Herstel na noodgevallen in Azure Service Fabric
Een essentieel onderdeel van het leveren van hoge beschikbaarheid is ervoor te zorgen dat services alle verschillende soorten fouten kunnen overleven. Dit is vooral belangrijk voor fouten die ongepland en buiten uw controle vallen.
In dit artikel worden enkele veelvoorkomende foutmodi beschreven die mogelijk rampen zijn als ze niet correct worden gemodelleerd en beheerd. Ook worden oplossingen en acties besproken die moeten worden ondernomen als er toch een noodgeval optreedt. Het doel is om het risico op downtime of gegevensverlies te beperken of te elimineren wanneer er fouten optreden, gepland of anderszins.
Noodgeval voorkomen
Het belangrijkste doel van Azure Service Fabric is om u te helpen bij het modelleren van zowel uw omgeving als uw services op een zodanige manier dat veelvoorkomende fouttypen geen rampen zijn.
Over het algemeen zijn er twee soorten scenario's voor noodgeval/storingen:
- Hardware- en softwarefouten
- Operationele fouten
Hardware- en softwarefouten
Hardware- en softwarefouten zijn onvoorspelbaar. De eenvoudigste manier om fouten te overleven, is het uitvoeren van meer kopieën van de service over hardware- of softwarefoutgrenzen.
Als uw service bijvoorbeeld op slechts één computer wordt uitgevoerd, is de fout van die ene machine een noodgeval voor die service. De eenvoudige manier om dit noodgeval te voorkomen, is ervoor te zorgen dat de service op meerdere computers wordt uitgevoerd. Testen is ook nodig om ervoor te zorgen dat de storing van één machine de actieve service niet onderbroken. Capaciteitsplanning zorgt ervoor dat een vervangingsexemplaren elders kunnen worden gemaakt en dat de capaciteitsvermindering de resterende services niet overbelast.
Hetzelfde patroon werkt, ongeacht wat u probeert te voorkomen. Als u zich bijvoorbeeld zorgen maakt over de fout van een SAN, voert u meerdere SAN's uit. Als u zich zorgen maakt over het verlies van een rek met servers, voert u meerdere racks uit. Als u zich zorgen maakt over het verlies van datacenters, moet uw service worden uitgevoerd in meerdere Azure-regio's, in meerdere Azure-Beschikbaarheidszones of in uw eigen datacenters.
Wanneer een service wordt verdeeld over meerdere fysieke exemplaren (machines, rekken, datacenters, regio's), bent u nog steeds onderhevig aan bepaalde typen gelijktijdige storingen. Maar één en zelfs meerdere fouten van een bepaald type (bijvoorbeeld een enkele virtuele machine of netwerkkoppeling mislukt) worden automatisch afgehandeld en dus niet langer een 'noodgeval'.
Service Fabric biedt mechanismen voor het uitbreiden van het cluster en handles voor het terugbrengen van mislukte knooppunten en services. Service Fabric biedt ook de mogelijkheid om veel exemplaren van uw services uit te voeren om te voorkomen dat ongeplande fouten worden omgezet in echte rampen.
Er kunnen redenen zijn waarom het uitvoeren van een implementatie groot genoeg is om fouten te omvatten, niet haalbaar is. Het kan bijvoorbeeld meer hardwareresources kosten dan u bereid bent te betalen ten opzichte van de kans op fouten. Wanneer u te maken hebt met gedistribueerde toepassingen, kunnen extra communicatiehops of statusreplicatiekosten voor geografische afstanden onacceptabele latentie veroorzaken. Waar deze lijn wordt getekend, verschilt voor elke toepassing.
Voor softwarefouten is de fout mogelijk in de service die u probeert te schalen. In dit geval voorkomen meer exemplaren het noodgeval niet, omdat de foutvoorwaarde is gecorreleerd in alle exemplaren.
Operationele fouten
Zelfs als uw service over de hele wereld wordt verspreid met veel redundantie, kan het nog steeds rampzalige gebeurtenissen ervaren. Iemand kan bijvoorbeeld de DNS-naam voor de service per ongeluk opnieuw configureren of deze verwijderen.
