oplossing in slechts een paar minuten bouwen met behulp van Azure Portal. U hoeft niet uitgebreid te codeeren. In plaats daarvan kunt u de SQL-taal gebruiken om de bedrijfslogica uit te drukken.
Dit oplossingspatroon biedt de laagste latentie van de gebeurtenisbron naar het Power BI-dashboard in een browser. Azure Stream Analytics is de enige Azure-service met deze ingebouwde mogelijkheid.
SQL gebruiken voor dashboard
Het Power BI-dashboard biedt lage latentie, maar u kunt het niet gebruiken om volwaardige Power BI-rapporten te produceren. Een veelvoorkomend rapportagepatroon is om uw gegevens eerst uit te voeren naar SQL Database. Gebruik vervolgens de SQL-connector van Power BI om een query uit te voeren op SQL voor de meest recente gegevens.
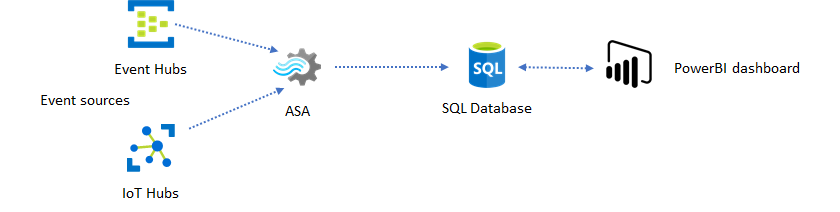
Wanneer u SQL Database gebruikt, biedt het u meer flexibiliteit, maar ten koste van een iets hogere latentie. Deze oplossing is optimaal voor taken met latentievereisten die groter zijn dan één seconde. Wanneer u deze methode gebruikt, kunt u power BI-mogelijkheden maximaliseren om de gegevens voor rapporten verder te segmenteren en te dobbelen, en nog veel meer visualisatieopties. U krijgt ook de flexibiliteit van het gebruik van andere dashboardoplossingen, zoals Tableau.
SQL is geen gegevensarchief met hoge doorvoer. De maximale doorvoer naar SQL Database vanuit Azure Stream Analytics is momenteel ongeveer 24 MB/s. Als de gebeurtenisbronnen in uw oplossing gegevens met een hogere snelheid produceren, moet u verwerkingslogica in Stream Analytics gebruiken om de uitvoersnelheid naar SQL te verminderen. U kunt technieken gebruiken, zoals filteren, vensteraggregaties, patroonkoppeling met tijdelijke joins en analysefuncties. U kunt de uitvoersnelheid optimaliseren voor SQL met behulp van technieken die worden beschreven in Azure Stream Analytics-uitvoer naar Azure SQL Database.
Realtime inzichten opnemen in uw toepassing met gebeurtenisberichten
Het tweede populairste gebruik van Stream Analytics is het genereren van realtime waarschuwingen. In dit oplossingspatroon kan bedrijfslogica in Stream Analytics worden gebruikt om tijdelijke en ruimtelijke patronen of afwijkingen te detecteren en vervolgens waarschuwingssignalen te produceren. In tegenstelling tot de dashboardoplossing waarbij Stream Analytics Power BI als voorkeurseindpunt gebruikt, kunt u echter andere tussenliggende gegevenssinks gebruiken. Deze sinks omvatten Event Hubs, Service Bus en Azure Functions. U moet als opbouwfunctie voor toepassingen bepalen welke gegevenssink het beste werkt voor uw scenario.
U moet de logica van de downstream gebeurtenisconsumer implementeren om waarschuwingen te genereren in uw bestaande bedrijfswerkstroom. Omdat u aangepaste logica in Azure Functions kunt implementeren, is Azure Functions de snelste manier om deze integratie uit te voeren. Zie Azure Functions uitvoeren vanuit Azure Stream Analytics-taken voor een zelfstudie over het gebruik van Azure Function als uitvoer voor een Stream Analytics-taak. Azure Functions ondersteunt ook verschillende typen meldingen, waaronder tekst en e-mail. U kunt Logic Apps ook gebruiken voor dergelijke integratie, met Event Hubs tussen Stream Analytics en Logic Apps.
