Anomaliedetectie in Azure Stream Analytics
Azure Stream Analytics is beschikbaar in zowel de cloud als Azure IoT Edge en biedt ingebouwde mogelijkheden voor anomaliedetectie op basis van machine learning die kunnen worden gebruikt om de twee meest voorkomende afwijkingen te bewaken: tijdelijk en permanent. Met de functies AnomalyDetection_SpikeAndDip en AnomalyDetection_ChangePoint kunt u anomaliedetectie rechtstreeks in uw Stream Analytics-taak uitvoeren.
Bij de machine learning-modellen wordt uitgegaan van een uniform gesampleerde tijdreeks. Als de tijdreeks niet uniform is, kunt u een aggregatiestap invoegen met een tumblingvenster voordat u anomaliedetectie aanroept.
De machine learning-bewerkingen bieden momenteel geen ondersteuning voor seizoensgebondenheidstrends of correlaties met meerdere varianten.
Anomaliedetectie met behulp van machine learning in Azure Stream Analytics
In de volgende video ziet u hoe u een anomalie in realtime detecteert met behulp van machine learning-functies in Azure Stream Analytics.
Modelgedrag
Over het algemeen verbetert de nauwkeurigheid van het model met meer gegevens in het schuifvenster. De gegevens in het opgegeven schuifvenster worden behandeld als onderdeel van het normale bereik van waarden voor dat tijdsbestek. Het model beschouwt alleen gebeurtenisgeschiedenis via het schuifvenster om te controleren of de huidige gebeurtenis afwijkend is. Terwijl het schuifvenster wordt verplaatst, worden oude waarden verwijderd uit de training van het model.
De functies werken door een bepaalde normaal vast te stellen op basis van wat ze tot nu toe hebben gezien. Uitbijters worden geïdentificeerd door te vergelijken met het vastgestelde normale niveau, binnen het betrouwbaarheidsniveau. De venstergrootte moet zijn gebaseerd op de minimale gebeurtenissen die nodig zijn om het model te trainen voor normaal gedrag, zodat wanneer er een anomalie optreedt, het model zou kunnen herkennen.
De reactietijd van het model neemt toe met de geschiedenisgrootte, omdat deze moet worden vergeleken met een hoger aantal eerdere gebeurtenissen. U wordt aangeraden alleen het benodigde aantal gebeurtenissen op te nemen voor betere prestaties.
Hiaten in de tijdreeks kunnen het gevolg zijn van het model dat op bepaalde tijdstippen geen gebeurtenissen ontvangt. Deze situatie wordt verwerkt door Stream Analytics met behulp van imputatielogica. De geschiedenisgrootte, evenals een tijdsduur, voor hetzelfde schuifvenster wordt gebruikt om de gemiddelde snelheid te berekenen waarmee gebeurtenissen naar verwachting aankomen.
Een anomaliegenerator die hier beschikbaar is, kan worden gebruikt om een IoT-hub met gegevens met verschillende anomaliepatronen te voeden. Een Azure Stream Analytics-taak kan worden ingesteld met deze anomaliedetectiefuncties om te lezen uit deze IoT Hub en afwijkingen te detecteren.
Piek en dip
Tijdelijke afwijkingen in een tijdreeks-gebeurtenisstroom worden pieken en dips genoemd. Pieken en dips kunnen worden bewaakt met behulp van de machine learning-operator AnomalyDetection_SpikeAndDip.
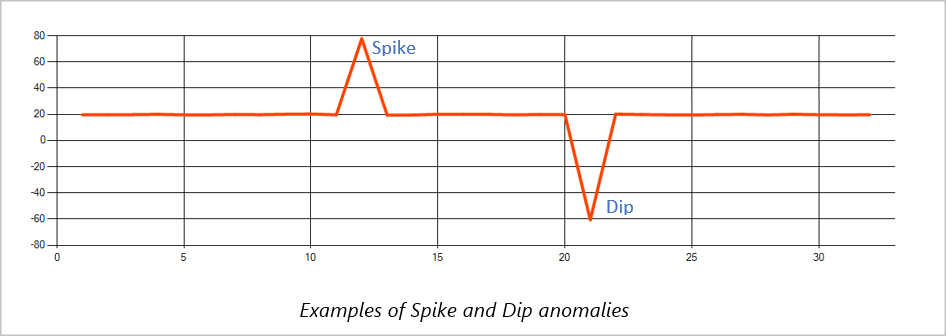
Als in hetzelfde schuifvenster een tweede piek kleiner is dan de eerste, is de berekende score voor de kleinere piek waarschijnlijk niet significant genoeg vergeleken met de score voor de eerste piek binnen het opgegeven betrouwbaarheidsniveau. U kunt proberen het betrouwbaarheidsniveau van het model te verlagen om dergelijke afwijkingen te detecteren. Als u echter te veel waarschuwingen krijgt, kunt u een hoger betrouwbaarheidsinterval gebruiken.