Stel dat u een stateful Service Fabric-service hebt en dat iemand die service per ongeluk heeft verwijderd. Tenzij er een andere beperking is, zijn die service en alle status die deze had nu verdwenen. Voor deze typen operationele rampen ('oeps') zijn verschillende oplossingen en stappen vereist voor herstel dan normale ongeplande fouten.
De beste manieren om deze typen operationele fouten te voorkomen, zijn:
- Beperk de operationele toegang tot de omgeving.
- Controleer gevaarlijke operaties strikt.
- Automatisering opleggen, handmatige of out-of-band-wijzigingen voorkomen en specifieke wijzigingen valideren in de omgeving voordat ze worden uitgevoerd.
- Zorg ervoor dat destructieve bewerkingen 'zacht' zijn. Zachte bewerkingen worden niet onmiddellijk van kracht of kunnen binnen een tijdvenster ongedaan worden gemaakt.
Service Fabric biedt mechanismen om operationele fouten te voorkomen, zoals op rollen gebaseerd toegangsbeheer voor clusterbewerkingen. Voor de meeste operationele fouten zijn echter organisatie-inspanningen en andere systemen vereist. Service Fabric biedt mechanismen voor het overleven van operationele fouten, met name back-up en herstel voor stateful services.
Fouten beheren
Het doel van Service Fabric is automatisch beheer van fouten. Maar om bepaalde typen fouten af te handelen, moeten services aanvullende code hebben. Andere soorten fouten mogen niet automatisch worden aangepakt om veiligheids- en bedrijfscontinuïteitsredenen.
Enkele fouten afhandelen
Enkele machines kunnen om allerlei redenen mislukken. Soms zijn het hardwareoorzaken, zoals voedingen en netwerkhardwarefouten. Andere fouten bevinden zich in software. Dit zijn onder andere fouten van het besturingssysteem en de service zelf. Service Fabric detecteert automatisch deze typen fouten, waaronder gevallen waarin de machine wordt geïsoleerd van andere computers vanwege netwerkproblemen.
Ongeacht het type service, leidt het uitvoeren van één exemplaar tot downtime voor die service als die ene kopie van de code om welke reden dan ook mislukt.
Als u één fout wilt afhandelen, kunt u er het eenvoudigst voor zorgen dat uw services standaard op meer dan één knooppunt worden uitgevoerd. Voor staatloze services moet u ervoor zorgen dat deze InstanceCount groter is dan 1. Voor stateful services is de minimale aanbeveling dat TargetReplicaSetSize en MinReplicaSetSize beide zijn ingesteld op 3. Door meer exemplaren van uw servicecode uit te voeren, zorgt u ervoor dat uw service elke fout automatisch kan afhandelen.
Gecoördineerde fouten afhandelen
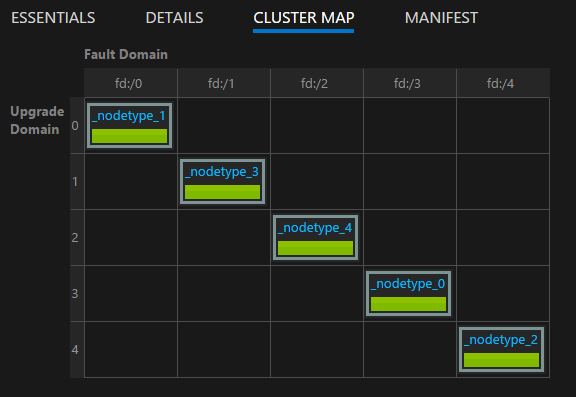
Gecoördineerde fouten in een cluster kunnen worden veroorzaakt door geplande of ongeplande infrastructuurfouten en -wijzigingen, of geplande softwarewijzigingen. Service Fabric modelleert infrastructuurzones die gecoördineerde fouten ervaren als foutdomeinen. Gebieden die gecoördineerde softwarewijzigingen ervaren, worden gemodelleerd als upgradedomeinen. Zie Een Service Fabric-cluster beschrijven met behulp van Cluster Resource Manager voor meer informatie over foutdomeinen, upgradedomeinen en clustertopologie.
Service Fabric beschouwt standaard fout- en upgradedomeinen bij het plannen waar uw services moeten worden uitgevoerd. Service Fabric probeert standaard ervoor te zorgen dat uw services worden uitgevoerd in verschillende fout- en upgradedomeinen, zodat uw services beschikbaar blijven als geplande of niet-geplande wijzigingen plaatsvinden.