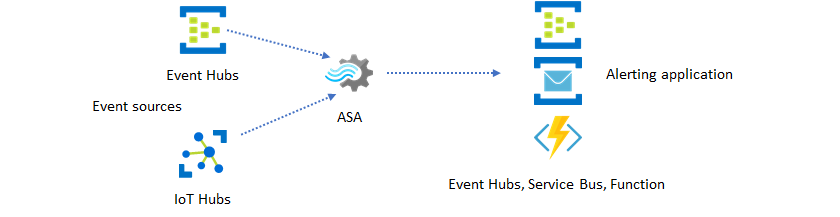
De Azure Event Hubs-service biedt daarentegen het meest flexibele integratiepunt. Veel andere services, zoals Azure Data Explorer en Time Series Insights, kunnen gebeurtenissen van Event Hubs gebruiken. Services kunnen rechtstreeks worden verbonden met de Event Hubs-sink vanuit Azure Stream Analytics om de oplossing te voltooien. Event Hubs is ook de hoogste doorvoerberichtenbroker die beschikbaar is in Azure voor dergelijke integratiescenario's.
Dynamische toepassingen en websites
U kunt aangepaste realtime visualisaties maken, zoals dashboard- of kaartvisualisatie, met behulp van Azure Stream Analytics en Azure SignalR Service. Wanneer u SignalR gebruikt, kunnen webclients in realtime worden bijgewerkt en dynamische inhoud weergeven.
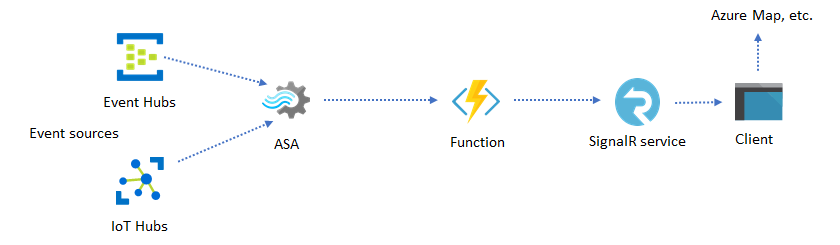
Realtime inzichten opnemen in uw toepassing via gegevensarchieven
De meeste webservices en webtoepassingen gebruiken tegenwoordig een aanvraag-/antwoordpatroon voor de presentatielaag. Het aanvraag-/antwoordpatroon is eenvoudig te bouwen en kan eenvoudig worden geschaald met een lage reactietijd met behulp van een staatloze front-end en schaalbare winkels zoals Azure Cosmos DB.
Hoog gegevensvolume creëert vaak prestatieknelpunten in een CRUD-systeem. Het patroon van de oplossing voor gebeurtenisbronnen wordt gebruikt om de prestatieknelpunten aan te pakken. Tijdelijke patronen en inzichten zijn ook moeilijk en inefficiënt om te extraheren uit een traditioneel gegevensarchief. Moderne gegevensgestuurde toepassingen met grote volumes gebruiken vaak een architectuur op basis van een gegevensstroom. Azure Stream Analytics als de rekenengine voor gegevens in beweging is een linchpin in die architectuur.