In de volgende voorbeeldquery wordt uitgegaan van een uniforme invoersnelheid van één gebeurtenis per seconde in een schuifvenster van 2 minuten met een geschiedenis van 120 gebeurtenissen. Met de laatste SELECT-instructie wordt de score en anomaliestatus geëxtraheerd en uitgevoerd met een betrouwbaarheidsniveau van 95%.
WITH AnomalyDetectionStep AS
(
SELECT
EVENTENQUEUEDUTCTIME AS time,
CAST(temperature AS float) AS temp,
AnomalyDetection_SpikeAndDip(CAST(temperature AS float), 95, 120, 'spikesanddips')
OVER(LIMIT DURATION(second, 120)) AS SpikeAndDipScores
FROM input
)
SELECT
time,
temp,
CAST(GetRecordPropertyValue(SpikeAndDipScores, 'Score') AS float) AS
SpikeAndDipScore,
CAST(GetRecordPropertyValue(SpikeAndDipScores, 'IsAnomaly') AS bigint) AS
IsSpikeAndDipAnomaly
INTO output
FROM AnomalyDetectionStep
Wijzigingspunt
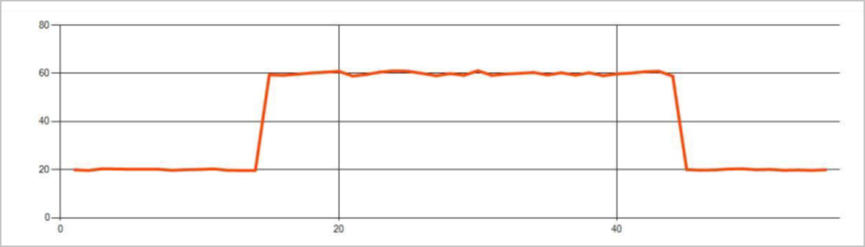
Permanente afwijkingen in een tijdreeks gebeurtenisstroom zijn wijzigingen in de verdeling van waarden in de gebeurtenisstroom, zoals niveauwijzigingen en trends. In Stream Analytics worden dergelijke afwijkingen gedetecteerd met behulp van de machine learning-operator AnomalyDetection_ChangePoint .
Permanente wijzigingen duren veel langer dan pieken en dips en kunnen duiden op catastrofale gebeurtenissen. Permanente wijzigingen zijn meestal niet zichtbaar voor het naakte oog, maar kunnen worden gedetecteerd met de operator AnomalyDetection_ChangePoint .
De volgende afbeelding is een voorbeeld van een niveauwijziging:
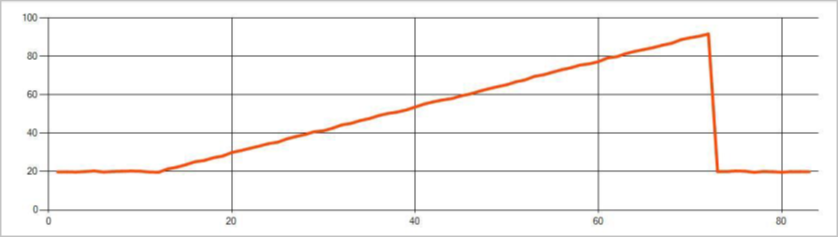
De volgende afbeelding is een voorbeeld van een trendwijziging:
In de volgende voorbeeldquery wordt uitgegaan van een uniforme invoersnelheid van één gebeurtenis per seconde in een schuifvenster van 20 minuten met een geschiedenisgrootte van 1200 gebeurtenissen. Met de laatste SELECT-instructie wordt de score en anomaliestatus geëxtraheerd en uitgevoerd met een betrouwbaarheidsniveau van 80%.
WITH AnomalyDetectionStep AS
(
SELECT
EVENTENQUEUEDUTCTIME AS time,
CAST(temperature AS float) AS temp,
AnomalyDetection_ChangePoint(CAST(temperature AS float), 80, 1200)
OVER(LIMIT DURATION(minute, 20)) AS ChangePointScores
FROM input
)
SELECT
time,
temp,
CAST(GetRecordPropertyValue(ChangePointScores, 'Score') AS float) AS
ChangePointScore,
CAST(GetRecordPropertyValue(ChangePointScores, 'IsAnomaly') AS bigint) AS
IsChangePointAnomaly
INTO output
FROM AnomalyDetectionStep
Prestatiekenmerken
De prestaties van deze modellen zijn afhankelijk van de geschiedenisgrootte, de duur van het venster, de belasting van gebeurtenissen en of partitionering op functieniveau wordt gebruikt. In deze sectie worden deze configuraties besproken en vindt u voorbeelden voor het ondersteunen van opnamesnelheden van 1 K, 5 K en 10.000 gebeurtenissen per seconde.