Stel dat uitval van een voedingsbron ervoor zorgt dat alle machines in een rek tegelijkertijd mislukken. Als er meerdere exemplaren van de service worden uitgevoerd, verandert het verlies van veel computers in foutdomeinfouten in slechts een ander voorbeeld van één fout voor een service. Daarom is het beheren van fout- en upgradedomeinen essentieel om hoge beschikbaarheid van uw services te garanderen.
Wanneer u Service Fabric uitvoert in Azure, worden foutdomeinen en upgradedomeinen automatisch beheerd. In andere omgevingen zijn ze mogelijk niet. Als u uw eigen clusters on-premises bouwt, moet u de indeling van uw foutdomein correct toewijzen en plannen.
Upgradedomeinen zijn handig voor het modelleren van gebieden waar software tegelijkertijd wordt bijgewerkt. Daarom definiëren upgradedomeinen ook vaak de grenzen waar software wordt verwijderd tijdens geplande upgrades. Upgrades van Zowel Service Fabric als uw services volgen hetzelfde model. Zie voor meer informatie over rolling upgrades, upgradedomeinen en het Service Fabric-statusmodel waarmee onbedoelde wijzigingen niet van invloed zijn op het cluster en uw service:
U kunt de indeling van uw cluster visualiseren met behulp van de clustertoewijzing in Service Fabric Explorer:
Notitie
Modelleringsgebieden van fouten, rolling upgrades, het uitvoeren van veel exemplaren van uw servicecode en status, plaatsingsregels om ervoor te zorgen dat uw services worden uitgevoerd in fout- en upgradedomeinen, en ingebouwde statuscontrole zijn slechts enkele van de functies die Service Fabric biedt om normale operationele problemen en storingen te voorkomen.
Gelijktijdige hardware- of softwarefouten verwerken
We hebben het gehad over enkele fouten. Zoals u kunt zien, zijn ze eenvoudig te verwerken voor staatloze en stateful services door meer kopieën van de code (en status) te bewaren die worden uitgevoerd in fout- en upgradedomeinen.
Er kunnen ook meerdere gelijktijdige willekeurige fouten optreden. Deze leiden waarschijnlijker tot downtime of een werkelijke ramp.
Stateless services
Het aantal exemplaren voor een staatloze service geeft het gewenste aantal exemplaren aan dat moet worden uitgevoerd. Wanneer een (of alle) exemplaren mislukken, reageert Service Fabric door automatisch vervangingsexemplaren op andere knooppunten te maken. Service Fabric blijft vervangingen maken totdat de service weer terug is naar het gewenste aantal exemplaren.
Stel dat de staatloze service de InstanceCount waarde -1 heeft. Deze waarde betekent dat één exemplaar moet worden uitgevoerd op elk knooppunt in het cluster. Als sommige van deze exemplaren mislukken, detecteert Service Fabric dat de service niet de gewenste status heeft en probeert de exemplaren te maken op de knooppunten waar ze ontbreken.
Stateful services
Er zijn twee soorten stateful services:
- Stateful met persistente status.
- Stateful met niet-persistente status. (Status wordt opgeslagen in het geheugen.)
Herstel van een stateful service is afhankelijk van het type stateful service, hoeveel replica's de service had en hoeveel replica's zijn mislukt.
In een stateful service worden binnenkomende gegevens gerepliceerd tussen replica's (de primaire en actieve secundaire databases). Als een meerderheid van de replica's de gegevens ontvangt, worden gegevens beschouwd als quorum dat is doorgevoerd. (Voor vijf replica's is drie een quorum.) Dit betekent dat er op elk moment ten minste een quorum van replica's met de meest recente gegevens is. Als replica's mislukken (bijvoorbeeld twee van de vijf), kunnen we de quorumwaarde gebruiken om te berekenen of we kunnen herstellen. (Omdat de resterende drie van de vijf replica's nog steeds up zijn, is het gegarandeerd dat ten minste één replica volledige gegevens bevat.)