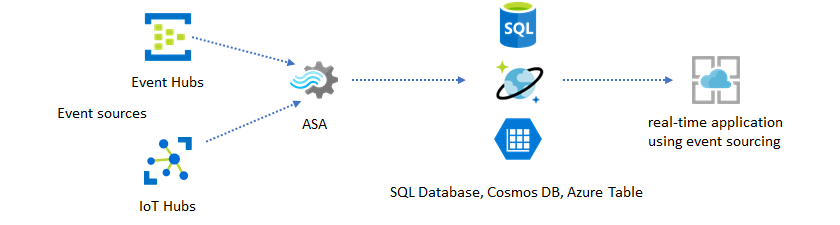
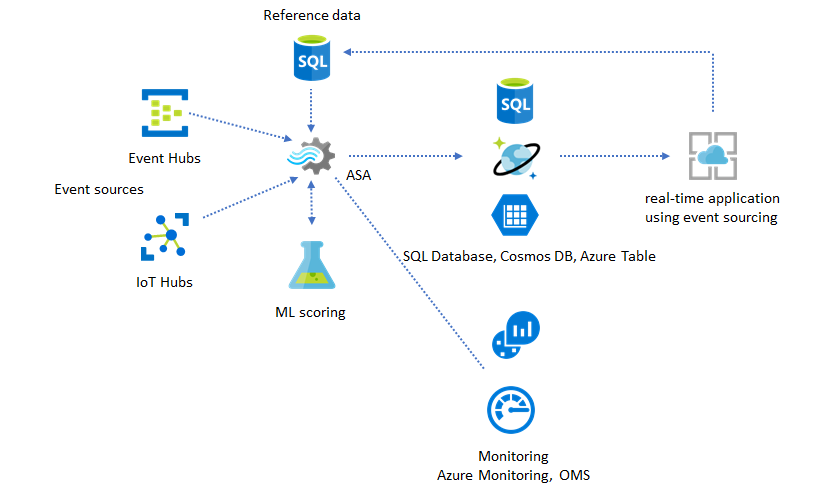
In dit oplossingspatroon worden gebeurtenissen verwerkt en samengevoegd in gegevensarchieven door Azure Stream Analytics. De toepassingslaag communiceert met gegevensarchieven met behulp van het traditionele aanvraag-/antwoordpatroon. Vanwege de mogelijkheid van Stream Analytics om een groot aantal gebeurtenissen in realtime te verwerken, is de toepassing zeer schaalbaar zonder dat de laag van het gegevensarchief bulksgewijs hoeft te worden opgeslagen. De gegevensarchieflaag is in feite een gerealiseerde weergave in het systeem. Azure Stream Analytics-uitvoer naar Azure Cosmos DB beschrijft hoe Azure Cosmos DB wordt gebruikt als Stream Analytics-uitvoer.
In echte toepassingen waarbij verwerkingslogica complex is en er behoefte is aan het onafhankelijk bijwerken van bepaalde onderdelen van de logica, kunnen meerdere Stream Analytics-taken samen met Event Hubs worden samengesteld als intermediaire gebeurtenisbroker.
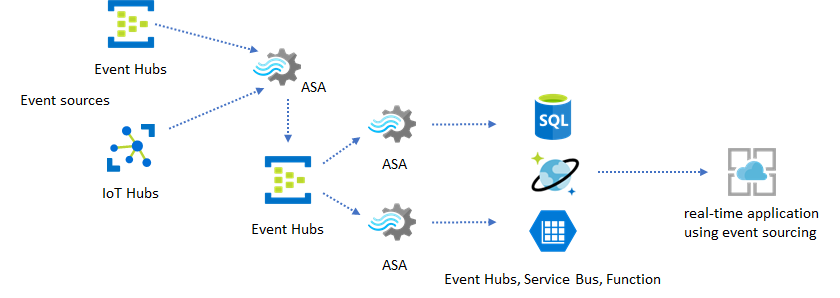
Dit patroon verbetert de tolerantie en beheerbaarheid van het systeem. Hoewel Stream Analytics echter precies eenmaal verwerking garandeert, is er een kleine kans dat dubbele gebeurtenissen terechtkomen in de intermediaire Event Hubs. Het is belangrijk dat de downstream Stream Analytics-taak gebeurtenissen ontdubbelt met behulp van logische sleutels in een lookback-venster. Zie de naslaginformatie over garanties voor gebeurtenisbezorging voor meer informatie over de levering van gebeurtenissen.