- Geschiedenisgrootte : deze modellen worden lineair uitgevoerd met de geschiedenisgrootte. Hoe langer de geschiedenisgrootte, hoe langer de modellen duren om een nieuwe gebeurtenis te scoren. Dit komt doordat de modellen de nieuwe gebeurtenis vergelijken met elk van de eerdere gebeurtenissen in de geschiedenisbuffer.
- Duur van het venster: de duur van het venster moet weerspiegelen hoe lang het duurt om zoveel gebeurtenissen te ontvangen als is opgegeven door de geschiedenisgrootte. Zonder dat veel gebeurtenissen in het venster, zou Azure Stream Analytics ontbrekende waarden invoeren. Het CPU-verbruik is daarom een functie van de geschiedenisgrootte.
- Gebeurtenisbelasting : hoe groter de belasting van de gebeurtenis, hoe meer werk wordt uitgevoerd door de modellen, wat van invloed is op het CPU-verbruik. De taak kan worden uitgeschaald door deze gênant parallel te maken, ervan uitgaande dat het zinvol is voor bedrijfslogica om meer invoerpartities te gebruiken.
- Partitionering op functieniveau Partitionering - op functieniveau wordt uitgevoerd met behulp van
PARTITION BYde functieaanroep anomaliedetectie. Dit type partitionering voegt overhead toe, omdat de status voor meerdere modellen tegelijkertijd moet worden onderhouden. Partitionering op functieniveau wordt gebruikt in scenario's zoals partitionering op apparaatniveau.
Relatie
De geschiedenisgrootte, de duur van het venster en de totale belasting van gebeurtenissen zijn op de volgende manier gerelateerd:
windowDuration (in ms) = 1000 * historySize / (totale invoergebeurtenissen per seconde / Aantal invoerpartities)
Wanneer u de functie partitioneert op deviceId, voegt u PARTITION BY deviceId toe aan de aanroep van de functie anomaliedetectie.
Observaties
De volgende tabel bevat de doorvoerobservaties voor één knooppunt (zes SU) voor de niet-gepartitioneerde case:
| Geschiedenisgrootte (gebeurtenissen) | Duur van venster (ms) | Totaal aantal invoerevenementen per seconde |
|---|---|---|
| 60 | 55 | 2200 |
| 600 | 728 | 1,650 |
| 6.000 | 10,910 | 1,100 |
De volgende tabel bevat de doorvoerobservaties voor één knooppunt (zes SU) voor de gepartitioneerde case:
| Geschiedenisgrootte (gebeurtenissen) | Duur van venster (ms) | Totaal aantal invoerevenementen per seconde | Aantal apparaten |
|---|---|---|---|
| 60 | 1,091 | 1,100 | 10 |
| 600 | 10,910 | 1,100 | 10 |
| 6.000 | 218,182 | <550 | 10 |
| 60 | 21,819 | 550 | 100 |
| 600 | 218,182 | 550 | 100 |
| 6.000 | 2,181,819 | <550 | 100 |
Voorbeeldcode voor het uitvoeren van de bovenstaande niet-gepartitioneerde configuraties bevindt zich in de opslagplaats streaming op schaal van Azure-voorbeelden. Met de code wordt een Stream Analytics-taak gemaakt zonder partitionering op functieniveau, waarbij Event Hubs als invoer en uitvoer worden gebruikt. De invoerbelasting wordt gegenereerd met behulp van testclients. Elke invoer gebeurtenis is een json-document van 1 kB. Gebeurtenissen simuleren een IoT-apparaat dat JSON-gegevens verzendt (voor maximaal 1 K-apparaten). De geschiedenisgrootte, de duur van het venster en de totale belasting van gebeurtenissen zijn gevarieerd over twee invoerpartities.
Notitie
Voor een nauwkeurigere schatting kunt u de voorbeelden aanpassen aan uw scenario.
Knelpunten identificeren
Als u knelpunten in uw pijplijn wilt identificeren, gebruikt u het deelvenster Metrische gegevens in uw Azure Stream Analytics-taak. Bekijk invoer-/uitvoergebeurtenissen voor doorvoer en 'Watermerkvertraging' of 'Backloggebeurtenissen' om te zien of de taak de invoersnelheid bijhoudt. Voor metrische gegevens van Event Hubs zoekt u naar vertraagde aanvragen en past u de drempelwaarde-eenheden dienovereenkomstig aan. Raadpleeg voor metrische gegevens van Azure Cosmos DB het maximum aantal verbruikte RU/s per partitiesleutelbereik onder Doorvoer om ervoor te zorgen dat uw partitiesleutelbereiken uniform worden gebruikt. Voor Azure SQL DB bewaakt u logboek-IO en CPU.