Wanneer een quorum met replica's mislukt, wordt de partitie gedeclareerd dat deze de status quorumverlies heeft. Stel dat een partitie vijf replica's heeft, wat betekent dat ten minste drie gegarandeerd volledige gegevens hebben. Als een quorum (drie van de vijf) replica's mislukt, kan Service Fabric niet bepalen of de resterende replica's (twee op vijf) voldoende gegevens hebben om de partitie te herstellen. In gevallen waarin Service Fabric quorumverlies detecteert, is het standaardgedrag om extra schrijfbewerkingen naar de partitie te voorkomen, quorumverlies te declareren en te wachten tot een quorum van replica's is hersteld.
Bepalen of er een noodgeval is opgetreden voor een stateful service en vervolgens het beheer ervan volgt drie fasen:
Bepalen of er quorumverlies is of niet.
Quorumverlies wordt gedeclareerd wanneer een meerderheid van de replica's van een stateful service tegelijkertijd uitvalt.
Bepalen of het quorumverlies permanent is of niet.
Meestal zijn fouten tijdelijk. Processen worden opnieuw opgestart, knooppunten worden opnieuw opgestart, virtuele machines worden opnieuw gestart en netwerkpartities worden hersteld. Soms zijn fouten echter permanent. Of fouten permanent zijn of niet, is afhankelijk van of de stateful service de status behoudt of dat deze alleen in het geheugen wordt bewaard:
- Voor services zonder permanente status resulteert een storing in een quorum of meer replica's onmiddellijk in permanent quorumverlies. Wanneer Service Fabric quorumverlies in een stateful niet-permanente service detecteert, gaat het onmiddellijk verder met stap 3 door gegevensverlies (potentieel) te declareren. Het is logisch om door te gaan met gegevensverlies, omdat Service Fabric weet dat er geen punt is om te wachten tot de replica's terugkomen. Zelfs als ze herstellen, gaan de gegevens verloren vanwege de niet-persistente aard van de service.
- Voor stateful permanente services zorgt een storing in een quorum of meer replica's ervoor dat Service Fabric wacht totdat de replica's terugkomen en het quorum herstellen. Dit resulteert in een servicestoring voor schrijfbewerkingen naar de betreffende partitie (of 'replicaset') van de service. Leesbewerkingen kunnen echter nog steeds mogelijk zijn met beperkte consistentiegaranties. De standaardtijd die Service Fabric wacht totdat het quorum wordt hersteld, is oneindig, omdat de procedure een (potentiële) gebeurtenis voor gegevensverlies is en andere risico's met zich meebrengt. Dit betekent dat Service Fabric niet verdergaat met de volgende stap, tenzij een beheerder actie onderneemt om gegevensverlies te declareren.
Bepalen of gegevens verloren gaan en herstellen vanuit back-ups.
Als quorumverlies is gedeclareerd (automatisch of via administratieve actie), gaan Service Fabric en de services verder om te bepalen of gegevens daadwerkelijk verloren zijn gegaan. Op dit moment weet Service Fabric ook dat de andere replica's niet terugkomen. Dat was de beslissing die we hebben genomen toen we stopten met wachten op het quorumverlies om zichzelf op te lossen. De beste procedure voor de service is meestal om te blokkeren en te wachten op specifieke administratieve interventie.
Wanneer Service Fabric de
OnDataLossAsyncmethode aanroept, is dit altijd het gevolg van vermoedelijk gegevensverlies. Service Fabric zorgt ervoor dat deze aanroep wordt geleverd aan de beste resterende replica. Dit is de replica die de meeste vooruitgang heeft geboekt.De reden waarom we altijd zeggen dat verdacht gegevensverlies is, is dat de resterende replica dezelfde status heeft als de primaire replica toen het quorum verloren ging. Maar zonder die status om deze te vergelijken, is er geen goede manier om Service Fabric of operators zeker te weten.
Wat doet een typische implementatie van de
OnDataLossAsyncmethode?De implementatielogboeken die
OnDataLossAsynczijn geactiveerd en worden eventuele benodigde administratieve waarschuwingen geactiveerd.Normaal gesproken wordt de implementatie onderbroken en wordt gewacht op verdere beslissingen en handmatige acties. Dit komt doordat zelfs als er back-ups beschikbaar zijn, ze mogelijk moeten worden voorbereid.
Als twee verschillende services bijvoorbeeld informatie coördineren, moeten deze back-ups mogelijk worden gewijzigd om ervoor te zorgen dat na het herstellen de informatie die voor deze twee services belangrijk is, consistent is.