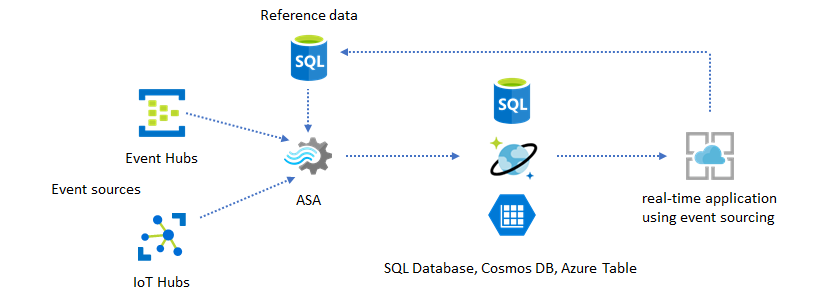
Referentiegegevens gebruiken voor toepassingsaanpassing
De azure Stream Analytics-referentiegegevensfunctie is speciaal ontworpen voor aanpassingen van eindgebruikers, zoals drempelwaarde voor waarschuwingen, verwerkingsregels en geofences. De toepassingslaag kan parameterwijzigingen accepteren en opslaan in SQL Database. De Stream Analytics-taak voert periodiek query's uit op wijzigingen uit de database en maakt de aanpassingsparameters toegankelijk via een referentiegegevensdeelname. Zie SQL-referentiegegevens en referentiegegevens samenvoegen voor meer informatie over het gebruik van referentiegegevens voor toepassingsaanpassing.
Dit patroon kan ook worden gebruikt om een regelengine te implementeren waarbij de drempelwaarden van de regels worden gedefinieerd op basis van referentiegegevens. Zie Configureerbare regels op basis van drempelwaarden in Azure Stream Analytics voor meer informatie over regels.
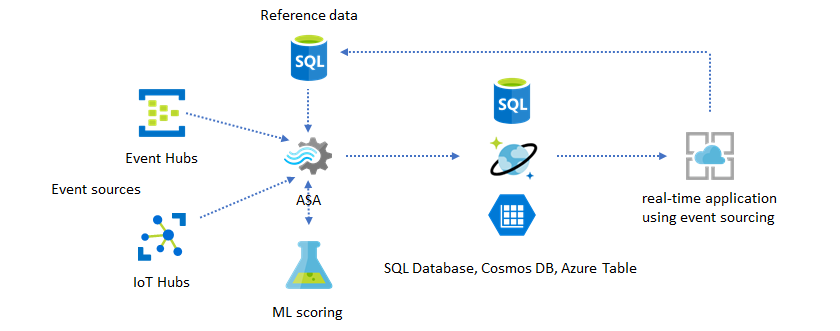
Machine Learning toevoegen aan uw realtime inzichten
Het ingebouwde Anomaly Detection-model van Azure Stream Analytics is een handige manier om Machine Learning te introduceren in uw realtime-toepassing. Zie Azure Stream Analytics is geïntegreerd met de scoreservice van Azure Machine Learning voor een breder scala aan Machine Learning-behoeften.
Voor geavanceerde gebruikers die onlinetraining en scoren willen opnemen in dezelfde Stream Analytics-pijplijn, raadpleegt u dit voorbeeld van hoe dat met lineaire regressie gaat.
Realtime datawarehousing
Een ander veelvoorkomend patroon is realtime datawarehousing, ook wel streaming datawarehouse genoemd. Naast gebeurtenissen die binnenkomen bij Event Hubs en IoT Hub vanuit uw toepassing, kan Azure Stream Analytics die wordt uitgevoerd op IoT Edge worden gebruikt om te voldoen aan de behoeften voor het opschonen van gegevens, het verminderen van gegevens en het opslaan en doorsturen van gegevens. Stream Analytics die wordt uitgevoerd op IoT Edge kan probleemloos omgaan met bandbreedtebeperking en connectiviteitsproblemen in het systeem. Stream Analytics kan doorvoersnelheden van maximaal 200 MB per seconde ondersteunen tijdens het schrijven naar Azure Synapse Analytics.
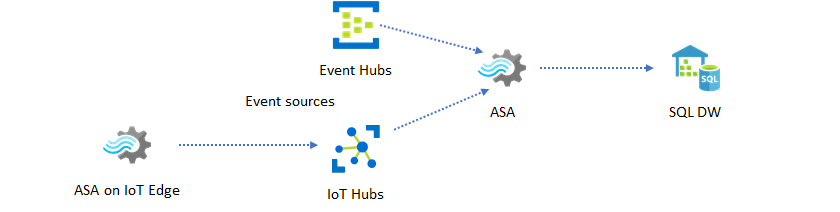
Realtime gegevens archiveren voor analyse
De meeste data science- en analyseactiviteiten worden nog steeds offline uitgevoerd. U kunt gegevens in Azure Stream Analytics archiveren via uitvoer- en Parquet-uitvoerindelingen van Azure Data Lake Store Gen2. Met deze mogelijkheid wordt de wrijving verwijderd voor het rechtstreeks invoeren van gegevens in Azure Data Lake Analytics, Azure Databricks en Azure HDInsight. Azure Stream Analytics wordt in deze oplossing gebruikt als een bijna realtime ETL-engine (Extract-Transform-Load). U kunt gearchiveerde gegevens in Data Lake verkennen met behulp van verschillende rekenengines.
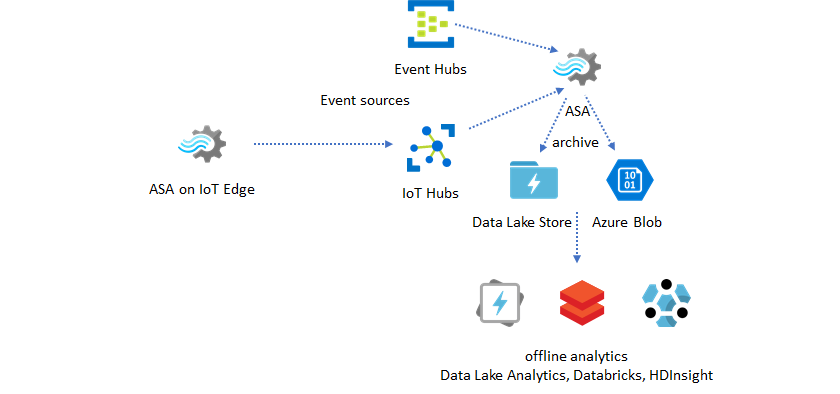
Referentiegegevens gebruiken voor verrijking
Gegevensverrijking is vaak een vereiste voor ETL-engines. Azure Stream Analytics biedt ondersteuning voor gegevensverrijking met referentiegegevens uit zowel SQL Database als Azure Blob Storage. Gegevensverrijking kan worden uitgevoerd voor gegevenslanding in zowel Azure Data Lake als Azure Synapse Analytics.
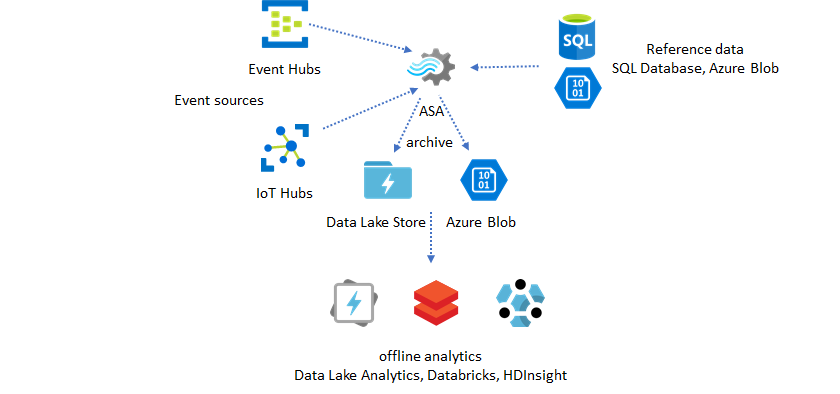
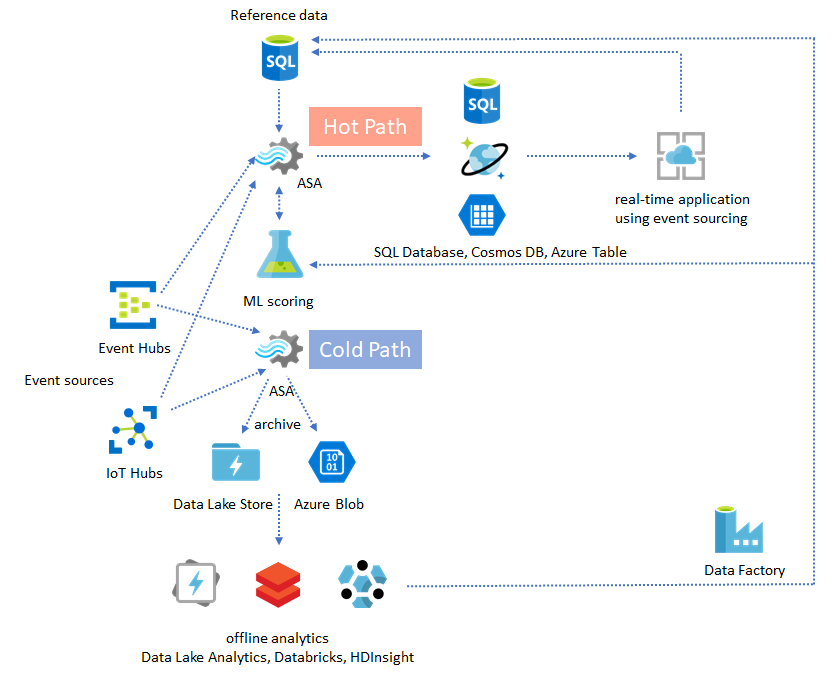
Inzichten van gearchiveerde gegevens operationeel maken
Als u het offlineanalysepatroon combineert met het bijna realtime toepassingspatroon, kunt u een feedbacklus maken. Met de feedbacklus kan de toepassing automatisch aanpassen voor het wijzigen van patronen in de gegevens. Deze feedbacklus kan net zo eenvoudig zijn als het wijzigen van de drempelwaarde voor waarschuwingen of zo complex als het opnieuw trainen van Machine Learning-modellen. Dezelfde oplossingsarchitectuur kan worden toegepast op zowel ASA-taken die worden uitgevoerd in de cloud als op IoT Edge.
ASA-taken bewaken