Vaak is er een andere telemetrie of uitputting van de service. Deze metagegevens kunnen zijn opgenomen in andere services of in logboeken. Deze informatie kan indien nodig worden gebruikt om te bepalen of er aanroepen zijn ontvangen en verwerkt op de primaire die niet aanwezig waren in de back-up of gerepliceerd naar deze specifieke replica. Deze aanroepen moeten mogelijk opnieuw worden afgespeeld of aan de back-up worden toegevoegd voordat herstel mogelijk is.
De implementatie vergelijkt de status van de resterende replica met die in alle beschikbare back-ups. Als u betrouwbare Service Fabric-verzamelingen gebruikt, zijn er hulpprogramma's en processen beschikbaar om dit te doen. Het doel is om te zien of de status binnen de replica voldoende is en om te zien wat de back-up mogelijk ontbreekt.
Nadat de vergelijking is voltooid en nadat het herstellen is voltooid (indien nodig), moet de servicecode waar retourneren als er statuswijzigingen zijn aangebracht. Als de replica heeft vastgesteld dat het de beste beschikbare kopie van de status was en geen wijzigingen heeft aangebracht, retourneert de code onwaar.
Een waarde van true geeft aan dat andere resterende replica's nu mogelijk inconsistent zijn met deze replica. Ze worden verwijderd en opnieuw opgebouwd vanaf deze replica. Een waarde van false geeft aan dat er geen statuswijzigingen zijn aangebracht, zodat de andere replica's kunnen behouden wat ze hebben.
Het is van cruciaal belang dat serviceauteurs potentiële scenario's voor gegevensverlies en storingen uitvoeren voordat services in productie worden geïmplementeerd. Ter bescherming tegen de mogelijkheid van gegevensverlies is het belangrijk om periodiek een back-up te maken van de status van een van uw stateful services naar een geografisch redundant archief.
U moet er ook voor zorgen dat u de status kunt herstellen. Omdat back-ups van veel verschillende services op verschillende tijdstippen worden gemaakt, moet u ervoor zorgen dat uw services na een herstel een consistente weergave van elkaar hebben.
Denk bijvoorbeeld aan een situatie waarin een service een getal genereert en opslaat en deze vervolgens naar een andere service verzendt waarin deze ook wordt opgeslagen. Na een herstelbewerking ontdekt u mogelijk dat de tweede service het nummer heeft, maar de eerste niet, omdat de back-up die bewerking niet heeft opgenomen.
Als u erachter komt dat de resterende replica's onvoldoende zijn om door te gaan in een scenario voor gegevensverlies en u de servicestatus niet kunt reconstrueren op basis van telemetrie of uitputting, bepaalt de frequentie van uw back-ups uw best mogelijke RPO (Recovery Point Objective). Service Fabric biedt veel hulpprogramma's voor het testen van verschillende foutscenario's, waaronder permanent quorum en gegevensverlies waarvoor herstel van een back-up is vereist. Deze scenario's worden opgenomen als onderdeel van de testbaarheidshulpprogramma's in Service Fabric, die worden beheerd door de Fault Analysis Service. Zie Inleiding tot de Foutanalyseservice voor meer informatie over deze hulpprogramma's en patronen.
Notitie
Systeemservices kunnen ook quorumverlies ondervinden. De impact is specifiek voor de betreffende service. Quorumverlies in de naamgevingsservice is bijvoorbeeld van invloed op naamomzetting, terwijl quorumverlies in de Failover Manager-service het maken en failovers van nieuwe services blokkeert.
De Service Fabric-systeemservices volgen hetzelfde patroon als uw services voor statusbeheer, maar we raden u niet aan om ze uit quorumverlies en mogelijk gegevensverlies te verplaatsen. In plaats daarvan raden we u aan om ondersteuning te zoeken naar een oplossing die is gericht op uw situatie. Het verdient meestal de voorkeur om gewoon te wachten totdat de replica's omlaag terugkeren.
Problemen met quorumverlies oplossen
Replica's kunnen af en toe offline zijn vanwege een tijdelijke fout. Wacht even totdat Service Fabric ze probeert op te halen. Als replica's langer dan verwacht zijn, volgt u deze probleemoplossingsacties:
- Replica's kunnen vastlopen. Controleer statusrapporten op replicaniveau en uw toepassingslogboeken. Verzamel crashdumps en voer de benodigde acties uit om te herstellen.