Een Azure Stream Analytics-taak kan 24/7 worden uitgevoerd om binnenkomende gebeurtenissen continu in realtime te verwerken. De uptimegarantie is van cruciaal belang voor de status van de algehele toepassing. Stream Analytics is de enige streaming analytics-service in de branche die een beschikbaarheidsgarantie van 99,9% biedt, maar u ondervindt nog steeds enige vertraging. In de loop der jaren heeft Stream Analytics metrische gegevens, logboeken en taakstatussen geïntroduceerd om de status van de taken weer te geven. Ze worden allemaal weergegeven via de Azure Monitor-service en kunnen verder worden geëxporteerd naar OMS. Zie Stream Analytics-taak bewaken met Azure Portal voor meer informatie.
Er zijn twee belangrijke dingen om te controleren:
-
In de eerste plaats moet u ervoor zorgen dat de taak wordt uitgevoerd. Zonder de taak met de actieve status worden er geen nieuwe metrische gegevens of logboeken gegenereerd. Taken kunnen om verschillende redenen veranderen in een mislukte status, waaronder het hebben van een hoog SU-gebruiksniveau (dat wil gezegd, onvoldoende resources).
Metrische gegevens voor watermerkvertraging
Deze metrische waarde geeft aan hoe ver achter de verwerkingspijplijn de kloktijd van de wand (seconden) ligt. Een deel van de vertraging wordt toegeschreven aan de inherente verwerkingslogica. Als gevolg hiervan is het bewaken van de toenemende trend veel belangrijker dan het bewaken van de absolute waarde. De vertraging van de constante status moet worden opgelost door uw toepassingsontwerp, niet door bewaking of waarschuwingen.
Bij fouten zijn activiteitenlogboeken en diagnostische logboeken de beste plekken om te beginnen met het zoeken naar fouten.
Tolerante en bedrijfskritieke toepassingen bouwen
Ongeacht de SLA-garantie van Azure Stream Analytics en hoe voorzichtig u uw end-to-end-toepassing uitvoert, treden er storingen op. Als uw toepassing essentieel is, moet u voorbereid zijn op storingen om probleemloos te kunnen herstellen.
Voor waarschuwingstoepassingen is het belangrijkst om de volgende waarschuwing te detecteren. U kunt ervoor kiezen om de taak opnieuw op te starten vanaf de huidige tijd bij het herstellen, waarbij eerdere waarschuwingen worden genegeerd. De semantiek van de begintijd van de taak is de eerste uitvoertijd, niet de eerste invoertijd. De invoer wordt teruggeschoven voor een geschikte hoeveelheid tijd om te garanderen dat de eerste uitvoer op het opgegeven tijdstip is voltooid en correct is. Als gevolg hiervan krijgt u geen gedeeltelijke aggregaties en activeert u waarschuwingen onverwacht.
U kunt er ook voor kiezen om de uitvoer van enige tijd in het verleden te starten. Zowel het bewaarbeleid van Event Hubs als het bewaarbeleid van IoT Hub bevat een redelijke hoeveelheid gegevens om verwerking vanuit het verleden mogelijk te maken. De afweging is hoe snel u de huidige tijd kunt inhalen en tijdig nieuwe waarschuwingen kunt genereren. Gegevens verliezen de waarde ervan snel in de loop van de tijd, dus het is belangrijk om snel in te halen naar de huidige tijd. Er zijn twee manieren om snel in te halen:
- Richt meer resources (SU) in bij het inhalen.
- Opnieuw opstarten vanaf de huidige tijd.
Opnieuw opstarten vanaf de huidige tijd is eenvoudig te doen, met het compromis van het verlaten van een kloof tijdens de verwerking. Het opnieuw opstarten op deze manier is mogelijk in orde voor waarschuwingsscenario's, maar kan problematisch zijn voor dashboardscenario's en is een niet-starter voor archiverings- en datawarehousingscenario's.
Het inrichten van meer resources kan het proces versnellen, maar het effect van een verwerkingssnelheidspiek is complex.
Test of uw taak schaalbaar is voor een groter aantal RU's. Niet alle query's zijn schaalbaar. U moet ervoor zorgen dat uw query is geparallelliseerd.
Zorg ervoor dat er voldoende partities in de upstream Event Hubs of IoT Hub zijn die u meer doorvoereenheden (TU's) kunt toevoegen om de invoerdoorvoer te schalen. Houd er rekening mee dat elke Event Hubs-TU maximaal wordt uitgevoerd met een uitvoersnelheid van 2 MB/s.
Zorg ervoor dat u voldoende resources hebt ingericht in de uitvoersinks (dat wil gezegd: SQL Database, Azure Cosmos DB), zodat ze de piek in uitvoer niet beperken, waardoor het systeem soms wordt vergrendeld.
Het belangrijkste is om te anticiperen op de wijziging van de verwerkingssnelheid, deze scenario's te testen voordat u in productie gaat en klaar te zijn om de verwerking correct te schalen tijdens de hersteltijd van fouten.
In het extreme scenario dat binnenkomende gebeurtenissen allemaal worden vertraagd, is het mogelijk dat alle vertraagde gebeurtenissen worden verwijderd als u een laat binnenkomend venster op uw taak hebt toegepast. Het neervallen van de gebeurtenissen lijkt aan het begin een mysterieus gedrag te zijn; Aangezien Stream Analytics echter een realtime verwerkingsengine is, verwacht het dat binnenkomende gebeurtenissen dicht bij de kloktijd van de muur liggen. Het moet gebeurtenissen verwijderen die deze beperkingen schenden.
Lambda Architecturen of Backfill-proces
Gelukkig kan het vorige patroon voor gegevensarchivering worden gebruikt om deze late gebeurtenissen correct te verwerken. Het idee is dat de archiveringstaak binnenkomende gebeurtenissen verwerkt in de aankomsttijd en gebeurtenissen in de juiste tijdbucket in Azure Blob of Azure Data Lake Store met hun gebeurtenistijd. Het maakt niet uit hoe laat een gebeurtenis aankomt, het zal nooit worden verwijderd. Het landt altijd in de juiste tijdsbucket. Tijdens het herstel is het mogelijk om de gearchiveerde gebeurtenissen opnieuw te verwerken en de resultaten in te vullen in het archief van de keuze. Dit is vergelijkbaar met hoe lambda-patronen worden geïmplementeerd.