- Het replicaproces reageert mogelijk niet meer. Inspecteer uw toepassingslogboeken om dit te controleren. Verzamel procesdumps en stop het niet-reagerende proces. Service Fabric maakt een vervangingsproces en probeert de replica terug te brengen.
- Knooppunten waarop de replica's worden gehost, zijn mogelijk niet beschikbaar. Start de onderliggende virtuele machine opnieuw op om de knooppunten weer op te halen.
Soms is het niet mogelijk om replica's te herstellen. De stations zijn bijvoorbeeld mislukt of de machines reageren niet fysiek. In dergelijke gevallen moet Service Fabric worden verteld om niet te wachten op herstel van replica's.
Gebruik deze methoden niet als mogelijk gegevensverlies onaanvaardbaar is om de service online te brengen. In dat geval moeten alle inspanningen worden gedaan om fysieke machines te herstellen.
De volgende acties kunnen leiden tot gegevensverlies. Controleer voordat u ze volgt.
Notitie
Het is nooit veilig om deze methoden te gebruiken, behalve op een gerichte manier tegen specifieke partities.
- Gebruik de
Repair-ServiceFabricPartition -PartitionIdofSystem.Fabric.FabricClient.ClusterManagementClient.RecoverPartitionAsync(Guid partitionId)API. Met deze API kunt u de id van de partitie opgeven om uit quorumverlies en mogelijk gegevensverlies te komen. - Als uw cluster frequente fouten tegenkomt waardoor services in een quorumverliesstatus komen en mogelijk gegevensverlies acceptabel is, kan het opgeven van een geschikte QuorumLossWaitDuration-waarde ervoor zorgen dat uw service automatisch kan worden hersteld. Service Fabric wacht op de opgegeven
QuorumLossWaitDurationwaarde (standaard is oneindig) voordat u herstel uitvoert. We raden deze methode niet aan omdat deze onverwachte gegevensverlies kan veroorzaken.
Beschikbaarheid van het Service Fabric-cluster
Over het algemeen is het Service Fabric-cluster een zeer gedistribueerde omgeving zonder single points of failure. Een fout van één knooppunt veroorzaakt geen beschikbaarheids- of betrouwbaarheidsproblemen voor het cluster, voornamelijk omdat de Service Fabric-systeemservices dezelfde richtlijnen volgen die eerder zijn opgegeven. Dat wil gezegd, ze worden altijd uitgevoerd met drie of meer replica's, en systeemservices die staatloos worden uitgevoerd op alle knooppunten.
De onderliggende Service Fabric-netwerk- en foutdetectielagen zijn volledig gedistribueerd. De meeste systeemservices kunnen opnieuw worden opgebouwd op basis van metagegevens in het cluster of weten hoe ze hun status opnieuw moeten synchroniseren vanaf andere locaties. De beschikbaarheid van het cluster kan worden aangetast als systeemservices in situaties met quorumverlies komen, zoals eerder beschreven. In dergelijke gevallen kunt u mogelijk bepaalde bewerkingen op het cluster niet uitvoeren (zoals het starten van een upgrade of het implementeren van nieuwe services), maar het cluster zelf is nog steeds actief.
Services op een actief cluster blijven in deze omstandigheden actief, tenzij ze schrijfbewerkingen naar de systeemservices vereisen om door te gaan met functioneren. Als failoverbeheer bijvoorbeeld in quorumverlies is, blijven alle services actief. Maar services die mislukken, kunnen niet automatisch opnieuw worden opgestart, omdat hiervoor failoverbeheer vereist is.
Fouten in een datacenter of een Azure-regio
In zeldzame gevallen kan een fysiek datacenter tijdelijk niet beschikbaar zijn vanwege stroomverlies of netwerkconnectiviteit. In deze gevallen zijn uw Service Fabric-clusters en -services in dat datacenter of azure-gebied niet beschikbaar. Uw gegevens blijven echter behouden.
Voor clusters die worden uitgevoerd in Azure, kunt u updates bekijken over storingen op de azure-statuspagina. In het zeer onwaarschijnlijke geval dat een fysiek datacenter gedeeltelijk of volledig wordt vernietigd, kunnen alle Service Fabric-clusters die daar worden gehost, of de services erin, verloren gaan. Dit verlies omvat alle statussen waarvan geen back-up wordt gemaakt buiten dat datacenter of die regio.
Er zijn verschillende strategieën voor het overleven van de permanente of aanhoudende storing van één datacenter of regio:
Voer afzonderlijke Service Fabric-clusters uit in meerdere regio's en gebruik een mechanisme voor failover en failback tussen deze omgevingen. Voor dit soort actieve/actieve of actieve/passieve modellen met meerdere clusters is extra beheer- en bewerkingscode vereist. Dit model vereist ook coördinatie van back-ups van de services in het ene datacenter of de regio, zodat ze beschikbaar zijn in andere datacenters of regio's wanneer een storing optreedt.
Voer één Service Fabric-cluster uit dat meerdere datacenters omvat. De minimaal ondersteunde configuratie voor deze strategie is drie datacenters. Zie Een Service Fabric-cluster implementeren in Beschikbaarheidszones voor meer informatie.
Voor dit model is extra installatie vereist. Het voordeel is echter dat het mislukken van één datacenter wordt omgezet van een noodgeval in een normale fout. Deze fouten kunnen worden verwerkt door de mechanismen die werken voor clusters binnen één regio. Foutdomeinen, upgradedomeinen en Service Fabric-plaatsingsregels zorgen ervoor dat workloads worden gedistribueerd, zodat ze normale fouten verdragen.
Zie Plaatsingsbeleid voor Service Fabric-services voor meer informatie over beleidsregels die u kunnen helpen bij het uitvoeren van services in dit type cluster.
Voer één Service Fabric-cluster uit dat meerdere regio's omvat met behulp van het zelfstandige model. Het aanbevolen aantal regio's is drie. Zie Een zelfstandig cluster maken voor meer informatie over de zelfstandige Service Fabric-installatie.
Willekeurige fouten die leiden tot clusterfouten
Service Fabric heeft het concept seed-knooppunten. Dit zijn knooppunten die de beschikbaarheid van het onderliggende cluster behouden.
Seed-knooppunten helpen ervoor te zorgen dat het cluster actief blijft door leases met andere knooppunten tot stand te brengen en als tiebreakers te fungeren tijdens bepaalde soorten storingen. Als willekeurige fouten het merendeel van de seed-knooppunten in het cluster verwijderen en ze niet snel worden teruggehaald, wordt uw cluster automatisch afgesloten. Het cluster mislukt.
In Azure beheert De Service Fabric-resourceprovider service fabric-clusterconfiguraties. Resource Provider distribueert standaard seed-knooppunten over fout- en upgradedomeinen voor het primaire knooppunttype. Als het primaire knooppunttype is gemarkeerd als Silver- of Gold-duurzaamheid, probeert het cluster bij het verwijderen van een seed-knooppunt (door te schalen in het primaire knooppunttype of door het handmatig te verwijderen), een ander niet-seed-knooppunt uit de beschikbare capaciteit van het primaire knooppunttype te promoten. Deze poging mislukt als u minder beschikbare capaciteit hebt dan het betrouwbaarheidsniveau van uw cluster vereist voor het primaire knooppunttype.
In zowel zelfstandige Service Fabric-clusters als Azure is het primaire knooppunttype het type dat de zaden uitvoert. Wanneer u een primair knooppunttype definieert, profiteert Service Fabric automatisch van het aantal knooppunten dat wordt geleverd door maximaal negen seed-knooppunten en zeven replica's van elke systeemservice te maken. Als een set willekeurige fouten een meerderheid van deze replica's tegelijk uitneemt, worden de quorumverlies door de systeemservices ingevoerd. Als een meerderheid van de seed-knooppunten verloren gaat, wordt het cluster kort daarna afgesloten.
Volgende stappen
- Meer informatie over het simuleren van verschillende fouten met behulp van het testbaarheidsframework.
- Lees andere resources voor herstel na noodgevallen en hoge beschikbaarheid. Microsoft heeft een grote hoeveelheid richtlijnen voor deze onderwerpen gepubliceerd. Hoewel sommige van deze resources verwijzen naar specifieke technieken voor gebruik in andere producten, bevatten ze veel algemene aanbevolen procedures die u in de Service Fabric-context kunt toepassen:
- Meer informatie over service fabric-ondersteuningsopties.