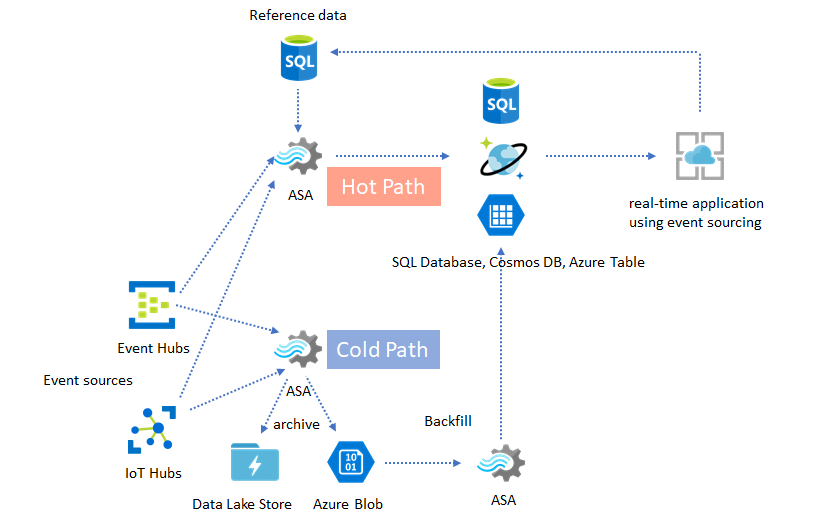
Het backfillproces moet worden uitgevoerd met een offline batchverwerkingssysteem, dat waarschijnlijk een ander programmeermodel heeft dan Azure Stream Analytics. Dit betekent dat u de volledige verwerkingslogica opnieuw moet inschakelen.
Voor het doorvoeren van back-ups is het nog steeds belangrijk om ten minste tijdelijk meer resources in te richten voor de uitvoersinks om een hogere doorvoer te verwerken dan de behoefte aan onveranderlijk verwerken van de verwerking.
| Scenario's | Alleen vanaf nu opnieuw opstarten | Opnieuw opstarten vanaf de laatste gestopte tijd | Opnieuw opstarten vanaf nu + backfill met gearchiveerde gebeurtenissen |
|---|---|---|---|
| Dashboards | Maakt een gat | OK voor korte storing | Gebruiken voor lange storingen |
| Waarschuwingen | Aanvaardbaar | OK voor korte storing | Niet nodig |
| Gebeurtenisbronnen-app | Aanvaardbaar | OK voor korte storing | Gebruiken voor lange storingen |
| Datawarehousing | Gegevensverlies | Aanvaardbaar | Niet nodig |
| Offlineanalyse | Gegevensverlies | Aanvaardbaar | Niet nodig |
Alles samenvoegen
Het is niet moeilijk voor te stellen dat alle eerder genoemde oplossingspatronen samen kunnen worden gecombineerd in een complex end-to-end systeem. Het gecombineerde systeem kan dashboards, waarschuwingen, toepassing voor gebeurtenisbronnen, datawarehousing en offlineanalysemogelijkheden omvatten.
De sleutel is het ontwerpen van uw systeem in samenstelbare patronen, zodat elk subsysteem onafhankelijk kan worden gebouwd, getest, bijgewerkt en hersteld.
Volgende stappen
U hebt nu verschillende oplossingspatronen gezien met behulp van Azure Stream Analytics. Hierna kunt u zich verder in de materie verdiepen en uw eerste Stream Analytics-taak maken:
- Een Stream Analytics-taak maken via Azure Portal.
- Create a Stream Analytics job by using Azure PowerShell (Een Stream Analytics-taak maken met behulp van Azure PowerShell).
- Create a Stream Analytics job by using Visual Studio (Een Stream Analytics-taak maken met behulp van Visual Studio).